
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Привет! Меня зовут Юра, я работаю в компании Кристалл Сервис Интеграция, занимаюсь доставкой софта нашим клиентам и пишу плейбуки. Я расскажу, почему мы используем модель On-Premise, какие инструменты применяем и с какими проблемами сталкиваемся. Моей целью не будет детальное описание наших методов и предоставление точных рецептов (это я оставлю на потом, тем более, что мы и сами находимся в постоянном поиске и оптимизации). Думаю, коллеги ДевОпсы (да, да, я знаю, что ДевОпс — не человек, а пароход) захотят технических подробностей, а каких конкретно — надеюсь выяснить по результатам, чтобы в дальнейшем удовлетворить их интерес.
Происхождение частной собственности, персональных данных и тревожных состояний

Всем нам хочется контролировать. Владеть. Давайте подумаем, а действительно ли мы обладаем тем, что покупаем? Становимся ли мы хозяевами приобретаемой вещи, или пребываем в иллюзии владения? Логика нашего общества требует полного контроля за своими вещами, абсолютной собственности на них.
Всё становится сложнее, когда мы имеем дело с информацией. Данные. Data. Information. Личные данные. Всем нам звонила Служба Безопасности Сбербанка, а некоторые даже имели честь познакомиться со следователем уголовного розыска города Москвы. Печальный финал охраны наших сокровенных номеров паспортов, имён и фамилий.
Всё становится интереснее, когда мы имеем дело с чувствительной коммерческой информацией и процессами, эту информацию обрабатывающими. Здесь нам предстоит сделать трудный выбор — доверить её сохранность неизвестности или быть в ответе самим. Дополнительную пикантность ситуации придаёт то, что мы имеем дело не с какой-то скучной библиотекой, которую можно положить под замок и вынимать, когда приходят гости, чтобы порадовать их интересным предметом, а с постоянно меняющейся структурой, растущей и требующей обработки в реальном времени. Мы генерируем эту информацию постоянно, мы не можем её локализовать и обычно не знаем, какой объем будет создан в том или ином месте. Прогнозировать это мы способны, но, как и любой прогноз, он весьма не точен.
Как и в реальном мире, в мире информационных технологий немногие проблемы имеют однозначные решения. Поиск наилучшего — это всегда компромисс, всегда баланс вреда и пользы, опасности и спокойствия. Коммерческий проект в этом смысле есть равновесие рисков. Мы много времени и сил уделяем дизайну наших продуктов, поскольку они способны нарушить эту хрупкую гармонию, и никто вокруг не сможет вовремя заметить опасность, ведь у владельца данных нет такой компетенции. У нас же она есть, как и уверенность в полноте контроля. Это наш бизнес.
Действующие лица

Крупные сетевые ритейлеры с несколькими тысячами магазинов, в каждом из которых множество касс и интеллектуальных весов разных производителей, с иерархией персонала, скидочными акциями и программами лояльности, со своей ERP и CRM-системами. Со своим отделом разработки ПО и, бывает, тяжёлым легаси.
Торговые сети поменьше — магазинов уже не тысячи, в остальном никаких отличий. Такой же удельный объём данных, те же CRM/ERP-системы и не менее сложная организация.
Отдельные магазины и некрупные сети. Предъявляют такие же требования к процессингу данных, но относительная цена простоя для них гораздо выше из-за эффекта масштаба. У них может не быть своего отдела разработки, а инфраструктура отдана на аутсорс, или вовсе отсутствует.
Компания «Кристалл Сервис Интеграция». Это мы. Разрабатываем программные экосистемы для розничной торговли (Set Retail, Set Prisma). Умеем обрабатывать миллионы чеков, делать процессинг программ лояльности, обрабатывать акцизные марки в разных проявлениях. Автоматизируем разнообразные процессы внутри торговых залов.
Магомед не идёт к горе

Все хотят контроля. Контроль — это спокойствие и надёжность, а, значит, и успех. Коммерческий успех — это то, к чему стремится бизнес, и мы ему это обеспечиваем. Чтобы бизнес обладал контролем, он должен быть способен в любой момент времени дотянуться до своих данных, до своего процессинга, до всего, что критически важно в его работе. Контроль над инфраструктурой — важная вещь, и его можно добиться разными способами.
Самый простой — воспользоваться сторонним сервисом на стороннем железе и не тратить время и нервы. Пусть все вопросы решают инженеры компании-провайдера SaaS решения. В таком принципе нет ничего порочного, кроме некоторых важных моментов, которые практически блокируют возможность его применить на практике в некоторых случаях. Во-первых, нельзя спрогнозировать ни скорость работы такого решения, ни оценить степень надёжности. Единственное, на что можно опереться - соглашение об уровне услуг - SLA. Я не стал бы утверждать, что такой документ гарантирует что-либо, кроме основания для разбора спорных моментов. С другой стороны не все SaaS одинаково бесполезны - покупая процессинг как сервис можно избавить себя от многих головных болей. Всё же я утверждаю - это подходит для небольших проектов, чей процессинг не критичен по времени, а возможные ошибки всегда поддаются исправлению в полевых условиях. Так же подходит и для сервисов, влияние которых на бизнес процессы не носит определяющий характер. Естественно исключения есть везде. В некоторых случаях такое решение оптимально. Кстати, мы делаем ряд продуктов именно с такой архитектурой, так что понимаем все преимущества.
Можно разместить важные функции в чужой облачной инфраструктуре, например AWS или Google cloud, не покупая при этом у них саму бизнес логику, но приобрести кучу разного программного обеспечения — сервисов, баз данных, инструкций к нему. Собственно наше ПО. Научится его устанавливать, эксплуатировать, обновлять, чинить в случае падения. Интегрировать в свою существующую инфраструктуру ведь, скорее всего, мы начинаем не с нуля. Звучит громоздко, трудоёмко и сложно. На практике даже хуже: коллектив IT-отдела от такого может приуныть, а это чертовски дорого в наших реалиях. Нанимать дополнительных сотрудников — ещё печальнее — даже если всё пройдёт удачно и через пару месяцев таковые сотрудники придут, им придётся изучить чужой софт, пройтись по граблям и после всего этого, скорее всего, применить План Б.
Важный момент — законы многих стран регулируют местоположение некоторой информации, делая невозможным размещение в датацентрах Амазона, Гугла. Алибабы и подобных. Это наш случай.
Приведу небольшую табличку про отличия разных концепций:
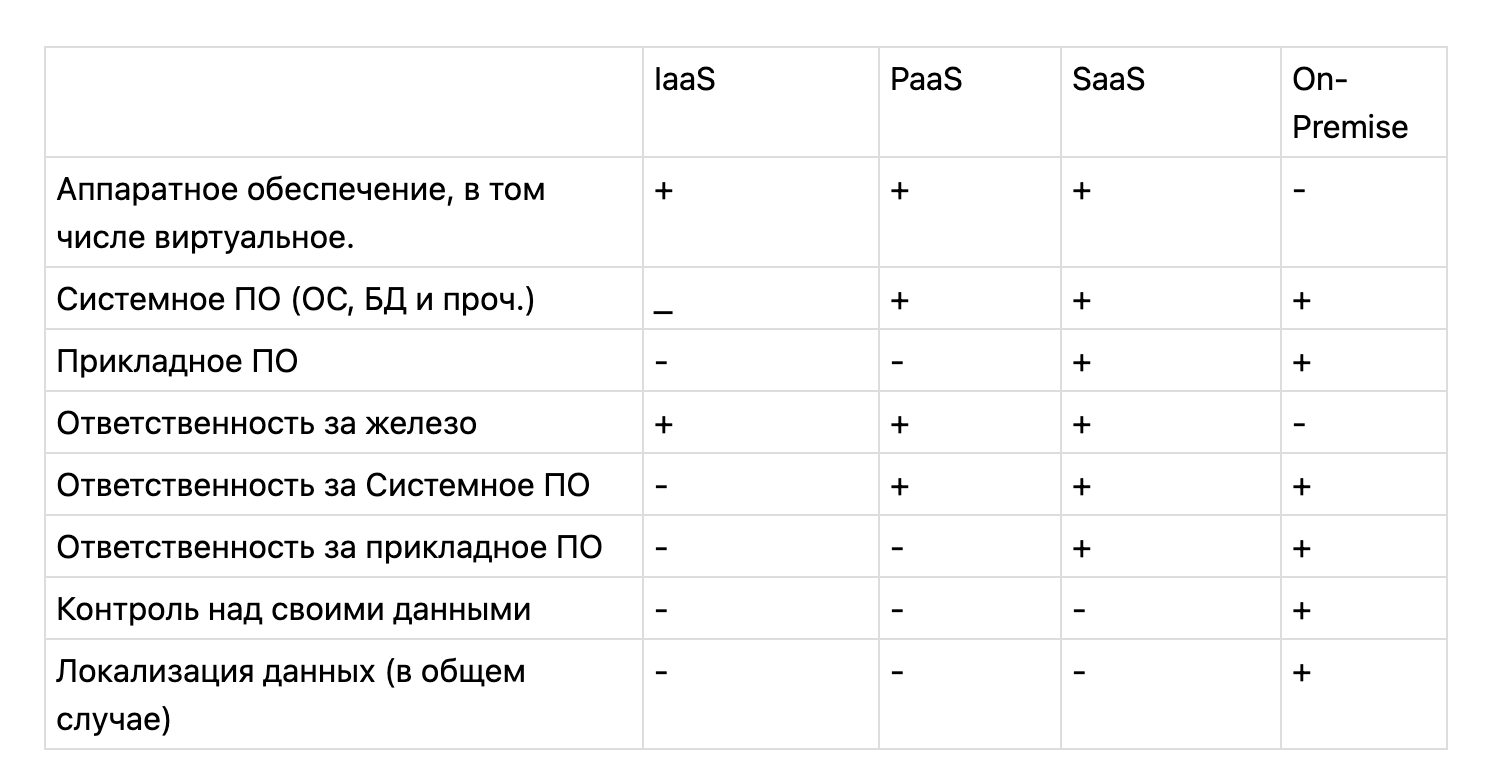
Есть прекрасная альтернатива облачным сервисам — собственное железо. Максимальный контроль при альтернативных затратах. Тот самый случай! Если компания не сильно децентрализована, то и дизайн датацентра не так важен, главное — обеспечить надёжность и предсказуемость соединения и хранения данных. Не уверен, но подозреваю, что некоторые наши клиенты держат машины прямо в магазинах. Тем не менее всё тот же вопрос сохраняет актуальность — как софт, ради которого всё и затевалось, окажется на этом железе и интегрируется в уже существующий, а также в процессы предприятия? Нужен План Б!
Наконец, бывают любые сочетания, вплоть до самых экзотических — железо в собственном датацентре дополняется виртуальным от провайдера, некоторые некритичные процессы внедрены как SaaS (у нас есть несколько таких). И всё это должно работать как единое целое.
Бизнес склонен к оптимизации. Склонен — не значит всегда оптимален, но этот вопрос оставим на потом. Клиенты не хотят решать проблемы дорогим и сложным способом, тем более, что в дальнейшем он не принесёт им никаких «value». Они не идут к той горе софта, которая требуется им для успеха. Это не их проблема. Мы привезём им эту гору, независимо от того, какое железо и где оно находится, лишь бы оно соответствовало нашим, весьма разумным требованиям, которые совсем не сложно соблюсти.
План Б. On-prem software

Напомню, что такое On-prem программное обеспечение и чем оно отличается от off-prem, называемого обычно SaaS, то есть Software as a Service. Всё просто, практически назад к истокам. On-prem ПО находится на железе клиента, принадлежит ему и контролируется им, в противоположность программного обеспечения как сервис, которое не принадлежит потребителю этого сервиса и им не контролируется. Конечно, мы обслуживаем его, а иначе всё написанное выше было бы написано зря.

Мы доставляем

В нашем случае мы доставляем не только софт, но и его логическую инфраструктуру. Сейчас расскажу подробнее.
Выше я кратко описал наших клиентов. Они разного размера, географической локализации, с разным ассортиментом, но с точки зрения процессов они весьма похожи. Для нас не важно, какого объёма трафик у клиента и сколько чеков он генерирует в секунду — мы умеем масштабировать наши решения для каждого конкретного случая.
У каждого нашего клиента своё оборудование. Разное. Это было бы проблемой, если бы мы пользовались древней как мамонт и такой же понятной всем методикой установки — пакетными дистрибутивами. В таком случае обеспечить повторяемость, предсказуемость и надёжность, вероятно, не вышло бы. Кроме того, трудоёмкость процесса могла быть запредельной, ведь речь идёт не об одной машине, а о целом датацентре, хоть и небольшом. К счастью, будущее уже наступило и мы можем высвободить всю мощь технологий на наше благо.
Let’s Rock!
Ansible Playbooks. Многие думают, что плейбук переводится как «сборник пьес(plays)», но даже Гугл знает, что это ещё и «схема игры». Ребята, которые делали Ансибл, видели его как тренера у бейсболистов, который вручает им те самые плейбуки и “Go ahead, guys, let’s rock!”. А чтобы получился рок, нам надо постараться.
Мы пользуемся не таким уж большим количеством инструментов для доставки наших приложений. Это классический Гит для хранения кода и описания инфраструктуры, Ансибл для его доставки, а также для провижининга машин клиента. Под провижинингом мы понимаем установку элементов логической инфраструктуры и донастройку самих машин для участия в кластерах наших приложений.
Большая боль для нас — зоопарк дистрибутивов операционных систем и их версий. Конечно, мы бы могли написать убер-роли и плейбуки, которые можно загонять на любые операционки в зависимости от дистрибутива и версии, а также от предустановленных пакетов. Это плохое решение. Во-первых, это было бы громоздко и потенциально ненадёжно — кто видел универсальные роли из Ansible galaxy, меня поймут. Во-вторых, разработка и поддержание заняли бы уйму времени, а, в третьих, гораздо логичнее сформировать стандарт на операционные системы, которые стоят в инфраструктуре клиента. Это драматически упрощает всю подготовку с обеих сторон. Мы используем Centos 7 — minimal. Понимаем, что скоро предстоит подкрутить роли под то, что заменит старый добрый Цент, но этот вопрос разберём уже в следующей серии. В любом случае, мы решаем конкретную задачу — создать у клиента надёжный процессинг, а не написать универсальный комбайн на все случаи жизни. Этого подхода мы придерживаемся и в разработке самих приложений, и в разработке инфраструктуры. Кстати, я обратил внимание на подход к выбору ОС у наших критиков — установка полноценной Убунты 18.04 на кассовый аппарат. Как раз решение из разряда «пусть будет, авось пригодится». Со всеми, видимо, пакетами, зависимостями и уязвимостями. О быстродействии такого решения и говорить страшно. Такой вот отход от Unix-way. Мы, в свою очередь, всё же ему следуем.
В нашем репозитории лежат описания не просто отдельных компонентов инфраструктуры, а описание датацентра с ней целиком. Каждый раз, когда мы устанавливаем наше ПО клиенту, мы строим у него всё. Вообще всё. Поэтому температура под нами возрастает пропорционально количеству дополнительных пакетов, которые «случайно» оказались на машинах, нам предоставленных. Обычное дело — на тестовом окружении (а у нас принято, что каждый клиент имеет минимум одно под нашу интеграцию) стоит прекрасный набор пакетов, ничего лишнего, всё работает и нам хорошо. Когда же мы начинаем строить продакшн, вдруг оказывается, что на машине завёлся, к примеру, пайтон модной версии или какой-нибудь порт занят неизвестно (на самом деле, известно) чем. Мы научились решать такие коллизии просто и со вкусом — достаточно установить седьмую Центос в минимальной поставке и наши проблемы сами собой решаются.
Мы постарались сделать так, чтобы масштабирование происходило на уровне инвентори, без кастомных плейбуков, без допиливания по месту и прочей потенциально опасной истории. Некоторые клиенты по своему дизайну требуют кастомные модули. Например, наша реализация паттерна ESB (Enterprise Service Bus, транспортная шина предприятия) часто требует клиентозависимых сервисов, ведь у многих своё легаси и свои системы, которые используют разные модели данных. Я обращал на это внимание выше. Это, пожалуй, единственный случай, когда приходится адаптировать наш продукт под клиента на этапе деплоя. Наша модель организации описания инфраструктуры легко позволяет делать такое. Мы просто допишем сколько надо плейбуков (скорее всего, один) — и не будем устраивать аттракцион с «универсальными скриптами», которые потенциально могут установить не то и не туда. Мы за здоровый минимализм, с одной стороны, и против автоматизации ради автоматизации, с другой.
Архитектура — классика или модерн?

Я не скажу за всё вообще ПО, написанное нами, но актуальные на сегодняшний день решения строятся в парадигме микросервисной архитектуры и являются горизонтально масштабируемыми. Этот принцип органично вытекает из нашей специфики и диктуется клиентом. Такая имплементация Domain Driven Development (DDD). Само собой, воспользоваться преимуществами этой архитектуры было бы невозможно без IaC, но она тянет за собой и другие решения, без которых трудно представить современную разработку, да ещё и DevOps процесс. Как всегда, со своими особенностями.
Я упомянул выше, что у каждого нашего клиента есть тестовые окружения, находящиеся примерно там же, где и боевые. У некоторых этих стендов несколько — на каждый продукт. Мы изолируем компоненты: лучше иметь несколько обособленных кластеров, отказ одного из которых — невероятная сама по себе вещь. Тем не менее мы считаем, что дополнительные ресурсы, выделенные на организацию дополнительной инфраструктуры, тотально повышают надёжность. Общее количество поддерживаемых окружений — сотни, и каждое их них критически важное. Как же мы не путаемся в этом множестве?
Стандартизация
Итак. Контейнеры докера, запущенные под docker, crio или containerd с оркестратором — индустриальный стандарт. В качестве оркестратора мы выбрали Hashicorp Nomad. Почему не модный К8s? Надёжность, простота, предсказуемость. Контроль. Мы любим контроль, наши клиенты любят контроль. Номад — это один бинарник на Go, несколько серверов и клиентов, на которых выполняется docker. Функция сервера и клиента могут быть совмещены, оверхед совсем небольшой, так что в принципе можно назначить хоть поровну, и на каждой машине по экземпляру того и другого. Так делать не надо, конечно. Номад может работать как со многими драйверами контейнеров, так и с Java напрямую. Мы не используем его в таком режиме, но такая возможность требует упоминания. В качестве KV хранилища мы используем Hashicorp Consul — прекрасно подходящее нам решение, по стилю конфигурирования идентично с Номадом, по надёжности и простоте соответственно тоже. Консул мы используем и как конфиг сервер, и как дискавери. Недавно мы запилили свой инструмент для конфигурирования микросервисов самим клиентом или его командой эксплуатации - фронтенд, который позволяет безопасно менять конфигурации в Консуле без риска что-то сломать. Инструмент будет развиваться и, уверен, превратится в отдельный полезный продукт. Надо сказать, что часть нашего ПО написано на Spring, там есть своя имплементация взаимодействия с KV. Часть приложений её не используют, и мы воспользовались решением от того же Hashicorp - envconsul - процесс в контейнере, который берёт на себя пробрасывание конфига из консула в контейнер и перезапускает приложение, когда произошли изменения в KV. Решение, не лишённое недостатков, но надёжное. С точки зрения DevOps я не могу дать оценку этим двум подходам — в принципе, нет никаких проблем с обоими. С точки зрения разработки — с помощью envconsul можно быстро адаптировать приложение для работы c KV без доработки.
В качестве мониторинга мы используем связку Prometheus - Grafana. Они устанавливаются сразу вместе с кластером приложений и таким образом проактивная защита у всех клиентов имеется «из коробки». Отдельной болью стало создание оповещений в Графане для каждого клиента. Дело в том, что алерты приходят в наш сервис, в телеграм-чаты девопсов (это мы) и разработчикам. Есть необходимость правильной маршрутизации алертов. С этим вполне справляется Прометеус алерт-менеджер, но сами настройки в Графане требуется изменять от клиента к клиенту, а обычная джинджа в Ансибле — крайне негуманный для этого инструмент. Мы изучаем опыт коллег по использованию grafonnet - jsonnet библиотеки для генерации дашборд Графаны.
Как показала практика, сбор метрик может быть нетривиальной задачей в случае, если их количество на хосте становится шестизначным числом. Кафка с несколькими сотнями партиций, парой десятков топиков и несколькими тысячами консьюмеров может запросто положить мониторинг. Приходится решать и такие задачи.
Логирование. ELK стек. Сборка логов - filebeat/logstash. Простое и понятное решение. На сегодняшний день мы не применяем тяжёлых решений вроде кластеров из InfluxDb или транспорта логов сквозь Кафку — в масштабах отдельно взятого клиента это не требуется.
Послесловие
Сохранять и поддерживать, а, главное, доставлять софт в таких конфигурациях — несколько кластеров приложения, логирование и мониторинг до клиента без разнообразных приключений — мы умеем. Стандартизация, простота компонентов и проработанность их связи позволяют справляться даже в особо сложных случаях. В дальнейшем планируем упростить процесс таким образом, чтобы участие в нём коллектива девопсов свелось к минимуму и, возможно, пойдём по пути централизованного управления окружениями клиентов. Это несёт в себе не только преимущества — например, мы отказались от внедрения Tower/AWX, взвесив все «за» и «против». На это решение повлияла, в частности, хабростатья “Xудшие практики для Ansible”, где автор помимо всего упомянул и это решение, обратив внимание, что последний является журналом запусков, не решая при этом проблем самого Ансибла. Видимо, тот случай, когда своё решение будет самым лучшим.
Спасибо.


