
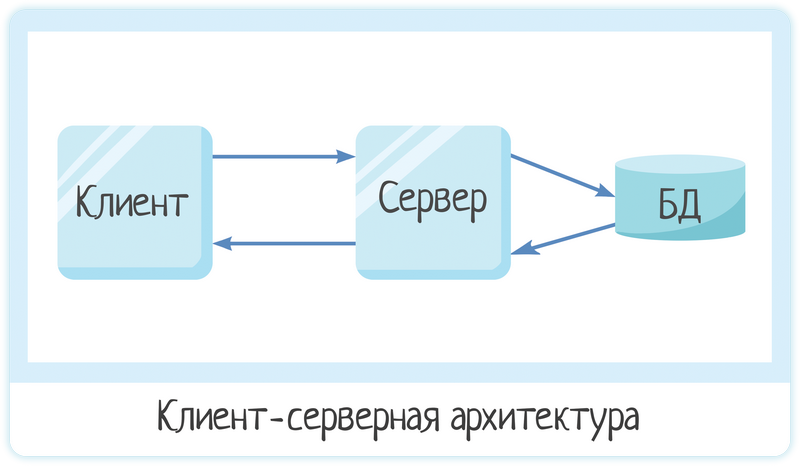
Знакомая картинка? А вы ведь постоянно сталкиваетесь с этой архитектурой — когда покупаете билет в кино онлайн, бронируете путевку на море или записываетесь ко врачу.
На клиент-серверной архитектуре построены все сайты и интернет-сервисы. Также ее используют десктоп-программы, которые передают данные по интернету. Поэтому ИТ-специалисту нужно понимать, что это такое и как работает.
Об этом я и расскажу в статье. Объясню на пальцах, с примерами и забавными картинками =) Если вы больше любите видео-формат, можно посмотреть мой ролик на youtube на ту же тему.
Содержание
- Что это и как работает
- Зачем нужен клиент
- Зачем нужен сервер
- Зачем нужна база
- Плюсы архитектуры
- Минусы архитектуры
- Что тестировать
- Итого
Что это и как работает
Вот есть у нас некий Вася, который решил купить машину. Такую, как в рекламе — быструю, мощную, красивую! Только стоит она как хвост самолета, у Васи таких денег нет.

Конечно, Вася может подкопить несколько лет, а потом уже покупать машину. Но ведь хочется здесь и сейчас! Да и средство передвижения нужно…
А еще Вася не умеет копить — получил зарплату, закупился основным, оплатил жилье, всё! Остальное можно потратить. Для таких людей есть банки, куда можно прийти и взять деньги в кредит.

Конечно, потом вы будете переплачивать, возвращая их назад. Проценты то конские. Но зато уже сейчас можете позволить купить себе что-то дорогое.
Вася подумал, прикинул и сказал:
— Да, хочу именно так! 100 рублей с зарплаты платить в банк могу, а откладывать — нет. Потрачу.
Поэтому Вася идет в банк и говорит:
— Я Василий Иванов, хочу автокредит на 1000р.

Операционистка Катя должна проверить его кредитную историю. Вдруг ему нельзя давать кредит, у него плохая история? Может, он уже набрал 10 кредитов и ни один не выплачивает? Или вдруг он вообще террист?! Нужно проверить, операционисты не знают черные списки наизусть.

У Кати есть специальная программа для проверки данных по клиентам. Эта программа может быть как web, так и desktop:
- Web — в браузере открыта, как google или facebook
- Desktop — на компьютере, как ворд или калькулятор
Это неважно, смотрит Катя в браузер или просто в программу. В любом случае это будет клиент. Клиент — это ваше приложение. То, с которым работает наша операционистка.

Катя вбивает в программу «Василий Иванов» и получает информацию по клиенту — есть ли он в черных списках? Была ли кредитная история раньше? И так далее. Но что происходит в потрохах приложения?
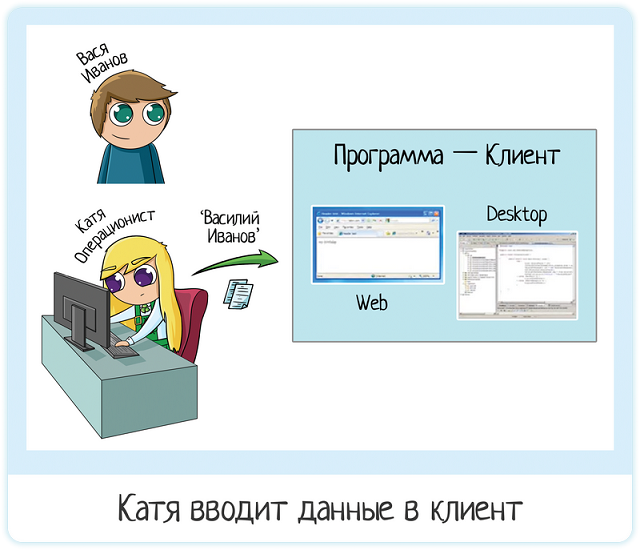
Катя ввела данные на клиенте. Но когда она нажала «проверить», клиент отправил запрос на сервер:
— Дай мне информацию по Васе Иванову!

Сервер отправил запрос в БД, базу данных:
— Select * from clients where fio = ‘Василий Иванов’. (Дай мне всю информацию по ФИО ‘Василий Иванов’)

База ответила:
— Вот тебе все, что нашла.

Сервер вернул эту информацию клиенту:
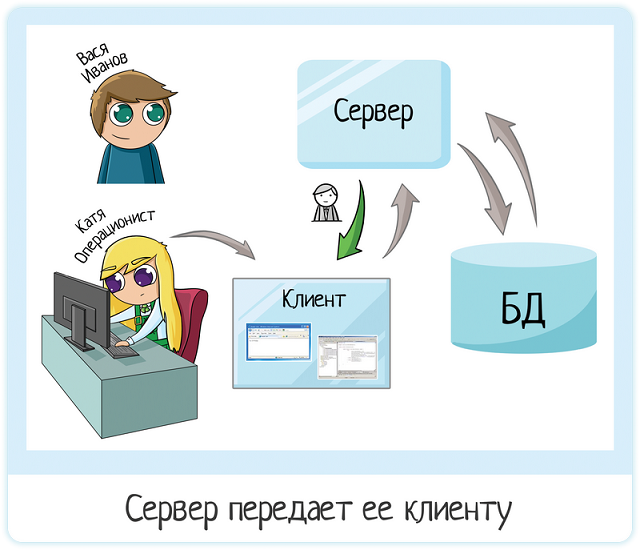
А клиент уже отрисовал ее для Кати:

Катя смотрит:
— Ага, кредитная история хорошая.

И делает предложение Васе:
— Пожалуйста, если хотите взять кредит, то мы готовы выделить 1000р на 12 лет под 80% годовых. Устроит?

Вася доволен:
— Да, меня всё устраивает, давайте скорее деньги, и я побежал за машиной!
Все счастливы, все довольны.

Катя даже не догадывается, какой путь проделали данные в программе, когда она вбила туда ФИО своего клиента. Но мы с вами должны узнать, что же это за путь такой? И к чему все эти сложности? Почему именно такая структура? Почему есть клиент, почему есть сервер?
Зачем нужен клиент
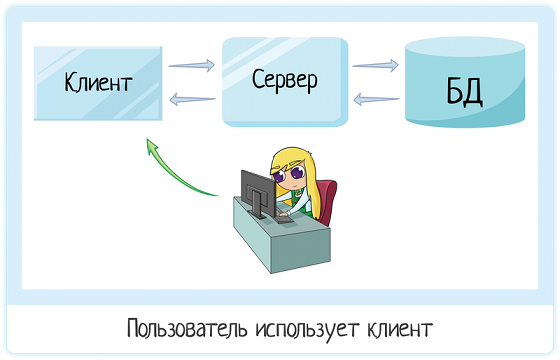
Тут все просто — с клиентом работает пользователь. Он нужен, чтобы превратить байтики программного кода в красивую и понятную картинку. Пользователь — не программист, он не понимает язык программирования или sql. Он понимает формочки и кнопочки. Их в клиенте и рисуем.
Зачем нужен сервер
Он мощнее
Клиентов может быть много. В примере с банком у нас может быть по 10 отделений в 10 городах России, а в каждом отделении по 10 операционисток. Тысяча Катек, и у каждой отдельный компьютер.
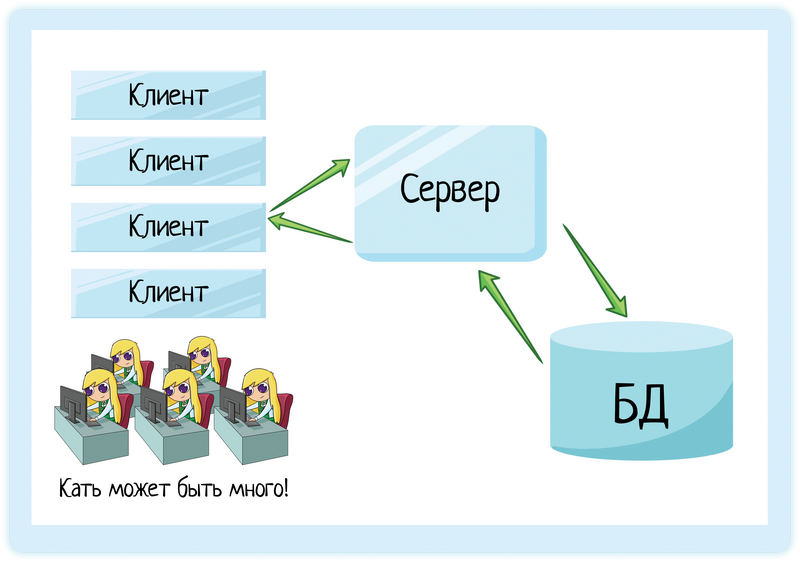
А мы ведь хотим, чтобы приложение работало быстро. Чтобы оно не тупило и не зависало, нервируя операциониста и заставляя клиента ждать. Значит, машина нужна мощная. Но если делать мощным каждый компьютер операциониста, денег придется вложить очень много!
Поэтому мы выносим всю основную логику на сервер. И вот его уже делаем мощным! А клиентские машины могут быть дешевыми, потому что на них остается лишь логика в стиле «запросить информацию и красиво отрисовать».
Нет дублирования кода
Если бы у нас были только клиентские машины, на каждой из них хранился бы одинаковый код по обработке логики, лежала вся база данных, все справочники террористов и прочая. Но так как сервер и БД вынесены в отдельные звенья, с клиентской машины освобождается куча места… И кода.
Не надо дублировать код, ведь вся основная логика вынесена на более мощный сервер.

Так безопаснее
На сервере и в базе хранится информация, недоступная простому операционисту. Это:
- Персональные данные клиентов
- Сведения о его финансах
- Черные списки банка
- ...
Зачем показывать эту информацию всем и каждому? Операционистка видит только свой интерфейс. Вбила ФИО — получила ответ, дать кредит или нет. Всё. Ей больше ничего не нужно.
Есть операционисты, готовые за денюшку слить информацию о клиентах. Есть нечистые на руку люди, готовые невзначай заглянуть через плечо. А, может, клиент сам такой человек. Представляете, отпихивает Вася хрупкую Катю, садится за ее компьютер, и переводит себе на счет миллионы, пока его не повяжет охрана.

Зачем нужна база
При чем же тут БД? Вот у нас есть наш сервер, пусть он и хранит всю информацию. Бывает и так, иногда база просто не нужна и у нас остается двузвенная архитектура клиент-сервер.
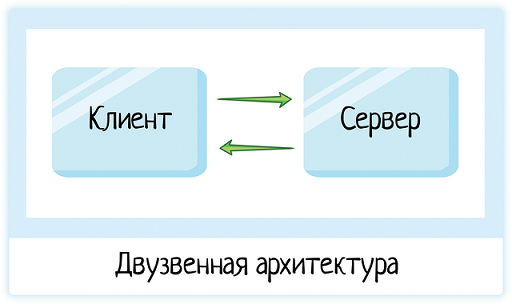
В таком случае все данных сервер хранит в памяти. Вот только если сервер упадет, или просто перезагрузится — вся информация будет потеряна. Все, что было в памяти, стирается при выключении системы.
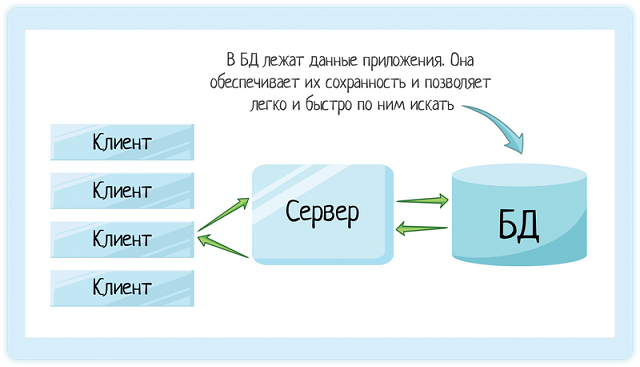
БД (база данных) — отдельный программный продукт, который позволяет:
- быстро делать выборки информации;
- сохранять информацию даже при рестарте системы.
То есть если вдруг пропадет сеть, база зависнет, машина с базой перезагрузится, или случится что-то другое, наши изменения не пропадут. Это называется персистентность. Достигается она за счет транзакций, которые откатываются, когда что-то идет не так. Но в этой статье мы углубляться в эту тему не будем ))
Да, базы может не быть. Но когда она есть, мы уверены в сохранности данных и легко можем по ним поискать.
Плюсы архитектуры
Резюмируем плюсы архитектуры:
- Мощный сервер дешевле 100+ мощных клиентских машин — если мы хотим, чтобы приложение не тормозило, нужна хорошая машина. Она у вас будет одна. Или несколько, если нагрузка большая, но явно меньше, чем количество клиентов.
- Нет дублирования кода — основной код хранится на сервере, клиент отвечает только за «нарисовать красивенько» и простенькие проверки на полях «тут число, тут строка не длиннее 100 символов».
- Персональные данные в безопасности — простой пользователь не видит лишнего. Он не знает ваше ключевое слово, паспортные данные и количество денег на счете.
Минусы архитектуры
Упало одно звено — все отдыхают
Если упал сервер или отвалилась база, то есть испортилось 1 звено — всё, все в ступоре, все отдыхают. Сотни, тысячи, да хоть миллионы клиентов если есть — никто не может работать. Все операционистки грустно смотрят на окно «Простите, что-то пошло не так» и разводят руками перед клиентом.

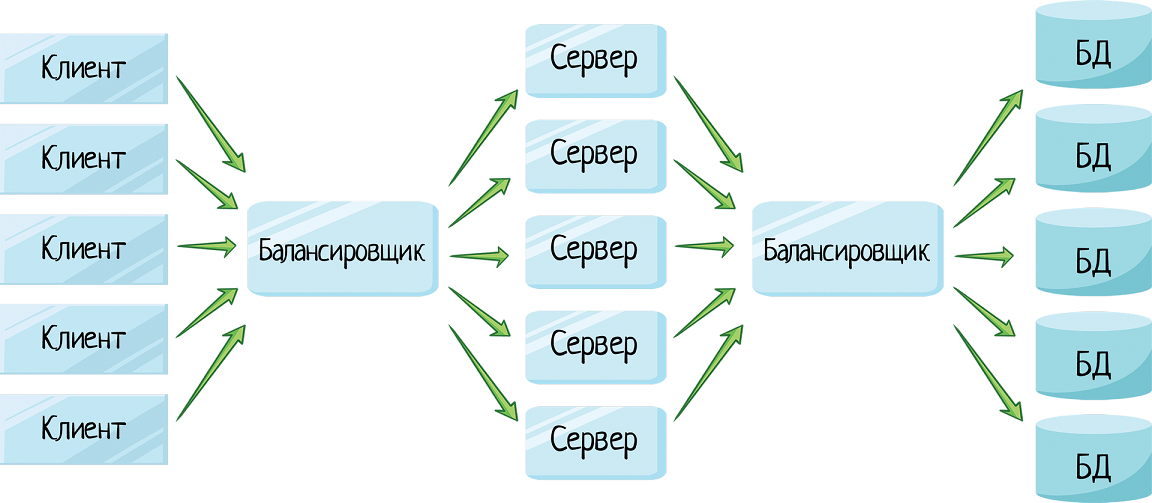
Именно поэтому в бизнес-критичном ПО архитектуру усложняют и даже дублируют. Банк с тысячами операционистов не может позволить себе простой. Поэтому они используют кластер серверов — один упал, остальные работают.

Как в таком случае клиент понимает, куда ему отправлять запрос?
Перед серверами ставят балансировщик, и клиент шлет запрос туда. Сколько бы серверов не поставили в кластер, клиенту это не интересно. У него есть один URL — адрес балансировщика.
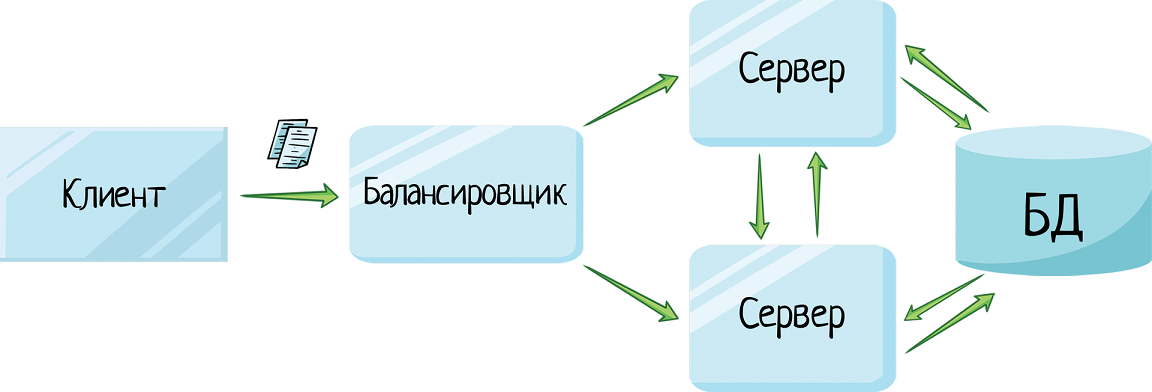
И вот с клиента поступает запрос:
— Дай мне всю информацию по Васе Иванову.
Балансировщик говорит:
— Ребята, новый запрос! Кто меньше загружен?
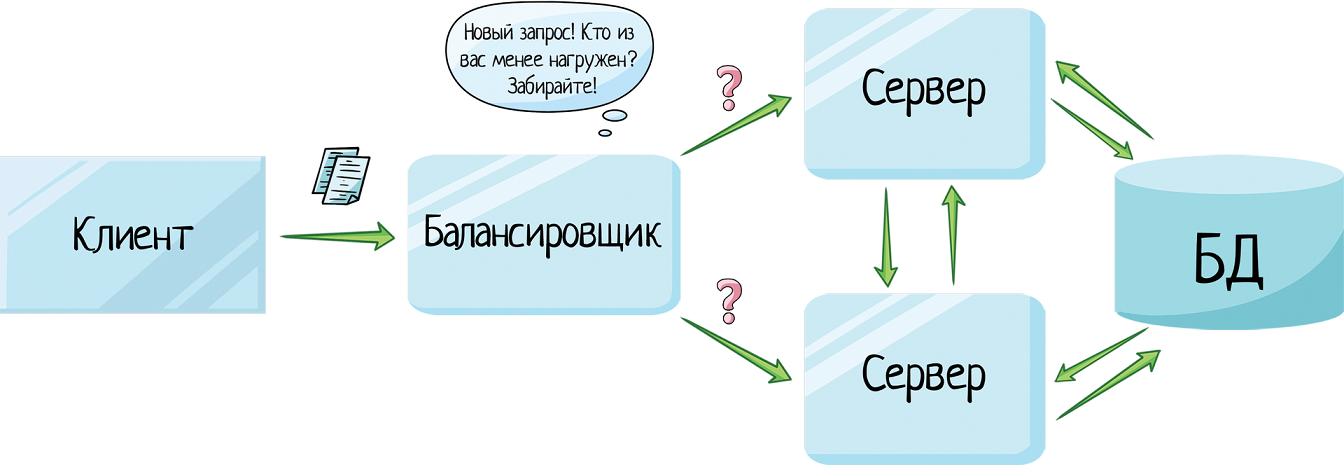
Первый сервер:
— У меня 5 запросов в очереди стоит.
Второй:
— А у меня 2.
Балансировщик отправляет запрос второму серверу.

Такая схема используется для высоконагруженного приложения — когда запросов поступает так много, что один сервер с ними просто не справляется.
Facebook, amazon, google — туда заходят миллионы пользователей. Один сервер с ними не справится. Поэтому ставят кластер, а балансировщик делит между ними нагрузку. И в таком случае в кластере может быть не 2 сервера, а 10, 15, сколько нужно, столько и ставим.

При этом мы можем точно также балансировать базу данных. У нас может быть несколько копий баз данных на самых разных машинах, и балансировщик отправляет запросы то к одной, то ко второй.

Такая схема называется горячий резерв — когда у нас есть несколько серверов, работающих в параллель, и балансировщик распределяет нагрузку между ними.
При этом может быть и схема холодного резерва — когда у нас второй сервер является резервной копией «на всякий случай». Все запросы идут на первый сервер, второй отдыхает.
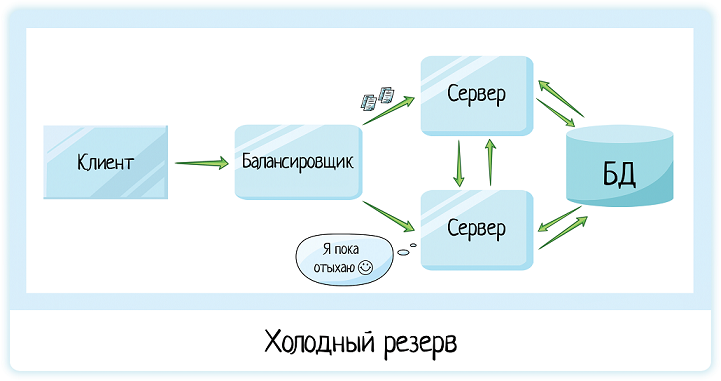
Но если с первым сервером что-то случится и он помрет, балансировщик перенаправит нагрузку на второй сервер:


В это время у администраторов будет время разобраться с проблемой на сервере 1.
Схема холодного резерва используется тогда, когда один сервер способен выдержать нагрузку и выдавать хорошую скорость работы. Но приложение при этом бизнес-критичное и простой неприемлем.
Простой может быть не только потому, что случилось что-то плохое. Есть еще штатное обновление приложения. Обе схемы резервирования позволяют обновляться безболезненно. Если в кластере два сервера, обновление будет выглядеть так:
- Перенаправляем всю нагрузку на сервер 2
- Останавливаем сервер 1
- Обновляем сервер 1
- Запускаем его и направляем на него всю нагрузку
- Останавливаем сервер 2
- Обновляем его
- Запускаем
- Снова делим нагрузку (если это горячий резерв)
То есть работа приложения вообще не останавливается!
Таким образом, схемы резервирования помогают нам устранить проблему «упало 1 звено — все отдыхают». Клиент никогда не узнает, что один или несколько серверов в кластере сдохли, у него всё как работало, так и работает.
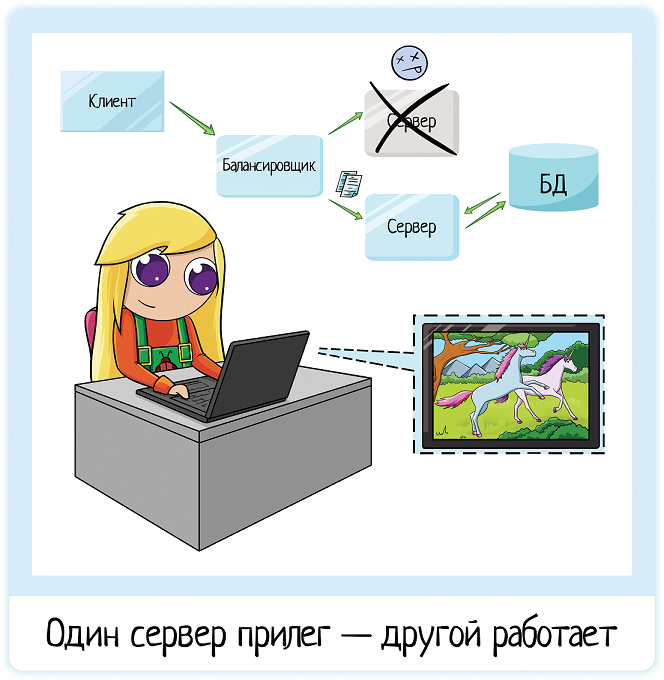
Высокая стоимость оборудования
Сервера стоят дорого. Туда нельзя поставить обычный SSD как для домашнего компьютера. Почему? Потому что к железу для серверов совсем другие требования по надежности + есть поддержка специфичных функций:
— у HDD это специальная микропрограмма контроллера, которая оптимизирована для работы диска в RAID, дома это не нужно.
— у SSD это наличие группы конденсаторов, которые хранят энергию на случай отключения питания, чтобы хватило времени скинуть из DDR кэша данные в энергонезависимую память и данные не побились.
SSD — быстро работающий диск, HDD — обычный. RAID — когда мы N дисков вместе соединили, а DDR кэш — это оперативная память
Плюс у серверных решений гарантия обычно гораздо дольше: 5 лет, а не год.

По цене отличаются в 2 раза. Например, SSD:
- для дома гигабайт стоит 16,53р
- для сервера энтерпрайз гиг стоит 32 рубля
Цифры на декабрь 2019 года. Это если не брендированное железо брать, а от производителя.
Вроде не сильно отличается, да? Но смысл в том, что для дома 1 тб хватает за глаза — и фоточки все влезут, и кино, и куча приложений… А для сервера иногда и 10 тб будет мало. А если делать кластер, то умножаем стоимость на 2, если не больше. Поэтому и разница в цене кажется огромная, но при пересчете на гигабайт небольшая выходит.
Не забывайте, что дома вам просто надо свои фоточки держать, да и те обычно в облаке. А на сервере бизнес-критичный функционал, который жрет дофига ресурсов и который надо дублировать на случай «вдруг первый сдохнет».
Нужно нанять сисадмина ツ
Нам нужно нанять сисадмина, который будет следить за всеми нашеми серверами приложения и БД. Добавляем его зарплату к стоимости оборудования!
Что тестировать
Чтобы понимать, что тестировать, надо понимать, с чем имеет дело человек.
Пользователь работает с клиентом. Это может быть web или desktop приложение, не суть. Операционистке Кате дали рабочее место, показали какую программу запускать и как с ней работать. Она знать не знает о наличии серверов и БД, она работает только с клиентом.
Поэтому тестировщик в первую очередь проверяет клиент! Потому что сервер может работать идеально, вы можете даже написать тесты на уровне API и они все будут зелененькие, и кажется, что все зашибись! А пользователь загрузит отчет и увидит ошибку. Ой.
Сервер работает, на клиенте ошибка. И плевать на сотни «зеленых» автотестов. У пользователя все равно ошибка. И наша задача — посмотреть с его точки зрения.

Однако, если у вас есть доступ к серверу приложения и его базе данных — стоит проверять и их тоже! Так мы можем увидеть «будущий баг». Например:
- Сохранили карточку товара — система ее отрисовывает и говорит, что все хорошо. На клиенте все отлично!
- Проверили по базе — а там часть полей осталась пустая, разработчик неправильно указал название поля в БД. И информация потерялась.
То, что сейчас пользователь видит в клиенте — это просто кеш, «что ввел, то и отображаю». Если не проверить по базе, такая проблема может даже вскрыться не сразу. Пользователь открывает карточку товара — часть полей не заполнена:
— Ну, наверное, их и не заполняли.
А их заполняли! Просто сохранение криво сработало. Поэтому, если у нас только черный ящик, то нужно проверять, «а реально ли сохранились данные?». Сохранили? Откройте карточку в новом окне или вызовете информацию через API-метод.
Если доступ к базе есть — просто проверьте по ней, что все хорошо. Если есть доступ к серверным логам — проверьте их на наличие ошибок.

Помимо простых пользователей бывают злые люди, которые пытаются встрять в наше приложение и своровать деньги / данные. Они используют не клиент или сервер — туда у них доступа нет. Они пытаются перехватить данные в пути от клиента к серверу, или от сервера к БД.
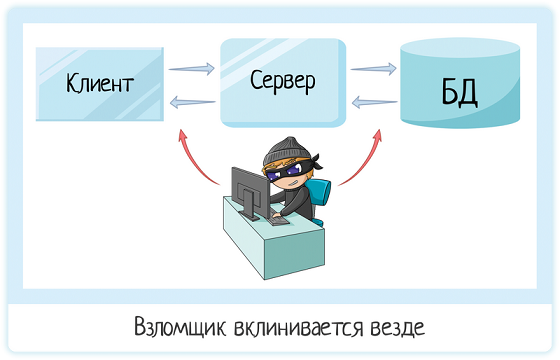
Ну а раз нехорошие люди могут это сделать, то тестировщик тоже должен это уметь! Потому что тестировщик предоставляет информацию о нашем продукте.

Тестировщик изучает уязвимости и потом рассказывает команде:
— Ребята, вот я проверил, у нас есть такие-то и такие-то потенциальные дыры. Давайте подумаем, надо нам их как-то закрывать или нет.
То есть не факт, что исправлять проблему будут. Может, у вас некритичное приложение — данные не утекут, деньги вы не храните. Тогда и заморачиваться лишний раз никто не будет, потому что тестировать на защищенность — дорого, специалистов мало.
Но какие-то базовые проверки типа sql-иньекций или XSS-атак стоит изучить и проверить на своем приложении. Хотя бы чтобы понять их критичность. Ведь если атака сломает клиент — ну и пусть, сам себе буратино. А если атака положит сервер, это уже не очень хорошо. И надо хотя бы знать, от чего это бывает.
Итого
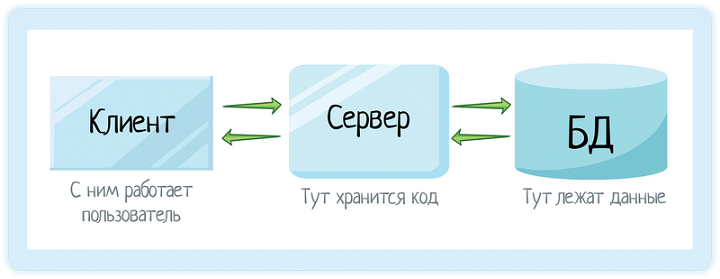
Клиент — та программа, с которой работает пользователь. Он знать не знает, это у него на компьютере программа целиком, или где-то за ней прячутся сервер с базой, а то и целый RAID. Он работает в браузере или с desktop-приложением. И всё, что ему нужно знать — это «куда тут тыкать».
Клиенту не нужно много памяти, места на диске и других ресурсов. Поэтому рабочие места относительно дешево стоят. А это именно то, что нам нужно, особенно если нужно закупить оборудование для тысяч операционисток банка.
Сервер — компьютер, на котором хранится само приложение. Весь код, вся логика, все дополнительные материалы и справочники. Например, справочник адресов ФИАС или справочник юр лиц ЕГРЮЛ — они тоже занимают место, как сами по себе, так и в памяти приложения.
Иногда говорят «сервер приложения» и «сервер БД». Это нормально, ведь фактически сервер — это просто машина, компьютер. А базу и сервер приложения обычно хранят на разных машинах, ради безопасности. В таком случае, если говорят «сервер приложения» — речь о втором звене нашей схемы.
Приложения бывают самые разные. Есть ресурсоемкие, им нужно много памяти и места на диске. Есть «легкие», которые можно развернуть даже на домашнем компьютере.
БД (база данных) — хранилище данных. Тут вы можете легко поискать информацию + уверены в том, что она сохранится, даже если в приложении что-то сломается.
Сколько места нужно под базу, зависит от количества данных. Есть огромные базы в банках, где и 1тб будет мало. А есть совсем небольшие, которые вы можете установить на своей машине. Например, XAMPP можно поставить. И врядли вы напихаете туда столько данных, что у вас не останется под них место.
Отдельной базы может не быть, тогда структура станет двузвенной: клиент-сервер. И все!
Схема условная, в реальной жизни у нас как минимум будет больше клиентов. А если приложение высоконагруженное, то будет несколько серверов и несколько баз данных:
PS — больше полезных статей ищите в моем блоге по метке «полезное»




