
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
 Привет, Хаброжители! Все мы хотим построить успешную карьеру. Как найти ключ к долгосрочному успеху в Data Science? Для этого понадобятся не только технические ноу-хау, но и правильные «мягкие навыки». Лишь объединив оба этих компонента, можно стать востребованным специалистом. Узнайте, как получить первую работу в Data Science и превратиться в ценного сотрудника высокого уровня! Четкие и простые инструкции научат вас составлять потрясающие резюме и легко проходить самые сложные интервью. Data Science стремительно меняется, поэтому поддерживать стабильную работу проектов, адаптировать их к потребностям компании и работать со сложными стейкхолдерами не так уж и легко. Опытные дата-сайентисты делятся идеями, которые помогут реализовать ваши ожидания, справиться с неудачами и спланировать карьерный путь.
Привет, Хаброжители! Все мы хотим построить успешную карьеру. Как найти ключ к долгосрочному успеху в Data Science? Для этого понадобятся не только технические ноу-хау, но и правильные «мягкие навыки». Лишь объединив оба этих компонента, можно стать востребованным специалистом. Узнайте, как получить первую работу в Data Science и превратиться в ценного сотрудника высокого уровня! Четкие и простые инструкции научат вас составлять потрясающие резюме и легко проходить самые сложные интервью. Data Science стремительно меняется, поэтому поддерживать стабильную работу проектов, адаптировать их к потребностям компании и работать со сложными стейкхолдерами не так уж и легко. Опытные дата-сайентисты делятся идеями, которые помогут реализовать ваши ожидания, справиться с неудачами и спланировать карьерный путь. План анализа
Для дата-сайентистов нет ничего увлекательнее, чем погрузиться в данные, чтобы ответить на вопросы. Загружаем данные! Группируем! Подводим итог! Подбираем модель и получаем результаты! К сожалению, из-за бесчисленных способов обобщения и моделирования данных может получиться так, что вы потратите недели на работу и лишь потом обнаружите, что ничего из созданного вами не отвечает на поставленный бизнес-вопрос. Худшее из ощущений — осознание, что ничего полезного сделать не получилось. С аналитиками такое часто случается, особенно с джунами без солидного опыта.
Один из способов решить эту проблему — установить рамки, чтобы держать все под контролем и выполнять только нужную работу. План анализа — это и есть рамки. Идея заключается в том, что перед просмотром данных вы записываете все, что планируете с ними делать. Затем, по мере продвижения анализа, вы проверяете, какая часть плана выполнена. Когда все его пункты выполнены, работа завершена! Так можно не только сверяться с планом, но и отслеживать прогресс и обеспечивать отчетность. Ее можно даже показать на совещании с руководителем, чтобы обсудить, как идут дела.
При составлении плана все его пункты должны быть выполнимыми. Можно написать код для задачи «сделать линейную регрессию продаж по регионам», но у вас не получится сделать то же самое для формулировки «выяснить, почему продажи упали»; это результат других вещей. Если задачи в плане выполнимы, оценить прогресс легко. Это также упростит анализ, потому что вам не придется ломать голову над дальнейшими действиями. Вместо этого вы просто смотрите на план анализа и выбираете следующую задачу.
Чтобы вам было легче составить несколько первых планов анализа, мы настоятельно рекомендуем использовать следующий шаблон:
— Начало. Укажите название анализа, его цель и ваши данные (в случае, если доступ к нему будет у кого-то еще).
— Разделы. Каждый раздел должен представлять общую тему анализа. Он должен быть понятным и независимым (анализ не полагается на результаты других разделов), чтобы другой человек мог работать над любым из них. В каждом разделе должен быть список задач.
— Первый уровень раздела. Здесь должен быть заданный вопрос. Он напомнит остальным, почему вы выполняете эту задачу. Если вам удастся найти правильные ответы, значит, вы поняли тему основного раздела.
— Второй уровень раздела. Здесь должны быть указаны задачи, которые можно отмечать по мере выполнения работы. Например, можно указать типы моделей для запуска; описания должны быть достаточно конкретными, чтобы в любое время можно было точно определить статус завершения работы.
На рис. 10.3 показан пример плана анализа. У нас это план оценки причин, по которым клиенты уезжают из Североамериканского региона. Вверху указаны название, цель и контактная информация дата-сайентиста на случай, если этот материал будет кому-то передаваться. Каждый раздел охватывает отдельный компонент анализа (например, анализ по Северной Америке или сравнение с другими регионами). Подразделы (пронумерованные) — это вопросы анализа, а самый нижний раздел (отмеченный буквами) — это конкретные задачи, которые необходимо решить.

При составлении плана поделитесь им с руководителем и стейкхолдером, сделавшим запрос. Они должны либо предложить варианты по его улучшению, либо одобрить его. Утвержденный план анализа обеспечивает согласованную базу для работы. Если по итогу вас спросят, почему вы так поступили, можете сослаться на утвержденный документ с исходными целями.
Вполне вероятно, что в процессе работы вы поймете, что упустили что-то важное, или у вас появится новая идея. Это совершенно нормально; просто обновите план и сообщите стейкхолдеру, что вы вносите изменения. Поскольку ваше время ограничено, возможно, придется пожертвовать какой-нибудь менее важной задачей. План анализа полезен, потому что он создает диалог вокруг удаления ненужных пунктов, чтобы вам не приходилось пытаться выполнить невозможный объем работы.
Выполнение анализа
С подписанным планом на руках вы можете приступать к работе! Для начала производится импорт данных для дальнейших очистки и обработки. Затем вы несколько раз преобразуете данные путем их обобщения, агрегирования, изменения, визуализации и моделирования. Когда данные готовы, вы передаете их другим специалистам.
В следующих разделах мы кратко рассмотрим некоторые вопросы, которые следует учитывать при выполнении таких задач в рабочей среде. Целые книги, посвященные этой теме, также могут научить вас писать код для анализа на выбранном вами языке.
Импорт и очистка данных
Прежде чем вы сможете начать отвечать на вопросы согласно плану анализа, вам необходимо сохранить данные в удобном формате там, где с ними можно будет работать. Обычно это означает возможность загрузить их на R или Python, но иногда используется SQL или другие языки. Почти всегда эта задача отнимает у вас больше времени, чем вы рассчитываете. В процессе может возникнуть много сюрпризов. Вот некоторые из этих ужасных моментов:
— Проблемы с подключением к базам данных компании в конкретной интегрированной среде разработки (IDE).
— Проблемы с неправильными типами данных (например, числами в виде строк).
— Проблемы со странными форматами времени («год-день-месяц» вместо «год-месяц-день»).
— Данные, требующие форматирования (возможно, каждый идентификатор заказа начинается с элемента «ID-», который необходимо удалить).
— Отсутствующие записи.
Хуже того, ни одна из этих задач не выглядит продуктивной для людей, далеких от технических вопросов; вы не можете показать стейкхолдеру убедительный график работы драйвера БД, да и он не поймет, что манипуляции со строками помогают решить его бизнес-вопрос. Поэтому, какой бы утомительной ни была эта задача, вам нужно ее поскорее решить и приступить наконец к исследованию данных.
Занимаясь импортом и приведением данных в порядок, помните, что перед вами стоит двойная задача: побыстрее решить не столь важные моменты и уделить как можно больше времени задачам, которые помогут в дальнейшем. Если у вас есть столбец с датами, который представлен в виде строк, и вы сомневаетесь, что он вам когда-либо понадобится, не тратьте время на изменение формата. Но если вы считаете, что он пригодится, сделайте эту работу как можно скорее, потому что для анализа нужен чистый датасет. Трудно сказать заранее, что пригодится, а что нет, но если вы заметили, что времени на определенную задачу уходит слишком много, спросите себя, действительно ли она так нужна.
При импорте и очистке данных какая-нибудь проблема может выбить вас из колеи на несколько дней, например подключение к БД. Если вы оказались в такой ситуации, у вас есть три варианта: (1) попросить о помощи, (2) найти способ полностью избежать проблемы или (3) продолжать попытки решить ее самостоятельно. Вариант (1) подходит отлично, если вы можете к нему прибегнуть: человек, разбирающийся в вопросе лучше вас, может быстро найти решение, а вы сможете у него поучиться. Вариант (2) тоже хорош — можно, например, использовать файл .csv вместо подключения к базе. Варианта (3) — бесконечных попыток — стоит избегать любой ценой. Сотрудник, потративший несколько дней на одну проблему, выглядит бесполезным. Если какая-то задача ставит вас в тупик, обсудите с руководителем дальнейшие действия; не стоит продолжать попытки и надеяться, что проблема решится сама собой.
После загрузки и форматирования можете приступать к работе и искать неадекватные данные. Сюда относится все, что выходит за рамки фундаментальных представлений. Например, если при просмотре архивных данных о рейсах авиакомпаний обнаружилось, что несколько бортов приземлились до взлета, это странно, потому что обычно самолеты сначала взлетают! Выбиваться из ряда может что угодно, от магазина, продающего товары с отрицательной ценой, до производственных данных, показывающих, что на одном заводе произвели в тысячу раз больше товаров, чем на аналогичном. Такие странности наблюдаются постоянно, и их невозможно спрогнозировать до проверки.
Если вам встретились такие данные, не игнорируйте их! Худшее, что вы можете сделать, — это предположить, что с ними все в порядке, а затем, спустя несколько недель упорного аналитического труда, обнаружить, что это не так и все усилия были напрасны. В такой ситуации следует поговорить либо со стейкхолдером, либо с кем-то, кто отвечает за эти данные, и спросить, знают ли они о несоответствиях. Во многих случаях об этом уже знают и могут предложить это проигнорировать. В примере с датасетом авиакомпании можно просто удалить данные о бортах, которые приземлились до взлета.
Если выяснится, что о проблеме не знали, а она может поставить под угрозу анализ, необходимо изучить способы спасения ситуации. Если вам нужен сравнительный анализ доходов и расходов, но при этом, как ни странно, половина имеющихся у вас данных не содержит информации о тратах, посмотрите, можете ли вы работать только с каким-то одним их видом (например, только с доходами). В некотором смысле этот подход превращается в анализ в квадрате: вы проводите мини-анализ, чтобы понять, возможен ли общий анализ в принципе.
Просмотр и моделирование данных
Во время просмотра и моделирования вы пересматриваете свой план анализа и пытаетесь завершить работу. В следующих разделах представлена общая схема подхода к каждому его пункту.
ИСПОЛЬЗУЙТЕ МЕТОД ОБОБЩЕНИЯ И ПРЕОБРАЗОВАНИЯ
Подавляющее большинство аналитической работы можно выполнить путем обобщения и преобразования данных. Чтобы ответить на вопрос: «Сколько клиентов у нас было каждый месяц?», можно взять информацию о клиентах, сгруппировать ее по месяцам, а затем подсчитать количество человек в каждом месяце. Здесь не нужны статистические методы или модели МО — просто преобразования.
Можно решить, что это не очень-то похоже на анализ данных, ведь вы не пользуетесь ничем, кроме множества арифметических действий, но часто правильное выполнение преобразований бесценно. Большинство других людей в компании вообще не имеют доступа к данным, не могут эффективно их преобразовывать или не знают, какие преобразования вообще нужны.
В зависимости от данных вы можете задействовать некоторые статистические методы, например поиск значений на разных уровнях процентилей или вычисление среднеквадратического отклонения.
ВИЗУАЛИЗИРУЙТЕ ДАННЫЕ ИЛИ СОЗДАЙТЕ СВОДНЫЕ ТАБЛИЦЫ
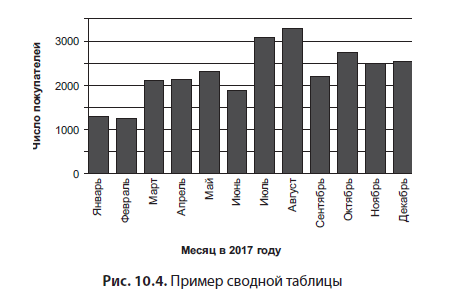
Выполнив соответствующие преобразования, создайте визуализации или сводные таблицы, чтобы видеть, что происходит с данными. Вернемся к предыдущему примеру: если у вас есть определенное количество клиентов в месяц, можно создать столбчатую диаграмму, чтобы проследить изменения. С помощью такого графика можно легко увидеть закономерности, а не просто вывести фрейм данных на экран.
На рис. 10.4 представлен пример сводной визуализации, показывающей общее количество клиентов за каждый месяц. На этом графике люди могут легко увидеть, что их число понемногу растет.
Выбор типа визуализации зависит от имеющихся данных. Можно использовать линейный график, диаграмму размаха или любой из многих других вариантов.
Вместо диаграммы можно сделать сводную таблицу. Все зависит от того, что вы пытаетесь понять. В конце этого раздела среди материалов к нему можно найти информацию о выборе правильного типа графика для ваших данных. Обратите внимание, что в процессе визуализации вы можете осознать, что некоторые этапы преобразования следует изменить. Скорее всего, вам придется много раз скакать между разными этапами анализа.
Поскольку при визуализации будет множество итераций и непрерывного преобразования данных, следует найти золотую середину между желанием удалить промежуточные этапы ради чистоты кода и стремлением сохранить абсолютно все на всякий случай. Лучше всего оставить как можно больше кода при условии, что (1) старый код будет работать нормально после того, как вы внесете дальнейшие изменения, и (2) вы можете четко обозначить, какие результаты являются «хорошими». Не храните код, не работающий для вашего анализа, или его большие части с комментариями — это чрезвычайно затрудняет его поддержку. Помимо этого, неплохо бы использовать контроль версий вроде git и GitHub; каждый раз, добавляя в анализ новый контент, можно записывать изменения и откатывать код, если что-то пошло не так.
ПРИ НЕОБХОДИМОСТИ СОЗДАЙТЕ МОДЕЛЬ
Если в данных есть закономерности, которые предполагают, что здесь отлично подойдет моделирование, — действуйте! Возможно, было бы целесообразно применить модель временнˆого ряда, чтобы спрогнозировать количество клиентов в следующем году. При создании моделей следует выводить результаты и визуализировать их, чтобы понимать, насколько они точны или полезны. Можно создавать графики, которые сравнивают прогноз с фактическими значениями или содержат такие показатели, как оценки точности и значения важности функций.
Если вы создаете модели машинного обучения, которые могут быть использованы не только для анализа, а, например, для запуска в производство (о чем мы расскажем в главе 11), убедитесь, что вы изолировали код построения модели от общего анализа. Поскольку в дальнейшем вы будете использовать только ее, вам нужно будет легко извлекать этот код из того, который составляет общие диаграммы визуализации.
ПОВТОРИТЕ
Все эти шаги нужно проделать для каждого пункта плана анализа. В процессе работы у вас может появиться новое представление о том, что следует анализировать, или вы вдруг осознаете, что то, что вы считали целесообразным, на самом деле не имеет смысла. В таком случае нужно скорректировать план и продолжить работу.
Вероятно, разные пункты плана анализа будут взаимосвязаны, поэтому код, который вы использовали в одном пункте, будет повторяться и в другом. Постарайтесь структурировать план, чтобы можно было запускать одну и ту же программу несколько раз, а обновления в одной ее части сразу же распространялись бы на другие. Ваша цель — создать систему, которую можно поддерживать и легко менять, не затрачивая массу времени на отслеживание сложного кода.
Важные моменты для анализа и моделирования
Работа по анализу и моделированию данных зависит от поставленной задачи. Математические и статистические методы для кластеризации данных не подходят для прогнозирования или оптимизации решения. Если вы будете следовать некоторым общим советам, то сможете сделать не просто хороший, а отличный анализ.
СОСРЕДОТОЧЬТЕСЬ НА ОТВЕТЕ НА ВОПРОС
Как уже говорилось в разделе 10.2, очень легко потратить время на выполнение работы, которая не приводит к достижению цели. Если вы анализируете заказы клиентов с целью узнать, можно ли спрогнозировать, когда клиент сделает свой последний заказ и больше никогда не вернется, вы можете получить нормально работающую модель нейронной сети, а затем потратить несколько недель на настройку гиперпараметров. Если стейкхолдеру достаточно только ответа «да» или «нет» на вопрос о работоспособности модели, то настройка гиперпараметров для повышения ее эффективности не поможет. Вместо того чтобы неделями заниматься этой настройкой, можно было бы сделать что-то более полезное.
При анализе важно сосредоточиться на плане и ответить на заданный вопрос. Нужно постоянно спрашивать себя: «Это относится к поставленной задаче?» Вы должны думать об этом каждый раз, когда составляете график или таблицу. Здорово, если вы все время положительно отвечаете на этот вопрос. Но ситуации, когда вы порой думаете: «Этот график (или таблица) бесполезен», гораздо более вероятны, и тогда, возможно, придется скорректировать свою работу. Во-первых, постарайтесь остановиться и подойти к проблеме иначе. Если вы пытались сгруппировать клиентов по расходам, попробуйте вместо этого выполнить кластеризацию. С совершенно новым подходом у вас больше шансов на успех, чем при внесении незначительных изменений. Во-вторых, поговорите с руководителем или стейкхолдером проекта: возможно, данные, которые вы используете, неэффективны для решения возникшей проблемы.
На протяжении всего процесса анализа нужно стабильно собирать набор действительно актуальных результатов и (в идеале) следовать плану.
ИСПОЛЬЗУЙТЕ ПРОСТЫЕ МЕТОДЫ ВМЕСТО СЛОЖНЫХ
Сложные методы так увлекательны! Зачем нам линейная регрессия, если можно использовать случайный лес? Зачем использовать случайный лес, если есть нейронная сеть? Эти методы показали себя эффективнее, чем старая добрая регрессия или кластеризация k-средних, и они интереснее. Поэтому, когда вас просят решить бизнес-вопросы с помощью данных, вы, безусловно, должны использовать наилучшие методы.
К сожалению, у сложных методов есть множество недостатков, которые неочевидны, если сосредоточиться исключительно на точности. Цель анализа не в том, чтобы получить максимально возможную точность или прогноз; он должен ответить на вопрос так, чтобы представитель бизнеса мог его понять. Это означает, что вам нужно объяснить, откуда взялся такой результат. С помощью простой линейной регрессии можно легко построить графики и понять, как каждая функция повлияла на результат, тогда как при использовании других методов описать причины результатов модели бывает очень сложно, а заказчику будет сложнее поверить в их правильность. Более сложные методы настраиваются дольше, отладка и запуск нейронной сети занимают некоторое время, тогда как линейная регрессия выполняется довольно быстро.
Поэтому при проведении анализа стоит выбирать простые методы как в моделях, так и в преобразованиях и агрегировании как можно чаще. Например, вместо того чтобы отсекать определенный процент выбросов, выполните логарифмическое преобразование или возьмите медианное значение вместо среднего. Если линейная регрессия работает достаточно хорошо, не тратьте время на создание нейронной сети ради незначительного повышения точности. Применение простых методов там, где это возможно, делает результат намного понятнее для других, а вам будет проще осуществлять поддержку и отладку.
ГРАФИКИ ДЛЯ ИССЛЕДОВАНИЙ VS ГРАФИКИ ДЛЯ ПРЕЗЕНТАЦИЙ
Есть две разные причины, по которым дата-сайентист предпочитает визуализировать данные: для исследования и для обмена информацией. Первый он составляет, чтобы понять динамику данных. Сложный и плохо размеченный граф — это нормально до тех пор, пока специалист понимает его. Цель графика для презентаций состоит в том, чтобы тот, кто мало знает о данных, получил конкретную информацию, которую пытается вывести дата-сайентитст. Для того чтобы такой график считался эффективным, он должен быть простым и понятным. При проведении анализа вам понадобится использовать множество графиков для анализа, но ими не стоит делиться с другими сотрудниками.
Рассмотрим пример, основанный на вымышленных данных о кличках домашних животных в городе: дата-сайентист хочет понять, соотносится ли первая буква клички домашнего животного с его видом (коты или собаки). Он загружает данные и создает визуализацию, показывающую для каждой буквы разбиение групп котов и собак, чьи клички начинаются с нее (рис. 10.5).
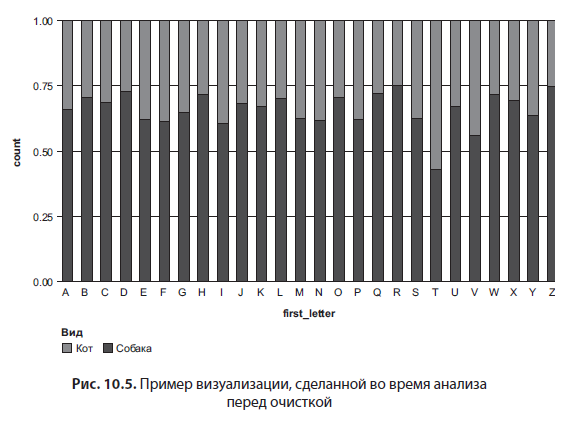
Если вы внимательно посмотрите на рис. 10.5, то заметите, что в столбце Т гораздо больше кошек, чем собак — важный вывод для дата-сайентиста. При этом это не тот график, который следует показывать стейкхолдеру: в нем слишком много информации и с первого взгляда не все очевидно.
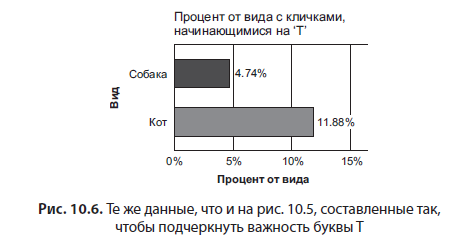
На рис. 10.6 показаны те же данные, построенные другим, более простым способом. В этой версии очевидно, что шанс котов получить кличку, начинающуюся на букву T, составляет 12 %, тогда как для собак он равен только 5 %. Теперь этими данными можно поделиться со стейкхолдером.
НЕПРЕРЫВНАЯ ГОТОВНОСТЬ ДЕЛИТЬСЯ
Результат анализа может принимать различные формы, выбор которых зависит от целевой аудитории. Если анализ предназначен для бизнесменов, часто используется набор слайдов или редактируемый документ. PowerPoint или Word (или Google Slides и Google Docs) — хороший вариант, потому что любой может открыть такие файлы (при наличии пакета Microsoft Office для первых двух вариантов), а их форматы поддерживают множество диаграмм, таблиц и текстовых описаний. Если анализ предназначен для технических специалистов, можно передать выходной HTML-файл Jupyter Notebook или R Markdown. Эти методы хороши тем, что для их обработки обычно требуется меньше усилий (например, не нужно тратить время на выравнивание фигур на слайде). Если нужно передать большое количество таблиц с данными для финансовых специалистов, лучшим вариантом может стать Excel: это отличный инструмент на случай, если конечному пользователю нужно взять значения из результатов и произвести дальнейшие вычисления. Чтобы впоследствии вам не пришлось столкнуться с доработкой, решите на раннем этапе анализа, какой результат вы ожидаете получить.
В зависимости от объема работы вам нужно будет периодически связываться с заказчиком и показывать ему результат. Это позволяет предотвратить катастрофу: представьте, что вы неделями в одиночку работали над анализом, а когда пришло время сдавать проект, стейкхолдер находит что-нибудь, что сводит все ваши усилия на нет. Например, говорит: «Вы рассматривали продажи, но не учли возвраты». Если бы этот пункт был указан в начале, напрасной траты времени можно было бы избежать. Кроме того, стейкхолдер часто может вносить изменения, предлагая возможные сферы, на которых необходимо сосредоточиться, или методы, которые следует попробовать. В некотором смысле такое общение на протяжении всего процесса аналогично концепции гибкой методологии разработки ПО: постоянное улучшение работы, а не выпуск одного объемного готового продукта.
Регулярная координации со стейкхолдером — это хорошо, но дата-сайентисты часто пренебрегают им. А еще в этой ситуации плохо то, что работу приходится показывать человеку, не занимающемуся данными, то есть промежуточный результат должен быть в таком состоянии, которое не стыдно показать. Нужны графики с четкими обозначениями и смыслом, код с минимальным количеством ошибок и базовая история происходящего. Поэтому дата-сайентисты часто думают: «Не буду показывать результат, пока не доработаю его; займусь этим в конце». Не делайте так! В итоге это практически всегда выливается в больший объем работы. С постоянным поддержанием работы в виде, подходящем для показа, вы в итоге получите более качественный продукт.
ЗАПУСК ОДНОЙ КНОПКОЙ
Точно так же как для загрузки и подготовки данных неплохо бы запустить только один сценарий, нужно предусмотреть единственную кнопку, запускающую анализ. В Python для автоматической загрузки данных есть Jupyter Notebook, который выполняет анализ без ошибок. В R это файл R Markdown — он загружает данные, анализирует их и выводит HTML-файл, документ Word или презентацию PowerPoint.
При проведении анализа избегайте запуска слишком большого количества кода за пределами сценария или беспорядочного выполнения сценариев. Такие методы увеличивают вероятность ошибки при повторном запуске. Это нормально, если вы захотите написать ad hoc код под конкретную ситуацию, но для начала убедитесь, что сможете повторно запустить файл без ошибок. Так вы сможете в любой момент поделиться результатами работы с другими людьми и гарантированно потратите меньше времени на исправление сценария в конце анализа.
ОБ АВТОРАХ
Эмили Робинсон
Написала Жаклин Нолис
Эмили Робинсон — блестящий старший дата-сайентист в компании Warby Parker; ранее она работала в DataCamp и Etsy.
Впервые я встретила Эмили на Data Day Texas 2018, когда она была одной из немногих слушательниц моего доклада о Data Science в индустрии. В конце моего выступления она подняла руку и задала прекрасный вопрос. К моему удивлению, через час мы поменялись местами — теперь уже я слушала, как она спокойно проводила восхитительную презентацию, и с нетерпением ждала возможности поднять руку и задать ей вопрос. В тот день я уже поняла, какой она трудолюбивый и умный специалист. Несколько месяцев спустя, когда пришло время искать соавтора для моей книги, Эмили Робинсон была первым кандидатом в списке на эту роль. Отправляя ей электронное письмо, я думала, что мне, скорее всего, откажут: она, пожалуй, была «не моего уровня».
Работа с Эмили над этой книгой была сплошным удовольствием. Она очень заботится о трудностях младших специалистов по работе с данными, а еще у нее есть способность четко выделять важное. Она всегда качественно выполняет свою работу и каким-то образом умудряется одновременно писать статьи в блогах. Наблюдая за ней на других конференциях и общественных мероприятиях, я видела, как она общалась со многими дата-сайентистами, каждый из которых чувствовал себя с ней комфортно. Она также является экспертом в области A/B-тестирования и экспериментирования, хотя ясно, что для нее это просто временный этап. При желании она могла бы взять любую другую область DS и стать в ней экспертом.
Единственное, что меня расстраивает, так это то, что я пишу эти слова о ней на финальном этапе создания книги, и, как только мы закончим, возможность сотрудничать с Эмили появится уже у кого-то другого.
Жаклин Нолис
Написала Эмили Робинсон
Когда меня спрашивают о том, стоит ли писать книгу, я всегда отвечаю: «Только если у вас будет соавтор». Но это еще не все. Полный ответ должен быть таким: «Только если у вас будет такой же веселый, душевный, щедрый, умный, опытный и заботливый соавтор, как Жаклин». Я не знаю, каково писать книгу с «нормальным» соавтором, потому что Жаклин всегда была просто потрясающей, и мне невероятно повезло поработать с ней над этим проектом.
На фоне такого образованного человека, как Жаклин, вы запросто можете почувствовать себя неловко. У нее есть степень кандидата наук в промышленной инженерии и $100 000 за победу в третьем сезоне телевизионного реалити-шоу «Король ботанов». Жаклин работала директором по аналитике и основала собственное успешное консалтинговое агентство. Она выступает на конференциях по всей стране и регулярно получает приглашения от своей альма-матер приехать и провести карьерные консультации для студентов-математиков (ее специализация). Когда она выступает на онлайн-конференциях, ее забрасывают комплиментами вроде «это лучшее, что я когда-либо слышал», «превосходное выступление», «действительно полезно», «отличная живая презентация». Но Жаклин никогда не дает людям повода чувствовать себя недостойно или плохо из-за того, что они чего-то не знают; наоборот, она любит делать сложные понятия простыми, как, например, в ее презентации «Глубокое обучение — это нетрудно, даю слово».
Ее личная жизнь тоже впечатляет — у нее прекрасный яркий дом в Сиэттле, где она живет со своей подругой, сыном, двумя собаками и тремя кошками. Надеюсь, однажды она приютит соавтора, чтобы заполнить немного оставшегося места. Она со своей подругой Хизер даже провели презентацию перед аудиторией в тысячу человек об их опыте в использовании R для развертывания моделей машинного обучения в производство T-Mobile. А еще у них, пожалуй, самая милая история знакомства: они встретились на том самом шоу «Король ботанов», где Хизер также была участницей.
Я очень благодарна Жаклин за этот опыт, ведь она могла бы заработать гораздо больше, занимаясь чем-то гораздо менее утомительным, чем написание этой книги вместе со мной. Надеюсь, что наша работа подтолкнет начинающих дата-сайентистов стать частью сообщества людей, таких же прекрасных, как Жаклин.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Data Science
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.



