 Привет, Хаброжители! Обычно на глубокое обучение смотрят с ужасом, считая, что только доктор математических наук или ботан, работающий в крутой айтишной корпорации, могут разобраться в этой теме. Отбросьте стереотипы: любой программист, знакомый с Python, может добиться впечатляющих результатов. Как? С помощью fastai — библиотеки, предоставляющей комфортный интерфейс для решения наиболее популярных задач. Создатели fastai доказали, что самые модные и актуальные приложения можно делать быстро и не засыпать над скучными теоретическими выкладками и зубодробительными формулами.
Привет, Хаброжители! Обычно на глубокое обучение смотрят с ужасом, считая, что только доктор математических наук или ботан, работающий в крутой айтишной корпорации, могут разобраться в этой теме. Отбросьте стереотипы: любой программист, знакомый с Python, может добиться впечатляющих результатов. Как? С помощью fastai — библиотеки, предоставляющей комфортный интерфейс для решения наиболее популярных задач. Создатели fastai доказали, что самые модные и актуальные приложения можно делать быстро и не засыпать над скучными теоретическими выкладками и зубодробительными формулами.
Для кого эта книга
Если вы новичок в области глубокого и машинного обучения, эта книга для вас. Но желательно уметь писать код на Python.
Если вы уверенно себя чувствуете в глубоком обучении, то все равно найдете в книге много полезного. Мы покажем, как добиваться высоких результатов, и познакомим вас с новейшими передовыми техниками. Вы увидите, что для этого не требуется глубокое знание математики. Нужны лишь здравый смысл и упорство.
Если вы уверенно себя чувствуете в глубоком обучении, то все равно найдете в книге много полезного. Мы покажем, как добиваться высоких результатов, и познакомим вас с новейшими передовыми техниками. Вы увидите, что для этого не требуется глубокое знание математики. Нужны лишь здравый смысл и упорство.
Об авторах
Джереми Ховард — предприниматель, бизнес-стратег, разработчик и преподаватель. Основал исследовательский институт fast.ai, цель которого — сделать глубокое обучение максимально доступным каждому. Джереми — выдающийся ученый-исследователь Университета Сан-Франциско, член факультета в Университете сингулярности, обладатель звания молодого мирового лидера, присужденного на международном экономическом форуме.
Последняя организованная им компания Enlitic первой применила глубокое обучение в медицине и, согласно MIT Tech Review, была зачислена в топ-50 интеллектуальных компаний мира в 2015 и 2016 годах. Ранее Джереми занимал пост президента и главного научного консультанта в Kaggle, где на ведущих ролях принимал участие в международных соревнованиях по машинному обучению два года подряд. Стал основоположником двух успешных австралийских стартапов (FastMail и Optimal Decisions Group, которые были приобретены LexisNexis). До этого восемь лет занимался управленческим консультированием в компаниях McKinsey & Co и AT Kearney. Джереми инвестировал во многие стартапы, оказывал им содействие в качестве наставника и просто давал советы. Помимо этого, принимал участие во многих опенсорсных проектах.
Он частый гость известной австралийской утренней программы новостей, выступал на TED.com и выпустил учебники по науке о данных и веб-разработке.
Сильвейн Гуггер — инженер-исследователь в HuggingFace. Ранее в роли ученого-исследователя fast.ai работал над расширением доступности глубокого обучения путем разработки и совершенствования техник, позволяющих ускоренно обучать модели в условиях ограниченных ресурсов.
До этого на протяжении семи лет Сильвейн преподавал computer science и математику по программе CPGE во Франции. CPGE — это особый вид занятий, которые посещают отдельные студенты по завершении высшей школы для подготовки к вступительным экзаменам в ведущие инженерные и бизнес-институты. Помимо этого, Сильвейн написал несколько книг, посвященных всему преподаваемому им курсу обучения, которые были изданы Editions Dunod.
Окончил Высшую школу Нормаль (Париж, Франция), где изучал математику. Более того, Сильвейн получил в этой области степень магистра от IX Парижского университета (Орсе, Франция).
Последняя организованная им компания Enlitic первой применила глубокое обучение в медицине и, согласно MIT Tech Review, была зачислена в топ-50 интеллектуальных компаний мира в 2015 и 2016 годах. Ранее Джереми занимал пост президента и главного научного консультанта в Kaggle, где на ведущих ролях принимал участие в международных соревнованиях по машинному обучению два года подряд. Стал основоположником двух успешных австралийских стартапов (FastMail и Optimal Decisions Group, которые были приобретены LexisNexis). До этого восемь лет занимался управленческим консультированием в компаниях McKinsey & Co и AT Kearney. Джереми инвестировал во многие стартапы, оказывал им содействие в качестве наставника и просто давал советы. Помимо этого, принимал участие во многих опенсорсных проектах.
Он частый гость известной австралийской утренней программы новостей, выступал на TED.com и выпустил учебники по науке о данных и веб-разработке.
Сильвейн Гуггер — инженер-исследователь в HuggingFace. Ранее в роли ученого-исследователя fast.ai работал над расширением доступности глубокого обучения путем разработки и совершенствования техник, позволяющих ускоренно обучать модели в условиях ограниченных ресурсов.
До этого на протяжении семи лет Сильвейн преподавал computer science и математику по программе CPGE во Франции. CPGE — это особый вид занятий, которые посещают отдельные студенты по завершении высшей школы для подготовки к вступительным экзаменам в ведущие инженерные и бизнес-институты. Помимо этого, Сильвейн написал несколько книг, посвященных всему преподаваемому им курсу обучения, которые были изданы Editions Dunod.
Окончил Высшую школу Нормаль (Париж, Франция), где изучал математику. Более того, Сильвейн получил в этой области степень магистра от IX Парижского университета (Орсе, Франция).
Категориальные вложения
В таблицах некоторые столбцы могут содержать численные данные, такие как «age» (возраст), в то время как в остальных будут строчные значения, например «sex» (пол). Численные данные можно передавать модели непосредственно (при желании можно их предварительно обработать), но столбцы в другом формате необходимо сначала преобразовать в числа. Поскольку значения в этих столбцах соответствуют разным категориям, мы зачастую называем такой тип переменных категориальными. Переменные первого типа называются непрерывными.
Термин: Непрерывные и категориальные переменные
Непрерывные переменные — это численные данные, такие как «age», которые допускается передавать напрямую в модель, так как их можно складывать и умножать непосредственно. Категориальные переменные содержат ряд дискретных уровней, таких как movie ID, для которых сложение и умножение бессмысленно (даже если они сохранены в виде чисел)
В конце 2015 года на Kaggle компанией Rossman проводилось соревнование по прогнозированию продаж (https://oreil.ly/U85_1). Участникам соревнования был предоставлен обширный набор данных по различным магазинам в Германии. Задачей же было попытаться спрогнозировать продажи в течение определенного количества дней. Основная цель — помочь компании организовать рациональное управление запасами, удовлетворяя потребительский спрос без лишней загрузки складских резервов. В официальной обучающей выборке предоставлялся большой объем информации по магазинам. Помимо прочего, участникам разрешалось использовать дополнительные данные при условии, что эти данные будут открытыми и доступными для всех участников.
Один из золотых медалистов в одном из первых известных примеров эталонной табличной модели применил глубокое обучение. Его метод задействовал намного меньше инженерии признаков, основанной на знании предметной области, чем методы других золотых медалистов. Этот подход описан в работе Entity Embeddings of Categorical Variables (https://oreil.ly/VmgoU) («Вложения категориальных переменных в виде сущностей»). В онлайн-главе на сайте книги (https://book.fast.ai/) мы показываем, как повторить его с нуля и достичь такой же точности, какая приводится в работе. В аннотации к этому труду его авторы Чен Го (Cheng Guo) и Феликс Бекхан (Felix Bekhahn) пишут:
Вложение сущностей не только уменьшает потребление памяти и ускоряет нейронные сети в сравнении с быстрым кодированием, но, что более важно, путем отображения схожих значений, близких друг к другу в пространстве вложений, оно раскрывает внутренние свойства категориальных переменных… [Это] особенно полезно для датасетов с большим количеством признаков с высокой кардинальностью, где другие методы склонны приводить к переобучению… Поскольку вложение сущностей определяет меру расстояния для категориальных переменных, его можно использовать для визуализации категориальных данных и для кластеризации данных.
Мы уже отмечали все эти моменты, когда создавали модель коллаборативной фильтрации.
Теперь же становится очевидно, что эти открытия выходят далеко за ее рамки.
В данной работе также указывается, что (как мы говорили в предыдущей главе) слой вложений в точности равнозначен размещению стандартного линейного слоя после каждого вводного слоя, закодированного быстро. Авторы для демонстрации этой равнозначности использовали схему, приведенную на рис. 9.1. Имейте в виду, что термин dense layer означает то же, что «линейный слой», а one-hot encoding layer (слои в быстрой кодировке) представляют собой вводы.
Это открытие важно, потому что мы уже знаем, как обучать линейные слои, а значит, это показывает, что с точки зрения архитектуры и алгоритма обучения слой вложений — это просто другой слой. Мы также видели это на практике в предыдущей главе, когда создавали нейронную сеть коллаборативной фильтрации, которая выглядит в точности как эта схема.

Точно так же, как мы анализировали веса вложений для оценок фильмов, авторы работы проанализировали веса вложений для их модели прогнозирования продаж. При этом они обнаружили весьма удивительный факт, который отражает их второе ключевое открытие: вложение преобразует категориальные переменные во вводы, которые являются непрерывными и в то же время несут смысл.
Изображения на рис. 9.2 отражают эти идеи. Они основаны на подходах, использованных в этой работе, а также на некоторой добавленной нами аналитике.
Слева показан график матрицы вложений для возможных значений категории State. Возможные значения категориальной переменной мы называем «уровнями» (или «категориями», или «классами»), поэтому здесь один уровень — это «Berlin», следующий — «Hamburg» и т. д. Справа приведена карта Германии. Фактические местоположения германских земель не являлись частью предоставленных данных, тем не менее модель сама выучила, где они должны находиться, взяв за основу одни только данные о продажах в магазинах.
Помните ли вы наш разговор о расстоянии между вложениями? Авторы рассматриваемой работы нарисовали график расстояний между вложениями магазинов, сопоставив их с фактическими географическими расстояниями между этими магазинами (рис. 9.3), и обнаружили таким образом очень близкое соответствие!
Мы даже пробовали отобразить на графике вложения для дней недели и месяцев, выяснив, что те дни и месяцы, которые находятся близко друг к другу в календаре, также оказались близки и во вложениях. Это показано на рис. 9.4.

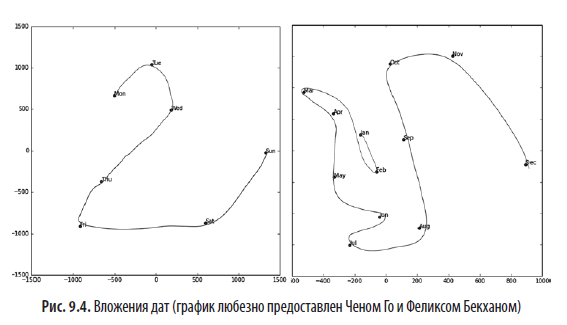
В обоих этих примерах выделяется то, что мы передаем модели конкретно категориальные данные о дискретных сущностях (например, земли Германии или дни недели), после чего модель изучает вложение для этих сущностей, которое определяет непрерывное обозначение расстояния между ними. Поскольку расстояние между вложениями было выучено на основе реальных паттернов в данных, оно склонно соответствовать нашему представлению.
Помимо этого, непрерывность вложений ценна сама по себе, потому что модели лучше понимают именно непрерывные переменные. Это неудивительно, учитывая, что модели построены из множества непрерывных весов параметров и непрерывных значений активаций, которые обновляются посредством градиентного спуска (алгоритм обучения для нахождения минимумов непрерывных функций).
Еще одно преимущество в том, что мы можем легко совмещать непрерывные значения вложений с истинными непрерывными входными данными: мы просто конкатенируем эти переменные и передаем результат в первый линейный слой. Другими словами, сырые категориальные данные преобразуются слоем вложений перед тем, как он взаимодействует с сырыми непрерывными входными данными. Именно так fastai, а также Го и Бекхан обрабатывают табличные модели, содержащие непрерывные и категориальные переменные.
К примерам использования этого подхода с конкатенацией можно отнести то, как Google формирует свои рекомендации в Google Play, что объясняется в работе Wide & Deep Learning for Recommender Systems (https://oreil.ly/wsnvQ) («Широкое и глубокое обучение для рекомендательных систем»). Эта система показана на рис. 9.5.

Интересно, что команда Google совместила оба подхода, которые мы видели в предыдущей главе: скалярное произведение (которое они называют перекрестным произведением) и подходы с нейронными сетями.
Давайте сделаем небольшую паузу. До этого момента решением для всех задач моделирования было обучение модели глубокого обучения. И в самом деле, это очень хорошее правило для сложных неструктурированных данных вроде изображений, звуков, текста естественного языка и т. д. Глубокое обучение также отлично работает для коллаборативной фильтрации. Но для анализа табличных данных оно не всегда является наилучшей отправной точкой.
За гранью глубокого обучения
Большинство курсов по ML буквально закидывают вас десятками алгоритмов — они дают краткое объяснение стоящих за ними математических принципов и приводят игрушечный пример. Вы теряетесь и не понимаете, как именно их нужно применять.
Но мы рады сообщить, что современное машинное обучение можно сузить до двух ключевых техник, которые применимы практически повсеместно. Недавние исследования показали, что огромное множество датасетов можно наилучшим образом смоделировать с помощью всего двух методов.
— Ансамблей деревьев решений (то есть случайных лесов и градиентного бустинга), используемых в основном для структурированных данных (какие можно встретить в таблицах баз данных большинства компаний).
— Многослойных нейронных сетей, обученных с помощью SGD (то есть неглубокого и/или глубокого обучения) и используемых в основном для неструктурированных данных (аудио, изображения и естественный язык).
Несмотря на то что глубокое обучение практически всегда показывает себя лучше в отношении неструктурированных данных, эти два подхода склонны давать схожие результаты для многих видов структурированных данных. Тем не менее ансамбли деревьев решений, как правило, обучаются быстрее, зачастую легче интерпретируются, не нуждаются в специальном GPU-оборудовании и обычно требуют меньше настроек гиперпараметров. К тому же популярность они завоевали намного раньше техник глубокого обучения, поэтому имеют более зрелую экосистему инструментов и документации.
Более существен тот факт, что важнейший этап процесса, а именно интерпретация модели табличных данных, в ансамблях деревьев решений намного проще. Для этого существуют инструменты и методы, позволяющие получать ответы на актуальные вопросы: какие столбцы датасета оказались наиболее важными для прогнозов? Как они связаны с зависимыми переменными? Как они взаимодействуют друг с другом? Какие конкретные признаки были наиболее важны для конкретных наблюдений?
Следовательно, ансамбли деревьев решений — это наш первый подход для анализа нового табличного датасета.
Исключением из этого правила будут случаи, когда датасет отвечает одному из следующих условий.
— Наличие важных категориальных переменных с высокой кардинальностью (кардинальность подразумевает число дискретных уровней, представляющих категории, то есть категориальная переменная с высокой кардинальностью — это нечто вроде почтового индекса, который может иметь тысячи возможных уровней).
— Присутствуют столбцы, содержащие данные, которые будет легче понять с помощью нейронной сети, например простой текст.
На практике, когда мы имеем дело с датасетами, отвечающими этим условиям, то всегда пробуем и метод ансамблей деревьев решений, и глубокое обучение, проверяя, какой сработает лучше. Глубокое обучение наверняка окажется более полезным в нашем примере совместной фильтрации, так как в нем есть не менее двух категориальных переменных с высокой кардинальностью: пользователи и фильмы. Но на практике все выходит не столь однозначно, и зачастую будет присутствовать смесь из категориальных переменных как с высокой, так и с низкой кардинальностью вместе с непрерывными переменными.
Так или иначе очевидно, что нам нужно добавить в наш арсенал моделирования ансамбли деревьев решений.
До этого момента мы использовали PyTorch и fastai почти для всех сложных задач. Но эти библиотеки главным образом спроектированы для алгоритмов, которые выполняют много операций матричного умножения и получения производных (как раз то, что относится к глубокому обучению). Деревья решений на эти операции совсем не опираются, поэтому PyTorch здесь не особо пригодится.
Вместо этого мы будем в основном опираться на библиотеку под названием scikit-learn (также известную как sklearn). Scikit-learn — это популярная библиотека для создания моделей ML, использующая подходы, не относящиеся к глубокому обучению. Дополнительно нам понадобится выполнять обработку табличных данных и запросы, для чего мы используем библиотеку Pandas. И наконец, нам также потребуется NumPy, так как это основная числовая библиотека программирования, на которую опирается и sklearn, и Pandas.
У нас не хватает времени на подробное знакомство со всеми этими библиотеками, поэтому мы просто будем затрагивать самые основные элементы каждой из них. Для более подробного ознакомления мы настоятельно рекомендуем книгу Уэса Маккинни (Wes McKinney) Python for Data Analysis (http://shop.oreilly.com/product/0636920050896.do) («Python для аналитики данных») (O’Reilly). Маккинни является создателем Pandas, так что вы можете быть уверены в точности изложенной в его книге информации.
Перейдем к сбору нужных данных.
Датасет
Датасет, который мы будем использовать в этой главе, взят из соревнования Kaggle по созданию справочника цен (Голубой книги) на подержанные бульдозеры. Целью соревнования было спрогнозировать стоимость продажи конкретной единицы спецтехники на аукционе, исходя из ее износа, типа и комплектации. Представленные для рассмотрения данные взяты из опубликованных результатов аукционов и включают в себя информацию о состоянии спецтехники, а также ее комплектации.
Это очень распространенный тип датасета и задачи прогнозирования, аналогичные которым вы можете встретить и в своем проекте или организации. Рассматриваемый набор данных доступен для загрузки на Kaggle, сайте, проводящем соревнования в области data science.
Соревнования Kaggle
Kaggle — это замечательный ресурс для целеустремленных специалистов по данным и всех тех, кто ищет возможность отточить свои навыки в машинном обучении. Ничто так не поможет повысить мастерство, как решение практических задач с одновременным получением обратной связи.
Kaggle предоставляет:
— интересные датасеты;
— обратную связь по вашим результатам;
— таблицу лидеров, по которой можно оценить хорошие результаты: достижимые и топовый эталонный уровень;
— публикации в блоге от победителей соревнований, дающих полезные советы и рассказывающих об эффективных техниках.
До сих пор все наши датасеты были доступны для скачивания через интегрированную систему датасетов fastai. Текущий набор данных доступен только на Kaggle. Поэтому вам понадобится зарегистрироваться на их сайте, перейти на страницу соревнования (https://oreil.ly/B9wfd), щелкнуть на Rules, а затем на I Understand and Accept. (Несмотря на то что данное соревнование завершилось и участвовать вы в нем не будете, вам все равно нужно принять правила для получения доступа к загрузке данных.)
Самый простой способ скачивания датасетов Kaggle — это использовать Kaggle API. Вы можете установить его с помощью команды pip, выполнив в ячейке блокнота следующую инструкцию:
!pip install kaggleДля использования API Kaggle вам понадобится ключ API, который можно получить, щелкнув на картинке профиля на сайте, выбрав My Account, а затем щелкнув на Create New API Token, — в результате на ваш ПК будет сохранен файл kaggle.json. Далее нужно скопировать этот ключ на GPU-сервер. Для этого откройте скачанный файл, скопируйте содержимое и вставьте его в одиночные кавычки в следующей ячейке блокнота этой главы (например, creds = '{«username»:«xxx»,«key»:«xxx»}'):
creds = ''Затем выполните эту ячейку (выполнение потребуется только один раз):
cred_path = Path('~/.kaggle/kaggle.json').expanduser()
if not cred_path.exists():
cred_path.parent.mkdir(exist_ok=True)
cred_path.write(creds)
cred_path.chmod(0o600)Теперь вы можете скачивать датасеты, для этого осталось только выбрать нужный путь их сохранения:
path = URLs.path('bluebook')
path
Path('/home/sgugger/.fastai/archive/bluebook')После чего можете использовать Kaggle API для скачивания и распаковки датасета:
if not path.exists():
path.mkdir()
api.competition_download_cli('bluebook-for-bulldozers', path=path)
file_extract(path/'bluebook-for-bulldozers.zip')
path.ls(file_type='text')
(#7) [Path('Valid.csv'),Path('Machine_Appendix.csv'),Path('ValidSolution.csv'),Path('TrainAndValid.csv'),Path('random_forest_benchmark_test.csv'),Path('Test.csv'),Path('median_benchmark.csv')]
Теперь, когда мы загрузили датасет, изучим его!
Знакомство с данными
На странице Data (https://oreil.ly/oSrBi) сайта Kaggle дается общая информация по датасету и указывается, что основные его поля, расположенные в train.csv, это:
— SalesID — уникальный идентификатор продажи;
— MachineID — уникальный идентификатор машины. Машина может быть продана несколько раз;
— saleprice — цена, по которой машина ушла с аукциона (указано только в train.csv);
— saledate — дата продажи.
При любом виде работы, связанной с исследованием данных, важно непосредственно изучить эти данные, убедившись, что вы понимаете их формат, как они сохранены, какие типы значений содержат и т. д. Имейте в виду, что даже если вы прочли описание, фактические данные могут оказаться не такими, как вы ожидаете. Мы начнем с чтения обучающей выборки в Pandas DataFrame. Обычно рекомендуется сразу установить параметр low_memory=False и не менять его до тех пор, пока Pandas реально не исчерпает ресурс памяти и не выдаст ошибку. Этот параметр, который по умолчанию установлен как True, дает Pandas команду при определении типа данных каждого столбца просматривать только несколько его строк за раз. Это может привести к тому, что Pandas в разных строках будет использовать разные типы данных, что, в свою очередь, приведет либо к ошибкам обработки данных, либо к последующим проблемам при обучении модели.
Загрузим наши данные и взглянем на столбцы:
df = pd.read_csv(path/'TrainAndValid.csv', low_memory=False)
df.columns
Index(['SalesID', 'SalePrice', 'MachineID', 'ModelID', 'datasource',
'auctioneerID', 'YearMade', 'MachineHoursCurrentMeter', 'UsageBand',
'saledate', 'fiModelDesc', 'fiBaseModel', 'fiSecondaryDesc',
'fiModelSeries', 'fiModelDescriptor', 'ProductSize',
'fiProductClassDesc', 'state', 'ProductGroup', 'ProductGroupDesc',
'Drive_System', 'Enclosure', 'Forks', 'Pad_Type', 'Ride_Control',
'Stick', 'Transmission', 'Turbocharged', 'Blade_Extension',
'Blade_Width', 'Enclosure_Type', 'Engine_Horsepower', 'Hydraulics',
'Pushblock', 'Ripper', 'Scarifier', 'Tip_Control', 'Tire_Size',
'Coupler', 'Coupler_System', 'Grouser_Tracks', 'Hydraulics_Flow',
'Track_Type', 'Undercarriage_Pad_Width', 'Stick_Length', 'Thumb',
'Pattern_Changer', 'Grouser_Type', 'Backhoe_Mounting', 'Blade_Type',
'Travel_Controls', 'Differential_Type', 'Steering_Controls'],
dtype='object')Многовато столбцов! Лучше просмотреть весь датасет, чтобы понять, какая информация находится в каждом из них. Вскоре мы увидим, как «сосредоточиться» на самых интересных.
Правильным будет начать с обработки порядковых столбцов. Порядковые столбцы — это те, которые содержат строки или аналогичные данные, имеющие естественный порядок. Например, вот уровни ProductSize:
df['ProductSize'].unique()
array([nan, 'Medium', 'Small', 'Large / Medium', 'Mini', 'Large', 'Compact'],
dtype=object)О подходящем порядке этих уровней можно сообщить Pandas так:
sizes = 'Large','Large / Medium','Medium','Small','Mini','Compact'
df['ProductSize'] = df['ProductSize'].astype('category')
df['ProductSize'].cat.set_categories(sizes, ordered=True, inplace=True)Самым важным столбцом данных является зависимая переменная: та, которую мы будем прогнозировать. Вспомните, что метрика модели — это функция, отражающая качество прогнозов. Само собой разумеется, что ее выбор является значительной частью настройки проекта. Во многих случаях выбор удачной метрики станет больше напоминать процесс проектирования — будет недостаточно подобрать уже существующую переменную. Вам нужно внимательно подумать о том, какая метрика или набор метрик реально измеряют важный для вас показатель эффективности модели. Если эту метрику не представляет никакая переменная, то следует оценить возможность ее создания из доступных переменных.
Как бы то ни было, но в данном случае выбор метрики уже предписан Kaggle: мы берем среднеквадратичную логарифмическую ошибку (RMLSE) между фактическими и спрогнозированными ценами аукциона. Вычисляется же она достаточно простым способом: мы получаем логарифм цен, для значения которого m_rmse и дает нам то, что в итоге нужно:
dep_var = 'SalePrice'
df[dep_var] = np.log(df[dep_var])Теперь мы подготовились к изучению нашего первого алгоритма машинного обучения для табличных данных: деревьев решений.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 30% по купону — PyTorch




