
 Привет, Хаброжители! Пора научиться использовать TensorFlow.js для построения моделей глубокого обучения, работающих непосредственно в браузере! Умные веб-приложения захватили мир, а реализовать их в браузере или серверной части позволяет TensorFlow.js. Данная библиотека блестяще портируется, ее модели работают везде, где работает JavaScript. Специалисты из Google Brain создали книгу, которая поможет решать реальные прикладные задачи. Вы не будете скучать над теорией, а сразу освоите базу глубокого обучения и познакомитесь с продвинутыми концепциями ИИ на примерах анализа текста, обработки речи, распознавания образов и самообучающегося игрового искусственного интеллекта.
Привет, Хаброжители! Пора научиться использовать TensorFlow.js для построения моделей глубокого обучения, работающих непосредственно в браузере! Умные веб-приложения захватили мир, а реализовать их в браузере или серверной части позволяет TensorFlow.js. Данная библиотека блестяще портируется, ее модели работают везде, где работает JavaScript. Специалисты из Google Brain создали книгу, которая поможет решать реальные прикладные задачи. Вы не будете скучать над теорией, а сразу освоите базу глубокого обучения и познакомитесь с продвинутыми концепциями ИИ на примерах анализа текста, обработки речи, распознавания образов и самообучающегося игрового искусственного интеллекта.
Для кого предназначено издание
Книга написана для тех программистов с практическими знаниями JavaScript и опытом разработки веб-клиентской части либо прикладной части на основе Node.js, которые хотели бы заняться глубоким обучением. Она будет полезна следующим двум группам читателей.
JavaScript-программистам без особого опыта работы с машинным обучением и знания его математических основ, стремящимся хорошо разобраться в том, как функционирует глубокое обучение, и получить практические знания технологического процесса глубокого обучения, чтобы иметь возможность решать распространенные задачи науки о данных, такие как классификация и регрессия.
Веб- и Node.js-разработчикам, перед которыми стоит задача развертывания предобученных моделей в своем веб-приложении или стеке прикладной части.
Для первой группы читателей в книге подробно «разжевываются» основные понятия машинного и глубокого обучения. Это делается на интересных примерах кода JavaScript, готовых для дальнейших экспериментов и исследований. Вместо формальных математических формул мы используем схемы, псевдокод и конкретные примеры, чтобы помочь вам усвоить на интуитивном уровне, но достаточно прочно принципы работы глубокого обучения.
Для второй группы читателей мы рассмотрим основные этапы преобразования уже существующих моделей (например, из библиотек обучения Python) в совместимый с веб или Node формат, подходящий для развертывания в клиентской части или стеке Node. Особое внимание мы уделяем практическим вопросам, таким как оптимизация размера и производительность модели, а также особенностям различных сред развертывания, от серверов до расширений браузеров и мобильных приложений.
Для всех читателей подробно описывается API TensorFlow.js для ввода, обработки и форматирования данных, для создания и загрузки моделей, а также для выполнения вывода, оценки и обучения.
Наконец, книга окажется полезной в качестве вводного руководства как по простым, так и по продвинутым нейронным сетям всем заинтересованным читателям с техническим складом ума, которым не приходится регулярно программировать на JavaScript или каком-либо другом языке.
JavaScript-программистам без особого опыта работы с машинным обучением и знания его математических основ, стремящимся хорошо разобраться в том, как функционирует глубокое обучение, и получить практические знания технологического процесса глубокого обучения, чтобы иметь возможность решать распространенные задачи науки о данных, такие как классификация и регрессия.
Веб- и Node.js-разработчикам, перед которыми стоит задача развертывания предобученных моделей в своем веб-приложении или стеке прикладной части.
Для первой группы читателей в книге подробно «разжевываются» основные понятия машинного и глубокого обучения. Это делается на интересных примерах кода JavaScript, готовых для дальнейших экспериментов и исследований. Вместо формальных математических формул мы используем схемы, псевдокод и конкретные примеры, чтобы помочь вам усвоить на интуитивном уровне, но достаточно прочно принципы работы глубокого обучения.
Для второй группы читателей мы рассмотрим основные этапы преобразования уже существующих моделей (например, из библиотек обучения Python) в совместимый с веб или Node формат, подходящий для развертывания в клиентской части или стеке Node. Особое внимание мы уделяем практическим вопросам, таким как оптимизация размера и производительность модели, а также особенностям различных сред развертывания, от серверов до расширений браузеров и мобильных приложений.
Для всех читателей подробно описывается API TensorFlow.js для ввода, обработки и форматирования данных, для создания и загрузки моделей, а также для выполнения вывода, оценки и обучения.
Наконец, книга окажется полезной в качестве вводного руководства как по простым, так и по продвинутым нейронным сетям всем заинтересованным читателям с техническим складом ума, которым не приходится регулярно программировать на JavaScript или каком-либо другом языке.
Работа с данными
Нынешней революцией машинного обучения мы во многом обязаны широкой доступности больших массивов данных. Без свободного доступа к большим объемам высококачественных данных такое взрывное развитие сферы машинного обучения было бы невозможно. Наборы данных сейчас доступны по всему Интернету, они свободно распространяются на таких сайтах, как Kaggle и OpenML, равно как и эталоны современных уровней производительности. Целые отрасли машинного обучения продвигаются вперед прежде всего за счет доступности «трудных» наборов данных, задавая планку и эталон для всего сообщества машинного обучения. Если считать, что развитие машинного обучения — «космическая гонка» нашего времени, то данные можно считать «ракетным топливом» благодаря их большому потенциалу, ценности, гибкости и критической важности для работы систем машинного обучения. Не говоря уже о том, что зашумленные данные, как и испорченное топливо, вполне могут привести к сбою системы. Вся эта глава посвящена данным. Мы рассмотрим рекомендуемые практики организации данных, обнаружения и исправления проблем в них, а также их эффективного использования.
«Но разве мы не работали с данными все это время?» — спросите вы. Да, в предыдущих главах мы работали с самыми разнообразными источниками данных. Мы обучали модели для изображений как на искусственных, так на и взятых с веб-камеры изображениях. Мы использовали перенос обучения для создания средства распознавания речи на основе набора аудиосемплов и брали данные из табличных наборов для предсказания цен. Что же здесь еще обсуждать? Разве мы не достигли мастерства в работе с данными?
Вспомните, какие паттерны использования данных встречались в предыдущих примерах. Обычно сначала нужно было скачать данные из удаленного источника. Далее мы (обычно) приводили их в нужный формат, например преобразовывали строки в унитарные векторы слов или нормализовали средние значения и дисперсии табличных источников данных. После этого мы организовывали данные в батчи и преобразовывали их в стандартные массивы чисел, представленные в виде тензоров, а затем уже подавали на вход модели. И это все еще до первого шага обучения.
Подобный паттерн скачивания — преобразования — организации по батчам очень распространен, и библиотека TensorFlow.js включает инструменты для его упрощения, модульной организации и снижения числа ошибок. В этой главе мы расскажем вам об инструментах из пространства имен tf.data и главном из них — tf.data.Dataset, позволяющем выполнять отложенную потоковую обработку данных. Благодаря этому подходу можно скачивать, преобразовывать данные и обращаться к ним по мере необходимости, вместо того чтобы скачивать источник данных полностью и хранить его в памяти для возможного доступа. Отложенная потоковая обработка существенно упрощает работу с источниками данных, не помещающимися в памяти отдельной вкладки браузера или даже в оперативной памяти машины.
Сначала мы познакомим вас с API tf.data.Dataset и покажем, как его настраивать и связывать с моделью. А затем приведем немного теории и расскажем об утилитах, предназначенных для просмотра и исследования данных с целью поиска и разрешения возможных проблем. Завершается глава рассказом о дополнении данных — методе расширения набора данных путем создания их искусственных псевдопримеров для повышения качества работы модели.
Работа с данными с помощью пространства имен tf.data
Как обучить спам-фильтр, если размер базы данных электронной почты занимает сотни гигабайт и база требует специальных учетных данных для доступа? Как создать классификатор изображений, если база данных обучающих изображений слишком велика и не помещается на одной машине?
Обращение к большим массивам данных и выполнение операций с ними — ключевой навык любого специалиста по машинному обучению, но до сих пор мы имели дело лишь с приложениями, в которых данные прекрасно помещались в доступной приложению оперативной памяти. Множество приложений требуют работы с большими, громоздкими и, возможно, содержащими персональную информацию источниками данных, для которых подобная методика не подходит. Большие приложения требуют технологии доступа к данным, размещенным в удаленном источнике, по частям, по мере требования.
TensorFlow.js включает интегрированную библиотеку, предназначенную как раз для подобных операций с данными. Эта библиотека, вдохновленная API tf.data Python-версии TensorFlow, создана, чтобы пользователи могли с помощью коротких и удобочитаемых команд вводить данные, выполнять их предварительную обработку и переправлять их далее. Вся эта функциональность доступна в пространстве имен tf.data, если предварительно импортировать TensorFlow.js с помощью оператора следующего вида:
import * as tf from '@tensorflow/tfjs';Объект tf.data.Dataset
Основная работа с модулем tfjs-data выполняется через единственный объект tf.data.Dataset. Он предоставляет простой, высокопроизводительный, с широкими возможностями настройки способ обхода и обработки больших (потенциально вообще неограниченных) списков элементов данных. В самом первом приближении можно считать Dataset аналогом итерируемой коллекции произвольных элементов, в чем-то напоминающей Stream в Node.js. При запросе очередного элемента из Dataset внутренняя реализация скачивает его и обеспечивает доступ к нему либо при необходимости запускает функцию для его создания. Эта абстракция упрощает обучение модели на объемах данных, целиком не помещающихся в оперативной памяти, а также облегчает совместное использование и организацию объектов Dataset как полноправных объектов в тех случаях, когда их более одного. Dataset экономит память за счет потоковой передачи лишь требуемых битов данных, и не приходится обращаться ко всему массиву. API Dataset также оптимизирует работу, по сравнению с «наивной» реализацией, за счет упреждающей выборки значений, которые могут понадобиться.
Создание объекта tf.data.Dataset
По состоянию на версию 1.2.7 TensorFlow.js существует три способа подключения объекта tf.data.Dataset к поставщику данных. Мы довольно подробно рассмотрим их все, а краткую сводку вы найдете в табл. 6.1.
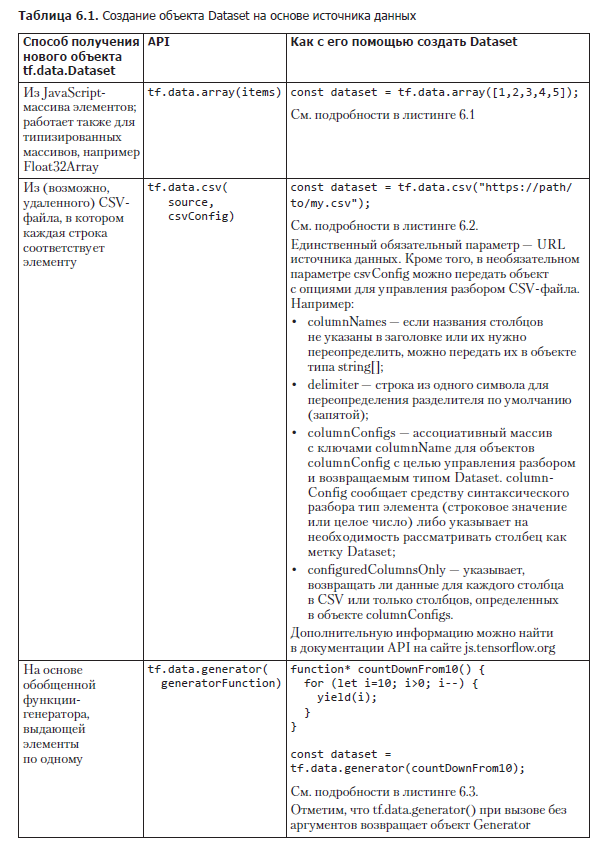
Создание объекта tf.data.Dataset из массива
Простейший способ создать новый объект tf.data.Dataset — сформировать его на основе JavaScript-массива. Создать Dataset на основе загруженного в память массива можно с помощью функции tf.data.array(). Конечно, не будет никакого выигрыша в скорости обучения или экономии памяти, по сравнению с непосредственным использованием массива, но у доступа к массиву через объект Dataset есть свои преимущества. Например, использование объектов Dataset упрощает организацию предварительной обработки, а также обучение и оценку благодаря простым API model.fitDataset() и model.evaluateDataset(), как мы увидим в разделе 6.2. В отличие от model.fit(x, y) вызов model.fitDataset(myDataset) не перемещает сразу все данные в память GPU, благодаря чему можно работать с наборами данных, не помещающимися туда целиком. Ограничение по памяти движка V8 JavaScript (1,4 Гбайт в 64-битных системах) обычно превышает объем, который TensorFlow.js может целиком разместить в памяти WebGL. Кроме того, использование API tf.data — одна из рекомендуемых практик инженерии разработки ПО, ведь оно упрощает модульный переход на другие типы данных без особых изменений кода. Без абстракции объекта Dataset подробности реализации источника данных могут легко просочиться в код его использования при обучении модели — узел, который придется распутывать при переходе на другую реализацию.
Для создания объекта Dataset из уже существующего массива можно воспользоваться tf.data.array(itemsAsArray), как показано в листинге 6.1.
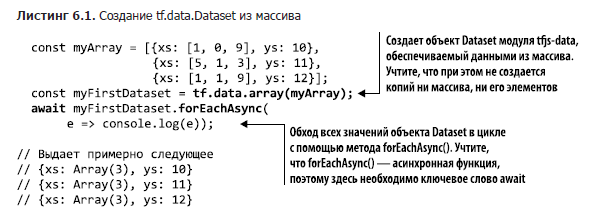
Мы проходим по всем элементам Dataset в цикле с помощью функции forEachAsync(), по очереди выдающей все элементы. Больше подробностей о функции forEachAsync() вы можете найти в подразделе 6.1.3.
Элементы объектов Dataset, помимо тензоров, могут содержать простые типы данных JavaScript1(например, числа и строковые значения), а также кортежи, массивы и многократно вложенные объекты подобных структур данных. В этом крошечном примере структура всех трех элементов объекта Dataset одинакова: это объекты с одинаковыми ключами и одним типом значений для ключей. В принципе, tf.data.Dataset позволяет комбинировать различные типы элементов, но наиболее распространен сценарий использования, при котором элементы Dataset представляют собой осмысленные семантические единицы одного типа. Обычно они отражают примеры одной сущности. Поэтому, за исключением очень необычных сценариев использования, типы данных и структуры всех элементов совпадают.
Создание объекта tf.data.Dataset из CSV-файла
Один из чаще всего встречающихся типов элементов в наборах данных — объект типа «ключ/значение», соответствующий одной строке таблицы, например одна строка CSV-файла. В листинге 6.2 приведена очень простая программа — она подключает и выводит набор данных Boston-housing, знакомый нам по главе 2.
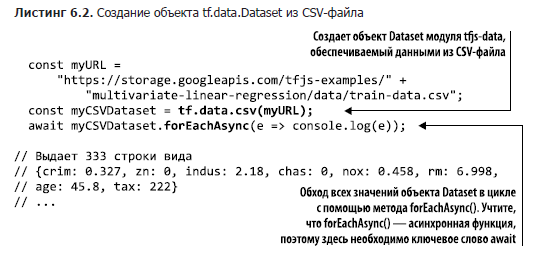
Здесь вместо tf.data.array() используется функция tf.data.csv(), в которую передается URL CSV-файла. В результате создается объект Dataset, обеспечиваемый данными из CSV-файла, проход в цикле по которому эквивалентен обходу в цикле строк CSV-файла. В Node.js можно подключиться к локальному CSV-файлу с помощью дескриптора URL с префиксом file://, вот так:
> const data = tf.data.csv(
'file://./relative/fs/path/to/boston-housing-train.csv');В цикле каждая строка CSV-файла преобразуется в объект JavaScript. Возвращаемые из объекта Dataset элементы представляют собой объекты, содержащие по одному свойству для каждого столбца CSV, причем эти свойства называются в соответствии с названиями столбцов CSV-файла, что удобно для работы с элементами, ведь теперь не требуется запоминать порядок полей. В подразделе 6.3.1 мы рассмотрим подробнее, как работать с CSV-файлами.
Создание объекта tf.data.Dataset на основе функции-генератора
Третий и наиболее гибкий способ создания tf.data.Dataset — на основе функции-генератора, для чего используется метод tf.data.generator(). Метод принимает в качестве аргумента функцию-генератор (function*1) языка JavaScript. Если вы не знакомы с функциями-генераторами — относительно новой возможностью JavaScript, то рекомендуем потратить немного времени на чтение документации. Цель функции-генератора — выдавать последовательность значений по мере необходимости, либо в бесконечном цикле, либо пока последовательность не закончится. Выдаваемые функцией-генератором значения превращаются в значения объекта Dataset. Например, простейшая функция-генератор может выдавать случайные числа или извлекать «снимки» состояния подключенного аппаратного устройства. Сложные функции-генераторы могут интегрироваться в компьютерные игры, выдавая снимки экрана, игровой счет, а также управлять вводом/выводом. В листинге 6.3 очень простая функция-генератор выдает элементы выборки бросания костей.

Несколько любопытных замечаний относительно объекта Dataset для имитации игры из листинга 6.3. Во-первых, обратите внимание, что созданный здесь набор данных, myGeneratorDataset, бесконечен. Поскольку в функции-генераторе отсутствует return, можно спокойно производить выборку элементов из набора данных до бесконечности. Выполнение для этого набора данных forEachAsync() или toArray() (см. подраздел 6.1.3) никогда бы не завершилось и привело бы, по всей видимости, к аварийному сбою сервера или браузера, так что будьте осторожны! Для работы с подобными объектами необходимо создать другой объект Dataset — ограниченную выборку из неограниченного первоисточника, для чего следует воспользоваться take(n). Чуть позже мы расскажем об этом подробнее.
Во-вторых, учтите, что объект Dataset производит замыкание локальной переменной. Это помогает при журналировании и отладке, позволяя определить число произведенных вызовов функции-генератора.
В-третьих, учтите, что данные до момента их запроса не существуют. В нашем случае мы за все время обращаемся только к одному элементу набора данных, что и отразится в значении numPlaysSoFar.
Наборы данных на основе генераторов отличаются широкими возможностями и исключительной гибкостью, позволяя разработчикам подключать модели к разнообразным API поставщиков данных, например получать данные из запроса к БД, из скачиваемых частями по сети данных или от подключенного аппаратного обеспечения. Подробнее API tf.data.generator() рассматривается в инфобоксе 6.1.


Доступ к данным в объекте Dataset
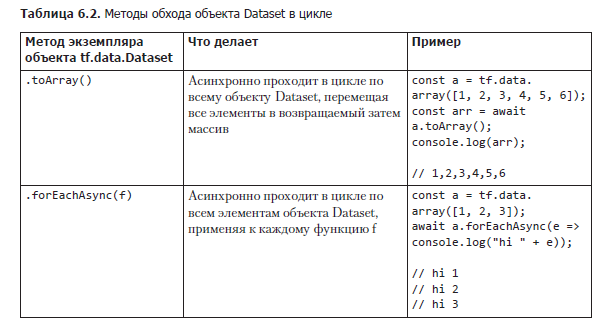
При наличии данных в объекте Dataset, разумеется, хочется каким-либо образом получить к ним доступ. Структуры данных, которые можно создать, но из которых нельзя ничего прочитать, не слишком полезны. Существует два API для извлечения данных из объекта Dataset, но пользователям tf.data редко приходится их применять. Обычно за доступ к данным в объекте Dataset отвечают более высокоуровневые API. Например, при обучении модели мы используем описанный в разделе 6.2 API model.fitDataset(). Он обращается к данным в объекте Dataset вместо нас, а нам как пользователям никогда не приходится обращаться к данным напрямую. Тем не менее для отладки, тестирования и анализа работы объекта Dataset важно понимать, что у него внутри.
Первый способ доступа к данным в объекте Dataset — их потоковый вывод в массив с помощью функции Dataset.toArray(), которая делает именно то, что и подразумевает ее название: проходит в цикле по всему объекту Dataset, перемещая все элементы в массив, и возвращает этот массив пользователю. Пользователям следует с осторожностью выполнять эту функцию, чтобы случайно не создать массив, слишком большой для среды выполнения JavaScript. Это распространенная ошибка, в случае, например, когда объект Dataset подключен к большому удаленному источнику данных или представляет собой неограниченный Dataset, предназначенный для чтения данных с датчика.
Второй способ доступа к данным в Dataset — выполнение некой функции для каждого примера данных этого Dataset с помощью dataset.forEachAsync(f). Передаваемый forEachAsync(f) аргумент f применяется ко всем элементам по очереди аналогично конструкции forEach() в массивах и множествах JavaScript, то есть нативным Array.forEach() и Set.forEach().
Важно отметить, что и Dataset.forEachAsync(), и Dataset.toArray() — асинхронные функции, в отличие от синхронной Array.forEach(), и допустить ошибку здесь очень легко. Dataset.toArray() возвращает промис и в общем случае требует ключевого слова await либо .then(), если от него ожидается синхронное поведение. Учтите, что, если забыть await, промис может не разрешиться так, как нужно, что приведет к ошибкам в работе программы. Одна из типичных ошибок связана с тем, что объект Dataset кажется пустым, поскольку обход его содержимого происходит до разрешения промиса.
Функция Dataset.forEachAsync() асинхронная, в отличие от синхронной Array.forEach(), вовсе не потому, что данные, к которым обращается Dataset, приходится создавать, вычислять или получать из удаленного источника. Асинхронность в этом случае дает возможность эффективно использовать доступные вычислительные ресурсы во время ожидания. Общая сводка этих методов приведена в табл. 6.2.
Операции над наборами данных модуля tfjs-data
Безусловно, очень удобно, если данные можно использовать в исходном виде, без какой-либо очистки или предварительной обработки. Но, по нашему личному опыту, такого практически никогда не случается, за исключением примеров, специально создаваемых в учебных целях или для оценки производительности. Чаще всего данные приходится каким-либо образом преобразовывать перед их анализом или применением в задачах машинного обучения. Например, источники данных нередко содержат лишние элементы, которые нужно отфильтровать. Зачастую данные, относящиеся к некоторым ключам, требуют разбора, десериализации или переименования. Данные могут храниться в отсортированном виде, а значит, их нужно перетасовать случайным образом, прежде чем использовать для обучения или оценки качества модели. Набор данных может требовать разбиения на непересекающиеся множества для обучения и контроля. Предварительная обработка практически неизбежна. Если вам попался чистый и готовый к использованию набор данных — скорее всего, кто-то уже очистил и предварительно обработал их вместо вас!
tf.data.Dataset предоставляет предназначенные для подобных операций методы (табл. 6.3), которые можно организовывать цепочкой. Все они возвращают новый объект Dataset, но не думайте, что все элементы набора данных копируются или при каждом вызове метода все элементы обходятся в цикле! API tf.data.Dataset просто загружает и преобразует элементы отложенным образом. Объект Dataset, созданный соединением цепочкой нескольких из этих методов, можно считать маленькой программой, выполняемой только при запросе элементов на конце цепочки. Только в этот момент экземпляр Dataset проходит обратно по цепочке операций, возможно, прямо до запроса данных из удаленного источника данных.
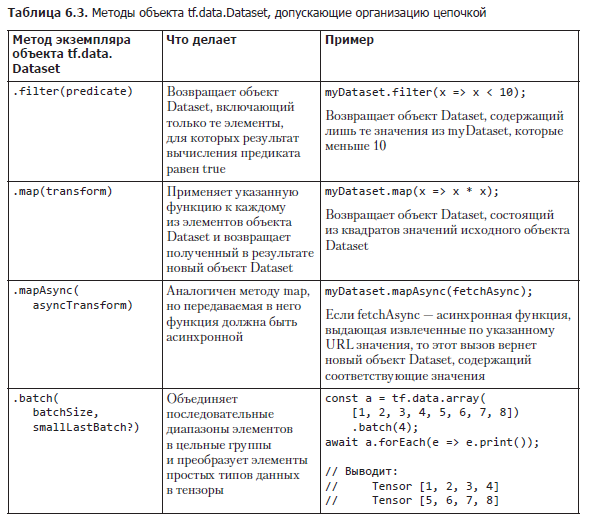
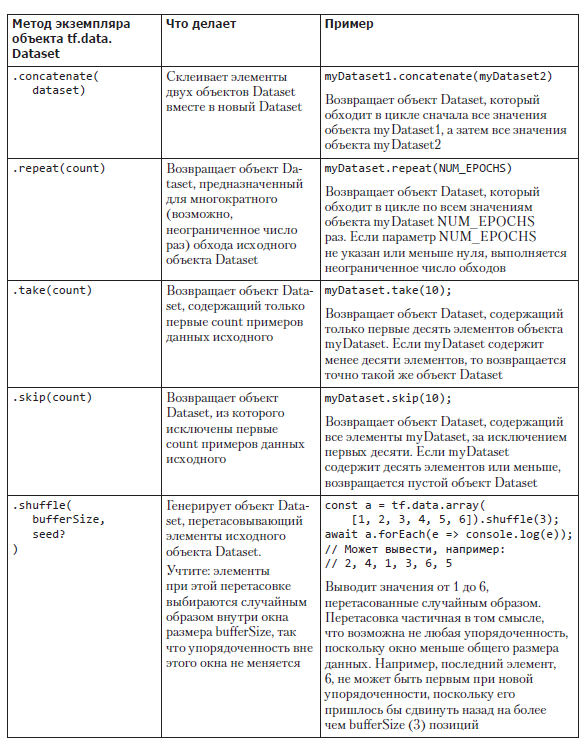
Эти операции можно связывать цепочкой, создавая простые, но обладающие широкими возможностями конвейеры обработки. Например, для разбиения случайным образом набора данных на обучающий и контрольный наборы можно воспользоваться рецептом из листинга 6.4 (см. tfjs-examples/iris-fitDataset/data.js).

В этом листинге важно обратить внимание на следующее. Чтобы распределить примеры данных случайным образом по обучающему и контрольному наборам, мы сначала перетасовываем данные. Первые N примеров берем в качестве обучающих данных. А для получения контрольных данных пропускаем эти N примеров и берем остальные. Очень важно перетасовывать данные одинаково при выборке, чтобы один и тот же пример данных не оказался в обоих множествах; поэтому при выборке из обоих конвейеров используется одинаковое начальное значение для перетасовки.
Важно также отметить, что функция map() применяется после операции skip. Вызвать .map(preprocessFn) можно и до skip, но при этом preprocessFn будет выполняться и для отброшенных примеров данных — пустая трата вычислительных ресурсов. Проверить, что все происходит именно так, можно с помощью кода из листинга 6.5.


Еще один распространенный сценарий использования dataset.map() — нормализация входных данных. Например, легко представить себе сценарий, в котором может пригодиться нормализация данных до нулевого среднего значения, но число входных примеров данных бесконечно. Для вычитания среднего значения необходимо сначала вычислить математическое ожидание распределения, но как вычислить среднее значение бесконечного множества? Можно было бы рассчитать среднее значение репрезентативной выборки из этого распределения, но, если взять выборку неправильного размера, легко допустить ошибку. Например, представьте себе распределение, почти все значения которого равны 0 и лишь значение каждого десятимиллионного примера данных равно 109. Математическое ожидание такого распределения равно 100, но, если вычислить среднее значение первого миллиона примеров данных, результат получится совершенно неправильный.
Можно выполнить потоковую нормализацию с помощью API Dataset следующим образом (листинг 6.6). В листинге подсчитывается скользящий итог числа просмотренных примеров данных, а также их скользящая сумма. Благодаря этому возможна потоковая нормализация. Здесь мы работаем со скалярными значениями, не тензорами, но структура версии для тензоров будет выглядеть аналогично.

Обратите внимание, что мы создаем новую функцию отображения, использующую собственные копии счетчика и накопителя элементов. Благодаря этому можно нормализовать несколько наборов данных одновременно. В противном случае оба объекта Dataset подсчитывали бы вызовы и суммы с помощью одних и тех же переменных. У этого решения есть свои ограничения, из которых особенно стоит отметить опасность арифметического переполнения переменных samplesSoFar и sumSoFar, так что осторожность здесь не помешает.
Об авторах
Шэнкуинг Цэй, Стэн Байлесчи и Эрик Нильсон — специалисты по разработке программного обеспечения из команды Google Brain, основные разработчики высокоуровневого API TensorFlow.js, в том числе примеров, документации и соответствующих утилит. Они использовали глубокое обучение на основе TensorFlow.js для реальных задач, например для альтернативных методов коммуникации с инвалидами. Все они имеют ученые степени от MIT.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — JavaScript
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.




