
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
 Привет, Хаброжители!
Привет, Хаброжители!Микросервисная архитектура обеспечивает высокую скорость изменений и хорошую масштабируемость, а также позволяет создавать чистые эволюционирующие системы. Но реализовать свою первую микросервисную архитектуру непросто. Как сделать выбор из множества вариантов и обучить свою команду всем техническим деталям, чтобы максимально увеличить шансы на успех? В этой книге авторы, Ронни Митра и Иракли Надареишвили, предоставили пошаговое руководство для построения эффективной архитектуры микросервисов. Архитекторы и инженеры пройдут путь внедрения, основанный на методах и архитектурах, доказавших свою эффективность для микросервисных систем. Вы создадите операционную модель, проект микросервиса, инфраструктурную основу и два работающих микросервиса, а затем соедините эти компоненты в одну реализацию. Для любого, перед кем стоит задача создания микросервисов, руководство станет бесценным источником знаний.
Для кого эта книга
Мы написали эту книгу для разработчиков микросервисов. Затрагивая некоторые принципы и модели системы микросервисов, основное внимание мы уделяем практическому проектированию и разработке. Если вы архитектор или инженер микросервисов, то эта книга для вас. Но она также будет полезна читателям, которые просто хотят больше узнать о реализации микросервисов.
Почему границы имеют значение, когда они имеют значение и как их найти
В самом названии архитектурного шаблона присутствует слово «микро»: архитектура, которую мы разрабатываем, — это архитектура микросервисов! Но насколько «микро» должны быть наши сервисы? Очевидно, что речь не идет о физической длине чего-либо и не предполагается, что микро означает одну миллионную долю метра (то есть базовой единицы длины в Международной системе единиц). Так что же означает микро для нас? Как разделить нашу большую задачу на мелкие сервисы, чтобы получить обещанные преимущества микросервисов? Может быть, нужно распечатать исходный код на бумаге, склеить все листы вместе и измерить его буквальную длину? Или, если без шуток, следует руководствоваться количеством строк в исходном коде — и постараться сохранить это число небольшим, чтобы гарантировать, что каждый из микросервисов также получится достаточно малым? Однако что значит «достаточно»? Можно ли просто произвольно объявить, что каждый микросервис должен содержать не более 500 строк кода? А может быть, можно провести границы по сторонам функциональных блоков и сказать, что каждая отдельная возможность, представленная функцией в исходном коде нашей системы, является микросервисом? Следуя этой логике, мы могли бы реализовать все наше приложение, скажем, с помощью бессерверных функций, объявив каждую такую функцию микросервисом. Легко и просто! Верно? А может быть, и нет.
На самом деле все эти упрощенные подходы были опробованы на практике, и все они имеют существенные недостатки. Традиционно исходные строки кода (source lines of code, SLOC) использовались в качестве меры затрат усилий/сложности, но ныне общепризнанно, что это плохая мера определения сложности или истинного размера любого кода, которым легко манипулировать. Поэтому, даже если бы нашей целью было создание мини-сервисов в надежде сохранить их простыми, количество строк кода было бы плохим показателем.
Проведение границ по краям функциональных блоков еще более заманчиво. И стало еще более соблазнительным с ростом популярности бессерверных функций, таких как лямбда-функции Amazon Web Services (AWS). Опираясь на производительность и широкое внедрение лямбд AWS, многие команды поспешили объявить эти функции микросервисами. Если вы пойдете по этому пути, то возникнет ряд проблем, наиболее серьезными из которых являются следующие.
- Проведение границ на основе технических потребностей является антипаттерном. Согласно Льюису и Фаулеру (https://oreil.ly/mRUrv), микросервисы должны быть «организованы вокруг бизнес-возможностей», а не технических потребностей. Аналогично Парнас (https://oreil.ly/1AcI0) в статье 1972 года рекомендует разделять системы, основываясь на модульной инкапсуляции изменений проекта с течением времени. Ни один из подходов не имеет строгого соответствия границам бессерверных функций.
- Слишком подробная детализация, слишком рано. Взрывная детализация на ранних этапах проектирования микросервисов может привести к чрезмерному усложнению, способному затормозить работу над микросервисами еще до того, как у них появится шанс добиться успеха.
В главе 1 мы сформулировали основную цель архитектуры микросервисов: в первую очередь минимизировать затраты на координацию в сложной среде с несколькими командами для достижения гармонии между скоростью и безопасностью. Поэтому сервисы должны проектироваться так, чтобы свести к минимуму необходимость координации между командами, работающими над различными микросервисами. Однако если разделить код на функции так, что это не обязательно приведет к минимизации координации, то мы получим микросервисы неправильного размера. Просто предполагать, что любой способ организации кода в бессерверные функции уменьшит координацию, ошибочно.
Ранее мы заявляли, что важной причиной отказа от подхода к разделению приложения на микросервисы, основанного на размере или функциональных границах, является опасность преждевременной оптимизации — слишком большого количества слишком маленьких сервисов на ранних этапах вашего пути к микросервисам. Первопроходцы в мире микросервисов, такие как Netflix, SoundCloud, Amazon и другие, в конечном итоге обнаружили, что у них слишком много микросервисов (https://oreil.ly/r5vYU)! Однако это не означает, что они начали с сотен узкоспециализированных микросервисов в первый же день. Скорее, большое количество микросервисов — это то, до чего они оптимизировали свои системы за многие годы разработки, после достижения операционной зрелости, позволяющей справиться с уровнем сложности, обусловленным высокой степенью детализации микросервисов.
Избегайте создания избыточного количества микросервисов на ранних этапах
Определение размера сервисов в микросервисной архитектуре, безусловно, является процессом, который должен разворачиваться со временем. Верный способ саботировать все усилия — попытаться разработать чрезмерно детализированную систему на ранних этапах этого процесса.
Независимо от того, работаете ли вы над новым проектом или разделяете на части существующий монолит, начинать нужно с небольшого количества сервисов и постепенно увеличивать его. Если это приведет к тому, что некоторые из микросервисов изначально получатся больше, чем в их целевом состоянии, то это совершенно нормально. Вы сможете разделить их позже.
Даже если мы начинаем с нескольких микросервисов и делаем это постепенно, нам нужна надежная методология определения их размера. Далее мы рассмотрим практические рекомендации, успешно применяемые в отрасли.
Предметно-ориентированное проектирование и границы микросервисов
В начале изучения успешных приемов проектирования микросервисов Сэм Ньюман представил некоторые основополагающие базовые правила в своей книге Building Microservices (O’Reilly) (http://shop.oreilly.com/product/0636920033158.do). Он предположил, что при определении границ сервисов мы должны стремиться к такому проекту, чтобы сервисы были:
- слабосвязанными — сервисы должны быть достаточно неосведомленными и независимыми друг от друга, чтобы изменение кода в одном из них не приводило к возникновению волнового эффекта в других. Желательно также ограничить количество различных типов вызовов от одного сервиса к другому, поскольку, помимо потенциальной проблемы с производительностью, интенсивное общение также может привести к тесной связанности компонентов. Учитывая наш подход «минимизации координации», преимущество слабой связи сервисов совершенно очевидно;
- высокосвязными — функции, присутствующие в сервисе, должны быть тесно связаны, в то время как несвязанные функции должны инкапсулироваться в другом месте. Таким образом, если требуется изменить логическую функциональную единицу, вы сможете изменить ее в одном месте и минимизировать время на публикацию этого изменения (важный показатель). Напротив, если для этого придется изменить код в нескольких сервисах, то понадобится выпустить множество различных сервисов одновременно, чтобы внедрить это изменение. Это потребует значительных затрат на координацию, особенно если этими сервисами «владеют» несколько разных команд, и напрямую поставит под угрозу нашу цель минимизации затрат на координацию;
- согласованными с бизнес-возможностями — большинство запросов на модификацию или расширение функциональности обусловлены потребностями бизнеса, и, если наши границы хорошо согласованы с границами бизнес-возможностей, то нам будет проще удовлетворить указанные выше первое и второе требования к проекту. Во времена монолитных архитектур программисты часто пытались стандартизировать «канонические модели данных». Однако практика вновь и вновь демонстрировала, что подробные модели данных, моделирующие реальность, существуют недолго — они довольно часто меняются и их стандартизация приводит к частым переделкам. Набор бизнес-возможностей, предоставляемых вашими подсистемами, напротив, является более долговечным. Модуль учета всегда сможет предоставить желаемый набор возможностей более крупной системе независимо от того, как ее внутренняя организация будет развиваться с течением времени.
Эти принципы проектирования доказали свою полезность и получили широкое распространение среди разработчиков микросервисов. Тем не менее они являют собой довольно высокоуровневые амбициозные принципы и, возможно, не предоставляют конкретных рекомендаций по выбору сервисов, необходимых практикам в их повседневной работе. В поисках более практичной методологии многие обратились к предметно-ориентированному проектированию.
Методология проектирования программного обеспечения, известная как предметно-ориентированное проектирование (Domain-Driven Design, DDD), появилась значительно раньше архитектуры микросервисов. Ее представил Эрик Эванс в 2003 году в своей одноименной книге Domain-Driven Design: Tackling Complexity in the Heart of Software (Addison-Wesley) (https://learning.oreilly.com/library/view/domain-driven-design-tackling/0321125215). Основной предпосылкой появления методологии является утверждение о том, что при анализе сложных систем мы должны избегать поиска единой универсальной модели предметной области, представляющей всю систему. В частности, как сказал Эванс в своей книге,
«в больших проектах сосуществует несколько моделей, и во многих случаях это прекрасно работает. Разные модели применяются в разных контекстах».
Как только Эванс установил, что сложная система, по сути, представляет собой набор моделей нескольких предметных областей, он сделал важный дополнительный шаг, введя понятие ограниченного контекста. В частности, он заявил, что:
«ограниченный контекст определяет диапазон применимости каждой модели».
Ограниченные контексты позволяют реализовывать и выполнять различные части более крупной системы, не искажая присутствующих в ней независимых моделей предметной области. После выявления ограниченных контекстов Эрик также любезно предоставил формулу определения оптимальных границ такого контекста, установив концепцию единого языка (ubiquitous language).
Чтобы понять значение единого языка, важно отметить следующее. Четко определенная модель предметной области в первую очередь обеспечивает общий словарь определенных терминов и понятий, общий язык для описания предметной области, который эксперты и инженеры разрабатывают совместно в тесном сотрудничестве, согласуя бизнес-требования и реализацию. Этот общий язык, или общий словарный запас, — то, что в DDD мы называем единым языком. Важность данного наблюдения заключается в признании, что одни и те же слова могут иметь разное значение в разных ограниченных контекстах. Классический пример этого показан на рис. 4.1. Термин account имеет существенно иное значение в контексте управления идентификацией и доступом, управления клиентами и финансового учета в системе онлайн-бронирования.

Действительно, в контексте управления идентификацией и доступом учетная запись (account) — это набор учетных данных, используемых для аутентификации и авторизации. В контексте управления клиентами аккаунт — это набор демографических и контактных данных, в то время как в контексте финансового учета — это платежная информация и список прежних транзакций. Мы можем видеть, что одно и то же базовое английское слово используется с принципиально разным значением в разных контекстах, и это нормально, поскольку нам нужно только согласовать единое значение терминов (единый язык) в ограниченном контексте конкретной модели предметной области. Согласно DDD, наблюдая границы, по которым термины меняют свое значение, можно определить границы контекстов.
В DDD не все термины, приходящие на ум при обсуждении модели предметной области, попадают в соответствующий единый язык. Концепции в ограниченном контексте, которые являются ключевыми для основной цели контекста, выступают частью единого языка команды; все остальные должны быть опущены. Эти основные понятия можно узнать из набора JTBD, который вы создаете для ограниченного контекста. В качестве примера посмотрим на рис. 4.2.
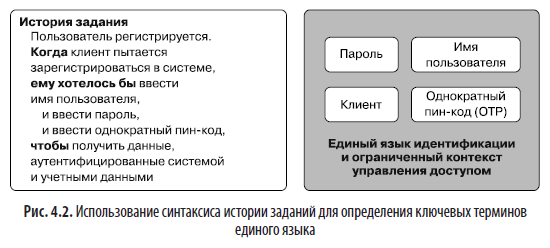
В этом примере мы используем формат истории заданий, представленный в главе 3, и применяем его к заданию из ограниченного контекста идентификации и управления доступом. Мы видим, что ключевые слова, выделенные на рис. 4.2, соответствуют терминам в едином языке. Мы настоятельно рекомендуем применять технику использования ключевых слов из историй заданий при определении словарных терминов, имеющих отношение к вашему единому языку.
Теперь, обсудив некоторые ключевые концепции DDD, перейдем к следующему разделу и рассмотрим кое-что, что может пригодиться при проектировании взаимодействий между микросервисами: составление карты контекста.
Составление карты контекста
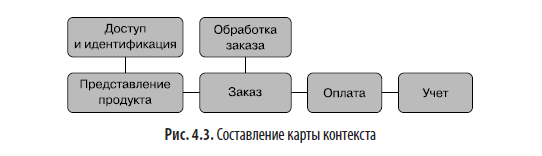
В DDD мы не пытаемся описать сложную систему с помощью одной модели предметной области. Скорее разрабатываем несколько независимых моделей, сосуществующих в системе. Эти подобласти обычно взаимодействуют, используя опубликованные описания интерфейса. Представление различных областей в более крупной системе и способов их взаимодействий называется картой контекста. Отсюда акт идентификации и описания указанных взаимодействий известен как составление карты контекста (рис. 4.3).
DDD определяет несколько основных типов взаимодействий в совместной работе при составлении карт ограниченных контекстов. Самый базовый тип известен как общее ядро (shared kernel). Оно возникает, когда две области разрабатываются практически независимо и в конце почти случайно перекрываются на некотором подмножестве точек друг друга (рис. 4.4). Две стороны могут договориться о совместной работе над этим общим ядром, которое может включать общий код и модель данных, а также описание предметной области.

Несмотря на то что на первый взгляд все выглядит заманчиво (в конце концов, стремление к сотрудничеству — один из человеческих инстинктов), общее ядро представляет собой проблемный шаблон, особенно в микросервисных архитектурах. По определению, общее ядро требует высокой степени координации между двумя независимыми командами при создании и продолжает требовать координации согласований для любых дальнейших модификаций. Добавление общих ядер в микросервисную архитектуру приводит к появлению множества точек координации. В тех случаях, когда общее ядро действительно необходимо в экосистеме микросервисов, рекомендуется назначить одну команду основным владельцем/куратором, а все остальные — участниками.
В качестве альтернативы два ограниченных контекста могут вступать в отношения, которые в DDD называются отношениями типа «вышестоящий — нижестоящий» (Upstream — Downstream). В этом типе отношений вышестоящий контекст действует как поставщик некоторой возможности, а нижестоящий — как потребитель. Поскольку определения предметной области и реализации не пересекаются, этот тип отношений дает более слабую связанность, чем общее ядро (рис. 4.5).
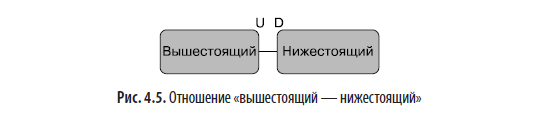
В зависимости от типа координации и связи, отношение «вышестоящий — нижестоящий» можно представить в нескольких формах.
- Клиент — поставщик. В этом сценарии вышестоящий контекст (поставщик) предоставляет функциональность нижестоящему (клиенту). Пока предоставляемая функциональность ценна, все довольны. Однако вышестоящий контекст несет накладные расходы, связанные с обратной совместимостью. При изменении вышестоящего сервиса (поставщика) необходимо убедиться, что эти изменения не нарушат работу клиента. Что еще более важно, нижестоящий контекст (клиент) рискует своей работоспособностью из-за того, что поставщик намеренно или непреднамеренно что-то повредит или проигнорирует будущие потребности клиента.
- Конформист. Такие отношения — крайний случай рисков для взаимодействия клиента и поставщика. Это разновидность сценария «вышестоящий — нижестоящий», когда поставщик явно не заботится о потребностях своего клиента или не может этого делать. Это взаимодействие типа «на свой страх и риск». Поставщик предоставляет некоторые ценные возможности, в которых заинтересован клиент, но, учитывая, что поставщик не будет удовлетворять его потребности, клиент должен постоянно подстраиваться под изменения в сервисе-поставщике.
Конформистские отношения часто возникают в крупных организациях и системах, когда гораздо более крупная подсистема используется более мелкой. Представьте, что вы разрабатываете небольшую новую функцию внутри системы бронирования авиабилетов и вам нужно использовать, скажем, корпоративную платежную систему. Такая крупная корпоративная система вряд ли уделит время какой-то небольшой новой инициативе, но и вы не можете реализовать всю платежную систему самостоятельно. Поэтому вам придется либо стать конформистом, либо использовать другое жизнеспособное решение, прибегнув к разделению путей. Последнее не всегда означает реализацию аналогичной функциональности. Платежные системы слишком сложны, и ни одной маленькой команде не под силу реализовать такую систему как побочную задачу для достижения другой цели. Но вы можете выйти за пределы своего предприятия и использовать услуги коммерческой платежной системы, если ваша компания это позволяет.
В дополнение к конформизму и разделению путей у нижестоящего контекста есть еще несколько санкционированных DDD способов защитить себя от небрежности сервиса-поставщика: слой предотвращения повреждений и использование поставщика, предлагающего интерфейсы с открытым протоколом.
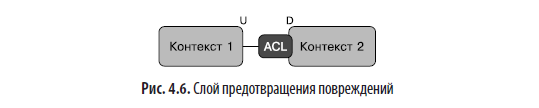
- Слой предотвращения повреждений. В данном сценарии клиент создает слой преобразования, называемый антикоррозийным или слоем предотвращения повреждений (anticorruption layer, ACL), между едиными языками, своим и поставщика, чтобы защитить себя от будущих критических изменений в интерфейсе поставщика. Создание ACL — эффективная и иногда необходимая мера защиты, но команды должны иметь в виду, что в долгосрочной перспективе она может быть довольно дорогостоящей для сервисов-клиентов (рис. 4.6).
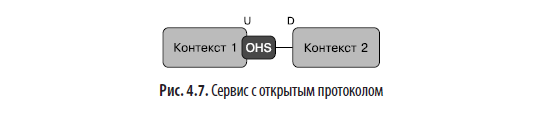
- Сервис с открытым протоколом (open host service, OHS). Допустим, поставщик знает, что его возможности могут использовать несколько разных клиентов. Тогда вместо того, чтобы пытаться координировать потребности своих многочисленных текущих и будущих потребителей, он может определить и опубликовать стандартный интерфейс, который все потребители должны будут принять. В DDD такие поставщики известны как сервисы с открытым протоколом. Предлагая открытый простой протокол для интеграции со всеми авторизованными сторонами и поддерживая обратную совместимость указанного протокола или обеспечивая четкое и безопасное управление его версиями, сервис с открытым протоколом может масштабировать свои операции без особых проблем. Практически все общедоступные сервисы (API) используют этот подход. Например, когда вы используете API поставщика общедоступных облачных сервисов (AWS, Google, Azure и т. д.), они обычно не знают и не обслуживают вас конкретно, поскольку у них миллионы клиентов, но могут предоставлять и развивать полезную услугу, работая как сервисы с открытым протоколом (рис. 4.7).
В дополнение к типам отношений между предметными областями карты контекстов также могут различаться типами интеграции между ограниченными контекстами.
Синхронные и асинхронные интеграции
Интерфейсы интеграции между ограниченными контекстами могут быть синхронными или асинхронными, как показано на рис. 4.8. Ни одна из моделей интеграции принципиально не предполагает того или иного стиля.
Типичными представителями модели синхронной интеграции между контекстами являются RESTful API, доступные через HTTP, сервисы gRPC, использующие двоичные форматы, такие как protobuf, и более новые сервисы, использующие интерфейсы GraphQL.
На асинхронной стороне лидируют взаимодействия типа «публикация — подписка». В этой модели взаимодействия поставщики могут генерировать некоторые события, а клиенты используют исполнителей (обработчиков) для обработки интересующих их событий, как показано на рис. 4.8.

Взаимодействия вида «публикация — подписка» сложнее в реализации и отладке, но они могут обеспечить превосходный уровень масштабируемости, устойчивости и гибкости, поскольку несколько получателей, даже реализованных с применением разных стеков технологий, могут подписываться на одни и те же события, используя единый подход и реализацию.
Чтобы завершить обсуждение ключевых концепций предметно-ориентированного проектирования, мы должны изучить концепцию агрегатов. Обсудим ее в следующем подразделе.
Агрегаты в DDD
В DDD агрегат — это набор связанных предметных объектов, которые внешние потребители могут рассматривать как единое целое. Эти внешние потребители ссылаются только на одну сущность в агрегате, известную в DDD как корень агрегата (aggregate root). Агрегаты позволяют предметным областям скрывать внутреннее устройство и предоставлять только ту информацию и возможности (интерфейс), которые «интересны» внешнему потребителю. Например, в отношениях «поставщик — клиент», обсуждавшихся выше, клиент не должен и, как правило, не захочет знать о каждом отдельном предметном объекте в поставщике. Вместо этого он будет рассматривать поставщика как агрегат или совокупность агрегатов.
Мы снова встретимся с понятием агрегата в следующем разделе, когда будем обсуждать Event Storming — эффективную методологию, значительно упрощающую процесс анализа предметной области и превращающую его в гораздо более быстрое и увлекательное упражнение.
Введение в Event Storming
Предметно-ориентированное проектирование — эффективная методология для анализа как общесистемного (называемого «стратегическим» в DDD), так и углубленного (называемого «тактическим») уровней больших и сложных систем. Мы также видели, что анализ DDD может помочь идентифицировать автономные подкомпоненты, слабосвязанные через ограниченные контексты соответствующих предметных областей.
Очень легко прийти к следующему выводу: чтобы научиться правильно определять размеры микросервисов, достаточно хорошо разбираться в анализе предметной области. Если мы заставим всю нашу компанию изучить и полюбить эту методологию (поскольку DDD, безусловно, командный вид спорта), то мы окажемся на пути к успеху!
На заре микросервисных архитектур DDD было настолько широко провозглашено единственным верным способом определения размера микросервисов, что их развитие также дало огромный толчок практике DDD, по крайней мере больше людей узнали об этом подходе к проектированию и ссылались на него. Внезапно многие докладчики заговорили о DDD на всевозможных конференциях по программному обеспечению и многие команды начали утверждать, что используют этот способ проектирования в повседневной работе. Увы, при ближайшем рассмотрении легко обнаружить, что реальность была несколько иной и DDD стало одним из подходов, о которых «много говорят, но мало практикуют».
Не поймите нас неправильно: были люди, которые прибегали к DDD задолго до появления микросервисов, и многие используют его и сейчас, но, говоря конкретно о его применении в качестве инструмента определения размера микросервисов, это было больше шумихой и пародией, чем реальностью.
Есть две основные причины, почему люди больше говорили о DDD, чем практиковали его всерьез, — это сложно и дорого. Чтобы применять DDD, нужны обширные знания и опыт. Оригинальная книга Эрика Эванса на эту тему насчитывает 520 страниц, и вам нужно прочитать как минимум еще несколько книг, чтобы действительно понять тему, не говоря уже о том, чтобы получить некоторый опыт практического применения этого способа на практике. Просто не хватало людей с необходимыми навыками и опытом, а кривая обучения была крутой.
Хуже того, как мы уже упоминали, DDD — командный вид спорта, к тому же требующий большого количества времени. Недостаточно иметь парочку технологов, хорошо разбирающихся в DDD. Вам также нужно убедить команды разработчиков продукта, проектирования и т. д. принять участие в длительных и насыщенных встречах для обсуждения предметной области, не говоря уже о том, чтобы объяснить им хотя бы основы того, чего вы пытаетесь достичь. Итак, по большому счету, стоит ли оно того? Скорее всего, да: особенно большим, рискованным и дорогим системам DDD может дать множество преимуществ. Однако если вы просто хотите быстро продвинуться в процессе разработки и изменить размер некоторых микросервисов и уже нажили свой политический капитал на работе, продавая всем новинку под названием «микросервисы», — желаем удачно убедить множество занятых людей дать вам достаточно времени, чтобы выбрать оптимальный размер для ваших сервисов! Этого просто не случится — слишком дорого и отнимет много времени.
А потом вдруг парень по имени Альберто Брандолини (https://oreil.ly/TiPOb), потративший десятилетия на поиск лучших способов совместной работы команд, нашел кратчайший путь! Он предложил увлекательный, легкий и недорогой процесс Event Storming, в значительной степени основанный на идеях DDD и способный помочь найти ограниченные контексты за считаные часы, а не недели или месяцы. Внедрение Event Storming стало прорывом и способствовало удешевлению применения DDD и, в частности, упрощению определения размера сервиса. Конечно, это не полная замена и она не дает всех преимуществ формального подхода DDD (в противном случае это было бы волшебно).
Но что касается выявления ограниченных контекстов с хорошим приближением — это действительно волшебно!
Event Storming — очень эффективный метод, помогающий идентифицировать ограниченные контексты домена упрощенным, увлекательным и эффективным способом, обычно намного быстрее, чем при использовании традиционной методологии DDD. Этот прагматичный подход снижает стоимость анализа DDD настолько, что делает его жизнеспособным в ситуациях, когда DDD было бы недоступно. Давайте посмотрим, как работает «магия» Event Storming.
КЛЮЧЕВОЕ РЕШЕНИЕ: ПРИМЕНЯТЬ EVENT STORMING ВМЕСТО ОФИЦИАЛЬНОГО DDD
Используйте более легкий процесс анализа событий вместо формального подхода DDD, чтобы выявить основные агрегаты в предметной области и провести границы различных ограниченных контекстов, присутствующих в вашей системе.
Процесс Event Storming
Красота Event Storming заключается в его гениальной простоте. Для проведения сеанса Event Storming вам понадобится очень длинная стена (желательно в физическом пространстве и чем длиннее, тем лучше), много принадлежностей, в основном стикеров и фломастеров, и 4–5 часов времени, уделенного представительными членами вашей команды. Для успешного проведения Event Storming крайне важно, чтобы участники были не только инженерами — существенное значение имеет участие представителей производства и бизнеса. Сеансы Event Storming также можно проводить виртуально, с помощью цифровых инструментов для организации совместной работы, которые могут имитировать физический процесс, описанный здесь.
Процесс проведения сеансов Event Storming вживую начинается с покупки расходных материалов. Чтобы упростить этот процесс для вас, мы создали список покупок на Amazon (https://oreil.ly/T7Y0i), включающий все, что мы используем в ходе сеансов Event Storming (рис. 4.9), в том числе следующее.
- Большое количество стикеров разных цветов, в первую очередь оранжевого и синего, а также нескольких других цветов для представления объектов различных типов. Вам понадобится действительно много таких стикеров. (В обычных магазинах их никогда не было в достаточном количестве, поэтому вошло в привычку покупать онлайн.)
- Рулон 12 мм белого бумажного скотча.
- Длинный рулон бумаги (например, бумага для рисования IKEA Mala), который будет вешаться на стену с помощью бумажного скотча. Лучше сделать несколько «дорожек».
- Маркеры, как минимум по количеству участников сеанса. У каждого должен быть собственный маркер!
- Мы уже упоминали длинную ровную стену, к которой можно приклеить рулон бумаги?

Во время сеансов Event Storming очень ценно широкое участие, например, экспертов в предметной области, владельцев продуктов и проектировщиков взаимодействий. Сеансы достаточно короткие (всего несколько часов, а не дни или недели, обычно уходящие на анализ). Учитывая ценность результатов сеансов, ясность, которую они вносят для всех представленных групп, и время, экономящееся в долгосрочной перспективе, это разумная трата времени для всех участников. Сеанс Event Storming, проводимый только с инженерами-программистами, по большей части бесполезен, поскольку происходит в ограниченном мирке и не может привести к межпредметным обсуждениям, необходимым для достижения желаемых результатов.
Итак, у нас есть расходные материалы, большая комната с длинной открытой стеной, к которой скотчем приклеен рулон бумаги, и все необходимые люди. Ведущий просит всех взять по несколько оранжевых стикеров и свой маркер. Затем дается простое задание: записать на оранжевых стикерах ключевые события анализируемой области (по одному событию на стикере), выраженные глаголами в прошедшем времени, и разместить эти стикеры вдоль временной шкалы на бумаге, приклеенной к стене, чтобы создать «дорожку» времени, как показано на рис. 4.10.

Участники не должны зацикливаться на точной последовательности событий, и на данном этапе от участников не требуется согласовывать между собой порядок событий. Единственное, что им предлагается, — чтобы каждый придумал как можно больше событий и поместил более ранние, по их мнению, левее, а более поздние — правее. В задачу участников не входит отсеивать дубликаты. По крайней мере пока. Этот этап обычно занимает от 30 минут до часа в зависимости от масштаба задачи и количества участников. Обычно, чтобы назвать мероприятие успешным, необходимо, чтобы было создано не менее 100 заметок о событиях.
На втором этапе сеанса группе предлагают взглянуть на заметки на стене и с помощью ведущего начать упорядочивать их по времени, попутно удаляя дубликаты. При наличии достаточного количества времени весьма желательно, чтобы участники начали создавать «сюжетную линию», расставляя события в порядке, создающем что-то вроде «пути потребителя». На данном этапе у команды могут возникнуть вопросы или противоречия, но мы должны не решить их немедленно, а просто зафиксировать с помощью стикеров разного цвета (обычно фиолетовых) как «спорные точки». На вопросы в «спорных точках» мы будем отвечать позднее. Этот этап также может занять от 30 до 60 минут.
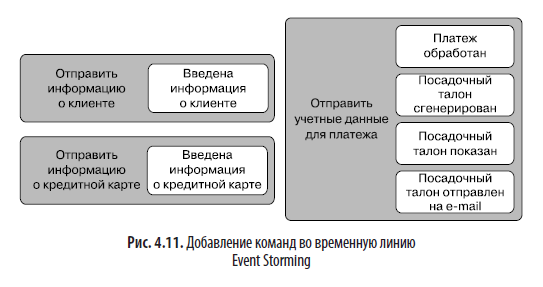
На третьем этапе создается то, что в Event Storming известно как обратное повествование. По сути, мы проходим временную шкалу от конца к началу и определяем команды — действия, вызвавшие события. Для обозначения команд используются стикеры другого цвета (обычно синего). На данном этапе ваша раскадровка может выглядеть примерно так, как показано на рис. 4.11.
Имейте в виду, что многие команды будут прямо связаны с событиями. Это может выглядеть как излишнее формулирование одного и того же в прошлом времени и в настоящем. И действительно, первые две команды на рис. 4.11 выглядят именно так. Это часто сбивает с толку людей, незнакомых с Event Storming. Просто не обращайте на это внимания! Мы не выносим суждений во время сеанса Event Storming, и хотя одни команды могут прямо соответствовать событиям, другие могут не иметь такого соответствия. Например, команда «Отправить учетные данные для платежа» запускает множество событий. Просто фиксируйте то, что, по вашему мнению, происходит в реальной жизни, и не старайтесь сделать все «красивым» или «аккуратным». В реальном мире, который вы моделируете, тоже много беспорядка.
На следующем этапе мы признаем, что команды не создают события напрямую. Их получают специальные типы предметных объектов и генерируют события. В Event Storming эти объекты называются агрегатами (да, название навеяно аналогичным понятием в DDD). На этом этапе мы перестраиваем наши команды и события, при необходимости нарушая упорядоченность во времени, чтобы сгруппировать команды вокруг агрегатов, в которые они отправляются, а события, «запущенные» этим агрегатом, поместить в него. Пример этого этапа Event Storming показан на рис. 4.12.
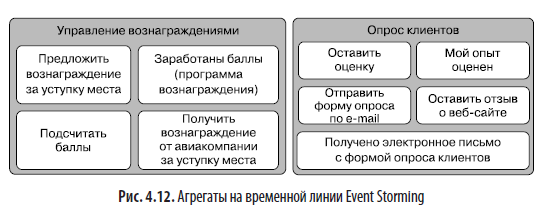
Этот этап сеанса может занять от 15 до 25 минут. По его завершении вы обнаружите, что стена теперь больше похожа на группы событий и команд вокруг агрегатов, а не на временну´ю шкалу событий. И представляете, эти кластеры являются ограниченными контекстами, которые мы искали.
Единственное, что осталось, — классифицировать различные контексты по уровню их приоритета (по аналогии с «корневыми», «вспомогательными» и «общими» контекстами в DDD). Для этого мы создаем матрицу ограниченых контекстов/подобластей и упорядочиваем их по двум свойствам: сложности и конкурентному преимуществу. В каждой категории мы используем размеры футболок (S, M или L) для упорядочения. В конце концов, принятие решения о том, когда вкладывать усилия, основывается на руководящих принципах, изложенных ниже.
1. Большое конкурентное преимущество/большие затраты усилий: эти контексты разрабатываются и внедряются собственными силами и на них тратится больше всего времени.
2. Небольшое преимущество/большие затраты усилий: покупаем!
3. Небольшое преимущество/небольшие затраты усилий: отличные задания для стажеров.
4. Другие комбинации как лотерея, и по ним решения должны приниматься коллегиально.
Последний этап, конкурентный анализ, не является частью первоначального процесса Event Storming Брандолини и был предложен Грегом Янгом для определения приоритетов предметных областей в DDD в целом. Мы считаем его полезной и забавной практикой, если к его выполнению подходить с юмором.
В целом процесс очень интерактивный, требущий участия всех присутствующих и обычно заканчивается весело. Чтобы все шло гладко, нужен опытный ведущий, но чтобы стать хорошим ведущим, не требуется прилагать столько же усилий, сколько необходимо, чтобы стать специалистом по ракетостроению (или экспертом по DDD). Прочитав эту книгу и проведя несколько пробных занятий для практики, вы сможете стать превосходным ведущим Event Storming!
Желательно, чтобы ведущий следил за временем и имел план сеанса. Для четырехчасового сеанса приблизительное распределение времени будет выглядеть следующим образом:
- этап 1 (~30 минут): определение событий предметной области;
- этап 2 (~45 минут): создание временно´й линии;
- этап 3 (~60 минут): обратное повествование и идентификация команд;
- этап 4 (~30 минут): определение агрегатов/ограниченных контекстов;
- этап 5 (~15 минут): конкурентный анализ.
Если вы заметили, что этапы выше в сумме дают меньше 4 часов, то имейте в виду, что в процессе вы должны будете сделать несколько перерывов для участников, а также оставить себе время для подготовки пространства и ознакомления участников с правилами.
Об авторах
Ронни Митра — автор книг, стратег и консультант с более чем 25-летним опытом работы с веб-технологиями и технологиями связи. Соавтор книг Microservice Architecture и Continuous API Management (обе изданы O’Reilly).
Иракли Надареишвили — вице-президент по основным инновациям в Capital One Financial Corporation, возглавляет команды, ответственные за создание современной облачной банковской платформы, основанной на микросервисах. Ранее был соучредителем и техническим директором медицинского стартапа ReferWell, а также занимал руководящие должности в CA Technologies и NPR. Соавтор книги Microservice Architecture (O’Reilly). Вы можете подписаться на Иракли в Твиттере: @inadarei.
Иракли Надареишвили — вице-президент по основным инновациям в Capital One Financial Corporation, возглавляет команды, ответственные за создание современной облачной банковской платформы, основанной на микросервисах. Ранее был соучредителем и техническим директором медицинского стартапа ReferWell, а также занимал руководящие должности в CA Technologies и NPR. Соавтор книги Microservice Architecture (O’Reilly). Вы можете подписаться на Иракли в Твиттере: @inadarei.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Микросервисы



