 Привет, Хаброжители! Когда дело доходит до выбора, использования и обслуживания базы данных, важно понимать ее внутреннее устройство. Как разобраться в огромном море доступных сегодня распределенных баз данных и инструментов? На что они способны? Чем различаются?
Привет, Хаброжители! Когда дело доходит до выбора, использования и обслуживания базы данных, важно понимать ее внутреннее устройство. Как разобраться в огромном море доступных сегодня распределенных баз данных и инструментов? На что они способны? Чем различаются?Алекс Петров знакомит нас с концепциями, лежащими в основе внутренних механизмов современных баз данных и хранилищ. Для этого ему пришлось обобщить и систематизировать разрозненную информацию из многочисленных книг, статей, постов и даже из нескольких баз данных с открытым исходным кодом.
Вы узнаете о принципах и концепциях, используемых во всех типах СУБД, с акцентом на подсистеме хранения данных и компонентах, отвечающих за распределение. Эти алгоритмы используются в базах данных, очередях сообщений, планировщиках и в другом важном инфраструктурном программном обеспечении. Вы разберетесь, как работают современные системы хранения информации, и это поможет взвешенно выбирать необходимое программное обеспечение и выявлять потенциальные проблемы.
В этой книге вы углубитесь в:
- Механизмы хранения: классификация и таксономия хранилищ, механизмы хранения на основе B-дерева и неизменяемые лог-структуры.
- Строительные блоки хранилища: организация файлов баз данных, позволяющая создавать эффективные хранилища с использованием вспомогательных структур (кэш страниц и пулы буферов).
- Распределенные системы: пошаговое руководство по подключению узлов и процессов и построение сложных схем взаимодействия.
- Кластеры баз данных: модели согласованности в современных базах данных и согласованность распределенных систем хранения.
Предисловие к русскому изданию
С детства я говорил на украинском и русском языках. Но ради того, чтобы как можно больше людей узнало о предмете настолько важном, как базы данных, я решил написать эту книгу на английском. Можете представить себе мой восторг, когда я узнал, что издательство «Питер», технические книги которого я помню еще с университетских лет, занимается переводом моей книги на русский.
Мы приложили все усилия для того, чтобы вы не только познакомились с устройством баз данных, но и могли использовать русский перевод книги как основу для дальнейшего изучения этой темы, и снабдили русские термины их английскими эквивалентами для того, чтобы помочь русскоязычному сообществу разработчиков баз данных стандартизировать терминологию.
Обнаружение отказов
Слышен ли звук падающего дерева в лесу, если рядом никого нет?
Неизвестный автор
Для того чтобы система надлежащим образом реагировала на отказы, их следует своевременно обнаруживать. Попытки установить связь с неисправным узлом могут продолжаться, даже если он продолжает не отвечать, увеличивая задержки и снижая общую доступность системы.
Обнаружить отказ в асинхронных распределенных системах (т. е. без каких-либо предположений о времени) чрезвычайно сложно, так как невозможно определить, произошло ли аварийное завершение процесса или он работает медленно, и для ответа требуется неопределенно много времени. Мы обсуждали эту проблему в разделе «Невозможность Фишера–Линча–Патерсона» на с. 207.
Такие определения, как «мертвый» (dead), «отказавший» (faulty) и «аварийно завершившийся» (crashed), обычно используются для описания процессов, которые полностью прекратили выполнение своих шагов. Такие определения, как «неотвечающий» (unresponsive), «неисправный» (faulty) и «медленный» (slow), используются для описания подозрительных процессов, которые на самом деле могут быть «мертвыми».
Отказы могут возникать на уровне канала (когда сообщения между процессами теряются или доставляются медленно) или на уровне процесса (когда процесс аварийно завершается или работает медленно); при этом медленное выполнение иногда невозможно отличить от отказа. Это означает, что всегда приходится находить компромисс между ошибочным отнесением активных процессов к числу отказавших (что ведет к получению ложноположительных результатов) и задержкой отнесения неотвечающих процессов к числу отказавших с предоставлением им возможности рано или поздно ответить (что ведет к получению ложноотрицательных результатов).
Детектор отказов (failure detector) — это локальная подсистема, отвечающая за выявление отказавших или недоступных процессов с целью исключить их из алгоритма и гарантировать его живучесть с сохранением безопасности.
Живучесть и безопасность — это свойства, которые отражают способность алгоритма решать конкретную проблему и корректность выдаваемых им результатов. Если выражаться более формально, свойство живучести (likeness) гарантирует, что произойдет конкретное предполагаемое событие. Например, в случае отказа одного из процессов детектор отказов должен обнаружить этот отказ. Свойство безопасности (safety) гарантирует, что не произойдут непредвиденные события. Например, если детектор отказов пометит процесс как «мертвый», этот процесс должен на самом деле быть «мертвым» [LAMPORT77] [RAYNAL99] [FREILING11].
С практической точки зрения исключение отказавших процессов помогает избежать выполнения лишней работы и предотвращает распространение отказов и каскадные отказы, одновременно снижая доступность за счет исключения подозрительных активных процессов.
Алгоритмы обнаружения отказов должны обладать несколькими неотъемлемыми свойствами. Прежде всего каждый свободный от неисправностей участник должен в конце концов заметить отказ процесса, а алгоритм должен быть в состоянии продолжить работу и в конечном итоге достичь своего целевого результата. Это свойство называется завершаемостью (completeness).
Качество алгоритма можно оценить по его эффективности, т. е. по тому, насколько быстро детектор отказов способен идентифицировать отказы процессов. Алгоритм также можно оценить по его точности, т. е. по тому, насколько точно выявляется отказ процесса. Другими словами, алгоритм не является точным, если он ошибочно относит активный процесс к числу отказавших или не способен обнаружить существующие отказы.
Мы можем рассматривать отношение между эффективностью и точностью как настраиваемый параметр: более эффективный алгоритм может быть менее точным, а более точный алгоритм обычно менее эффективен. Вероятно, невозможно создать детектор отказов, который будет и точным, и эффективным. В то же время детекторам отказов разрешается выдавать ложноположительные результаты (т. е. ложно идентифицировать активные процессы как отказавшие и наоборот) [CHANDRA96].
Детекторы отказов являются важным элементом и неотъемлемой частью многих алгоритмов достижения консенсуса и алгоритмов атомарной рассылки, которые мы обсудим позже в этой книге.
Многие распределенные системы реализуют детекторы отказов с применением контрольных пакетов (heartbeat). Этот подход довольно популярен из-за своей простоты и сильной завершаемости. Алгоритмы, которые мы здесь обсуждаем, предполагают отсутствие византийских ошибок: процессы не пытаются преднамеренно выдавать ложную информацию о своем состоянии или состояниях своих соседей.
Контрольные пакеты и эхо-запросы
Мы можем запрашивать состояние удаленных процессов, используя один из двух периодических процессов:
- Мы можем использовать эхо-запросы (ping), отправляя сообщения удаленным процессам и проверяя их активность путем ожидания ответа в течение определенного времени.
- Мы можем использовать контрольные пакеты: при этом процесс активно уведомляет одноранговые процессы о своей активности путем отправки им сообщений.
В следующем примере мы будем использовать эхо-запросы, но эту же задачу можно решить с аналогичными результатами и с помощью контрольных пакетов.
Каждый процесс поддерживает список других процессов (активных, отказавших и подозрительных) и обновляет его данными о времени последнего ответа для каждого процесса. Если процесс не отвечает на сообщение эхо-запроса в течение длительного времени, он помечается как подозрительный (suspected).
На рис. 9.1 показано нормальное функционирование системы: процесс P1 запрашивает состояние соседнего узла P2, который отвечает подтверждением.

На рис. 9.2 показан случай, когда подтверждения задерживаются, что может привести к отнесению активного процесса к числу неработающих.

Многие алгоритмы обнаружения отказов используют контрольные пакеты и время ожидания. Например, в популярном фреймворке для создания распределенных систем Akka реализован детектор отказов на основе лимита времени, который использует контрольные пакеты и уведомляет о сбое процесса, если тот не «отметился» в течение фиксированного интервала времени.
У этого подхода есть несколько потенциальных недостатков: его точность зависит от правильного выбора частоты отправки эхо-запросов и величины времени ожидания, и, кроме того, он не учитывает видимость процесса с точки зрения других процессов (см. подраздел «Сторонние контрольные пакеты» на с. 217).
Детектор отказов без времени ожидания
Некоторые алгоритмы не используют время ожидания для обнаружения отказов. Например, не использующий время ожидания детектор отказов на основе контрольных пакетов [AGUILERA97] представляет собой алгоритм, который просто подсчитывает контрольные пакеты и позволяет приложению выявлять отказы процессов на основе содержимого векторов счетчиков контрольных пакетов. Поскольку этот алгоритм не использует время ожидания, он работает исходя из допущений, свойственных асинхронной системе.
Этот алгоритм предполагает, что любые два корректных процесса должны быть связаны друг с другом посредством линии связи с «допустимыми потерями», которая содержит только каналы с допустимыми потерями (т. е. если сообщение передается по этому каналу бесконечное число раз, оно также принимается бесконечное число раз), и что каждый процесс осведомлен о существовании всех других процессов в сети.
Каждый процесс поддерживает список соседей и связанные с ними счетчики. Процессы начинают выполнение с отправки сообщений контрольных пакетов соседям. Каждое сообщение содержит информацию о том, по какому пути уже прошел контрольный пакет. Исходное сообщение содержит данные о первом отправителе в качестве пути и уникальный идентификатор, который можно использовать для исключения многократной отправки одного и того же сообщения.
Когда процесс получает новое сообщение контрольного пакета, он увеличивает счетчики для всех участников, присутствующих в пути, и отправляет контрольный пакет тем участникам, которые не указаны в пути, добавив в путь информацию о себе. Процессы прекращают распространение сообщения после того, как его получают все известные процессы (о чем говорит наличие идентификатора процесса в информации о пути).
Поскольку сообщения распространяются разными процессами и пути контрольных пакетов содержат агрегированную информацию, полученную от соседей, мы можем (корректно) пометить недоступный процесс как активный, даже если прямая связь между двумя процессами не работает.
Счетчики контрольных пакетов представляют собой общее и нормализованное представление системы. Это представление показывает, как контрольные пакеты распространяются относительно друг друга, что позволяет нам сравнивать процессы. Однако одним из недостатков этого подхода является то, что интерпретация счетчиков контрольных пакетов может оказаться довольно сложной: необходимо выбрать порог, способный обеспечить надежные результаты. В противном случае алгоритм будет ошибочно помечать активные процессы как подозрительные.
Сторонние контрольные пакеты
В протоколе SWIM [GUPTA01] используется альтернативный подход, который сводится к тому, чтобы использовать сторонние контрольные пакеты для повышения надежности за счет получения информации о жизнеспособности процесса с точки зрения его соседей. Этот подход не требует, чтобы процессы были осведомлены обо всех других процессах в сети, — достаточно иметь информацию лишь о некотором подмножестве подключенных одноранговых узлов.
Как показано на рис. 9.3, процесс P1 отправляет сообщение эхо-запроса процессу P2. Процесс P2 не отвечает на сообщение, поэтому процесс P1 продолжает, выбрав нескольких случайных участников (P3 и P4). Эти случайные участники пытаются отправить сообщения контрольных пакетов процессу P2 и, если он отвечает, направляют подтверждения обратно процессу P1.

Этот подход позволяет учитывать как прямую, так и опосредованную доступность. Например, если у нас есть процессы P1, P2 и P3, мы можем проверить состояние процесса P3 и со стороны процесса P1, и со стороны процесса P2.
Алгоритм сторонних контрольных пакетов позволяет надежно обнаруживать отказы, распределяя ответственность за принятие решений по группе участников. Этот подход не требует широковещательной рассылки сообщений большой группе процессов. Поскольку сторонние контрольные пакеты могут запускаться параллельно, с помощью этого подхода можно быстро собирать больше информации о подозрительных процессах и принимать более взвешенные решения.
Детектор отказа с накопленным уровнем подозрительности
Вместо того чтобы рассматривать отказ узла как бинарную задачу, где процесс может быть только в двух состояниях: работоспособном или неработоспособном, детектор отказа с накопленным фи (φ) (phi accrual failure detector) [HAYASHIBARA04] использует непрерывную шкалу, отражающую вероятность аварийного завершения отслеживаемого процесса. Такой детектор использует скользящее окно, собирая данные о времени поступления самых последних контрольных пакетов от других процессов. Эта информация используется для вычисления приблизительного времени поступления следующего контрольного пакета, дальнейшего сравнения этого значения с фактическим временем поступления и вычисления уровня подозрительности φ — степени уверенности детектора отказа в наличии отказа с учетом текущего состояния сети.
Данный алгоритм работает путем сбора и выборки данных о времени поступления с созданием представления, позволяющего надежно оценить работоспособность узла. На основе этих выборочных данных вычисляется значение φ, и если оно превышает некоторый порог, узел помечается как неработоспособный. Такой детектор отказов динамически адаптируется к изменяющимся условиям сети путем регулирования шкалы, используемой для выявления подозрительных узлов.
С точки зрения архитектуры детектор отказа с накопленным уровнем подозрительности можно рассматривать как комбинацию трех подсистем:
Мониторинг
Сбор информации о живучести с помощью эхо-запросов (ping), контрольных пакетов или выборочных данных о запросах и ответах.
Интерпретация
Принятие решения о том, должен ли процесс быть помечен как подозрительный.
Действие
Ответный вызов, выполняемый всякий раз, когда процесс помечается как подозрительный.
Процесс мониторинга собирает и сохраняет выборки данных (которые, как предполагается, следуют нормальному распределению) в фиксированного размера окне времен поступления контрольных пакетов. Новые поступления добавляются в окно, а самые старые элементы данных о контрольных пакетах отбрасываются.
Параметры распределения оцениваются на основе окна выборки путем определения среднего значения и дисперсии выборок. Эта информация используется для вычисления вероятности поступления сообщения в течение t единиц времени после поступления предыдущего. На основе этой информации мы вычисляем показатель φ, отражающий вероятность принятия верного решения об активности процесса, или, иначе говоря, вероятность того, что мы допустим ошибку и получим контрольный пакет, не согласующийся с проведенными расчетами.
Этот подход разработан исследователями из Японского передового института науки и техники (JAIST) и в настоящее время используется во многих распределенных системах, например в системах Cassandra и Акка (как и вышеупомянутый детектор отказов на основе лимита времени).
Сплетни и обнаружение отказов
Другим подходом, который при принятии решения не полагается на представление с точки зрения одного узла, является служба обнаружения отказов со сплетнями [VANRENESSE98], которая использует механизм «сплетен» (см. раздел «Распространение сплетен» на с. 268) для сбора и распространения информации о состоянии соседних процессов.
Каждый участник поддерживает список других участников с соответствующими счетчиками контрольных пакетов и временными метками, отражающими время последнего увеличения счетчика контрольных пакетов. Периодически каждый участник увеличивает свой счетчик контрольных пакетов и отправляет свой список случайному соседу. После получения сообщения соседний узел объединяет принятый список со своим собственным, обновляя счетчики для других соседей.
Кроме того, узлы периодически проверяют список состояний и счетчики контрольных пакетов. Если какой-либо узел не обновлял свой счетчик достаточно долго, он считается отказавшим. Необходимо тщательно подбирать величину этого периода ожидания, чтобы минимизировать вероятность получения ложноположительных результатов. Частота обмена сообщениями между участниками (т. е. пропускная способность в наихудшем случае) не должна быть больше некоторого предела и может возрастать не быстрее линейной зависимости от количества процессов в системе.
На рис. 9.4 показано, как три процесса могут обмениваться данными о своих счетчиках контрольных пакетов:
а) Все три процесса могут обмениваться сообщениями и обновлять свои временные метки.
б) Процесс P3 не может связаться с процессом P1, но его временная метка t6 по-прежнему может распространяться через процесс P2.
в) Произошло аварийное завершение процесса P3. Поскольку он больше не отправляет обновления, он распознается другими процессами как отказавший.
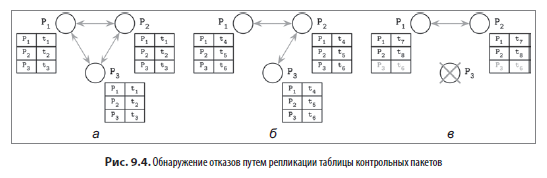
Таким образом, мы можем выявлять отказавшие узлы, а также узлы, недоступные ни одному другому участнику кластера. Принимаемое решение является надежным, поскольку представление кластера представляет собой агрегат данных, получаемых от нескольких узлов. При сбое канала между двумя хостами контрольные пакеты все равно могут распространяться через другие процессы. Использование механизма сплетен для распространения состояний системы увеличивает количество сообщений в системе, но позволяет распространять информацию более надежно.
Обратный взгляд на проблему обнаружения отказов
Поскольку распространение информации об отказах не всегда возможно, а ее распространение путем уведомления каждого участника может оказаться затратным, один из подходов, называемый FUSE (служба уведомления о сбоях, failure notification service) [DUNAGAN04], ставит целью обеспечение надежного и незатратного распространения информации об отказах, которое будет работать даже в случае распада сети.
Для обнаружения отказов процессов этот подход объединяет все активные процессы в группы. Если одна из групп становится недоступной, все участники обнаруживают отказ. Другими словами, каждый раз, когда обнаруживается отказ одного процесса, он преобразуется и распространяется как групповой отказ. Это позволяет обнаруживать отказы при наличии любой схемы потери соединения, распадов сети и отказов узлов.
Процессы в группе периодически отправляют сообщения эхо-запросов (ping) другим участникам с целью выяснить, являются ли они по-прежнему активными. Если один из участников не может ответить на это сообщение из-за отказа, распада сети или сбоя соединения, то участник, инициировавший эхо-запрос, в свою очередь, сам перестает отвечать на сообщения эхо-запросов.
На рис. 9.5 показано, как могут обмениваться данными четыре процесса:
а) Исходное состояние: все процессы активны и могут обмениваться сообщениями.
б) Процесс P2 аварийно завершается и перестает отвечать на сообщения эхо-запросов.
в) Процесс P4 обнаруживает отказ процесса P2 и перестает отвечать на сообщения эхо-запросов.
г) В конечном итоге процессы P1 и P3 замечают, что процессы P1 и P2 не отвечают, и отказ процесса распространяется на всю группу.

Все отказы распространяются через систему от источника отказа ко всем остальным участникам. Участники постепенно прекращают отвечать на сообщения эхо-запросов, превращая отказ отдельного узла в групповой отказ.
Здесь мы используем отсутствие связи как средство распространения. Преимущество этого подхода заключается в том, что каждый участник гарантированно узнает о групповом отказе и адекватно отреагирует на него. Одним из недостатков является то, что отказ канала, отделяющий один процесс от других процессов, также может быть преобразован в групповой отказ, но, в зависимости от сценария использования, это может рассматриваться и как преимущество. Приложения могут принять в расчет такой сценарий, используя собственные определения распространяющихся отказов.
Итоги
Детекторы отказов являются неотъемлемой частью любой распределенной системы. Как видно из теоремы Фишера–Линча–Патерсона, ни один протокол не в состоянии гарантировать консенсус в асинхронной системе. Детекторы отказов помогают дополнить модель, позволяя нам решить проблему консенсуса за счет компромисса между точностью и завершаемостью. Одно из важных открытий в этой области, доказывающее полезность детекторов отказов, было описано в источнике [CHANDRA96], в котором показано, что достижение консенсуса возможно даже с детектором отказов, который совершает бесконечное количество ошибок.
Мы рассмотрели несколько алгоритмов обнаружения отказа, каждый из которых использует свой подход: некоторые фокусируются на обнаружении отказов путем прямого обмена сообщениями, некоторые используют широковещательную рассылку или механизм сплетен для распространения информации, а некоторые, наоборот, используют бездействие (другими словами, отсутствие связи) как средство распространения. Теперь мы знаем, что можем использовать контрольные пакеты или эхо-запросы (ping), жесткие временные рамки или непрерывную шкалу. Каждый из этих подходов имеет свои преимущества: простоту, безошибочность, или точность.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Алгоритмы
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Поделиться ссылкой:
Интересные статьи
Интересные статьи

Здравствуйте! В этой статье, я постараюсь кратко рассказать о четырёх достаточно известных способах хранения деревьев с указанием преимуществ и недостатков. На идею напис...

Недавно на Хабре вышли две статьи про новую корпоративную почтовую систему Mailion от МойОфис (1, 2) — уникальную российскую разработку, которая отличается беспрецедентны...

Утилита awk — это нечто вроде швейцарского ножа для обработки текстовых файлов. Но некоторые ограничения awk порой доставляют неудобства тем, кто этой утилитой пользуется. Я, для того что...
Привет.
Если ты программист — все человеческое тебе не чуждо.
И, скорее всего, ты сталкивался с вопросами саморазвития и повышения собственной эффективности как в профессиональном так и в лично...

Одной из «киллер-фич» 12й версии Битрикса была объявлена возможность отдавать статические файлы из CDN, тем самым увеличивая скорость работы сайта. Попробуем оценить практический выигрыш от использова...