
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
 Привет, Хаброжители!
Привет, Хаброжители!Создание программных продуктов всегда связано с компромиссами. В попытках сбалансировать скорость, безопасность, затраты, время доставки, функции и многие другие факторы можно обнаружить, что вполне разумное дизайнерское решение на практике оказывается сомнительным. Советы экспертов и яркие примеры, представленные в этой книге, научат вас делать правильный выбор в дизайне и проектировании приложений.
Мы будем рассматривать реальные сценарии, в которых были приняты неверные решения, а затем искать пути, позволяющие исправить подобную ситуацию. Томаш Лелек и Джон Скит делятся опытом, накопленным за десятки лет разработки ПО, в том числе рассказывают о собственных весьма поучительных ошибках. Вы по достоинству оцените конкретные советы и практические методы, а также неустаревающие паттерны, которые изменят ваш подход к проектированию.
Для кого эта книга
Книга предназначена для разработчиков, которые хотят изучить паттерны, используемые в реальных системах, и связанные с ними компромиссы. Также она учит избегать неочевидных ошибок. Книга начинается с низкоуровневых решений, что очень полезно для начинающих разработчиков. Затем рассматриваются более сложные темы — это пригодится даже опытному специалисту. Большинство примеров, паттернов и фрагментов кода написаны на Java, но сами решения не привязаны к этому языку.
Код потребителя и разные семантики доставки
После того как данные будут успешно сохранены в структуре топика, доступной только для присоединения, код потребителя Kafka сможет загрузить его. Так как для топиков можно настроить время удержания, события с самыми старыми смещениями удаляются по истечении этого времени. Время удержания может быть бесконечным; в этом случае старые события вообще не будут удаляться. Начнем с примера кода потребителя.
При настройке потребителя также необходимо передать список брокеров Kafka. Как вы, возможно, помните, компонент производителя должен использовать сериализатор для преобразования объекта в массив байтов. Потребитель должен провести обратное преобразование: из байтов в объекты. Следовательно, необходимо предоставить классы десериализаторов пар «ключ-значение». Каждый потребитель работает внутри группы, поэтому также необходимо передать идентификатор группы, который будет использоваться потребителем.
Важно понимать, что смещения топика Kafka отслеживаются конкретной группой потребителей. Это означает, что при чтении потребителем пакетов событий из топика смещение должно быть зафиксирован, указывая на корректную обработку событий. В случае сбоя другой потребитель из группы может возобновить обработку от последнего зафиксированного смещения.
Способ фиксации и возобновления обработки влияет на семантику доставки, предоставляемую приложением-потребителем. Начнем с простейшего случая, в котором потребитель Kafka автоматически фиксирует смещения за нас. Того же эффекта можно добиться, присвоив enable.auto.commit (http://mng.bz/ZzgR) значение true, как показано в следующем листинге.
Листинг 11.3. Настройка потребителя Kafka
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
IntegerDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "receiver");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
return props;
}Эта конфигурация может использоваться для создания потребителя Kafka. Потребитель может работать для N топиков и может совместно использоваться между потоками. Только не забудьте подписаться на топик, информация которого должна потребляться, как показано в следующем листинге.
Листинг 11.4. Создание потребителя Kafka с автоматической фиксацией

Метод startConsuming() в цикле вызывает метод poll() потребителя и ожидает результата в течение 100 мс. Этот метод возвращает пакет записей, который должен быть обработан. Каждая запись содержит ключи и значения, а также информацию отслеживания — например, топик и раздел. Метод offset() возвращает точное смещение конкретной записи в разделе заданного топика. Наконец, мы перебираем пакет записей и обрабатываем каждую из них.
Когда потребитель работает в режиме автофиксации, он закрепляет смещения в фоновом режиме каждые N мс в соответствии с настройкой auto.commit.interval.ms (http://mng.bz/REnZ), которая по умолчанию равна 5 с.
Представьте, что ваше приложение обрабатывает 100 событий в секунду, как показано на рис. 11.11. Допустим, они поступили пятью пакетами. В таком сценарии смещение фиксируется после обработки 500 событий. Если сбой в приложении происходит менее чем за 5 с, смещение не фиксируется. Тогда последнее известное смещение для этой обработки равно 0.
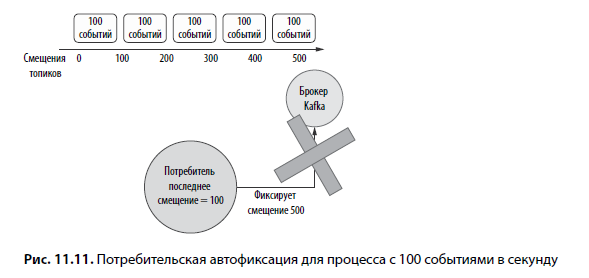
Если другой потребитель в этой группе возобновляет обработку из-за сбоя, он видит, что последнее фиксированное смещение равно 0. Он опрашивает 500 событий, которые, возможно, уже были обработаны потребителем с предшествующим сбоем, а это означает вероятность обработки 500 дублированных событий. Это пример семантики доставки «не менее одного». Наш потребитель может получить событие один раз в случае успешной фиксации. Но если фиксация не будет успешной, то другой потребитель снова обработает данные.
11.4.1. Ручная фиксация у потребителя
Положение дел можно поправить за счет использования ручной фиксации. Сначала необходимо отключить автофиксацию, присвоив параметру значение false, как показано в следующем листинге:
Листинг 11.5. Отключение автофиксации
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");После этого потребитель уже не фиксирует смещения автоматически. Эта обязанность теперь возлагается на вас. Самое важное решение, которое необходимо принять, — фиксировать смещения при входе в систему или после обработки. Если вы хотите поддерживать семантику доставки «не менее одного», смещение должно фиксироваться после логики обработки. Тем самым гарантируется, что сообщение его успешной обработки будет помечено как зафиксированное. Процесс показан в следующем листинге.
Листинг 11.6. Синхронная фиксация

В листинге 11.6 для достижения цели используется метод commit(). Он фиксирует смещения всех разделов, назначенных этому конкретному потребителю. Важно заметить, что метод commit() является блокирующим. Это означает, что обработка продолжится только после фиксации смещений. Хотя такой подход обеспечивает безопасность, он может повлиять на общую производительность нового решения, так что операция commit() может оказаться весьма затратной.
Если эти затраты неприемлемы, можно воспользоваться методом commitAsync(), который не блокирует обрабатывающий поток. Однако при асинхронной фиксации необходимо внимательно следить за обработкой ошибок, потому что исключения не распространяются в основной поток вызывающей стороны. Реализация с commitAsync() приведена в следующем листинге.
Листинг 11.7. Асинхронная фиксация
consumer.commitAsync(
(offsets, exception) -> {
if (exception != null) LOGGER.error(
➥ "Commit failed for offsets {}", offsets, exception);
});Иногда асинхронная фиксация завершается ошибкой, но фиксация для последующего пакета событий проходит успешно. В таком сценарии это никак не повлияет на работу системы, потому что правильное смещение, зафиксированое последующим действием, было сохранено.
Рассмотрим ситуацию, в которой требуется зафиксировать смещения перед тем, как логика обработает события. В таком случае сбой в логике обработки пройдет незамеченным для брокера Kafka. Смещение уже закреплено, поэтому, когда логика потребителя возобновит обработку, предыдущий пакет не будет обработан заново.
Если метод logicProcessing() не завершится успешно, некоторые события не будут обработаны. В этом случае возникает риск потери событий. В такой системе действуют гарантии доставки «не более одного». Одно событие будет обработано только один раз (но существует вероятность, что оно не будет обработано ни разу).
11.4.2. Перезапуск от самых ранних или поздних смещений
Существует и второй аспект, влияющий на гарантии доставки приложений-потребителей. Рассмотрим сценарий с топиком из 10 записей (а следовательно, с 10 смещениями). Клиентское приложение получает все записи из пакета. Пакет может содержать от 1 до 10 событий и фиксировать смещение, равное N (любое число от 0 до 10, равное количеству событий в пакете). К сожалению, на этапе фиксации в приложении происходит сбой. В этом случае мы не знаем, сколько событий обработало приложение-потребитель. На это может влиять много факторов, включая тайм-аут пула потребителей, размер пакета и т.д. Когда приложение перезапускается, возможны два варианта возобновления обработки.
В таком сценарии обеими стратегиями возобновления обработки управляет параметр auto.offet.reset (http://mng.bz/2jqg). Если ему присваивается значение earliest, возобновление обработки событий начнется с последнего зафиксированного смещения для разделов топика (если оно есть). Если смещения нет, повторная обработка всех событий начинается заново. Эта стратегия проиллюстрирована на рис. 11.12.
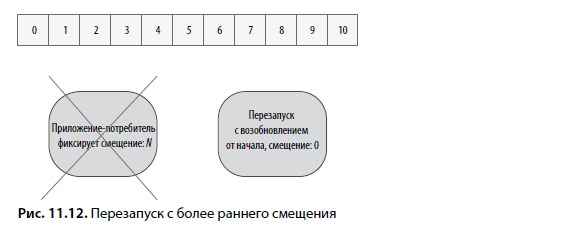
В этой ситуации у приложения-потребителя могут появиться дубликаты. Дело в том, что сбои логики потребителя могут произойти в любой момент во время обработки последующих записей. При одном перезапуске можно получить до 20 дубликатов (2 × 10 событий). Такая стратегия сброса смещений обеспечивает семантику доставки «не менее одного».
За этой стратегией можно понаблюдать в интеграционном тесте. В этом тесте мы передадим потребителю Kafka значение OffsetResetStrategy.EARLIEST, как показано в следующем листинге.
Листинг 11.8. Тестирование стратегии возврата к самому раннему смещению

После отправки 10 событий, запуска потребителя и отправки еще 10 событий можно проверить количество полученных записей. Здесь потребитель получает все 20 событий, опубликованные производителем.
Также можно выбрать стратегию последнего смещения. С этой стратегией возобновление обработки после сбоя начинается с последнего смещения для этого топика. В нашем сценарии приложение начинает со смещения 10 или выше. Данный сценарий актуален, если производитель добавляет новые события. Эта стратегия показана на рис. 11.13.
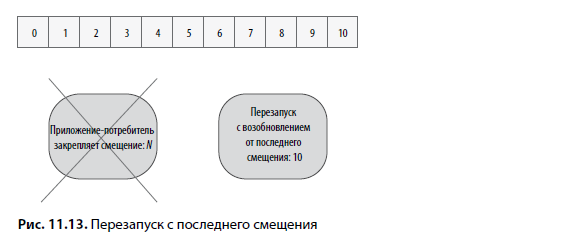
В этом сценарии приложение может потерять некоторые события, доставленные до сбоя. Возможно, они были доставлены, но не обработаны. В нем также не будет дубликатов, но возможна потеря событий. Использование стратегии последнего смещения предоставляет гарантию доставки «не более одного».
Логика тестирования похожа на ту, что была использована в предыдущем примере. Сначала мы создаем потребителя Kafka со стратегией OffsetResetStrategy.LATEST, как показано в листинге 11.9. Передавать этот параметр не обязательно, потому что это значение используется в Kafka по умолчанию; здесь оно передается для полной ясности и выражения намерений. Потребитель создается для случайного идентификатора группы (чтобы начать с несуществующего смещения), и смещения не фиксируются автоматически. Затем мы отсылаем 10 сообщений в топик Kafka. После того как сообщения будут отправлены, можно запустить потребителя Kafka. Когда он будет запущен, передаются следующие 10 сообщений.
Листинг 11.9. Тестирование стратегии возврата к последнему смещению

Возможно, вы заметили, что потребитель Kafka получил 10 событий. События, опубликованные до запуска потребителя, не учитываются этим потребителем.
Этот интеграционный тест похож на предыдущий. У обеих ситуаций есть свои плюсы и минусы и свои сценарии применения. Если в вашей области задержки критичны и необходимо реагировать на последние события, вариант с возобновлением с последнего смещения может подойти. Например, для системы оповещения могут не представлять интереса события, доставленные минуты назад. Реагирование на устаревшие данные не принесет пользы. С другой стороны, если ваша система критична к правильности информации, следует обрабатывать все события и защищаться от дубликатов. Например, если в платежной системе произойдет сбой, необходимо возобновить обработку с точки сбоя и обработать все незавершенные платежи.
11.4.3. Семантика «фактически ровно один»
Построить систему, предоставляющую гарантию «ровно один», сложно. До сих пор мы представили две возможные семантики доставки: «не менее одного» и «не более одного». Если логика системы неидемпотентна и никакие события не должны теряться, необходима разновидность семантики «ровно один».
На практике системы, предоставляющие семантику «фактически ровно один», часто строятся на базе семантики доставки «не менее одного». Вы узнали в предыдущей главе, что реализация логики дедупликации может предоставить разновидность семантики «фактически ровно один». Мы говорим фактически, потому что на каком-то уровне события могут дублироваться. Например, они могут дублироваться логикой повторных попыток на стороне производителя. В этом случае такие дубликаты скрываются от системы, которая ожидает ровно однократной доставки.
Apache Kafka формирует семантику «фактически ровно один», реализуя разновидность распределенных транзакций. В архитектуре Kafka дубликаты могут существовать на уровнях как производителя, так и потребителя. По умолчанию производитель также может получать дубликаты при перезапуске из-за поведения закрепления смещений, описанного в разделе 11.4.
Для решения этой проблемы Apache Kafka применяет транзакции. Они начинаются на стороне производителя до отправки нового события в топик Kafka. При этом идентификатор транзакции transactional_id (http://mng.bz/1jPX) используется для обеспечения семантики «фактически ровно один» в пределах транзакции. Каждой записи назначается идентификатор транзакции. В случае сбоя при отправке операция отменяется и Kafka гарантирует, что заданная запись не будет присутствовать в топике Kafka. Можно сделать повторную попытку с другой транзакцией. Тем не менее транзакция только охватывает логику внутри заданного производителя Kafka. Если логика производителя в сервисе базируется на внешнем событии (получаемом от другого кластера Kafka или из HTTP), все равно можно получить дубликат.
Событие, инициирующее отправку производителем, может доставляться с семантикой гарантий «не менее одного» (рис. 11.14). Если система, использующая транзакции Kafka, не защищается от таких дубликатов, эти события рассматриваются производителем как два независимых события.
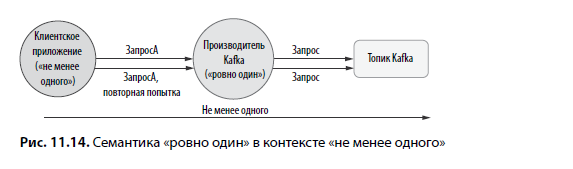
Предположим, что клиентское приложение не реализует транзакции и предоставляет семантику доставки «не менее одного». В случае сбоя оно может повторить попытку запроса. Приложение, логика которого основана на этом клиентском событии, использует транзакции производителя Kafka для предоставления семантики «фактически ровно один». Важно заметить, что при этом отсутствует защита от дубликатов.
С точки зрения приложения-производителя Kafka запросы различны. Если механизм дедупликации не реализован, невозможно определить, являются ли запросы дубликатами. Затем запросы доставляются с использованием транзакций, и оба — с гарантиями «фактически ровно один». Тем не менее с позиций логики системы одно событие было отправлено Kafka дважды (оба события являются дубликатами). Следовательно, на логическом уровне действует гарантия доставки «не менее одного».
Очевидно, семантика «фактически ровно один» может работать, но только в том случае, если она поддерживается всеми компонентами бизнес-процесса приложения. На практике она может содержать N стадий обработки, взаимодействия и обмена данными по системе pub-sub, протоколу HTTP или другому механизму. Это будет означать, что весь конвейер должен быть заключен в одну транзакцию. Такое решение может оказаться непрочным и не отказоустойчивым. В случае сбоя на какой-либо из стадий может оказаться, что бизнес-процесс не сможет продолжать выполнение без ручного вмешательства оператора для исправления нарушенной транзакции.
Если вы хотите использовать в приложении семантику «фактически ровно один», будьте внимательны с его производительностью и доступностью. Решение об использовании этого механизма необходимо принимать на основе результатов тщательного тестирования производительности и хаотического тестированияпродукта. В следующем разделе мы покажем, как применить семантику доставки Kafka для улучшения отказоустойчивости системы.
Об авторах
Томаш Лелек
За свою карьеру разработчика Томаш имел дело с разными сервисами, архитектурами и языками программирования (прежде всего для JVM). У него есть реальный опыт работы с монолитными и микросервисными архитектурами. Томаш проектировал системы, обрабатывающие запросы десятков миллионов уникальных пользователей и сотни тысяч операций в секунду. В частности, он работал над следующими проектами:
Сейчас Томаш работает в Dremio, где помогает создавать современные решения для хранения данных. До этого он работал в DataStax, где строил различные продукты для Cassandra Database. Он создавал инструменты для тысяч разработчиков, которые больше всего ценят проектирование API, производительность и удобство UX. Он внес свой вклад в разработку Java-Driver, Cassandra Quarkus, соединителя Cassandra-Kafka и Stargate.
Джон Скит
Джон — специалист по выстраиванию отношений с разработчиками в Google, в настоящее время работающий над библиотеками Google Cloud Client Libraries для .NET. Его вклад в сообщество с открытым кодом включает библиотеку даты и времени Noda Time для .NET (https://nodatime.org). Вероятнее всего, он известен благодаря своим публикациям на сайте Stack Overflow. Джон — автор книги «C# in Depth» (издательство Manning). Также он участвовал в работе над книгами «Groovy in Action» и «Real-World Functional Programming». Джон интересуется API даты/времени и версионированием — многим эти увлечения кажутся в лучшем случае необычными.
За свою карьеру разработчика Томаш имел дело с разными сервисами, архитектурами и языками программирования (прежде всего для JVM). У него есть реальный опыт работы с монолитными и микросервисными архитектурами. Томаш проектировал системы, обрабатывающие запросы десятков миллионов уникальных пользователей и сотни тысяч операций в секунду. В частности, он работал над следующими проектами:
- Микросервисная архитектура с CQRS (на базе Apache Kafka).
- Автоматизация маркетинга и обработка потоков событий.
- Обработка больших данных в Apache Spark и Scala.
Сейчас Томаш работает в Dremio, где помогает создавать современные решения для хранения данных. До этого он работал в DataStax, где строил различные продукты для Cassandra Database. Он создавал инструменты для тысяч разработчиков, которые больше всего ценят проектирование API, производительность и удобство UX. Он внес свой вклад в разработку Java-Driver, Cassandra Quarkus, соединителя Cassandra-Kafka и Stargate.
Джон Скит
Джон — специалист по выстраиванию отношений с разработчиками в Google, в настоящее время работающий над библиотеками Google Cloud Client Libraries для .NET. Его вклад в сообщество с открытым кодом включает библиотеку даты и времени Noda Time для .NET (https://nodatime.org). Вероятнее всего, он известен благодаря своим публикациям на сайте Stack Overflow. Джон — автор книги «C# in Depth» (издательство Manning). Также он участвовал в работе над книгами «Groovy in Action» и «Real-World Functional Programming». Джон интересуется API даты/времени и версионированием — многим эти увлечения кажутся в лучшем случае необычными.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Software



