
Аутентификация и авторизация — неисчерпаемые бесконечные темы. И как раз именно про них всегда забывают на старте разработки. У нас MVP и обойдемся без всех этих сложностей. Именно на этом умирает огромное количество хороших начинаний в крупных компаниях, поскольку масштабирование от лабораторного проекта до промышленной среды - самая сложная часть в любом проекте. Под катом история нашей эволюции от «авторизовался в ДБО — доверяем!» до «а у вас нет доступа к данным при этом значении атрибута», расширения GraphQL и прочая магия в популярном изложении.
Предыстория, или как мы стали платформой
Несколько лет назад (это были времена, когда логика создания продукта была сосредоточена вокруг его развития в каждом канале) мы сидели небольшой командой разработчиков и «пилили» свой уютный интернет-банк. Вроде бы даже неплохо получалось, но маятник качнулся в другую сторону.
В определенный момент стало понятно, что синхронизация развития продуктов в разных каналах требует определенного количества ресурсов, а клиентский путь по одной услуге может развиваться в нескольких каналах параллельно.
Например:
Звонок с предложением услуги из контакт-центра;
Заполнение заявки на сайте или в мобильном приложении;
Заключение сделки в отделении.
Такое развитие CJM обусловило необходимость иметь контекст пользователя и клиента. Для приложения в целом было принято решение сосредоточить логику создания и сопровождения продуктов в едином слое, к которому обращались множество фронтов. Этот слой был назван Digital Platform.
Первые шаги по созданию авторизации
Среди прочих проблем, которые возникли при создании платформы, таких как организация процессов разработки и поставки, о которых ранее мы уже рассказывали, встал и вопрос организации доступа к сервисам Digital Platform. Немало копий было сломано в ходе обсуждения, как именно это реализовать, и далеко не с первой попытки мы пришли к текущему решению.
Субъекты можно было группировать по каналу, из которого они получали доступ. И организовать схему доступа вокруг этого. Когда-то мы именно так и делали. Выглядело это так: множество бэковых систем накрывается неким фасадом — API Gateway, где происходит аутентификация пользователей, которые, в свою очередь, обращаются к нему с фронта. Запросы от API Gateway поступают к бэковым сервисам и считаются доверенными (никакой авторизации на бэковых сервисах нет). Различные компоненты системы при таком подходе обычно размещаются в различных сегментах сети, как изображено на рисунке.
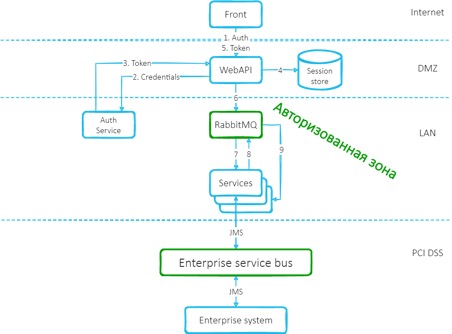
Такой подход имеет право на существование, хотя и обладает рядом минусов, среди которых можно выделить:
Разграничение доступа на уровне инфраструктуры
При добавлении новых компонентов системы приходится производить дополнительные настройки сети, чтобы разрешить к ним доступ.
Другие команды из доверенных сегментов могут все
Так как на самих сервисах нет никакой аутентификации, любой вызов из нашего сегмента сети может произойти ко всем сервисам и выполнить любую операцию. Мы столкнулись с этой проблемой, когда предоставили доступ нашим коллегам внутри организации, которые занимались развитием других систем. Они начали вызывать совсем не те операции, на которые изначально запросили доступ.

Нам пришлось писать для них отдельный адаптер и контролировать доступ к сервисам нашей системы через него.
Отсутствие разграничения доступа к операциям сервиса
Так как авторизация на сервисах отсутствует, мы имеем потенциальную дыру в безопасности. Если скомпрометировать API Gateway (а их потенциально может быть несколько, для каждого фронта свой шлюз) или какой-то компонент из внутреннего сегмента сети, то будет получен полный доступ к множеству сервисов.
Непонятно, кто инициатор сообщения
При разборе проблем и раскопках в логах конкретного сервиса было непонятно, кто его вызывал. Каждый раз приходилось раскручивать цепочку запросов до самого начала, что было весьма трудозатратно и утомительно.
При чем тут GraphQL
Проекции
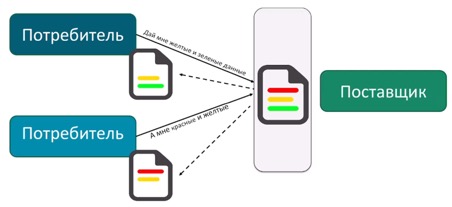
Кроме проблемы авторизации, стоял вопрос создания оптимальной проекции данных для каждого потребителя. Предоставляя публичный API, мы постоянно получали просьбы о его доработке под того или иного потребителя. потому что каждому потребителю требовался свой набор получаемых данных (проекция).
У нас оставалось только два решения:
Создавать такие API, которые возвращали бы сущности целиком со всеми степенями вложенности, а потребители сами решали бы, какие подмножества (проекции) им использовать для своих нужд. Это порождает новую проблему, которая называется overfetching данных. Очевидным минусом такого подхода являются тяжелые DTO, передаваемые по сети;
Создавать такие API, которые возвращали бы только атомарные сущности (только один уровень вложенности). При таком подходе потребителям, чтобы сформировать у себя требуемую проекцию данных, пришлось бы посылать несколько запросов. Эта проблема также известна как underfetching данных.
На самом деле есть и третий путь — проектировать API таким образом, чтобы для каждого потребителя была возможность возвращать свой набор данных. Другими словами, свое API для каждого из потребителей. Но это достаточно трудоемкая задача, даже если вы работаете всего с тремя клиентами.
Контракты
Кроме того, возникала проблема обмена знаниями о контрактах сервиса с потребителями. Отправлять клиента на какую-то wiki-страницу во внутренней сети с неактуальной документацией случалось, наверное, каждому разработчику. Если нет, значит, возможно, доводилось быть в еще более неприятной ситуации. Так что очевидным требованием была автоматическая, структурированная документация. Разработчики не любят писать документацию по разным причинам: кто-то не видит в этом смысла, руководствуясь тем, что такая документация всегда находится в неактуальном состоянии, а кто-то просто не успевает в пылу дедлайнов отражать изменения на странице в wiki. У нас давно практикуется документация кода xml-комментариями. Поэтому, предоставив разработчикам такой инструмент, мы получали описание API прямо в коде, которое менялось одновременно с самим кодом и позволяло иметь максимально актуальную информацию о сервисах и их контрактах.
Мультиплатформенность
Третья проблема — поддержка разных платформ. Мы должны были выбрать современную, свежую технологию, которая бурно развивалась бы, имела качественные реализации и подходящие библиотеки для работы с ней для разных платформ и языков программирования.
Варианты решений
Разумеется, начали с классического, проверенного подхода — WSDL. Но уже на тот момент технология считалась устаревшей и не очень дружила с .NET Core в части создания сервера. А на тот момент .NET Core стал нашим основным стеком.
Другим вариантом для нас было использование технологии OpenAPI. Это решение оказалось значительно лучше и мы его какое-то время использовали. Но такой подход не прошел проверку временем, т.к. реализации OpenAPI в разных стеках были не совместимы между собой.
Мы даже думали отказаться от НТТР API совсем и использовать для взаимодействия только брокер очередей. Пытались воспользоваться внутренним протоколом обмена данных между сервисами для внешних потребителей. Это обычный JSON-документ, вполне очевидно, содержащий имена операций, их параметры и информацию о типах. Сделали описание сервисов в виде документа в формате JSON Schema. В результате стало возможным взаимодействовать с сервисами по внутреннему протоколу на разных платформах. Но, поразмыслив, поняли, что сломаем еще много копий на этом подходе. А также, прикинув, как придется поддерживать это решение и распространять на потенциальные другие платформы, делать то же самое на других языках программирования, приняв во внимание отсутствие какого-либо стандарта и «прекрасную» возможность получить проблемы во всей внутренней шине данных, поняли, что это тупик. В итоге отказались от этой затеи, но не ушли с пустыми руками. Мы получили «чистые контракты», о контроле обратной совместимости которых рассказывали в этой статье.
Мы стали подумывать о каком-то гибридном варианте, при котором потребители сами смогут определять, какие данные им нужны от поставщиков (Consumer Driven Contracts). Присматривались к таким технологиям как oData, но примерно в это время на сцене появилась технология GraphQL. Если быть точным, то сама технология появилась в 2015 году, а в тот момент, как говорят наши архитекторы, она уже зеленела на техрадаре. Наши исследования и эксперименты показали, что технология предоставляет решения к обозначенным выше проблемам “из коробки”, хотя и была довольно сыровата на тот момент.
В итоге на начальных этапах текущего проекта и создания нашей микросервисной платформы было принято решение, что, GraphQL будет обязательным стандартом к доменным сервисам.
Не будем в деталях рассказывать что такое GraphQL, на просторах интернета много хороших статей на эту тему. Скажем лишь, что GraphQL — стандарт, который описывает взаимодействие между поставщиками и потребителями контрактов.
Реализаций у этого стандарта может быть несколько. На тот момент, когда мы начинали создавать платформу, основной стек разработки на бэке был .Net (сегодня добавилась Java) и в качестве основной имплементации была выбрана библиотека graphql-dotnet.
И снова про авторизацию
Пройдя первые шаги в создании авторизации, мы поняли, что старые подходы плохо применимы при создании платформы. Детальный пересмотр подходов к проектированию и реализации ролевой модели и организации разграничения доступа привел нас к мысли о том, что необходимо организовывать раздельный доступ к ресурсам системы вплоть до каждого отдельного сервиса. В ходе выбора конкретного решения мы выделили для себя два концептуальных подхода:
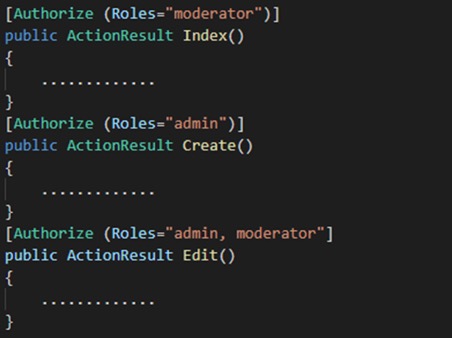
Разграничение доступа на уровне роли (Role-based access control)
В каждой операции описываем, какой ролью она может выполняться, т.е. в атрибутах или параметрах методов проставляем роли, которые могут выполнять эти методы.
За:
Плюсами такого подхода мы считали то, что, во-первых, он был довольно популярен на тот момент и де-факто являлся стандартом, во-вторых, как следствие первого, в ASP .Net MVC функционал был доступен «из коробки» (Identity Framework).
Против:
Главным минусом для нас являлось то, что при добавлении новой роли нужно было в явном виде обозначить в коде все методы, к которым роль должна иметь доступ. Что при активном добавлении ролей постоянно приводило бы к ковровым изменениям в коде. Такая проблема решалась путем создания атомарных ролей (например, в разрезе операций), объединения их в группы и создания из них уже более крупных пользовательских, но все это довольно сложно администрировать и поддерживать.
Также нельзя было гранулярно определить различные уровни доступа разными ролями к одному и тому же методу. Проблема решалась путем написания нескольких перегрузок и развешивания привилегий уже на них. Или можно было повесить по несколько маленьких ролей на методы, а внутри метода написать различные обработчики. Но и это решение сопряжено с дополнительными сложностями в его поддержке. Сложность такого подхода сильно увеличивает порог входа: при выводе нового человека на проект разобраться в том, что происходит внутри, ему было бы довольно проблематично.
Разграничение доступа на уровне отдельных ресурсов (Attribute-based access control)
Суть этого подхода состоит в том, что мы составляем список доступных операций. И в явном виде прописываем каждой роли список операций, которые доступны ей для выполнения.

Так как мы заранее не знали, какие роли в системе у нас будут, предполагалась их активное добавление и изменение, этот подход показался нам более подходящим, чем первый. Управление уровнями доступа пользователей в одном месте сильно уменьшало стоимость поддержки. Более подробно про RBAC и ABAC можно почитать, например, тут.
Второй подход (разграничение доступа на уровне отдельных ресурсов) с политикой «запрещено все, что не разрешено» показался нам ближе и понятнее в простоте реализации администрирования и поддержки.
Долина смерти
Выбранные решения сами по себе не являются «серебряной пулей», которая решит все наши проблемы. Все сложности возникают в ходе реализации и далеко не на все есть готовые стандартные решения.
Bottleneck
В ходе проектирования еще одной нерешенной проблемой казалось то, что необходимо было каждый раз обращаться к сервису/базе авторизации и в явном виде (императивно) спрашивать его, имеет ли данный пользователь с текущей ролью право на выполнение данной операции или нет. Это создавало потенциально высоконагруженное узкое место в системе. Но, как оказалось позже, эту проблему можно решить, используя преимущества JWT токенов.
Мы предпочли использовать Authentication as a Service и выбрали для этого одно из уже готовых решений, так как написание подобных систем своими силами достаточно трудоемкий процесс, требующий особого внимания и высококвалифицированных кадров и все равно чреват проблемами с безопасностью. В условиях банка такое абсолютно недопустимо, поэтому мы полагаемся на труд профессионалов в этой области. Выбор пал на OAuth 2.0 — протокол, с которым многие из нас к тому моменту были знакомы. Если быть точнее, то его реализацию OpenID Connect. Использование OAuth 2.0 казалось рациональным решением еще и потому, что изначально мы не знали, с каким сервером будем работать. И поэтому требовалось абстрагироваться от аутентификации.
Процесс авторизации мы сделали самостоятельно, по сути, по той же причине: требовалась абстракция и отдельный сервис авторизации давал нам большую гибкость в этом вопросе. Это решало и другую проблему — чтобы постоянно не переспрашивать у сервиса, который отвечает за организацию доступа пользователей, «а может ли этот запрос быть исполнен с моей ролью». Токен, выданный сервисом авторизации, подписан им же. Потребитель проверяет валидность этого токена (корректность подписи) и верит содержимому.
Работает это так: сервис авторизации выдает Grant Token (GT), целостность которого также под контролем, в теле Grant Token прописаны привилегии на выполнение той или иной операции. Сервисы могут самостоятельно проверить актуальность и целостность переданного токена, имея при себе ключ сервиса авторизации. Ротация ключей также поддерживается.
Ошибка в выборе формата
Поначалу мы записывали названия ролей и операций в GT текстом. GT свою очередь помещался в Header запроса. Очень быстро получили такую проблему: Header увеличивался в размерах и стал превышать дефолтное значение нашего маршрутизатора, которое составляло 4Кб. Пришлось увеличивать размер заголовка в параметрах маршрутизатора и срочно делать бинарную сериализацию. При использовании бинарной сериализации токены стали значительно меньше, но даже при таком подходе они разрастаются по мере увеличения количества сервисов и доступных операций. Приходится применять дополнительные меры оптимизации. Например, в качестве альтернативы рассматриваются PASETO, мы наблюдаем за развитием этой технологии. Сразу мы не стали работать с ее применением, потому что на момент наших изысканий технология была довольно молодой (да и сейчас суперзрелой ее не назовешь). И нам не удалось обнаружить стабильных реализаций на нашем стеке.
Shared Library vs Sidecar
Выбранный подход не избавил нас от такой проблемы: поначалу функционал авторизации распространялся в виде библиотеки. Любое добавление нового функционала или изменение существующего функционала ролевой модели (а в момент ее создания и начальных этапов развития это происходило довольно часто) означало обновление всех сервисов, которых это изменение касается. А если изменения были обратно несовместимыми, обновлять нужно было все доменные сервисы и их клиенты, что довольно трудозатратно. Кроме того, для каждого стэка нужно было поддерживать свою реализации библиотеки на этом языке.
Для решения этой проблемы мы решили применить архитектурный шаблон «Ambassador» — вынести функционал, который касается авторизации, в отдельный Sidecar и назвали его Security proxy.

Доменный сервис деплоится вместе с Security proxy в одном Pod-е в Kubernetes. Среда настраивается так, чтобы исключить возможность запросов к доменным сервисам не через Security proxy. Сам Security proxy ничего не знает о логике доменного сервиса, ему лишь известно API, выставленное доменным сервисом наружу, он выступает в роли амбассадора. Непосредственно сервис декларативно размечает поля директивами и фокусируется только на бизнес-логике приложения. В случае необходимости изменения логики работы авторизации можно независимо от сервисов массово обновить Security proxy, не нарушая работу продуктовой логики и не пересобирая продуктовые сервисы. Это позволяет использовать один и тот же механизм авторизации для сервисов, использующих различные технологии.
Особенности конкретных реализаций GraphQL
Довольно нетривиально оказалось «подружить» GraphQL с Security Proxy, который инкапсулирует в себе логику авторизации.
При проектировании взаимодействия между самим сервисом и Security Proxy встал вопрос, как Security Proxy будет узнавать о том, к каким полям и методам можно предоставлять соответствующий доступ. О самих полях схемы можно было узнать при помощи специального стандартного запроса — интроспекции, а вот стандартного механизма передачи знаний о том, какой специфический доступ к ним разрешить, не существовало.
В качестве решения этой проблемы было предложено размечать поля схемы соответствующей метаинформацией, по которой Security Proxy будет понимать, разрешен ли доступ к этому полю для текущего запроса или нет. В спецификации GraphQL есть потенциальная возможность сделать это при помощи директив – специальных атрибутов, которыми может быть размечена схема.
В самом стандарте предопределены три директивы: серверная deprecated и клиентские skip и include. Можно было разметить схему дополнительными кастомными директивами, но стандарт не представлял никаких четких указаний по передаче этих директив в интроспекции. Нам частично пришлось реализовывать это самостоятельно, параллельно убеждая владельцев стандарта легализовать такие изменения. Рабочая группа стандарта ждала, пока кто-нибудь реализует возможность передачи кастомных директив в интроспекции. А разработчики библиотеки graphql-dotnet, которую мы активно используем, ждали, пока это будет явно указано в стандарте.
Долгое время в качестве решения мы использовали форк от официального репозитория, в котором были сделаны необходимые изменения. А именно, были добавлены дополнительные типы, описывающие директивы (__AppliedDirective) и тип ее аргументов (__DirectiveArgument). Добавлять в официальный репозиторий их было, разумеется, нельзя, так как все утилиты, вроде graphql-playground, Altair и прочие, работающие с graphql-схемой, просто перестанут работать.
Поддерживать форк было достаточно проблематично, поскольку репозиторий активно развивается и новые версии выходят достаточно часто, причем с функционалом, который нам очень хотелось бы видеть в своем проекте. Поэтому удалось найти компромисс с ментейнерами библиотеки graphql-dotnet и добавить глобальный флаг-переключатель «экспериментального» функционала. Он позволяет не возвращать эти «непонятные» типы, используя «старый» запрос интроспекции, чтобы обеспечить совместимость со старыми клиентами, и, при этом, иметь возможность работать с нашими кастомными директивами.

Позже аналогичное решение, основанное на нашем примере, было перенесено и в библиотеку GraphQL Java. В спецификации самого стандарта эти изменения по-прежнему не до конца легализованы и существуют в виде запроса на изменения, который вызывает активные обсуждения группы владельцев стандарта.
Текущая реальность и планы развития
Используя такую комбинацию технологий, мы получили комплексное решение со стороны безопасности и архитектуры:
Независимый от конкретного языка программирования механизм авторизации для компонентов системы (Digital Platform). Следуй стандарту, используй GraphQL, размечай поля директивами - и вперед;
Разделили авторизацию и бизнес-логику на уровне архитектуры. Разработчики доменных сервисов сосредоточены на создании бизнес-функционала и не думают о деталях реализации авторизации;
Позволили владельцам сервисов сосредоточиться на логике их реализации и не фокусироваться на том, какие именно проекции данных могут потребоваться конкретным потребителям;
Удобное управление ролями через внешний сервис, которое не блокируется развитием сервисов и само не блокирует их;
Оценить плюсы такого подхода как Sidecar, который позволил независимо релизить различные компоненты системы. Настоятельно рекомендую присмотреться к той части приложения, которую вы распространяете как библиотека, и вынести ее в Sidecar. Это особенно актуально для активно развивающихся систем, которые часто релизятся в процессе непрерывной поставки;
Популяризировать внутри организации современную технологию. Что ни говорите, а банки традиционно относят к консервативным структурам, тогда как современные разработчики любят
«стильно, модно, молодежно»пробовать новые решения и технологии.
Повышение Multitenancy — возможности повторно использовать компоненты системы гораздо шире, чем рамки одного проекта и даже организации. Активность в этом направлении (платформизация) позволяет нам экономить на создании типовых решений при запуске новых продуктов.
Надеемся, что история была интересной и наш опыт будет полезен для вас.


