
Docker Swarm, Kubernetes и Mesos являются наиболее популярными фреймворками для оркестровки контейнеров. В своем выступлении Арун Гупта сравнивает следующие аспекты работы Docker, Swarm, и Kubernetes:
В результате вы получите четкое представление о том, что может предложить каждый инструмент оркестровки, и изучите методы эффективного использования этих платформ.
Арун Гупта — главный технолог open-source продуктов Amazon Web Services, который уже более 10 лет развивает сообщества разработчиков Sun, Oracle, Red Hat и Couchbase. Имеет большой опыт работы в ведущих кросс-функциональных командах, занимающихся разработкой и реализацией стратегии маркетинговых кампаний и программ. Руководил группами инженеров Sun, является одним из основателей команды Java EE и создателем американского отделения Devoxx4Kids. Арун Гупта является автором более 2 тысяч постов в IT-блогах и выступил с докладами более чем в 40 странах.
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 1
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 2
В строке 55 содержится COUCHBASE_URI, указывающий к на сервис этой базы данных, который тоже создан с помощью файла конфигурации Kubernetes. Если посмотреть на строку 2, можно увидеть kind: Service – это сервис, который я создаю под именем couchbase-service, и это же имя указанно в строке 4. Ниже приводятся несколько портов.

Ключевыми строками являются 6 и 7. В service я говорю: «Эй, вот эти метки, которые я ищу!», и эти labels не что иное, как имена пар переменных, а строка 7 указывает на мое приложение couchbase-rs-pod. Далее перечислены порты, дающие доступ к этим самым labels.
В строке 19 я создаю новый тип ReplicaSet, в строке 31 содержится имя образа, а строки 24-27 указывают на метаданные, ассоциированные с моим подом. Это именно то, что ищет service и с чем должно быть установлено соединение. В конце файла расположен некий вид связи строк 55-56 и 4, говорящий: «используй этот service!».
Итак, я запускаю свой service при наличии набора реплик, и поскольку каждый набор реплик имеет свой порт с соответствующей меткой, он включается в состав service. С точки зрения разработчика, вы просто обращаетесь к сервису, который затем задействует нужный вам набор реплик.
В итоге у меня имеется под WildFly, который общается с бэкендом базы данных через Couchbase Service. Я могу использовать фронтенд с несколькими подами WildFly, который также через couchbase service связывается с бэкендом couchbase.
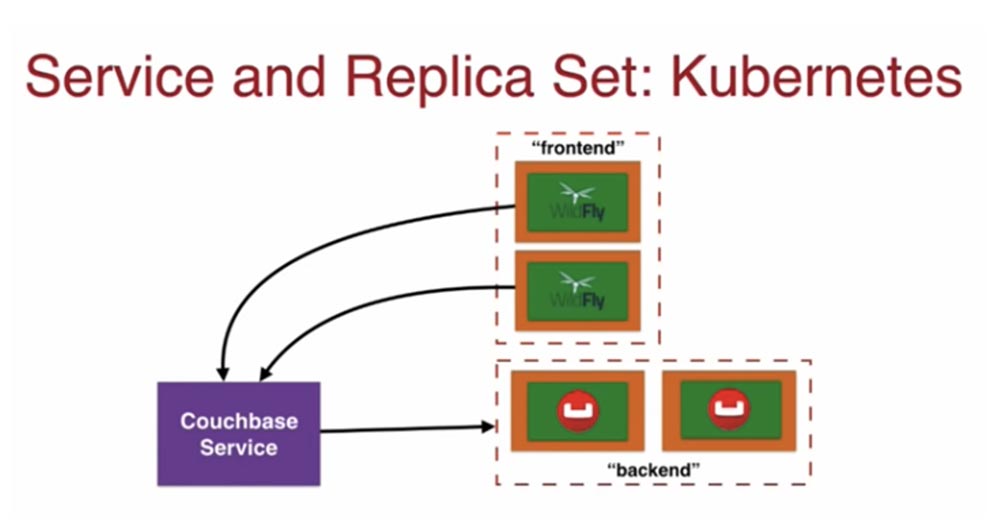
Позже мы рассмотрим, как service, расположенный вне кластера, через свой IP-адрес общается с элементами, которые расположены внутри кластера и имеют внутренний IP-адрес.
Итак, stateless-контейнеры – это хорошо, но насколько хороша идея использовать stateful-контейнеры? Давайте рассмотрим настройки системы для stateful, или постоянных контейнеров. В Docker существует 4 различных подхода к расположению хранилища данных, на которые следует обратить внимание. Первый – это Implicit Per-Container, означающий, что при использовании satateful-контейнеров couchbase, MySQL или MyDB, все они запускаются с дефолтным Sandbox. То есть все, что хранится в базе данных, хранится в самом контейнере. Если контейнер пропадает, данные пропадают вместе с ним.
Второй – это Explicit Per-Container, когда вы создаете конкретное хранилище командой docker volume create и сохраняете в нем данные. Третий подход Per-Host связан с маппингом хранилищ, когда все, что хранится в контейнере, одновременно дублируется на хосте. Если контейнер даст сбой, данные останутся на хосте. Последнее – это использование нескольких хостов Multi-Host, что целесообразно на стадии продакшена различных решений. Предположим, ваши контейнеры с вашими приложениями запущены на хосте, но при этом вы хотите хранить свои данные где-то в интернете, причем для этого используется автоматический маппинг для распределенных систем.

Каждый из этих методов использует конкретное местоположение хранилища. Implicit и Explicit Per-Container хранят данные на хосте по адресу /var/lib/docker/volumes. При использовании метода Per-Host хранилище монтируется внутри контейнера, а сам контейнер монтируется на хосте. Для мультихостов могут использоваться решения типа Ceph, ClusterFS, NFS и т.д.
При сбое постоянного контейнера директория хранилища становится недоступной в двух первых случаях, а в двух последних доступ сохраняется. Однако в первом случае вы можете добраться к хранилищу через хост Docker, запущенный на виртуальной машине. Во втором случае данные тоже не пропадут, потому что вы создали Explicit-хранилище.
При сбое хоста директория хранилища недоступна в трех первых случаях, в последнем случае связь с хранилищем не прерывается. Наконец, функция shared полностью исключена для хранилища в первом случае и возможна в остальных. Во втором случае можно поделиться хранилищем в зависимости от того, поддерживает ваша база данных распределенные хранилища или нет. В случае Per-Host распределение данных возможно только на данном хосте, а для мультихоста оно обеспечивается расширением кластера.
Это следует учитывать при создании stateful-контейнеров. Еще один полезный инструмент Docker – это плагин Volume, работающий по принципу «батареи присутствуют, но подлежат замене». При запуске контейнера Docker он говорит: «Эй, запустив контейнер с базой данных, ты можешь хранить свои данные в этом контейнере!» Эта функция по умолчанию, но вы можете ее изменить. Этот плагин позволяет использовать вместо контейнерной БД сетевой диск или что-то подобное. Он включает в себя драйвер по умолчанию для host-based хранилищ и позволяет интеграцию контейнеров с внешними системами хранения данных, такими как Amazon EBS, Azure Storage и постоянными дисками GCE Persistent.
На следующем слайде показана архитектура плагина Docker Volume.
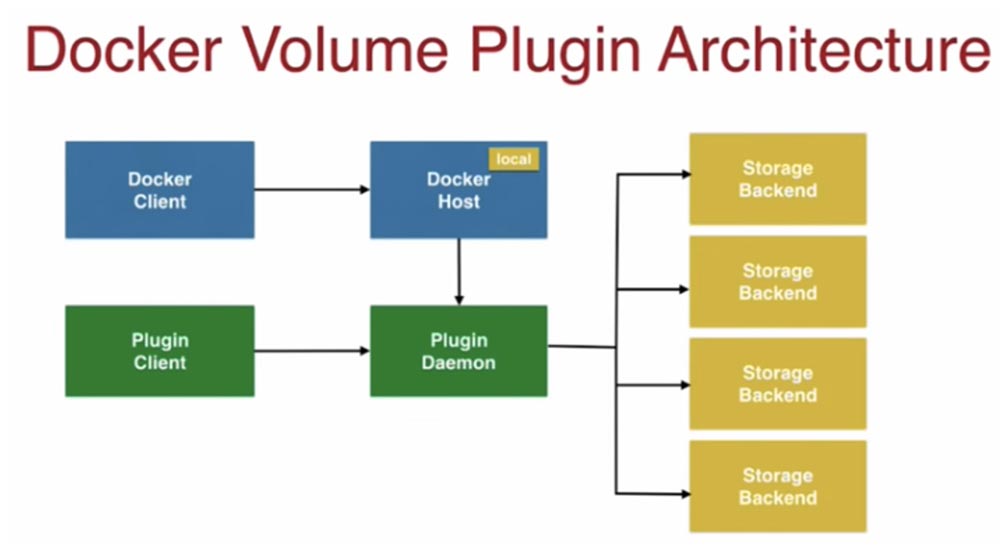
Синим цветом обозначен клиент Docker, связанный с синим Docker-хостом, на котором имеется Local storage engine, предоставляющий вам контейнеры для хранения данных. Зеленым цветом обозначены клиент Plugin Client и Plugin Daemon, которые также подсоединены к хосту. Они предоставляют возможность хранить данные в сетевых хранилищах нужного вам вида Storage Backend.
Плагин Docker Volume может использоваться с хранилищем Portworx. Модуль PX-Dev собственно является запускаемым вами контейнером, который подключается к Docker-хосту и позволяет легко сохранять данные на Amazon EBS.
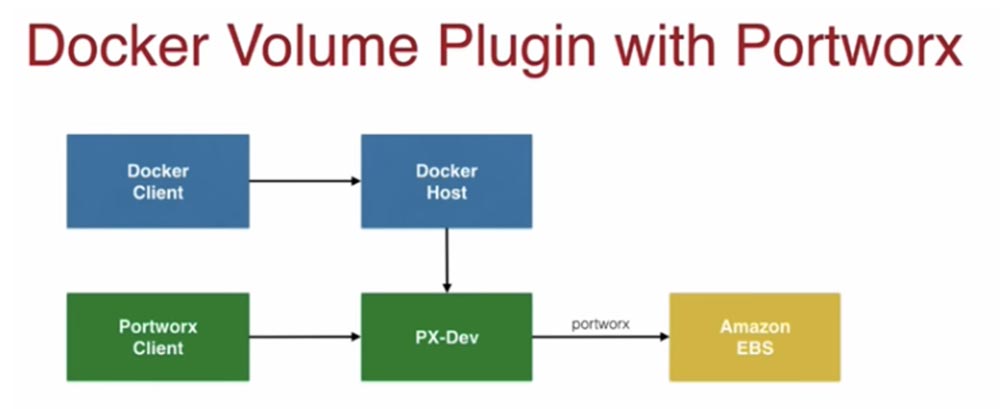
Клиент Portworx позволяет вам отслеживать состояние контейнеров с различными хранилищами, которые подсоединены к вашему хосту. Если вы посетите мой блог, то сможете прочесть, как наиболее эффективно использовать Portworx с Docker.
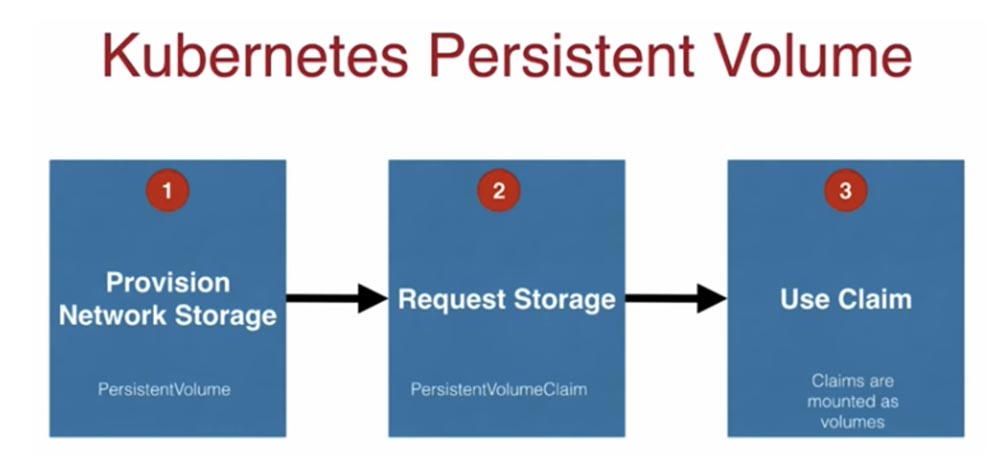
Концепция хранилищ в Kubernetes похожа на Docker и представлена директориями, которые доступны вашему контейнеру в поде. Они не зависимы от времени жизни любого контейнера. Наиболее распространенными доступными типами хранилищ являются hostPath, nfs, awsElasticBlockStore и gsePersistentDisk. Рассмотрим, как работают эти хранилища в Kubernetes. Обычно процесс их подключения состоит из 3 шагов.
Первый заключается в том, что кто-то на стороне сети, обычно это администратор, предоставляет вам постоянное хранилище. Для этого имеется соответствующий файл конфигурации PersistentVolume. Далее разработчик приложения пишет файл конфигурации под названием PersistentVolumeClaim, или запрос на хранилище PVC, в котором говорится: «у меня подготовлено распределенное хранилище объемом 50Гб, но чтобы другие люди тоже могли использовать его емкость, я сообщаю в этом PVC, что сейчас мне нужно всего 10 Гб». Наконец, третий шаг состоит в том, что ваш запрос монтируется как хранилище, и приложение, в котором имеется под, или набор реплик, или что-то подобное, начинает им пользоваться. Важно помнить, что этот процесс состоит из 3-х упомянутых этапов и позволяет масштабирование.
На следующем слайде показан постоянный контейнер Kubernetes Persistence Container архитектуры AWS.

Внутри коричневого прямоугольника, который изображает кластер Kubernetes, расположен один мастер-нод и два рабочих нода, обозначенные желтым цветом. В одном из worker node находится оранжевый под, хранилище, контроллер реплик и зеленый контейнер Docker Couchbase. Внутри кластера над нодами прямоугольником лилового цвета обозначен доступный извне Service. Эта архитектура рекомендуется для сохранения данных на самом устройстве. При необходимости я могу хранить свои данные в EBS за пределами кластера, как это показано на следующем слайде. Это типичная модель для масштабирования, однако при ее применении нужно учитывать финансовый аспект – хранить данные где-то в сети может быть дороже, чем на хосте. При выборе решений контейнеризации это один из весомых аргументов.
Так же, как в случае с Docker, вы можете использовать постоянные контейнеры Kubernetes вместе с Portworx.

Это то, что в нынешней терминологии Kubernetes 1.6 называется «StatefulSet» — способ работы со Stateful-приложениями, которым обрабатываются события об остановке работы Pod и осуществления Graceful Shutdown. В нашем случае такими приложениями являются базы данных. В моем блоге вы можете прочесть, как создавать StatefulSet в Kubernetes при помощи Portworx.
Давайте поговорим про аспект разработки. Как я сказал, Docker имеет 2 версии – СЕ и ЕЕ, в первом случае речь идет о стабильной версии Community Edition, которая обновляется раз в 3 месяца в отличие от ежемесячно обновляемой версии ЕЕ. Вы можете скачать Docker для Mac, Linux или Windows. После установки Docker будет автоматически обновляться, и начать работать с ним очень легко.
В Kubernetes я предпочитаю версию Minikube – это хороший способ начать работу с этой платформой путем создания кластера на одиночном узле. Для создания кластеров из нескольких нодов выбор версий шире: это kops, kube-aws (CoreOS+AWS), kube-up (устарела). Если вы собираетесь использовать Kubernetes на основе AWS, рекомендую присоединится к группе AWS SIG, которая встречается в сети каждую пятницу и публикует различные интересные материалы по работе с Kubernetes AWS.
Рассмотрим, как на этих платформах выполняется скользящее обновление Rolling Update. Если имеется кластер из нескольких нодов, то в нем используется конкретная версия образа, например, WildFly:1. Скользящее обновление означает, что версия образа последовательно заменяется новой на каждом ноде, один за другим.
Для этого используется команда docker service update (имя сервиса), в которой я указываю новую версию образа WildFly:2 и метод обновления update-parallelism 2. Цифра 2 означает, что система будет обновлять по 2 образа приложения одновременно, затем последует 10-ти секундная задержка update delay 10s, после чего будут обновлены 2 следующих образа еще на 2-х нодах, и т.д. Этот простой механизм скользящего обновления предоставляется вам как составная часть Docker.
В Kubernetes скользящее обновление происходит таким образом. Контроллер репликации rc создает набор реплик одной версии, и каждый под в этом webapp-rc снабжен меткой label, находящейся в etcd. Когда мне нужен какой-то под, я через Application Service обращаюсь к хранилищу etcd, которое по указанной метке предоставляет мне этот под.
В данном случае у нас в Replication controller имеется 3 пода, в которых запущено приложение WildFly версии 1. При обновлении в фоновом режиме создается еще один контроллер репликации с тем же именем и индексом в конце — - xxxxx, где х – случайные числа, и с теми же метками labels. Теперь Application Service располагает тремя подами с приложением старой версии и тремя подами с новой версией в новом Replication controller. После этого старые поды удаляются, контроллер репликации с новыми подами переименовывается и включается в работу.

Перейдем к рассмотрению мониторинга. В Docker имеется множество встроенных команд для мониторинга. Например, интерфейс командной строки docker container stats позволяет каждую секунду выводить в консоль данные о состоянии контейнеров – использование процессора, диска, загрузку сети. Инструмент Docker Remote API предоставляет данные о том, как клиент общается с сервером. Он использует простые команды, но в его основе лежит Docker REST API. В данном случае слова REST, Flash, Remote обозначают одно и то же. Когда вы общаетесь с хостом, это REST API. Docker Remote API позволяет получить больше сведений о запущенных контейнерах. В моем блоге изложены детали использования этого мониторинга с Windows Server.
Мониторинг системных событий docker system events при запуске мультихостового кластера дает возможность получить данные о падении хоста или падении контейнера на конкретном хосте, масштабировании сервисов и тому подобного. Начиная с версии Docker 1.20, в него включен Prometheus, который осуществляет встраивание endpoints в существующие приложения. Это позволяет получать метрики через HTTP и отображать их на панелях мониторинга.
Еще одна функция мониторинга – это cAdvisor (сокращение от container Advisor). Он анализирует и предоставляет данные об использовании ресурсов и производительности из запущенных контейнеров, предоставляя метрики Prometheus «прямо из коробки». Особенность этого инструмента в том, что он предоставляет данные только за последние 60 секунд. Поэтому вам нужно предусмотреть возможность собирать эти данные и помещать в базу данных, чтобы иметь возможность мониторинга длительного по времени процесса. Его также можно использовать для отображения метрик на панели мониторинга в графическом виде с помощью Grafana или Kibana. В моем блоге есть подробное описание того, как использовать cAdvisor для мониторинга контейнеров с помощью панели Kibana.
На следующем слайде показано, как выглядит результат работы Prometheus endpoint и доступные для отображения метрики.

Слева внизу вы видите метрики HTTP-запросов, ответов и т.д., справа – их графическое отображение.
Kubernetes также содержит встроенные инструменты мониторинга. На этом слайде показан типовой кластер, содержащий один мастер и три рабочих узла.
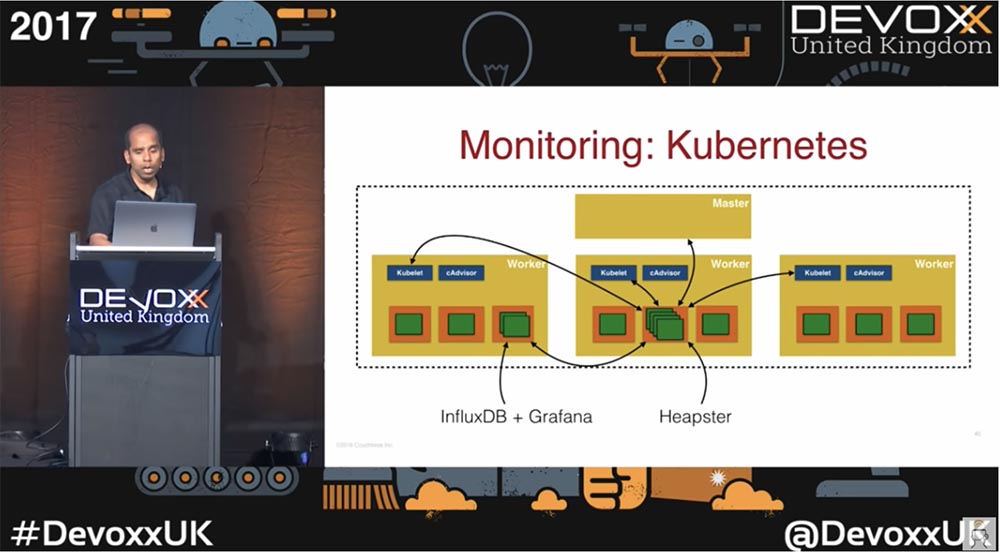
В каждом из рабочих нодов расположен автоматически запускаемый cAdvisor. Кроме этого, здесь имеется Heapster — система мониторинга производительности и сбора метрик, совместимая с Kubernetes версии 1.0.6 и выше. Heapster позволяет собирать не только показатели производительности рабочих нагрузок, модулей и контейнеров, но и события и другие сигналы, генерируемые целым кластером. Для сбора данных он общается с Kubelet каждого пода, автоматически сохраняет информацию в базе данных InfluxDB и выводит в виде метрик на панель мониторинга Grafana. Однако учтите – если вы используете miniKube, эта функция по умолчанию недоступна, поэтому для мониторинга придется использовать аддоны. Так что все зависит от того, где вы запускаете контейнеры и какими инструментами мониторинга можете воспользоваться по умолчанию, а какие требуется установить в виде отдельных дополнений.
На следующем слайде изображены панели мониторинга Grafana, которые показывают рабочее состояние моих контейнеров. Здесь достаточно много интересных данных. Конечно, существует множество коммерческих инструментов мониторинга процессов Docker и Kubernetes, например SysDig, DataDog, NewRelic. Некоторые из них имеют 30-ти бесплатный пробный период, так что можно попробовать и подобрать себе наиболее подходящий. Лично я предпочитаю использовать SysDig и NewRelic, которые отлично интегрируются в Kubernetes. Существуют инструменты, которые одинаково хорошо интегрируются в обе платформы – и Docker, и Kubernetes.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
- Локальный девелопмент.
- Функции развертывания.
- Мультиконтейнерные приложения.
- Обнаружение служб service discovery.
- Масштабирование сервиса.
- Run-once задания.
- Интеграция с Maven.
- «Скользящее» обновление.
- Создание кластера БД Couchbase.
В результате вы получите четкое представление о том, что может предложить каждый инструмент оркестровки, и изучите методы эффективного использования этих платформ.
Арун Гупта — главный технолог open-source продуктов Amazon Web Services, который уже более 10 лет развивает сообщества разработчиков Sun, Oracle, Red Hat и Couchbase. Имеет большой опыт работы в ведущих кросс-функциональных командах, занимающихся разработкой и реализацией стратегии маркетинговых кампаний и программ. Руководил группами инженеров Sun, является одним из основателей команды Java EE и создателем американского отделения Devoxx4Kids. Арун Гупта является автором более 2 тысяч постов в IT-блогах и выступил с докладами более чем в 40 странах.
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 1
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 2
В строке 55 содержится COUCHBASE_URI, указывающий к на сервис этой базы данных, который тоже создан с помощью файла конфигурации Kubernetes. Если посмотреть на строку 2, можно увидеть kind: Service – это сервис, который я создаю под именем couchbase-service, и это же имя указанно в строке 4. Ниже приводятся несколько портов.
Ключевыми строками являются 6 и 7. В service я говорю: «Эй, вот эти метки, которые я ищу!», и эти labels не что иное, как имена пар переменных, а строка 7 указывает на мое приложение couchbase-rs-pod. Далее перечислены порты, дающие доступ к этим самым labels.
В строке 19 я создаю новый тип ReplicaSet, в строке 31 содержится имя образа, а строки 24-27 указывают на метаданные, ассоциированные с моим подом. Это именно то, что ищет service и с чем должно быть установлено соединение. В конце файла расположен некий вид связи строк 55-56 и 4, говорящий: «используй этот service!».
Итак, я запускаю свой service при наличии набора реплик, и поскольку каждый набор реплик имеет свой порт с соответствующей меткой, он включается в состав service. С точки зрения разработчика, вы просто обращаетесь к сервису, который затем задействует нужный вам набор реплик.
В итоге у меня имеется под WildFly, который общается с бэкендом базы данных через Couchbase Service. Я могу использовать фронтенд с несколькими подами WildFly, который также через couchbase service связывается с бэкендом couchbase.
Позже мы рассмотрим, как service, расположенный вне кластера, через свой IP-адрес общается с элементами, которые расположены внутри кластера и имеют внутренний IP-адрес.
Итак, stateless-контейнеры – это хорошо, но насколько хороша идея использовать stateful-контейнеры? Давайте рассмотрим настройки системы для stateful, или постоянных контейнеров. В Docker существует 4 различных подхода к расположению хранилища данных, на которые следует обратить внимание. Первый – это Implicit Per-Container, означающий, что при использовании satateful-контейнеров couchbase, MySQL или MyDB, все они запускаются с дефолтным Sandbox. То есть все, что хранится в базе данных, хранится в самом контейнере. Если контейнер пропадает, данные пропадают вместе с ним.
Второй – это Explicit Per-Container, когда вы создаете конкретное хранилище командой docker volume create и сохраняете в нем данные. Третий подход Per-Host связан с маппингом хранилищ, когда все, что хранится в контейнере, одновременно дублируется на хосте. Если контейнер даст сбой, данные останутся на хосте. Последнее – это использование нескольких хостов Multi-Host, что целесообразно на стадии продакшена различных решений. Предположим, ваши контейнеры с вашими приложениями запущены на хосте, но при этом вы хотите хранить свои данные где-то в интернете, причем для этого используется автоматический маппинг для распределенных систем.
Каждый из этих методов использует конкретное местоположение хранилища. Implicit и Explicit Per-Container хранят данные на хосте по адресу /var/lib/docker/volumes. При использовании метода Per-Host хранилище монтируется внутри контейнера, а сам контейнер монтируется на хосте. Для мультихостов могут использоваться решения типа Ceph, ClusterFS, NFS и т.д.
При сбое постоянного контейнера директория хранилища становится недоступной в двух первых случаях, а в двух последних доступ сохраняется. Однако в первом случае вы можете добраться к хранилищу через хост Docker, запущенный на виртуальной машине. Во втором случае данные тоже не пропадут, потому что вы создали Explicit-хранилище.
При сбое хоста директория хранилища недоступна в трех первых случаях, в последнем случае связь с хранилищем не прерывается. Наконец, функция shared полностью исключена для хранилища в первом случае и возможна в остальных. Во втором случае можно поделиться хранилищем в зависимости от того, поддерживает ваша база данных распределенные хранилища или нет. В случае Per-Host распределение данных возможно только на данном хосте, а для мультихоста оно обеспечивается расширением кластера.
Это следует учитывать при создании stateful-контейнеров. Еще один полезный инструмент Docker – это плагин Volume, работающий по принципу «батареи присутствуют, но подлежат замене». При запуске контейнера Docker он говорит: «Эй, запустив контейнер с базой данных, ты можешь хранить свои данные в этом контейнере!» Эта функция по умолчанию, но вы можете ее изменить. Этот плагин позволяет использовать вместо контейнерной БД сетевой диск или что-то подобное. Он включает в себя драйвер по умолчанию для host-based хранилищ и позволяет интеграцию контейнеров с внешними системами хранения данных, такими как Amazon EBS, Azure Storage и постоянными дисками GCE Persistent.
На следующем слайде показана архитектура плагина Docker Volume.
Синим цветом обозначен клиент Docker, связанный с синим Docker-хостом, на котором имеется Local storage engine, предоставляющий вам контейнеры для хранения данных. Зеленым цветом обозначены клиент Plugin Client и Plugin Daemon, которые также подсоединены к хосту. Они предоставляют возможность хранить данные в сетевых хранилищах нужного вам вида Storage Backend.
Плагин Docker Volume может использоваться с хранилищем Portworx. Модуль PX-Dev собственно является запускаемым вами контейнером, который подключается к Docker-хосту и позволяет легко сохранять данные на Amazon EBS.
Клиент Portworx позволяет вам отслеживать состояние контейнеров с различными хранилищами, которые подсоединены к вашему хосту. Если вы посетите мой блог, то сможете прочесть, как наиболее эффективно использовать Portworx с Docker.
Концепция хранилищ в Kubernetes похожа на Docker и представлена директориями, которые доступны вашему контейнеру в поде. Они не зависимы от времени жизни любого контейнера. Наиболее распространенными доступными типами хранилищ являются hostPath, nfs, awsElasticBlockStore и gsePersistentDisk. Рассмотрим, как работают эти хранилища в Kubernetes. Обычно процесс их подключения состоит из 3 шагов.
Первый заключается в том, что кто-то на стороне сети, обычно это администратор, предоставляет вам постоянное хранилище. Для этого имеется соответствующий файл конфигурации PersistentVolume. Далее разработчик приложения пишет файл конфигурации под названием PersistentVolumeClaim, или запрос на хранилище PVC, в котором говорится: «у меня подготовлено распределенное хранилище объемом 50Гб, но чтобы другие люди тоже могли использовать его емкость, я сообщаю в этом PVC, что сейчас мне нужно всего 10 Гб». Наконец, третий шаг состоит в том, что ваш запрос монтируется как хранилище, и приложение, в котором имеется под, или набор реплик, или что-то подобное, начинает им пользоваться. Важно помнить, что этот процесс состоит из 3-х упомянутых этапов и позволяет масштабирование.
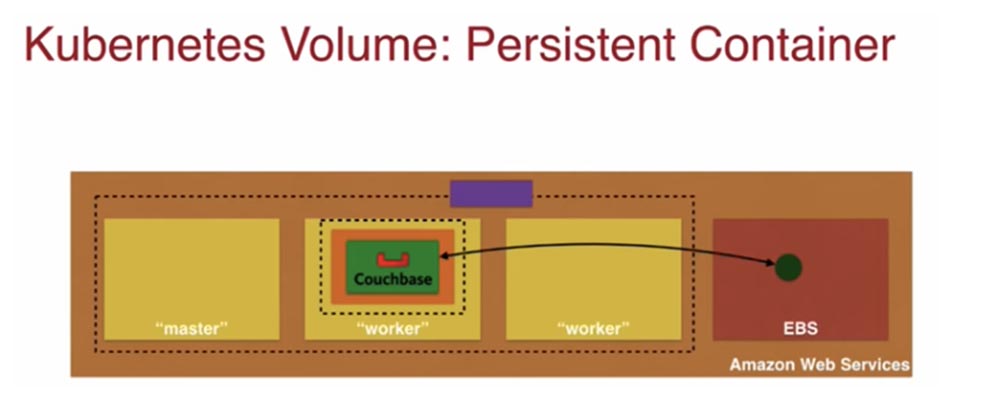
На следующем слайде показан постоянный контейнер Kubernetes Persistence Container архитектуры AWS.
Внутри коричневого прямоугольника, который изображает кластер Kubernetes, расположен один мастер-нод и два рабочих нода, обозначенные желтым цветом. В одном из worker node находится оранжевый под, хранилище, контроллер реплик и зеленый контейнер Docker Couchbase. Внутри кластера над нодами прямоугольником лилового цвета обозначен доступный извне Service. Эта архитектура рекомендуется для сохранения данных на самом устройстве. При необходимости я могу хранить свои данные в EBS за пределами кластера, как это показано на следующем слайде. Это типичная модель для масштабирования, однако при ее применении нужно учитывать финансовый аспект – хранить данные где-то в сети может быть дороже, чем на хосте. При выборе решений контейнеризации это один из весомых аргументов.
Так же, как в случае с Docker, вы можете использовать постоянные контейнеры Kubernetes вместе с Portworx.
Это то, что в нынешней терминологии Kubernetes 1.6 называется «StatefulSet» — способ работы со Stateful-приложениями, которым обрабатываются события об остановке работы Pod и осуществления Graceful Shutdown. В нашем случае такими приложениями являются базы данных. В моем блоге вы можете прочесть, как создавать StatefulSet в Kubernetes при помощи Portworx.
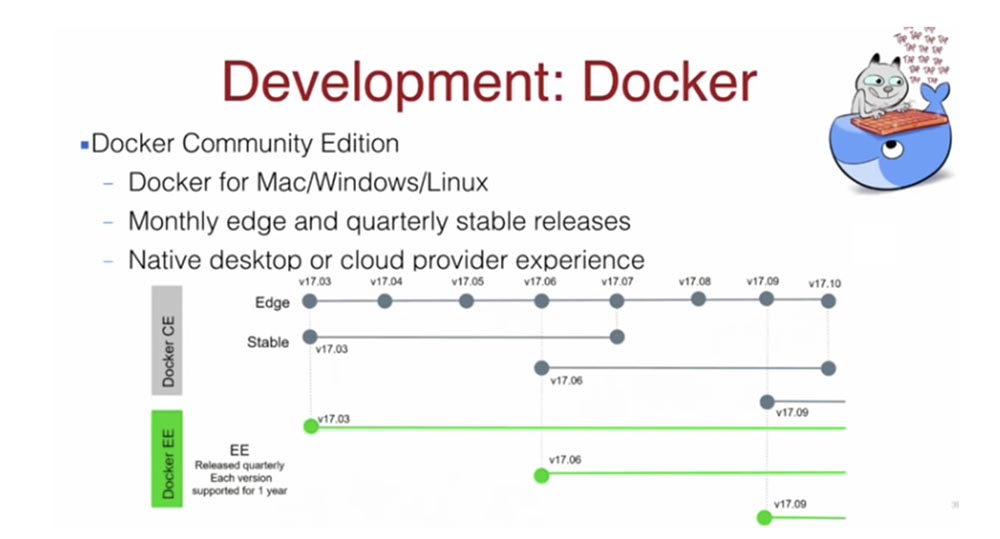
Давайте поговорим про аспект разработки. Как я сказал, Docker имеет 2 версии – СЕ и ЕЕ, в первом случае речь идет о стабильной версии Community Edition, которая обновляется раз в 3 месяца в отличие от ежемесячно обновляемой версии ЕЕ. Вы можете скачать Docker для Mac, Linux или Windows. После установки Docker будет автоматически обновляться, и начать работать с ним очень легко.
В Kubernetes я предпочитаю версию Minikube – это хороший способ начать работу с этой платформой путем создания кластера на одиночном узле. Для создания кластеров из нескольких нодов выбор версий шире: это kops, kube-aws (CoreOS+AWS), kube-up (устарела). Если вы собираетесь использовать Kubernetes на основе AWS, рекомендую присоединится к группе AWS SIG, которая встречается в сети каждую пятницу и публикует различные интересные материалы по работе с Kubernetes AWS.
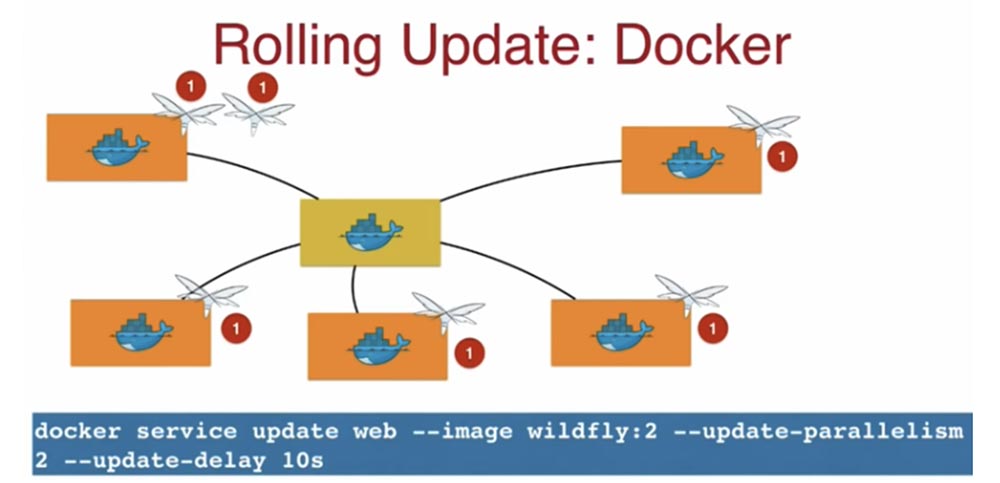
Рассмотрим, как на этих платформах выполняется скользящее обновление Rolling Update. Если имеется кластер из нескольких нодов, то в нем используется конкретная версия образа, например, WildFly:1. Скользящее обновление означает, что версия образа последовательно заменяется новой на каждом ноде, один за другим.
Для этого используется команда docker service update (имя сервиса), в которой я указываю новую версию образа WildFly:2 и метод обновления update-parallelism 2. Цифра 2 означает, что система будет обновлять по 2 образа приложения одновременно, затем последует 10-ти секундная задержка update delay 10s, после чего будут обновлены 2 следующих образа еще на 2-х нодах, и т.д. Этот простой механизм скользящего обновления предоставляется вам как составная часть Docker.
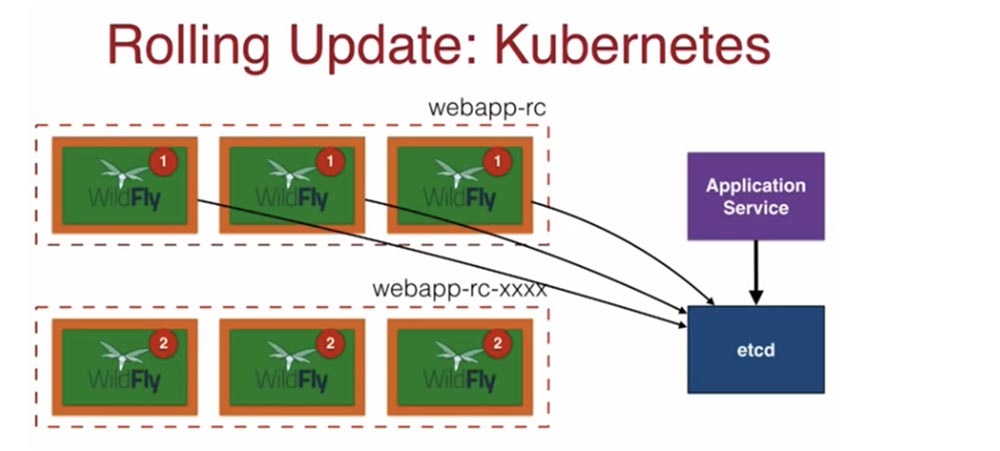
В Kubernetes скользящее обновление происходит таким образом. Контроллер репликации rc создает набор реплик одной версии, и каждый под в этом webapp-rc снабжен меткой label, находящейся в etcd. Когда мне нужен какой-то под, я через Application Service обращаюсь к хранилищу etcd, которое по указанной метке предоставляет мне этот под.
В данном случае у нас в Replication controller имеется 3 пода, в которых запущено приложение WildFly версии 1. При обновлении в фоновом режиме создается еще один контроллер репликации с тем же именем и индексом в конце — - xxxxx, где х – случайные числа, и с теми же метками labels. Теперь Application Service располагает тремя подами с приложением старой версии и тремя подами с новой версией в новом Replication controller. После этого старые поды удаляются, контроллер репликации с новыми подами переименовывается и включается в работу.
Перейдем к рассмотрению мониторинга. В Docker имеется множество встроенных команд для мониторинга. Например, интерфейс командной строки docker container stats позволяет каждую секунду выводить в консоль данные о состоянии контейнеров – использование процессора, диска, загрузку сети. Инструмент Docker Remote API предоставляет данные о том, как клиент общается с сервером. Он использует простые команды, но в его основе лежит Docker REST API. В данном случае слова REST, Flash, Remote обозначают одно и то же. Когда вы общаетесь с хостом, это REST API. Docker Remote API позволяет получить больше сведений о запущенных контейнерах. В моем блоге изложены детали использования этого мониторинга с Windows Server.
Мониторинг системных событий docker system events при запуске мультихостового кластера дает возможность получить данные о падении хоста или падении контейнера на конкретном хосте, масштабировании сервисов и тому подобного. Начиная с версии Docker 1.20, в него включен Prometheus, который осуществляет встраивание endpoints в существующие приложения. Это позволяет получать метрики через HTTP и отображать их на панелях мониторинга.
Еще одна функция мониторинга – это cAdvisor (сокращение от container Advisor). Он анализирует и предоставляет данные об использовании ресурсов и производительности из запущенных контейнеров, предоставляя метрики Prometheus «прямо из коробки». Особенность этого инструмента в том, что он предоставляет данные только за последние 60 секунд. Поэтому вам нужно предусмотреть возможность собирать эти данные и помещать в базу данных, чтобы иметь возможность мониторинга длительного по времени процесса. Его также можно использовать для отображения метрик на панели мониторинга в графическом виде с помощью Grafana или Kibana. В моем блоге есть подробное описание того, как использовать cAdvisor для мониторинга контейнеров с помощью панели Kibana.
На следующем слайде показано, как выглядит результат работы Prometheus endpoint и доступные для отображения метрики.
Слева внизу вы видите метрики HTTP-запросов, ответов и т.д., справа – их графическое отображение.
Kubernetes также содержит встроенные инструменты мониторинга. На этом слайде показан типовой кластер, содержащий один мастер и три рабочих узла.
В каждом из рабочих нодов расположен автоматически запускаемый cAdvisor. Кроме этого, здесь имеется Heapster — система мониторинга производительности и сбора метрик, совместимая с Kubernetes версии 1.0.6 и выше. Heapster позволяет собирать не только показатели производительности рабочих нагрузок, модулей и контейнеров, но и события и другие сигналы, генерируемые целым кластером. Для сбора данных он общается с Kubelet каждого пода, автоматически сохраняет информацию в базе данных InfluxDB и выводит в виде метрик на панель мониторинга Grafana. Однако учтите – если вы используете miniKube, эта функция по умолчанию недоступна, поэтому для мониторинга придется использовать аддоны. Так что все зависит от того, где вы запускаете контейнеры и какими инструментами мониторинга можете воспользоваться по умолчанию, а какие требуется установить в виде отдельных дополнений.
На следующем слайде изображены панели мониторинга Grafana, которые показывают рабочее состояние моих контейнеров. Здесь достаточно много интересных данных. Конечно, существует множество коммерческих инструментов мониторинга процессов Docker и Kubernetes, например SysDig, DataDog, NewRelic. Некоторые из них имеют 30-ти бесплатный пробный период, так что можно попробовать и подобрать себе наиболее подходящий. Лично я предпочитаю использовать SysDig и NewRelic, которые отлично интегрируются в Kubernetes. Существуют инструменты, которые одинаково хорошо интегрируются в обе платформы – и Docker, и Kubernetes.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
. Часть 2: «Симулятор NOR»")



