
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Всем привет. Расскажу вам про микросервисы, но немного с другой точки зрения, чем Вадим Мадисон в посте «Что мы знаем о микросервисах». Вообще я считаю себя разработчиком баз данных. При чем же тут микросервисы? В Авито используются: Vertica, PostgreSQL, Redis, MongoDB, Tarantool, VoltDB, SQLite… Всего у нас 456+ баз для 849+ сервисов. И с этим как-то нужно жить.
В этом посте я расскажу вам про то, как мы реализовали data discovery в микросервисной архитектуре. Этот пост — вольная расшифровка моего доклада с Highload++ 2018, видео можно посмотреть тут.

Как должна быть построена микросервисной архитектура с точки зрения баз, все неплохо знают. Вот паттерн, с которого все обычно начинают. Есть общая база между сервисами. На слайде оранжевые прямоугольники — это сервисы, между ними общая база.
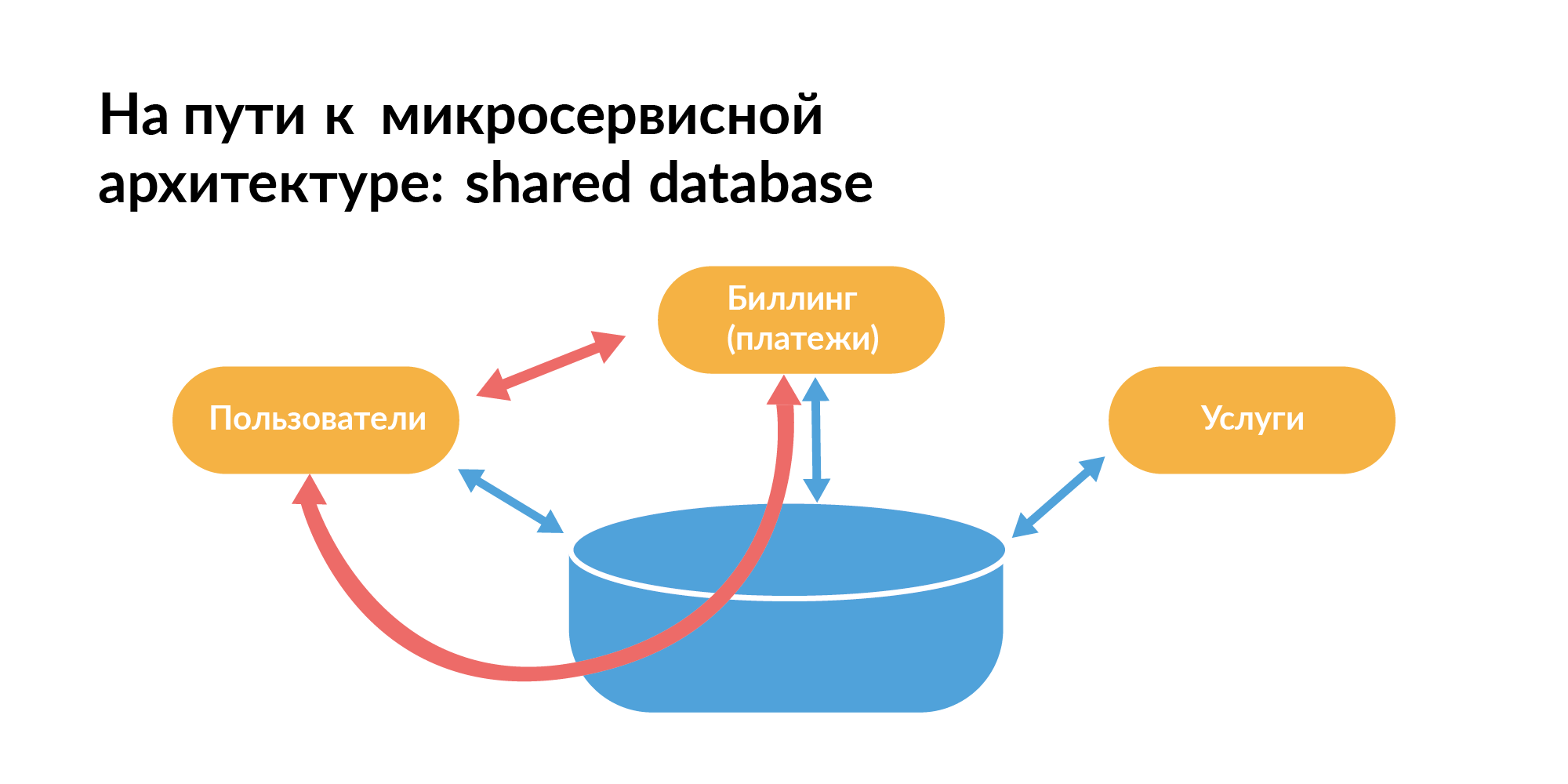
Так жить нельзя, потому что вы не можете изолированно тестировать сервисы, когда между ними помимо прямой связи есть еще связь через базу. Один сервис запросами может замедлять другой сервис. Это плохо.

С точки зрения работы с базами для микросервисной архитектуры должен применяться паттерн DataBase-per-Service — у каждого сервиса своя база. Если в базе много шардов, то база должна быть общая, чтобы они синхронизировались. Это теория, а в реальности все не так.

В реальных компаниях используют не только микросервисы, но и монолит. Есть сервисы, написанные правильно. А есть старые сервисы, которые до сих пор используют паттерн с общей базой.
Вадим Мадисон на своей презентации показывал эту картину со связанностью. Только он ее показывал без одного компонента, и сеть в ней была равномерна. В этой сети в центре есть точка, которая связана с многими точками (микросервисами). Это монолит. Он небольшой на схеме. Но на самом деле монолит большой. Когда мы говорим про реальную компанию, то вам нужно понимать нюансы сосуществования микросервисной, рождающейся, и уходящей, но по прежнему важной монолитной архитектуры.
С чего начинается переписывание монолита на микросервисную архитектуру на уровне планирования? Конечно, это доменное моделирование. Везде написано, что нужно сделать доменное моделирование. Но, к примеру, мы в Авито несколько лет создавали микросервисы без доменного моделирования. Потом им занялся я и разработчики баз данных. Мы имеем представление о полных потоков данных. Эти знания неплохо помогают спроектировать доменную модель.

У data discovery есть классическая интерпретация — это то, как работать с данными, разбросанными по разным хранилищам, чтобы приводить к совокупным выводам и делать какие-нибудь правильные выводы. На самом деле это все маркетинговый bullshit. Эти определения про то, как все данные с микросервисов загрузить в хранилище. Про это у меня были доклады несколько лет назад, останавливаться на этом не будем.
Я вам расскажу про другой процесс, который ближе к процессу перехода на микросервисы. Хочу показать способ, как вы можете осознать сложность непрерывно эволюционирующей системы с точки зрения данных, с точки зрения микросервисов. Где посмотреть цельную картину сотен сервисов, баз, команд, людей? Фактически этот вопрос является основной идеей доклада.

Чтобы в этой микросервисной архитектуре не умереть, вам нужен digital twin. Ваша компания — это совокупность всего, что обеспечивает технологическую инфраструктуру. Вам нужно создать адекватный образ всех этих сложностей, на основе которых можно быстро решать задачи. И это не аналитическое хранилище.

Какие задачи мы можем поставить такому digital twin? Ведь все начиналось с простейшего data discovery.
Вопросы:
- В каких сервисах хранятся важные данные?
- В каких не хранятся персональные данные?
- У вас сотни баз. В каких персональные данные есть? А в каких нет?
- Как важные данные ходят между сервисами?
- Например, в сервисе не было персональных данных, а потом он начал слушать шину, и они появились. Куда данные копируются, когда стираются?
- Кто с какими данными может работать?
- Кто может получить доступ напрямую через сервис, кто через базу, кто через шину?
- Кто через другой сервис может дернуть API ручку (запрос) и себе что-то скачать?
Ответом на эти вопросы практически всегда является граф элементов, граф связей. Этот граф нужно наполнить, актуализировать и поддерживать свежими данными. Мы этот граф решили назвать Persistent Fabric (в переводе — помнящая ткань). Вот его визуализация.
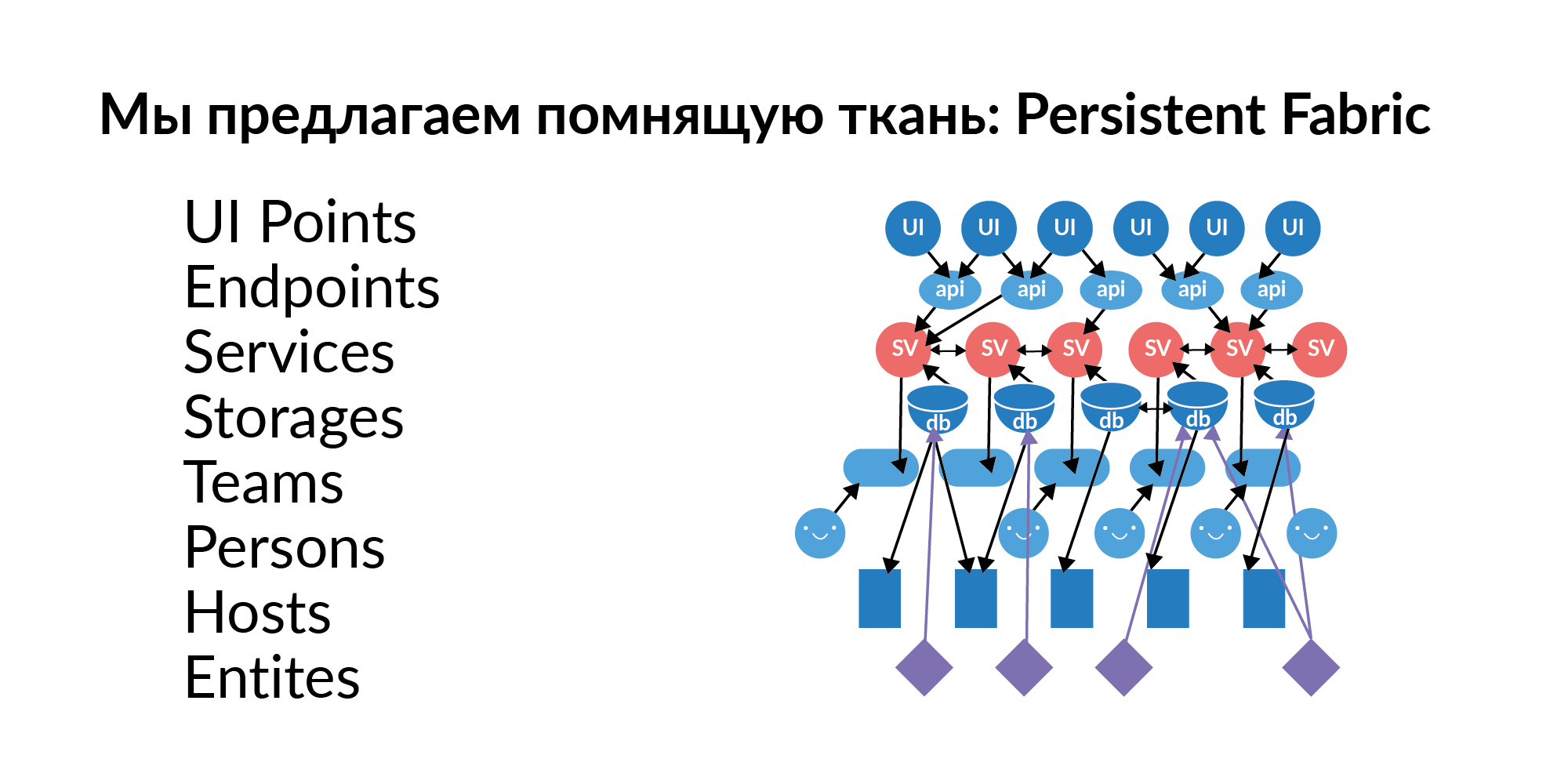
Посмотрим, что в этой помнящей ткани может быть.
Точки интерфейса. Это элементы пользовательского взаимодействия с графическим интерфейсом. На одной странице может быть несколько UI points. Это, условно говоря, пользовательские ключевые действия.
Endpoints. UI points дергают Endpoints. В русской традиции это называется ручками. Ручки сервисов. Endpoints дергают сервисы.
Сервисы. Сервисов сотни. Сервисы связаны друг с другом. Мы понимаем, какой сервис может дернуть сервис. Мы понимаем, какой вызов UI points может вызвать какие сервисы по цепочке.
Базы (в логическом смысле). База как термин хранилища плохо звучит, потому что под этим термином понимается что-то аналитическое. Сейчас мы рассматриваем базу как storage. Например, Redis, PostgreSQL, Tarantool. Если сервис использует базу, то обычно использует несколько баз.
- Для долговременного хранения данных, например, PostgreSQL.
- Redis используется как кэш.
- Tarantool, который может что-то быстро посчитать в потоке данных.
Хосты. У базы есть развертывание на хосты. Одна база, один Redis на самом деле может жить на 16 машинах (мастер кольцо) и еще на 16 живут slave. Это даёт понимание того, к каким серверам нужно ограничивать доступ, чтобы какие-то важные данные не утекли.
Сущности. В базах хранятся сущности. Примеры сущностей: пользователь, объявление, платёж. Сущности могут храниться в нескольких базах. И тут важно не просто знать, что эта сущность там есть. Важно знать, что у этой сущности один storage является Golden Source. Golden Source — это база, где сущность создается и редактируется. Все остальные базы являются функциональными кэшами. Важный момент. Если не дай бог у какой-то сущности два Golden Source, то необходимо трудоемкое согласование разделенных источников. Сущностям, лежащим в базе, нужно выдать доступ для сервиса, если хотим этот сервис обогатить новой функциональностью.
Команды. Команды, которые владеют сервисами. Сервис, который не принадлежит командам — это плохой сервис. Для него трудно найти ответственного.
Сейчас буду сильно коррелировать с докладом Вадима Мадисона, потому что он упоминал, что в сервисах отражается человек, который туда последним делал коммит. Это неплохо как отправная точка. Но в долгосрочной перспективе это плохо, потому что человек, который последний туда делал коммит, может уволиться.
Поэтому нужно знать команды, людей в них и их роли. У нас получился такой простенький граф, где на каждом слое несколько сотен элементов. Знаете ли вы систему, где это все можно хранить?
Ключевой момент. Чтобы этой Persistent Fabric жить, он должна не просто один раз наполниться. Сервисы создаются, умирают, storage выделяются, перемещаются по серверам, команды создаются, разбиваются, люди переходят в другие команды. Сущности появляются новые, добавляются в новые сервисы, удаляются. Endpoints создаются, регистрируется, пользовательские траектории с точки зрения GUI тоже переделываются. Самое важное — не то что где-то надо это технически хранить. Самое важное — сделать так, чтобы каждый слой Persistent Fabric был свежим и актуальным. Чтобы он актуализировался.
Предлагаю пройтись по слоям. Проиллюстрирую, как делается у нас. Покажу, как это можно сделать на уровне отдельных слоев.

Информацию про команды можно взять из организационной структуры 1С. Здесь я хочу проиллюстрировать, что для заполнения Persistent Fabric не нужно заполнять весь гигантский граф. Нужно чтобы каждый слой правильно заполнялся.

Информацию про людей можно взять из LDAP. Один человек может в разных командах занимать разные роли. Это абсолютно нормально. Сейчас мы сделали систему Авито People и из нее берем привязку людей к командам и занимаемые роли. Самое главное — чтобы такие простейшие данные шли, чтобы хотя бы сохраняли ссылки на концы связей, чтобы названия команд соответствовали командам из организационной структуры 1С.
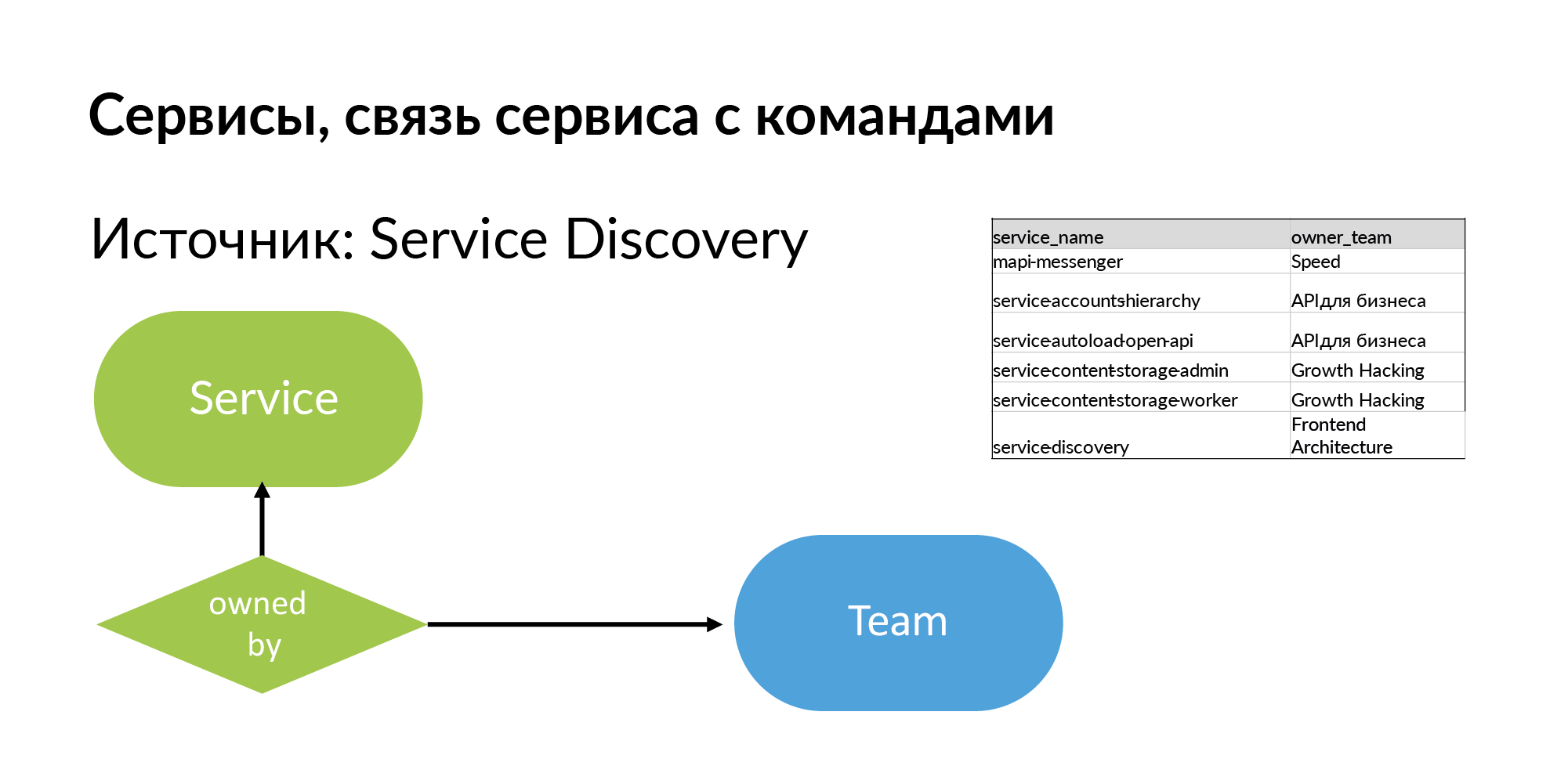
Сервисы. Для сервиса нужно получить название и команду, которая им владеет. Источник — это Service Discovery. Это система, которую упоминал Вадим Мадисон под названием Atlas. Atlas — общий реестр сервисов.
Полезно понимать, что почти все такие системы типа Atlas хранят информацию про 95% сервисов. 5% сервисов в таких системах отсутствуют, т.к. сервисы старые, созданные без регистрации в Atlas. И когда вы начинаете с этой схемой работать, вы чувствуете, чего вам не хватает.

Storages — это обобщенные хранилища. Это может быть PostgreSQL, MongoDB, Memcache, Vertica. У нас есть несколько источников Storage Discovery. Для NoSQL-баз используется своя «половинка» Атласа. Для информации о PostgreSQL-базах применяется парсинг yaml. Но они хотят сделать свой Storage Discovery более правильным.
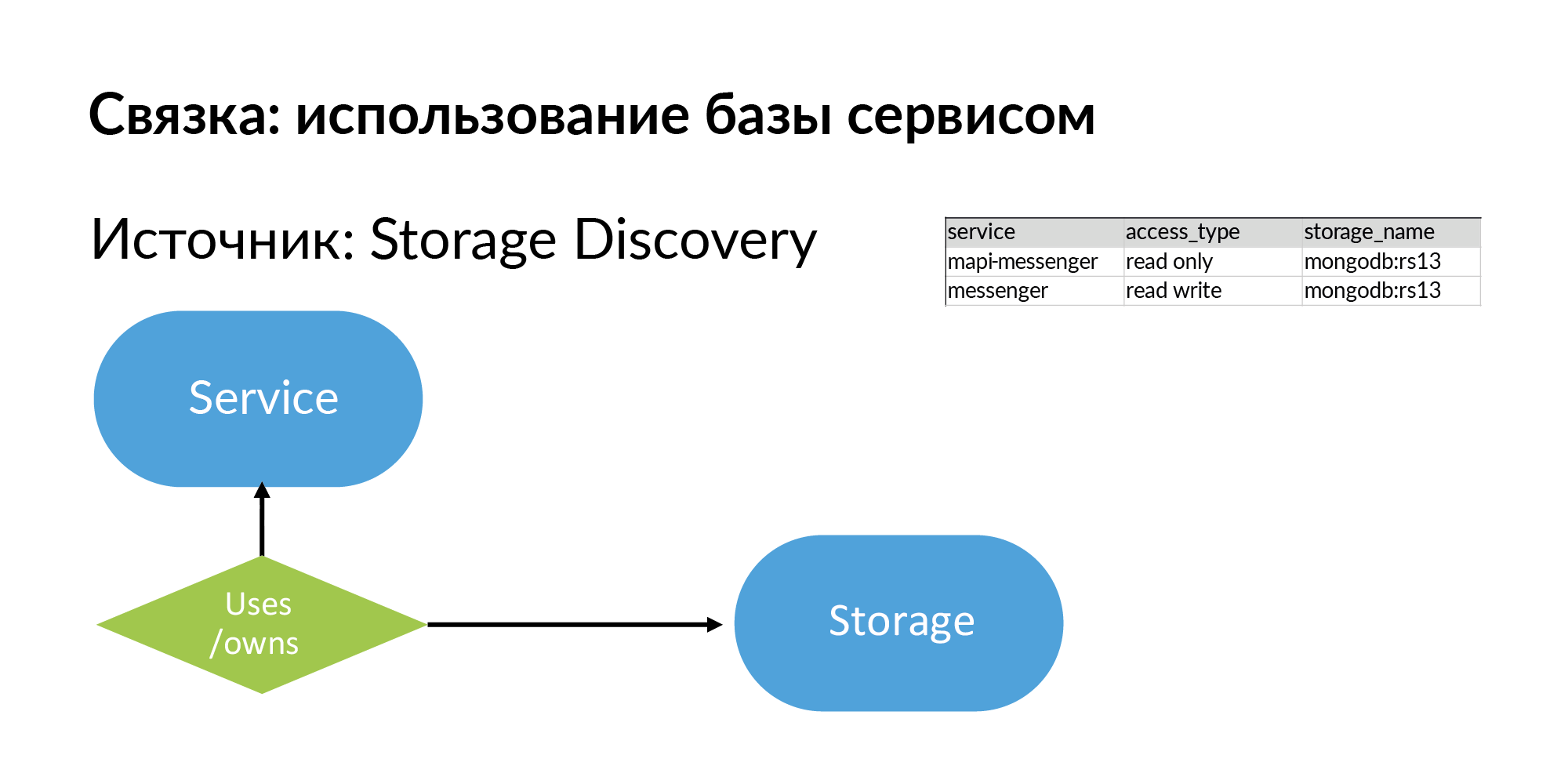
Итак, storages и информация о том, что сервис использует, ну или владеет (это разные типы) storage. Смотрите, все, что я описал, в принципе, довольно просто, это можно заполнить даже в Google Sheets.
Что с этим можно делать? Давайте представим, что это граф. Как работать с графом? Добавить его в графовую базу. Например, в Neo4j. Это уже примеры реальных запросов и примеры результатов этих запросов.
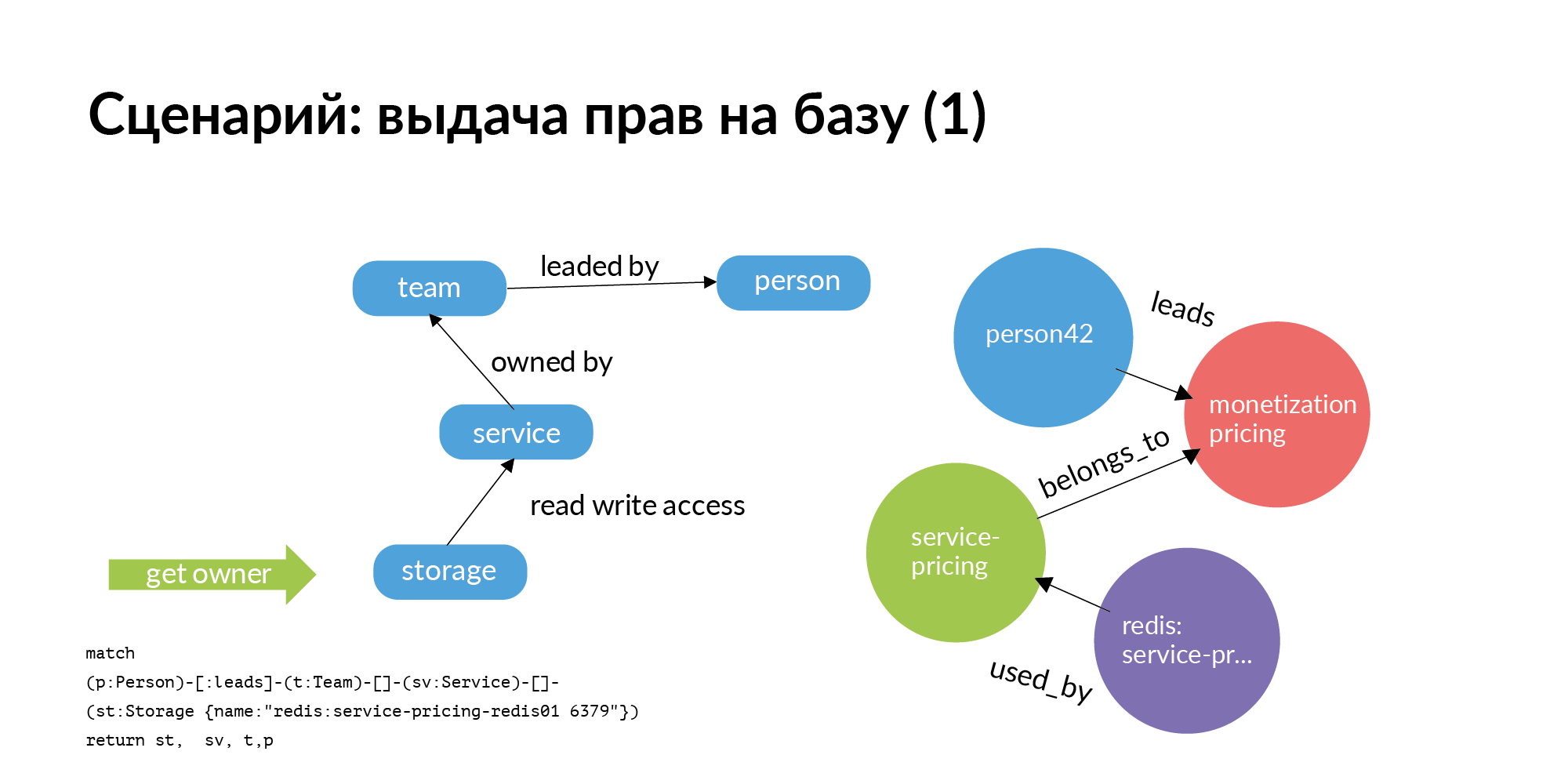
Первый сценарий. Нам нужно выдавать права на базу. База должна быть строго в сервисе. Туда должен входить только этот сервис и только члены команды, которая сервисом владеет. Но мы живем в реальном мире. Довольно часто другим командам полезно сходить в базу другого сервиса. Вопрос: у кого спросить о выдаче прав? Реально большая проблема — для сотни баз понять кто там главный. При том, что кто ее создавал, давно уволился, или перешёл на другую должность, или вообще не помнит, кто с ней работает.
И тут простейший графовый запрос (Neo4j). Вам нужен доступ к storage. Вы от storage идете к сервису, который владеет им. Переходите в команду, которая владеет сервисом. Дальше для сервиса вы узнаете, кто у этой команды TechLead. В Авито у продуктовых команд есть технический руководитель и продуктовый руководитель, который не сможет помочь по базам. На слайде на самом деле отображена только половина запроса. Доступ к storage — это не атомарная операция. Чтобы получить доступ к storage, нужно получить доступ к серверам, на которых он установлен. Это довольно интересная отдельная задача.
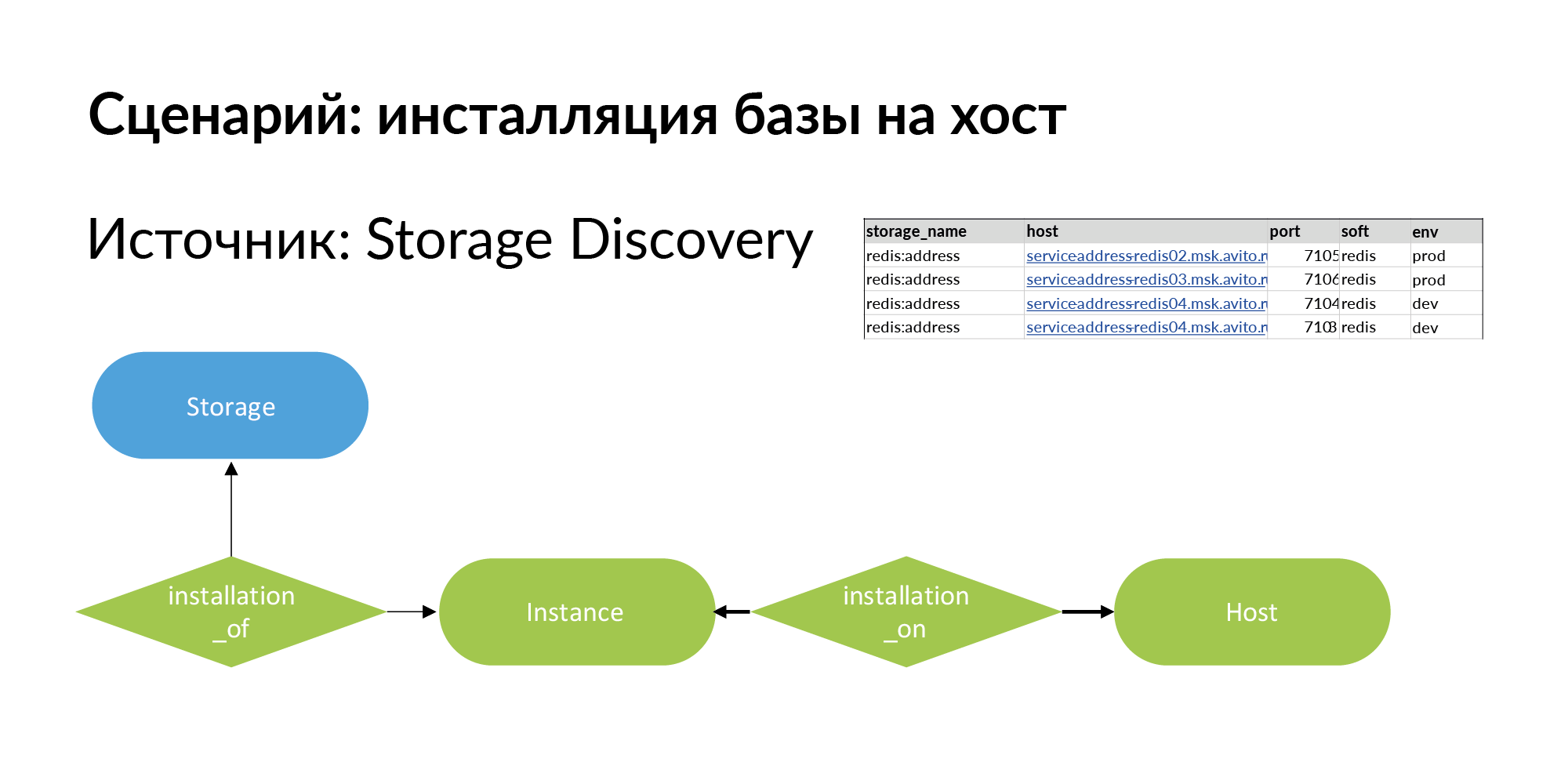
Для её решения мы добавляем новую сущность. Это инсталляция. Здесь терминологическая проблема. Есть storage, например Redis база (redis:address). Есть host — это может быть физическая машина, lxc-контейнер, kubernetes. Установку storage на хост мы называем Instance.
У него может быть четыре установки на три хоста, как показано в примере выше. Storage для production разумно установить на отдельные физические машины для увеличения performance. Для dev-среды вам достаточно установить на один хост и назначить Redis разные порты.

Первый запрос по выдаче прав на базу ушел к руководителю. Руководитель подтвердил, что права можно выдать.
Дальше идёт вторая часть запроса. Второй запрос от storage идет к instance и host. Этот запрос рассматривает все инсталляции для соответствующего окружения. На слайде — пример для production окружения. Исходя из этого выдаются уже права на подключение к конкретным хостам, конкретным портам. Это был пример запроса по выдаче прав для сотрудника не из команды.

Рассмотрим пример, когда в команду нужно взять нового сотрудника. Ему нужно выдать доступ (для начала — read only) ко всем сервисам, ко всем storage этой команды. На слайде реальная команда с неполной выборкой. Зеленые круги это руководители команд. Розовые круги — это команды. Желтые — сервисы. У ряда жёлтых сервисов есть синие storage. Серые — это хосты. Фиолетовые — это инсталляции storage на хосты. Это пример для небольшого юнита. Но есть много юнитов, у которых сервисов не 7, а 27. Для таких юнитов картинка будет большая. Если использовать есть Persistent Fabric, вы можете сделать запросы в ней и получить ответы списком.

Давайте продолжим наполнять нашу умную ткань и поговорим о бизнес-сущностях. Сущности в Авито — это объявления, пользователи, платежи и так далее. Из моих публикаций (HP Vertica, проектирование хранилища данных, больших данных, Vertica+Anchor Modeling = запусти рост своей грибницы) про хранилища данных вы знаете, что в Авито этих сущностей сотни. На самом деле все их логировать не обязательно. Откуда можно получить список сущностей? Из аналитического хранилища. Можно выгрузить информацию о том, откуда они эту сущность берут. На первом этапе этого достаточно.
Далее мы развиваем эти знания: для каждой сущности составляем список хранилищ где она есть. Там же указываем, что storage же хранит сущность как кэш или storage хранит сущность как Golden Source, то есть является ее первоисточником.

Когда вы заполняете этот граф, у вас появляется возможность делать запросы. У вас есть некоторая сущность, и вам нужно понять: в каких сервисах живет сущность, где она отражается, в каких storage, на какие хосты инсталлирована? Например, при обработке персональных данных нужно уничтожать лог-файлы. Для этого очень важно понять, на каких физических машинах могут остаться лог-файлы.
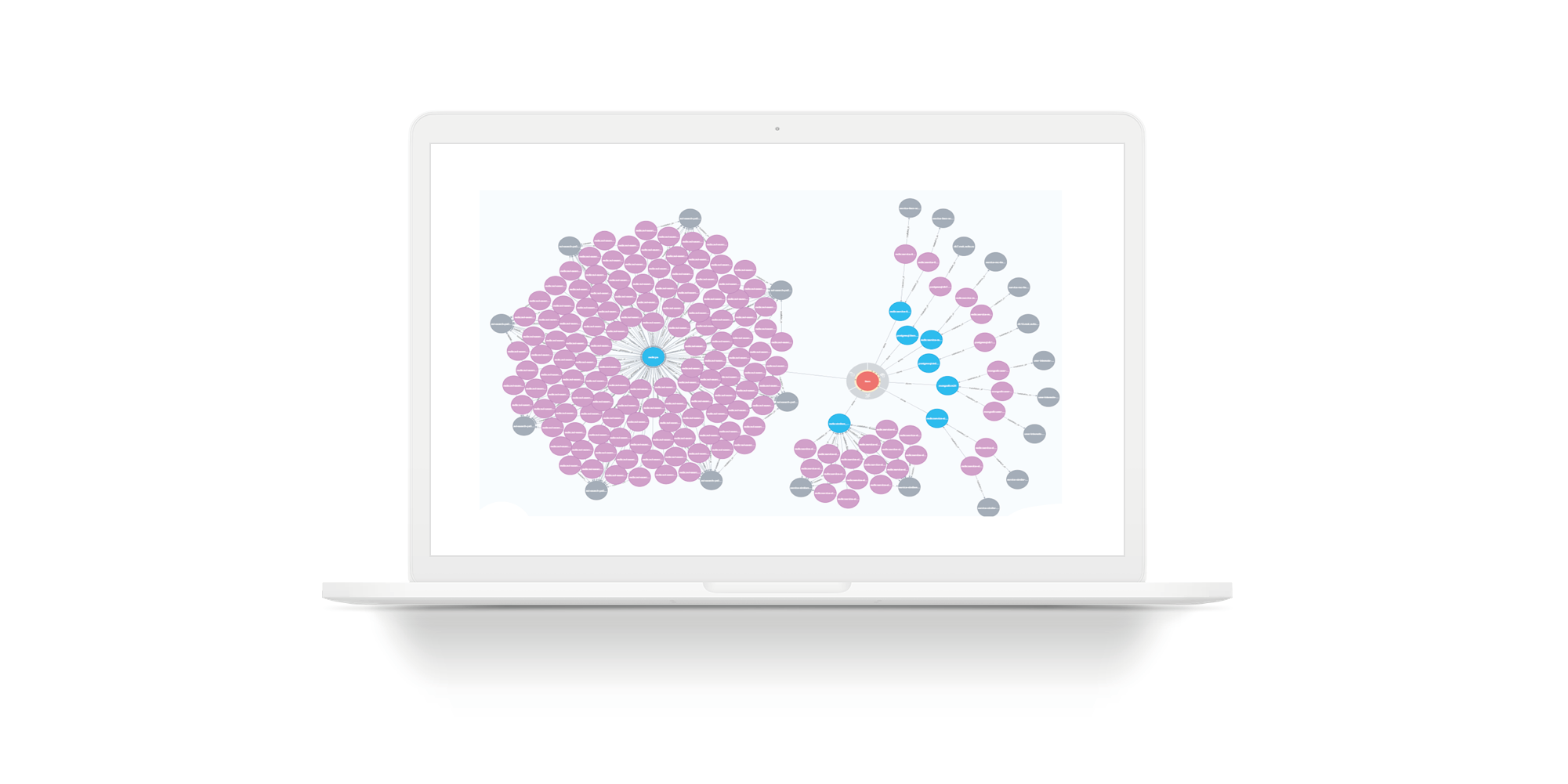
На слайде иллюстрация простого запроса для воображаемой сущности. Количество storage уменьшено, чтобы граф влез на слайд. Красные круги — это сущности. Синие круги — это базы, где эта сущность находится. Остальное как на предыдущих слайдах: серые круги это хосты, фиолетовые — инсталляции storage на хосты.
Соответственно, если вы хотите пройти PCI DSS, вам нужно ограничить доступ к определенным сущностям. Для этого вам нужно ограничить доступ к серым кругам. Если нужно имеется ввиду real-time доступ, то закрываем доступ к фиолетовым кругам. Это статическая информация.
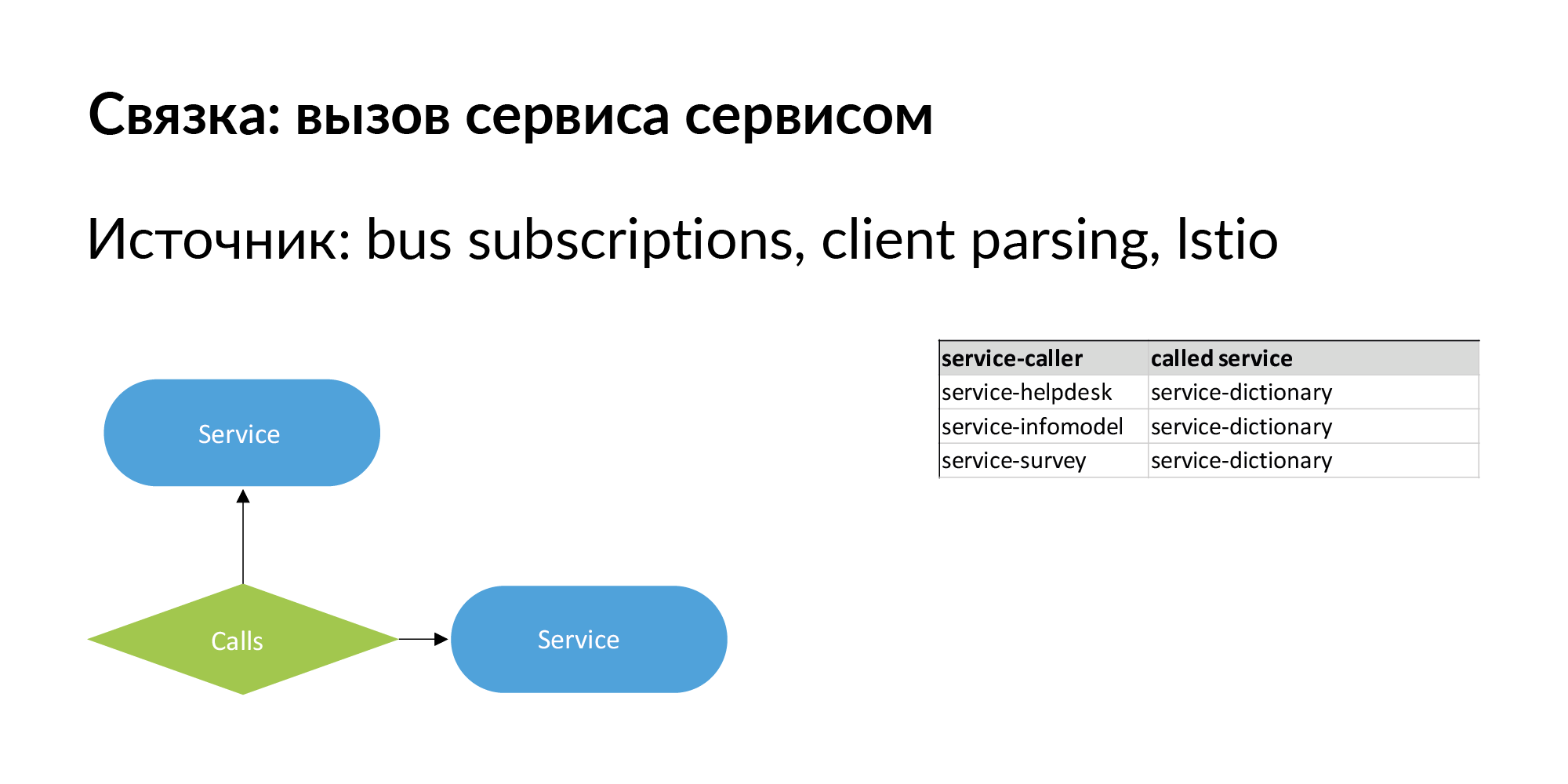
Когда мы говорим про микросервисную архитектуру, самое важное — это то, что она меняется. Важно иметь не просто иерархическую связь между сущностями, но и одноуровневые связи. Связка сервисов — пример одноуровневых связей, которую мы неплохо прокачали и используем. Связка вида «сервис вызывает сервис». Тут есть информация о прямых вызовах — сервис вызывает API другого сервиса.
Здесь также должна быть информация о связи вида: сервис №1 отправляет в шину (очередь) события, a сервис №2 на это событие подписан. Это похоже на асинхронную медленную связь, проходящую через шину. Такая связь тоже важна с точки зрения движения данных. С помощью подобных связей можно проверить работу сервисов, если поменялась версия сервиса, на которые они подписаны.
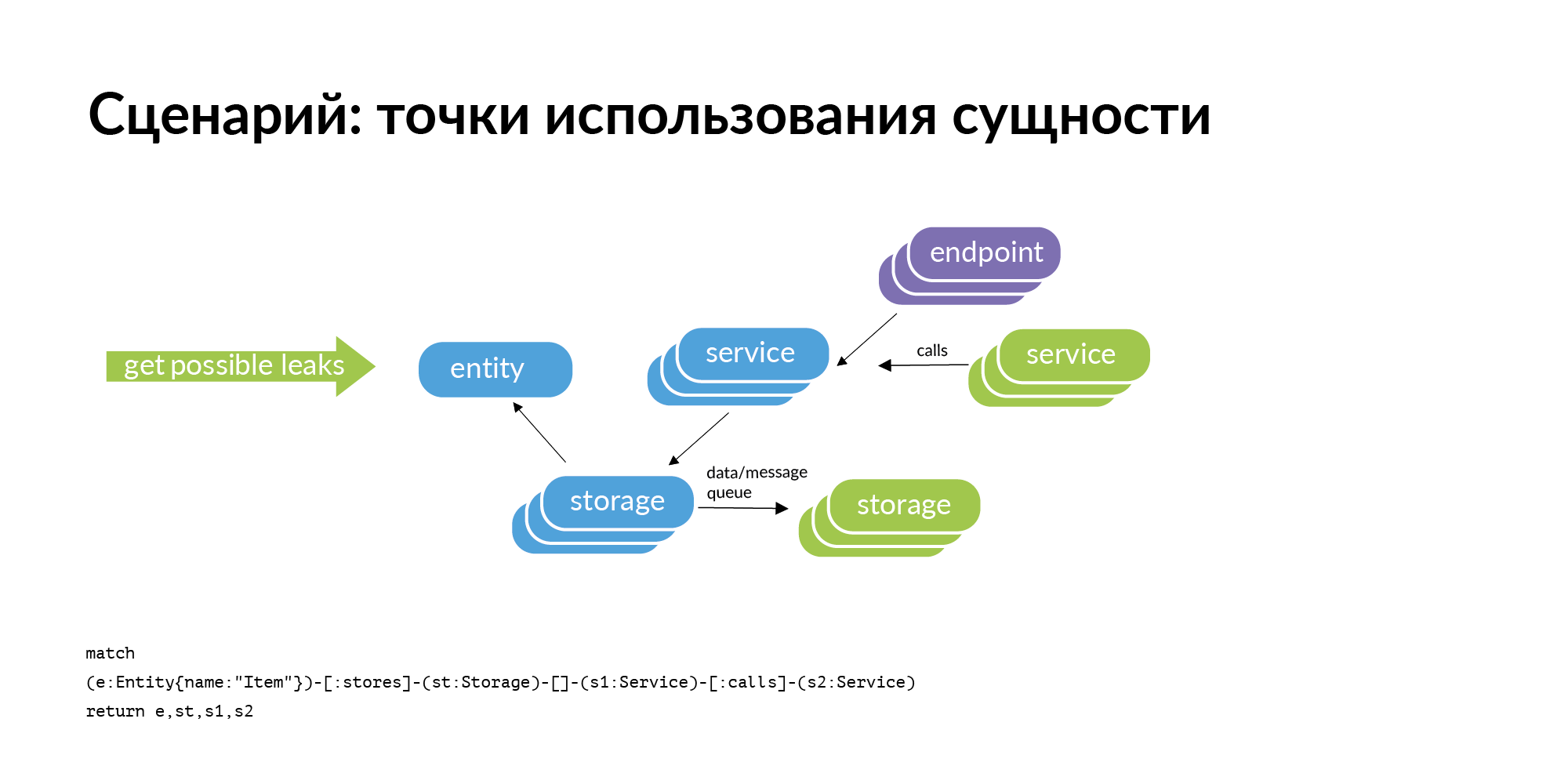
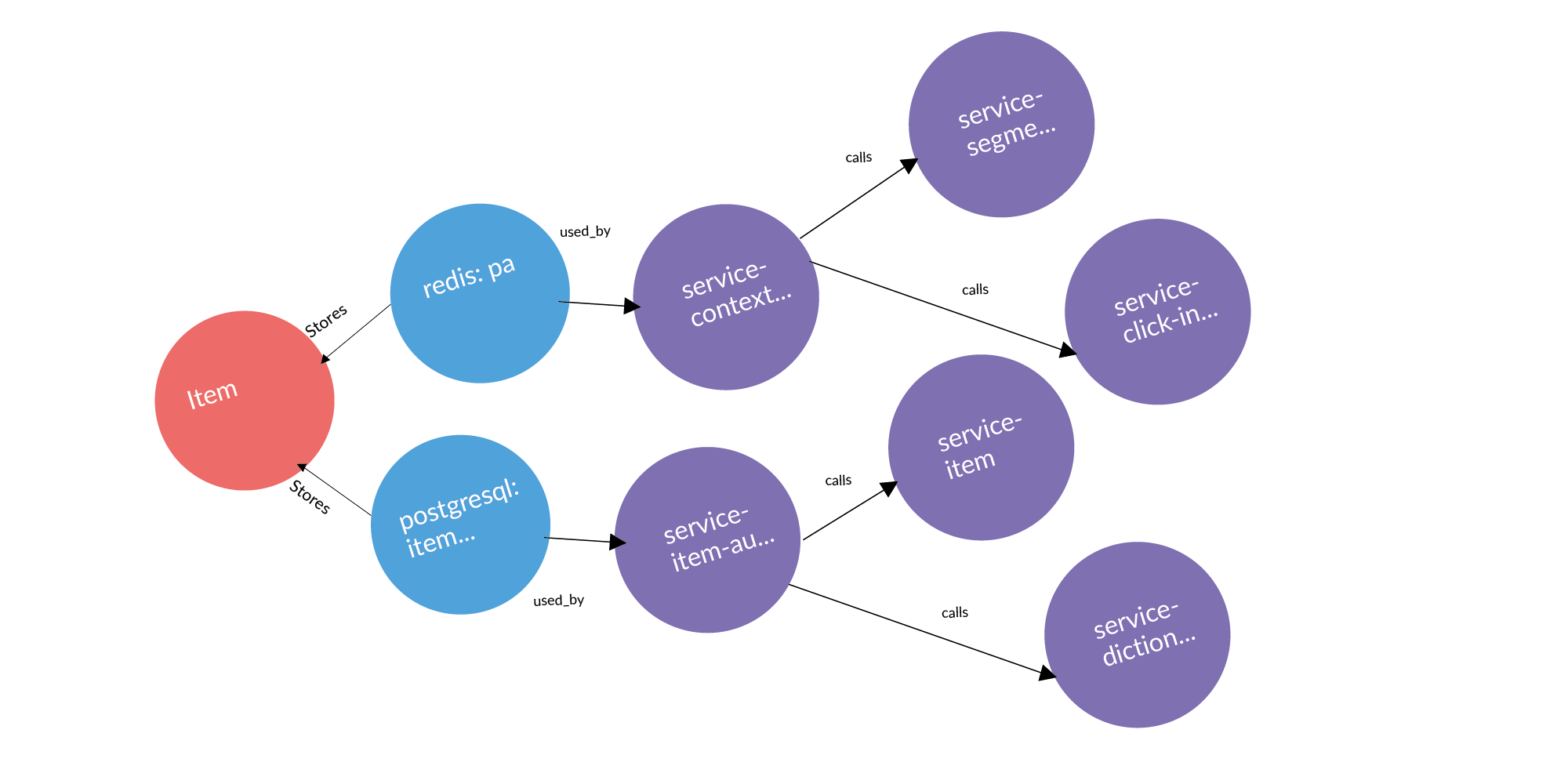
Есть сущность и мы знаем, что она хранится в определенных storage. Если мы рассматриваем задачу поиска точек использования сущности, то очевидный запрос, который у нас возникает, это проверка периметра. Storage принадлежат некоторым сервисам. Куда эта сущность может утечь (быть скопирована) из периметра? Она может утечь через вызовы сервисов. Сервис обратился, получил и сохранил у себя пользователя. Она может утечь через шины. Шины могут вас могут быть соединены друг с другом, используя RabbitMQ, Londiste. На слайде Londiste мы еще не подгрузили. А вот вызовы уже подгрузили.
Вот пример реального запроса: объявление, две базы, где оно хранится, два сервиса, которые владеют этими базами. После трех колонок идут сервисы, которые работают с сервисами, владеющими этой сущностью. Это потенциальные точки утечки, которые стоит добавить.

Endpoints. Вадим упоминал, что для построения реестра endpoints сервисов можно использовать документацию. Ещё можно получить эту информацию из мониторинга. Если Endpoint важный, то сами разработчики добавят его в мониторинг. Если Endpoint не мониторится, то он нам не нужен.
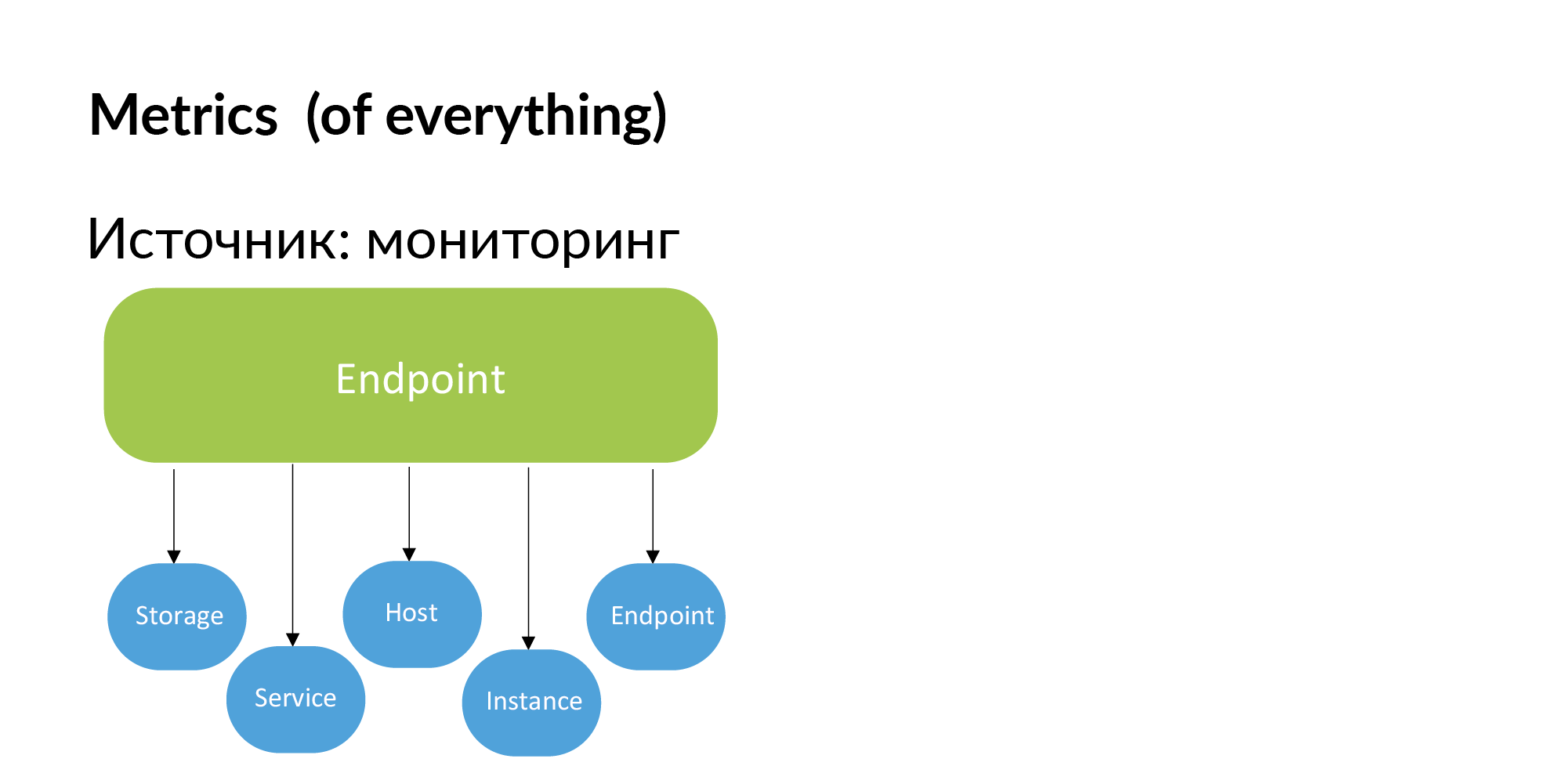
Соответственно, из мониторинга можно получить метрики. Привязка метрик к storage, к сервисам, к хостам, к instance (шардам баз) и endpoint.

Когда у вас возникает сбой, например, endpoint выдает HTTP код 500, то, чтобы отследить корень проблемы, необходимо сделать запрос по этому endpoint. От endpoint переходите к сервису, переходите к сервисам, которые этот сервис вызывает, от сервисов идете к storage, от storage идете instance и хостам.
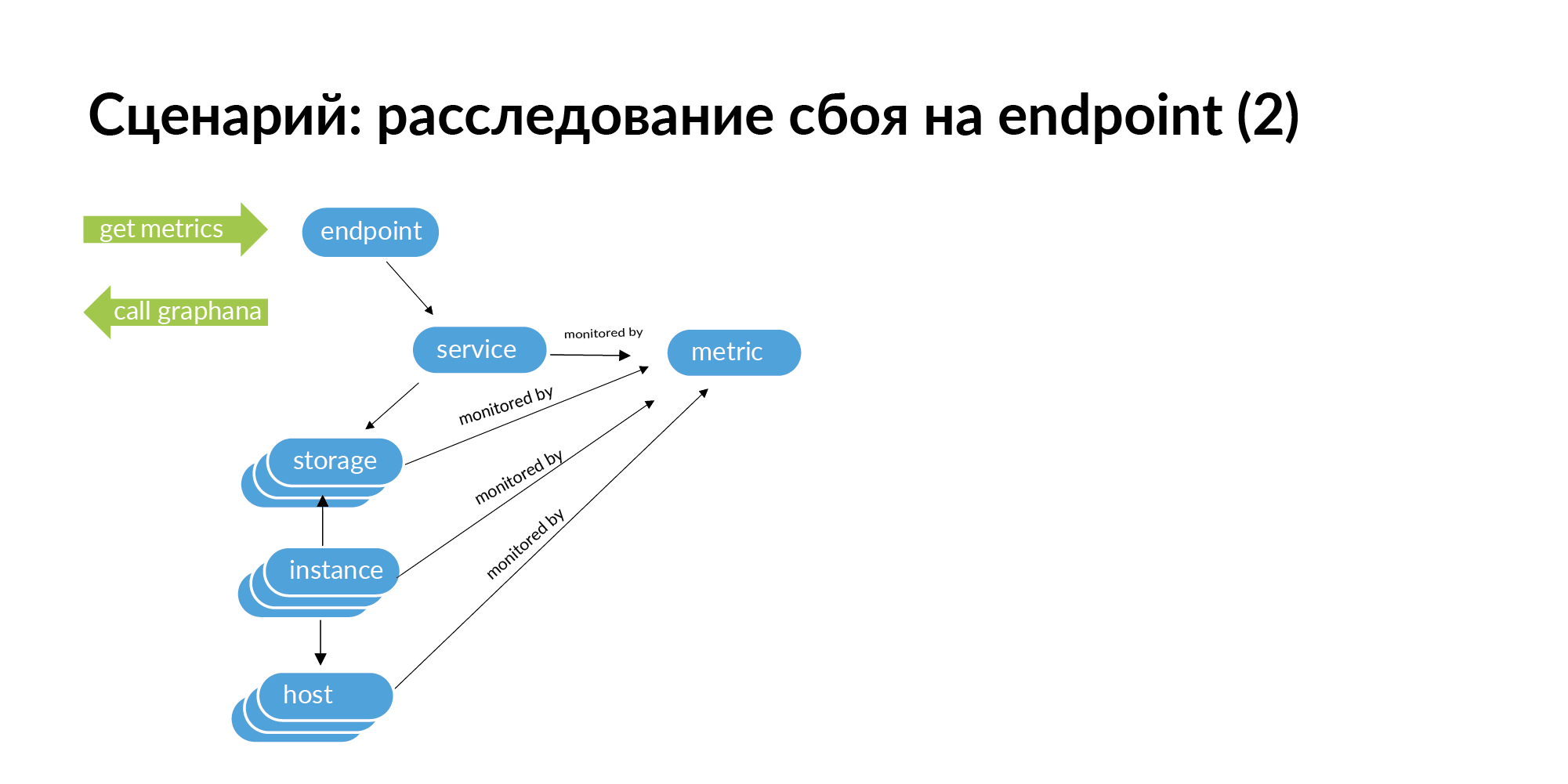
Далее, если пройти этот граф вниз, на его основе можно получить список идентификаторов для мониторинга. Вы можете посмотреть для этого endpoint всю цепочку вниз, что может вызвать сбой. В микросервисной архитектуре сбой на endpoint может быть вызван сбоем сети на каком-то сервере, на котором развернут один шард базы. В мониторинге это видно, но при большой структуре сервисов проверять все сервисы в мониторинге очень трудозатратно.

Тестирование. Чтобы адекватно тестировать микросервис, вам нужно проверять сервис с другими сервисами, которые нужны ему для работы. Вам нужно поднять в вашем тестовом окружении сервисы, которые он вызывает. А для вызываемых сервисов поднять все базы. В нашей помнящей ткани получается связный подграф. В этом графе не все связи нужны, некоторыми можно пренебречь. Этот подграф можно изолированно нагрузочно тестировать как полностью замкнутую систему.
Было бы здорово сейчас показать граф сущностей Авито, где изолированные подграфы микросервисов, которые можно поднять независимо, можно тестировать и выкатывать в production. На самом деле, оказалось что подграф вызовов у почти любого микросервиса входит и выходит из монолита. Это — иллюстрация того, что если разрабатывать микросервисы и не думать о таких последствиях, то в итоге микросервисная архитектура все равно не будет работать без монолита и не позволяет проводить изолированное тестирование не позволяет.
Но подобное графовое представление позволяет вам найти кандидаты на то, чтобы стать изолированными подграфами. Это подмножество сервисов почти готово для того, чтобы работать изолированно. Необходимо только отрефакторить пару вызовов. Это позволяет приоритезировать разбиение монолита в части уменьшения связанности архитектуры.
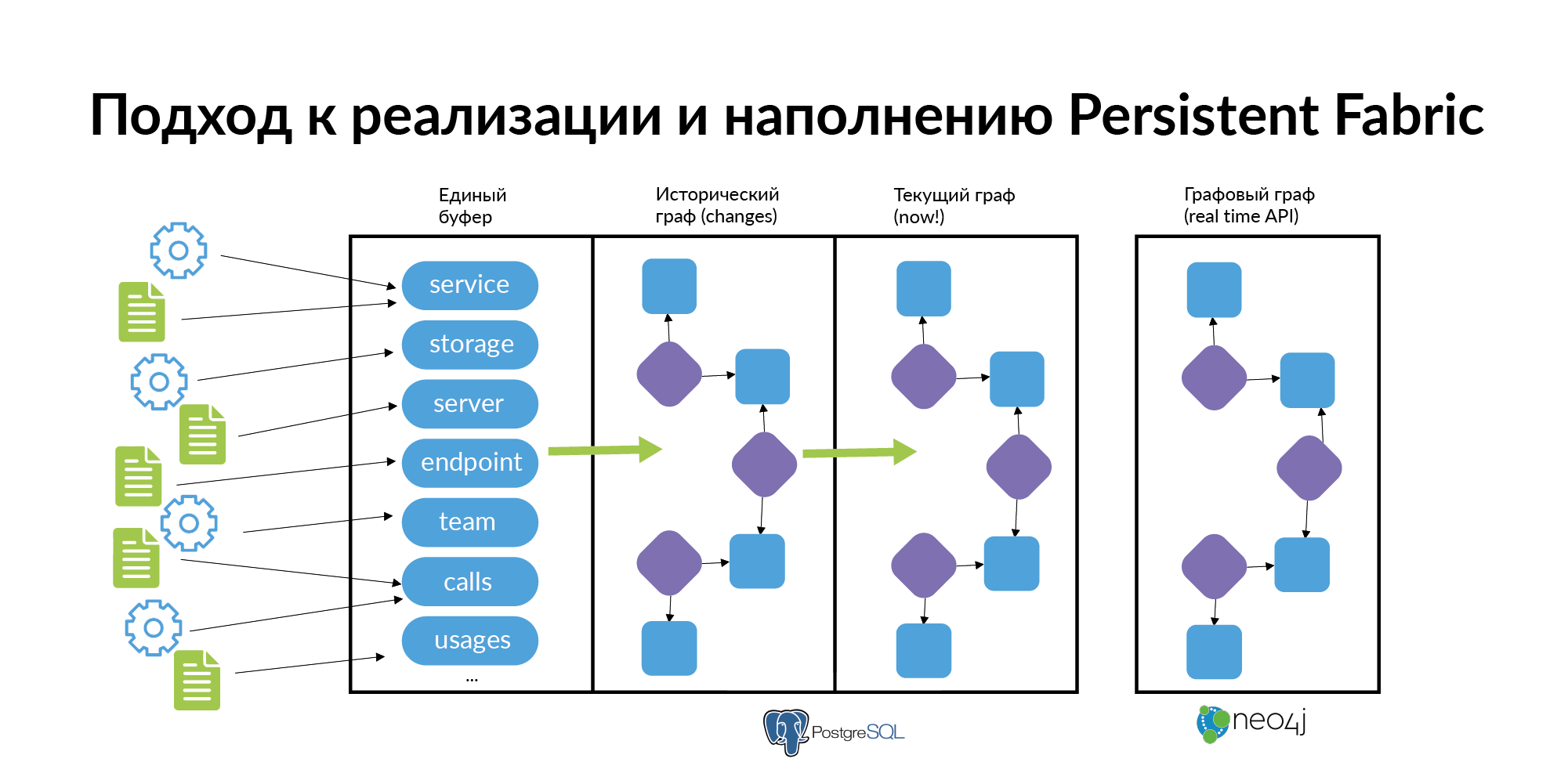
И напоследок — о том, как это всё поддерживать и наполнять. Это довольно просто сделать при соблюдении нескольких правил.
- Нельзя заставлять людей заполнять все зависимости всех сервисов. Нужно чтобы каждый источник заполнял только свой небольшой кусок информации. Слой сервисов заполняется из основного источника. Отсутствующие в этом источнике сервисы заполняются из ручных инструментов. Из второго источника заполняются storage. Из третьего — сервера. Из четвертого endpoint. Из отдельных источников заполняются ссылки, что сервис принадлежит команде, что человек стал техлидом и т.п. Информация должна заполнятся быстро и просто.
- Информация о графе с соблюдением историчности должна загружаться в базу. Так как реальная микросервисная архитектура постоянно «дышит» и меняется. Сервисы возникают, умирают, появляются новые базы, появляется connection, старый connection отменяют, люди ходят между командами. При расследовании инцидентов полезно знать, в каком сервисе живет сущность и в каком сервисе сущность жила раньше. (Как делать граф исторических связей, можно узнать в моём посте про Anchor Modeling). Большинству людей для того чтобы работать с данными историчность не нужна. Им нужен актуальный срез «на сейчас». На основании исторического графа должна строится витрина графа на текущий момент. В Авито используется база данных Neo4j, которую можно использовать для визуализации.
- Чем больше сотрудники используют граф, тем больше у них появляются стимул самим следить за его актуальностью. Каждый слой этого ткани может наполнить отдельная команда. Например, UI points наполняют frontend разработчики, сервисы заполняют backend разработчики, storage заполняют DBA, серверы заполняют DevOps инженеры, сущности заполняют аналитики.
Задачи in-progress
По некоторым направлениям у нас продолжается работа.
Мы хотим добавить еще информацию о потоке данных через шину (Londiste, PGQ, RabbitMQ).
Еще мы пытаемся добавить графы пользовательских траекторий. Граф связи UI points формируется на информации о том как пользователи ходят между ними. Сейчас это сделано на уровне клиентского логирования. В данное время переходим к объединению этой информации и пробросов в ткань (Persistent Fabric), чтобы можно было пользовательский опыт оттранслировать в UI points, оттуда в Endpoint, оттуда в сервисы. Из этой информации понять чем у нас пользователи чаще всего пользуются и узнать, например, почему небольшой сервис, не очень нагруженный и не очень важный, так аффектит пользовательский опыт.




