
Большинство компиляторов имеют следующую архитектуру:

В данной статье я собираюсь детально препарировать эту архитектуру, элемент за элементом.
Можно сказать, что эта статья — дополнение к огромному количеству существующих ресурсов на тему компиляторов. Она является автономным источником, который позволит вам разобраться в основах дизайна и реализации языков программирования.
Целевая аудитория статьи — люди, чье представление о работе компиляторов крайне ограничено (максимум — то, что они занимаются компилированием). Однако я жду, что читатель разбирается в структурах и алгоритмах данных.
Статья ни в коем случае не посвящена современным производственным компиляторам с миллионами строк кода — нет, это краткий курс «компиляторы для чайников», помогающий разобраться, что такое компилятор.
Введение
Сейчас я работаю над системным языком Krug, вдохновленным Rust и Go. В статье я буду обращаться к Krug в качестве примера для иллюстрации своих мыслей. Krug находится в стадии разработки, но уже доступен на https://github.com/krug-lang в репозиториях caasper и krug. Язык не совсем типичен по сравнению с обычной архитектурой компиляторов, что отчасти и вдохновило меня на написание статьи — но об этом позже.
Спешу сообщить, что я ни в коей степени не являюсь специалистом по компиляторам! У меня нет докторской степени, и я не проходил никакого формального обучения — все описанное в статье я изучил самостоятельно в свободное время. Также должен сказать, что я не описываю фактический, единственно верный подход к созданию компилятора, а, скорее, представляю базовые методы, пригодные для создания небольшого «игрушечного» компилятора.
Фронтенд
Вернемся к диаграмме выше: направленные к полю frontend стрелочки слева — известные и любимые нами языки вроде C. Фронтенд выглядит примерно так: лексический анализ -> парсер.
Лексический анализ
Когда я начинал изучать компиляторы и дизайн языков, мне сказали, что лексический анализ — то же самое, что и токенизация. Этим описанием мы и воспользуемся. Анализатор берет вводные данные в форме строк или потока символов и распознает в них паттерны, которые он нарезает в токены.
В случае компилятора на вход он получает написанную программу. Она считывается в строку из файла, а анализатор токенизирует ее исходный код.
enum TokenType {
Identifier,
Number,
};
struct Token {
std::string Lexeme;
TokenType type;
// ...
// It's also handy to store things in here
// like the position of the token (start to end row:col)
};В данном фрагменте, написанном на C-образном языке, можно увидеть структуру, содержащую вышеупомянутую lexeme, а также TokenType, который служит для распознавания данной лексемы.
Примечание: статья не является инструкцией для создания языка с примерами — но для лучшего понимания я буду время от времени вставлять фрагменты кода.
Обычно анализаторы являются простейшими компонентами компилятора. Весь фронтенд, по сути, довольно прост по сравнению с остальными кусочками паззла. Хотя это во многом и зависит от вашей работы
Возьмем следующий кусочек кода на C:
int main() {
printf("Hello world!\n");
return 0;
}Считав его из файла в строку и проведя линейное сканирование, вы, возможно, сможете нарезать токены. Мы идентифицируем токены естественным образом — видя, что int — это «слово», а 0 в операторе возврата — «число». Лексический анализатор проделывает ту же процедуру, что и мы — позже мы разберемся в этом процессе детальнее. Например, проанализируем числа:
0xdeadbeef — HexNumber (шестнадцатеричное число)
1231234234 — WholeNumber (целое число)
3.1412 — FloatingNumber (число с плавающей запятой)
55.5555 — FloatingNumber (число с плавающей запятой)
0b0001 — BinaryNumber (двоичное число)Определение слов может представлять сложность. Большинство языков определяют слово как последовательность букв и цифр, а идентификатор, как правило, должен начинаться с буквы или нижнего подчеркивания. Например:
123foobar := 3
person-age := 5
fmt.Println(123foobar)В Go этот код не будет считаться правильным и будет разобран на следующие токены:
Number(123), Identifier(foobar), Symbol(:=), Number(3) ...Большинство встречающихся идентификаторов выглядят так:
foo_bar
__uint8_t
fooBar123Анализаторам придется решать и другие проблемы, связанные, например, с пробелами, многострочными и однострочными комментариями, идентификаторами, числами, системами счисления и форматированием чисел (например, 1_000_000) и кодировками (например, поддержкой UTF8 вместо ASCII).
И если вы думаете, что можете прибегнуть к регулярным выражениям — лучше не стоит. Гораздо проще написать анализатор с нуля, но я очень рекомендую прочесть эту статью от нашего царя и бога Роба Пайка. Причины, по которым нам не подойдет Regex, описаны во множестве других статей, так что этот момент я опущу. К тому же, писать анализатор гораздо интереснее, чем мучиться над длинными многословными выражениями, загруженными на regex101.com в 5:24 утра. В своем первом языке я использовал для токенизации функцию
split(str) — и далеко не продвинулся.Парсинг
Парсинг несколько сложнее, чем лексический анализ. Существует множество парсеров и парсеров-генераторов — здесь начинается игра по-крупному.
Парсеры в компиляторах обычно принимают входные данные в форме токенов и строят определенное дерево — абстрактное синтаксическое дерево или дерево парсинга. По своей природе они сходны, но имеют некоторые различия.
Эти этапы можно представить в виде функций:
fn lex(string input) []Token {...}
fn parse(tokens []Token) AST {...}
let input = "int main() { return 0; }";
let tokens = lex(input);
let parse_tree = parse(tokens);
// ....Обычно компиляторы строятся из множества маленьких компонентов, которые берут входные данные, меняют их или преобразуют их в различные выходные данные. Это одна из причин, по которым функциональные языки хорошо подходят для создания компиляторов. Другие причины — прекрасное сопоставление с эталоном и довольно обширные стандартные библиотеки. Прикольный факт: первая реализация компилятора Rust была на Ocaml.
Советую держать эти компоненты как можно более простыми и автономными — модульность сильно облегчит процесс. По-моему, то же можно сказать и о многих других аспектах разработки ПО.
Деревья
Дерево парсинга
Что это, блин, такое? Также известное как дерево грамматического разбора, это густое дерево служит для визуализации программы-источника. В них содержится вся информация (или большая ее часть) о программе ввода, обычно совпадающая с тем, что описано в грамматике вашего языка. Каждый узел дерева будет концевым или неконцевым, например, NumberConstant или StringConstant.
Абстрактное синтаксическое дерево
Как можно понять из названия, АСД — абстрактное синтаксическое дерево. Дерево парсинга содержит множество (часто излишней) информации о вашей программе, а в случае АСД она не требуется. АСД не нуждается в бесполезной информации о структуре и грамматике, которая не влияет на семантику программы.
Предположим, в вашем дереве есть выражение типа ((5+5)-3)+2. В дереве парсинга вы хранили бы его полностью, вместе со скобками, операторами и значениями 5, 5, 3 и 2. Но с АСД можно просто провести ассоциации — нам нужно знать только значения, операторы и их порядок.
На картинке ниже показано дерево для выражения a+b/c.
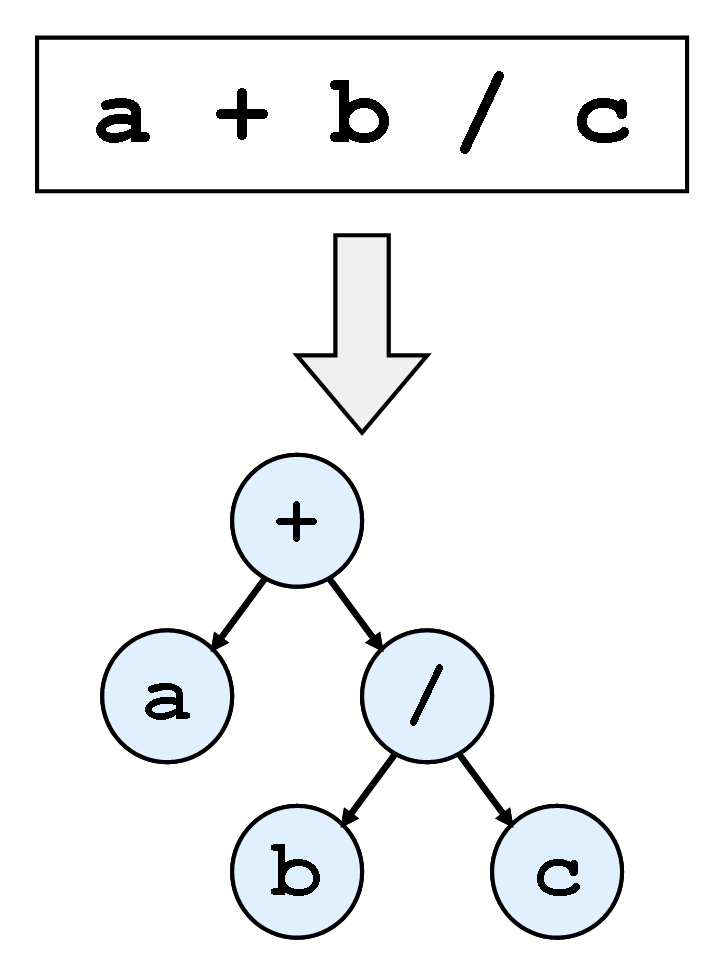
АСД можно представить следующим образом:
interface Expression { ... };
struct UnaryExpression {
Expression value;
char op;
};
struct BinaryExpression {
Expression lhand, rhand;
string op; // string because the op could be more than 1 char.
};
interface Node { ... };
// or for something like a variable
struct Variable : Node {
Token identifier;
Expression value;
};Это представление достаточно ограничено, но, надеюсь, вы сможете увидеть, как будут структурированы ваши узлы. Для парсинга можно прибегнуть к следующей процедуре:
Node parseNode() {
Token current = consume();
switch (current.lexeme) {
case "var":
return parseVariableNode();
// ...
}
panic("unrecognized input!");
}
Node n = parseNode();
if (n != null) {
// append to some list of top level nodes?
// or append to a block of nodes!
}Надеюсь, что вы уловили суть того, как будет проходить пошаговый парсинг остальных узлов, начиная с высокоуровневых языковых конструкций. Как именно реализуется синтаксический анализатор с рекурсивным спуском, вам нужно изучить самостоятельно.
Грамматика
Проведение парсинга в АСД из набора токенов может оказаться непростым. Обычно вам следует начать с грамматики вашего языка. По сути, грамматика определяет структуру вашего языка. Существует несколько языков для определения языков, которые могут описать (или разобрать) сами себя.
Пример языка для определения языков — расширенная форма Бэкуса-Наура (РБНФ). Она представляет собой вариацию БНФ с меньшим количеством угловых скобок. Вот пример РБНФ из статьи Википедии:
digit excluding zero = "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;
digit = "0" | digit excluding zero ;Продукционные правила определены: они указывают, какой шаблон терминалов составляет «нетерминал». Терминалы — часть алфавита, например, токен if или 0 и 1 в примере выше — терминалы. Нетерминалы — их противоположность, они находятся в левой части продукционных правил, и их можно считать переменными или «именованными указателями» на группы терминалов и нетерминалов.
Во многих языках имеются спецификации, которые содержат грамматику. Например, для Go, Rust и D.
Анализаторы с рекурсивным спуском
Рекурсивный спуск — самый простой из многочисленных подходов к парсингу.
Анализаторы с рекурсивным спуском — нисходящие, основанные на рекурсивных процедурах. Гораздо проще написать парсер, ведь в вашей грамматике нет левой рекурсии. В большинстве «игрушечных» языков этой техники достаточна для парсинга. В GCC используется написанный вручную нисходящий парсер, хотя до того использовался YACC.
Впрочем, с парсингом этих языков могут возникать проблемы. В особенности C, где
foo * barможет быть интерпретировано как
int foo = 3;
int bar = 4;
foo * bar; // unused expressionили как
typedef struct {
int b;
} foo;
foo* bar;
bar.b = 3;В реализации Clang также используется анализатор с рекурсивным спуском:
Поскольку это обычный код для C++, рекурсивный спуск позволяет новичкам легко его понять. Он поддерживает специально созданные правила и другие странные штуки, требуемые C/C++ и помогает с легкостью реализовать диагностику и исправление ошибок.
Также стоит обратить внимание на другие подходы:
- нисходящий LL, рекурсивный спуск
- восходящий LR, сдвиг, восходящий спуск
Парсеры-генераторы
Еще один хороший способ. Конечно, есть и минусы — но это можно сказать про любой другой выбор, который делают программисты при создании ПО.
Парсеры-генераторы работают очень резво. Использовать их проще, чем написать собственный анализатор и получить качественный результат — хотя они и не очень дружелюбны к пользователю и не всегда выводят сообщения об ошибках. К тому же, вам придется учиться использовать парсер-генератор, а при раскрутке компилятора, вероятно, придется раскручивать и парсер-генератор.
Пример парсера-генератора — ANTLR, есть и множество других.
Думаю, что этот инструмент подходит для тех, кому не хочется тратить время на написание фронтенда, и кто предпочел бы написать середину и бэкенд компилятора/интерпретатора и анализировать что бы то ни было.
Применение парсинга
Если вы еще не поняли сами. Даже фронтенд компилятора (lex/parse) может применяться и для решения других проблем:
- подсветка синтаксиса
- парсинг HTML/CSS для механизма визуализации
- транспиляторы: TypeScript, CoffeeScript
- компоновщики
- REGEX
- анализ интерфейсных данных
- парсинг URL
- форматирование инструментов типа gofmt
- парсинг SQL и многое другое.
Середина
Семантический анализ! Анализ семантики языка — одна из сложнейших задач при создании компилятора.
Нужно удостовериться, что все входные программы работают правильно. В мой язык Krug пока не включены аспекты, связанные с семантическим анализом, а без него программист будет обязан всегда писать верный код. В реальности это невозможно — и мы все время пишем, компилируем, иногда запускаем, исправляем ошибки. Эта спираль бесконечна.
Кроме того, компиляция программ невозможна без анализа правильности семантики на соответствующем этапе компиляции.
Когда-то мне попадалась диаграмма, посвященная процентному соотношению фронтенда, миддленда и бэкенда. Тогда оно выглядело как
F: 20% M: 20%: B: 60%Сегодня оно представляет собой что-то вроде
F: 5% M: 60% B: 35%Фронтендом занимается, в основном, генератор, а в безконтекстных языках, не обладающих двойственностью грамматики, их можно выполнить довольно быстро — здесь поможет рекурсивный спуск.
С технологией LLVM большая часть работы по оптимизации может быть загружена во фреймворк, в котором представлен целый ряд готовых оптимизаций.
Следующий шаг — семантический анализ, важнейшая часть фазы компиляции.
Например, в Rust с его моделью управления памятью компилятор выступает как большая мощная машина, которая проводит различные виды статического анализа на вводных формах. Отчасти эта задача состоит в конвертации входных данных в более удобную для анализа форму.
По этой причине семантический анализ играет важную роль в архитектуре компилятора, а изнурительная подготовительная работа вроде оптимизации сгенерированной сборки или считывания входных данных в АСД выполняется за вас.
Семантические проходы
В ходе семантического анализа большинство компиляторов проводят большое количество «семантических проходов» по АСД или другой абстрактной форме выражения кода. В этой статье содержатся детали о большинстве проходов, производящихся в компиляторе .NET C#.
Я не буду рассматривать каждый проход, тем более что они разнятся в зависимости от языка, но ниже описано несколько шагов в Krug.
Объявление высшего уровня
Компилятор пройдется по всем объявлениям «высшего уровня» в модулях и осознает их существование. Глубже в блоки он не пойдет — он просто объявит, какие структуры, функции и т.д. имеются в том или ином модуле.
Разрешение имени/символа
Компилятор проходит по всем блокам кода в функциях и т.п. и разрешает их — то есть, находит символы, требующие разрешения. Это распространенный проход, и именно отсюда, как правило, приходит ошибка No such symbol XYZ при компиляции кода Go.
Выполнить этот проход может быть очень непросто, особенно если в вашей диаграмме зависимостей есть циклические зависимости. Некоторые языки их не допускают, например, Go выдаст ошибку, если какой-то из ваших пакетов формирует цикл, как и мой язык Krug. Циклические зависимости можно считать побочным эффектом плохой архитектуры.
Циклы можно определять, модифицируя DFS в диаграмме зависимостей, или воспользовавшись алгоритмом Тарьяна (как это сделано в Krug) для определения (множественных) циклов.
Выведение типов (Type Inference)
Компилятор проходит через все переменные и выводит их типы. Выведение типов в Krug очень слабое, оно просто выводит переменные на основе их значений. Это никоим образом не причудливая система, вроде тех, можно встретить в функциональных языках наподобие Haskell.
Выводить типы можно с помощью процесса «унификации», или «унификации типов». Для более простых систем типов можно использовать очень простую реализацию.
Типы реализованы в Krug так:
interface Type {};
struct IntegerType : Type {
int width;
bool signed;
};
struct FloatingType : Type {
int width;
};
struct ArrayType : Type {
Type base_type;
uint64 length;
};Также у вас может быть простое выведение типов, при котором вы будете присваивать тип узлам выражений, например,
IntegerConstantNode может иметь тип IntegerType(64). А затем у вас может появиться функция unify(t1, t2), которая выберет самый широкий тип, который можно использовать для выведения типа более сложных выражений, скажем, бинарных. Так что это вопрос присвоения переменной слева значений приведённых типов справа.Когда-то я написал простое приведение типов на Go, которое стало прототипом реализации для Krug.
Проход на изменяемость переменных (Mutability Pass)
Krug (как и Rust) по умолчанию является неизменяемым языком, то есть переменные остаются неизменными, если не задано иное:
let x = 3;
x = 4; // BAD!
mut y = 5;
y = 6; // OK!Компилятор проходит по всем блокам и функциям и проверяет, что их «переменные корректны», то есть мы не меняем то, что не следует, и что все переменные, передаваемые определённым функциям, являются постоянными или изменяемым там, где требуется.
Это делается с помощью символьной информации, которая собрана за предыдущие проходы. Символьная таблица, построенная по результатам семантического прохода, содержит имена токенов и признаки изменяемости переменных. Она может содержать и другие данные, к примеру, в С++ в таблице может храниться информация о том, является символ внешним или статичным.
Символьные таблицы
Символьная таблица, или «stab», это таблица для поиска символов, которые используются в вашей программе. Для каждой области видимости создаётся по одной таблице, и все они содержат информацию о символах, присутствующих в конкретной области видимости.
К этой информации относятся такие свойства, как имя символа, тип, признак изменяемости, наличие внешней связи, расположение в статичной памяти и прочее.
Область видимости
Это важная концепция в языках программирования. Конечно, ваш язык не обязан разрешать создавать вложенные области видимости, всё можно поместить в одно общее пространство имён!
Хотя представление области видимости является интересной задачей для архитектуры компилятора, в большинстве С-подобных языков область видимости ведёт себя (или является) как стековая структура данных (stack data structure).
Обычно мы создаём и уничтожаем области видимости, и обычно они используются для управления именами, то есть позволяют нам скрывать (shadowing) переменные:
{ // push scope
let x = 3;
{ // push scope
let x = 4; // OK!
} // pop scope
} // pop scopeто можно представить иначе:
struct Scope {
Scope* outer;
SymbolTable symbols;
}Небольшой оффтоп, но рекомендую почитать про спагетти-стек. Это структура данных, которая используется для хранения областей видимости в АСД-узлах противоположных блоков.
Системы типов
Многие из последующих разделов можно развить в отдельные статьи, но мне кажется, этот заголовок заслуживает этого больше всего. Сегодня доступно много информации о системах типов, как и разновидностей самих систем, вокруг которых ломается много копий. Я не будут глубоко погружаться в эту тему, лишь оставлю ссылку на прекрасную статью Стива Клабника.
Система типов — это то, что обеспечивается и семантически определяется в компиляторе с помощью представлений компилятора и анализа этих представлений.
Владение
Эта концепция используется в программировании всё шире. Принципы семантики владения и перемещения заложены в язык Rust, и надеюсь, будут появляться и в других языках. В Rust выполняется много разных видов статического анализа, с помощью которого проверяется, удовлетворяют ли входные данные набору правил в отношении памяти: кто и какой памятью владеет, когда память уничтожается и сколько существует ссылок (или заимствований) на эти значения или память.
Красота Rust заключается в том, что всё это выполняется в ходе компиляции, внутри компилятора, так что программисту не приходится заниматься сборкой мусора или подсчётом ссылок. Все эти семантики отнесены к системе типов и могут обеспечиваться ещё до того, как программа будет представлена в виде завершённого бинарного файла.
Я не могу сказать, как всё это устроено под капотом, но всё это является результатом статического анализа и замечательного исследования команды Mozilla и участников проекта Cyclone.
Графы потоков управления (Control Flow Graphs)
Для представления потоков программ мы используем графы потоков управления (CFG), которые содержат все пути, по которым может пойти исполнение программы. Это используется при семантическом анализе для исключения нерабочих участков кода, то есть блоков, функций и даже модулей, которые никогда не будут достигнуты в ходе исполнения программы. Также графы можно применять для выявления циклов, которые не могут прерваться. Или для поиска недоступного кода, например, когда вы вызываете «панику» (call a panic), или возвращаете в цикле, а код снаружи цикла не исполняется. Анализ потока данных играет важную роль в ходе семантической фазы работы компилятора, так что рекомендую почитать о тех видах анализа, которые вы можете выполнять, как они работают и какие оптимизации могут делать.
Бэкенд

Заключительная часть нашей схемы архитектуры.
Мы сделали большую часть работы по генерированию исполняемых бинарников. Сделать это можно разными способами, которые мы обсудим ниже.
Не обязательно сильно менять фазу семантического анализа из-за информации, содержащейся в дереве. Возможно, лучше вообще её не менять, чтобы избежать возникновения «спагетти».
Несколько слов о транспиляторах
Это разновидность компиляторов, которые преобразуют код на одном языке в исходный код на другом. Например, вы можете написать код, который компилируется в исходники на С. На мой взгляд, вещь довольно бессмысленная, если только ваш язык не уступает сильно тому языку, в который он компилируется. Обычно траспиляция имеет смысл для относительно высокоуровневых языков, или для языков с ограниченными возможностями.
Тем не менее, в истории компиляторов очень часто встречается преобразование в код на С. По сути, первый компилятор С++ — Cfront — транспилировал в код на C.
Хорошим примером является JavaScript. В его код транспилирует TypeScript и многие другие языки, чтобы привнести больше возможностей и, что ещё важнее, чувствительную систему типов с разным количеством видов статического анализа для ловли багов и ошибок, прежде чем мы столкнёмся с ними в ходе исполнения.
Это одна из «целей» компилятора, причём чаще всего самая простая, поскольку вам не нужно думать в рамках более низкоуровневых концепций о присвоении переменных, о работе с оптимизации и так далее, ведь вы просто «падаете на хвост» другому языку. Однако у этого подхода есть очевидный недостаток — большие накладные расходы, к тому же вы обычно ограничены возможностями языка, в который транспилируете свой код.
LLVM
Многие современные компиляторы обычно используют в качестве своего бэкенда LLVM: Rust, Swift, C/C++ (clang), D, Haskell.
Это можно считать «простым путём», потому что за вас проделали большую часть работы по поддержке широкого спектра архитектур, и вам доступны оптимизации высочайшего уровня. По сравнению с вышеупомянутой транспиляцией, LLVM предоставляет и большие возможности по управлению. Уж точно больше, чем если бы вы компилировали в С. К примеру, вы можете решать, насколько большими должны быть типы, скажем, 1, 4, 8 или 16-битные. В С это сделать не так просто, иногда невозможно, а для каких-то платформ даже нельзя определить.
Генерирование ассемблер-кода
Генерирование кода под конкретную архитектуру — то есть генерирование машинного кода, — это технически самый популярный путь, который применяется во множестве языков программирования.
Go — это пример современного языка, который не пользуется преимуществами фреймворка LLVM (на момент написания этой статьи). Go генерирует код для нескольких платформ, в том числе Windows, Linux и MacOS. Забавно, что в прототипе Krug раньше тоже генерировался ассемблер-код.
У этого подхода есть много достоинств и недостатков. Однако сегодня, когда доступны технологии вроде LLVM, уже неразумно самостоятельно генерировать ассемблер, потому что маловероятно, что игрушечный компилятор с собственным бэкендом превзойдёт LLVM по уровню оптимизации для одной платформы, не говоря уже о нескольких.
Тем не менее, значительное преимущество самостоятельного генерирования ассемблера заключается в том, что ваш компилятор наверняка окажется гораздо быстрее, чем если бы вы использовали фреймворк наподобие LLVM, который сначала должен собрать ваш IR, оптимизировать и так далее, или потом, наконец, сможет выдать ассемблер (или что вы там выберете).
Но попытаться всё-равно приятно. И к тому же будет интересно, если вы захотите узнать больше о программировании на ассемблере, или о том, как языки программирования работают на нижних уровнях. Проще всего открыть АСД или сгенерированный IR (если у вас он есть) и «выдать» инструкции ассемблера в файл с помощью fprintf или другой утилиты. Так работает 8cc.
Генерирование байткода
Также вы можете генерировать байткод для виртуальной машины определённого вида или интерпретатора байткода. Яркий пример — Java: по сути, JVM породила целое семейство генерирующих для неё байткод языков, например, Kotlin.
У генерирования байткода много преимуществ, и для Java главным была портируемость. Если вы можете где угодно запускать свою виртуальную машину, то любой выполняемый на ней код тоже будет работать где угодно. К тому же гораздо проще запускать на машинах абстрактный набор байткодовых инструкций, чем генерировать код по стопицот компьютерных архитектур.
Насколько я знаю, JVM с помощью JIT превращает часто используемый код в нативные функции, а также применяет другие JIT-ухищрения, чтобы выжать ещё больше производительности.
Оптимизации
Они являются неотъемлемой частью компилятора, никому не нужен медленно работающий код! Обычно оптимизации составляют большую часть бэкенда, и разработчики прикладывают много усилий, чтобы повысить производительность. Если вы когда-нибудь скомпилируете код на С и запустите его со всеми оптимизациями, ты вы удивитесь, какое безумие получится. Godbolt — прекрасный инструмент, позволяющий понять, как современные компиляторы генерируют код и какие инструкции к какому исходному коду относятся. Также вы сможете задать нужный уровень оптимизаций, цели, версии компиляторов и так далее.
Если вы когда либо писали компилятор, то можете начать с создания простой программы на С, выключить все оптимизации и символы отладки (strip the debug symbols), и посмотрите, что сгенерирует GCC. Можете потом использовать как памятку, если когда-нибудь возникнут затруднения.
При настройке оптимизаций можно находить компромисс между точностью и скоростью работы программы. Однако нащупать верный баланс не так просто. Некоторые оптимизации очень специфичны, и в некоторых случаях могут приводить к ошибочному результату. По очевидным причинам их не включают в production-компиляторы.
В комментариях к этой статье на другом ресурсе пользователь rwmj заметил, что достаточно всего 8 оптимизирующих проходов, чтобы получить 80 % от максимальной производительности вашего компилятор. И все эти оптимизации были описаны в 1971-м! Речь идёт о публикации Грейдона Хоара, вдохновителя Rust.
IR
Промежуточное представление (intermediate representation, IR) не обязательно, но полезно. Вы можете генерировать код из АСД, хотя это может быть довольно утомительно и неаккуратно, а результат сложно будет оптимизировать.
Можно считать IR более высокоуровневым представлением генерируемого кода. Оно должно очень точно отражать то, что представляет, и содержать всю информацию, необходимую для генерирования кода.
Есть конкретные виды IR, или «формы», которые вы можете создать с помощью IR для упрощения оптимизаций. Например, SSA — Static Single Assignment, единственное статическое присваивание, при котором каждая переменная присваивается лишь один раз.
В Go перед генерированием кода строится IR на основе SSA. IR в LLVM основан на SSA, чтобы обеспечить его оптимизации.
Изначально SSA предоставляет несколько оптимизаций, к примеру, подстановка констант (constant propagation), исключение нерабочего кода и (очень важное) распределение регистров.
Распределение регистров
Это не требование для генерирования кода, а оптимизация. Одна абстракция, которую мы считаем данностью, заключается в том, что мы можем определять столько переменных, сколько нужно нашим программам. Однако в ассемблере нам доступно конечное количество регистров (обычно от 16 до 32), которые нужно держать в голове, или мы можем воспользоваться стеком (spill to the stack).
Распределение регистров — это попытка выбрать для конкретной переменной конкретный регистр в определённый момент времени (без перезаписывания других значений). Это гораздо эффективнее использования стека, хотя может повлечь дополнительные расходы, да и компьютер не всегда может вычислить идеальную схему распределения.
Есть несколько алгоритмов распределения регистров:
- Раскрашивание графов (graph colouring) — вычислительно сложен (NP-полная задача). Требуется представлять код в виде графа, чтобы вычислять диапазон жизни (liveness ranges) переменных.
- Линейное сканирование — просматривает переменные и определяет их диапазоны жизни.
О чём нужно помнить
О компилятора написано очень много. Столько, что не поместится ни в одну статью. Я хочу напомнить, или хотя бы упомянуть несколько важных моментов, о которых нужно помнить в ходе ваших будущих проектов.
Искажение имён (Name Mangling)
Если вы генерируете ассемблер-код, в котором на самом деле нет никаких областей видимости или пространств имён, то у вас часто будут возникать конфликты символов. Особенно если ваш язык поддерживает переопределение функций или классов, и тому подобное.
fn main() int {
let x = 0;
{
let x = 0;
{
let x = 0;
}
}
return 0;
}Например, в этом коде (если переменные каким-либо образом не оптимизированы :) ) вам придётся искажать имена этих символов, чтобы в ассемблере они не конфликтовали. Также искажение обычно используется для обозначения типа информации, или оно может содержать информацию о пространстве имён.
Отладочная информация
Инструменты вроде LLDB обычно используют стандарты наподобие DWARF. Одно из замечательных свойств LLVM заключается в том, что благодаря DWARF вы получается относительно простую интеграцию с существующим отладочным GNU-инструментарием. Возможно, вашему языку понадобится отладочный инструмент, и всегда легче использовать готовый, чем писать свой.
Интерфейс внешних функций (Foreign Function Interface, FFI)
Обычно от libc никуда не деться, вам нужно почитать об этой библиотеке и подумать, как встроить её в свой язык. Как вы подключитесь к коду на С, или как вы откроете свой код для С?
Линкер
Написание линкера — отдельная задача. Когда ваш компилятор генерирует код, то он генерирует машинные инструкции (в файл .s/.asm)? Он пишет код напрямую в файл объекта? Например, в языке программирования Jai весь код предположительно пишется в один файл объекта. Существуют разные варианты, для которых характерны свои компромиссы.
Компилятор как сервис (CaaS)
Здесь все рассмотренные выше фазы компилятора распределены по API-маршрутам. Это означает, что текстовый редактор может обращаться к Krug-серверу, чтобы тот токенизировал файл и вернул в ответ токены. Кроме того, все маршруты статического анализа открыты, так что применять инструментарий становится проще.
Конечно, у этого подхода есть недостатки, например, задержка при отправке и получении файлов. К тому же многие аспекты архитектуры компилятора нужно переосмыслить, чтобы работать в контексте API-маршрутов.
Мало какие production-компиляторы используются подход CaaS. На память приходит Microsofts Roslyn, хотя я мало знаю об этом компиляторе, так что изучите его самостоятельно. И я могу ошибаться, но, похоже, во многих компиляторах реализован этот подход, но их авторы пишут API-машруты, которые подключаются к существующим компиляторам, например, в Rust есть RLS.
В моём языке Krug — который ещё активно разрабатывается и работает неустойчиво — в компиляторе Caasper используется CaaS-архитектура.
Caasper выполняется локально на вашей машине (или, если захотите, на сервере), а затем фронтенды или клиенты например, krug, взаимодействуют с этим сервисом. Плюс в том, что у вас может быть много реализаций фронтенда, а единственный фронтенд можно загружать (bootstrap) в самом языке, прежде чем переписывать весь компилятор.
Фронтенд для Krug реализован на JavaScript, хотя будут и альтернативные реализации на Go*, а также, надеюсь, на самом Krug. JavaScript был выбран за его доступность, его можно скачать с очень популярными менеджерами пакетов yarn/npm.
* Изначально фронтенд был написан на Go и оказался (ожидаемо) значительно быстрее, чем вариант на JS.
Исходный код компилятора Caasper лежит здесь. В моём личном Github лежит прототип Krug, он написан на D и компилируется в LLVM. Также можете посмотреть демо на моём YouTube-канале.
Руководство по Krug (промежуточное) лежит здесь.
Полезные ссылки
- Jack Crenshaw — моя личная дверь в мир реализации языков программирования.
- Crafting Interpreters
- Введение в LLVM (с Go) — я!
- PL/0
- The Dragon Book — классическая книга, в которой есть всё.
- 8cc




