Обработка естественного языка(Natural Language Processing — NLP) сегодня становится очень востребованной, так как людям несомненно проще общаться с машинами, также как они общаются с людьми.

Поэтому сейчас, вместе с быстрым развитием этой области, всё больше сервисов используют NLP: чат-боты, в которых больше не нужно выбирать готовые ответы, голосовые ассистенты, электронная почта, чтобы автоматически сортировать письма и так далее. В этом посте я хочу рассказать об относительно новой Python библиотеке SpaCy, которая стала, если не индустриальным стандартом, как кричат заявляют сами создатели на сайте библиотеки: https://spacy.io/, то как минимум одним из самых популярных и удобных решений. Приятного чтения!
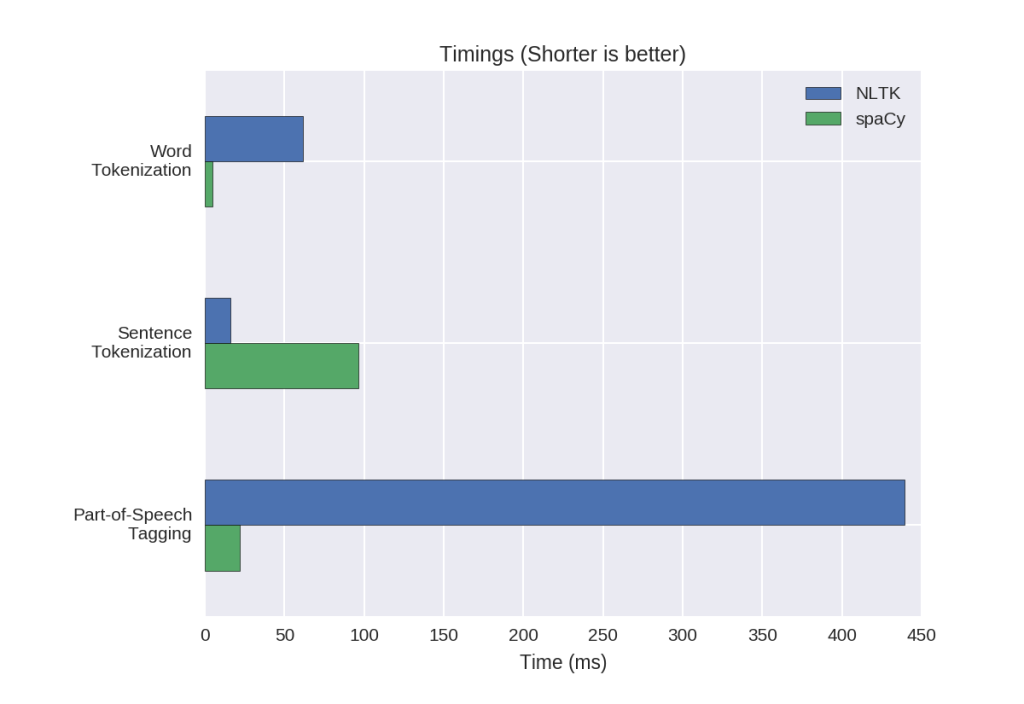
Сравнение с NLTK
NLTK(Natural Language ToolKit) — самая известная NLP библиотека, созданная исследователями в данной области. Она популярна в академических кругах и в основном используется для обучения или создания различных методов обработки и не только используя базовые инструменты, которые NLTK предоставляет в огромном количестве и не всегда самые лучшие. Так же она довольно медленная в силу того, что написана полностью на Python и работает со строками.
SpaCy — в каком-то смысле противоположность NLTK. Она значительно быстрее, так как она написана на Cython и работает с объектами, об этом дальше. SpaCy предоставляет в основном лучшие инструменты для решения конкретной задачи. Она — numpy из мира NLP.
В целом, SpaCy с её предобученными моделями, скоростью, удобным API и абстракцией гораздо лучше подходит для разработчиков, создающих готовые решения, а NLTK с огромным числом инструментов и возможностью городить любые огороды — для исследователей и студентов. В любом случае для создания собственных моделей ни та, ни другая библиотека не подходит. Для этого всего существуют Tensorflow, PyTorch и прочие.
https://spacy.io/usage/facts-figures
https://medium.com/activewizards-machine-learning-company/comparison-of-top-6-python-nlp-libraries-c4ce160237eb
Если кратко, то SpaCy может примерно всё то же самое, что и NLTK и их аналоги, но быстрее и точнее.
Архитектурные особенности
Центральными структурами данных в SpaCy являются Doc и Vocab. Объект Doc хранит последовательности токенов и все их аннотации. Объект Vocab хранит набор справочных таблиц, что делает общую информацию доступной для всех документов. При централизованном хранении строк, векторов слов и лексических атрибутов отсутствует необходимость хранения нескольких копий этих данных. Это экономит память и обеспечивает единый источник правды.
Объект Doc владеет данными, а Span и Token являются представлениями, что позволяет Spacy работать быстро, без лишних копирований, указывающими на них. Объект Doc создается объектом Tokenizer, а затем модифицируется in-place компонентами pipeline. Объект Language координирует эти компоненты. Он берет необработанный текст и отправляет его по pipeline, возвращая аннотированный документ.

Курс от создателей
У создателей есть хороший подробный курс по NLP с использованием SpaCy, начиная с самых основ и заканчивая дообучением встроенных моделей и адаптированию библиотеки под ваш проект: https://course.spacy.io/en
Установка
Весь код примеров будет по ссылке на Colab ниже.
Установка под все платформы предельно проста и не отличается от других пакетов Python(установка через pip/conda), и описана на сайте библиотеки, где можете собрать свой стартовый набор. Я использую Python 3.8.2 под Pop!_OS 20.04(короче Ubuntu):
Зависимости для Ubuntu:
sudo apt-get install build-essential python-dev gitУстановка SpaCy и en_core_web_sm — пакета небольшой модели английского, которая почти не уступает более крупным собратьям: https://spacy.io/models/en
pip3 install -U spacy
pip3 install -U spacy-lookups-data
python3 -m spacy download en_core_web_smТак же вы можете поставить Spacy с поддержкой вычислений на CUDA, о которой тоже есть информация на странице с установкой. Установка на Google Colab ничем не отличается. Официальных моделей русского языка пока нет, но они в процессе разработки. Но есть очень неплохо работающий вариант, который не работает пока на последней версии Spacy и тянет дополнительные зависимости: https://github.com/buriy/spacy-ru
Простейшие примеры
Весь код примеров будет на Colab: https://colab.research.google.com/drive/1BmOAjjYt-t_lT9suZNnf1j5ykDX5IYT0?usp=sharing
Для начала импортнём SpaCy и создадим объект nlp, что будет общей частью всех примеров:
import spacy
nlp = spacy.load("en_core_web_sm")Токенизация, POS-tagging и определение начальной формы слова — лемматизация в случае SpaCy:
(текст токена, начальная форма, часть речи, является ли стоп-словом)
doc = nlp("While Samsung has expanded overseas, South Korea is still host to most of its factories and research engineers.")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.is_stop)While while SCONJ True
Samsung Samsung PROPN False
has have AUX True
expanded expand VERB False
overseas overseas ADV False
,, PUNCT False
South South PROPN False
Korea Korea PROPN False
is be AUX True
still still ADV True
host host NOUN False
to to ADP True
most most ADJ True
of of ADP True
its -PRON- DET True
factories factory NOUN False
and and CCONJ True
research research NOUN False
engineers engineer NOUN False
.. PUNCT False
Построение дерева зависимостей для того же примера:
(текст токена, тип зависимости(согласно Universal Dependency), корневое слово)
for token in doc:
print(token.text, token.dep_, token.head)While mark expanded
Samsung nsubj expanded
has aux expanded
expanded advcl is
overseas advmod expanded
, punct is
South compound Korea
Korea nsubj is
is ROOT is
still advmod is
host attr is
to prep host
most pobj to
of prep most
its poss factories
factories pobj of
and cc factories
research compound engineers
engineers conj factories
. punct is
Несомненно, лучший способ увидеть зависимости — увидеть дерево. В Spacy есть модуль для визуализации дерева зависимостей, а также распознанных сущностей. Посмотрим как работает, сделав это для слайса от первого до 11 токенов:
from spacy import displacy
displacy.render(doc[:11], style='dep', jupyter=True)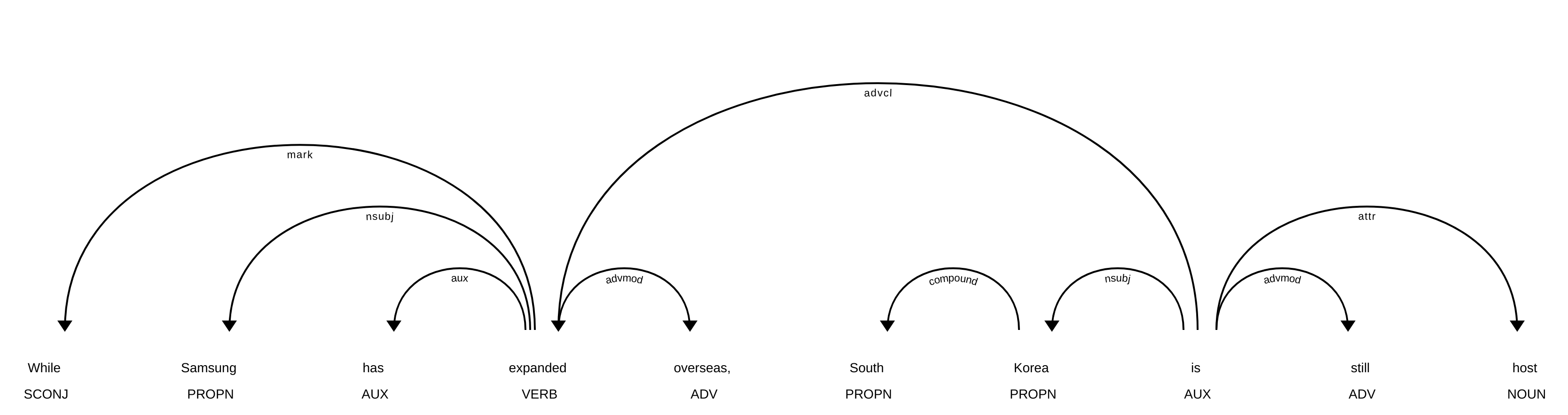
Распознавание именованных сущностей:
doc2 = nlp("Nasa administrator Jim Bridenstine says at the moment of launch, he was praying.")
for ent in doc2.ents:
print(ent.text, ent.label_)
displacy.render(doc2, style='ent', jupyter=True)Nasa ORG
Jim Bridenstine PERSON

Это были самые базовых возможностей данной библиотеки.
Возможности из коробки
- Находить фразы по паттернам. Live-демонстрация с возможность "похимичить": https://explosion.ai/demos/matcher
- Гибкая кастомизация пайплайна обработки
- Fine-tuning встроенных моделей на ваших данных и создание своих
- И другие полезности
Подробные примеры
Огромное множество полезнейших наработок для и с использованием SpaCy: https://spacy.io/universe, в том числе решение кореферентности, обвязка для PyTorch, готовые движки для чат-ботов и так далее.
Заключение
Эта библиотека хорошо подойдёт как для разработчиков, так и для исследователей. SpaCy скрывает лишние подробности, позволяя быстро решать задачи NLP state-of-the-art решениями. При этом возможность допиливать модельки и кастомизировать пайплайн развязывает руки для новых экспериментов, чем вам я и желаю заниматься!

