
Сегодня, в среду, состоится очередной релиз Kubernetes — 1.16. По сложившейся для нашего блога традиции, вот уже в юбилейный — десятый — раз мы рассказываем о наиболее значимых изменениях в новой версии.
Информация, использованная для подготовки этого материала, взята из таблицы Kubernetes enhancements tracking, CHANGELOG-1.16 и сооветствующих issues, pull requests, а также Kubernetes Enhancement Proposals (KEP). Итак, поехали!..
Узлы
По-настоящему большое число заметных нововведений (в статусе альфа-версии) представлено на стороне узлов K8s-кластеров (Kubelet).
Во-первых, представлены так называемые «эфемерные контейнеры» (Ephemeral Containers), призванные упростить процессы отладки в pod'ах. Новый механизм позволяет запускать специальные контейнеры, которые стартуют в пространстве имён существующих pod'ов и живут непродолжительное время. Их предназначение — взаимодействие с другими pod'ами и контейнерами в целях решения каких-либо проблем и отладки. Для этой возможности реализована новая команда
kubectl debug, схожая по своей сути с kubectl exec: только вместо запуска процесса в контейнере (как в случае exec) она запускает контейнер в pod'е. Например, такая команда подсоединит новый контейнер к pod'у:kubectl debug -c debug-shell --image=debian target-pod -- bashПодробности об эфемерных контейнерах (и примеры их использования) можно найти в соответствующем KEP. Текущая реализация (в K8s 1.16) — альфа-версия, а среди критериев её перевода в бета-версию значится «тестирование Ephemeral Containers API на протяжении не менее 2 релизов [Kubernetes]».
NB: По своей сути и даже названию фича напоминает уже существующий плагин kubectl-debug, о котором мы уже писали. Предполагается, что с появлением эфемерных контейнеров развитие отдельного внешнего плагина прекратится.
Другое новшество —
PodOverhead — призвано предоставить механизм подсчёта накладных расходов на pod'ы, которые могут сильно отличаться в зависимости от используемой исполняемой среды (runtime). В качестве примера авторы этого KEP приводят Kata Containers, которые требуют запуска гостевого ядра, агента kata, init-системы и т.п. Когда overhead становится таким большим, его нельзя игнорировать, а значит — требуется способ учитывать его для дальнейшего квотирования, планирования и т.п. Для его реализации в PodSpec добавлено поле Overhead *ResourceList (сопоставляется с данными в RuntimeClass, если таковой используется).Ещё одно заметное нововведение — менеджер топологии узла (Node Topology Manager), призванный унифицировать подход к тонкой настройке распределения аппаратных ресурсов для различных компонентов в Kubernetes. Эта инициатива вызвана растущей потребностью различных современных систем (из области телекоммуникаций, машинного обучения, финансовых услуг и т.п.) в высокопроизводительных параллельных вычислениях и минимизации задержек при исполнении операций, для чего они используют продвинутые возможности CPU и аппаратного ускорения. Такие оптимизации в Kubernetes до сих пор достигались благодаря разрозненным компонентам (CPU manager, Device manager, CNI), а теперь им добавят единый внутренний интерфейс, который унифицирует подход и упростит подключение новых аналогичных — так называемых topology-aware — компонентов на стороне Kubelet. Подробности — в соответствующем KEP.
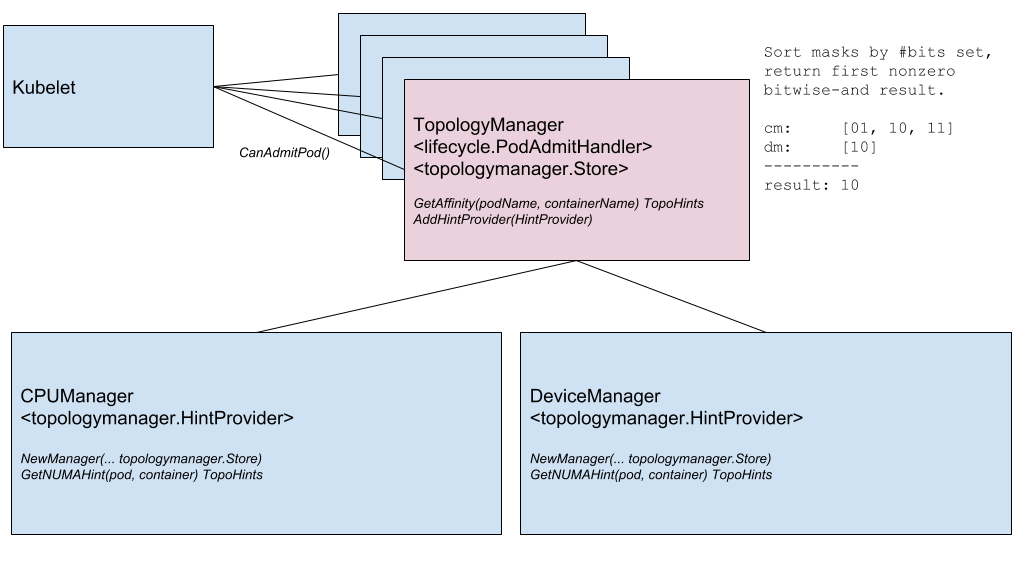
Схема компонентов Topology Manager
Следующая фича — проверка контейнеров во время их запуска (startup probe). Как известно, для контейнеров, что долго запускаются, затруднительно получить актуальный статус: их либо «убивают» ещё до реального начала функционирования, либо они на долгое время попадают в deadlock. Новая проверка (включается через feature gate под названием
StartupProbeEnabled) отменяет — точнее, откладывает — действие любых других проверок до того момента, когда pod закончил свой запуск. По этой причине фичу изначально называли pod-startup liveness-probe holdoff. Для pod'ов, что долго стартуют, можно проводить опрос состояния в относительно короткие временные интервалы.Кроме того, сразу в статусе бета-версии представлено улучшение для RuntimeClass, добавляющее поддержку «гетерогенных кластеров». C RuntimeClass Scheduling теперь вовсе не обязательно каждому узлу иметь поддержку каждого RuntimeClass'а: для pod'ов можно выбирать RuntimeClass, не думая о топологии кластера. Раньше для достижения этого — чтобы pod'ы оказывались на узлах с поддержкой всего им нужного — приходилось назначать соответствующие правила к NodeSelector и tolerations. В KEP рассказывается о примерах использования и, конечно же, подробностях реализации.
Сеть
Две значимые сетевые фичи, что появились впервые (в альфа-версии) в Kubernetes 1.16 — это:
- Поддержка двойного сетевого стека — IPv4/IPv6 — и соответствующее его «понимание» на уровне pod'ов, узлов, сервисов. Она включает в себя взаимодействие IPv4-to-IPv4 и IPv6-to-IPv6 между pod'ами, с pod'ов во внешние сервисы, эталонные реализации (в рамках плагинов Bridge CNI, PTP CNI и Host-Local IPAM), а также обратную совместимость с кластерами Kubernetes, работающими только по IPv4 или IPv6. Подробности реализации — в KEP.
Пример вывода IP-адресов двух видов (IPv4 и IPv6) в списке pod'ов:
kube-master# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE nginx-controller 1/1 Running 0 20m fd00:db8:1::2,192.168.1.3 kube-minion-1 kube-master#
- Новый API для Endpoint — EndpointSlice API. Он решает проблемы существующего Endpoint API с производительностью/масштабируемостью, что затрагивают различные компоненты в control-plane (apiserver, etcd, endpoints-controller, kube-proxy). Новый API будет добавлен в API-группу Discovery и сможет обслуживать десятки тысяч backend endpoint'ов на каждом сервисе в кластере, состоящем из тысячей узлов. Для этого каждый Service отображается в N объектов
EndpointSlice, каждый из которых по умолчанию имеет не более 100 endpoint'ов (значение настраивается). В EndpointSlice API предусмотрят и возможности для его будущего развития: поддержки множества IP-адресов у каждого pod'а, новых состояний для endpoint'ов (не толькоReadyиNotReady), динамического subsetting для endpoint'ов.
До бета-версии продвинулся представленный в прошлом релизе finalizer, названный
service.kubernetes.io/load-balancer-cleanup и прикрепляемый к каждому сервису с типом LoadBalancer. В момент удаления такого сервиса он предотвращает фактическое удаление ресурса, пока не завершена «зачистка» всех соответствующих ресурсов балансировщика.API Machinery
Настоящая «веха стабилизации» зафиксирована в области API-сервера Kubernetes и взаимодействия с ним. Во многом это случилось благодаря переводу в статус stable не нуждающихся в особом представлении CustomResourceDefinitions (CRD), что имели статус бета-версии со времён далёкого Kubernetes 1.7 (а это июнь 2017 года!). Такая же стабилизация пришла и к связанным с ними фичам:
- «подресурсы» (subresources) со
/statusи/scaleдля CustomResources; - преобразование версий для CRD, основанное на внешнем webhook'е;
- представленные недавно (в K8s 1.15) значения по умолчанию (defaulting) и автоматическое удаление полей (pruning) для CustomResources;
- возможность применения схемы OpenAPI v3 для создания и публикации OpenAPI-документации, используемой для валидации CRD-ресурсов на стороне сервера.
Ещё один механизм, давно ставший привычным для администраторов Kubernetes: admission webhook — тоже долгое время пребывал в статусе беты (с K8s 1.9) и теперь объявлен стабильным.
Две другие фичи достигли бета-версии: server-side apply и watch bookmarks.
А единственным значимым нововведением в альфа-версии стал отказ от
SelfLink — специального URI, представляющего указанный объект и являющегося частью ObjectMeta и ListMeta (т.е. частью любого объекта в Kubernetes). Зачем от него отказываются? Мотивация «по-простому» звучит как отсутствие настоящих (непреодолимых) причин для того, чтобы это поле по-прежнему существовало. Более формальные причины — оптимизировать производительность (убрав ненужное поле) и упростить работу generic-apiserver, который вынужден обрабатывать такое поле особым образом (это единственное поле, которое устанавливается прямо перед сериализацией объекта). Настоящее «устаревание» (в рамках бета-версии) SelfLink произойдет к версии Kubernetes 1.20, а окончательное — 1.21.Хранение данных
Основная работа в области storage, как и в прошлых релизах, наблюдается в области поддержки CSI. Главными изменениями здесь стали:
- впервые (в альфа-версии) появилась поддержка CSI-плагинов для рабочих узлов с Windows: актуальный способ работы с хранилищами и здесь придёт на смену плагинам in-tree в ядре Kubernetes и FlexVolume-плагинам от Microsoft на базе Powershell;
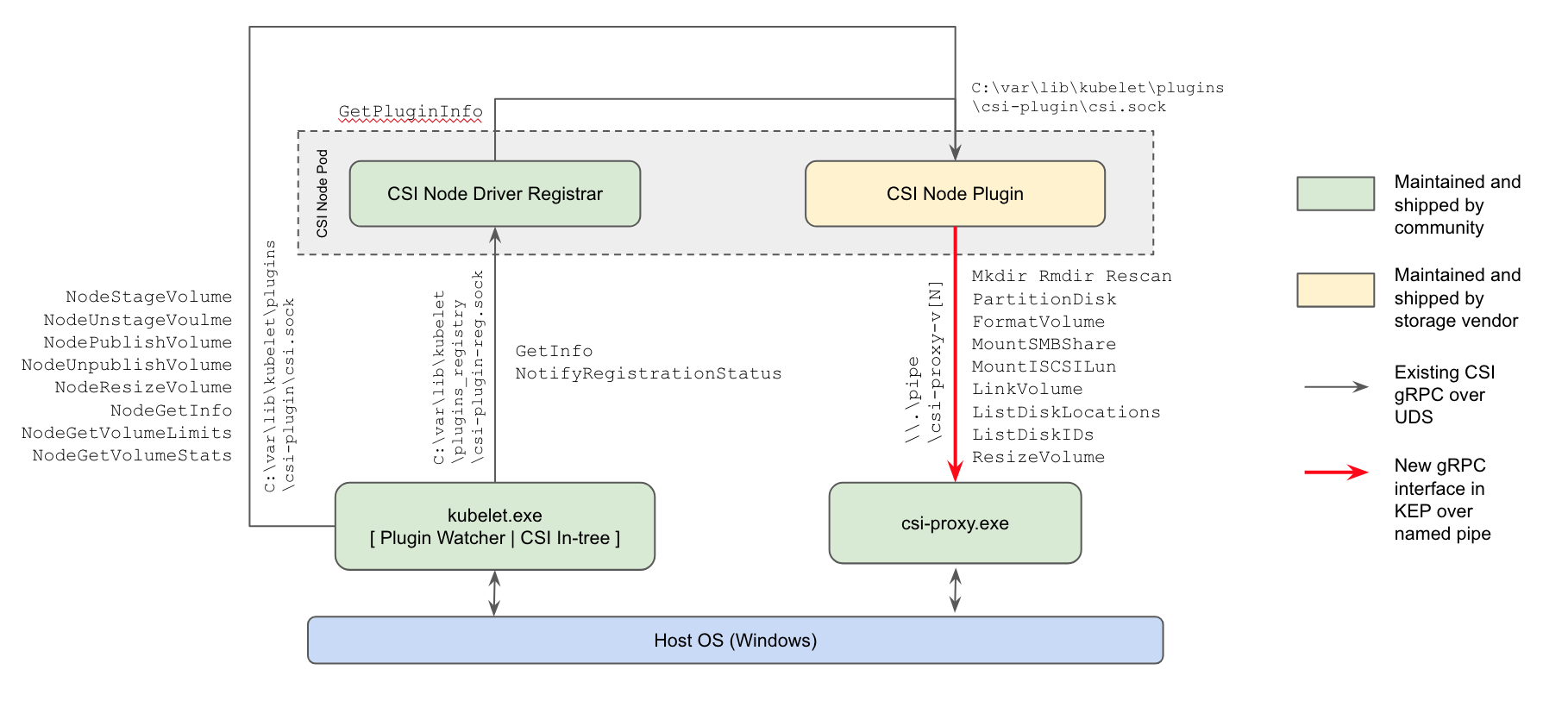
Схема реализации CSI-плагинов в Kubernetes для Windows
- возможность изменения размера CSI-томов, представленная ещё в K8s 1.12, доросла до бета-версии;
- аналогичного «повышения» (с альфа- до бета-версии) достигла возможность использования CSI для создания локальных эфемерных томов (CSI Inline Volume Support).
Появившаяся в прошлой версии Kubernetes функция клонирования томов (использование существующих PVC в качестве
DataSource для создания новых PVC) тоже теперь получила статус бета-версии.Планировщик
Два заметных изменения в планировании (оба в альфа-версии):
-
EvenPodsSpreading— возможность использовать для «честного распределения» нагрузок pod'ы вместо логических единиц приложения (вроде Deployment и ReplicaSet) и регулировки этого распределения (как жёсткого требования или как мягкого условия, т.е. приоритета). Фича расширит имеющиеся возможности распределения планируемых pod'ов, ныне ограниченные опциямиPodAffinityиPodAntiAffinity, предоставив администраторам более тонкий контроль в этом вопросе, а значит — лучшую высокую доступность и оптимизированное потребление ресурсов. Подробности — в KEP. - Использование BestFit Policy в RequestedToCapacityRatio Priority Function во время планирования pod'ов, что позволит применять bin packing («упаковку в контейнеры») как для основных ресурсов (процессор, память), так и расширенных (вроде GPU). Подробнее см. в KEP.

Планирование pod'ов: до использования best fit policy (напрямую через default scheduler) и с её использованием (через scheduler extender)
Кроме того, представлена возможность создавать свои плагины для планировщика вне основного дерева разработки Kubernetes (out-of-tree).
Другие изменения
Также в релизе Kubernetes 1.16 можно отметить инициативу по приведению имеющихся метрик в полный порядок, а если точнее — в соответствие с официальными предписаниями к инструментации K8s. Они по большому счёту опираются на соответствующую документацию Prometheus. Несыстоковки же образовались по разным причинам (например, некоторые метрики были попросту созданы ещё до того, как текущие инструкции появились), и разработчики решили, что настало время привести всё к единому стандарту, «в соответствие с остальной экосистемой Prometheus». Текущая реализация этой инициативы носит статус альфа-версии, который будет последовательно повышаться в последующих версиях Kubernetes до беты (1.17) и стабильного (1.18).
Кроме того, можно отметить следующие изменения:
- Развитие поддержки Windows с появлением утилиты Kubeadm для этой ОС (альфа-версия), возможностью
RunAsUserNameдля Windows-контейнеров (альфа-версия), улучшением поддержки Group Managed Service Account (gMSA) до бета-версии, поддержкой mount/attach для томов vSphere. - Переработанный механизм сжатия данных в ответах API. Раньше для этих целей использовался HTTP-фильтр, который накладывал ряд ограничений, препятствующих его включению по умолчанию. Теперь работает «прозрачное сжатие запросов»: клиенты, отправляющие
Accept-Encoding: gzipв заголовке, получают сжатый в GZIP ответ, если его размер превышал 128 Кб. Клиенты на Go автоматически поддерживают сжатие (отправляют нужный заголовок), так что сразу заметят снижение трафика. (Для других языков могут потебоваться небольшие модификации.) - Стало возможным масштабирование HPA из/до нуля pod'ов на основе внешних метрик. Если масштабирование производится на основе объектов/внешних метрик, то когда рабочие нагрузки простаивают, можно автоматически масштабироваться до 0 реплик, чтобы сэкономить ресурсы. Особенно полезной эта фича должна оказаться для случаев, когда worker'ы запрашивают ресурсы GPU, а количество различных типов простаивающих worker'ов превышает число доступных GPU.
- Новый клиент —
k8s.io/client-go/metadata.Client— для «обобщённого» доступа к объектам. Он предназначен для того, чтобы легко получать метаданные (т.е. подразделmetadata) из ресурсов кластера и осуществлять с ними операции из разряда сбора мусора и квотирования. - Собирать Kubernetes теперь можно без устаревших («встроенных» в in-tree) облачных провайдеров (альфа-версия).
- В утилиту kubeadm добавили экспериментальную (альфа-версия) возможность применять патчи kustomize во время операций
init,joinиupgrade. Подробнее о том, как пользоваться флагом--experimental-kustomize, см. в KEP. - Новый endpoint для apiserver —
readyz, — позволяющий экспортировать информацию о его готовности (readiness). Также у API-сервера появился флаг--maximum-startup-sequence-duration, позволяющий регулировать его перезапуски. - Две фичи для Azure объявлены стабильными: поддержка зон доступности (Availability Zones) и cross resource group (RG). Кроме того, в Azure добавлены:
- поддержка аутентификации AAD и ADFS;
- аннотация
service.beta.kubernetes.io/azure-pip-nameдля указания публичного IP у балансировщика нагрузки; - возможность настройки
LoadBalancerNameиLoadBalancerResourceGroup.
- У AWS появилась поддержка для EBS в Windows и оптимизированы API-вызовы EC2
DescribeInstances. - Kubeadm теперь самостоятельно мигрирует конфигурацию CoreDNS при обновлении версии CoreDNS.
- Бинарники etcd в соответствующем Docker-образе сделали world-executable, что позволяет запускать этот образ без необходимости в правах root. Кроме того, образ миграции etcd прекратил поддержку версии etcd2.
- В Cluster Autoscaler 1.16.0 перешли на использование distroless в качестве базового образа, улучшили производительность, добавили новых облачных провайдеров (DigitalOcean, Magnum, Packet).
- Обновления в используемом/зависимом программном обеспечении: Go 1.12.9, etcd 3.3.15, CoreDNS 1.6.2.
P.S.
Читайте также в нашем блоге:
- «Kubernetes 1.15: обзор основных новшеств»;
- «Kubernetes 1.14: обзор основных новшеств»;
- «Kubernetes 1.13: обзор основных новшеств»;
- «Kubernetes 1.12: обзор основных новшеств».




 03.10.2019")