
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Прим. перев.: Dailymotion — один из крупнейших в мире сервисов хостинга видео и потому заметный пользователь Kubernetes. В этом материале системный архитектор David Donchez делится итогами создания production-платформы компании на базе K8s, которая начиналась с облачной инсталляции в GKE и закончилась как гибридное решение, что позволило добиться лучшего времени реакции и сэкономить на инфраструктурных затратах.
Принимая решение о перестройке основного API Dailymotion три года назад, мы хотели разработать более эффективный способ размещения приложений и облегчить процессы в разработке и production. Для этой цели мы решили использовать платформу оркестрации контейнеров и естественным образом выбрали Kubernetes.
Почему стоит создавать собственную платформу на базе Kubernetes?
API production-уровня в кратчайшие сроки с помощью Google Cloud
Лето 2016-го
Три года назад, сразу после покупки Dailymotion компанией Vivendi, наши инженерные команды сфокусировались на одной глобальной цели: создать совершенно новый продукт Dailymotion.
По итогам анализа контейнеров, решений для оркестрации и нашему прошлому опыту мы убедились, что Kubernetes — правильный выбор. Часть разработчиков уже имела представление о базовых концепциях и знала, как его использовать, что было огромным преимуществом для инфраструктурной трансформации.
С точки зрения инфраструктуры требовалась мощная и гибкая система для размещения новых типов облачных (cloud-native) приложений. Мы предпочли остаться в облаке в начале нашего путешествия, чтобы спокойно построить максимально надежную локальную платформу. Свои приложения решили развертывать с помощью Google Kubernetes Engine, хотя знали, что рано или поздно перейдем на собственные ЦОД и применим гибридную стратегию.
Почему выбрали GKE?
Мы сделали этот выбор главным образом по техническим соображениям. Кроме того, требовалось быстро предоставить инфраструктуру, отвечающую нуждам бизнеса компании. У нас были некоторые требования к размещению приложений, такие как географическая распределенность, масштабируемость и отказоустойчивость.
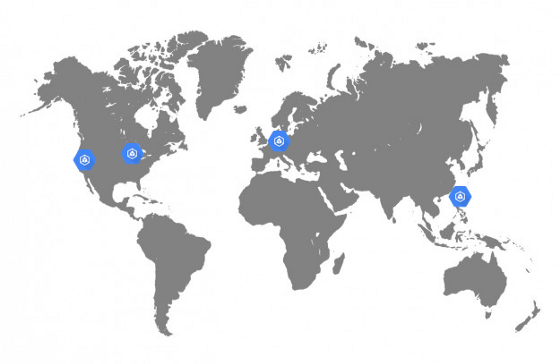
Кластеры GKE в Dailymotion
Поскольку Dailymotion — видеоплатформа, доступная по всему миру, мы очень хотели повысить качество сервиса, сократив время ожидания (latency). Ранее наш API был доступен только в Париже, что было неоптимально. Хотелось иметь возможность размещать приложения не только в Европе, но и в Азии, и в США.
Эта чувствительность к задержкам означала, что придется серьезно поработать над сетевой архитектурой платформы. В то время как большинство облачных сервисов вынуждали создавать свою сеть в каждом регионе и потом связывать их через VPN или некий управляемый сервис, Google Cloud позволял создать полностью маршрутизируемую единую сеть, охватывающую все регионы Google. Это большой плюс в смысле эксплуатации и эффективности системы.
Кроме того, со своей работой отлично справляются сетевые сервисы и балансировщики нагрузки от Google Cloud. Они просто позволяют использовать произвольные общедоступные IP-адреса из каждого региона, а замечательный протокол BGP позаботится обо всем остальном (т. е. перенаправит пользователей к ближайшему кластеру). Очевидно, что в случае сбоя трафик будет автоматически идти в другой регион без какого-либо вмешательства человека.
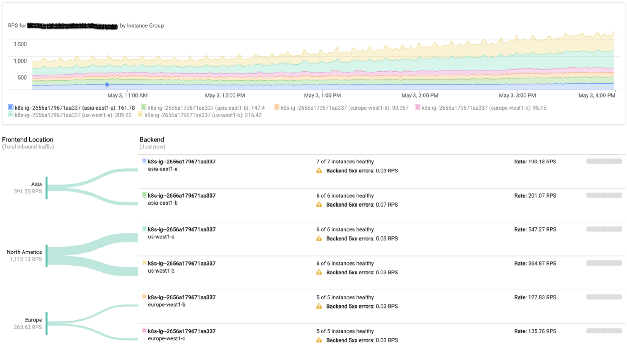
Мониторинг балансировки нагрузок в Google
Наша платформа также активно задействует графические процессоры. Google Cloud позволяет весьма эффективно использовать их прямо в кластерах Kubernetes.
В то время инфраструктурная команда преимущественно концентрировалась на старом стеке, развернутом на физических серверах. Именно поэтому использование управляемого сервиса (включая мастер-компоненты Kubernetes) отвечало нашим требованиям и позволяло обучить команды работе с локальными кластерами.
В результате мы смогли начать принимать production-трафик на инфраструктуре Google Cloud всего через 6 месяцев после начала работы.
Однако несмотря на ряд преимуществ, работа с облачным провайдером сопряжена с определенными затратами, которые могут увеличиваться в зависимости от нагрузки. Вот почему мы внимательно анализировали каждый используемый управляемый сервис, рассчитывая в будущем реализовать их у себя on-premises. На самом деле внедрение локальных кластеров началось в конце 2016 года и тогда же была инициирована гибридная стратегия.
Запуск локальной платформы оркестрации контейнеров Dailymotion
Осень 2016-го
В условиях, когда весь стек был готов к production, а работа над API продолжалась, было время сконцентрироваться на региональных кластерах.
На тот момент пользователи ежемесячно просматривали более 3 млрд видеороликов. Конечно, у нас уже не один год функционировала собственная разветвленная Content Delivery Network. Мы хотели воспользоваться этим обстоятельством и развернуть кластеры Kubernetes в существующих ЦОДах.
Инфраструктура Dailymotion насчитывала более чем 2,5 тыс. серверов в шести дата-центрах. Все они конфигурируются с помощью Saltstack. Мы начали готовить все необходимые рецепты для создания мастер- и worker-узлов, а также кластера etcd.

Сетевая часть
Наша сеть полностью маршрутизируемая. Каждый сервер анонсирует свой IP в сети с помощью Exabgp. Мы сравнили несколько сетевых плагинов и единственным удовлетворяющим всем потребностям (из-за используемого подхода на уровне L3) оказался Calico. Он прекрасно вписался в существующую сетевую модель инфраструктуры.
Поскольку хотелось использовать все имеющиеся элементы инфраструктуры, прежде всего предстояло разобраться с нашей доморощенной сетевой утилитой (используемой на всех серверах): воспользоваться ей для анонсирования диапазонов IP-адресов в сети с Kubernetes-узлами. Мы позволили Calico присваивать IP-адреса pod'ам, но не использовали его и до сих пор не используем для BGP-сессий на сетевом оборудовании. По факту маршрутизацией занимается Exabgp, который анонсирует подсети, используемые Calico. Это позволяет нам достучаться к любому pod'у из внутренней сети (и в частности от балансировщиков нагрузки).
Как мы управляем ingress-трафиком
Для перенаправления входящих запросов на нужный сервис было решено использовать Ingress Controller из-за его интеграции с ingress-ресурсами Kubernetes.
Три года назад nginx-ingress-controller был наиболее зрелым контроллером: Nginx использовался уже давно и был известен своей стабильностью и производительностью.
В своей системе мы решили разместить контроллеры на выделенных 10-гигабитных блейд-серверах. Каждый контроллер подключался к endpoint'у kube-apiserver соответствующего кластера. На этих серверах также использовался Exabgp для анонсирования публичных или частных IP-адресов. Топология нашей сети позволяет использовать BGP из этих контроллеров для маршрутизации всего трафика непосредственно на pod'ы без использования сервиса типа NodePort. Такой подход помогает избежать горизонтального трафика между узлами и повышает эффективность.
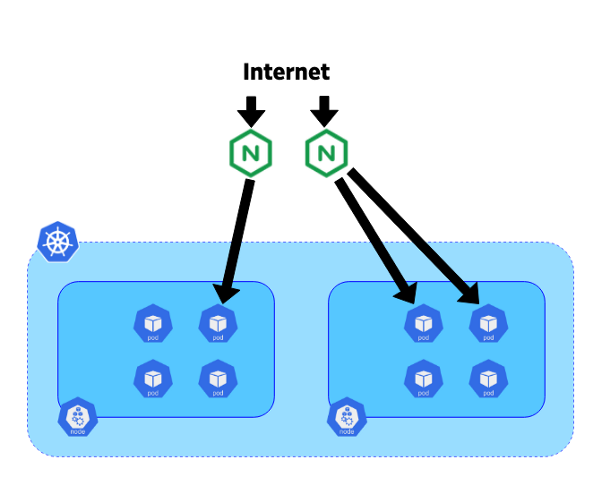
Движение трафика из интернета к pod'ам
Теперь, когда разобрались с нашей гибридной платформой, можно углубиться в сам процесс миграции трафика.
Миграция трафика из Google Cloud в инфраструктуру Dailymotion
Осень 2018-го
После почти двух лет создания, тестирования и настройки мы, наконец, получили полный стек Kubernetes, готовый принять часть трафика.

Текущая стратегия маршрутизации довольно проста, но вполне удовлетворяет потребностям. Помимо общедоступных IP (в Google Cloud и Dailymotion) используется AWS Route 53 для задания политик и перенаправления пользователей к кластеру по нашему выбору.
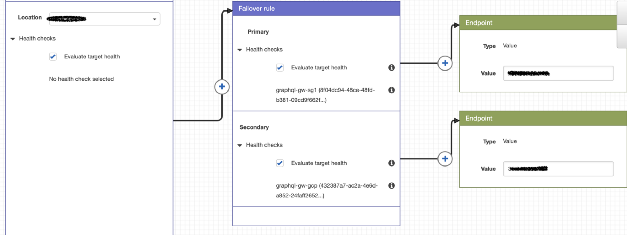
Пример политики маршрутизации с использованием Route 53
С Google Cloud это просто, поскольку мы задействуем единый IP для всех кластеров, а пользователь перенаправляется к ближайшему кластеру GKE. Для наших кластеров технология другая, поскольку их IP отличаются.
Во время миграции мы стремились к перенаправлению региональных запросов на соответствующие кластеры и оценивали преимущества такого подхода.
Поскольку наши GKE-кластеры сконфигурированы на автоматическое масштабирование с помощью Custom Metrics, они наращивают/сокращают мощности в зависимости от входящего трафика.
В нормальном режиме весь региональный трафик направляется на локальный кластер, а GKE служит резервом на случай возникновения проблем (health-check'и проводятся Route 53).
…
В будущем мы хотим полностью автоматизировать политики маршрутизации, чтобы получить автономную гибридную стратегию, которая постоянно улучшает доступность для пользователей. Что касается плюсов: значительно сократились расходы на облако и удалось даже сократить время реакции API. Мы доверяем получившейся облачной платформе и готовы при необходимости перенаправить на нее больше трафика.
P.S. от переводчика
Возможно, вас еще заинтересует другая недавняя публикация Dailymotion про Kubernetes. Она посвящёна деплою приложений с Helm на множестве Kubernetes-кластеров и была опубликована около месяца назад.
Читайте также в нашем блоге:
- «Переход Tinder на Kubernetes».
- «Истории успеха Kubernetes в production. Часть 10: Reddit»;
- «Истории успеха Kubernetes в production. Часть 9: ЦЕРН и 210 кластеров K8s»;
- «Истории успеха Kubernetes в production. Часть 8: Huawei»;
- «Истории успеха Kubernetes в production. Часть 7: BlackRock»;
- «Истории успеха Kubernetes в production. Часть 6: BlaBlaCar»;
- «Истории успеха Kubernetes в production. Часть 5: цифровой банк Monzo»;
- «Истории успеха Kubernetes в production. Часть 4: SoundCloud (авторы Prometheus)»;
- «Истории успеха Kubernetes в production. Часть 3: GitHub»;
- «Истории успеха Kubernetes в production. Часть 2: Concur и SAP»;
- «Истории успеха Kubernetes в production. Часть 1: 4200 подов и TessMaster у eBay».




