

Чтение рекомендуется начать с первой части, в которой мы терзаем ОС нереальным количеством потоков, смотрим, что из этого вышло, и видим, что согласованность — это не обязательно многопоточность.
Лезем в сорцы и видим объяснение всем нашим G, P и М.
- G — горутина, которую мы будем запускать.
- М — машина, то есть поток, который будет запускаться на процессоре и выполнять ваши задачи.
- Р — процессор, который будет выполнять работу.
Когда вы запускаете программу, написанную на голанге, среда исполнения читает GOMAXPROC для того, чтобы узнать, сколько реальных процессорных ядер существует в системе. Хотя нет, звучит как-то неправильно. Редко кто выставляет GOMAXPROC перед запуском программ на голанге, и ничего, работает на мультипроцессорных системах.
Давайте посмотрим в сорец. На строке 706 в proc.go находим следующее:
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}Это всё происходит в функции schedinit, которая как раз занимается запуском планировщика задач. Смотрим на комментарий к этой функции и выясняем:
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime main.Ага, то есть мы не просто запускаем планировщик, мы стартуем нашу программу. Для начала включается osinit и как раз в секции инициализации операционной системы делаем вот что:
cpuinit() // must run before alginitКстати, прямо перед этим мы выставляем sched.maxmcount = 10000. То есть изначально мы зачем-то ограничиваем максимальное количество машин до 10000. Запомним это и пойдём дальше.
Cpuinit вместе с osinit с помощью приличного количества ассемблера и вызова функций из стандартных библиотек OC выясняют количество ядер, доступных на конечной машине. Исходники данных функций разные для разных процессоров и ОС, посему здесь мы в детали лезть не будем, ибо их очень уж много.
Как бы то ни было, мы выставляем количество процессоров, основываясь на данных из ОС, а ПОСЛЕ этого перегружаем количество процессоров тем, что хранится в GOMAXPROCS. А если в GOMAXPROCS записана белиберда, то мы на неё забиваем и просто продолжаем работать с количеством процессоров, которое дано системой.
Но и тут у нас есть первая возможность серьёзно ошибиться. Выставляя GOMAXPROCS в определённое значение, вы берёте на себя ответственность за понимание того, как работает планировщик. Если выставить GOMAXPROCS в значение больше того, что на самом деле есть в ОС, то можно серьёзно запороть скорость выполнения своей программы.
Кстати, читая документацию и роясь чуть глубже, находим, что maxmcount можно изменить вызовом
debug.SetMaxThreads. В документации этой функции мы видим, что ограничение произвольное, но позволяет предотвратить убийство операционной системы созданием неограниченного количества потоков. Функция эта предназначена в основном для отладки. Среда исполнения упадёт в тот момент, когда мы попытаемся создать больше потоков (М, машин), чем это значение.Смотрим, что делает func main, помимо инициализации планировщика. Лирическое отступление: видим повсюду, что если мы запускаем программу на wasm, то никаких потоков не создаётся и все горутины запускаются на одной машине. Поэтому будьте осторожны при переносе вашего кода в wasm. С параллелизмом могут быть проблемы.
Далее мы найдём основную горутину, которую нужно будет исполнять, и привяжем её к первому потоку, запущенному ОС. Большинству программ это не особо важно, но есть некоторые ситуации, в которых необходимо, чтобы ваша горутина работала именно на первом потоке ОС.
Теперь вернёмся в мир теории ненадолго. Дано:
- P, G, M.
- Список процессоров в системе.
- Список машин (потоков), которые мы запускаем на этой системе.
- Список задач G, которые мы пытаемся запустить на всём этом добре. Куда и как?
- Список Р достаточно простой. Это массив структур, описывающих процессоры. А вот с М немного интереснее будет.
М — это наш поток выполнения. М — это то, за что сражается операционная система, как мы видели раньше. Чем меньше работающих М, тем легче живётся в стране планирования задач ОС и тем быстрее гарцует процессор. Но при слишком маленьком количестве М у нас накапливается невероятное количество незаконченных горутин.
Посему М можно парковать. Если на данный момент работы нет, то и держать М в активном состоянии не нужно. Его можно отправить в резерв.
Парковка и запуск
Тут важен баланс количества запущенных и припаркованных процессов (М), чтобы правильно использовать все возможные ресурсы системы. Опять же, много потоков — нагружаем процессор, мало потоков — простаиваем. Балансировать тут непросто как минимум по двум причинам:
- Сам планировщик распределённый. Очереди работы (готовые к выполнению горутины) хранятся отдельно для каждого процессора. Так что вычислить, в какой последовательности выполнять все имеющиеся горутины прямо сейчас, невозможно.
- Плюс, как мы видели ранее, ОС и процессор играют в ту ещё чехарду, когда приходится снимать процессы с исполнения. Так что если у нас на подходе есть горутина, но прямо вот сейчас она не готова, то парковать поток исполнения будет глупо, проще подождать 200 циклов и запустить её в уже имеющемся потоке.
Вариантов решения этой проблемы много. Вот, например, неправильные варианты:
- Централизовать планировщик задач. Хотя, понятное дело, с таким подходом у нас будут проблемы с увеличением нагрузки. Планировщик будет бутылочным горлышком.
- Запускать новый поток исполнения, как только появляется новая горутина. Пример — однопоточная программа запускает go(). В таком случае мы можем подобрать новый поток, запустить его на незанятом Р (процессоре) и жить себе поживать. При этом поток, который только что запустил эту горутину, может закончить исполнение, и его самого придётся парковать. Плюс контекст исполнения (переменные, память и кеши) хранится в потоке. Если мы запускаем горутину в новом потоке, то всё это надо будет копировать.
- Можно просто перезапускать новый процесс М, без запуска свежесозданной горутины на этом процессе. При этом у нас появляется возможность запустить ещё больше горутин, если вдруг потребуется. Но если не понадобится, то придётся запускать и парковать поток впустую.
Тут как раз мы понимаем, что переключение контекста — это не просто смена указателя текущей инструкции выполнения программы. С контекстом надо переключить стек. А в стеке могут храниться данные. Например, у нас есть функция 1, которая запускает функцию 2. Функция 2 не будет особо париться и использует адресное пространство потока, в котором запущена функция 1. Исполнение-то у нас не параллельное. Сохраняем текущий указатель стека, прибавляем к нему немного, ровняем это всё по границе памяти и работаем себе спокойно. Когда пришло время возвращать значение, запихиваем его куда надо и кладём обратно положение стека функции 1. Всё! Простота! На ассемблере такое писать можно в три строчки:
push rbp
mov rbp, rsp
sub rsp, 32Теперь представим, что функция 1 и функция 2 — это горутины, которые исполняются в разных машинах М. Тут со стеком вообще чудеса происходят. Возвращать значения через регистры не получится, писать всё надо в память. А если функция 2 пытается воспользоваться данными из функции 1, то и того веселее. Программист сел и написал замыкание, в котором захватил кучу переменных. Их надо будет либо копировать в стек, либо класть в общедоступную память.
Вспомним картинку об устройстве процессора:
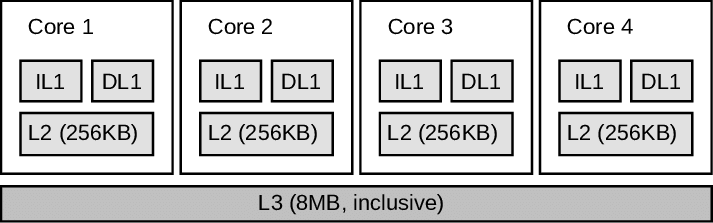
Кеша у нас не то чтобы очень много. Что если одна горутина запускается на первом ядре, а её дочерний процесс на третьем? Потоки исполнения работают на разных ядрах, и второй горутине надо будет ждать, пока данные из памяти попадут в кеш.
Что уж там. Задержки небольшие, волноваться не стоит. Хотя нет, всё-таки стоит. Если нагрузка большая, а ваши горутины маленькие, то как раз таки волноваться очень даже стоит. Каждый раз, когда вы пытаетесь сделать тривиальные вычисления с 4 килобайтами памяти миллиард раз в разных потоках, то проблем может быть много.
Это, кстати, объясняет почему создание бесконечного количества процессов в ОС не помогает. Нам не только нужны параллельные вычисления, они ещё должны быть быстрыми.
И по ходу дела мы можем понять, зачем же и почему нам нужны М. Ведь мы могли бы просто запускать горутины на реальном процессоре Р, без привязки к машинам М. Но теперь всё понятно, ведь М содержит в себе этот контекст исполнения и её легче таскать за собой, если понадобится.
Посему вот вам описание того, как работа распределяется в голанге на данный момент.
Для начала надо понять, что поток исполнения может находиться на холостом ходу. В английской версии это называется spinning. Если вы когда-либо были на текстильных предприятиях, то вы возможно видели нитки, которые снимаются с бобин, и бобины, которые иногда крутятся вхолостую. Посему будем называть это холостым ходом.
Поток исполнения М будет отмечен как работающий вхолостую (m.spinning = true), если у нас произошло следующее:
- Поток М закончил все горутины в очереди исполнения.
- В глобальной очереди исполнения тоже пусто и нет никаких новых горутин.
- В очереди исполнения завершённых таймеров. Если вы запустили Sleep в вашей горутине, то она уходит в спячку, пока ее время тикает. Как только время истекло, эта рутина попадает в специальную очередь выполнения, где ждут подобные горутины.
- В очереди исполнения сетевого стека тоже всё пусто и печально. (Про эту очередь я расскажу чуть дальше по тексту)
Поток поочерёдно осматривает эти очереди, и если в них есть что-либо для исполнения, то он берётся за работу. Если же поток не нашёл никакой приличной работы, то он автоматически припаркуется. (То есть его снимут с процессора и положат в корзинку — подождать).
Все вновь созданные потоки создаются в этом холостом состоянии.
При появлении новой работы (какой-либо горутины) мы запустим новый М, если у нас есть простаивающие процессоры Р и у нас нет потоков М, которые стоят на холостом ходу. Если же у нас есть один поток на холостом ходу, то мы просто передаём работу этому потоку. При этом есть ещё один прикол. Каждый раз, когда какой-либо поток на холостом ходу находит работу и начинает её исполнять, он проверит, есть ли в системе другие потоки на холостом ходу. Если таковых не осталось, то он запустит новый поток и оставит его на холостом ходу.
При таком подходе случайная работа по старту и парковке потоков существенно уменьшается и ресурсы системы используются более правильно.
Итого, дано:
Процессоры, столько-то штук.
Рабочие потоки: В зависимости от нагрузки, по потоку на процессор. Можно запустить и больше при выставлении переменных руками, но это создаст проблемы.
Задачи для выполнения: тьма. В зависимости от того, что случилось в системе. Либо программист вызывает новую задачу, либо таймер тикает, либо пора собирать мусор. Сборщик мусора мог подкинуть задачи для обработки в бэкграунде. Хотя, судя по сорцам, сейчас это отключено (строка 108).
// * Idle-priority GC: The GC wakes a stopped idle thread to contribute to
// background GC work (note: currently disabled per golang.org/issue/19112).
// Also see golang.org/issue/44313, as this should be extended to all GC
// workers.Задачи запускаются на потоках, выполняются и завершаются. Идиллия. Хотя нет, как мы видим, они не всегда завершаются, но при этом могут быть сняты с выполнения. Как, например, то, что мы видели в таймерах. Но есть и другие причины, по которым задачи могут быть не выполнены.
Ввод/вывод информации
Ваша горутина всегда может вызвать что-то такое неприличное, что полностью заблокирует поток исполнения. Например, запросить данные с жёсткого диска. Не SSD, а обычного винчестера. Да ещё и с такого, какой операционная система положила поспать, и для того, чтобы включиться, ему потребуется 5 секунд. Непозволительная трата ресурсов. Ведь в таком виде ваш поток исполнения будет простаивать 5 секунд.
10 лет назад Майкрософт решила бороться с подобной проблемой в Windows 8 путём создания новых API, в которых все подобные обращения к дискам или сетевым ресурсам были асинхронными по умолчанию. Каждый раз, когда вы обращались к диску, вам надо было писать замыкание или коллбэк для обработки результата. Конечно, идея была простая, все программисты просто возьмут и перейдут на новые API, правильно? Ха. Прямо вот так все и спохватились.
Сама идея ввода-вывода в голанге решена просто. У нас нет API для асинхронного ввода и вывода. Всё, что вам нужно сделать асинхронно — делайте сами через горутины. Казалось-бы странное решение. Другие платформы из кожи вон лезут, пытаясь предоставить асинхронные системы, а мы в голанге просто на всё это забиваем и ничего предоставлять не будем. Но всё как раз наоборот. Создавая хорошо продуманную среду исполнения, мы делаем так, что вам не нужно будет париться по поводу работы с асинхронными системами ввода/вывода.
Ну и на самом-то деле. Синхронные системы намного проще использовать. Как вам такое — создавать новый поток в пуле на каждую операцию чтения/записи? А современные извращения, которые используются в Javascript/Java и С# вообще стоят отдельного упоминания. Ведь мы в шарпах уже навернули полный круг и пришли к async/await операциям.
Теперь вместо создания нового потока можно просто писать:
var text = await File.ReadAllLinesAsync(...);В голанге подобное не нужно. Просто пишите синхронные операции ввода/вывода и, когда надо, запускайте их в горутинах. А среда исполнения как раз подчистит все неприятные моменты, которые могут быть с этим связаны.
Системные вызовы бывают разными. Некоторые бывают очень быстрыми, например, когда нам надо узнать текущее время, некоторые могут заблокировать поток исполнения. В любом случае при выполнении системного вызова процессор становится непригодным для выполнения нашего кода, поскольку мы должны переключить процессор в пространство ядра, а там наш код будет недоступен, пока ОС не вернёт нам значение.
Как же мы будем работать с горутиной, которая попытается совершить системный вызов и запросит запретные данные, создавая беспощадные задержки, которые приведут к лагам программы?
Если мы решаем проблему в лоб, то мы можем просто запустить программу на потоке М и прямо после того, как этот поток совершит системный вызов на процессоре Р, мы отвяжем М от этого Р и переведём его выполнение на другое свободное ядро. После того как мы получаем данные нашего системного вызова и считаем его завершённым, мы попытаемся приземлить поток выполнения М на наш процессор Р. А если мы сняли поток исполнения процессора и узнали, что у нас нет дополнительных процессоров, на которые этот поток можно приземлить, то мы просто припаркуем эту горутину в глобальной очереди исполнения. Пусть она посидит и подождёт, ничего с ней не сделается.
Но тут вот в чём прикол. В мире документации мы можем увидеть, что все системные вызовы в теории блокирующие и переводящие процессор в режим исполнения ядра. Хотя на самом деле это не так. У нас давно появились vDSO, которые позволяют запрашивать некоторые данные без блокировок.
Просто если уж нам и хочется совершить системный вызов — уж очень это муторно — снимать поток исполнения с процессора и искать новый процессор для продолжения выполнения того, что можно. Слишком много усилий надо прикладывать для того, чтобы скопировать все структуры данных, которые идут в комплекте с этими машинами М и процессорами Р. Да и в дополнение ко всему, если мы попадаем в ситуацию, когда у нас не хватает процессоров для обработки всех существующих горутин, которые готовы выполнятся, то исходя из такого планирования обработки системных вызовов, нам придётся парковать горутину, которая сделала этот вызов. Вся эта волокита просто бесполезна, если ваши системные вызовы завершаются быстро или вообще не ходят в систему и получают ответ за наносекунды из vDSO.
Посему в голанге у нас есть два варианта исполнения этих горутин: пессимистичный и оптимистичный.
При пессимистичном варианте исполнения среда просто сдаётся, вешает плечи и говорит “Ну вас нафиг, не могу я уже больше”, отпускает текущий процессор Р перед системным вызовом и попытается получить этот процессор обратно, когда вызов завершён.
При оптимистичном варианте среда говорит: «а что уж там, просто пометим этот процессор флагом» — “занят выполнением системного вызова” и забивает на все проблемы. При этом поток М с процессора не снимается, но потоки могут захватить работу из очереди выполнения данного потока, если они, в свою очередь, попали в состояния простоя на холостом ходу.
Давайте пойдём дальше и найдём строчку:
5244: func sysmon() {А вот и один из главных героев того, что происходит в рантайме. Эта горутина работает постоянно. Под капотом можно найти много интересного, включая обработку состояния процессоров, которые ожидают выполнения системного вызова. В частности, sysmon пытается “забрать” ядра, которые заняты выполнением системных вызовов:
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}Смотрим глубже в то, что происходит внутри retake:
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}Ага, то есть мы попытаемся освободить процессор, который занят ожиданием выполнения системного вызова. Но при всём при этом мы не будем уж слишком жадничать. Если у нас в текущий момент нет работы, то мы их оставим в покое и дадим им поработать над этими системными вызовами. В какой-то момент мы всё равно освободим эти процессоры, потому что они крутились уж очень долго, но это в далёком будущем.
Когда мы всё-таки получаем возвращаемое значение из системного вызова, мы сможем проверить, освободили ли бы этот процессор. Говоря другими словами, мы проверим, если мы “забрали” ковёр из-под ног горутины G и она сидит без процессора, то мы либо дадим этой горутине новый процессор Р, или просто отправим её в глобальную очередь выполнения, где её в конечном итоге подберёт процессор, которому нечего делать.
Если в мире всё чики-пуки и наш системный вызов занял какие-то наносекунды, у нас получается очень небольшой оверхед, мы просто делаем пару проверок и наша горутина просто продолжает работать на том же процессоре без каких-либо изменений. В случае если дела пошли вкось, то горутина, которая застряла на выполнении системного вызова, будет снята с процессора через 20 микросекунд. Если мы находимся в состоянии, когда у нас полно горутин и нет свободных процессоров для их выполнения, то мы жертвуем этими 20 микросекундами.
Это код расчёта задержки, с которой запускается sysmon:
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}Так что, в принципе, система очень даже себе честная и не создаёт большого количества проблем.
netpoll
А пока мы смотрели, как sysmon выполняет системные вызовы, мы наткнулись на вот этот код:
// poll network if not polled for more than 10ms
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(0) // non-blocking - returns list of goroutines
if !list.empty() {
// Need to decrement number of idle locked M's
// (pretending that one more is running) before injectglist.
// Otherwise it can lead to the following situation:
// injectglist grabs all P's but before it starts M's to run the P's,
// another M returns from syscall, finishes running its G,
// observes that there is no work to do and no other running M's
// and reports deadlock.
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}Ну и это последняя остановка в нашем сегодняшнем погружении. Работа с сетью выведена в отдельную систему под названием netpoll.
В переводе с английского слово poll означает опрос. Это наш сетевой опросчик, который проверяет, пришли ли к нам ответы по сети.
Эта подсистема создана для конвертирования неблокирующего сетевого ввода/вывода в тёплый, ламповый блокирующий вывод. Sysmon постоянно запускает netpoll для того, чтобы проверить, не пришло ли время передать выполнение горутинам, которые желают получать данные из сети.
netpoll состоит из двух частей. У нас есть платформно-независимая часть. После этого всё остальное дополняется платформно-зависимой частью. Вот эта версия для Windows, а вот эта для Linux. Эти, кстати, небольшие, всего по 200 строк. Windows-код использует API IoCompletionPort для получения этих данных, в имплементации для Linux используется epoll, а BSD — kqueue.
Каждый раз, когда вы открываете соединение в голанге, вы получаете дескриптор файла, который привязан к этому соединению. Этот дескриптор работает в неблокирующем режиме. Если вы пытаетесь сделать операцию ввода/вывода, но дескриптор для этого ещё не готов, то вы получите ошибку. Когда вы запускаете горутину для чтения/записи в сетевой поток, управление передаётся netpoll, который будет выполнять эту операцию до того момента, как она будет закончена. Сама горутина снимается с процессора и приостанавливает своё выполнение. После этого netpoll вернёт sysmon горутину, в которой операция ввода/вывода завершена. Эта горутина возобновит своё выполнение.
Самое интересное происходит в этих двух функциях:
// returns true if IO is ready, or false if timedout or closed
// waitio - wait only for completed IO, ignore errors
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
// set the gpp semaphore to pdWait
for {
old := *gpp
if old == pdReady {
*gpp = 0
return true
}
if old != 0 {
throw("runtime: double wait")
}
if atomic.Casuintptr(gpp, 0, pdWait) {
break
}
}
// need to recheck error states after setting gpp to pdWait
// this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl
// do the opposite: store to closing/rd/wd, membarrier, load of rg/wg
if waitio || netpollcheckerr(pd, mode) == pollNoError {
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
// be careful to not lose concurrent pdReady notification
old := atomic.Xchguintptr(gpp, 0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
return old == pdReady
}
func netpollunblock(pd *pollDesc, mode int32, ioready bool) *g {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
for {
old := *gpp
if old == pdReady {
return nil
}
if old == 0 && !ioready {
// Only set pdReady for ioready. runtime_pollWait
// will check for timeout/cancel before waiting.
return nil
}
var new uintptr
if ioready {
new = pdReady
}
if atomic.Casuintptr(gpp, old, new) {
if old == pdWait {
old = 0
}
return (*g)(unsafe.Pointer(old))
}
}
}Именно эти две функции добавляют и удаляют горутины из очереди выполнения netpoll. А после этого sysmon сидит и делает уже платформно-зависимый netpoll для того, чтобы узнать, какую горутину можно отправить обратно на выполнение путём передачи оной в очередь завершённых горутин netpoll.
Ну что же, на этом можно начинать подводить итоги.
Заключение
Мы изучили среду исполнения, в которой код не пестрит невнятными и невероятными конструкциями для “упрощения” операций ввода-вывода. Ваш код выглядит просто, но при этом вы не жертвуете правильными подходами для реализации этого многопоточного ввода/вывода.
Мы также видим, что планировщик задач среды исполнения (неважно, голанг или другой среды, мы наверняка найдём подобный подход в других средах) и планировщик ОС — это две совершенно разные вещи.
Написание правильного многопоточного приложения не подразумевает простое создание тысяч потоков. Наоборот, подобное приложение подразумевает наличие хорошо отточенного и проработанного подхода в том, как среда исполнения использует ОС для эффективного запуска и обработки задач.
Разные среды выполнения предоставляют вам разные подходы. Например, в .NET Framework применяется достаточно консервативный режим, который позволяет вам работать как с потоками напрямую, так и с системами пула потоков. В то же время в rust отсутствует сама идея того, что ваша среда исполнения будет как-либо работать за вас. Посему, если вам приспичило использовать какой-либо тредпул, то вам придётся воспользоваться сторонними компонентами, типа Tokio.
Голанг представляет вам абсолютно новый подход к исполнению своих приложений. Всё выглядит так, что вам не приходится задумываться о том, как правильно выполнять многопоточные приложения, но за кулисами происходит очень много. Вы сможете воспользоваться замечательными инструментами среды исполнения, не заморачиваясь тем, как всё это реализовано.
В заключение я хотел бы пересказать одну историю Скота Хансельмана:
Моя свояченица эммигрировала в США из Зимбабве. Ей 30, и она учитель. Она никогда не водила машину (а в США без машины туго). Я посадил её в наш Приус и мы поехали на парковку, где мы с ней тренировались несколько дней. Дело дошло до параллельной парковки, и вот это как раз то, что до неё не доходило ни в каком виде. Я ей сказал: “Ну, представь, как поворачиваются передние колёса, когда ты вращаешь руль”.Есть в мире программисты, которые гордо могут сказать: “Мне не нужно знать, как работает среда исполнения в моём языке программирования.” Это звучит, скажем так, недалёко, и в один прекрасный момент вы найдёте себя в состоянии психического срыва, пытаясь понять, почему ваш новый проект беспощадно тормозит на новом сервере.
“Передние?” — переспросила она — “А какая разница, какие колёса поворачиваются?” Выяснилось, что она не понимала, что поворачиваются передние колёса. Ей казалось, что ВСЕ ЧЕТЫРЕ колеса автомобиля поворачиваются при развороте автомобиля. Я, естественно, настаивал на своём, мол, нет, только передние. Она мне не верила, пока не вылезла из машины и не посмотрела, как я паркуюсь. Она была удивлена тем, что задние колёса на поворачивались и машина следовала положению передних колёс.
— Ты этого не знала? — спросил я.
— Я просто о таком не думала. Я подразумевала, что они все поворачивались, и никогда не задавалась вопросами по этому поводу.
Очевидно, это “подразумевание” превратилось в проблему, когда мы пытались раздебажить её умение парковаться.
Надеюсь, эта информация поможет вам разобраться и понять, как работает среда исполнения голанга и в чём именно заключается принципиальное отличие голанга от других языков программирования.
")


")