В Яндекс.Маркете большая микросервисная архитектура. Браузерный запрос главной страницы Маркета рождает десятки вложенных запросов в разные сервисы (бэкенды), которые разрабатываются разными людьми. В такой системе бывает сложно понять, по какой именно причине запрос упал или долго обрабатывался.
Анатолий Островский megatolya объясняет, как его команда решила эту проблему, и делится практиками, специфичными для Маркета, но в целом актуальными для любого большого сервиса. Его доклад основан на собственном опыте развёртывания нового маркетплейса в довольно сжатые сроки. Толя несколько лет руководил командой разработки интерфейсов в Маркете, а сейчас перешёл в направление беспилотных автомобилей.
— Все наши маркетплейсы построены по общим принципам. Это одна большая единая система. Но если говорить про фронтенд, то, с точки зрения пользователя, приложения абсолютно разные.
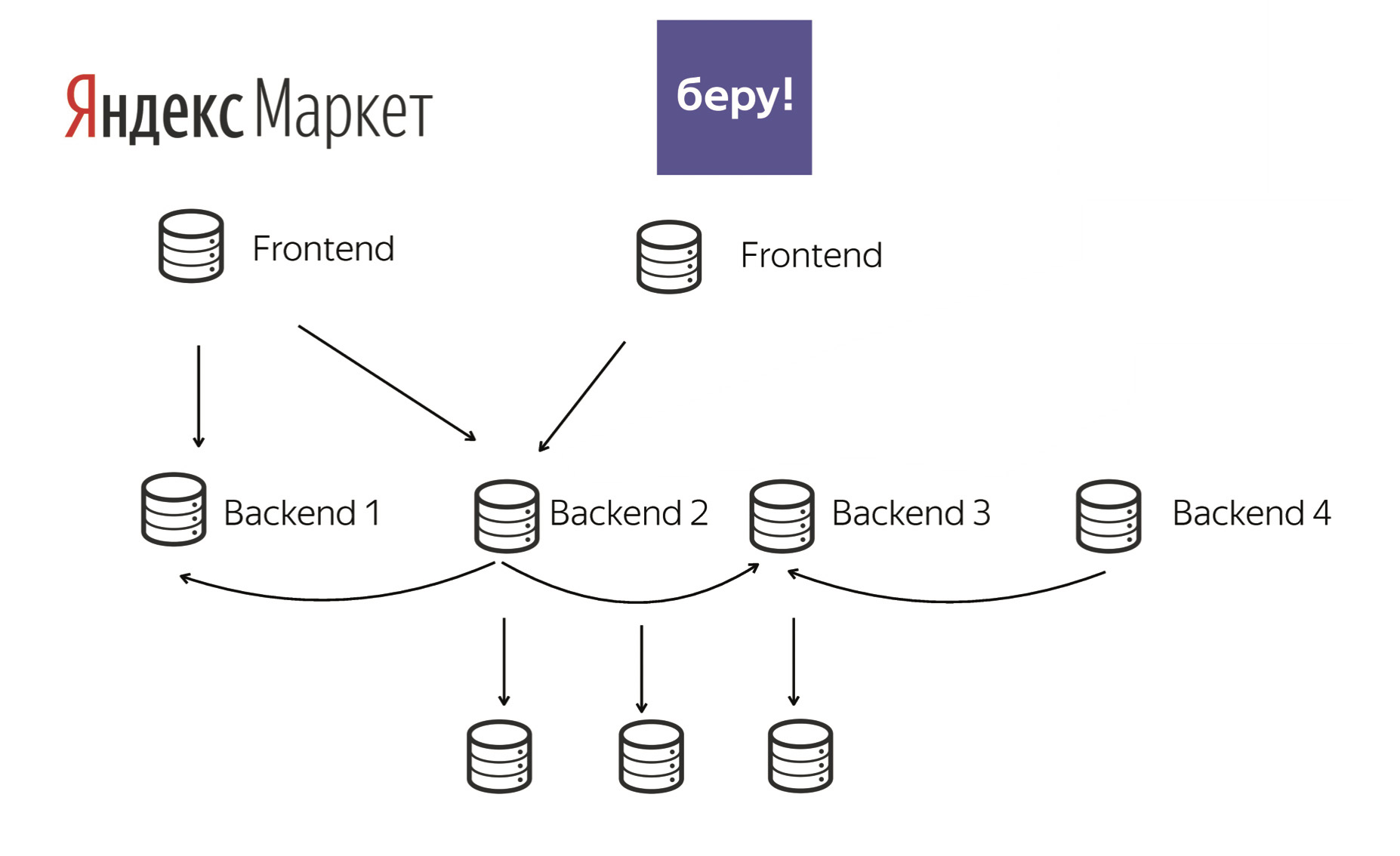
При этом наши фронтенды ходят во многие бэкенды. Иногда эти бэкенды похожи между собой (разные инстансы одного и того же приложения). А иногда они уникальны для сервиса (особенный биллинг). Структуру такой системы можно считать классической микросервисной архитектурой.
В большом сервисе всегда есть проблема — сложно понять, что именно в нем сейчас происходит. Или, например, что происходит в тот момент, когда случается ошибка оплаты у пользователя. Допустим, она произошла у него вчера, а нам сегодня нужно понять, что случилось.
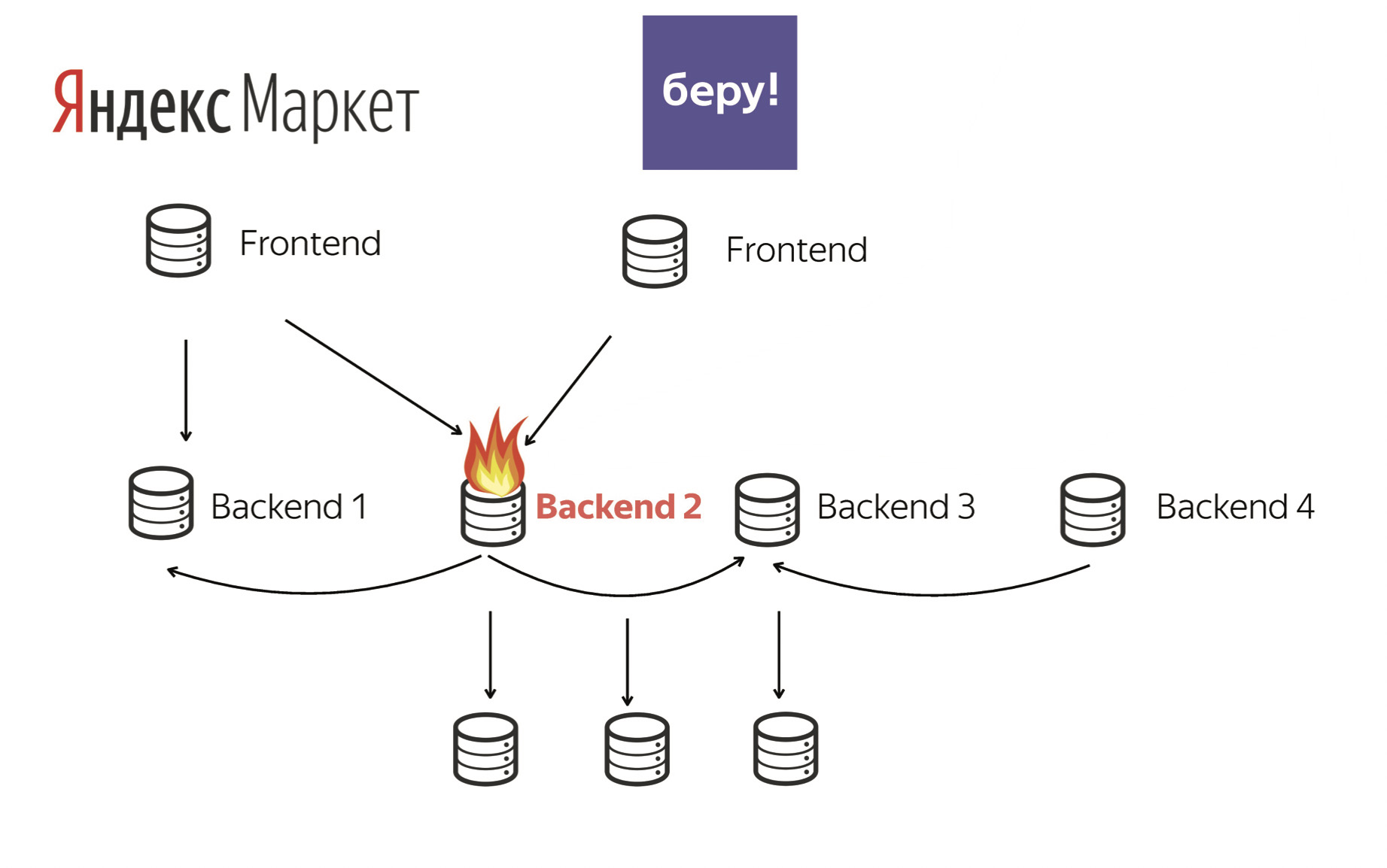
Backend 2 может «гореть» или для конкретного товара, или в конкретное время, или для конкретных пользователей. Нам нужно уметь реагировать на любую ситуацию.

У нас много бэкендов, и, как я говорил, они могут ходить сами в себя. Если это представить в виде графа, то он получится довольно запутанным. В реальной жизни микросервисов может быть сотни. Представьте, сколько между ними будет связей.
Есть много ступеней погружения в эту тему. О каждой из них я коротко расскажу.

В первую очередь, договоритесь с коллегами из бэкенда об общей системе маркировки запросов — так проще их находить потом. Далее нужно уметь быстро воспроизводить проблемы. Допустим, произошла ошибка оплаты — постарайтесь оперативно понять, как она произошла и в каком бэкенде. Храните логи не только в файлах, но и в базе данных, чтобы можно было делать агрегации. И, конечно, важная часть процесса — графики и мониторинги. Дальше обо всем по порядку.

Это один из самых простых инструментов для понимания того, что сейчас происходит с сервисом. Договоритесь с коллегами, что, например, ваш фронтенд генерирует какой-то id-запрос (переменная requestId на картинке) и далее прокидывает его во все endopoints бэкендов. А бэкенд сам уже ничего не перепридумывает. Он берет пришедший requestId и прокидывает его дальше в запросах к своим бэкендам. При этом он может указать свой префикс, чтобы среди одинаковых requestId можно было найти именно этот бэкенд.

Таким образом, когда вы будете грепать свои логи, то, убедившись, что в ваших логах написано, например, что бэкенд спятисотил, может быть два варианта. Вы либо отдадите этот id запроса коллегам, и они посмотрят его в своих логах, либо вы посмотрите сами.

Все наши логи промаркированы такими id, чтобы не только понимать, что и в какой момент произошло, но и сохранять контекст этого запроса. Он асинхронный, может сам попозже что-то в лог дописать. А если грепнуть по requestId, ничего хорошего не выйдет.
Для воспроизведения проблемы мы используем утилиту cURL. Это консольная утилита, которая делает сетевые запросы — http и https. cURL поддерживает еще много разных протоколов, но, занимаясь веб-разработкой, проще считать, что это инструмент для работы с http(s)-запросами.
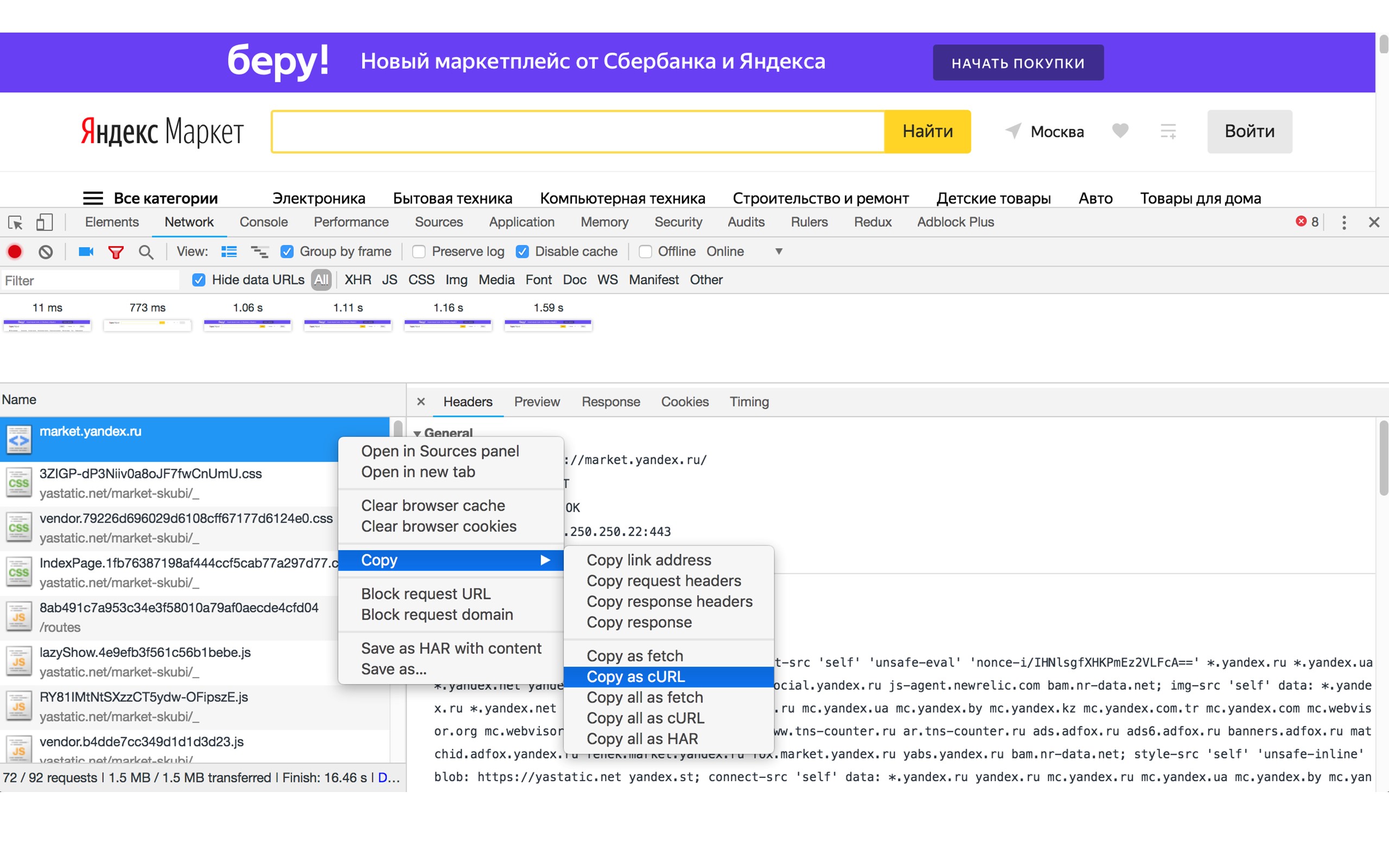
Чтобы познакомиться с командой cURL, можно зайти на любой сайт, затем зайти в Network и скопировать любой запрос в виде cURL. Получится такая большая строка:

Если постараться разобраться, то здесь нет ничего страшного. Давайте попробуем разобрать его по частям.

Здесь написан запрос к сайту market.yandex.ru.

Здесь добавился User-Agent, который занимает уже много места.

На самом деле все остальное место занимают куки. Их довольно много в коде Яндекса. В сериализованном виде у них весьма грозный вид. По факту кроме них здесь больше ничего и нет.
Так чем же полезен cURL? Если бы вы скопировали его себе и запустили, то увидели ту же самую страницу market.yandex.ru, что и я — отличался бы лишь компьютер, на котором он запускался. Конечно, отличия в IP-адресах могло бы дать некоторые сайд-эффекты, но в целом это были бы одинаковые запросы. Мы бы с вами воспроизвели один и тот же сценарий.

Чтобы каждый раз самим не изобретать такие cURL-запросы, можно воспользоваться npm-пакетом format-curl.

Он принимает в себя все параметры запроса, которые обычно принимает функция — то есть в данном случае только заголовки и url. Но также он умеет query, body и т. д. А на выходе получаем просто строку с cURL-запросом.

Поэтому все наши логи в dev-окружении также содержат сURL-запросы.

Мы даже сделали логирование бэкендных cURL-запросов прямо в браузере, чтобы сразу видеть, как мы ходим в наши бэкенды, не заглядывая в консоль браузера.

Учтите, что cURL-запросы подразумевают передачу сессионных куки — это плохо. Если бы вы мне скинули свой cURL-запрос в market.yandex.ru, то я мог бы войти под вашим логином в Маркет и любой другой сервис Яндекса. Поэтому такие запросы мы нигде не храним, а логируем их только в тестовых стендах для себя — таким данным нельзя утекать.
Далее я расскажу про структурированные логи. Здесь я буду иметь в виду конкретную базу данных ClickHouse, но вы можете выбрать любую. ClickHouse — столбцовая СУБД, в ней удобнее делать select из огромного количества данных и принимать в себя большие чанки данных. Она хороша тем, что в ней можно сохранить большой кусок лога и потом, например, сделать какую-то агрегацию по миллиарду записей.

В данном случае пример select по ClickHouse — обычный SQL. Здесь мы показываем количество запросов по статус-кодам за сегодняшний день.
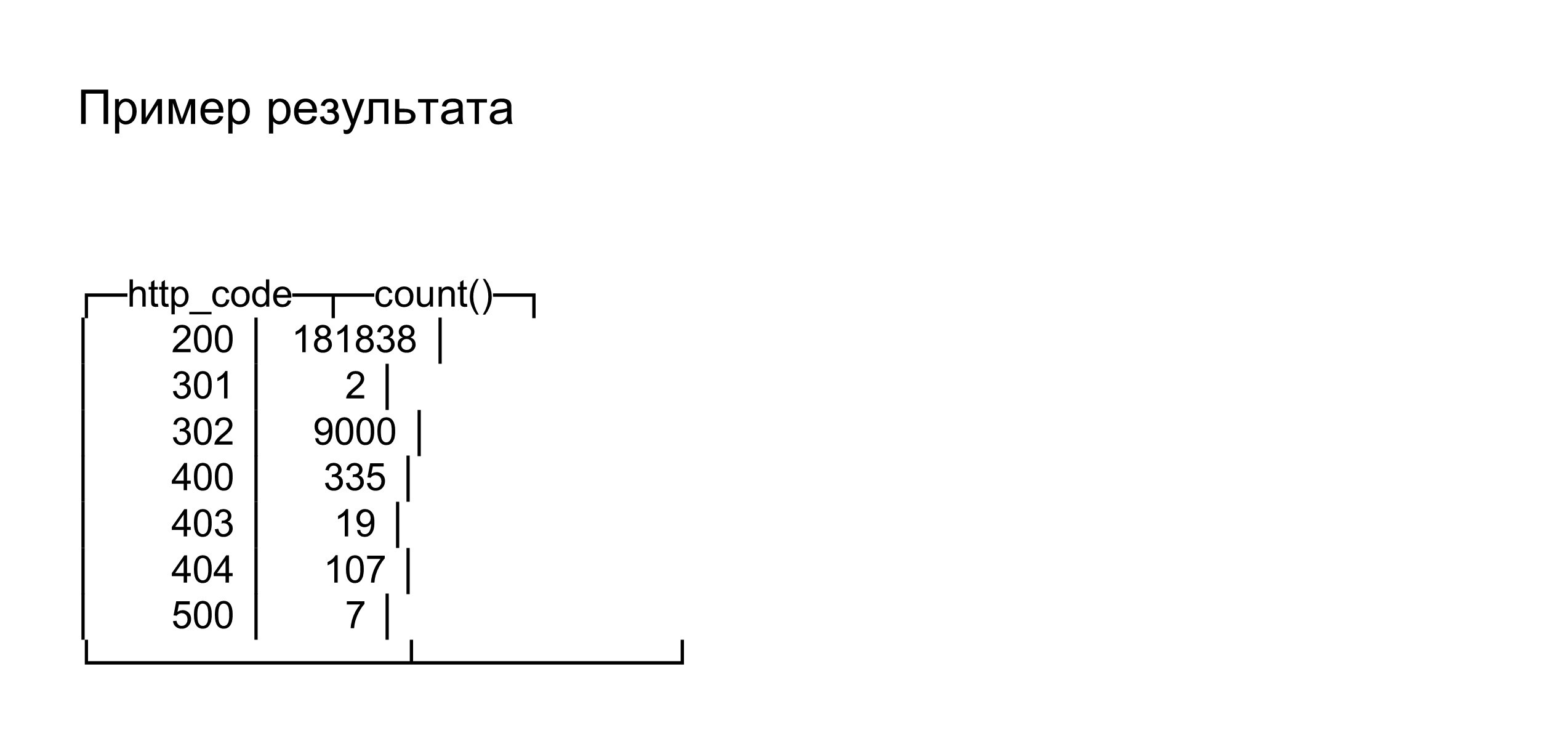
В результате у нас будут 180 тысяч двухсоток и семь пятисоток, а остальные статус-коды, допустим, нам не интересны. Но как мы можем это интересно использовать?

Можно сказать, что отношение двухсоток к отношению общего числа ответов — это Service Level Indicator, который отвечает на вопрос, насколько хорошо работает наше приложение в плане статус-кодов. Он хоть и простой, но уже о чем-то говорит.

На основе нашего индикатора мы можем придумать первый SLI, то есть сказать, например, что 99% наших запросов должны быть ОК. И здесь можем сравнить, что мы выполнили свой SLI. Если бы не выполнили, то могли бы постараться разобрать либо какие-то последние запросы, которые бы пятисотнули, либо просто критичные вещи.

Например, для нас критичны ошибки оплаты, но в данном случае они вернут ноль — повезло :)

Как добиться того, чтобы ваши логи лежали в таком удобном виде, и их можно было забирать через SQL?

Это тема для отдельного большого доклада, и всё сильно зависит от вашей инфраструктуры. Но кажется, здесь есть два пути. Первый: сабмитить метаданные напрямую в runtime, сразу в базу данных. Мы делаем иначе, вторым способом: следим за файлом логов и сабмитим чанками либо тоже в БД, либо в промежуточное место.
У нас это довольно многослойно работает — мы отправляем логи из конкретного инстанса на удаленный сервер-хранилище таких логов.
Нет понятия «трассировка запросов». Этот термин придумали в Google.

Если поискать в интернете «трассировка запросов», то вы встретите команду traceroute. Возможно, это похоже на трассировку запросов.

Есть даже консольная программа, и здесь я ее выполнил для сайта bringly.ru (сервис, который мы разрабатывали прошлой весной). Она помогает понять, через какие машины и сервера проходит запрос перед тем, как попадает на балансер, который ответит либо версткой, либо чем-то другим.

Вот наш балансер. Под трассировкой запросов мы понимаем не это, а все то, что происходит внутри нашего балансера — как запрос живет дальше внутри нашего node.js-приложения.
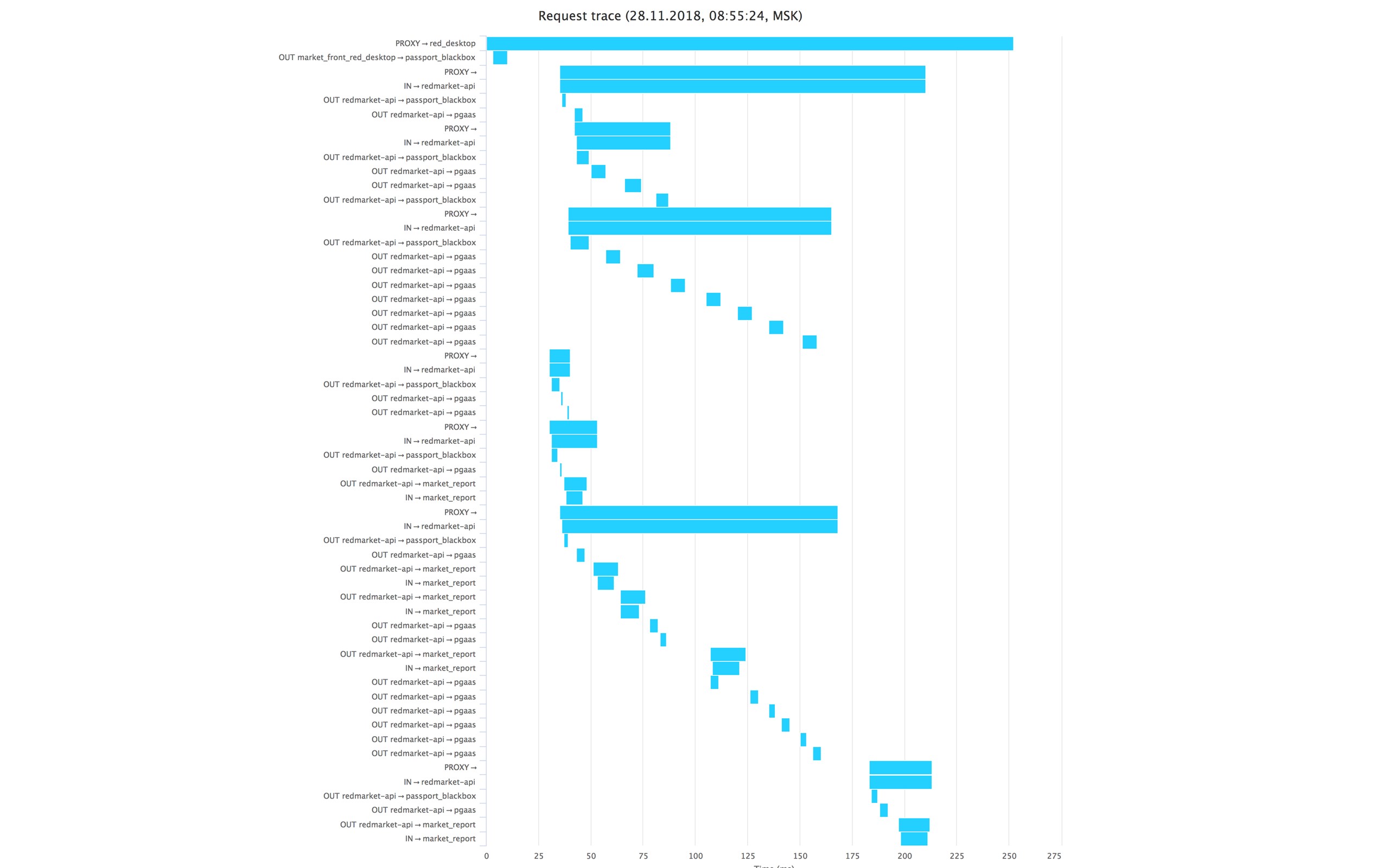
Мы это видим в виде timeline, где по горизонтали отображается время, а по вертикали очередность запросов. В данном случае перед нами запрос к карточке товара, где видно, что это запрос в бэкенд нашей авторизации. После его решения пошли три длинные линии — это уже запрос в наш основной бэкенд за корзиной, карточкой товара и похожими товарами. Так у нас выглядит трассировка.

Здесь видно тот же самый запрос за авторизацией, и далее пошел бэкенд. В данном случае бэкенд ведет себя не очень оптимально, потому что у него есть много последовательных запросов к себе в базу. Вероятно, такой запрос можно было бы оптимизировать.

А вот пример трассировки, когда мы не пошли ни в один бэкенд, а сразу дали статус 500. Чем нам полезна такая трассировка? Нам не придется тревожить коллег. У нас есть id этого запроса, поэтому мы можем сами посмотреть в логи и разобраться, что происходит.
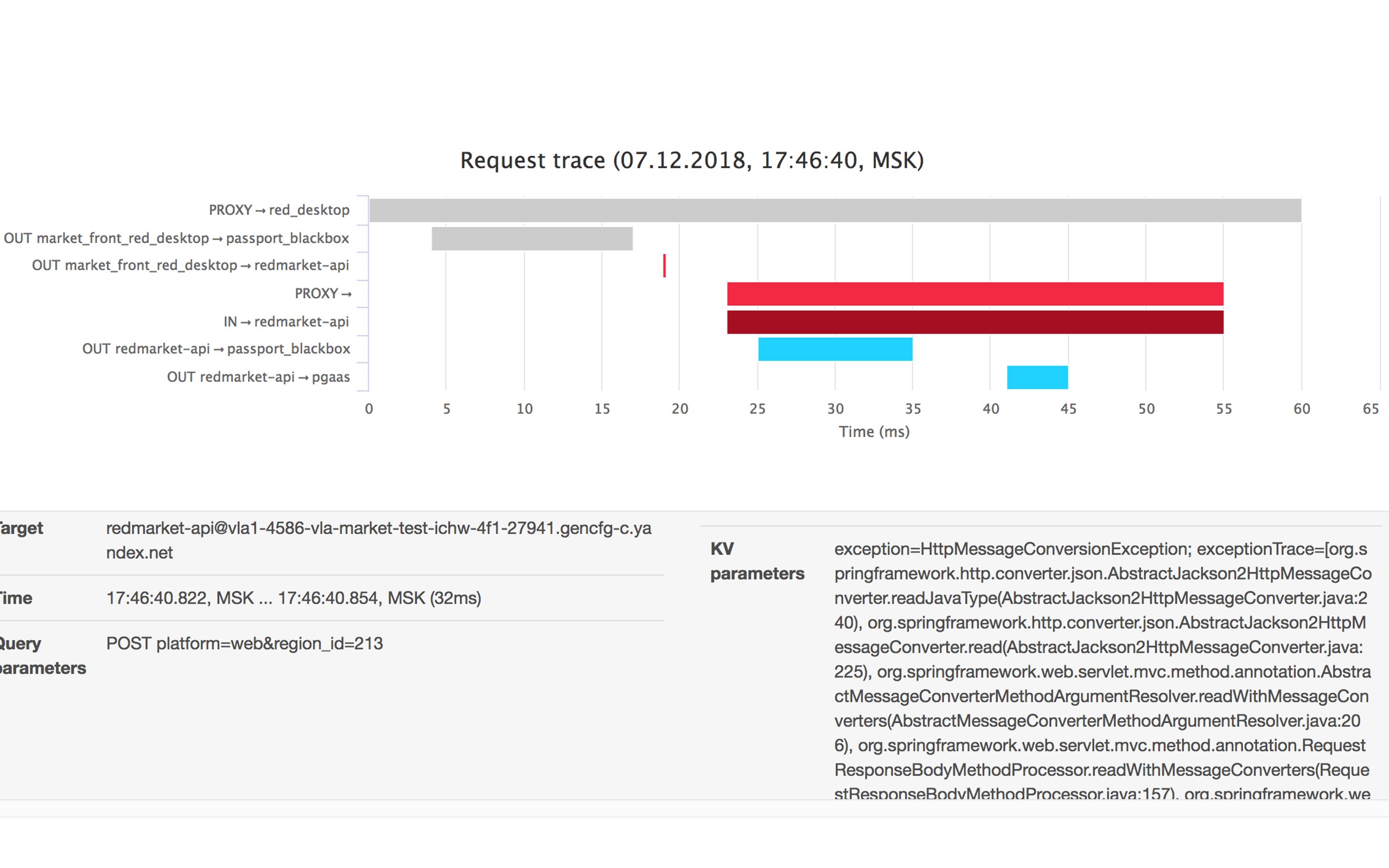
Здесь обратная ситуация. Бэкенд сказал, что что-то не так и при этом написал в метаинформации, что именно произошло — появился какой-то стек-трейс.

Как сделать себе такой же инструмент?
Самое важное здесь — база данных. Если у вас есть простейший «INSERT INTO» в базе каких-то действий с сервисом, позже можно будет как минимум с помощью SQL находить нужные события. А при необходимости можно сделать к этому интерфейс.
Это очень интересная тема, подробно останавливаться на ней сегодня, конечно, не буду :)

Поговорим именно про логирование. Графиков у нас много, мы на них смотрим, когда что-то выкатываем — и в таймингах происходит такой шум.

Графики помогают визуально увидеть, что что-то не так. А дальше нужно все равно смотреть в логи и по ним понимать, что конкретно не так. В данном случае всплеск сразу после релиза как минимум означает, что такой релиз нужно немедленно откатывать.
Еще более важная часть и более сильная степень погружения в эту тему — мониторинги. Под мониторингами я понимаю, во-первых, автоматическое наблюдение за графиками и, во-вторых, любые автоматизированные правила наблюдения за чем-либо.

Мы мониторим соотношение пятисоток к общему числу ответов в минуту. Также мониторим четырехсотки, наличие нагрузки на сервис, проверку ручки health check, который дергает ручку ping каждого из бэкендов и т. д.
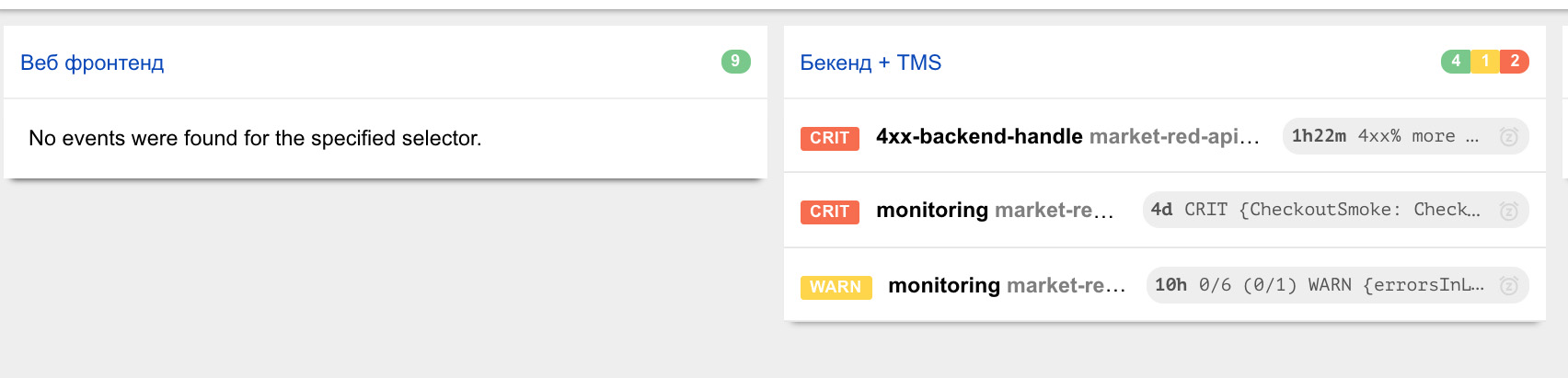
Кроме того, у нас есть дашборды мониторингов, которые мы включаем на экранах около рабочих мест. Так мы сразу видим, какие из мониторингов «краснеют». Например, здесь это один из основных, где виден фронтенд и наш основной бэкенд. Здесь видно, что у бэкенда загорелись какие-то мониторинги. Это значит, что в тот момент ответственному за этот сервис придет сообщение в Telegram, либо, возможно, ему даже позвонят — зависит от настройки мониторинга.
Единый requestId поможет вам проще находить проблемы в сервисе, который состоит из нескольких приложений. Правильный cURL позволит точнее воспроизводить проблемы и видеть, как вы сами, например, отправляете данные в бэкенд. Структурированные логи позволят придумывать SLI, а ими удобнее пользоваться, чем обычными текстовыми логами. И не забывайте следить за графиками и проводить мониторинги.
Рекомендую почитать книгу Site Reliability Engineering от Google, если вам интересны инфраструктурные вещи.
Анатолий Островский megatolya объясняет, как его команда решила эту проблему, и делится практиками, специфичными для Маркета, но в целом актуальными для любого большого сервиса. Его доклад основан на собственном опыте развёртывания нового маркетплейса в довольно сжатые сроки. Толя несколько лет руководил командой разработки интерфейсов в Маркете, а сейчас перешёл в направление беспилотных автомобилей.
— Все наши маркетплейсы построены по общим принципам. Это одна большая единая система. Но если говорить про фронтенд, то, с точки зрения пользователя, приложения абсолютно разные.
При этом наши фронтенды ходят во многие бэкенды. Иногда эти бэкенды похожи между собой (разные инстансы одного и того же приложения). А иногда они уникальны для сервиса (особенный биллинг). Структуру такой системы можно считать классической микросервисной архитектурой.
В большом сервисе всегда есть проблема — сложно понять, что именно в нем сейчас происходит. Или, например, что происходит в тот момент, когда случается ошибка оплаты у пользователя. Допустим, она произошла у него вчера, а нам сегодня нужно понять, что случилось.
Backend 2 может «гореть» или для конкретного товара, или в конкретное время, или для конкретных пользователей. Нам нужно уметь реагировать на любую ситуацию.
У нас много бэкендов, и, как я говорил, они могут ходить сами в себя. Если это представить в виде графа, то он получится довольно запутанным. В реальной жизни микросервисов может быть сотни. Представьте, сколько между ними будет связей.
Есть много ступеней погружения в эту тему. О каждой из них я коротко расскажу.
В первую очередь, договоритесь с коллегами из бэкенда об общей системе маркировки запросов — так проще их находить потом. Далее нужно уметь быстро воспроизводить проблемы. Допустим, произошла ошибка оплаты — постарайтесь оперативно понять, как она произошла и в каком бэкенде. Храните логи не только в файлах, но и в базе данных, чтобы можно было делать агрегации. И, конечно, важная часть процесса — графики и мониторинги. Дальше обо всем по порядку.
Единая система идентификации запросов
Это один из самых простых инструментов для понимания того, что сейчас происходит с сервисом. Договоритесь с коллегами, что, например, ваш фронтенд генерирует какой-то id-запрос (переменная requestId на картинке) и далее прокидывает его во все endopoints бэкендов. А бэкенд сам уже ничего не перепридумывает. Он берет пришедший requestId и прокидывает его дальше в запросах к своим бэкендам. При этом он может указать свой префикс, чтобы среди одинаковых requestId можно было найти именно этот бэкенд.
Таким образом, когда вы будете грепать свои логи, то, убедившись, что в ваших логах написано, например, что бэкенд спятисотил, может быть два варианта. Вы либо отдадите этот id запроса коллегам, и они посмотрят его в своих логах, либо вы посмотрите сами.
Все наши логи промаркированы такими id, чтобы не только понимать, что и в какой момент произошло, но и сохранять контекст этого запроса. Он асинхронный, может сам попозже что-то в лог дописать. А если грепнуть по requestId, ничего хорошего не выйдет.
cURL
Для воспроизведения проблемы мы используем утилиту cURL. Это консольная утилита, которая делает сетевые запросы — http и https. cURL поддерживает еще много разных протоколов, но, занимаясь веб-разработкой, проще считать, что это инструмент для работы с http(s)-запросами.
Чтобы познакомиться с командой cURL, можно зайти на любой сайт, затем зайти в Network и скопировать любой запрос в виде cURL. Получится такая большая строка:
Если постараться разобраться, то здесь нет ничего страшного. Давайте попробуем разобрать его по частям.
Здесь написан запрос к сайту market.yandex.ru.
Здесь добавился User-Agent, который занимает уже много места.
На самом деле все остальное место занимают куки. Их довольно много в коде Яндекса. В сериализованном виде у них весьма грозный вид. По факту кроме них здесь больше ничего и нет.
Так чем же полезен cURL? Если бы вы скопировали его себе и запустили, то увидели ту же самую страницу market.yandex.ru, что и я — отличался бы лишь компьютер, на котором он запускался. Конечно, отличия в IP-адресах могло бы дать некоторые сайд-эффекты, но в целом это были бы одинаковые запросы. Мы бы с вами воспроизвели один и тот же сценарий.
Чтобы каждый раз самим не изобретать такие cURL-запросы, можно воспользоваться npm-пакетом format-curl.
Он принимает в себя все параметры запроса, которые обычно принимает функция — то есть в данном случае только заголовки и url. Но также он умеет query, body и т. д. А на выходе получаем просто строку с cURL-запросом.
Поэтому все наши логи в dev-окружении также содержат сURL-запросы.
Мы даже сделали логирование бэкендных cURL-запросов прямо в браузере, чтобы сразу видеть, как мы ходим в наши бэкенды, не заглядывая в консоль браузера.
Учтите, что cURL-запросы подразумевают передачу сессионных куки — это плохо. Если бы вы мне скинули свой cURL-запрос в market.yandex.ru, то я мог бы войти под вашим логином в Маркет и любой другой сервис Яндекса. Поэтому такие запросы мы нигде не храним, а логируем их только в тестовых стендах для себя — таким данным нельзя утекать.
ClickHouse
Далее я расскажу про структурированные логи. Здесь я буду иметь в виду конкретную базу данных ClickHouse, но вы можете выбрать любую. ClickHouse — столбцовая СУБД, в ней удобнее делать select из огромного количества данных и принимать в себя большие чанки данных. Она хороша тем, что в ней можно сохранить большой кусок лога и потом, например, сделать какую-то агрегацию по миллиарду записей.
В данном случае пример select по ClickHouse — обычный SQL. Здесь мы показываем количество запросов по статус-кодам за сегодняшний день.
В результате у нас будут 180 тысяч двухсоток и семь пятисоток, а остальные статус-коды, допустим, нам не интересны. Но как мы можем это интересно использовать?
Можно сказать, что отношение двухсоток к отношению общего числа ответов — это Service Level Indicator, который отвечает на вопрос, насколько хорошо работает наше приложение в плане статус-кодов. Он хоть и простой, но уже о чем-то говорит.
На основе нашего индикатора мы можем придумать первый SLI, то есть сказать, например, что 99% наших запросов должны быть ОК. И здесь можем сравнить, что мы выполнили свой SLI. Если бы не выполнили, то могли бы постараться разобрать либо какие-то последние запросы, которые бы пятисотнули, либо просто критичные вещи.
Например, для нас критичны ошибки оплаты, но в данном случае они вернут ноль — повезло :)
Как добиться того, чтобы ваши логи лежали в таком удобном виде, и их можно было забирать через SQL?
Это тема для отдельного большого доклада, и всё сильно зависит от вашей инфраструктуры. Но кажется, здесь есть два пути. Первый: сабмитить метаданные напрямую в runtime, сразу в базу данных. Мы делаем иначе, вторым способом: следим за файлом логов и сабмитим чанками либо тоже в БД, либо в промежуточное место.
У нас это довольно многослойно работает — мы отправляем логи из конкретного инстанса на удаленный сервер-хранилище таких логов.
Трассировка запросов
Нет понятия «трассировка запросов». Этот термин придумали в Google.
Если поискать в интернете «трассировка запросов», то вы встретите команду traceroute. Возможно, это похоже на трассировку запросов.
Есть даже консольная программа, и здесь я ее выполнил для сайта bringly.ru (сервис, который мы разрабатывали прошлой весной). Она помогает понять, через какие машины и сервера проходит запрос перед тем, как попадает на балансер, который ответит либо версткой, либо чем-то другим.
Вот наш балансер. Под трассировкой запросов мы понимаем не это, а все то, что происходит внутри нашего балансера — как запрос живет дальше внутри нашего node.js-приложения.
Мы это видим в виде timeline, где по горизонтали отображается время, а по вертикали очередность запросов. В данном случае перед нами запрос к карточке товара, где видно, что это запрос в бэкенд нашей авторизации. После его решения пошли три длинные линии — это уже запрос в наш основной бэкенд за корзиной, карточкой товара и похожими товарами. Так у нас выглядит трассировка.
Здесь видно тот же самый запрос за авторизацией, и далее пошел бэкенд. В данном случае бэкенд ведет себя не очень оптимально, потому что у него есть много последовательных запросов к себе в базу. Вероятно, такой запрос можно было бы оптимизировать.
А вот пример трассировки, когда мы не пошли ни в один бэкенд, а сразу дали статус 500. Чем нам полезна такая трассировка? Нам не придется тревожить коллег. У нас есть id этого запроса, поэтому мы можем сами посмотреть в логи и разобраться, что происходит.
Здесь обратная ситуация. Бэкенд сказал, что что-то не так и при этом написал в метаинформации, что именно произошло — появился какой-то стек-трейс.
Как сделать себе такой же инструмент?
Самое важное здесь — база данных. Если у вас есть простейший «INSERT INTO» в базе каких-то действий с сервисом, позже можно будет как минимум с помощью SQL находить нужные события. А при необходимости можно сделать к этому интерфейс.
Графики
Это очень интересная тема, подробно останавливаться на ней сегодня, конечно, не буду :)
Поговорим именно про логирование. Графиков у нас много, мы на них смотрим, когда что-то выкатываем — и в таймингах происходит такой шум.
Графики помогают визуально увидеть, что что-то не так. А дальше нужно все равно смотреть в логи и по ним понимать, что конкретно не так. В данном случае всплеск сразу после релиза как минимум означает, что такой релиз нужно немедленно откатывать.
Мониторинги
Еще более важная часть и более сильная степень погружения в эту тему — мониторинги. Под мониторингами я понимаю, во-первых, автоматическое наблюдение за графиками и, во-вторых, любые автоматизированные правила наблюдения за чем-либо.
Мы мониторим соотношение пятисоток к общему числу ответов в минуту. Также мониторим четырехсотки, наличие нагрузки на сервис, проверку ручки health check, который дергает ручку ping каждого из бэкендов и т. д.
Кроме того, у нас есть дашборды мониторингов, которые мы включаем на экранах около рабочих мест. Так мы сразу видим, какие из мониторингов «краснеют». Например, здесь это один из основных, где виден фронтенд и наш основной бэкенд. Здесь видно, что у бэкенда загорелись какие-то мониторинги. Это значит, что в тот момент ответственному за этот сервис придет сообщение в Telegram, либо, возможно, ему даже позвонят — зависит от настройки мониторинга.
Итоги
Единый requestId поможет вам проще находить проблемы в сервисе, который состоит из нескольких приложений. Правильный cURL позволит точнее воспроизводить проблемы и видеть, как вы сами, например, отправляете данные в бэкенд. Структурированные логи позволят придумывать SLI, а ими удобнее пользоваться, чем обычными текстовыми логами. И не забывайте следить за графиками и проводить мониторинги.
Рекомендую почитать книгу Site Reliability Engineering от Google, если вам интересны инфраструктурные вещи.


