
Разберём основы логирования в Docker и Kubernetes, а затем рассмотрим два инструмента, которые можно смело использовать на продакшене: Grafana Loki и стек EFK (Elasticsearch + Fluent Bit + Kibana).
Материал статьи — выжимка из открытой лекции школы «Слёрм». Если есть желание и тем более производственная необходимость можно пройти полное обучение — записывайтесь на курс по Мониторингу и логированию инфраструктуры в Kubernetes.

Логирование в Docker
На уровне Kubernetes приложения запущены в подах, но на уровне ниже они всё-таки работают обычно в Docker. Поэтому нужно настроить логирование таким образом, чтобы собирать логи с контейнеров. Контейнеры запускает Docker — значит надо разобраться, как логирование устроено на уровне Docker.
Надеюсь, каждый читатель знает: логи приложения надо писать в stdout/stderr, а не внутрь контейнера. Логи агрегирует Docker Daemon, и он работает именно с теми логами, которые отправляются на stdout/stderr. К тому же запись логов внутрь контейнера чревата проблемами: контейнер пухнет от растущего лога (так как никакого Logrotate в контейнере скорее всего нет), а Docker Daemon и не в курсе про этот лог.
У Docker есть несколько лог-драйверов или плагинов для сбора логов контейнеров. В бесплатной версии Docker Community Edition (CE) лог-драйверов меньше, чем в коммерческой Docker Enterprise Edition (EE).

Docker EE я ни разу не использовал на практике: в Southbridge мы стараемся придерживаться Open Source решений, да и клиентам большая часть дополнительных возможностей Docker EE не нужна.
Лог-драйверы в Docker CE:
local — запись логов во внутренние файлы Docker Daemon;
json-file — создание json-log в папке каждого контейнера;
journald — отправка логов в journald.
Настройки логирования в Docker находятся в файле daemon.json.
В поле “log-driver” указывают плагин, а в поле “log-opts” — его настройки. В примере выше указан плагин “json-file”, ограничение по размеру лога — “max-size”: “10m”; ограничение по количеству файлов (настройки ротации) — “max-file”: “3”; а также значения, которые будут прикручены к логам.

Некоторые настройки лог-драйвера можно задать через командную утилиту. Это удобно, если отдельный контейнер нужно запустить с другим лог-драйвером.
Вот как выглядит схема логирования в Docker:
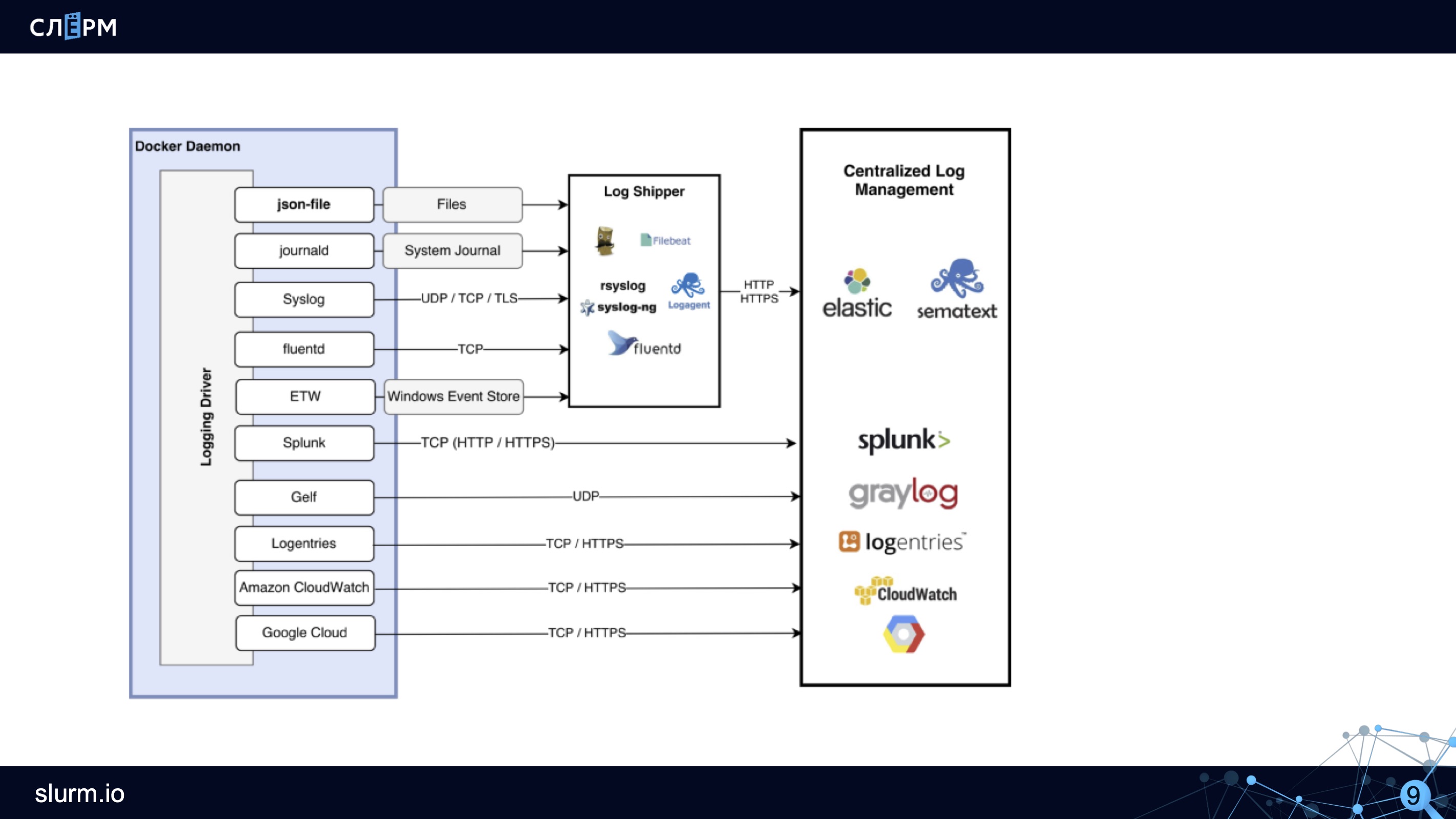
Как схема работает: лог-драйвер, например json-file, создаёт файлы. Сборщики логов (Rsyslog, Fluentd, Logagent и другие) эти файлы собирают и передают на хранение в Elastic, Sematext или другие хранилища.
Особенности логирования в Kubernetes
Упрощённо схема логирования в Kubernetes выглядит так: есть pod, в нём запущен контейнер, контейнер отправляет логи в stdout/stderr. Затем Docker создаёт файл и записывает логи, которые затем может ротировать.

Рассмотрим особенности логирования в Kubernetes.
Сохранять логи между деплоями. Это обязательное условие для корректной настройки логирования. Если не сохранять логи между деплоями, то при выходе новой версии приложения логи предыдущей будут затираться, перезагрузка контейнера также будет чревата потерей логов. У Kubernetes есть ключик --previous, он позволяет посмотреть логи приложения до последнего рестарта Pod, но не глубже.
Агрегировать логи со всех инстансов. Если микросервисы хостятся в облаках, то за контроль системы отвечает облачный провайдер. Если микросервисы на своём железе, то помимо логов с контейнеров нужно собирать и логи системы.
Раньше не было удобных инструментов для сбора логов и с системы, и с микросервисов. Обычно один инструмент собирал системные логи (например, Rsyslog), второй — логи с Docker (например, journal-bit с настройкой лог-драйвера Docker на journald). Пробовали использовать journal-bit — собирать логи и с контейнеров (в лог-драйвере Docker указывать, что нужно писать логи в journald), и с системы (в CentOS 7 уже есть systemd и journald). Решение рабочее, но не идеальное. Если логов много, journal-bit начинает лагать, сообщения теряются.
Эксперименты продолжались — и нашёлся другой способ. В CentOS 7 основные системные логи (messages, audit, secure) дублируются в var-лог в виде файлов. В Docker тоже можно настроить сохранение логов в файлы json. Соответственно, эти файлы из CentOS 7 и Docker можно собирать вместе.
Со временем стало популярно решение ELK Stack. Это комбинация нескольких инструментов: Elasticsearch, Logstash и Kibana.
Elasticsearch хранит логи с контейнеров, Logstash собирает логи с инстансов, Kibana позволяет обрабатывать полученные логи, строить по ним графики. Некоторое время ELK Stack активно использовали, но, на мой взгляд, его время проходит. Позже расскажу, почему.
Добавлять метаданные. Поды, приложения, контейнеры могут быть запущены, где угодно. Более того, у одного приложения может быть несколько инстансов. Логи записаны в одном формате, а нам надо понять, какая именно это реплика, какой Pod это пишет, в каком namespace он находится. Именно поэтому логам нужно добавлять метаданные.
Парсить логи. Забавно, но расходы на поддержку системы логирования и мониторинга могут превысить затраты на основное приложение. Когда у вас летят десятки и сотни тысяч логов в секунду, это кажется закономерным, но всё же надо знать грань. Один из способов эту грань найти — парсинг логов.
Как правило, не нужно собирать и хранить все логи, надо отправлять на хранение только часть — например, логи со статусом «warning» или «error». Если речь про логи nginx или ingress-контроллеров, то отправлять на хранение можно только те, статус которых отличен от 200. Но это не универсальный совет: если вы строите каким-то образом аналитику по логам Nginx, то их очевидно стоит собирать.
Бездумно фильтровать логи не рекомендуют, потому что отфильтрованных данных может не хватить для нормальной аналитики. С другой стороны, возможно аналитику стоит проводить не на уровне логирования, а на уровне сбора метрик. Тогда не придётся хранить сотни тысяч строк с кодом 200. Один из подходов — получать информацию о трафике и ошибках из метрик ingress-контроллеров.
В общем, здесь надо хорошо подумать: что вы хотите хранить и как долго, потому что иначе возникнет ситуация, когда система логирования будет отнимать ресурсов больше, чем основной проект.
Пока нет стандартного решения для логирования. В отличие от мониторинга, где есть одно наиболее распространенное решение Prometheus, в логировании стандарта нет.
В рамках этой лекции мы рассмотрим два инструмента: один популярный, а второй — набирающий популярность. Помимо них есть и другие, но в этой статье мы их не коснёмся.
Учитывая все рассмотренные выше особенности, логирование в Kubernetes теперь можно представить на такой схеме:
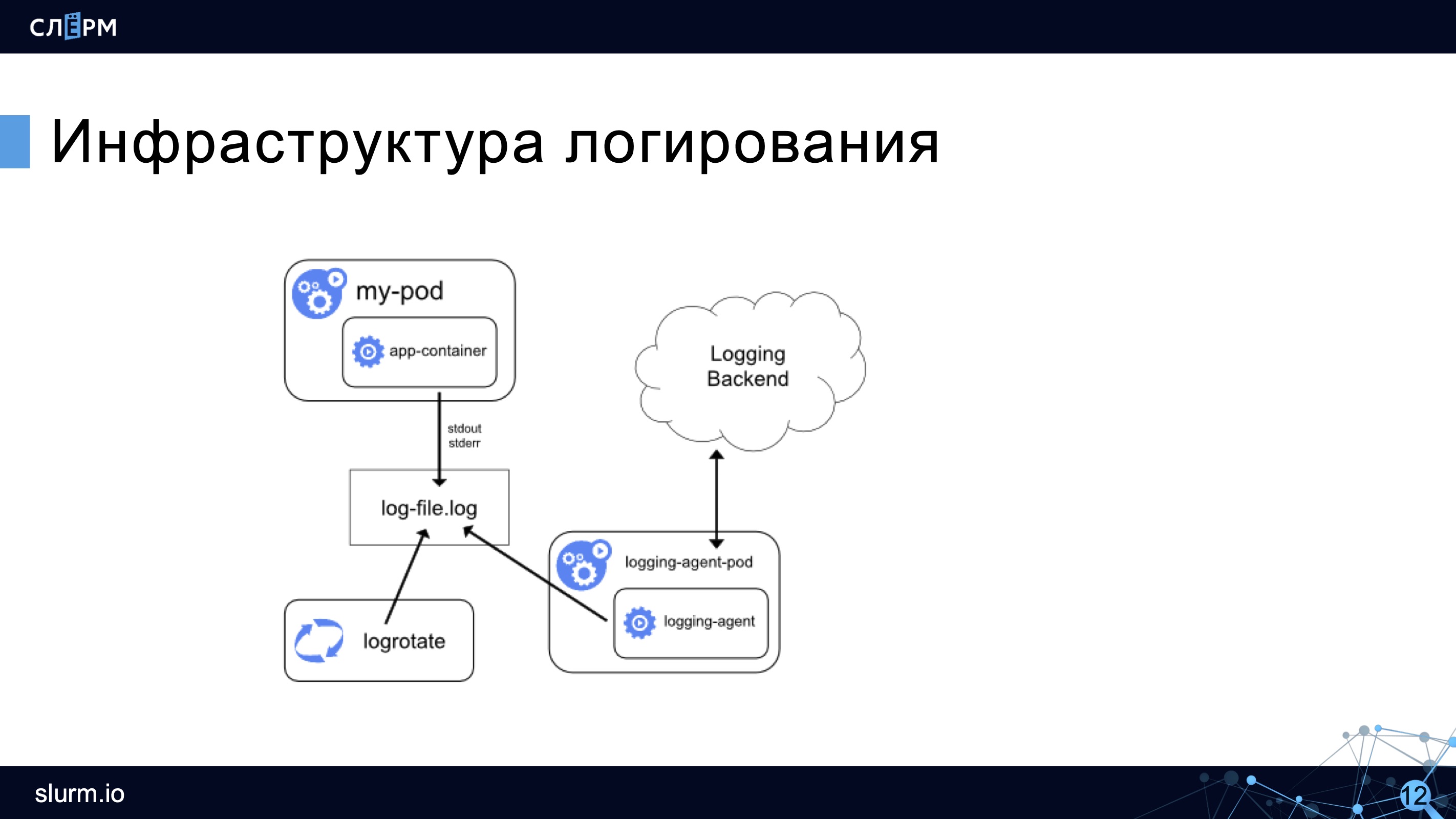
Остаётся лог контейнера, ротирование, но появляется агент-сборщик, который подбирает логи и отправляет на хранение (на схеме — в Logging Backend). Агент работает на каждой ноде и, как правило, запущен в Kubernetes.
Теперь рассмотрим инструменты для логирования.
Grafana Loki
Grafana Loki появился недавно, но уже стал довольно известным. Его преимущества: лёгко устанавливается, потребляет мало ресурсов, не требует установки Elasticsearch, так как хранит данные в TSDB (time series database). В прошлой статье я писал, что в такой базе хранит данные Prometheus, и это одно из многочисленных сходств двух продуктов. Разработчики даже заявляют, что Loki — это «Prometheus для мира логирования».
Небольшое отступление про TSDB для тех, кто не читал предыдущую статью: TSDB отлично справляется с задачей хранения большого количества данных, временных рядов, но не предназначена для долгого хранения. Если по какой-то причине вам нужно хранить логи дольше двух недель, то лучше настроить их передачу в другую БД.
Ещё одно преимущество Loki — для визуализации данных используется Grafana. Очень удобно: в Grafana мы смотрим данные по мониторингу и там же, подключив Loki, смотрим логи. По логам можно строить графики.
Архитектура Loki выглядит примерно так:

С помощью DaemonSet на всех серверах кластера разворачивается агент — Promtail или Fluent Bit. Агент собирает логи. Loki их забирает и хранит у себя в TSDB. К логам сразу добавляются метаданные, что удобно: можно фильтровать по Pods, namespaces, именам контейнеров и даже лейблам.
Инструкция по установке Loki
Loki работает в знакомом интерфейсе Grafana. У Loki даже есть собственный язык запросов, он называется LogQL — по названию и по синтаксису напоминает PromQL в Prometheus. В интерфейсе Loki есть подсказки с запросами, поэтому не обязательно их знать наизусть.
Документация к языку LogQL
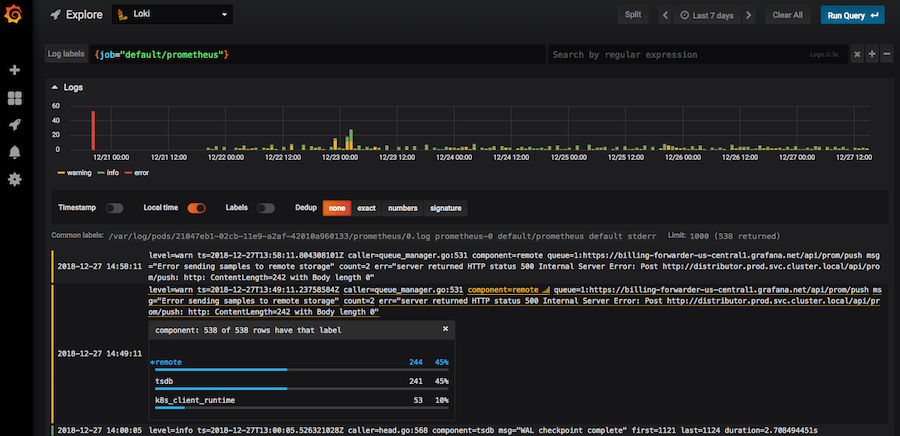
Loki в интерфейсе Grafana
Используя фильтры, в Loki можно найти коды (“400”, “404” и любой другой); посмотреть логи со всей ноды; отфильтровать все логи, где есть слово “error”. Если нажать на лог, раскроется карточка со всей информацией по событию.
В Loki достаточно инструментов, которые позволяют вытаскивать нужные логи, хотя честно говоря, технически их могло быть и больше. Сейчас Loki активно развивается и набирает популярность.
Elastic + Fluent Bit + Kibana (EFK Stack)
Стек EFK — это более классический, и при этом не менее популярный инструмент логирования.
В начале статьи упоминался ELK (Elasticsearch + Logstash + Kibana), но этот стек устарел из-за не очень производительного и при этом ресурсоёмкого Logstash. Вместо него стали использовать более легковесный и производительный Fluentd, а спустя некоторое время ему в помощь пришёл Fluent Bit — ещё более легковесный и ещё более производительный агент-сборщик.
Если верить разработчикам, то Fluent Bit более, чем в 100 раз лучше по производительности, чем Fluentd: «там, где Fluentd потребляет 20 Мб ОЗУ, Fluent Bit будет потреблять 150 Кб» — прямая цитата из документации. Глядя на это, Fluent Bit стали использовать чаще.
У Fluent Bit меньше возможностей, чем у Fluentd, но основные потребности он закрывает, поэтому мы в основном пользуемся Fluent Bit.
Схема работы стека EFK: агент собирает логи со всех подов (как правило, это DaemonSet, запущенный на всех серверах кластера) и отправляет в хранилище (Elasticsearch, PostgreSQL или Kafka). Kibana подключается к хранилищу и достаёт оттуда всю необходимую информацию.
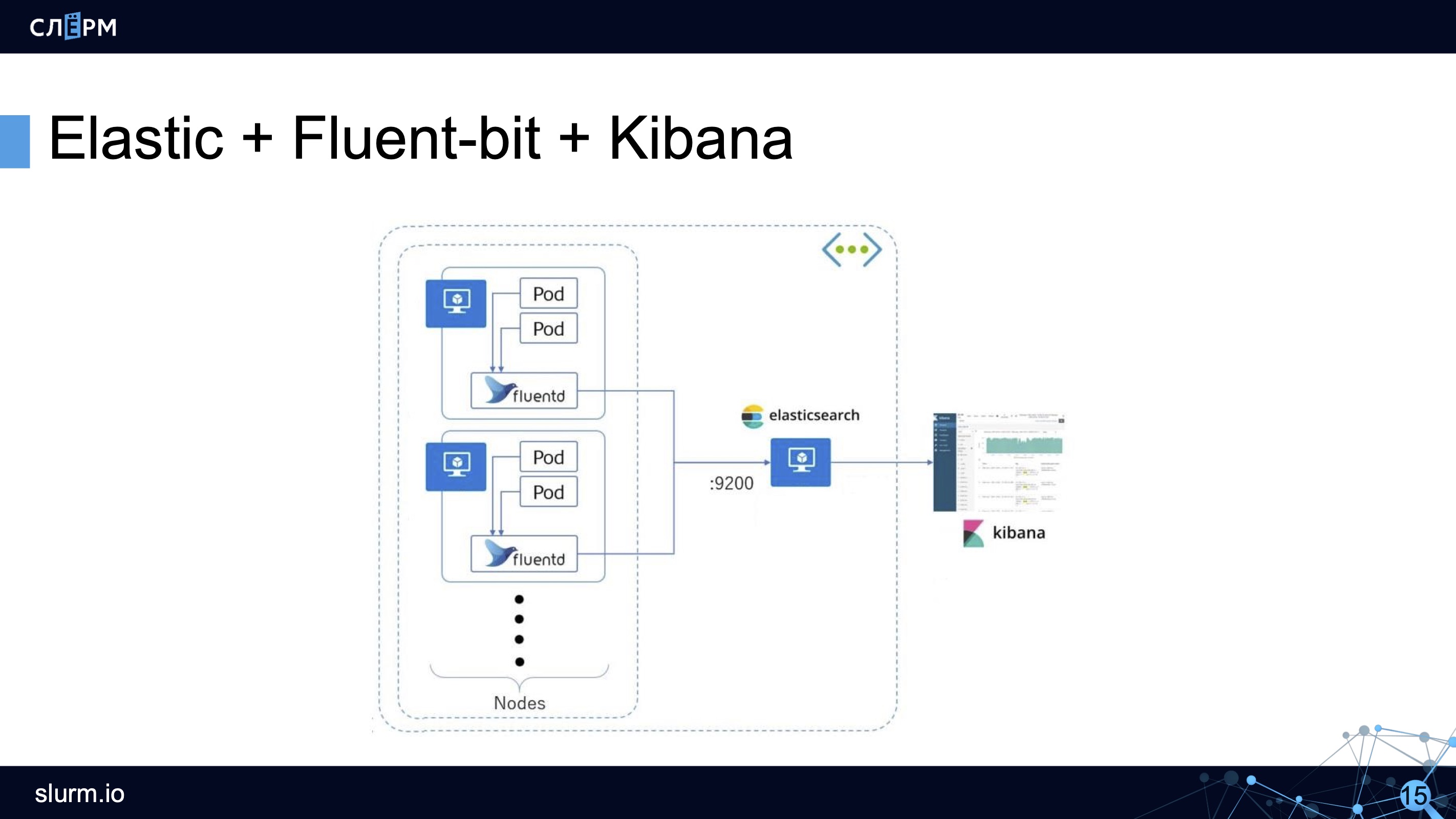
Kibana представляет информацию в удобном веб-интерфейсе. Есть графики, фильтры и многое другое.

По логам можно создавать целые дашборды.
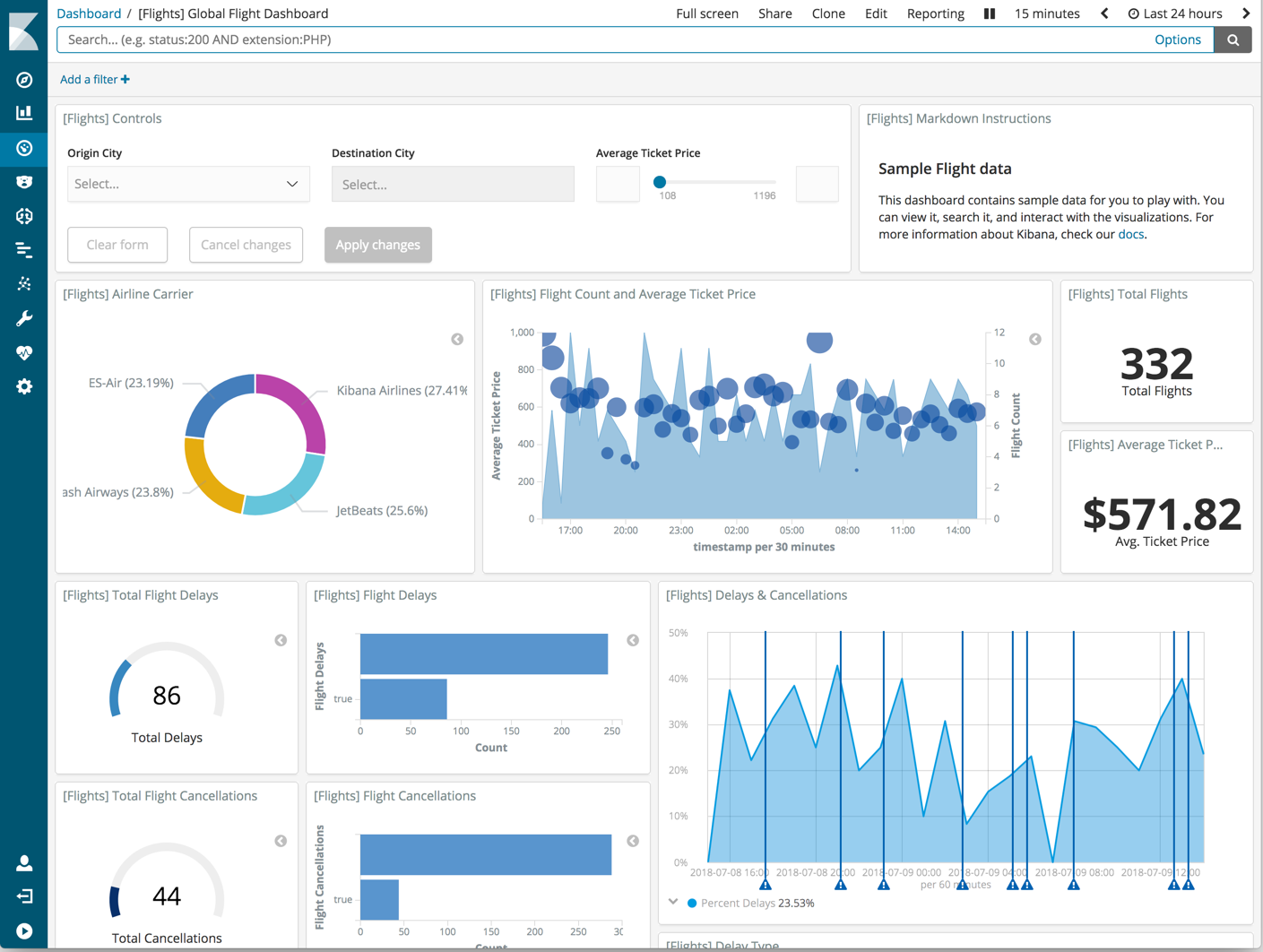
Возможности Fluent Bit
Так как о Fluent Bit, как правило, слышали меньше, чем о Logstash, рассмотрим его чуть подробнее. Fluent Bit логически можно поделить на 6 модулей, на часть модулей можно навесить плагины, которые расширяют возможности Fluent Bit.

Модуль Input собирает логи из файлов, служб systemd и даже из tcp-socket (надо только указать endpoint, и Fluent Bit начнёт туда ходить). Этих возможностей достаточно, чтобы собирать логи и с системы, и с контейнеров.
В продакшене мы чаще всего используем плагины tail (его можно натравить на папку с логами) и systemd (ему можно сказать, из каких служб собирать логи).
Модуль Parser приводит логи к общему виду. По умолчанию логи Nginx представляют собой строку. С помощью плагина эту строку можно преобразовать в JSON: задать поля и их значения. С JSON намного проще работать, чем со строковым логом, потому что есть более гибкие возможности сортировки.
Модуль Filter. На этом уровне отсеиваются ненужные логи. Например, на хранение отправляются логи только со значением “warning” или с определёнными лейблами. Отобранные логи попадают в буфер.
Модуль Buffer. У Fluent Bit есть два вида буфера: буфер памяти и буфер на диске. Буфер — это временное хранилище логов, нужное на случай ошибок или сбоев. Всем хочется сэкономить на ОЗУ, поэтому обычно выбирают дисковый буфер. Но нужно учитывать, что перед уходом на диск логи всё равно выгружаются в память.
Модуль Routing/Output содержит правила и адреса отправки логов. Как уже было сказано, логи можно отправлять в Elasticsearch, PostgreSQL или, например, Kafka.
Интересно, что из Fluent Bit логи можно отправлять во Fluentd. Так как первый более легковесный и менее функциональный, через него можно собирать логи и отправлять во Fluentd, и уже там, с помощью дополнительных плагинов, их дообрабатывать и отправлять в хранилища.
Если планируете использовать Elasticsearch…
Напоследок два совета для тех, кто планирует использовать в продакшене Elasticsearch как хранилище логов.
- Настройте оповещения с помощью ElastAlert. Эта программа вычленяет из общего потока логов важные сообщения и делает по ним алёрты в почту или другой канал. Правда, не так давно вышла грустная новость о том, что проект может скоро прекратить существование.
- Ротируйте логи с помощью приложения Curator или обращения к API Elasticsearch. Сам Elastic, в принципе, сейчас делает существенные шаги по управлению жизнью индексов без применения сторонних инструментов. В целом нет никакого смысла хранить логи долго: вряд ли какой-то лог понадобится спустя две недели — если он действительно критичный, за две недели он точно будет отработан. На крайний случай старые логи можно архивировать и отправлять куда-нибудь на долгосрочное хранение. Я слышал про особенные логи, которые положено по закону хранить до 5 лет. Лично с таким не сталкивался, но я бы подобную информацию не приравнивал к обычным логам, и возможно даже хранил их отдельно.
Продолжение следует...
Автор: Марсель Ибраев, сертифицированный администратор Kubernetes, практикующий инженер в компании Southbridge, спикер и разработчик курсов Слёрм.




