
Многие слышали про Midjourney, но про то, что есть локальная Stable Diffusion, которая может даже больше, знает уже куда меньше людей, или они не знают, что она локальная. И если они пробовали её онлайн, то быстро приходили к выводу, что она сильно хуже чем Midjourney и не стоит обращать на неё более внимания. И да, SD появился раньше Midjourney. Для запуска хватит и cpu или 4гб видеопамяти.
Аналогично с chatGPT, про попытку сделать его локальную версию, не требующую супер компьютер, тоже мало кто слышал и знает, несмотря на то, что выходило несколько статей.

Локальная генерация картинок (Stable Diffusion, на видеокартах AMD, на CPU)
Если вы просто поставите SD и попробуете что-то сгенерировать, то вы увидите в лучшем случае что-то такое:

Это совсем не похоже на уровень Midjourney. Все дело в том, что дефолтная SD модель не понимает, что именно вы от неё хотите без дополнительных правок. Поэтому требуется много ключевых слов (промтов) как позитивных, так и негативных, чтобы добиться приемлемого качества.
Для того, чтобы этим не заниматься существуют уже дотюненные модели, где выставлено чтобы пальцев было 5, а тел 1, и другие ожидаемые от модели параметры. Пример, того же запроса, но на модели Deliberate:

Еще один пример, вроде бы у SD 1.5 что-то получается, но это всё равно далеко от ожидаемого.

Локальный запуск
Итак, чтобы локально запустить Stable Diffusion понадобиться не так много. Установить один из вариантов веб-интерфейсов. Например, самые интересные это вот эти:
stable-diffusion-webui - https://github.com/AUTOMATIC1111/stable-diffusion-webui
InvokeAI - https://github.com/invoke-ai/InvokeAI
SHARK - https://github.com/nod-ai/SHARK
Все они отличаются какой-то особенностью, из-за чего могут быть полезны все. И все схожи в установке, которая не отличается какой-то сложностью, достаточно просто следовать инструкции.
Для запуска будет достаточно видеокарты на 4гб. Если нет gpu, то доступен запуск на cpu - тогда генерация занимает минуты, и за счет оперативной памяти куда большие разрешения, но времени уйдет на это немыслимо. В зависимости от мощности процессора, генерация 512x512 может занять 3-4 минуты на 6 ядерном cpu.
После этого нужно найти и скачать понравившуюся модель, которые расположены на сайте https://civitai.com/

Если не хочется выбирать и сравнивать, то можете сразу взять Deliberate, она является одной из лучших моделей, у неё отлично и с анатомией, и с пальцами.
Все скачанные модели нужно размещать в папке моделей, либо вручную, для webui это будет путь: stable-diffusion-webui\models\Stable-diffusion\, либо через интерфейс добавления моделей, как у InvokeAI.
Самым продвинутым веб-интерфейсом можно назвать stable-diffusion-webui, где помимо базовых широких возможностей без плагинов, также доступны и различные полезные плагины, например, ControlNet - который позволяет делать много разного, не доступного в базовом виде.

В сочетании с плагином Posex можно делать и позы.

У webui легко возвращать забытые промпты и настройки, для этого есть панель с кнопками под кнопкой Generate. Для сгенерированной картинки достаточно перетянуть её в поле ввода, или скопировать чужие промпты, или взять инфо из PNG Info и нажать на кнопку со стрелкой, после этого все поля будут автоматически заполнены.
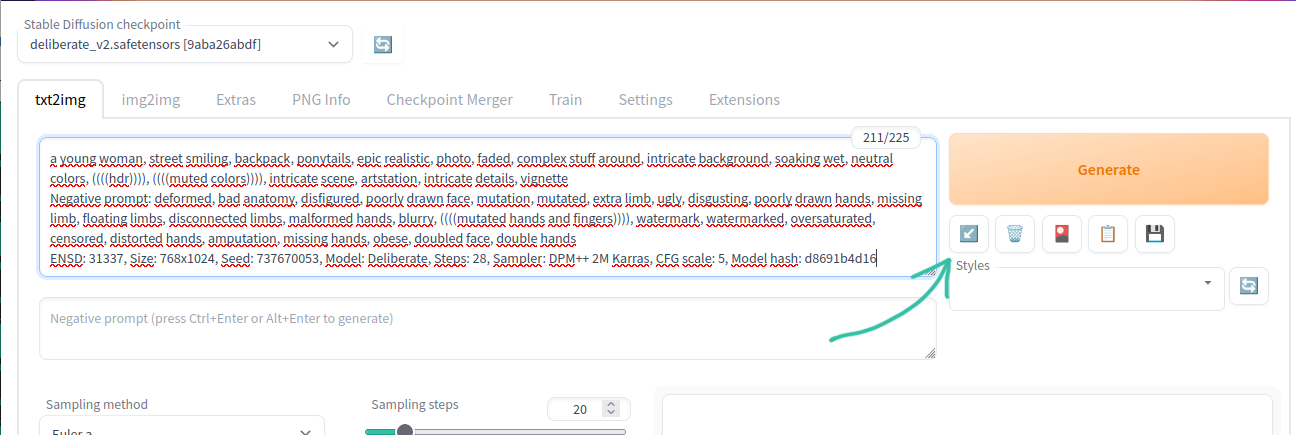
У sd есть проблема с повторяемостью результатов. Из-за того, что разные видяхи используют разные ускорители вычислений, то например, если кто-то сгенерировал картинку с xformers на nvidia, на amd вы не сможете повторить её один в один, и наоборот. Но при этом если вы генерируете в разных веб-интерфейсах с одинаковыми настройками на одинаковой машине, результат будет повторяться. Возможно причина в чем-то другом, но в целом такая проблема существует.
Запуск с ускорением на видеокартах AMD
Для своей работы sd использует pytorch, у которого доступны следующие варианты запуска:

На видеокартах nvidia доступно ускорение через CUDA, а на AMD через ROCm (hip). HIP - это прямой аналог cuda, но на данный момент он работает только под linux. Недавно blender для виндов добавил поддержку hip для виндовс, и в целом работы по переносу hip на windows ведутся, но пока для пользователей windows доступны другие варианты, менее удобные, а именно враппер для Vulkan и DirectML.
Таким образом, есть следующие варианты:
запускать на linux вместе с hip. Например, stable-diffusion-webui установит всё автоматически. Есть поддержка запуска в docker (под wsl2 не сработает).
под windows 2 варианта:
использовать для ускорение vulkan - запуск на vulkan возможен сейчас только sharp, работает почти на том же уровне что и hip, чуть медленее. Но sharp имеет меньше возможностей и настроек.
использовать форк https://github.com/lshqqytiger/stable-diffusion-webui-directml с ускорением через directml. По отзывам не всегда работает стабильно и отваливается с ошибкой о нехватки памяти, там где hip или vulkan работают без проблем. Лечится добавлением ключей запуска, которые замедляют генерацию, но снижает потребление памяти.
На данный момент для видеокарт amd самый быстрый вариант это linux + hip. И с этим есть некоторые особенности. Если всё не завелось автоматически и показывается сообщение об отсутствии hip-устройства, нужно явно указать версию HSA. В консоли перед запуском надо вбить один из 3х вариантов (в зависимости от вашей модели видеокарты):
export HSA_OVERRIDE_GFX_VERSION=10.3.0
export HSA_OVERRIDE_GFX_VERSION=9.0.12
export HSA_OVERRIDE_GFX_VERSION=8.3.0Другой вариант того же самого, например, это вводить команду запуска сразу с указанием нужного:
HSA_OVERRIDE_GFX_VERSION=10.3.0 ~/invokeai/invoke.shЕсли появляется проблема с нехваткой памяти, или видеокарта не поддерживает f16, помогут эти команды (только для webui, в других они выглядят по другому, если вообще есть):
# Если ошибка про half:
--precision full --no-half
# Если хочется генерацию больших разрешений на 8гб памяти:
--medvram
# Если совсем мало памяти, например, 4гб:
--lowvram Каждый из этих параметров сильно снижает скорость генерации (только medvram не существенно). Также medvram поможет при train.
Локальный chatGPT (только CPU)
С локальным chatGPT ситуация не на столько качественная, как с картинками. Но что-то работает. Есть некоторое количество моделей, которые обучены следовать инструкциям.
Для их локального запуска потребуется либо llama.cpp (https://github.com/ggerganov/llama.cpp), либо alpaca.cpp (https://github.com/antimatter15/alpaca.cpp) и найти нужную модель на huggingface. llama.cpp может запускать модели и от alpaca, и от gpt4all и от vicuna, поэтому можно сразу выбрать его для запуска.
Например, alpaca 30B: https://huggingface.co/Pi3141/alpaca-lora-30B-ggml/tree/main
Или 13B vicuna: https://huggingface.co/eachadea/ggml-vicuna-13b-4bit/tree/main
13B - это размер модели, 13 млрд параметров. Для запуска требуется меньше памяти, чем размер модели. Для alpaca 30B - 20гб памяти, а для vicuna 13B всего 4гб памяти. Для 7B совсем мало требуется памяти, можно запускать на Raspberry Pi 4.
Серия статей на хабре про эти модели: https://habr.com/ru/users/bugman/posts/
Или даже больше, попытка энтузиастов со всему мира сделать открытый аналог chatGPT: https://habr.com/ru/articles/726584/

Для запуска в интерактивном режиме (как chatGPT) нужна команда:
# для llama.cpp
./main -i --interactive-first -r "### Human:" --temp 0 -c 2048 -n -1 -t 12 --ignore-eos --repeat_penalty 1.2 --instruct -m ggml-vicuna-13b-4bit.bin
# для alpaca.cpp (можно указать через --threads количество потоков процессора)
./chat -m ggml-model-q4_0.bin --threads 1213B vicuna лучше справляется и с текстом и лучше генерирует код, чем 30B alpaca за счет более качественного подхода к обучению vicuna. Но 30B - это 30B, чем больше параметров, тем "начитаннее" бот.
Итог
Нейросетей для запуска локально становится всё больше. Если вы знаете еще какие-то интересные, то делитесь ими в комментариях.



