
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

TL;DR
- Чтобы добиться высокой наблюдаемости контейнеров и микросервисов, журналов и первичных метрик мало.
- Для более быстрого восстановления и повышения отказоустойчивости приложения должны применять Принцип высокой наблюдаемости (HOP, High Observability Principle).
- На уровне приложение для НОР требуется: должное журналирование, тщательный мониторинг, проверки работоспособности и трассировки производительности/переходов.
- В качестве элемента НОР используйте проверки readinessProbe и livenessProbe Kubernetes.
Что такое Шаблон проверки работоспособности?
Когда проектируешь критически важное и высокодоступное приложение, очень важно подумать о таком аспекте, как отказоустойчивость. Приложение считается отказоустойчивым, если оно быстро восстанавливается после отказа. Типичное облачное приложение использует архитектуру микросервисов – когда каждый компонент помещается в отдельный контейнер. А для того, чтобы убедиться, что приложение на k8s высокодоступно, когда проектируешь кластер, надо следовать определенным шаблонам. Среди них – Шаблон проверки работоспособности. Он определяет, как приложение сообщает k8s о своей работоспособности. Это не только информация о том, работает ли pod, а еще и о том, как он принимает запросы и отвечает на них. Чем больше Kubernetes знает о работоспоспособности pod'а, тем более умные решения принимает о маршрутизации трафика и балансировке нагрузки. Таким образом, Принцип высокой наблюдаемости приложению своевременно отвечать на запросы.
Принцип высокой наблюдаемости (НОР)
Принцип высокой наблюдаемости – это один из принципов проектирования контейнеризированных приложений. В микросеврисной архитектуре сервисам безразлично, как их запрос обрабатывается (и это правильно), но важно, как получить ответы от принимающих сервисов. К примеру, для аутентификации пользователя один контейнер посылает другому запрос HTTP, ожидая ответа в определенном формате – вот и все. Обрабатывать запрос может и PythonJS, а ответить – Python Flask. Контйнеры друг для друга – что черные ящики со скрытым содержимым. Однако принцип НОР требует, чтобы каждый сервис раскрывал несколько конечных точек API, показывающих, насколько он работоспособен, а также состояние его готовности и отказоустойчивости. Эти показатели и запрашивает Kubernetes, чтобы продумывать следующие шаги по маршрутизации и балансировке нагрузки.
Грамотно спроектированное облачное приложение журналирует свои основные события используя стандартные потоки ввода-вывода STDERR и STDOUT. Следом работает вспомогательный сервис, к примеру filebeat, logstash или fluentd, доставляющие журналы в централизованную систему мониторинга (например Prometheus) и систему сбора журналов (набор ПО ELK). На схеме ниже показано, как облачное прилоежние работает в соответствии с Шаблоном проверки работоспособности и Принципом высокой наблюдаемости.
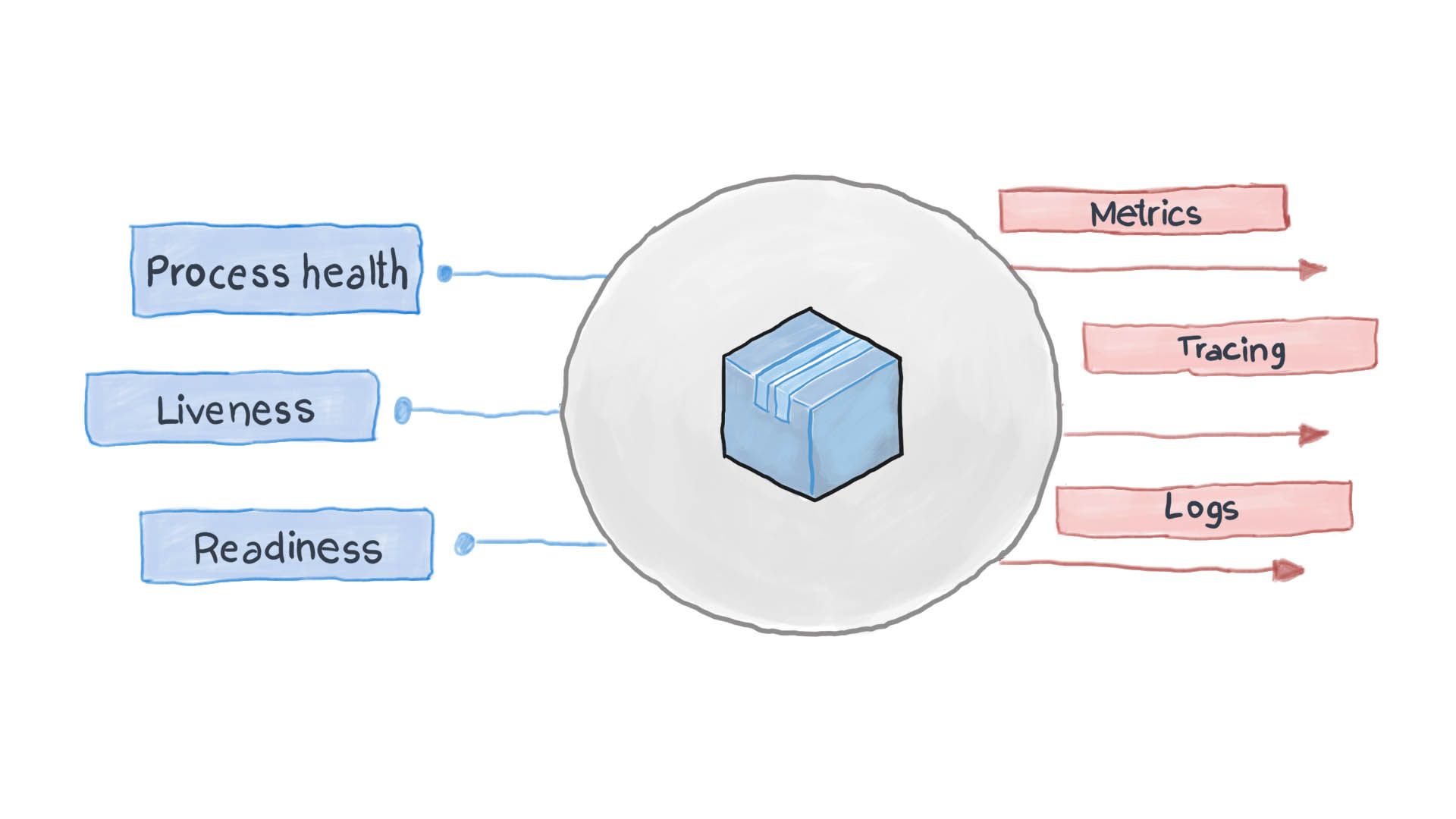
Как применить Шаблон проверки работоспособности в Kubernetes?
Из коробки k8s мониторит состояние pod’ов при помощи одного из контроллеров (Deployments, ReplicaSets, DaemonSets, StatefulSets и проч., проч.). Обнаружив, что pod по некой причине упал, контроллер пытается отрестартить его или перешедулить на другой узел. Однако pod может сообщить, что он запущен и работает, а сам при этом не функционирует. Приведем пример: ваше приложение использует в качестве веб-сервера Apache, вы установили компонент на несколько pod’ов кластера. Поскольку библиотека была настроена некорректно – все запросы к приложению отвечают кодом 500 (внутренняя ошибка сервера). При проверке поставки проверка состояния pod`ов дает успешный результат, однако клиенты считают иначе. Эту нежелательную ситуацию мы опишем следующим образом:
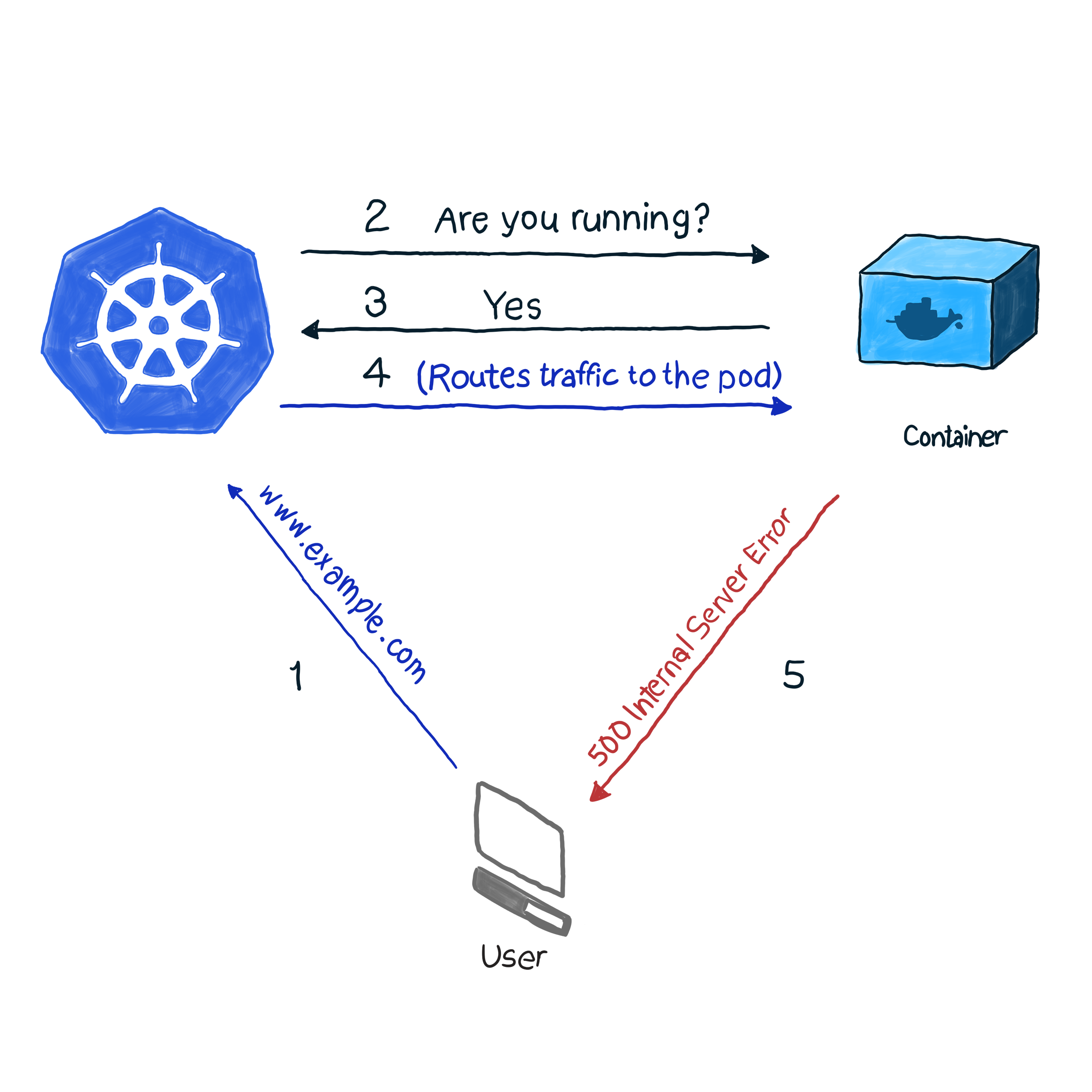
В нашем примере k8s выполняет проверку работоспособности. В этом виде проверки kubelet постоянно проверяет состояние процесса в контейнере. Стоит ему понять, что процесс встал, и он его рестартит. Если ошибка устраняется простым перезапуском приложения, а программа спроектирована так, чтобы отключаться при любой ошибке, тогда вам для следования НОР и Шаблону проверки работоспособности достаточно проверки работоспособности процесса. Жаль только, что не все ошибки устраняются перезапуском. На этот случай k8s предлагает 2 более глубоких способа выявления неполадок в работе pod'а: livenessProbe и readinessProbe.
LivenessProbe
Во время livenessProbe kubelet выполняет 3 типа проверок: не только выясняет, работает ли pod, но и готов ли он получать и адекватно отвечать на запросы:
- Установить HTTP-запрос к pod'у. Ответ должен содержать HTTP-код ответа в диапазоне от 200 до 399. Таким образом, коды 5хх и 4хх сигнализируют о том, что у pod'а проблемы, пусть даже процесс работает.
- Для проверки pod'ов с не-HTTP сервисами (например, почтовый сервер Postfix), надо установить TCP-связь.
- Исполнение произвольной команды для pod'а (внутренне). Проверка считается успешной, если код завершения команды – 0.
Пример того, как это работает. Определение следующего pod'а содержит NodeJS приложение, которое на HTTP-запросы выдает ошибку 500. Чтобы убедиться, что контейнер перезапускается, получив такую ошибку, мы используем параметр livenessProbe:
apiVersion: v1
kind: Pod
metadata:
name: node500
spec:
containers:
- image: magalix/node500
name: node500
ports:
- containerPort: 3000
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 3000
initialDelaySeconds: 5Это ничем не отличается от любого другого определения pod'а, но мы добавляем объект .spec.containers.livenessProbe. Параметр httpGet принимает путь, по которому отправляет HTTP GET запрос (в нашем примере это /, но в боевых сценариях может быть и нечто вроде /api/v1/status). Еще livenessProbe принимает параметр initialDelaySeconds, который предписывает операции проверки ждать заданное количество секунд. Задержка нужна, потому что контейнеру надо время для запуска, а при перезапуске он некоторое время будет недоступен.
Чтобы применить эту настройку к кластеру, используйте:
kubectl apply -f pod.yamlСпустя несколько секунд можно проверить содержимое pod'а с помощью следующей команды:
kubectl describe pods node500В конце вывода найдите вот что.
Как видите, livenessProbe инициировала HTTP GET запрос, контейнер выдал ошибку 500 (на что и был запрограммирован), kubelet его перезапустил.
Если вам интересно, как было запрограммировано NideJS приложение, вот файл app.js и Dockerfile, которые были использованы:
app.js
var http = require('http');
var server = http.createServer(function(req, res) {
res.writeHead(500, { "Content-type": "text/plain" });
res.end("We have run into an error\n");
});
server.listen(3000, function() {
console.log('Server is running at 3000')
})Dockerfile
FROM node
COPY app.js /
EXPOSE 3000
ENTRYPOINT [ "node","/app.js" ]Важно обратить внимание вот на что: livenessProbe перезапустит контейнер, только при отказе. Если перезапуск не исправит ошибку, мешающую работе контейнера, kubelet не сможет предпринять меры для устранения неисправности.
readinessProbe
readinessProbe работает аналогично livenessProbes (GET-запросы, ТСР связи и исполнение команд), за исключением действий по устранению неисправностей. Контейнер, в котором зафиксирован сбой, не перезапускается, а изолируется от входящего трафика. Представьте, один из контейнеров выполняет много вычислений или подвергается тяжелой нагрузке, из-за чего вырастает время ответа на запросы. В случае livenessProbe срабатывает проверка доступности ответа (через параметр проверки timeoutSeconds), после чего kubelet перезапускает контейнер. При запуске контейнер начинает выполнять ресурсоемкие задачи, и его снова перезапускают. Это может быть критично для приложений, которым важна скорость ответа. Например, машина прямо в пути ожидает ответа от сервера, ответ задерживается – и машина попадает в аварию.
Давайте напишем определение redinessProbe, которое установит время ответа на GET-запрос не более двух секунд, а приложение будет отвечать на GET-запрос через 5 секунд. Файл pod.yaml должен выглядеть следующим образом:
apiVersion: v1
kind: Pod
metadata:
name: nodedelayed
spec:
containers:
- image: afakharany/node_delayed
name: nodedelayed
ports:
- containerPort: 3000
protocol: TCP
readinessProbe:
httpGet:
path: /
port: 3000
timeoutSeconds: 2Развернем pod с kubectl:
kubectl apply -f pod.yamlВыждем пару секунд, а потом глянем, как сработала readinessProbe:
kubectl describe pods nodedelayedВ конце вывода можно увидеть, что часть событий аналогична вот этому.
Как видите, kubectl не стал перезапускать pod, когда время проверки превысило 2 секунды. Вместо этого он отменил запрос. Входящие связи перенаправляются на другие, рабочие pod'ы.
Заметьте: теперь, когда с pod'а снята лишняя нагрузка, kubectl снова направляет запросы ему: ответы на GET-запрос больше не задерживаются.
Для сравнения: ниже приведен измененный файл app.js:
var http = require('http');
var server = http.createServer(function(req, res) {
const sleep = (milliseconds) => {
return new Promise(resolve => setTimeout(resolve, milliseconds))
}
sleep(5000).then(() => {
res.writeHead(200, { "Content-type": "text/plain" });
res.end("Hello\n");
})
});
server.listen(3000, function() {
console.log('Server is running at 3000')
})TL;DR
До появления облачных приложений основным средством мониторинга и проверки состояния приложений были логи. Однако не было средств предпринимать какие-то меры по устранению неполадок. Логи и сегодня полезны, их надо собирать и отправлять в систему сборки логов для анализа аварийных ситуаций и принятия решений. [это все можно было делать и без облачных приложений с помощью monit, к примеру, но с k8s это стало гораздо проще :) – прим.ред. ]
Сегодня же исправления приходится вносить чуть ли не в режиме реального времени, поэтому приложения больше не должны быть черными ящиками. Нет, они должны показывать конечные точки, позволяющие системам мониторинга запрашивать и собирать ценные данные о состоянии процессов, чтобы в случае необходимости реагировать мгновенно. Это называется Шаблон проектирования проверки работоспособности, который следует Принципу высокой наблюдаемости (НОР).
Kubernetes по умолчанию предлагает 2 вида проверки работоспособности: readinessProbe и livenessProbe. Оба используют одинаковые типы проверок (HTTP GET запросы, ТСР-связи и исполнение команд). Отличаются они в том, какие решения принимают в ответ на неполадки в pod'ах. livenessProbe перезапускает контейнер в надежде, что ошибка больше не повторится, а readinessProbe изолирует pod от входящего трафика – до устранения причины неполадки.
Правильное проектирование приложения должно включать и тот, и другой вид проверки, и чтобы они собирали достаточно данных, особенно когда создана исключительная ситуация. Оно также должно показывать необходимые конечные точки API, передающие системе мониторинга (тому же Prometheus) важные метрики состояния работоспособности.



