Перевод статьи подготовлен для будущих учащихся на продвинутом курсе Machine Learning.
Обработка даже пары гигабайт данных на ноутбуке может стать сложной задачей, только если он не оснащен большим количеством оперативной памяти и не обладает хорошей вычислительной мощностью.
Несмотря на это, специалистам по анализу данных все еще приходится искать альтернативные решения для этой проблемы. Есть варианты настроить Pandas, чтобы обрабатывать огромные наборы данных, купить GPU или купить облачные вычислительные мощности. В этой статье мы рассмотрим, как использовать Dask для больших наборов данных на локальном компьютере.
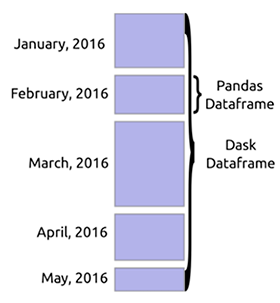
Dask – это гибкая библиотека для параллельных вычислений на Python. Она прекрасно взаимодействует с другими открытыми проектами, такими как NumPy, Pandas, и scikit-learn. В Dask есть структура массивов, которая эквивалентна массивам в NumPy, датафреймы в Dask аналогичны датафреймам в Pandas, а Dask-ML – это аналог scikit-learn.
Эти сходства позволяют с легкостью внедрить Dask в свою работу. Преимущество использования Dask заключается в том, что вы можете масштабировать вычисления до нескольких ядер на вашем компьютере. Так вы получаете возможность работать с большими объемами данных, которые не помещаются в память. Также вы можете ускорить вычисления, которые обычно занимают много места.
Источник
При загрузке большого объема данных, Dask обычно считывает сэмпл данных, чтобы распознать типы данных. Чаще всего это приводит к ошибкам, поскольку в одном столбце могут быть разные типы данных. Рекомендуется заранее объявлять типы, чтобы избежать ошибок. Dask может загружать огромные файлы, разрезая их на блоки, определенные параметром
Источник
Команды в Dask DataFrame схожи с командами Pandas. Например, получение
Функции в DataFrame выполняются лениво. То есть они не вычисляются до тех пор, пока не будет вызвана функция
Поскольку данные загружаются по частям, некоторые функции Pandas, такие как
Параллельные вычисления являются ключевыми в Dask, поскольку они позволяют считать на нескольких ядрах одновременно. Dask предоставляет
Использование
Использовать
Если вы не настроите
Dask также позволяет использовать параллельное обучение моделей и прогнозирование. Цель
Простая реализация будет выглядеть следующим образом.
Для начала импортируйте
Потом импортируйте модель, которую вы хотите использовать, и создайте ее экземпляр.
Затем нужно импортировать
Затем запустите обучение и прогнозирование с помощью parallel backend.
Отдельные задачи в Dask не могут выполняться параллельно. Воркеры – это процессы Python, которые наследуют преимущества и недостатки вычислений Python. Кроме того, при работе в распределенной среде следует соблюдать осторожность, чтобы обеспечить безопасность и конфиденциальность данных.
В Dask есть central scheduler, который отслеживает данные на узлах воркеров и в кластере. Также он управляет освобождением данных из кластера. Когда задача выполнится, он сразу удалит ее из памяти, чтобы освободить место для других задач. Но если что-то нужно определенному клиенту, или важно для текущих вычислений, оно будет храниться в памяти.
Другое ограничение Dask связано с тем, что он не реализует всех функций Pandas. Интерфейс Pandas очень большой, поэтому Dask не охватывает его полностью. То есть выполнение некоторых из этих операций в Dask может стать сложной задачей. Помимо этого, медленные операции из Pandas будут работать также медленно и в Dask.
В следующих ситуациях Dask может стать неподходящим вариантом для вас:
В этой статье мы познакомились с тем, как можно использовать Dask для распределенной работы с огромными наборами данных на локальном компьютере. Мы увидели, что можем использовать Dask, поскольку его синтаксис уже нам знаком. Также Dask может масштабироваться до тысяч ядер.
Также мы увидели, что можем использовать его в машинном обучении для прогнозирования и обучения. Если хотите узнать больше, ознакомьтесь с этими материалами в документации.

Обработка даже пары гигабайт данных на ноутбуке может стать сложной задачей, только если он не оснащен большим количеством оперативной памяти и не обладает хорошей вычислительной мощностью.
Несмотря на это, специалистам по анализу данных все еще приходится искать альтернативные решения для этой проблемы. Есть варианты настроить Pandas, чтобы обрабатывать огромные наборы данных, купить GPU или купить облачные вычислительные мощности. В этой статье мы рассмотрим, как использовать Dask для больших наборов данных на локальном компьютере.
Dask и Python
Dask – это гибкая библиотека для параллельных вычислений на Python. Она прекрасно взаимодействует с другими открытыми проектами, такими как NumPy, Pandas, и scikit-learn. В Dask есть структура массивов, которая эквивалентна массивам в NumPy, датафреймы в Dask аналогичны датафреймам в Pandas, а Dask-ML – это аналог scikit-learn.
Эти сходства позволяют с легкостью внедрить Dask в свою работу. Преимущество использования Dask заключается в том, что вы можете масштабировать вычисления до нескольких ядер на вашем компьютере. Так вы получаете возможность работать с большими объемами данных, которые не помещаются в память. Также вы можете ускорить вычисления, которые обычно занимают много места.
Источник
Dask DataFrame
При загрузке большого объема данных, Dask обычно считывает сэмпл данных, чтобы распознать типы данных. Чаще всего это приводит к ошибкам, поскольку в одном столбце могут быть разные типы данных. Рекомендуется заранее объявлять типы, чтобы избежать ошибок. Dask может загружать огромные файлы, разрезая их на блоки, определенные параметром
blocksize.data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )Источник
Команды в Dask DataFrame схожи с командами Pandas. Например, получение
head и tail датафрейма аналогично:df.head()
df.tail()Функции в DataFrame выполняются лениво. То есть они не вычисляются до тех пор, пока не будет вызвана функция
compute.df.isnull().sum().compute()Поскольку данные загружаются по частям, некоторые функции Pandas, такие как
sort_values() не смогут выполниться. Зато можно использовать функцию nlargest().Кластеры в Dask
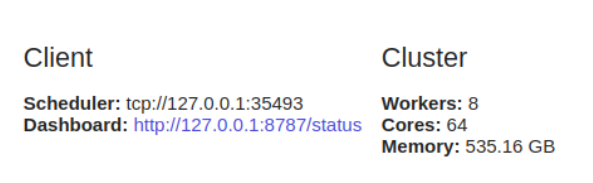
Параллельные вычисления являются ключевыми в Dask, поскольку они позволяют считать на нескольких ядрах одновременно. Dask предоставляет
machine scheduler, который работает на одной машине. Он не масштабируется. Также есть distributed scheduler, который позволяет масштабироваться на несколько машин.Использование
dask.distributed требует настройки клиента. Вы сделаете это первым делом, если соберетесь использовать dask.distributed в анализе. Он обеспечивает низкую задержку, локальность данных, обмен данными между воркерами, и его просто настраивать.from dask.distributed import Client
client = Client()Использовать
dask.distributed выгодно даже на одной машине, поскольку он предлагает функции диагностики через панель мониторинга.Если вы не настроите
Client, то по умолчанию будете использовать machine scheduler для одной машины. Он обеспечит параллелизм на одном компьютере с помощью процессов и потоков.Dask ML
Dask также позволяет использовать параллельное обучение моделей и прогнозирование. Цель
dask-ml – предложить масштабируемое машинное обучение. Когда вы объявляете n_jobs = -1 в scikit-learn, вы можете запустить вычисления параллельно. Dask использует эту возможность для того, чтобы вы могли делать вычисления в кластере. Сделать это можно с помощью пакета joblib, который позволяет использовать параллелизм и конвейеризацию в Python. С помощью Dask ML вы можете использовать модели scikit-learn и другие библиотеки, например, XGboost.Простая реализация будет выглядеть следующим образом.
Для начала импортируйте
train_test_split, чтобы разделить ваши данные на обучающие и тестовые наборы.from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Потом импортируйте модель, которую вы хотите использовать, и создайте ее экземпляр.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)Затем нужно импортировать
joblib, чтобы включить параллельные вычисления.import joblibЗатем запустите обучение и прогнозирование с помощью parallel backend.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)Ограничения и использование памяти
Отдельные задачи в Dask не могут выполняться параллельно. Воркеры – это процессы Python, которые наследуют преимущества и недостатки вычислений Python. Кроме того, при работе в распределенной среде следует соблюдать осторожность, чтобы обеспечить безопасность и конфиденциальность данных.
В Dask есть central scheduler, который отслеживает данные на узлах воркеров и в кластере. Также он управляет освобождением данных из кластера. Когда задача выполнится, он сразу удалит ее из памяти, чтобы освободить место для других задач. Но если что-то нужно определенному клиенту, или важно для текущих вычислений, оно будет храниться в памяти.
Другое ограничение Dask связано с тем, что он не реализует всех функций Pandas. Интерфейс Pandas очень большой, поэтому Dask не охватывает его полностью. То есть выполнение некоторых из этих операций в Dask может стать сложной задачей. Помимо этого, медленные операции из Pandas будут работать также медленно и в Dask.
В каких случаях вам не понадобится Dask DataFrame
В следующих ситуациях Dask может стать неподходящим вариантом для вас:
- Когда в Pandas есть функции, которые вам нужны, а в Dask они реализованы не были.
- Когда ваши данные идеально вписываются в память вашего компьютера.
- Когда ваши данные не представлены в табличной форме. В таком случае попробуйте dask.bag или disk.array.
Заключительные мысли
В этой статье мы познакомились с тем, как можно использовать Dask для распределенной работы с огромными наборами данных на локальном компьютере. Мы увидели, что можем использовать Dask, поскольку его синтаксис уже нам знаком. Также Dask может масштабироваться до тысяч ядер.
Также мы увидели, что можем использовать его в машинном обучении для прогнозирования и обучения. Если хотите узнать больше, ознакомьтесь с этими материалами в документации.
Читать ещё:
- Два мегатренда в области искусственного интеллекта, доминирующие в Gartner Hype Cycle 2020




