
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В IT здоровый проект — это система или сервис, который, с одной стороны, качественный, то есть соответствует требованиям и нравится пользователям. С другой стороны, приносит прибыль, потому что бизнес всегда на самом деле хочет зарабатывать деньги. Без связки качества и бизнеса ничего путного не выйдет.

Под катом Руслан Остропольский (RusOstropolsky) расскажет всё о метриках, которые являются индикаторами здоровья IT-систем. Разберет, какие бывают метрики, как они меняются по мере развития проекта, какие в каком проекте лучше применять. Объяснит, как качество и бизнес помогают друг другу с точки зрения метрик и зачем нужна эта коллаборация.
О спикере и компании: Руслан Остропольский в IT с 2010 года, главная сфера интересов — обеспечение качества. Последние 5 лет работает в компании DocDoc, которая разрабатывает медицинские интернет-сервисы. Основной продукт — это онлайн-запись к врачу, более 2 млн пациентов записались к врачу через DocDoc, также есть направление диагностики, телемедицины и ДМС-страхование.
Без обеспечения качества бизнесу будет трудно зарабатывать в долгосрочной перспективе. Нужна связка качества и бизнеса. Если её нет, то возможны следующие ситуации.
Во-первых, бывает качество ради качества: когда все известные виды тестирования применяются в одном маленьком стартапе. Сразу думать об автоматизации и тестировании под нагрузками можно, но если переборщить, то продукт может так и не дойти до продакшна. Поэтому нужно:
Во-вторых, бывает другой случай — бизнес без качества. В IT-компании может даже быть отдел тестирования, но если QA имеет слабый вес или существует в виде monkey testing, который просто подчищает регрессию и на этом останавливается, то качество это не особо повысит.
Как понять разрабатываете вы качественно или нет?

Для объективной оценки нужны метрики, которые бы показывали:
Выбирать метрики можно по трем принципам.
Там, где болит. Если случается какой-то инцидент, его нужно разобрать, обвесить метриками и посмотреть на боль: как проходит лечение, какая динамика, исправляются ли баги.

При целевом подходе мы заведомо ориентируемся на цели, например, ускорение и автоматизацию. Раньше у нас автоматическое тестирование занимало два часа. Мы поставили цель в 10 минут и по метрикам смотрели, приближаемся ли к этому значению.

Но невозможно получить здоровый проект, если метрики не имеют никакой связи с бизнесом, они только технические, а бизнес не получает результатов. И наоборот, если багов нет, а бизнес при этом теряет деньги, значит, происходит что-то странное.

При этом важно помнить, что бывает разный бизнес и разные стадии проекта. Стартапу, растущей компании или проекту в стадии расширения нужны разные метрики. Это как с болезнью — если вы просто кашляете, можно померить температуру, выпить аскорбинку, и всё пройдет. Если же у вас подозрение на пневмонию, нужно сделать снимки, пойти на обследование и лечиться по-другому.
Расскажу, какие метрики мы измеряли, когда были стартапом, а потом стали расти и расширяться.
На этом этапе продукт только зарождается, вы проверяете какую-то гипотезу, исследуете, нужно ли это людям.

На этапе стартапа для бизнеса важно, чтобы идеи доставлялись до пользователя как можно быстрее, и можно было их проверить. То есть нужно измерять time-to-market — скорость доставки идеи до пользователей (именно до продакшна, а не просто до релиза) и количество клиентов.
В части QA у нас было всего 3-5 метрик:
Ответ на вопрос, как собирать метрики, простой: есть руки и есть Excel. Примерно раз в месяц складывайте руками данные в таблицу, этого должно хватать.
На следующем этапе мы уже научились стоять на ногах, немножечко ходим.

Нужды бизнеса эволюционируют, становится важно измерять:
QA уже становится больше: 10-15 метрик. Если в стартапе мы создавали продукт по нашим ощущениям, например, основатель говорил: «Хочу синюю кнопку», и все делали ее, то теперь есть первая статистика. Можно пропускать фичи через A/B-тесты и не забывать измерять результаты.
Появляется автоматизация. Monkey testing уже недостаточно, и есть смысл вкладываться в расширение. На этом этапе появляется автоматическое тестирование, которое должно помочь сделать регрессионное тестирование быстрее. Соответственно, измеряется скорость тестирования релиза: насколько автоматизация оправдана. Печально, когда на автоматизацию ушло полгода, а релизы почему-то не ускорились.
Также измеряется объем релиза, чтобы видеть, если, например, разработчиков вместо 5 стало 15, но почему-то объем релиза не вырос.
Для сбора метрик на этапе роста кроме рук и Excel появляются специализированные системы. Системы — это любые инструменты, которые помогают создавать продукт. Если раньше те же тест-кейсы писались в Google docs, здесь появляются:
Система строит внутри себя еще дополнительные метрики и отчеты.
Растем дальше, «обрастаем жиром» — не влезаем в офисы, в которых сидели, и начинаем периодически переезжать.

Что важно для бизнеса?
В QA уже входит примерно 30-50 метрик. Мы измеряем:
Собираем данные как и раньше, но используемых систем становится больше.
Все гладко не бывает, и мы не исключение. Расскажу, с какими трудностями мы столкнулись, когда проект достаточно разросся.

Систем стало очень много, появилась необходимость ими как-то управлять. Смотреть в каждую систему — это, как минимум, много времени.
Выросло количество направлений, как продуктовых, так и технических. Причем каждое направление развивается по-разному, некоторые из них запускаются как стартап, и накладывать на них всю машину метрик и обеспечения качества будет неправильным.
Усложнились процессы: если раньше над проектом работало 5 человек, которым было нетрудно договориться и действовать соответственно, то теперь нужно следить за процессами. Например, новых людей нужно вводить постепенно, иначе им будет трудно разобраться в накопившемся числе систем.
Данные и отчеты уникальны в рамках сервиса. Это вытекает из того, что систем много, и нужно их все смотреть. Каждый сервис порождает свои отчеты, и нужно следить за ними всеми. Причем настроить их под себя становится тяжелее: нужно либо обращаться в техподдержку за новым отчетом, либо пытаться настроить его самостоятельно с помощью скриптов.
А если данных много, то Exсel уже не помогает. Особенно если десятки людей начинают работать над одним файлом, в котором все настроено на формулах — кто-то один что-то поменял, все сломалось — увидели через неделю.
Наверное, так в компаниях и появляются аналитики — специальные люди, которые собирают и поддерживают статистику и данные, потому что занимает слишком много времени, чтобы можно было совмещать.
И конечно, становится гораздо сложнее анализировать информацию из-за того, что опять же много систем, разных данных, которые хочется между собой связать.
Можно уехать на море, отдохнуть, вернуться и посмотреть на опыт других компаний.

Логичное решение — собрать всё вместе с точки зрения данных и преобразовать в метрики.
Мы сформулировали следующие критерии:
У нас множество дашбордов, только активных технических сейчас около 30, а общих около 100.
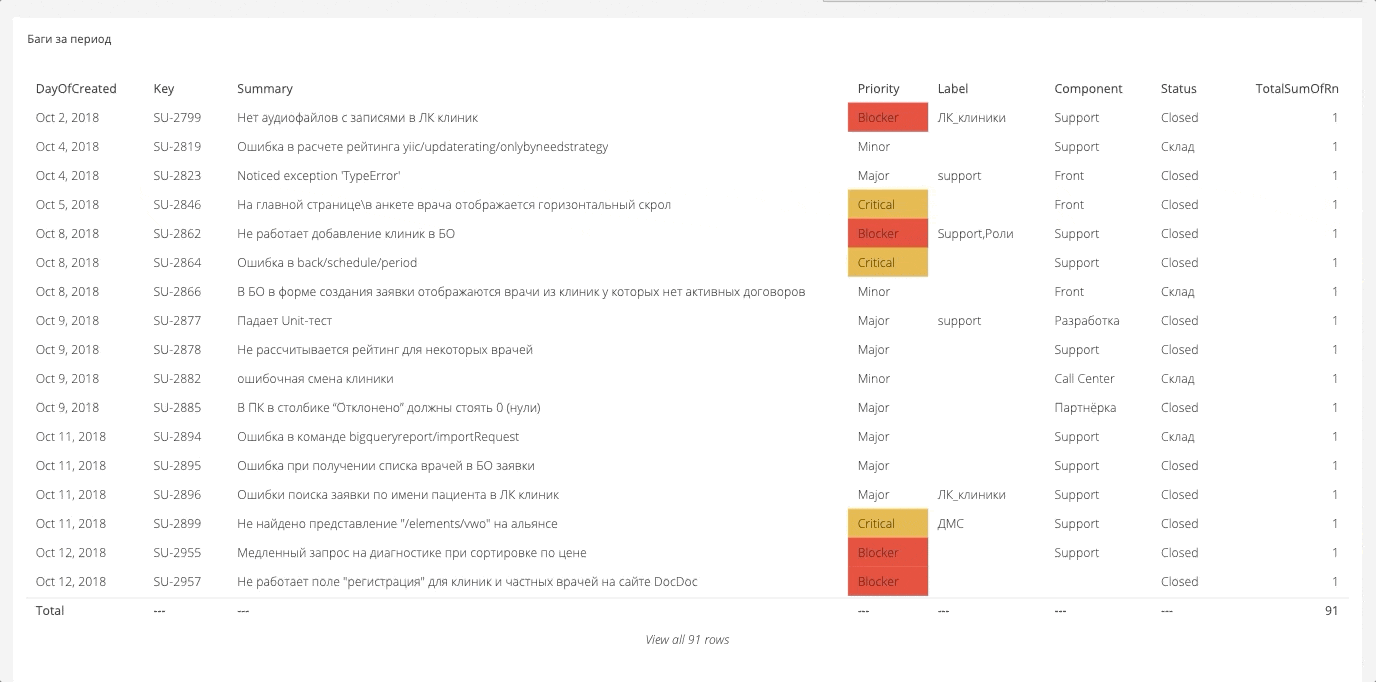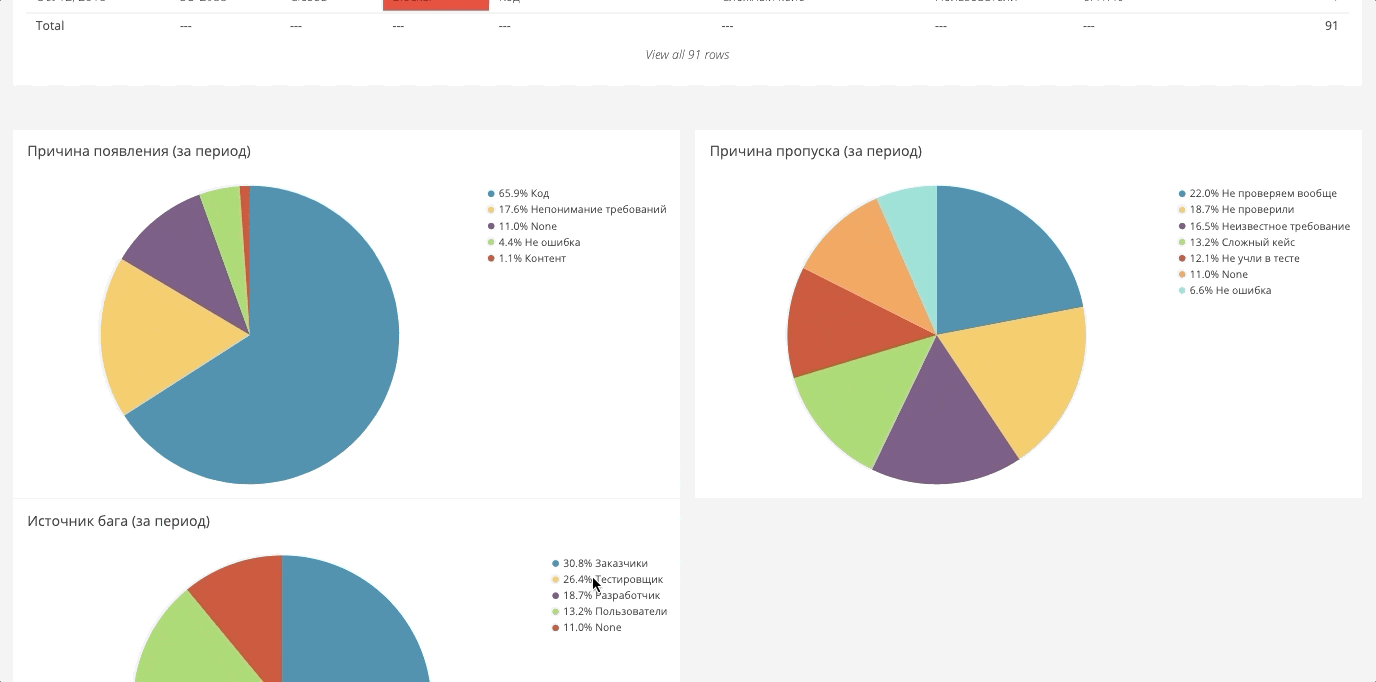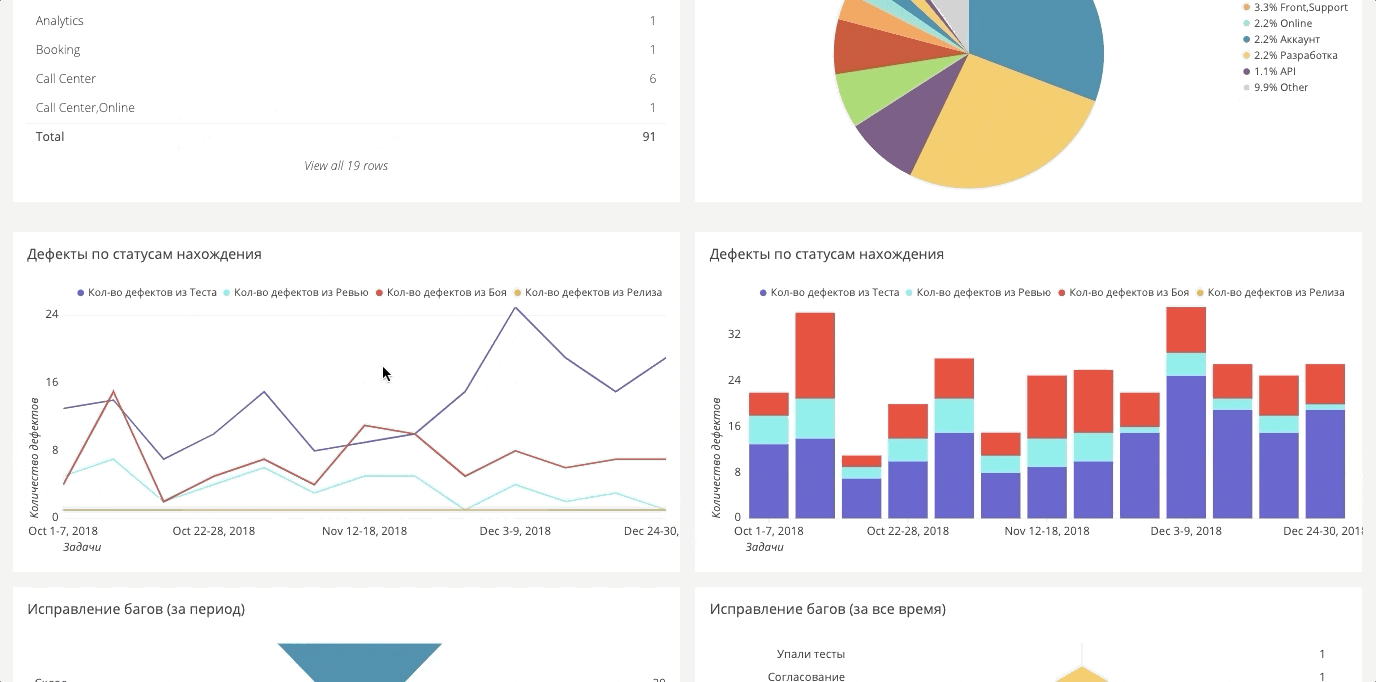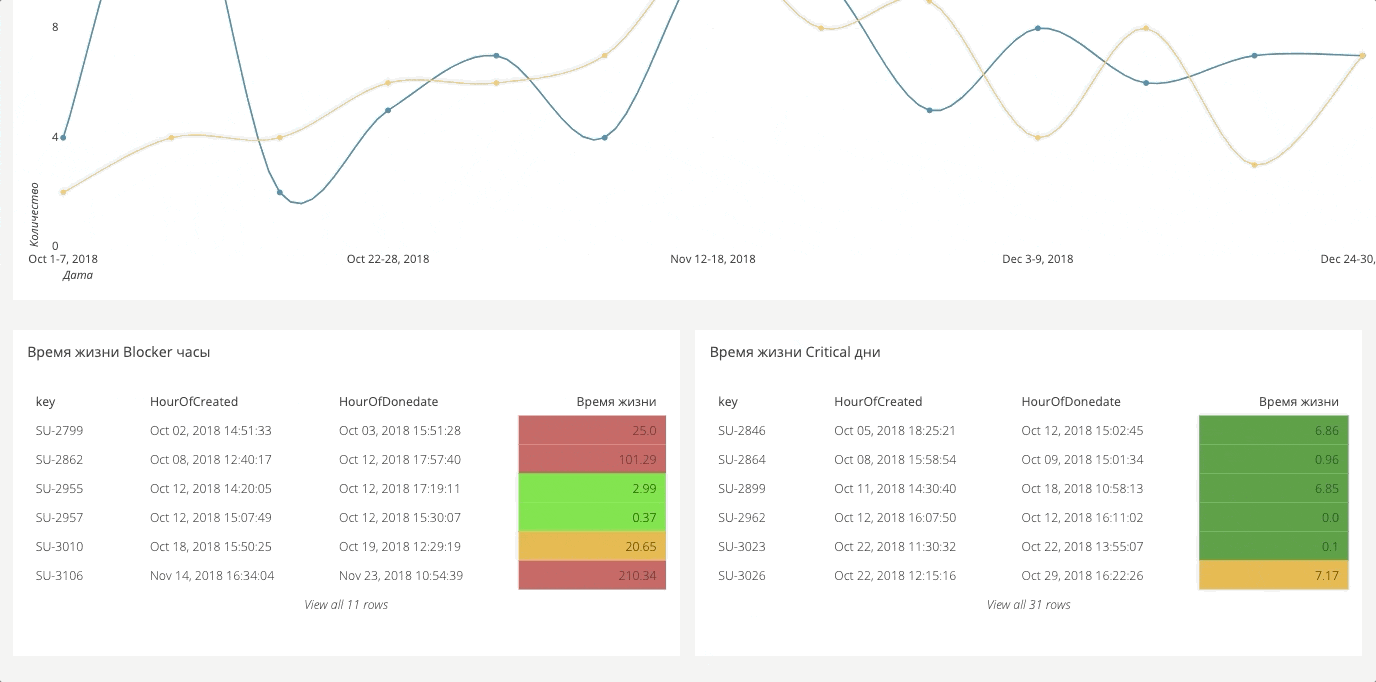
Данные для дашборда собираются вообще отовсюду. Получается большое полотно, из которого можно формировать нужные отчеты. Ниже несколько примеров.
Разбивка багов по критичности
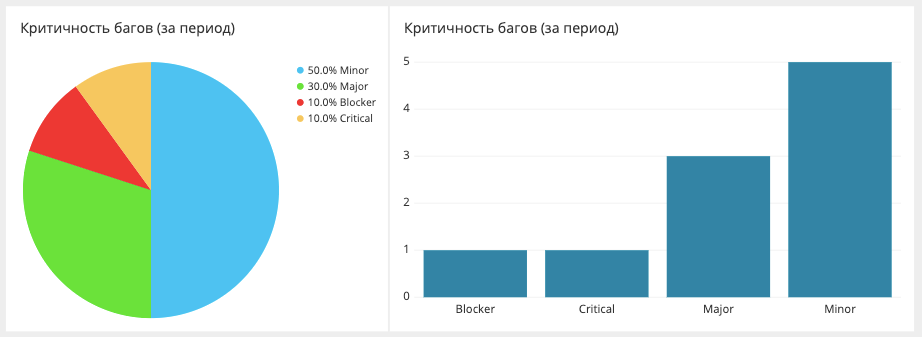
Здесь мы измеряем и отображаем число багов за определенный период и то, насколько они были критичными. Данные вытаскиваются из Jira. Сама Jira, наверное, может построить такой отчет, но не в очень удобной форме.
Разбивка багов по собственным полям
В Jira можно упаковывать любые кастомные поля, и эти поля могут являться аналитикой, которая также загружается в общую систему. Например, ниже баги по компонентам.
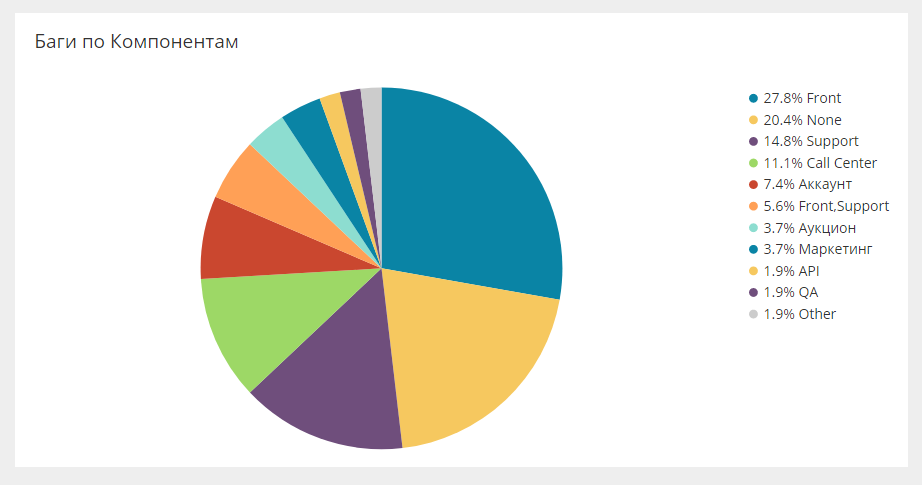
Есть такой же срез по командам, людям, направлениям. Это позволяет смотреть самые разные срезы.
Соотношение новых и закрытых багов
Если мы создаем 20 багов, а закрываем только 5, то в какой-то момент погрязнем в них. Поэтому нужно следить за цифрами и стремиться, чтобы соотношение было равно 1.

Тренд по багам за период
Чем удобна система, которую мы ввели, так это тем, что мы выгрузили все исторические данные и можем видеть динамику.

В Jira это сделать сложновато. У нас же все работает автоматически, причем можно выбирать любой период и смотреть, удалось ли что-то улучшить, и сработали ли введенные процессы и идеи.
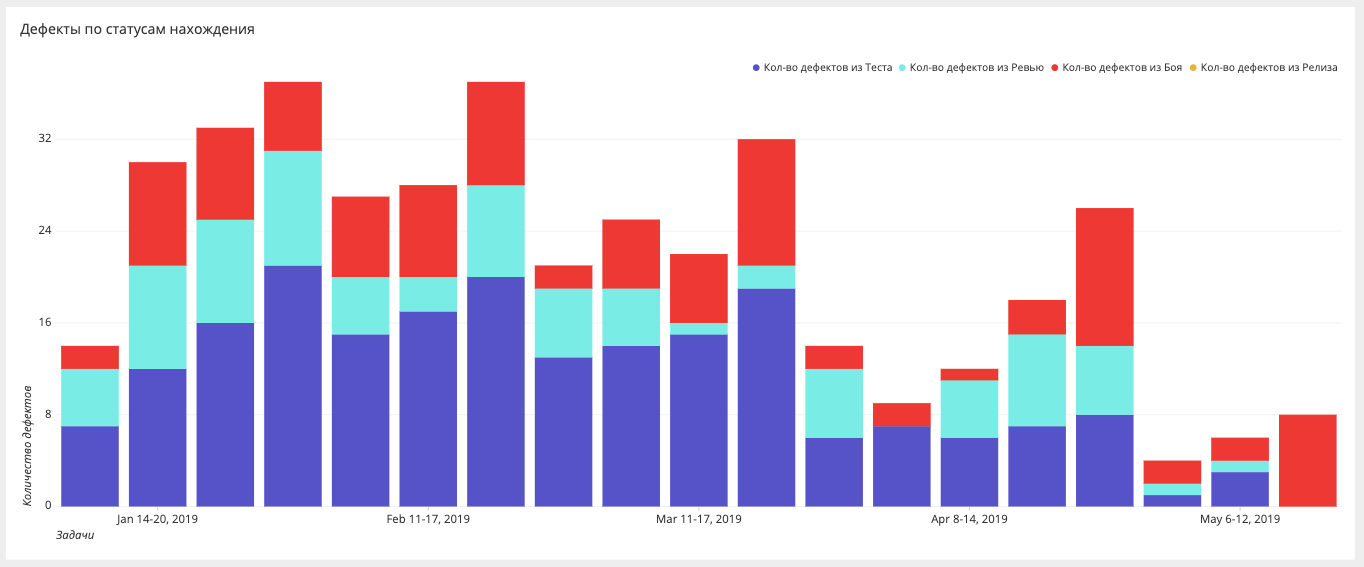
Этапы нахождения багов
Если раньше мы измеряли только баги в бою, то сейчас стремимся, чтобы багов в бою не было совсем, и строим срезы на разных этапах: бой, релиз, тестирование, автоматизация, ревью, требования.
Дашборд автоматизации
Для автоматического тестирования тоже есть свой дашборд. Он очень большой, поэтому ниже два отдельных фрагмента.

Здесь отражается количество пропущенных багов. Если у вас покрытие 90%, но на самом деле половина из багов просто закомментирована или пропущена, то это весьма критично, потому что в действительности верно работает только 50% функциональности.
То же самое по фейлам: сколько тестов падает. Мы обычно выделяем разные причины падений: системное падение, падение бага, изменилась функциональность. Отдельно разделяем падения, которые зависели от системы и от окружения, и которые были чисто по тестам. Первое — это работа команды эксплуатации, второе — автоматизации.
Также смотрим покрытие автоматизацией. Забираем из TestRial все сьюты, а еще можем погрузиться в блоки функциональности и определить, например, что поиск покрыт на 30%.

Кроме того здесь отражаются данные по срезу статусов:
На критичность тоже есть свой срез.
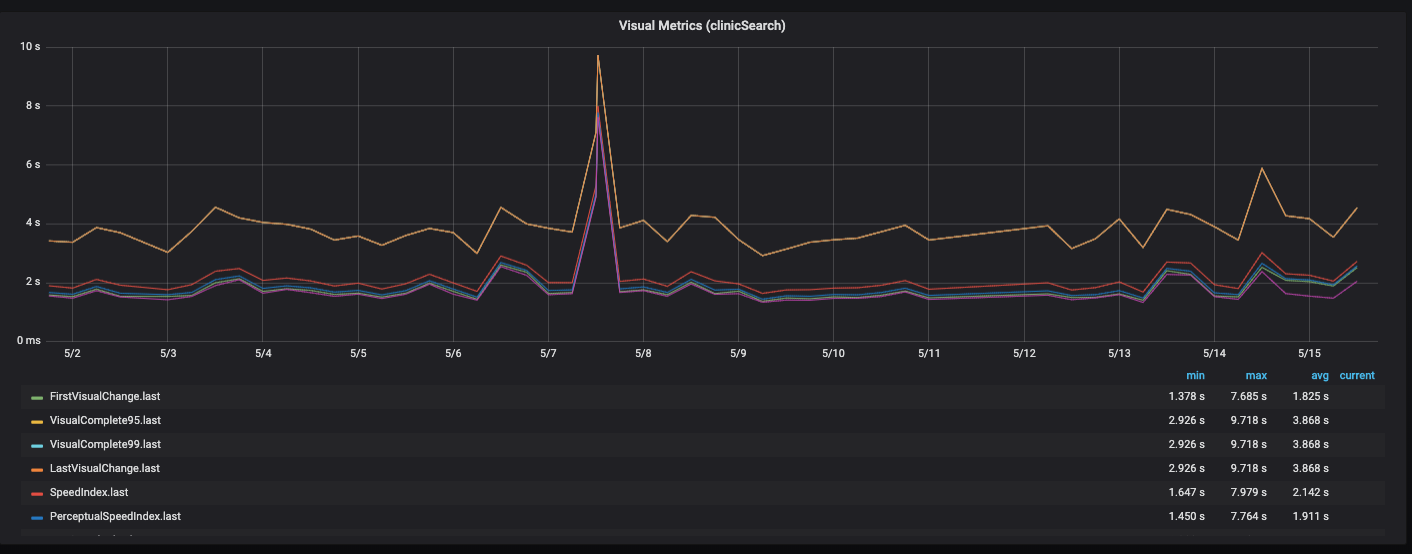
Дашборд Performance
Этот дашборд мы строим в Grafana, причем подгружаем метрики отдельно по API, фронтенду, бэкенду и серверной части. Есть блок, который показывает текущий срез последнего релиза. Соответственно, можно провалиться в каждую из метрик и посмотреть в динамике.

Это все накладывается на различную функциональность, разные страницы сайта.
Вроде бы, теперь все отлично: собирается само и в одном месте, метрик куча. Можно смело двигаться дальше.

Но по дороге встречаются новые проблемы. Графиков слишком много, и поэтому их реже смотрят. Когда графиков 5, их легко проверять каждый день. С увеличением их количества получается режим раз в неделю — тоже хорошо. А потом внезапно 3 дня назад случился факап, который никто не заметил. Отсюда же, реакция становится долгой, а метрики и дашборды успевают устареть. На это есть разные причины, с которыми тоже надо уметь бороться.
Нужно сделать агрегированные графики: из 10 делаем один, который будет показывать состояние этих 10. Причем основные показатели вытаскиваем наверх. Вы открываете дашборд и сразу видите нужные значения, а потом уже все остальное, подробнее раскрывающее метрики.
Мы разделяем: бизнес-метрики, метрики процессов, QA-метрики (Web / Mobile, Ручное / Автоматизация, Performance).
Так выглядит агрегированный график (NPS, CSAT).
Наверху значения и дельта по сравнению с предыдущим периодом. В данном случае, если стрелочка красная, то нужно что-то делать, как минимум подробнее смотреть графики. Если стрелочка зеленая — значит, все хорошо и можно не реагировать.
Также в графики встроена возможность провалиться на уровень ниже, никуда не переходя.

Баги связаны с людьми, их допустившими (тестировщиками или разработчиками). Если кликнуть отдельно на какого-нибудь тестировщика, по нему откроется отдельная таблица — срез по задачам.
Следующим действием решим проблему с тем, что графики редко контролируются. А именно, расширим схему работы с данными и с метриками: добавим оповещения на нужные метрики.
Мы используем достаточно много оповещений. Приведу примеры категорий и конкретных ситуаций:
На задачи, которые подгорают, бот пишет номер задачи, статус, приоритет, сколько времени задача уже тестируется и кто ее тестирует.

Оповещение, оформленное в виде сводки, приходит отдельному человеку, который смотрит, какие у него есть проблемы. Вот пример оповещений для ревью-кейса, которые присылает TestRial.

Здесь указано, какие кейсы на кого назначены, с каким статусом и кому надо посмотреть.
Еще один пример — бот Ябеда, который следит за процессами.

Это было нужно, чтобы настроить процесс связывания бага и задачи. Разработчик, разбирая баг, должен найти задачу, в которой мы этот баг пропустили, для последующей аналитики, чтобы знать, почему мы пропустили баг. Это своего рода разбор инцидента, но с запозданием.
Если оповещений будет очень много, то от них будет много стресса. Поэтому мы для себя вывели правила управления оповещениями.
Слишком много оповещений — перестаем реагировать. 500 оповещений в день вы совершенно точно перестанете успевать просматривать, а значит можете пропустить важное.
Слишком мало — не видим проблем. Если сообщений слишком мало, например, просто половину выкинуть, можно не увидеть какую-то проблему.
Нет проблем — сводка по фактам. В случае отсутствия проблем оповещения тоже нужно посылать, но в виде сводки: что произошло за день, что работало, какие были задачи, что случилось. Если не делать сводку, можно подумать, что просто все сломалось и надо искать, какие оповещения отвалились.
Обычно алертинг настраивается на пороговое значение метрики: если метрика перешла порог, прилетает оповещение. Но, как правило, в этот момент уже поздно что-то исправлять, системе уже плохо. Мы на этом обожглись, поэтому ввели метод светофора:
Кроме того, мы ввели уровни оповещений:
Метрики и дашборды устаревают по мере того как меняется продукт. Некоторые из них становятся неактуальными, и можно перестать их отслеживать. В то же время смещаются приоритеты. Например, в начале наш фокус был направлен на скорость автоматизации, и мы завели много соответствующих оповещений, то теперь нам важнее скорость сайта, и у нас появилось много новых алертов для этого. И, конечно, меняются цели: багов теперь практически нет, можно следить за ними менее пристально.

Чтобы следить за актуальностью метрик и дашбородов, полезно делать следующее:
Дать инструмент, научить им пользоваться, а дальше отпустить в самостоятельное плавание. Это даст несколько преимуществ. Во-первых, команда изнутри, скорее всего, видит больше, чем вы сверху, особенно если у вас 15 команд, и вы пытаетесь всеми ими управлять. Во-вторых, команда может определить метрики, которые для них важны. Не надо строить универсальную систему и предлагать всем командам работать именно так. В-третьих, люди должны уметь строить нужные дашборды. Система, которую вы делаете, не должна быть суперсложной, такой, в которой разбирается только один человек, и только он является носителем знания.
Для этой команды не важна скорость поставки релиза. Им важно количество интеграций с клинками и текущее состояние инфраструктуры, то есть сколько времени тратится на поддержку. Полезен срез по людям, кто как отрабатывает внутри команды. Соответственно, дашборд этой команды очень отличается от других команд.

Наконец, рассмотрим на кейсах связку QA и бизнеса.
Эксперты говорят: это эффект сезонности, просто люди сейчас не болеют, поэтому не звонят.
Проверяем: на определенном сегменте с определенным решением пользователь видит белый экран, который ни мониторинг, ни тесты не смогли поймать.
Но при этом есть график связки релиза и конверсии:

Здесь узлы — это релизы, по оси X конверсия в запись (фиолетовая линия), в заявку (синяя) и в открытие формы (зеленая). Когда мы видим, что график где-то проседает, обращаемся к релизу (на него можно кликнуть) и видим связанную задачу: когда она была, кто накатывал. Можно быстро перейти и посмотреть, что же накатилось. Как минимум, можно развернуть эту ветку задач на окружение определенным тестом и посмотреть, это реальная причина проблем или нет. Такие срезы есть по устройствам, окружениям и другим параметрам, которые только есть.
Эксперты говорят: любой баг в биллинге — это блокер, его надо исправлять, и багов очень много (раз человек сам их нашел, ему кажется, что много).
Проверяем: баги были по «спящим клиентам». Это те клиенты, которые или не платили деньги, или не собираются платить, или платили, но очень мало. Это явно не было каким-то блокером. Соответственно не все из этих багов напрямую влияли на деньги.
Позже мы сделали срез, что влияет на деньги, а что нет. Оказалось, что влиял только один баг, а десяток не влияли. Соответственно исправлять их в режиме блокера не было никакого смысла.
Эксперты говорят: доля онлайна растет, люди точно уже не звонят, а записываются через интернет. Плюс, молодое поколение не любит звонить в принципе.
Проверяем: был сбой у провайдера, который предоставляет нам телефонию, и после восстановления, часть телефонов не вернулась.
Это очень сложно заметить сходу, потому что у нас более 10 тысяч номеров, и если не вернулось 500, мы это вообще не увидим. Ночные тесты это поймают, но пройдут целые сутки.
Есть график по звонкам. Если видим падение, должен сработать алертинг, что звонков стало меньше обычного.

Суть этих примеров в том, что ответы не в ветвях, а у корней, поэтому нужно всегда проверять экспертов. Что бы ни казалось на интуитивном уровне, что бы эксперт не говорил, надо всегда докопаться до сути через метрики. Есть техника «5 почему», которая позволяет это сделать.
Если у вас есть технические метрики, подумайте, как их можно применить к вашему бизнесу, чтобы вы лучше чувствовали друг друга.
Здоровый проект — это не система и не робот, а живой организм. В нем много составляющих, которые помогают ему повышать качество и быть здоровым. Вы не можете сделать систему, которая будет решать всё за вас. Люди, процессы, системы, информация — это организм, который надо улучшать.

Нет универсального набора метрик:
На них и надо опираться. Все примеры метрик, которые я показал, могут сработать, но могут и не сработать. Смотрите всегда на ваш проект изнутри.
Метрики — это не решения. Это всего лишь показатели здоровья проекта, которые говорят о текущем состоянии и о его динамике. Оповещения как раз являются индикаторами, которые помогут не пропустить, если что-то случится.
Но в итоге принимают решения люди. Система за вас не скажет, что вам делать.
Что получилось у нас:
Под катом Руслан Остропольский (RusOstropolsky) расскажет всё о метриках, которые являются индикаторами здоровья IT-систем. Разберет, какие бывают метрики, как они меняются по мере развития проекта, какие в каком проекте лучше применять. Объяснит, как качество и бизнес помогают друг другу с точки зрения метрик и зачем нужна эта коллаборация.
О спикере и компании: Руслан Остропольский в IT с 2010 года, главная сфера интересов — обеспечение качества. Последние 5 лет работает в компании DocDoc, которая разрабатывает медицинские интернет-сервисы. Основной продукт — это онлайн-запись к врачу, более 2 млн пациентов записались к врачу через DocDoc, также есть направление диагностики, телемедицины и ДМС-страхование.
Когда качество и бизнес не дружат
Без обеспечения качества бизнесу будет трудно зарабатывать в долгосрочной перспективе. Нужна связка качества и бизнеса. Если её нет, то возможны следующие ситуации.
Во-первых, бывает качество ради качества: когда все известные виды тестирования применяются в одном маленьком стартапе. Сразу думать об автоматизации и тестировании под нагрузками можно, но если переборщить, то продукт может так и не дойти до продакшна. Поэтому нужно:
- Понимание бизнеса — что актуально в текущий момент: заработать денег, выйти на рынок или быстро масштабироваться. Задача бизнеса — передавать эти цели в техотдел.
- Качество в нужном месте и в нужном количестве. Иногда, можно выпускать релизы с багами, но понимать риски, и соответственно, учитывать это.
Во-вторых, бывает другой случай — бизнес без качества. В IT-компании может даже быть отдел тестирования, но если QA имеет слабый вес или существует в виде monkey testing, который просто подчищает регрессию и на этом останавливается, то качество это не особо повысит.
NB: QA на самом деле — это не тестирование, а общий подход на уровне компании к тому, как вы делаете хорошие продукты.
Как понять разрабатываете вы качественно или нет?
Для объективной оценки нужны метрики, которые бы показывали:
- Факт проблем. Что у вас в принципе есть проблемы, а если проблем нет, надо их поискать более тщательно. Скорее всего, они где-то есть, просто вы их еще не видите.
- Факт результатов. Проекты создаются, чтобы заработать денег, выйти на рынок, увеличить конверсию. Эти результаты нужно отслеживать.
- Текущее состояние. Где вы находитесь на пути к поставленным целям, сколько у вас в текущий момент багов, успеваете ли вы в спринт, с какой скоростью двигаетесь.
Как выбирать метрики
Выбирать метрики можно по трем принципам.
Там, где болит. Если случается какой-то инцидент, его нужно разобрать, обвесить метриками и посмотреть на боль: как проходит лечение, какая динамика, исправляются ли баги.
При целевом подходе мы заведомо ориентируемся на цели, например, ускорение и автоматизацию. Раньше у нас автоматическое тестирование занимало два часа. Мы поставили цель в 10 минут и по метрикам смотрели, приближаемся ли к этому значению.
Но невозможно получить здоровый проект, если метрики не имеют никакой связи с бизнесом, они только технические, а бизнес не получает результатов. И наоборот, если багов нет, а бизнес при этом теряет деньги, значит, происходит что-то странное.
При этом важно помнить, что бывает разный бизнес и разные стадии проекта. Стартапу, растущей компании или проекту в стадии расширения нужны разные метрики. Это как с болезнью — если вы просто кашляете, можно померить температуру, выпить аскорбинку, и всё пройдет. Если же у вас подозрение на пневмонию, нужно сделать снимки, пойти на обследование и лечиться по-другому.
Метрики на разных стадиях проекта
Расскажу, какие метрики мы измеряли, когда были стартапом, а потом стали расти и расширяться.
Стартап
На этом этапе продукт только зарождается, вы проверяете какую-то гипотезу, исследуете, нужно ли это людям.
На этапе стартапа для бизнеса важно, чтобы идеи доставлялись до пользователя как можно быстрее, и можно было их проверить. То есть нужно измерять time-to-market — скорость доставки идеи до пользователей (именно до продакшна, а не просто до релиза) и количество клиентов.
В части QA у нас было всего 3-5 метрик:
- количество багов с боя;
- количество багов, которые доходят до релиза;
- критичность багов.
Ответ на вопрос, как собирать метрики, простой: есть руки и есть Excel. Примерно раз в месяц складывайте руками данные в таблицу, этого должно хватать.
Растём
На следующем этапе мы уже научились стоять на ногах, немножечко ходим.
Нужды бизнеса эволюционируют, становится важно измерять:
- Трафик. Когда стало понятно, что продукт нужен пользователям, генерируется как можно больше трафика, например, появляются партнерские программы.
- Масштабирование — насколько возможно вырасти как со стороны продукта, так и со стороны разработки.
QA уже становится больше: 10-15 метрик. Если в стартапе мы создавали продукт по нашим ощущениям, например, основатель говорил: «Хочу синюю кнопку», и все делали ее, то теперь есть первая статистика. Можно пропускать фичи через A/B-тесты и не забывать измерять результаты.
Появляется автоматизация. Monkey testing уже недостаточно, и есть смысл вкладываться в расширение. На этом этапе появляется автоматическое тестирование, которое должно помочь сделать регрессионное тестирование быстрее. Соответственно, измеряется скорость тестирования релиза: насколько автоматизация оправдана. Печально, когда на автоматизацию ушло полгода, а релизы почему-то не ускорились.
Также измеряется объем релиза, чтобы видеть, если, например, разработчиков вместо 5 стало 15, но почему-то объем релиза не вырос.
Для сбора метрик на этапе роста кроме рук и Excel появляются специализированные системы. Системы — это любые инструменты, которые помогают создавать продукт. Если раньше те же тест-кейсы писались в Google docs, здесь появляются:
- менеджер-системы, например, TestRail;
- Google Analytics для сбора данных о пользователях;
- Report portal, Allure для автоматизации.
Система строит внутри себя еще дополнительные метрики и отчеты.
Обрастаем жиром
Растем дальше, «обрастаем жиром» — не влезаем в офисы, в которых сидели, и начинаем периодически переезжать.
Что важно для бизнеса?
- LTV. Нужно удерживать клиентов. Если раньше клиент записывался один раз и уходил, то сейчас, очевидно, что нужно его удерживать, строить пользовательский сервис.
- Бренд / Репутация. Если раньше люди обращаясь в DocDoc, могли думать, что это клиника, теперь они знают, что попали именно в сервис, который им помогает.
- SLA. Так как люди начинают пользоваться сервисом постоянно, доступность сервиса становится критичной, потому что любой простой напрямую влияет на деньги.
- Данные. Появляются первые данные, причем как продуктовые, так и технические и пользовательские, которые нужно уметь обрабатывать и хранить. Встает вопрос безопасности.
- Конверсия. На этапе масштабирования не создается принципиально новый продукт, а улучшается созданный.
В QA уже входит примерно 30-50 метрик. Мы измеряем:
- Нагрузку: бэкенд, серверную и фронтовую, причем в разных срезах.
- Безопасность.
- Скорость релизов.
- Скорость автоматизации.
- Стабильность автоматизации: скорость и стабильность автоматизации напрямую влияют на скорость релизов, потому что ручной регрессии на этой стадии развития проекта не место.
- Покрытие автоматизации.
Собираем данные как и раньше, но используемых систем становится больше.
Трудности
Все гладко не бывает, и мы не исключение. Расскажу, с какими трудностями мы столкнулись, когда проект достаточно разросся.
Систем стало очень много, появилась необходимость ими как-то управлять. Смотреть в каждую систему — это, как минимум, много времени.
Выросло количество направлений, как продуктовых, так и технических. Причем каждое направление развивается по-разному, некоторые из них запускаются как стартап, и накладывать на них всю машину метрик и обеспечения качества будет неправильным.
Усложнились процессы: если раньше над проектом работало 5 человек, которым было нетрудно договориться и действовать соответственно, то теперь нужно следить за процессами. Например, новых людей нужно вводить постепенно, иначе им будет трудно разобраться в накопившемся числе систем.
Данные и отчеты уникальны в рамках сервиса. Это вытекает из того, что систем много, и нужно их все смотреть. Каждый сервис порождает свои отчеты, и нужно следить за ними всеми. Причем настроить их под себя становится тяжелее: нужно либо обращаться в техподдержку за новым отчетом, либо пытаться настроить его самостоятельно с помощью скриптов.
А если данных много, то Exсel уже не помогает. Особенно если десятки людей начинают работать над одним файлом, в котором все настроено на формулах — кто-то один что-то поменял, все сломалось — увидели через неделю.
Наверное, так в компаниях и появляются аналитики — специальные люди, которые собирают и поддерживают статистику и данные, потому что занимает слишком много времени, чтобы можно было совмещать.
И конечно, становится гораздо сложнее анализировать информацию из-за того, что опять же много систем, разных данных, которые хочется между собой связать.
Лечим грусть
Можно уехать на море, отдохнуть, вернуться и посмотреть на опыт других компаний.
Логичное решение — собрать всё вместе с точки зрения данных и преобразовать в метрики.
Мы сформулировали следующие критерии:
- Собирать автоматически, чтобы руками никто ничего никуда не подгружал.
- Реализовывать различные представления данных.
- Должна быть связка систем: если половина данных берется из Jira, половина из TestRail, они должны попасть в одну копилку, из которой потом получится уникальный отчет.
- Все должно быть управляемым и легко поддерживаемым. Это значит, что люди сами могут на основе системы построить нужные отчеты, сами её поддерживать.
Дашборды
У нас множество дашбордов, только активных технических сейчас около 30, а общих около 100.
Данные для дашборда собираются вообще отовсюду. Получается большое полотно, из которого можно формировать нужные отчеты. Ниже несколько примеров.
Разбивка багов по критичности
Здесь мы измеряем и отображаем число багов за определенный период и то, насколько они были критичными. Данные вытаскиваются из Jira. Сама Jira, наверное, может построить такой отчет, но не в очень удобной форме.
Разбивка багов по собственным полям
В Jira можно упаковывать любые кастомные поля, и эти поля могут являться аналитикой, которая также загружается в общую систему. Например, ниже баги по компонентам.
Есть такой же срез по командам, людям, направлениям. Это позволяет смотреть самые разные срезы.
Соотношение новых и закрытых багов
Если мы создаем 20 багов, а закрываем только 5, то в какой-то момент погрязнем в них. Поэтому нужно следить за цифрами и стремиться, чтобы соотношение было равно 1.
Тренд по багам за период
Чем удобна система, которую мы ввели, так это тем, что мы выгрузили все исторические данные и можем видеть динамику.
В Jira это сделать сложновато. У нас же все работает автоматически, причем можно выбирать любой период и смотреть, удалось ли что-то улучшить, и сработали ли введенные процессы и идеи.
Этапы нахождения багов
Если раньше мы измеряли только баги в бою, то сейчас стремимся, чтобы багов в бою не было совсем, и строим срезы на разных этапах: бой, релиз, тестирование, автоматизация, ревью, требования.
Дашборд автоматизации
Для автоматического тестирования тоже есть свой дашборд. Он очень большой, поэтому ниже два отдельных фрагмента.
Здесь отражается количество пропущенных багов. Если у вас покрытие 90%, но на самом деле половина из багов просто закомментирована или пропущена, то это весьма критично, потому что в действительности верно работает только 50% функциональности.
То же самое по фейлам: сколько тестов падает. Мы обычно выделяем разные причины падений: системное падение, падение бага, изменилась функциональность. Отдельно разделяем падения, которые зависели от системы и от окружения, и которые были чисто по тестам. Первое — это работа команды эксплуатации, второе — автоматизации.
Также смотрим покрытие автоматизацией. Забираем из TestRial все сьюты, а еще можем погрузиться в блоки функциональности и определить, например, что поиск покрыт на 30%.
Кроме того здесь отражаются данные по срезу статусов:
- New — новая функциональность.
- Need correction — нужно апдейтить кейс.
- Not need — не хотим покрывать автоматизацией.
- Done — покрыто.
На критичность тоже есть свой срез.
Дашборд Performance
Этот дашборд мы строим в Grafana, причем подгружаем метрики отдельно по API, фронтенду, бэкенду и серверной части. Есть блок, который показывает текущий срез последнего релиза. Соответственно, можно провалиться в каждую из метрик и посмотреть в динамике.
Это все накладывается на различную функциональность, разные страницы сайта.
Летим дальше
Вроде бы, теперь все отлично: собирается само и в одном месте, метрик куча. Можно смело двигаться дальше.
Но по дороге встречаются новые проблемы. Графиков слишком много, и поэтому их реже смотрят. Когда графиков 5, их легко проверять каждый день. С увеличением их количества получается режим раз в неделю — тоже хорошо. А потом внезапно 3 дня назад случился факап, который никто не заметил. Отсюда же, реакция становится долгой, а метрики и дашборды успевают устареть. На это есть разные причины, с которыми тоже надо уметь бороться.
Нужно сделать агрегированные графики: из 10 делаем один, который будет показывать состояние этих 10. Причем основные показатели вытаскиваем наверх. Вы открываете дашборд и сразу видите нужные значения, а потом уже все остальное, подробнее раскрывающее метрики.
Мы разделяем: бизнес-метрики, метрики процессов, QA-метрики (Web / Mobile, Ручное / Автоматизация, Performance).
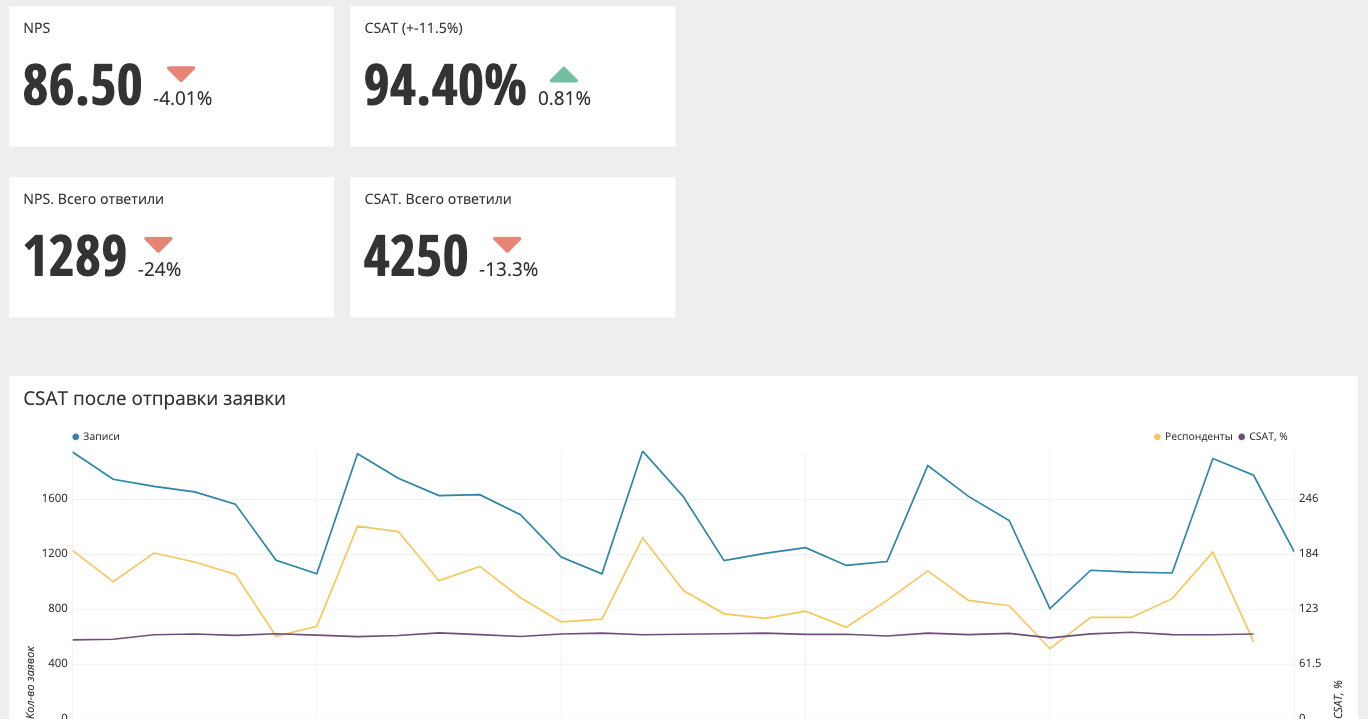
Так выглядит агрегированный график (NPS, CSAT).
Наверху значения и дельта по сравнению с предыдущим периодом. В данном случае, если стрелочка красная, то нужно что-то делать, как минимум подробнее смотреть графики. Если стрелочка зеленая — значит, все хорошо и можно не реагировать.
Также в графики встроена возможность провалиться на уровень ниже, никуда не переходя.
Баги связаны с людьми, их допустившими (тестировщиками или разработчиками). Если кликнуть отдельно на какого-нибудь тестировщика, по нему откроется отдельная таблица — срез по задачам.
Следующим действием решим проблему с тем, что графики редко контролируются. А именно, расширим схему работы с данными и с метриками: добавим оповещения на нужные метрики.
Оповещения
Мы используем достаточно много оповещений. Приведу примеры категорий и конкретных ситуаций:
- Performance.
- Автотесты. Например, если слишком повышается процент пропущенных багов или если слишком много новой функциональности не покрыто тестами.
- Входящие баги. У нас в компании любой человек может завести баг в тикет-системе. Раньше это сопровождалось сообщением в личку, а теперь есть канал оповещений о новых багах, мало того, баги автоматически назначаются на исполнителя по очереди. Назначенный человек должен разобрать баг, иначе бот будет каждые 15 минут ему напоминать.
- Скорость тестирования/ожидания тестирования. Если видно, что человек закопался в задачу — неважно, он ее кодировал, делал ревью, тестировал — должно прилететь оповещение: «Ты уже три занимаешься одной задачей, возможно, ты закопался, попроси помощи».
- Дефекты на задачу/команду.
- Ревью тест-кейсов. Это просто автоматизация процесса, чтобы не делать это руками.
Примеры оповещений
На задачи, которые подгорают, бот пишет номер задачи, статус, приоритет, сколько времени задача уже тестируется и кто ее тестирует.
Оповещение, оформленное в виде сводки, приходит отдельному человеку, который смотрит, какие у него есть проблемы. Вот пример оповещений для ревью-кейса, которые присылает TestRial.
Здесь указано, какие кейсы на кого назначены, с каким статусом и кому надо посмотреть.
Еще один пример — бот Ябеда, который следит за процессами.
Это было нужно, чтобы настроить процесс связывания бага и задачи. Разработчик, разбирая баг, должен найти задачу, в которой мы этот баг пропустили, для последующей аналитики, чтобы знать, почему мы пропустили баг. Это своего рода разбор инцидента, но с запозданием.
Сколько нужно оповещений и как часто?
Если оповещений будет очень много, то от них будет много стресса. Поэтому мы для себя вывели правила управления оповещениями.
Слишком много оповещений — перестаем реагировать. 500 оповещений в день вы совершенно точно перестанете успевать просматривать, а значит можете пропустить важное.
Слишком мало — не видим проблем. Если сообщений слишком мало, например, просто половину выкинуть, можно не увидеть какую-то проблему.
Нет проблем — сводка по фактам. В случае отсутствия проблем оповещения тоже нужно посылать, но в виде сводки: что произошло за день, что работало, какие были задачи, что случилось. Если не делать сводку, можно подумать, что просто все сломалось и надо искать, какие оповещения отвалились.
Обычно алертинг настраивается на пороговое значение метрики: если метрика перешла порог, прилетает оповещение. Но, как правило, в этот момент уже поздно что-то исправлять, системе уже плохо. Мы на этом обожглись, поэтому ввели метод светофора:
- Зеленый сигнал — релиз проходит, оповещение не нужно.
- Желтый сигнал — прилетит алерт, но смотреть его не нужно, если он разовый. Если повторяется, вы в жёлтой зоне и пора посмотреть, что же происходит. При этом релиз желтой зоны все равно проходит.
- Красный сигнал — все должно само останавливаться с обязательным разбором, почему так случилось, в том числе, почему дело дошло до красной зоны, и проблема не была выявлена раньше.
Кроме того, мы ввели уровни оповещений:
- Исполнитель — первый, кого будет бить бот, если задача горит.
- Команда / общий чат. Если исполнитель не реагирует, подключается команда или чат, в котором собраны люди по релизам или по перформансу.
- Лид. Если исполнитель или команда не реагируют, сообщение получит лид.
- Руководитель. Если и лид не среагировал, сообщение прилетит уже к руководителю. Плюс, обычно мы отправляем руководителю ставим сводку. Он не видит обычных оповещений, но получает результат, как идут дела.
Метрики и дашборды устаревают
Метрики и дашборды устаревают по мере того как меняется продукт. Некоторые из них становятся неактуальными, и можно перестать их отслеживать. В то же время смещаются приоритеты. Например, в начале наш фокус был направлен на скорость автоматизации, и мы завели много соответствующих оповещений, то теперь нам важнее скорость сайта, и у нас появилось много новых алертов для этого. И, конечно, меняются цели: багов теперь практически нет, можно следить за ними менее пристально.
Чтобы следить за актуальностью метрик и дашбородов, полезно делать следующее:
- Регулярное ревью и пересмотр метрик. Примерно раз в месяц я пробегаюсь по дашбордам, смотрю, какие метрики нужны, какие не нужны. Где все стало совсем хорошо можно отключить оповещения.
- Убираем ненужное. Например, на начальном этапе у нас была автоматизация, в которой мы замеряли, сколько сценариев покрыто тестами и общий процент покрытия. Но общий процент ничего не дает, когда у вас 10 разных продуктов — точно нужны срезы.
- Делегировать. Причем делегировать надо умно, через цели и инструменты.
Дать инструмент, научить им пользоваться, а дальше отпустить в самостоятельное плавание. Это даст несколько преимуществ. Во-первых, команда изнутри, скорее всего, видит больше, чем вы сверху, особенно если у вас 15 команд, и вы пытаетесь всеми ими управлять. Во-вторых, команда может определить метрики, которые для них важны. Не надо строить универсальную систему и предлагать всем командам работать именно так. В-третьих, люди должны уметь строить нужные дашборды. Система, которую вы делаете, не должна быть суперсложной, такой, в которой разбирается только один человек, и только он является носителем знания.
Пример метрик в команде Online
Для этой команды не важна скорость поставки релиза. Им важно количество интеграций с клинками и текущее состояние инфраструктуры, то есть сколько времени тратится на поддержку. Полезен срез по людям, кто как отрабатывает внутри команды. Соответственно, дашборд этой команды очень отличается от других команд.
QA и бизнес
Наконец, рассмотрим на кейсах связку QA и бизнеса.
Упала конверсия
Эксперты говорят: это эффект сезонности, просто люди сейчас не болеют, поэтому не звонят.
Проверяем: на определенном сегменте с определенным решением пользователь видит белый экран, который ни мониторинг, ни тесты не смогли поймать.
Но при этом есть график связки релиза и конверсии:
Здесь узлы — это релизы, по оси X конверсия в запись (фиолетовая линия), в заявку (синяя) и в открытие формы (зеленая). Когда мы видим, что график где-то проседает, обращаемся к релизу (на него можно кликнуть) и видим связанную задачу: когда она была, кто накатывал. Можно быстро перейти и посмотреть, что же накатилось. Как минимум, можно развернуть эту ветку задач на окружение определенным тестом и посмотреть, это реальная причина проблем или нет. Такие срезы есть по устройствам, окружениям и другим параметрам, которые только есть.
Много багов в биллинге
Эксперты говорят: любой баг в биллинге — это блокер, его надо исправлять, и багов очень много (раз человек сам их нашел, ему кажется, что много).
Проверяем: баги были по «спящим клиентам». Это те клиенты, которые или не платили деньги, или не собираются платить, или платили, но очень мало. Это явно не было каким-то блокером. Соответственно не все из этих багов напрямую влияли на деньги.
Позже мы сделали срез, что влияет на деньги, а что нет. Оказалось, что влиял только один баг, а десяток не влияли. Соответственно исправлять их в режиме блокера не было никакого смысла.
Падение количества звонков в колл-центре
Эксперты говорят: доля онлайна растет, люди точно уже не звонят, а записываются через интернет. Плюс, молодое поколение не любит звонить в принципе.
Проверяем: был сбой у провайдера, который предоставляет нам телефонию, и после восстановления, часть телефонов не вернулась.
Это очень сложно заметить сходу, потому что у нас более 10 тысяч номеров, и если не вернулось 500, мы это вообще не увидим. Ночные тесты это поймают, но пройдут целые сутки.
Есть график по звонкам. Если видим падение, должен сработать алертинг, что звонков стало меньше обычного.
Суть этих примеров в том, что ответы не в ветвях, а у корней, поэтому нужно всегда проверять экспертов. Что бы ни казалось на интуитивном уровне, что бы эксперт не говорил, надо всегда докопаться до сути через метрики. Есть техника «5 почему», которая позволяет это сделать.
Если у вас есть технические метрики, подумайте, как их можно применить к вашему бизнесу, чтобы вы лучше чувствовали друг друга.
Итоги
Здоровый проект — это не система и не робот, а живой организм. В нем много составляющих, которые помогают ему повышать качество и быть здоровым. Вы не можете сделать систему, которая будет решать всё за вас. Люди, процессы, системы, информация — это организм, который надо улучшать.
Нет универсального набора метрик:
- есть разные стадии проекта;
- есть разные цели, которые вы для себя ставите;
- есть разные проблемы, которые вы хотите решить.
На них и надо опираться. Все примеры метрик, которые я показал, могут сработать, но могут и не сработать. Смотрите всегда на ваш проект изнутри.
Метрики — это не решения. Это всего лишь показатели здоровья проекта, которые говорят о текущем состоянии и о его динамике. Оповещения как раз являются индикаторами, которые помогут не пропустить, если что-то случится.
Но в итоге принимают решения люди. Система за вас не скажет, что вам делать.
Что получилось у нас:
- ~ 50 метрик QA и более 100 остальных.
- ~ 30 активных дашбордов.
- Разные уровни погружения — можно быстро посмотреть, где проблема.
- Обязательные оповещения на метрики.
- Создание и поддержку мы отдали в сами команды.
- Связка QA и бизнеса must have.
Наша конференция, которая объединяет в себе все аспекты разработки качественных продуктов, в следующем году переродится, выпорхнет из-под крыла РИТ++ и станет самостоятельным масштабным мероприятием TechLead Conf. Дату и место скоро объявим в telegram-канале, но если вы на собственном опыте убедились, что процесс разработки – это не набор несвязанных между собой кирпичиков, и хотите поделиться решениями по выстраиванию инженерных процессов, подавайте заявку на доклад, не дожидаясь анонсов.



