
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Монолитная и микросервисная архитектуры — два диаметрально разных подхода. Во время круглого стола на конференции DevOps Live 2020 столкнулись адепты этих архитектур, которые в формате баттла искали ответы на самые актуальные вопросы. Избыточны ли ресурсы на каждый микросервис? Есть ли необходимость в постоянном рефакторинге? И как грамотно организовать рабочее место?

Адвокатом микросервисов выступил Алексей Шарапов, а обвинительную речь зачитал Андрей Булов. Оба сотрудники Deutsche Telekom IT Solutions — стратегического подразделения крупнейшей в Европе телекоммуникационной компании Deutsche Telekom — и не новички в обсуждаемом вопросе.
Андрей Булов: Я работаю в довольно крупном энтерпрайзе, в котором берут свое начало молодые стартапы. Побывал в разных ролях: архитектора, девелопера. С 2016 года начал писать на микросервисах.
С тех пор я невзлюбил паттерн «Microservice as a goal», которым грешат многие энтерпрайзы, и стал пропагандировать здравый смысл. Честно говоря, я считаю, что микросервис и текущая разработка — это что-то типа Spotify в Agile: все хотят внедрить, но не все понимают, зачем это нужно.
Тема этого мини-баттла родилась чуть ли не из кухонного спора. Я устал всем доказывать, что микросервис — это не Грааль, не панацея, и готов поделиться своим мнением.
А еще я люблю лямбды, и считаю, что микросервис — это некое переходное звено.
Алексей Шарапов: На данный момент я являюсь DevOps евангелистом. То есть хожу и очень громко всем говорю: «Давайте делать DevOps!». Я в разработке с 2010 года. Занимался разработкой фронтенда и немного бэкенда. С 2015 года влюбился в DevOps и DevOps-практики. Стараюсь заниматься ими ежедневно и приносить счастье нашим разработчикам.
Я работаю с Андреем в одной компании. Это крупный энтерпрайз. И у нас есть исключительно микросервисные проекты, которые я полюбил всем сердцем. Поэтому я выступлю адвокатом микросервисов.
Андрей Булов: Начнем с меня. Почему микросервисы — это плохо? Во-первых, потому что это очень дорого. Почему-то считается, что у всех, как у Google, есть куча намаринованных маленьких серверов, в которые можно засунуть маленькие сервисы, и все будет прекрасно работать.
На самом деле, вам придется купить облако и Кубер, и во всей этой виртуализации будет работать Docker, в котором зашиты ОС Java-машина, Application Server и микросервис, раздающий три строчки. А вы будете греть воздух всей этой чудесной инфраструктурой.
С точки зрения программной оптимизации, микросервис — это постоянная перегонка из строк в строки. Это съедает массу памяти, и возникает нагрузка и на сеть, и на программистов. Микросервисы дорого имплементировать, и не всегда понятно, зачем люди их выбирают.
Тот же монолит или мелкая галька прекрасно выполняются на Bare Metal, не требуют особых ресурсов, Application Server JVM. И внутри себя они общаются по бинарным внутренним протоколам, байтики бегают по серверу: все прекрасно и довольно быстро работает.
Да, можно писать не на JVM, но все равно выходит недешево. Микросервисы обходятся дорого с точки зрения перформанса, скорости разработки и работы внутри.
Алексей Шарапов: На все это могу ответить, как человек, занимающийся инфраструктурой в крупных компаниях последние несколько лет, что мы можем делать очень много классных вещей. В первую очередь, ограничивать минимум. Если на наш сервис нет нагрузки в спокойном состоянии, можем сделать ему минимальные ресурсы. Мы должны содержать Kubernetes-кластер, какие-то дополнительные сущности, но запуском внутренних компонентов можем управлять очень-очень тонко. И если в какой-то момент нам на определенное время нужны сущности, мы можем использовать CronJob. А еще Openfaas, о чем часто забывают. Мы не греем наш кластер ненужными сущностями, а запускаем только то, что необходимо.
Хорошо, когда инженер по инфраструктуре сотрудничает с разработчиками каждый день, подключается к ним ближе и может дать полезные советы, как вынести часть какого-то функционала дополнительно.
Например, можно использовать те же самые AWS лямбды и запускать в них какой-то код — да, может быть, это будет не в кластере, а отдельно. Кроме того, не стоит забывать, что у нас есть Kubernetes-кластер. Мы можем не иметь его у себя, а запускать где-то на стороне. Такую возможность предоставляет облачный провайдер.
Не стоит забывать и о том, что когда мы запускаем на Bare Metal, нужно какое-то общее окружение, с которым мы работаем. Если все это учесть, получается даже чуть больше, чем в кластере Kubernetes.
Андрей Булов: Микросервисы — это штука, которая требует некоей Java-команды и постепенного обучения. То есть вы девелопите какой-то микросервис, и в нем может постепенно меняться его бизнес-контекст. Многие забывают, что помимо обычного советского рефакторинга, который нужно делать практически каждый день, микросервисы еще требуют бизнес-рефакторинга. Если в монолите вы можете просто порефачить модули и сделать git push force, как тимлид или девелопер, то в микросервисах вам придется договориться с другими командами, с другими людьми и, например, перенести функционал из одного микросервиса в другой.
Мой личный опыт: когда разрастается какой-нибудь важный микросервис типа Order-микросервиса, или Booking-микросервиса, который выполнял 90% функционала приложения, по-моему, немного теряется смысл. Нам требовался временный рефакторинг в заказной разработке или в бизнесе. Довольно трудно продать людям, которые заведуют деньгами, что нам нужно еще пару спринтов, чтобы перекроить бизнес boundaries наших микросервисов. Потому что с первого раза (и со второго, и с третьего) мы не смогли понять этот контекст, зато теперь научились.
Я это лично продавал продуктоунерам. Это занимательно. Если уж вы отважились на микросервисы, всегда помните о том, что рефакторинг не закончится никогда. Он как ремонт, и вам нужно будет всегда со всеми договариваться. Закладывайте хотя бы процентов 20 времени исключительно на это.
Алексей Шарапов: С мыслями о рефакторинге я не согласен. Если API меняется от версии к версии, возможно, это включает в себя несколько проблем, которые больше на совести девелопера, разрабатывающего эту часть. Либо нужно запланировать, что не стоит вводить постоянные изменения, включая новый функционал микросервисов.
С другой стороны, если это все сложно переписать, может быть это уже и не микросервис вовсе? И огромный микросервис, который выполняет большое количество бизнес-логики, превращается в мини-монолит. Да, это сервис, но не микросервис. В моем идеальном восприятии — и я стараюсь работать именно так — микросервис должен держать минимальную бизнес-логику. Он — небольшая сущность, которую Java-команда может написать и переписать за спринт. И это не должно задеть какой-то другой функционал. Именно тогда речь идет о микросервисе.
Если же мы от этого уходим, ломается идеология. А если нам хочется сломать идеологию, то зачем мы вообще в это все ввязались, и как планируем работать дальше?
Как всегда, когда собрались архитекторы, происходит рефакторинг ради рефакторинга. Но нужен ли он здесь на самом деле, или хочется впихнуть то, что в формат микросервиса впихивать не нужно? В монолите мы привыкли к тому, что можно что-то переписать, поменять модуль, и все классно! Но чтобы отрефакторить монолит, которому 20 лет (а я с таким сталкивался в реальном мире, это не сказки), только для того, чтобы разобраться, как это сделать, нужно полгода. И это без учета времени на необходимые изменения.
Андрей Булов: Микросервисы — copy & paste driven development. Согласно идеологии микросервисов, в них не должно быть общих зависимостей, кроме какого-нибудь спринга, или общих либ. Но почему-то все забывают о том, что когда микросервисы пишутся для энтерпрайза, пусть и не очень кровавого, у него есть enterprise-specific вещи. А есть еще базовые, типа общей аутентификации, общего логирования, общих доменных объектов.
В зависимости от упорства адептов микросервиса, мы будем либо копипастить весь этот код между нашими микросервисами, либо сделаем библиотеку, либо вынесем это в отдельный микросервис.
Я прекрасно помню кейс, когда мы деплоимся на какой-то init или prod, у нас собираются нормально десять микросервисов, а одиннадцатый — бабах! — падает. Мы забыли туда скопипастить наш общий user-объект, в котором есть пермиссии. И с матами, конечно, все это дело правим.
Поэтому от идеологии всегда приходится отступать, и делать либы. Но тогда это уже перестает быть микросервисом.
Очень трудно определить бизнес-контекст такого микросервиса. Например, аутентификация — это бизнес или не бизнес? А общие объекты, которые валидны для всего приложения, или для всего энтерпрайз-ландшафта? И начинаются всякие интересные спекуляции.
За это я микросервисы не очень люблю.
Алексей Шарапов: В этом моменте я с тобой согласен, но не во всем. Мне нравится подход, когда библиотека выносится отдельно, и все ее куски делаются при помощи CTRL-C — CTRL-V. С июля мы начали новый проект, в котором изначально используется микросервисный подход. И я слышал что-то подобное от наших архитекторов: либо мы копируем, либо выносим в библиотеки.
Но подключать библиотеку стоит, наверное, на стадии сборки самого микросервиса. А мы сейчас говорим про наш энтерпрайз Agile, и в этом нет ничего страшного. Это просто зависимость, которая будет выполнять близкий функционал. Либо — к чему мы пришли только спустя четыре месяца работы — стоит выносить этот функционал в отдельный микросервис.
Ты говорил о том, что такая мысль у тебя возникала, но почему-то вы решили этого не делать. Наверное, об этом стоит поговорить побольше. Мне это видится либо разницей во взглядах, либо потенциальным опытом. Пока я еще не видел каких-то проблем с тем, чтобы вынести что-то в отдельные микросервисы и жить спокойно.
Ты сам это проговорил, но неизвестно почему не захотел к этому прийти, несмотря на то, что понимаешь необходимость такого шага.
Андрей Булов: Собственно, именно поэтому: в микросервисах нет единого хорошего стандарта, а есть набор практик и адепты, каждый из которых агитирует за свое. Если микросервис разрабатывает программист или команда программистов, вы получите свой уникальный стиль микросервиса с такими вещами, как POST vs PUT (холивар на кухне), и рассуждениями о том, какие ошибки мы возвращаем при валидации, какое возвращаем время и в каком стиле мы возвращаем API.
Это требует либо постоянного ревью: чтобы пришел архитектор или лид-девелопер и вставил руки в нужное место, либо нужен общий гайдлайн на проект. Но опять же, общих best practices для микросервисов, к сожалению, нет. Адепты спорят друг с другом. И ты думаешь: «Хм, разработчик Василий так любит двухсотый код возвращать, надо учесть эту специфику. А этот, наверное, 404 бросит. Ведь тут не сервер упал, просто у него код ошибки такой». Либо требуется централизованное управление, и тогда теряется весь смысл микросервисов. У тебя получается команда с многими модулями, которые просто деплоятся отдельно, и архитектор ходит и пишет для них гайдлайны.
Где эта хваленая независимость, когда команда может переписать микросервис за спринт? Необходимо много документации по описанию джейсонов, свайгеров и прочего, и много-много ревью. В монолите все это делать, наверное, проще.
Алексей Шарапов: А как вообще жить без документации? Я бы начал с этого, потому что я себе такого не представляю. Да, мысль, может быть, чуть-чуть испорчена энтерпрайз-сложным миром, большим и тяжелым. Но даже несмотря на микросервисную инфраструктуру и архитектуру, мне нравится документация. Под ней можно понимать не подробный талмуд о том, как мы должны написать микросервис, а описание общих частей.
Сейчас мы что-то подобное подготавливаем для наших команд. И я не вижу в этом ничего плохого. Там просто написано о том, что нужно использовать классические коды ошибок, как это описано в интернете.
По поводу всего остального. Во-первых, инфраструктура as a code становится проще. То есть деплой становится everything as a code, а все части деплоя, инфраструктуры и самого кода вы можете посмотреть в Гите. Разработчику проще, когда он деплоит какое-то количество микросервисов, и отлавливает эти ошибки быстрее. Ему не нужно лезть в тяжелый монолит, рассматривать его и пытаться понять, что происходит. Он понимает, что происходит от написания первой строчки до попадания на ProdStage, и на каждой отдельной части.
Плюс выпуск происходит намного быстрее, и ему легче свериться с документацией. Ему не нужно разбираться с внутренними взаимодействиями, с тем, как работает система. Он написал свою часть. Видит, с чем это все вместе работает, и может выпускать этот кусочек. С Андреем я согласен в одном: в команде должны быть люди, которые понимают, что они делают. Даже несмотря на кровавый энтерпрайз, они должны понять, что они создают микросервис по определенным законам. И все будет круто до тех пор, пока люди соблюдают установленные правила, хотя бы из взаимоуважения.
Андрей Булов: Да, давайте наймем команду космонавтов, которая нам все хорошо сделает.
О, мое любимое.
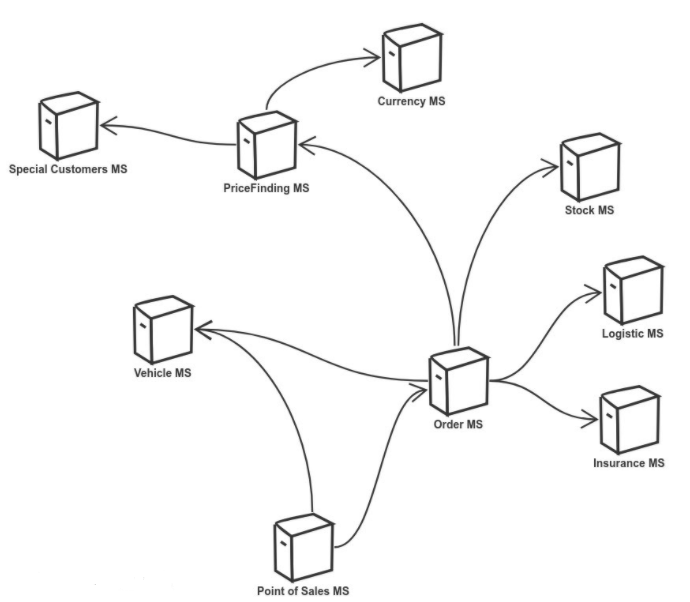
На самом деле картинка — это практически реальный ландшафт системы и реальный кейс. Прибегает ко мне заказчик, говорит: «Слушай, там бага. Из Гуя на проде неправильно заказ считается для такой-то модели машинки для немецкого рынка. Для остальных все хорошо работает. Вот тебе логи, прод не трогай. На деве это воспроизводится. И вот тебе данные».
На деве все хорошо. Значит, мне нужно поднять у себя Docker, кучу микросервисов с базой, учесть взаимодействие этого всего. А потом сидеть, как обезьянка, переключаться между PyCharm и смотреть, куда приведет тот или иной breakpoint. Потому что проблема очень скользкая, и просто логами ее вычислить невозможно.
С точки зрения вычислительных мощностей, поднять у себя такое количество докеров, конечно, можно, но тогда тормозить будет зверски. Если мы подключаемся к какому-нибудь Куберу и удаленно пробрасываем порты, конечно, оно может сработать. Но тогда получается, что один девелопер блокирует все девовское окружение, а другие сидят, курят бамбук или девелопят локально. Либо нам нужно много-много окружения, иначе необходимо много-много серверов. Что возвращает нас к первому вопросу: все это совсем не дешево.
А в-третьих, чтобы банально сграбить данные со всех этих микросервисов, из БД, мне нужно залезть в каждый, вытащить какие-то данные и посмотреть, совпадают ли они. Потому что у нас констрейнтов нет. А потом нужно это все себе залить, или залить на дев, поднять и посмотреть, чтобы заработало. Да, чтобы еще у меня port forward не умер в самый интересный момент, потому что процесс растянут во времени.
Поэтому дебажить микросервисы я «люблю» очень сильно!
Алексей Шарапов: Андрей прямо по больному прошелся. Конечно, дебажить микросервисы довольно-таки сложно. Но, на самом деле, команда должна просто привыкнуть к освоению новых инструментов.
В мыслях о port forwarding я с Андреем абсолютно не согласен. Если приходится пробрасывать огромное количество каких-то сущностей в единицу времени, наверное, мы опять говорим о том, что у нас слишком большое количество взаимодействий. Нужно вообще прекратить это дебажить, поднимая какие-то локальные контейнеры. Либо, необходимо иметь достаточное количество неймспейсов. Понимайте изначально, во что вы вписываетесь. Да, это может быть дорого. Вы можете поднять какой-нибудь свой minikube.
Кстати, мы жили с проектом для тестирования на minikube, и никто ни разу не пожаловался, что нам не хватает ресурсов. Есть какие-то локальные машинки, где-то можно что-то подешевле запустить — с этим проблем быть не должно. Не нужно запускать столько сервисов, чтобы проверить это между собой в тесте.
Кроме того, можно прекратить создавать костыли, и позвать человека. Можно окружить все трассировкой, например использовать Jaeger, посмотреть, собирать логи с каждого момента. Логов не хватает: значит нужно посмотреть, как микросервисы взаимодействуют между собой. При нормальной трассировке можно обнаружить, где происходят падения. Придется поднять буквально несколько сервисов. И это займет не так много времени и ресурсов. И жизнь твоя улучшится.
К этому просто надо привыкнуть. Очень сложно осознать, что все поменялось — извините, теперь будет так. Но когда привыкнешь, станет легче.
Андрей Булов: Видимо, я морально устарел в микросервисах.
Есть еще вот такой интересненький кейс:

У нас есть микросервис со своими бизнес-контекстами, сервис, который делает Order, сервис, хранящий в себе Vehicle. Есть API GW, есть GUI. К нам приходит продактоунер и говорит: «Эй, ребята, мы принимаем заказы на машины, и теперь занимаемся отделкой салона».
И начинается парад независимости. Это когда команды внедряют у себя один параметр и проносят его через все независимо друг от друга.
А потом начинается игра: давайте все это дело проинтегрируем! Мы возвращаемся к предыдущему слайду: как это дебажить?
Очень тяжело и с первого, и с десятого раза определить реальный бизнес-контекст микросервиса и приложения. И во всяких крупных энтерпрайзах часто получается, что flow идет как бы через все микросервисы. Все они, вроде бы, независимые, но друг без друга не могут, и все должно работать вместе.
Это абсолютно реальный пример: нам никуда не деться от того, что придется пронести бедный параметр Vehicle Cover через все микросервисы и базы. Давайте это сделаем и помолимся, чтобы все программисты микросервисов назвали это правильно, соблюли чудесный capital letter, сделали везде одинаковый тип, воркчар был правильным, все это прошло ревью архитектора и т.д.
В монолите это сделать довольно легко: открываем идею, смотрим, даем кому надо по рукам — профит! В микросервисах придется побегать между командами.
Алексей Шарапов: Я согласен с тем, что это будет боль. Но самое главное — не создавать SOA в этом случае. Это же не микросервис: протаскиваешь через распределенные данные монолита из кусков какое-то значение, которое ты должен везде обработать. Почему твое значение не может быть отдельным микросервисом, из которого все берут данные? Или который это обрабатывает отдельно от всех, чтобы не нарушать состояние остального. Если такие требования появились, как их вписать со стороны идеологии? А если это вам не подходит, зачем вы вообще начали делать микросервисы?
По поводу зависимостей. Хочу вернуться к прошлому вопросу про копипаст, где нужно вставлять и описывать одну часть. Ты говоришь: не факт, что они правильно дадут название во всех своих сервисах. Именно для этого и нужна если не документация, то хотя бы минимальное описание, как с этим работать. Нужно просто предложить определенный алгоритм с этого дня: есть такие-то требования и проект может быть такого-то характера. А еще существует вероятность того, что этот проект изначально не был подготовлен для микросервисов.
Я такое видел: берут какой-то проект, для которого не нужны микросервисы. Но нет, мы просто обязаны сделать классно и красиво, ведь решение о необходимости микросервисов спустили сверху. Но ведь главное — не применять технологии там, где они не нужны. Плохо делать что-то просто потому, что так захотелось.
Больше по этому поводу мне нечего сказать. Наверное, это вопрос ко все участникам разработки.
Андрей Булов: О, я тебя заразил здравым смыслом!
Тестирование.
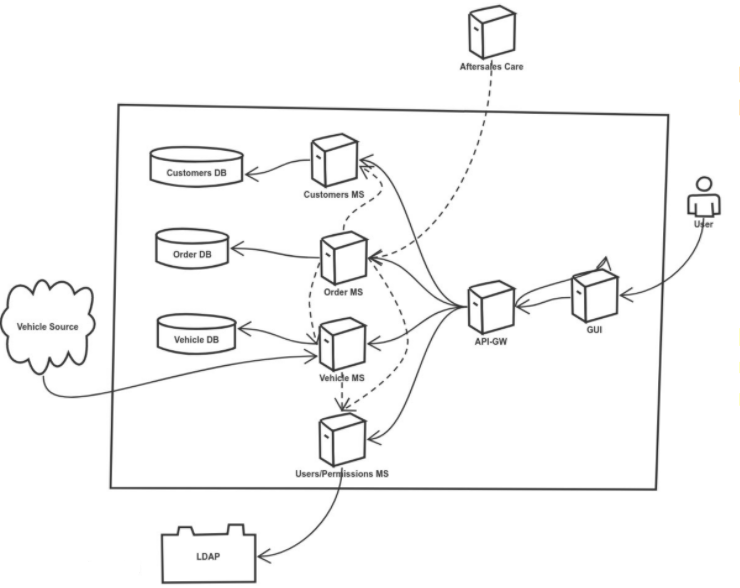
Мой любимый вопрос на Lead Test Engineer или Test Manager. Я рисую такую картинку и говорю:
— Это система, которая работает с деньгами — пусть будет продажа машин. Если мы там что-то потеряем, человек не получит машину, а компания не получит деньги, плюс ее ждут репутационные издержки и т.д. Вопрос: как нам релизиться раз в спринт, не падать в проде и не попасть на штрафы? Напиши мне такой процесс тестирования, и я смогу убедить разработчиков написать тест. Но только напиши мне так, чтобы я был уверен хотя бы на 85%, что я в проде не упаду.
На этот вопрос, к сожалению, пока мало, кто ответил. Все почему-то говорят про модульные тесты, про то, что нам нужно окружение, еще одно окружение, еще одно окружение.
Конечно, правильно было бы иметь какой-то хороший пре-прод, в котором мы все это тестируем. Но это не всегда возможно. В классической разработке с классическими программистами, тест-лидами, менеджерами и т.д., мы имеем все эти dev-test, int, какое-нибудь staging-окружение, куда мы релизимся по определенному процессу. И мы должны понимать, что у нас все это будет протестировано.
Ни технически, ни организационно идеальных практик пока, к сожалению, нет. В общем, тяжело это работает. С монолитом проще: взяли Selenium, все протестировалось, смоками покрыли, выкатываемся в прод — все работает. Мы красавцы, мы восхитительны!
Алексей Шарапов: А как же без проблем, Андрей? Может быть, в том, что касается тестирования, я с тобой согласен. Я не то чтобы заразился здравым смыслом. Просто не так глубоко погружался в проблемы тестирования.
И я еще раз призываю прекратить думать о микросервисе, как о монолите. Мы привыкли тестить так, чтобы было красиво, но теперь условия изменились. Мы, например, во время тестирования очень активно используем testcontainers. И это решает часть проблем.
Я все время говорю о том, что нужно иметь достаточное количество стендов. Я хожу в свои команды и напоминаю: «Ребят, поднимите нормальное количество стендов, прекратите страдать на одном, который упал, после чего все сломалось, и вы мучаетесь. Распределите запросы, и страдания закончатся». Человек, который у вас близко работает с инфраструктурой, как мне кажется, должен взаимодействовать и с и с девелопмент командой. Хотя бы для того, чтобы подойти и сказать им: «Поднимите стенды, все пробросьте к себе на машину, используйте testcontainers, прекратите тестить это, как монолит, и все будет хорошо».
Не надо тащить за собой опыт монолита, применять его на микросервисах и говорить — блин, ничего не работает, как нам теперь жить, и что же с этим делать?
Частично, Андрей, я с тобой согласен, но и монолит не отменяет множества стендов. Я не могу себе представить отчаянных людей, которые запустили монолит на одной машине, чтобы сэкономить свои ресурсы, и сказали: «Все классно! Мы никогда не падали, а во время деплоя там огромный downtime».
Андрей Булов: Уел!
Хочу рассказать про «каждому разработчику по своему Куберу». CI/CD — моя любимая тема.
Во-первых, чтобы это все собрать, нам нужен очень хороший Jenkins с кучей слейвов. В разработке возникает несколько вопросов:
Мы пересобираем все сервисы каждый коммит?
Сколько нужно слейвов на сборку?
Приходит бизнес и говорит:
— А сколько нам нужно заплатить за сборку? Сколько-сколько? Нет, вон там стоит под столом сервер, давайте его использовать.
А почему все так медленно работает?
— У меня пять разработчиков сделали коммиты, и пять раз подряд пересобирается весь этот зоопарк.
Помимо очень мощного окружения нужен очень мощный CI/CD.
Можем ли мы считать, что у нас работает система, когда собралось 60 микросервисов, и 61, который мы не релизим, упал?
— У меня вопрос: можем мы зарелизиться, или нет?
— Тот сервис, конечно, релизить не будем, остальные зарелизим. Какая радость от того, что мы в проде упадем?
— А нужно ли вообще смотреть, что с этим микросервисом? Мы его уже 100 лет не трогали, что-то упало.
— Ну, не знаю. Может быть, сам заработает.
С continuous delivery отдельная песня, когда нам нужно заделиверить что-то. Мы деливерим, деливерим, деливерим это в прод — бах! — падает какая-нибудь джоба, нам это нужно пересобирать все по новой, и т.д. В общем, это гораздо больнее, чем собрать один Maven clean install, прогнать все тесты — все работает, мы великолепны.
Алексей Шарапов: А как жить без CI/CD? Попробую описать, что я имею в виду.
Мне кажется, что CI и CD необходимы для любого проекта. Ты используешь CI в проекте с монолитом, с микросервисами. Почему появляется необходимость на каждый коммит пересобирать все-все-все микросервисы? Здесь стоит опять задуматься о независимости. Возможно, разговор тут идет не про инструменты. Однако, предположим, какой-нибудь GitLab CI с его Docker runners сильно сэкономили бы тебе ресурсы. Мы не говорим про этот страшный Jenkins, который перегружен, огромную Java-машину. Мы можем использовать что-то более легковесное.
Может быть, каждый CI/CD должен заканчиваться на том моменте, где это на самом деле необходимо. Если речь идет об огромном монолите, который работает в нашем энтерпрайзе, скажу честно, CD у нас поскольку постольку, просто потому что есть такие условия. Однако же мы предоставляем и такой инструмент. И мы не берем jenkins , как мы привыкли, а находим необходимый инструмент — легковесный, удобный. Именно с его помощью мы что-то делаем, и это классно работает.
Я просто не могу себе представить, как можно жить без CI/CD. У нас микросервисы — это огромный проект, все они собирались отдельно. Был микросервис, который жил с самой первой версии, никогда не менялся, мы его не пересобирали, однако же он всегда работал. Вот она — независимость.
Андрей Булов: О, вот это мой любимый вопрос на собеседовании — отдельные DevOps команды.
Допустим, у нас есть вполне себе микросервисный ландшафт с базами под каждый микросервис. Все это в consistency состоянии находится, все прямо по матчасти. Приходит заказчик и говорит: «Пожалуйста, перед выкаткой сделайте бэкап прода. И сделайте нормально, чтобы транзакции загасились, мы все забэкапили, сохранили и дальше накатывали, потому что деньги, заказы — страшно».
Мой любимый вопрос DevOps’ам: как написать такую чудесную синюю кнопку, которую жмешь, все базы в один момент с каким-то снепшотом бэкапятся. А еще все это можно потом либо восстановить одной зеленой кнопкой, либо слить разработчикам на дев-окружение. Причем мне нужно не ощущение: «Ну, в принципе, нормально! Вроде, все закончилось», а что-то более доказательное. Если бизнес говорит: «Ребята, это какая-то фигня», что мы ему можем возразить в ответ? Что, по нашим ощущениям, все должно работать?
Как останавливать кучу баз в один момент в микросервисах — это хороший вопрос. Сможешь ли ты на него ответить?
Алексей Шарапов: Нет, потому что это один из самых сложных вопросов касательно микросервисов.
Есть разные подходы на данный момент. Предположим, что существует сложная система с балансировкой через Patroni. Мы в наших реалиях никому не можем передать имеющиеся snapshot базы, просто потому что это невозможно.
Нужно использовать грамотно балансировку, геораспределенный кластер. Когда вы уверены, что ваша хорошая балансировка на 90% обезопасит от всех проблем, вам будет легче. А в ситуации, когда грохнулось все, развалился гео-кластер, машины упали во всех частях, в такой момент то, что у тебя на одну транзакцию меньше забекапилось, как мне кажется, — это меньшая из проблем.
То есть нужно постараться максимально избегать ситуации, когда все это придется в огне восстанавливать, и это уже решит часть твоих проблем. Я обычно делаю ставку именно на это. Но, на самом деле, подходов много. Когда приходишь, а тебе говорят: «Мы сделали одну базу, она крутится, все к ней обращаются. А у нас микросервисы, что теперь делать?», бывает страшно. Об это можно открыть отдельную дискуссию.
Андрей Булов:
Микросервисы просто математически дольше создавать, чем монолит. Нужно написать исходящий интерфейс, входящий интерфейс, обработку ошибок на обеих сторонах, и это все должно как-то вместе срастись. В продакшен какие-то PoC MVP быстрее писать в одной кодовой базе, в одном гите, и не гонять ресты.
К сожалению, в бизнесе с религиозным рвением верят в то, что каким-то образом можно стать лучше, быстрее, зарабатывать в пять раз больше денег, просто потому, что система написана на микросервисах. И есть технари, которые хотят написать микросервисы, потому что: «Я же никогда не делал так — давайте попробуем!». И они совершенно не обращают внимания на то, что до этого они десять лет занимались монолитами.
Получается, все то, про что я говорил: все выливается в эти проблемы. Используйте паттерн мудро и только там, где это необходимо. Аминь.
Алексей Шарапов: Абсолютно согласен — не нужно применять микросервисы там, где этого не требуется. Я хочу привести пример того, как я это представляю. Мы не можем запустить проект в продакшен, пока не будет написано большое количество бизнес-логики. Но мы можем посмотреть на это с другой стороны: у нас есть простой бизнес. Предположим, я сейчас делаю автоматическое создание ресурсов внутри нашей сети.
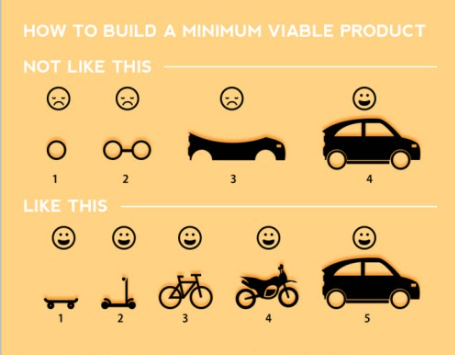
Крошечный скейтбордик — это первый маленький микросервис, который дергает по REST какой-нибудь AWX и запускает создание первой машины: класс, продукт уже есть, и я могу пользоваться этим каждый день. Потом я хочу сделать самокат. Прикручиваю туда базу данных, чтобы ходить в стейты. Дальше велосипед, мотоцикл, в конце машина — это уже AWX плюс Terraform, Cloud, которые взаимодействуют между собой через разные микросервисы, Kafka. Я могу создавать какие-то вещи уже с первой улыбающейся рожицы, которая на меня смотрит (LIKE THIS).
Или возьмем другой бизнес-кейс. Предположим, у вас магазин с напитками. Сегодня вы принимаете заказ с одним напитком, но когда у вас есть автомобиль, это уже огромная сеть ресторанов.
Я предлагаю применять паттерны, подходы, архитектуру там, где это действительно нужно, а не разбивать монолит на куски в ожидании, когда это все вместе будет отработает огромную транзакцию. Тут все зависит от проекта. У меня работает скейтборд, я с ним счастлив и знаю, что послезавтра самокат будет уже готов.
Профессиональная конференция по интеграции процессов разработки, тестирования и эксплуатации DevOpsConf 2021 пройдет 30 и 31 мая 2021. Но билеты на нее вы можете приобрести уже сейчас, успев сделать это до повышения цены.
А еще вы можете сами стать героями конференции, подав доклад.
Хотите бесплатно получить материалы предыдущей конференции по DevOps? Подписывайтесь на рассылку.


