
Задача: используя наименьшее возможное количество ресурсов, отрендерить осмысленный текст.
- Насколько маленьким может быть читаемый шрифт?
- Сколько памяти понадобится, чтобы его хранить?
- Сколько кода понадобится, чтобы его использовать?
Посмотрим, что у нас получится. Спойлер:

Введение в битмэпы
Компьютеры представляют растровые изображения в виде битмэпов. Речь не о формате .bmp, а о способе хранения пикселей в памяти. Для понимания происходящего нам надо кое-что про этот способ узнать.
Слои
Изображение обычно содержит несколько слоёв, расположенных один поверх другого. Чаще всего они соответствуют координатам цветового пространства RGB. Один слой для красного, один для зелёного и один для синего. Если формат изображения поддерживает прозрачность, то для неё создаётся четвёртый слой, обычно называемый альфа. Грубо говоря, цветное изображение — это три (или четыре, если есть альфа-канал) чёрно-белых, расположенных одно над другим.
- RGB — не единственное цветовое пространство; формат JPEG, например, использует YUV. Но в этой статье остальные цветовые пространства нам не понадобятся, поэтому мы их не рассматриваем.
Набор слоёв может быть представлен в памяти двумя способами. Либо они хранятся по отдельности, либо значения из разных слоёв перемежаются. В последнем случае слои называются каналами, и именно так устроено большинство современных форматов.
Допустим, у нас есть рисунок 4x4, содержащий три слоя: R для красного, G для зелёного и B для синего компонента каждого из пикселей. Он может быть представлен вот так:
R R R R
R R R R
R R R R
R R R R
G G G G
G G G G
G G G G
G G G G
B B B B
B B B B
B B B B
B B B BВсе три слоя хранятся по отдельности. Перемежающийся формат выглядит иначе:
RGB RGB RGB RGB
RGB RGB RGB RGB
RGB RGB RGB RGB
RGB RGB RGB RGB- каждая тройка символов соответствует ровно одному пикселю
- значения в пределах тройки идут в порядке RGB. Иногда может использоваться и другой порядок (например, BGR), но этот — самый распространённый.
Для простоты я расположил пиксели в виде двухмерной матрицы, потому что так понятнее, где в изображении находится та или иная тройка. Но на самом деле память компьютера не двумерная, а одномерная, поэтому рисунок 4х4 будет храниться вот так:
RGB RGB RGB RGB RGB RGB RGB RGB RGB RGB RGB RGB RGB RGB RGB RGBbpp
Аббревиатурой bpp обозначается количество битов или байт на пиксель (bits/bytes per pixel). Вам могло где-то попадаться на глаза 24bpp или 3bpp. Эти две характеристики означают одно и то же — 24 бита на пиксель или 3 байта на пиксель. Так как в байте всегда 8 бит, по величине значения можно догадаться, о какой из единиц идёт речь.
Представление в памяти
24bpp, он же 3bpp — самый распостранённый формат для хранения цветов. Вот так на уровне отдельных битов выглядит один пиксель в порядке RGB.
бит 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
пиксель R R R R R R R R G G G G G G G G B B B B B B B B- Один байт для R, один для G и один для B, итого три байта.
- Каждый из них содержит значение от 0 до 255.
Так что если данный пиксель имеет следующий цвет:
R 255G 80B 100
Тогда в первом байте хранится 255, во втором 80, а в третьем — 100.
Чаще всего эти значения представляются в шестнадцатеричном виде. Скажем, #ff5064. Так гораздо удобнее и компактнее: R = 0xff (т.е. R=255 в десятеричном представлении), G = 0x50 (=G=80), B=0x64 (=B=100).
- У шестнадцатеричного представления есть одно полезное свойство. Так как каждый байт цвета представлен двумя символами, каждый символ кодирует ровно пол-байта, или четыре бита. 4 бита, кстати, называются ниббл.
Ширина строки
Когда пиксели идут один за другим и каждый содержит больше одного канала, в данных легко запутаться. Неизвестно, когда заканчивается одна строка и начинается следующая, поэтому для интерпретации файла с битмэпом нужно знать размер изображения и bpp. В нашем случае рисунок имеет ширину w = 4 пикселя и каждый из этих пикселей содержит 3 байта, поэтому строка кодируется 12 (в общем случае w*bpp) байтами.
- Строка не всегда кодируется ровно
w*bppбайтами; часто в неё добавляются "скрытые" пиксели, чтобы довести ширину изображения до какой-то величины. Например, масштабировать рисунки быстрее и удобнее, когда их размер в пикселях равен степени двойки. Поэтому файл может содержать (доступное пользователю) изображение 120х120 пикселей, но храниться как изображение 128х128. При выводе изображения на экран эти пиксели игнорируются. Впрочем, нам о них знать не обязательно.
Координата любого пикселя (x, y) в одномерном представлении — (y * w + x) * bpp. Это, в общем-то, очевидно: y — номер строки, каждая строка содержит w пикселей, так что y * w — это начало нужной строки, а+x переносит нас к нужному x в её пределах. А так как координаты не в байтах, а в пикселях, всё это умножается на размер пикселя bpp, в данном случае в байтах. Так как пиксель имеет ненулевой размер, нужно прочитать ровно bpp байт, начиная с полученной координаты, и у нас будет полное представление нужного пикселя.
Атлас шрифта
Реально существующие мониторы отображают не пиксель как единое целое, а три субпикселя — красный, синий и зелёный. Если посмотреть на монитор под увеличением, то вы увидите что-то вроде вот этого:

- Рисунок с википедии
Нас интересует LCD, так как, скорее всего, именно с такого монитора вы и читаете этот текст. Разумеется, есть подводные камни:
- Не все матрицы используют именно такой порядок субпикселей, бывает и BGR.
- Если повернуть монитор (например, смотреть на телефоне в альбомной ориентации), то паттерн тоже повернётся и шрифт перестанет работать.
- Разные ориентации матрицы и расположение субпикселей потребуют переделки самого шрифта.
- В частности, он не работает на AMOLED-дисплеях, использующих расположение PenTile. Такие дисплеи чаще всего используются в мобильных устройствах.
Использование связанных с субпикселями хаков для увеличения разрешения называется субпиксельным рендерингом. О его применении в типографике можно почитать, например, здесь.
К счастью для нас, Мэтт Сарнов уже догадался использовать субпиксельный рендеринг для создания крошечного шрифта millitext. Вручную он создал вот эту крошечную картинку:

Которая, если очень внимательно вглядываться в монитор, выглядит вот так:

А вот она же, программно увеличенная в 12 раз:
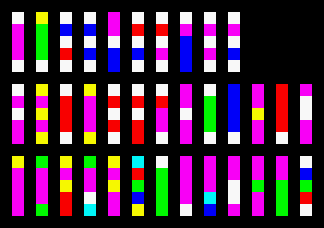
Отталкиваясь от его работы, я создал атлас шрифта, в котором каждому символу соответствует колонка 1x5 пикселей. Порядок символов следующий:
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ
Тот же атлас, увеличенный в 12 раз:

С 36 используемыми символами получается ровно 36х5 пикселей. Если считать, что каждый пиксель занимает 3 байта, то нам нужно 36*5*3 = 540 байт на то, чтобы хранить весь рисуонк (прим. пер.: в оригинале запутанная серия правок по поводу альфа-канала, удаления метаданных и т.п. В переводе я её опустил и использую только окончательный вариант файла). PNG-файл, пропущенный через pngcrush и optipng, занимает даже меньше:
# wc -c < font-crushed.png
390Но можно добиться ещё меньшего размера, если использовать слегка другой подход
Сжатие
Внимательный читатель мог заметить, что атлас использует всего 7 цветов:
#ffffff#ff0000#00ff00#0000ff#00ffff#ff00ff#ffff00
Палитра
В таких ситуациях часто проще создать палитру. Тогда для каждого пикселя можно хранить не три байта цвета, а только номер цвета в палитре. В нашем случае для выбора из 7 цветов будет достаточно 3 бит (7 < 2^3). Если каждому пикселю сопоставить трёхбитное значение, то весь атлас поместится в 68 байт.
- Читатель, разбирающийся в сжатии данных, может ответить, что вообще-то есть такая штука как "дробные биты" и в нашем случае достаточно 2.875 бит на пиксель. Такой плотности можно добиться с помощью чёрной магии, известной как арифметическое кодирование. Мы этого делать не будем, потому что арифметическое кодирование — сложная штука, а 68 байт — это и так немного.
Выравнивание
У трёхбитного кодирования есть один серьёзный недостаток. Пиксели не могут быть равномерно распределены по 8-битным байтам, что важно, потому что байт — минимальный адресуемый участок памяти. Допустим, мы хотим сохранить три пикселя:
A B CЕсли каждый занимает 3 бита, то на их хранение уйдёт 2 байта (- обозначает неиспользуемые биты):
bit 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
pixel A A A B B B C C C - - - - - - -Что важно, пиксель C не просто оставляет кучу пустого места; он разорван между двумя байтами. Когда мы начнём добавлять следующие пиксели, они могут быть расположены как угодно относительно границ байтов. Простейшим решением будет использовать по нибблу на пиксель, потому что 8 прекрасно делится на 4 и позволяет помещать в каждый байт ровно по два пикселя. Но это увеличит размер атласа на треть, с 68 байт до 90 байт.
- На самом деле файл можно сделать ещё меньше, используя кодирование палиндромов, интервальное кодирование и другие методики сжатия. Как и арифметическое кодирование, эти методики мы отложим до следующей статьи.
Битовый буфер
К счастью, в работе с 3-битными значениями нет ничего принципиально невозможного. Нужно просто следить за тем, какую позицию внутри байта мы пишем или читаем в данный момент. Следующий простенький класс конвертирует 3-битный поток данных в массив байтов.
- Из соображений читаемости код написан на JS, но тот же метод генерализуется на другие языки.
- Используется порядок от младшего байта к старшему (Little Endian)
class BitBuffer {
constructor(bytes) {
this.data = new Uint8Array(bytes);
this.offset = 0;
}
write(value) {
for (let i = 0; i < 3; ) {
// bits remaining
const remaining = 3 - i;
// bit offset in the byte i.e remainder of dividing by 8
const bit_offset = this.offset & 7;
// byte offset for a given bit offset, i.e divide by 8
const byte_offset = this.offset >> 3;
// max number of bits we can write to the current byte
const wrote = Math.min(remaining, 8 - bit_offset);
// mask with the correct bit-width
const mask = ~(0xff << wrote);
// shift the bits we want to the start of the byte and mask off the rest
const write_bits = value & mask;
// destination mask to zero all the bits we're changing first
const dest_mask = ~(mask << bit_offset);
value >>= wrote;
// write it
this.data[byte_offset] = (this.data[byte_offset] & dest_mask) | (write_bits << bit_offset);
// advance
this.offset += wrote;
i += wrote;
}
}
to_string() {
return Array.from(this.data, (byte) => ('0' + (byte & 0xff).toString(16)).slice(-2)).join('');
}
};Давайте загрузим и закодируем файл с атласом:
const PNG = require('png-js');
const fs = require('fs');
// this is our palette of colors
const Palette = [
[0xff, 0xff, 0xff],
[0xff, 0x00, 0x00],
[0x00, 0xff, 0x00],
[0x00, 0x00, 0xff],
[0x00, 0xff, 0xff],
[0xff, 0x00, 0xff],
[0xff, 0xff, 0x00]
];
// given a color represented as [R, G, B], find the index in palette where that color is
function find_palette_index(color) {
const [sR, sG, sB] = color;
for (let i = 0; i < Palette.length; i++) {
const [aR, aG, aB] = Palette[i];
if (sR === aR && sG === aG && sB === aB) {
return i;
}
}
return -1;
}
// build the bit buffer representation
function build(cb) {
const data = fs.readFileSync('subpixels.png');
const image = new PNG(data);
image.decode(function(pixels) {
// we need 3 bits per pixel, so w*h*3 gives us the # of bits for our buffer
// however BitBuffer can only allocate bytes, dividing this by 8 (bits for a byte)
// gives us the # of bytes, but that division can result in 67.5 ... Math.ceil
// just rounds up to 68. this will give the right amount of storage for any
// size atlas.
let result = new BitBuffer(Math.ceil((image.width * image.height * 3) / 8));
for (let y = 0; y < image.height; y++) {
for (let x = 0; x < image.width; x++) {
// 1D index as described above
const index = (y * image.width + x) * 4;
// extract the RGB pixel value, ignore A (alpha)
const color = Array.from(pixels.slice(index, index + 3));
// write out 3-bit palette index to the bit buffer
result.write(find_palette_index(color));
}
}
cb(result);
});
}
build((result) => console.log(result.to_string()));Как и ожидалось, атлас поместился в 68 байт, что в 6 раз меньше PNG-файла.
(прим. пер.: автор несколько лукавит: он не сохранил палитру и размер изображения, что по моим прикидкам потребует 23 байт при фиксированном размере палитры и увеличит размер изображения до 91 байта)
Теперь давайте сконвертируем изображение в строку, чтобы можно было вставить его в исходный код. По сути, метод to_string это и делает: он представляет содержимое каждого байта в виде шестнадцатеричного числа.
305000000c0328d6d4b24cb46d516d4ddab669926a0ddab651db76150060009c0285
e6a0752db59054655bd7b569d26a4ddba053892a003060400d232850b40a6b61ad00Но получившаяся строка всё ещё довольно длинная, потому что мы ограничили себя алфавитом из 16 символов. Можно заменить его на base64, в котором символов вчетверо больше.
to_string() {
return Buffer.from(this.data).toString('base64');
}В base64 атлас выглядит вот так:
MFAAAAwDKNbUsky0bVFtTdq2aZJqDdq2Udt2FQBgAJwCheagdS21kFRlW9e1adJqTdugU4kqADBgQA0jKFC0CmthrQA=Эту строку можно захардкодить в JS-модуль и использовать для растеризации текста.
Растеризация
Для экономии памяти в каждый момент будет декодироваться только одна буква.
const Alphabet = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ';
const Atlas = Uint8Array.from(Buffer.from('MFAAAAwDKNbUsky0bVFtTdq2aZJqDdq2Udt2FQBgAJwCheagdS21kFRlW9e1adJqTdugU4kqADBgQA0jKFC0CmthrQA=', 'base64'));
const Palette = [
[0xff, 0xff, 0xff],
[0xff, 0x00, 0x00],
[0x00, 0xff, 0x00],
[0x00, 0x00, 0xff],
[0x00, 0xff, 0xff],
[0xff, 0x00, 0xff],
[0xff, 0xff, 0x00]
];
// at the given bit offset |offset| read a 3-bit value from the Atlas
read = (offset) => {
let value = 0;
for (let i = 0; i < 3; ) {
const bit_offset = offset & 7;
const read = Math.min(3 - i, 8 - bit_offset);
const read_bits = (Atlas[offset >> 3] >> bit_offset) & (~(0xff << read));
value |= read_bits << i;
offset += read;
i += read;
}
return value;
};
// for a given glyph |g| unpack the palette indices for the 5 vertical pixels
unpack = (g) => {
return (new Uint8Array(5)).map((_, i) =>
read(Alphabet.length*3*i + Alphabet.indexOf(g)*3));
};
// for given glyph |g| decode the 1x5 vertical RGB strip
decode = (g) => {
const rgb = new Uint8Array(5*3);
unpack(g).forEach((value, index) =>
rgb.set(Palette[value], index*3));
return rgb;
}Функция decode принимает на вход символ и возвращает соответствующий столбец исходного изображения. Впечатляет тут то, что на декодирование одного символа уходит всего 5 байт памяти, плюс ~1.875 байт на то, чтобы прочитать нужный кусок массива, т.е. в среднем 6.875 на букву. Если прибавить 68 байт на хранение массива и 36 байт на хранение алфавита, то получится, что теоретически можно рендерить текст со 128 байтами RAM.
- Такое возможно, если переписать код на C или ассемблере. На фоне оверхеда JS это экономия на спичках.
Осталось только собрать эти столбцы в единое целое и вернуть картинку с текстом.
print = (t) => {
const c = t.toUpperCase().replace(/[^\w\d ]/g, '');
const w = c.length * 2 - 1, h = 5, bpp = 3; // * 2 for whitespace
const b = new Uint8Array(w * h * bpp);
[...c].forEach((g, i) => {
if (g !== ' ') for (let y = 0; y < h; y++) {
// copy each 1x1 pixel row to the the bitmap
b.set(decode(g).slice(y * bpp, y * bpp + bpp), (y * w + i * 2) * bpp);
}
});
return {w: w, h: h, data: b};
};Это и будет минимальный возможный шрифт.
const fs = require('fs');
const result = print("Breaking the physical limits of fonts");
fs.writeFileSync(`${result.w}x${result.h}.bin`, result.data);Добавим немножко imagemagick, чтоб получить изображение в читаемом формате:
# convert -size 73x5 -depth 8 rgb:73x5.bin done.pngИ вот финальный результат:

Оно же, увеличенное в 12 раз:
Оно же, снятое макросъёмкой с плохо откалиброванного монитора:

И наконец, оно же на мониторе получше:


