
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
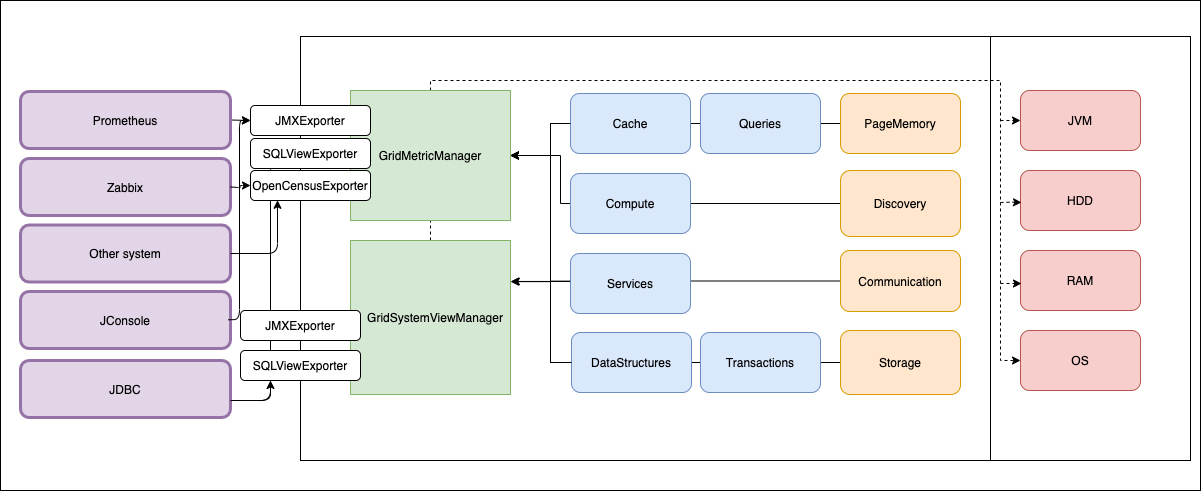
Мы сделали 2 подсистемы внутри Apache Ignite.
В статье расскажу про их архитектуру:
- Как сделали подсистему метрик и подсистему system view.
- Что сделано и что собираемся сделать?
Всем привет! Меня зовут Николай Ижиков. Я работаю в Сбербанк Технологии над развитием Open Source продуктов.
Замечание 1: «сделано» означает, что эта функциональность доступна в master Apache Ignite, можно собрать и посмотреть как все работает. Функционал попадёт в релиз 2.8 Apache Ignite, который будет выпущен в начале 2020 года.
Замечание 2: Статья про архитектуру, не будет конкретных чисел, которые понадобятся для мониторинга Apache Ignite.
Apache Ignite распределенная in-memory платформа. Предоставляет много API: для кеширования, распределённых вычислений, сервисов (построения микросервисной архитектуры), обеспечивает транзакционность.
Зачем
Допустим, у вас есть система и она как-то работает в проде. К вам обязательно придут администраторы и спросят: "А как посмотреть что происходит внутри, как система себя ведёт? Мы хотим узнать о происходящих процессах, до того момента как они приведут к падению или изменению поведения, которое невозможно скрыть." По сути вопросы сводятся к следующим:
- Что происходит? — Что происходит внутри кластера, внутри каждой ноды, какие процессы и как они себя ведут.
- Что внутри? — прикладная система для администратора часто является чёрным ящиком, который выполняет действия, создаются объекты: кеши, таблицы, выполняются транзакции, выполняются распределенные задачи. Администратор хочет знать, что внутри системы.
- Что тормозит? — Какой запрос к системе самый ресурсоёмкий на данный момент.
- Что будет тормозить? — Если мы подадим "вот такую" нагрузку на систему — как она себя будет вести?
Для ответов на часть этих вопросов необходимо разработать подсистему мониторинга.
В случае распределенной системы мониторинг это:
- Наблюдение параметров ноды кластера.
- Отслеживание изменения во времени — графики, которые можно построить по данным с ноды.
- Данные о происходящих внутри процессах. Мы хотим их измерить: время работы, потребляемые ресурсы.
- Данные об объектах и их параметрах: Какие есть таблицы, кеши, сервисы, задачи, транзакции.
Подсистема мониторинга нужна, с этим определились. Но, перед тем как разрабатывать мы должны понять, что у нас есть уже. Получилось следующее:
- Есть много API и много подсистем: transaction manager, cache manager, etc.
- Существуют процессы без метрик
из-за лени разработчиковпо историческим причинам. - Метрики выгружаются через различные API: JMX, SQL, Java. Нужна обратная совместимость с этими API.
Дизайн
Картина идеального мира:
- Легко сделать новую метрику: Почему так сложилось, что метрик в системе недостаточно? Причина в сложности кода. Чтобы сделать новую метрику надо поправить несколько интерфейсов, пробросить в нескольких местах переменные, завести новые методы, потом новую метрику где-то посчитать. Хочется этот процесс облегчить, чтобы разработчики могли легко добавить новую метрику в систему.
- Ноль усилий по «доставке» до администратора: после разработки метрики, администраторы могут анализировать ее через любой поддерживаемый API.
- Интеграция с системами мониторинга: Мы хотим поддержать протоколы jmx, sql, http(Prometheus) из коробки, а также интегрироваться с любыми системами мониторинга, которые использует конечный пользователь.
- Минимум конфигурации: никто не любит конфигурировать, ожидается что при установке из коробки все должно работать.
Необходимо уточнить как происходит работа в Open Source community над такими большими и объемными задачами. У нас есть процесс, который называется Ignite Enhancement Proposal (IEP), автор формулирует предлагаемые изменения, мотивацию, API, фазы изменения.
Было предложено несколько важных и долгоиграющих решений по дизайну:
Локальные
Ignite распределённая система: есть глобальное состояние, поддерживаемое между нодами. В текущей реализации есть глобальные метрики, которые отражают состояние всего кластера. С моей точки зрения, это неверный подход. Если метрика должна быть глобальной это означает, что Ignite должен обеспечивать консистентность подсчета этой метрики по всему кластеру. Что ведет к тому, что Ignite выполняет не свойственные для себя функции — правильный подсчет метрик и поддержание их в актуальном состоянии. Мое глубокое убеждение — метрики должны быть локальными. После их сбора в системе агрегации метрик (prometheus, zabbix) мы можем вычислить глобальное состояние.
Иерархические
В Ignite много подсистем. Также Ignite должен предоставлять информацию о своём окружении: jvm, диск, памяти, версия ОС и др. Каждая из подсистем Ignite предоставляет свой набор метрик. Есть подсистемы, внутри которых так же есть иерархия.
Пример: кеши — хочется смотреть метрики по каждому кешу отдельно.
Так появляется несколько уровней иерархии: кеши, data region'ы, сетевые сообщения от конкретной ноды и т.д. Иерархическая структура отображена в названии метрики, слева направо идут уровни иерархии, разделенные точкой.
Пример: io.dataregion.myregion.TotalAllocatedPages — количество страниц выделенных для Data Region с именем "myregion".
Реализация
В коде реализовано так:
Metric,Gauge— конкретное число которое вычисляется при работе ноды.MetricRegistry— набор (группа, реестр) метрик.MetricExporterSpi— экспортер метрик во внешний мир.ReadOnlyMetricRegistry— интерфейс, который доступен для exporter’о-в. read only access + listeners.GridMetricManager— управление всем хозяйством.
Выделено несколько типов метрик:
Metric— счётчик. Обновляется в процессе работы ноды.
Примеры:LongAddterMetric,DoubleMetricImpl,ObjectMetricImpl.Gauge— значение. Вычисляется в момент обращения, обертка над Supplier. Поддерживать актуальное состояние счетчика не всегда просто. Бывает, проще написать алгоритм, который вычисляет значение.
Примеры:LongGauge,DoubleGauge,ObjectGauge.HistogramMetric— интервалы + количество событий в интервале. Гистограмма считает количество событий, значение которых попало в определенный интервал.
Пример: количество запросов, обработанных быстрее 250 мсек, 500 мсек, 1 сек и все остальные.HitRateMetric— количество событий за последние X мсек.
Пример: количество страниц памяти, выделенных за последнюю минуту.
MetricExporterSpi — каждый из экспортеров работает независимо, по своему протоколу. Он выгружает в любую систему свои метрики, что обеспечивает универсальность и гибкость. Из коробки поддерживаются JMX, SQL, Log, OpenCensus.
Простота заведения
GridMetricManager mmgr = ...;
MetricRegistry mreg = mmgr.registry("io.dataregion." + name);
LongAdderMetric replacedPages = mreg.longAdderMetric("PagesReplaced",
"Number of pages replaced from last restart.");
//....
replacedPages.increment();Красивые картинки
Кажется, что на вопрос "Что происходит?" мы ответили.
Осталось всего лишь реализовать все нужные метрики.
System View — Что внутри?
При наличии опыта работы с реляционными БД все понимают идею — везде есть системные представления. Мы назвали сущность system view, но можем показывать ее не только с помощью SQL. Поддерживаются любые протоколы (из коробки еще JMX).
Дизайн
SystemView— именованный список объектов (таблица). Примеры: кэши, сервисы, compute task'и, sql table и т. д.SystemViewExporterSpi— экспортер во внешний мир.ReadOnlySystemViewRegistry— интерфейс для exporter'ов. read only access + listeners.GridSystemViewManager— управление всем хозяйством
Реализация
Особенности:
- Данные уже внутри системы. Понятно, что если система работает с кешами, то она про них знает и где-то хранит. Мы должны пользователю это описание вернуть.
- Нужен минимальный overhead. Мы не должны нагружать систему отдавая внутренние данные.
- Нужен быстрый обход по строкам и столбцам. Работаем с табличными данными. Каждый протокол выгружает описание столбцов в собственном формате.
При экспорте нужно знать схему данных: столбцы и их типы. Эта информация есть в java-классе. Задача выгрузки схемы формулируется следующим образом:
Есть пара десятков POJO. Их структура известна, новых классов не будет. Нужен быстрый проход по свойствам. Хочется поддерживать порядок обхода. Вопрос: Можно ли придумать более быстрый способ чем reflection?
Я сделал кодогенерацию:
- Вся информация есть в compile time.
- Генерируемый код очевидный и без условий.
- Можем задать порядок обхода.
- Запускаем генератор при сборке.
Что получилось:
Интерфейс(SystemViewRowAttributeWalker.java), который умеет обходить свойства объекта для формирования схемы и для выгрузки данных. Реализации интерфейса генерируются автоматически. Заведение system view становится очень простым. После заведения представление становится доступно всем экспортерам.
ctx.systemView().registerView(CACHES_VIEW, CACHES_VIEW_DESC,
new CacheViewWalker(),
registeredCaches.values(),
CacheView::new);
ctx.systemView().registerView(CACHE_GRPS_VIEW, CACHE_GRPS_VIEW_DESC,
new CacheGroupViewWalker(),
registeredCacheGrps.values(),
CacheGroupView::new);Reflection тормозит — как не удивительно, но не для всех это очевидно. Для обсуждения на dev-list я написал JMH benchmark. Для reflection он берет список методов из класса. В случае walker он вызывает конкретные методы. Walker работает в 4 раза быстрее.
Красивые картинки
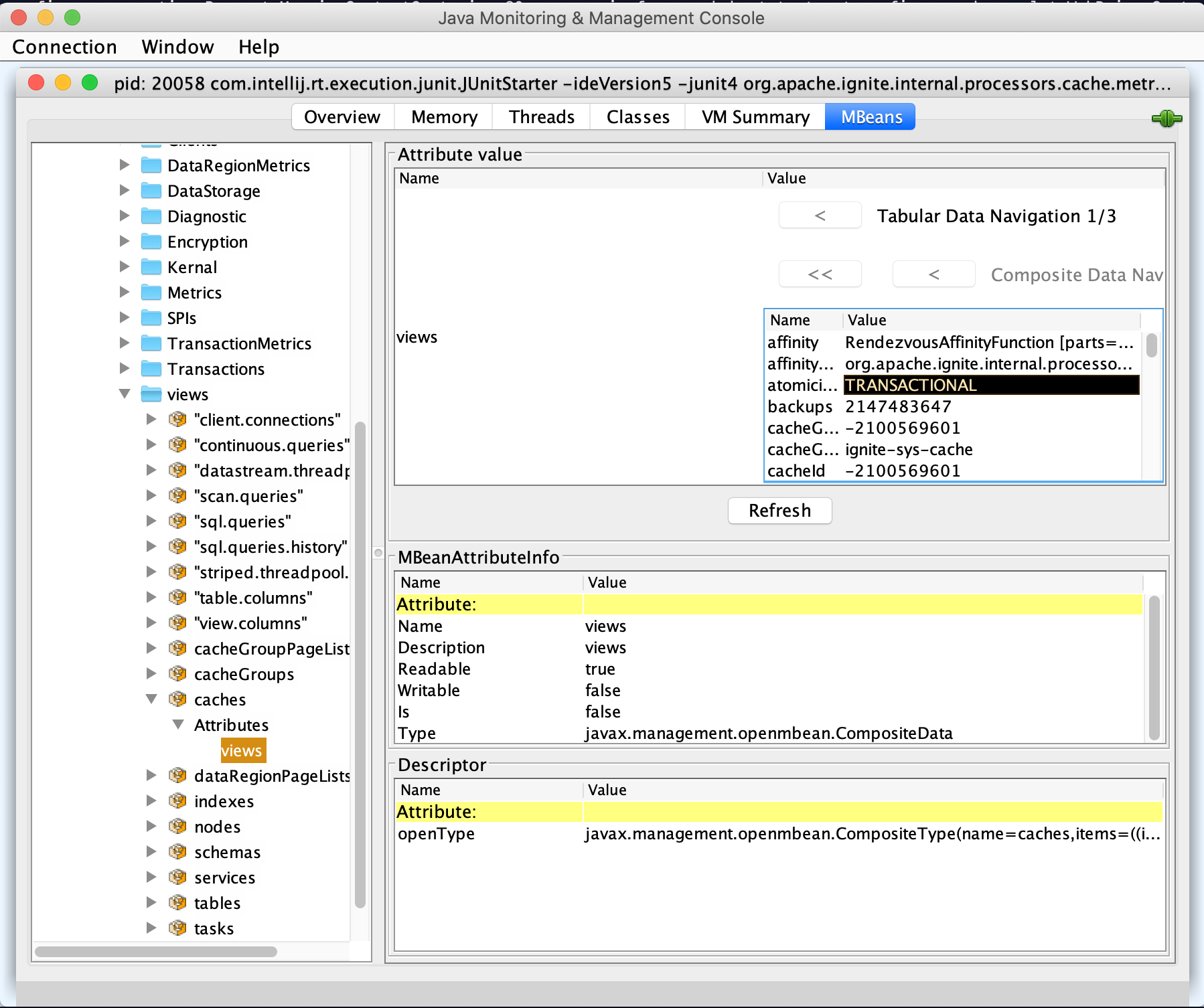
Кажется, что на вопрос "Что внутри?" мы ответили.
Осталось всего лишь
- Документация: сейчас документации нет, разработчики не любят ее писать и откладывают ее на последний момент.
Я такой же. - Настройки для взрослого мониторинга «из коробки» (prometheus, zabbix)
- Трейсинг. В случае мониторинга мы отслеживаем общие процессы, общее поведение ноды. В случае трейсинга — хотим получить информацию о параметрах единственного запроса в привязке к пользовательской активности.
- Отчёт производительности. Пользователи Oracle и других реляционных СУБД привыкли что есть возможность включить сбор статистики, подать нагрузку, и получить в удобном виде отчёт производительности: какие запросы выполнялись, сколько нагрузки они сгенерили, какие транзакции были, проблемы.
- Контроль пользовательского кода — в Ignite есть много мест, которые позволяют пользователю задать свой код для выполнения задач. Хочется предоставить возможность администратору контролировать как быстро работает пользовательский код. Задаётся некий threshold «compute задача не должна работать дольше 30 сек», и если она работает дольше, то вы получаете уведомление.
Полезные ссылки
- исходники
- dev@ignite.apache.org
- user@ignite.apache.org
Приходите! У нас практически русскоязычное community, почти все контрибьютеры из России, поэтому вы можете легко влиться и сделать вклад в Open Source.
Сейчас на dev-листе идет очень интересная дискуссия на тему "А правильно ли мы сделали?", а также по процессу замены устаревшего API
Презентация — https://www.highload.ru/moscow/2019/abstracts/6111
Видео:



