
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Добрый день, дорогой читатель! Эта статья возникла благодаря попытке взглянуть на операционный мониторинг со стороны аналитики. Она будет вам полезна, если:
- что-то из следующего списка хорошо знакомо: Grafana, InfluxDB, Prometheus, Zabbix или другая система мониторинга с похожими идеями;
- вы не эксперт/профессионал/уверенный миддл в различных типах отображения временных рядов и матстатистике (в противном случае для вас, весьма вероятно, будет скучновато);
- есть желание взглянуть на некоторые аспекты «под микроскопом».
Если вы решили, что условия выше соблюдены, добро пожаловать под кат.

— Скажите, пожалуйста, куда мне отсюда идти?
— А куда ты хочешь попасть? — ответил Кот.
— Мне все равно… — сказала Алиса.
— Тогда все равно, куда и идти, — заметил Кот.
—… только бы попасть куда-нибудь, — пояснила Алиса.
— Куда-нибудь ты обязательно попадешь, — сказал Кот. — Нужно только достаточно долго идти.
«Алиса в Стране чудес» Льюис Кэрролл
Путешествие начинается...
В вопросе с поиском проблем в реальном окружении есть множество предубеждений и ошибок. Во многом потому, что в постмортемах пишут в основном, как избежать подобных проблем в будущем, а не о том, почему не получилось починить сервис быстрее. Когда наблюдаешь проблемы достаточно часто, вопрос «почему?» сам собой возникает в голове. Почему? Все метрики собирались, дашборды на все критические компоненты были сделаны заранее и даже пара триггеров была заготовлена ( возможно, они даже сработали)! Тут начинается поиск подводных камней, и тут же начинается моё повествование.
Фундаментальные проблемы
Итак, в начале было слово был RFC1065:
…
3.2.3.3. Counter
This application-wide type represents a non-negative integer which
Rose & McCloghrie [Page 8]
RFC 1065 SMI August 1988
monotonically increases until it reaches a maximum value, when it
wraps around and starts increasing again from zero. This memo
specifies a maximum value of 2^32-1 (4294967295 decimal) for
counters.
3.2.3.4. Gauge
This application-wide type represents a non-negative integer, which
may increase or decrease, but which latches at a maximum value. This
memo specifies a maximum value of 2^32-1 (4294967295 decimal) for
gauges.
…
Исходя из этого, достоверно известно, что в августе 1988-го уже была спецификация, которая весьма однозначно разделяла две сущности: накопительный счётчик и измерение. Но почему-то мы продолжаем страдать от незнания этой разницы до сих пор, даже несмотря на усилия встроить это различие в современные системы максимально очевидным способом, например, в Prometheus.
То была фундаментальная проблема номер один. Проблема номер два — это необъяснимая всепоглощающая любовь к арифметическому среднему: вне зависимости от происхождения, значения, и поведения метрики многие люди при необходимости использовать функцию агрегации выбирают именно его. И тут мы наступаем на детские грабли из матстатистики — нельзя просто так брать среднее чего-то на неопределённом интервале и при этом не потерять ничего. А интервал может быть и вправду не слишком-то и определённым…
Если в качестве UI для просмотра метрик взять Grafana, которая, имхо, де-факто является стандартом в индустрии, то по умолчанию мы имеем $__interval, который, согласно документации, приблизительно считается на основе разрешения экрана. И это уже неопределённость — разве что внутри организации строго запрещено использовать любые экраны с разрешением, отличным от 4k. Не забываем про мобильные девайсы, макбуки, телевизоры с дашбордами — и тут уже становится понятнее боль фронтендеров. Хотя, конечно, без этой привязки ситуация может стать сильно хуже.
Вдобавок, нас (как опытных пользователей) может не устроить вариант «по умолчанию» по многим причинам. Возьмём для примера такую конструкцию:
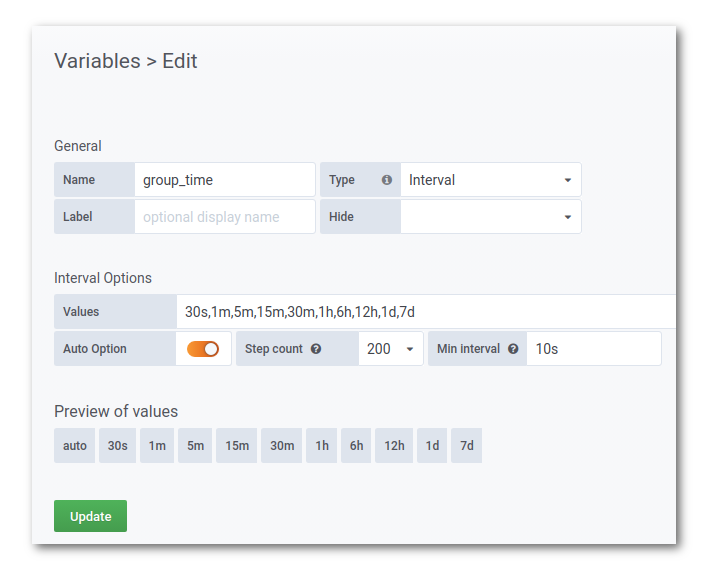
Эмпирически проверено, что значения “Step count” 200 и 300 работают неплохо (остальное, думаю, не нуждается в пояснениях. И попробуем менять глубину запроса: если интервал получения метрик составит 10 секунд, получим следующую таблицу:
| “Глубина” запроса | Размер семпла $group_time | Количество точек для расчёта среднего | |
|---|---|---|---|
| Пример InfluxQL | WHERE time>now()-... | GROUP BY time(...) | |
| 1h | 20s | 2 | |
| 1d (24h) | 5m | 30 | |
| 1w | 1h | 360 | |
| 1month | 3h | 1080 |
О да, больше тысячи значений за одной точкой! И если не было времени (или было просто лень) приблизить кусочки графика, то мы никогда не узнаем, что же было на графике на самом деле.
Среднее среднего
Пришло время вернуться к началу рассказа и вспомнить про накопительные счётчики. На эту тему я нарисовал такую картинку (с примерами опять из Influx’а, но в некоторых других системах мы можем наблюдать похожие проблемы):

Существует некоторая путаница понятий в именовании функций в InfluxDB, из этой статьи можно понять, что: An instantaneous rate of change is equivalent to a derivative (Мгновенная скорость изменения эквивалентна производной), что известно ещё из школьного курса математики. А в случае с дискретными точками, полученными просто периодическими измерениями, мы, соответственно, имеем дело с со средней скоростью изменения (average rate of change). Но проблема не в этом. Проблема в том, что, используя здесь mean (арифметическое среднее), мы получаем совсем не то, что хотели. Если счётчик растёт нелинейно, мы будем получать смещение «середины» внутри семпла данных, то есть результат просто-напросто не будет показывать изменение значения за указанный интервал. Ну и, в конце концов, эта конструкция алгоритмически выглядит совершенно глупо, несмотря на отсутствие явных просадок в производительности, ведь измеряя разницу между двумя точками накопительного счётчика, мы уже получаем среднюю скорость изменения.
Конец или начало
Но на этом «странности» не заканчиваются: внимательный пользователь заметит некоторое искажение последнего значения в меньшую сторону, если использовать last, как упомянуто выше (на примере InfluxQL, в promql другая история). При использовании last в запросе последний отрезок не будет равен выбранному интервалу группировки. В данном случае база данных в качестве начала каждого интервала берёт точку во времени, всегда округлённую в меньшую сторону. Например, в случае группировки за час мы будем наблюдать изменение значения счётчика на последнем интервале на протяжении часа, начиная с 00 минут этого часа. Поэтому я пока остановился на варианте non_negative_derivative(first(...)) для большинства случаев. Альтернатива, которая не имеет этой проблемы, — делить данные на кусочки, начиная с настоящего момента — также не слишком хороша: каждое обновление графика (а значит и обновление точки отсчёта) потребует пересчёта всех значений.

Простые функции кроме среднего
Чувствуете, что мы приближаемся к сути происходящего безумия? Давайте разберем каждый шаг.
Ну не устроил нас mean, в InfluxDB есть ещё уйма замечательных функций: max, min, last, и нечто, возможно, не столь очевидное — stddev. В prometheus есть аналогичные min_over_time, max_over_time, stddev_over_time, но дальше я разбираю на примере в Influx (есть предположение, что между ними в данной части много сходства). Last, я думаю, в пояснениях не нуждается, но если выбросы важны, то получается он даже лучше, чем mean: с ним есть хоть какой-то шанс заметить выбросы на графиках, в то время как mean всё усредняет, как мы и «хотели».
Очевидно, что max и min независимо друг от друга будут работать так себе. Но что если скомбинировать этих двоих и прибавить к ним среднее? Оказывается, эта идея не то что не нова, она вообще древняя, как пирамиды. Из «классических» примеров в системах мониторинга мне вспоминаются тренды в Zabbix (намеренно поискал ссылку на версию постарше) и Graphite Whisper Rollup, а также более ранний RRDtool, который так же использовался в Cacti, где почему-то min отсутствовал по умолчанию. Возможно, несмотря на весь последующий текст, это один из лучших подходов. Он достаточно информативен, не слишком зашумлён, интуитивно понятен, дёшев в реализации, относительно универсален и доступен практически во всех современных системах.
Примеры подобной отрисовки:
- в Zabbix

- в Grafana
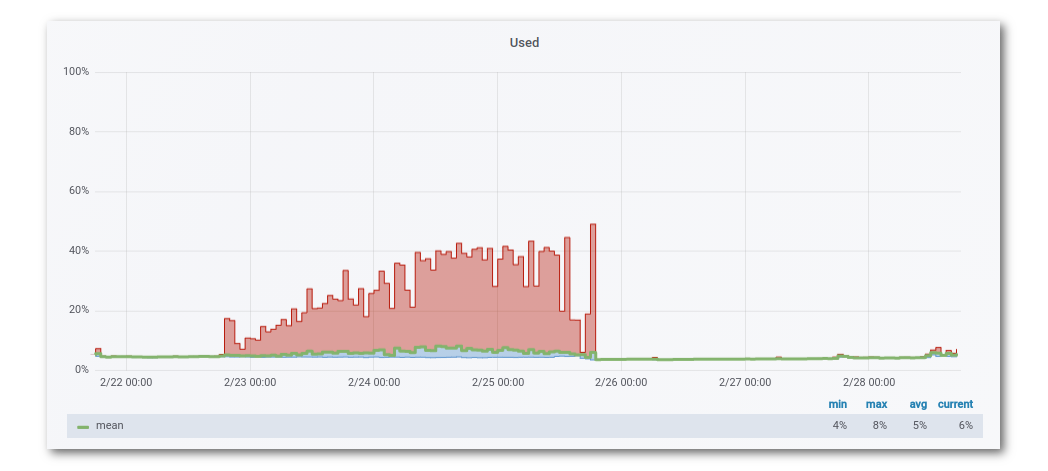
Несложно заметить, что min от mean (как и max и avg) отличаются от того, что должно бы быть, но в Grafana пока нельзя выбирать Legend -> Values для каждой отдельной серии измерений, а вывод всех трёх агрегаций с четырьмя колонками, имхо, загромождает отображение.
«Математический» подход к рисованию
Это всё хорошо, но не предел мечтаний хотя бы потому, что существует stddev — то есть standard deviation, или по-русски среднеквадратическое отклонение. Вкратце замечу, что таким образом мы получаем возможность наглядно наблюдать колебания нашей метрики, особенно когда они становятся больше обычного. Плюс, что более важно, можно оценить «близость» точек в выборке к среднему. Однако в данном случае мы теряем представление об абсолютных значениях исходной величины, чего не хотелось бы (если, конечно, мы вообще изначально представляли, что эти абсолютные значения означают, что далеко не всегда правда).
Итак, мы получили это самое отклонение и хотим показать его на графике вместе с исходными данными: это можно сделать с помощью error bar. Есть вариант ещё интереснее — “ящик с усами”, который строится на основе 1-го, 2-го и 3-го квартиля (25% процентиль, медиана и 75% процентиль). Как раз то, что нам нужно для лучшей жизни? Нет :) Хотя бы потому, что ни первого, ни второго не нашлось во всеми любимой Grafana. Правда, меня это не сильно смутило и я поигрался с данными с помощью pandas и seaborn (и даже plotly).
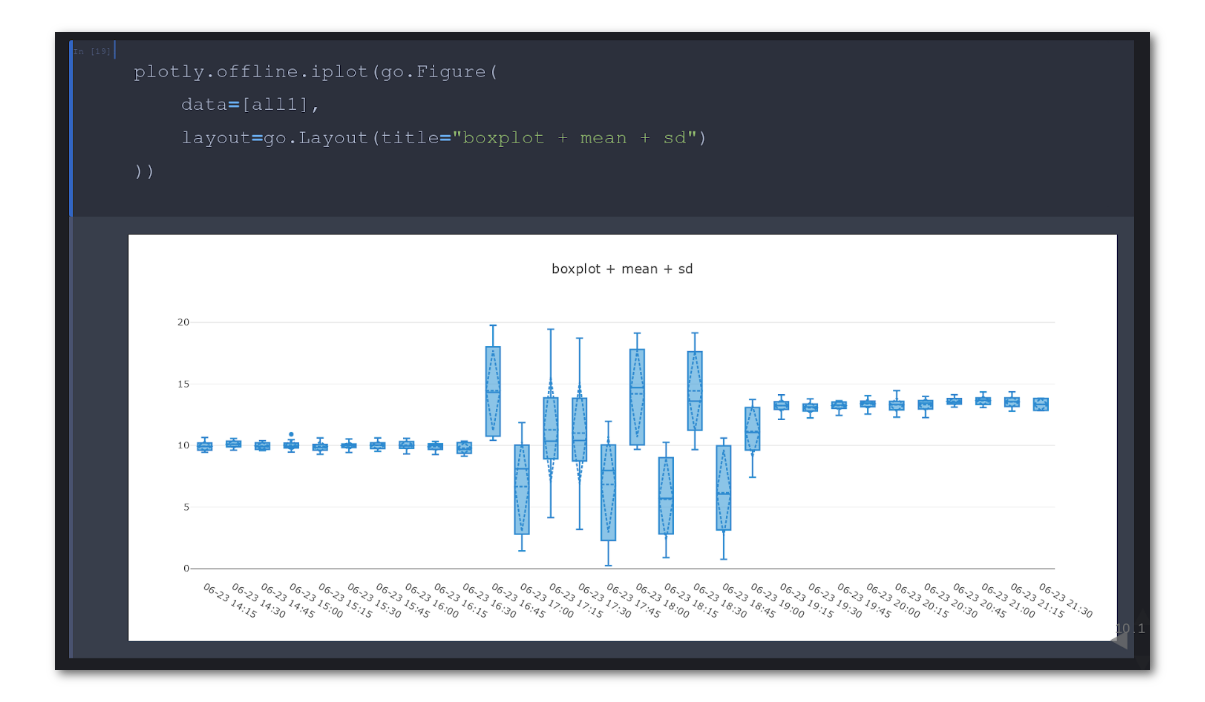
Тем не менее, это не существенно приблизило меня к цели, потому что «ящик с усами» имеет очевидные недостатки, которые унаследованы от тех величин, что он в себе содержит. Быстрее всего понять суть проблемы можно по ключевым словам “the Datasaurus Dozen animation” в Google.

На гифке видно, что множество точек можно расположить огромным количеством способов, при этом значительно не изменив среднее, среднеквадратическое отклонение и коэффициент корреляции Пирсона. В случае временных рядов, конечно, не получить такого же богатства вариантов на одной серии данных при фиксированном интервале сбора показателей, но тем не менее оно есть.
Предположим, что идея с «ящиком с усами» сыграла в ящик. Что дальше? Изучаем варианты визуализаций в seaborn! Берём первое, что попалось: violinplot. Классная штука, фразы «ядерная оценка плотности» и «метод окна Парзена-Розенблатта» звучат неплохо и, возможно, приведут нас к какой-нибудь цели, но в этот раз придётся пройти мимо: violinplot не поддерживается в Grafana.
Классификация
Самое время остановиться на секунду и задуматься: что же есть проблема, которую мы потенциально хотим обнаружить, изучая график? Что является нормальным, а что нет? Как мы определяем аномалию? Почему мы не видим аномалию, когда она на самом деле есть? Неплохо бы иметь хоть какую-то классификацию.
Кроме того, что мы уже знаем разницу между накопительным счётчиком и измерением, можно найти огромное количество информации о классификации метрик. Возьмём для примера один весьма авторитетный источник: Google SRE book. Там мы найдём упоминание о «четырёх золотых сигналах» (думаю, читателю лучше обратиться к первоисточнику, а я лишь упомяну их названия): latency, traffic, errors, saturation. В идеальном мире этими терминами маркируются все метрики в системе, или есть возможность как-то понять (по длинному человекочитаемому названию), к чему в выбранной классификации относится эта метрика. За примером далеко ходить не надо: если у нас метрика saturation и мы не перемудрили и измерили её в % от 100, то можно понять следующее: когда она принимает значение 100, наиболее вероятно система «перенасыщена» запросами, а когда 0 — наоборот, и это, скорее всего, тоже не очень хорошо. Также, в большинстве случаев, ошибки — это накопительный счётчик, что легко позволяет интерпретировать происходящее.
Скорость и производительность
Вернёмся к теме отображения метрик, чтобы столкнуться с ещё одной проблемой: тормозящие или вовсе не работающие дашборды. Чтобы понять, почему это может происходить, обратимся к истокам метрик, то есть к их сбору агентами/коллекторами. Тут мы наблюдаем две модели (которые, собственно, наблюдаем почти во всех современных информационных системах): pull и push. На этом месте ведутся вековые священные войны адептов двух противоборствующих лагерей, а я стараюсь сохранять нейтралитет во избежание сожжения на костре за невежество. Поэтому я лишь упомяну, что, на мой взгляд, наиболее яркий представитель лагеря push — это Riemann-tools, а лагеря pull — широко известный Prometheus.
Несколько промежуточную стратегию использует Telegraf, в котором есть как входы (input-plugins) для метрик через обе модели, так и выходы (output-plugins) через обе модели. К сожалению, в нём нет категории discovery-plugins— вместо этого наблюдаются решения внутри input-plugins, неоднородные по конфигурации и коду. Тут каждый ветеран индустрии мониторинга заметит, что обнаружение ресурсов на уровне сбора данных было давно, взять тот же LLD (low-level discovery) в Zabbix, но снова не удалось переиспользовать опыт предыдущих итераций. Однако это не все «усовершенствования»: механизм доставки конфигурации также деградировал в плане удобства (имеется в виду на нижнем уровне). Вместо этого предлагается перенести эту проблему на уровень управления конфигурацией в рамках системы доставки (например, prometheus-operator), что логично, но не всегда хорошо применимо на практике. Причём, несмотря на то, что с запросами о динамической конфигурации всех прямо отправили в … Kubernetes, не все готовы это принять — взять для примера хотя бы недавнюю статью в блоге Influxdata. Более-менее продуманный альтернативный подход (конфигурация через API/RPC) встречался в snap, который, в свою очередь, имел другие недостатки (но о почивших говорят либо хорошо, либо никак).
Допустим, мы имеем pull-модель для сбора метрик и какой то агент-сборщик, который имеет параметр интервала сбора. Это параметр может быть или глобальным, или настраиваемым вплоть до каждой конкретной серии измерений. Чем меньше интервал, тем больше мы, скорее всего, нагрузим базу. А может и нет. Может, у нас и вовсе нет базы: мы получаем оповещения на основе метрик в рантайме (например, уже упомянутый Riemann позволяет легко реализовать подобную схему). Но в более классической схеме мы всё же будем ожидать базу после некоторого кэша данных. Кэш, в свою очередь, расположен или после их сбора, или в самом процессе сборщика, или внешний (например, какая-либо очередь). Если взять для примера чуть более старые стеки с использованием Graphite и/или statsd, то мы увидим агрегатор посредине, который призван не только снизить нагрузку на базу, но и ускорить отрисовку на UI. В Prometheus за это отвечают recording rules и Thanos Compact, а в TICK-стеке есть выбор между двумя, имхо, весьма сомнительными вариантами: Continues Queries в InfluxDB и TICKscript в Kapacitor. При этом мы можем иметь дело с данными, изначально агрегированными на стороне коллектора, — например, Histogram и Summary в Prometheus, причём аналогичные структуры можно обнаружить в Accumulator interface в Telegraf.
B конечном итоге сильно абстрагировано получается, что, прежде чем оказаться на экране, метрика проходит путь, похожий на это:
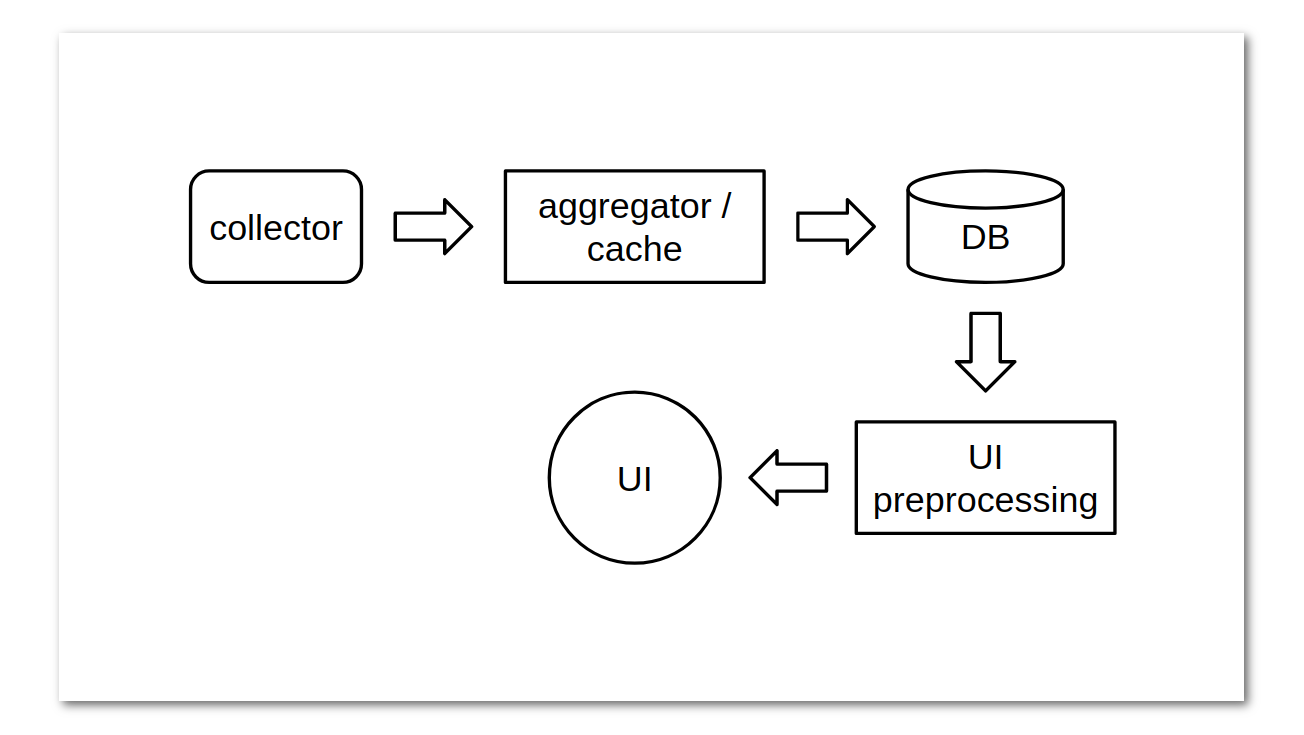
Отсюда видно, что чем больше точек мы пытаемся показать на UI, тем больше данных мы должны будем передать от одного этапа другому. И тут есть некоторый подвох: даже если мы изначально используем относительно низкоуровневый инструмент для отрисовки данных, в большинстве случаев мы хотим иметь все данные прямо в браузере клиента или, на крайний случай, на этапе UI-preprocessing. Но зачастую объём данных таков, что извлечение сырых данных прямо из базы уже несёт в себе проблемы. Также не стоит забывать, что обратным потоком от базы может «накрывать» UI-preprocessing или сам UI, или же последние в результате троттлинга откидывают часть или все данные, пришедшие от базы. В таком случае, как правило, агрегация данных на уровне базы или отдельным сервисом до/после базы — необходимость.
В этот момент уместно вернутся к «ящику с усами» и понять, что для его отрисовки без выбросов достаточно 3-х значений на один семпл данных, что представляет этот метод в весьма выгодном свете, если стоит задача минимизировать количество хранимых метрик. Поэтому хоронить его, похоже, пока рано.
Гистограмма
Если мы вернёмся к ещё недосказанным оставшимся вариантам отрисовки, то обнаружим, что надежда ещё остаётся: в Prometheus, Telegraf и многих других системах мониторинга упоминаются гистограммы. Ограниченное распространение гистограмм выглядит парадоксально, учитывая, что heatmap (в данном случае не что иное как гистограмма во времени), встроенный функционал в Grafana. Естественно, гистограмма как таковая также присутствует в «стандартной поставке», и ей тоже можно найти применение.
Картинка из официальной документации Grafana

Кроме того, в Grafana можно делать heatmap в формате time series buckets, что позволяет наглядно группировать метрики по тегам, например, показать утилизацию CPU по ядрам:
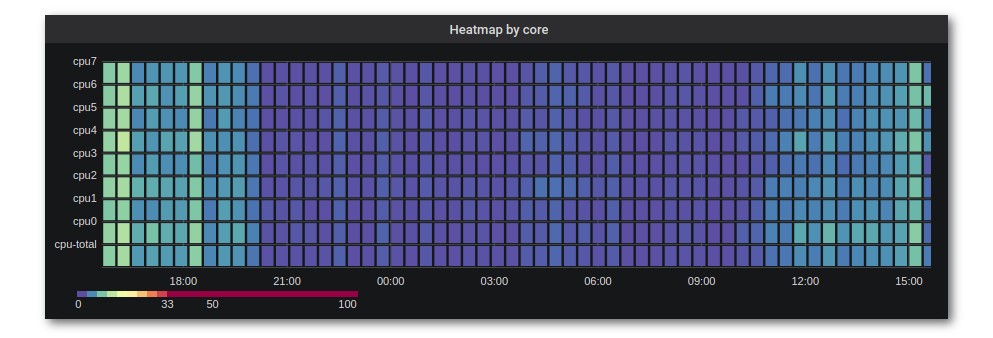
Итого
Просуммировав вышесказанное, получаем следующую логику действий для рисования дашборда:
- Классифицируем метрики:
накопительный счётчик или мгновенное измерение;
latency, traffic, errors или saturation. - Если это накопительный счётчик, то кроме применения функции для расчёта рейта знакомимся с особенностями её работы в конкретной системе.
- Если есть необходимость смотреть достаточно далеко в прошлое (что почти всегда правда), думаем, какие функции агрегации нужны и на каком этапе передачи данных эти функции должны быть применены, чтобы ничего не тормозило.
- Пытаемся сделать всё максимально просто. Если это невозможно и чего-то явно не хватает в Grafana (или родном UI системы мониторинга), то, скорее всего, потратив не слишком много времени, можно сделать что-то своё на Python или JS.
Простая задача создания дашборда в Grafana требует знаний а) путей доставки метрик до UI; б) конфигурации и производительности компонент на этом пути; в) базовых знаний математической статистики.
Но это не повод для грусти — графики могут быть не только полезными, но и весёлыми: например, вот такие фигуры, похожие на ёлочные игрушки.
Послесловие
Для тех, кому хочется больше информации, рекомендую статью с похожим ходом рассуждений, классной анимацией и другим выводом. Также не будет лишним упомянуть недавний пост Александра Валялкина про гистограммы. И интересное видео про latency и перцентили.



