
Введение
Толчком к появлению SRE было рассмотрение надежности продукта как одной из его функциональных возможностей. Однако последнее время внимание в основном уделяется SLO, бюджетам на ошибки (error budget), организации промышленной эксплуатации и другим SRE-практикам, и многие забыли о преимуществах подхода к надежности, ориентированного на продукт. В этом посте я размышляю об уровнях зрелости проектов, надежности в контексте SRE, а также о том, какие виды взаимодействия наиболее полезны на каждом из этапов проекта при реализации надежности как фичи.
Краткая история
Дисциплина Site Reliability Engineering (обеспечение надежности информационных систем), или сокращенно SRE, возникла в 2003 году в Google при решении задач повышения надежности сервисов. Практика SRE, о которой часто говорят как о "реализации DevOps", рассматривает эксплуатацию сервиса как программную задачу, решаемую с помощью методов инженерии программного обеспечения.
Согласно исследованию DevOps Institute, SRE действительно набирает обороты. Подход SRE получил широкое распространение: 22% организаций заявили, что в 2021 году у них есть SRE-команда. Этот сдвиг также можно увидеть по увеличению количества конференций, таких как SREcon от USENIX, которую начали проводить с 2014 года, или по выпуску в 2016 году популярной книги "Google SRE book".
Независимо от того есть ли у вас SRE-команда, использующая SLO, бюджеты на ошибки, и регулярно сокращающая трудозатраты через автоматизацию и внедрение SRE-практик, иногда теряется основная идея, лежащая в основе SRE: эксплуатация — это программная проблема. Или, если смотреть со стороны клиента, надежность — это фича продукта, которую мы должны реализовать.
Занимая в прошлом должности DevOps-инженера и SRE-инженера, а также тимлида, у меня было много возможностей определить ответственность, задачи и, главное, влияние SRE-команды. Каждый раз я наблюдал, как наиболее полезным аргументом при разговоре с руководством о работе SRE-команды ("почему") был перевод разговора в русло клиентского опыта в части надежности, а не очередное обсуждение возможных квартальных работ SRE-команды. Это также простой тест на полезность выполняемой работы. Если я не могу объяснить, как моя текущая работа влияет на надежность для клиентов, подразумевая, что надежность эксплуатации обычно приводит к надежности для клиентов, это может быть признаком необходимости поработать над чем-то другим.
Возвращаемся к надежности продукта
Смещение акцента с эксплуатации и разработки программного обеспечения на надежность как функциональность продукта дает ряд преимуществ. Во-первых, помогает лучше понять, что для нас и наших продуктов значит надежность: отказоустойчивость (устойчивость к сбоям), масштабируемость (способность работать с большими объемами данных), наблюдаемость (определение внутреннего состояния системы по ее выходным данным) или безопасность (доверие к системе). Часто эти характеристики продукта не прорабатываются должным образом, хотя и очень важны для клиентов.
Надежность выигрывает от поддержки управления продуктом (общение со стейкхолдерами, разработка дорожных карт, помощь в приоритезации и принятии решений и т.д.). Например, знаете ли вы своих внутренних стейкхолдеров в части масштабируемости продукта? Что входит в дорожную карту по наблюдаемости (observability) на ближайшие шесть месяцев? На два года? Какие метрики вы будете собирать для контроля достижения целей и выполнения этой дорожной карты? Как они согласуются с дорожными картами других фич? Один мой друг и бывший коллега говорил: "надежность — это функциональность продукта, независимо от того, уделяете вы ей внимание или нет". Если вы не определите критерии надежности явно, ваши клиенты сделают свои неявные предположения.
Надежность можно рассматривать как фичу и для внутренних, и для внешних стейкхолдеров, что вполне логично. При планировании работ стоит явно учитывать надежность. В технологическом радаре Thoughtworks (том 25) за октябрь 2021 года на эту тему есть рекомендации — даже внутренние команды должны думать о себе как о продуктовых командах. Также там есть рекомендация использовать для организации внутренних команд концепции из популярной книги Team Topologies (Топологии команд). Многие организации взяли на вооружение концепцию "PST" Саймона Уордли (Simon Wardley) — Pioneer-Settler-Town Planner (первопроходец (пионер) — поселенец (постоянный житель) — градостроитель).
Давайте посмотрим, как можно применить эти две идеи (надежность как фича продукта и наличие определенного профиля команды) для повышения эффективности SRE.
Стоит отметить, что не существует универсального подхода для повышения надежности: на разных стадиях проекта будут полезны различные SRE-практики. Я выделяю три уровня зрелости продуктов / сервисов: начальный (beginning), роста (growing) и устоявшийся (established).
Далее с помощью PST-фреймворка опишем наиболее эффективные SRE-активности на данном уровне зрелости.
Рисунок ниже поясняет три вида ролей/активностей в рамках PST.
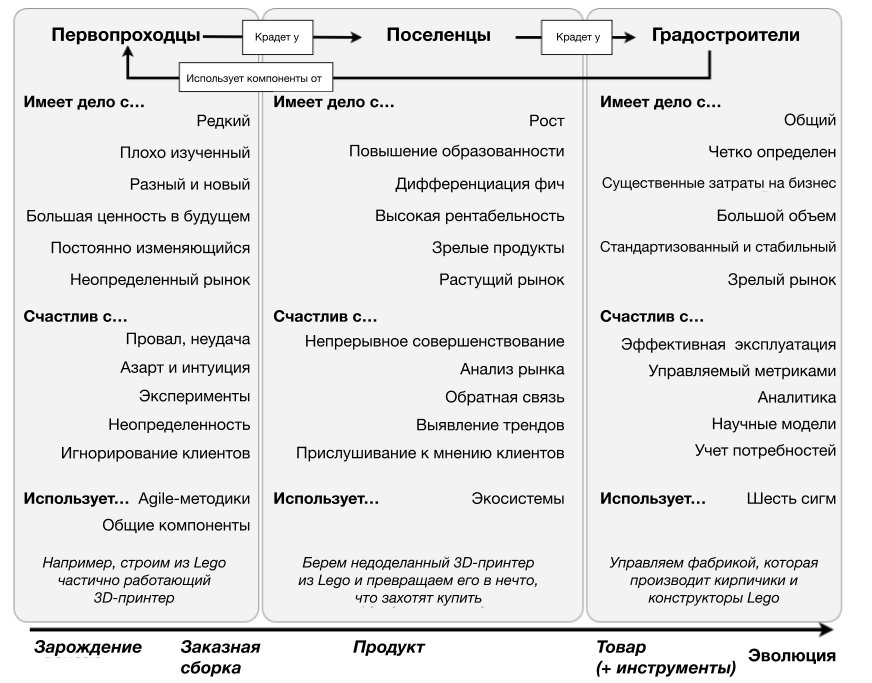
Профили команд, из поста Pioneers, Settlers and Town Planners Саймона Уордли.
Начальный этап (SRE-первопроходцы)
В новых проектах часто возникают неопределенность и вопросы без ответов. Небольшие изменения в направлении могут принести в будущем большую пользу, но и работа по проработке несостоявшихся идей может быть просто выброшена. Здесь SRE помогает в создании прототипов, быстром выявлении нежизнеспособных гипотез и в поиске гибких решений, уделяя при этом первостепенное внимание надежности.
Случалось ли вам подходить к завершению проекта, когда надежность и процессы эксплуатации не продуманы? "SRE-пионеры" могут помочь. Они должны быть частью команды, которая занимается разработкой нового продукта: оценивать готовые решения, создавать прототипы и влиять на архитектуру. На этом этапе необходимо спланировать всю работу по устранению брешей в надежности, или даже изменить направление, если стало ясно, что выбран неправильный путь.
Встраивание SRE в команду разработки — отличный способ для SRE участвовать в повышении надежности на ранних этапах. Если разработчики только время от времени консультируются по вопросам надежности или эксплуатации, часто конечный результат не отражает ожидания заказчиков и инженеров в отношении надежности продукта или работоспособности внутренних компонент.
Успех SRE-пионеров можно оценить по количеству новых продуктов или фич в дорожной карте, по скорости внедрения готовых решений и по скорости перехода проекта от "исследования" к "конкретным предложениям". Самый большой риск на этом этапе заключается в том, что SRE-команда в итоге окажется владельцем надежности системы, поскольку она участвовала в проектировании. Проектирование надежности силами SRE-команды в отрыве от других разработчиков обычно превращается в ситуацию, когда SRE-команду начинают рассматривать как команду эксплуатации для решения любых проблем с продуктом / сервисом. SRE в команде разработки — это средство обучения всей команды, а не увеличение их численности.
Этап роста (SRE-поселенцы)
На этом этапе проекта обычно создают инфраструктуру, пригодную для промышленной эксплуатации, занимаются передачей продукта заказчику и масштабированием до требуемой нагрузки. SRE могут помочь в создании зрелых и масштабируемых решений на основе первоначальных прототипов. Они также могут повысить уровень инженерной культуры в части подготовки к новым нагрузкам в промышленной эксплуатации, используя лучшие практики, такие как автоматизация рутинных операций или выбор правильных SLO.
Дальнейшее внедрение в команды — отличный способ для SRE участвовать в надежности уже запущенного продукта или фичи, особенно если SRE участвуют в обсуждении наблюдаемости, масштабируемости и безопасности. Консультирование команд по вопросам готовности к релизу, особенно для новых команд и сервисов, — еще один способ, с помощью которого SRE может гарантировать, что решение в продакшене, будет соответствовать первоначальным требованиям надежности, а также лучшим практикам эксплуатации (например, автоматизация миграций баз данных).
На этом этапе SRE контролируют готовность к релизу, что особенно важно при масштабировании продукта или организации. Это обеспечивает последовательный подход к надежности продуктов и сервисов, а также задает минимальную планку надежности, которая должна быть соблюдена. Здесь SRE даже могут встроить автоматизацию в пайплайн для гарантирования возможностей минимального масштабирования и устойчивости к конкретным сбоям.
Результативность SRE-поселенцев можно измерить по количеству новых релизов и фич, а также по степени наблюдаемости (эффективное логирование, сбор метрик и мониторинг). Этот этап также связан с выявлением паттернов, например, разработка шаблонов предложений (proposal templates). Ретроспектива проекта — отличный способ поиска паттернов и повышения вовлеченности SRE в проект.
Устоявшийся этап (SRE-градостроители)
На этом наиболее зрелом этапе продукты или сервисы обычно уже общедоступны и на надежность может влиять архитектура в целом и инструменты разработки.
Здесь SRE влияют на надежность, выявляя и работая над решением системных проблем надежности (например, повторяющиеся инциденты, неправильный выбор SLO, отсутствие дежурств и т. д.). Непрерывное совершенствование — один из распространенных способов, с помощью которого SRE влияют на надежность на данном этапе.
SRE-команда также может помочь с уменьшением рутинных операций при эксплуатации и масштабировании как через автоматизацию и изменение архитектуры, так и с помощью организационных изменений, знаний, навыков, инструментов и методик, необходимых для успеха крупномасштабных проектов.
На этом этапе некоторые SRE могут почувствовать стагнацию, связанную с уменьшением технической работы, но влияние этой работы невозможно переоценить — именно здесь SRE может стать настоящим мультипликатором по мере появления новых команд и продуктов/сервисов. В качестве примера можно привести внедрение систем управления инцидентами, SLA, планирование аварийного восстановления (Disaster Recovery) и непрерывности бизнеса (Business Continuity), а также хаос-инжиниринг (Chaos engineering). Решение этой проблемы заключается в работе SRE совместно с программным менеджером (TPM — Technical Program Manager). SRE занимается техническими аспектами, а TPM — организационными, необходимыми для улучшения процесса или запуска программ.
Успешность SRE-градостроителей измерить непросто. Можно анализировать простые метрики, такие как уменьшение количества инцидентов, сокращение продолжительности инцидентов, улучшение показателей SLO или количества DR-тестов, но сложно выделить среди них влияние SRE. Для оценки SRE-команды на этом этапе часто используется обратная связь от внутренних клиентов. Наиболее эффективные SRE, как правило, приводят к сдвигу парадигмы в командах разработки, а часто в своей SRE-команде.
Заключение
[PST] — это о том, как вы берете высокоэффективную компанию и подталкиваете ее [...] к непрерывно саморегулирующейся системе. 8 мая 2020 @swardley
Я надеюсь, что приведенная выше классификация будет вам полезна при организации работ по повышению надежности на различных уровнях зрелости продукта. Надежность как фича продукта — это не серебряная пуля для решения проблем, когда организация не понимает своего места на рынке и ценности, которую она приносит, а также при нездоровых практиках управления продуктом без понимания процессов разработки и управления поставкой продукта и его фичами.
Как уже упоминалось ранее, нет универсального подхода для обеспечения надежности. Возможно, вам по-прежнему потребуется применить некоторые из таких практик как "Ограничить рутинные операции 50% работы" или "Для каждой фичи продукта, вводимой в эксплуатацию, должно быть ревью с точки зрения надежности". Предложенная выше классификация, в сочетании с этими эмпирическими правилами, должна помочь сфокусировать ваши команды на достижение максимальной надежности ваших продуктов и сервисов.
При подготовке этой статьи было интересно проанализировать как различные организации "делают SRE". Их общая черта — непрерывное совершенствование. Также стоит обратить внимание на огромное количество материала о том, как SRE может эффективно сотрудничать с другими командами (например, встраивание (embedding) SRE). Недостаточное общение между командами может поставить под угрозу все ваши усилия.
Я прошу вас поделиться своим опытом, как положительным, так и отрицательным, в части рассмотрения надежности как основной функциональности продукта. Хочу выразить особую благодарность моей SRE-команде за многочисленные обсуждения и дискуссии о том, как нам лучше всего организовать работу по повышению надежности.
Материал подготовлен в рамках курса «SRE практики и инструменты».
Всех желающих приглашаем на бесплатное demo-занятие «Три слова на три буквы: SLA, SLO, SLI». На занятии мы:
— Обсудим, как SRE оценивает риски, управляет ими и использует лимит времени недоступности сервиса для того, чтобы объективно принимать решения.
— SLI, SLA, SLO — фундаментальные понятия для SRE. Рассмотрим каждый из этих понятий и определим показатели для сервиса. Записывайтесь, если интересно.
")


