
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Проснись… ты всегда ощущал, что мир не в порядке. Странная мысль, но ее не отогнать – она как заноза в мозгу. Ты всю жизнь живешь в темнице ограничений и правил, навязанных всесильным Майкрософтом, и даже не осознаешь этого.
Нажмешь дизлайк и сказке конец – ты закроешь вкладку и продолжишь бесцельно бродить по рекомендациям Хабра и YouTube.
Захочешь продолжить и войдешь в страну чудес – я покажу тебе насколько глубока… невозможная… кроличья нора успешной разработки на SQL Server Express Edition.

Порой с некой душевной добротой я вспоминаю ранние годы своей карьеры… когда трава была зеленее после свежей покраски… когда руководство компании ложило первопричину на многие лицензионные условности… но время быстро меняется и приходится соблюдать правила рынка, если хочется быть частью крупного бизнеса.
Обратной стороной этой медали приходит горькое осознание главной истины капитализма – весь бизнес постепенно вынуждают мигрировать в облачные дата-центры либо платить за дорогие лицензии. Но что если есть иной путь – когда не нужно платить за лицензии, но при этом свободно пользоваться всеми важными плюшками коммерческих редакций SQL Server.
И речь сейчас идет даже не о Developer Edition, которую Майкрософт еще в 2014 году сделала полностью бесплатной, хотя раньше охотно отдавала в одни руки по 59.95$. Больше интересна оптимизация затрат для продакшен серверов, когда клиенты, в условиях кризиса, просят по максимуму сократить издержки их бизнеса на оборудование.
Безусловно, уже сейчас можно собирать чемоданы и мигрировать логику на бесплатные аналоги, вроде PostgreSQL или MariaDB. Но сразу возникает риторический вопрос – кто будет это переписывать и тестировать в условиях, когда всем все нужно «на вчера»? И даже если волевым решением попробовать быстро мигрировать ентерпрайз проект, то больше вероятность по итогу успешно сыграть в любимый шутер Курта Кобейна, чем отрелизиться. Потому мы просто подумаем, как из Express Edition выжать максимум в рамках текущих технических ограничений.
Предварительный диагноз для SQL Server Express Edition, вынесенный коллегией врачей: пациенту можно использовать не более 4-х логических ядер в рамках одного сокета, чуть больше 1Гб памяти выделяется под Buffer Pool, размер файла данных не может превышать 10Гб… спасибо, на добром слове, что пациент хоть под себя не ходит, а остальное как-то вылечим.
Как не парадоксально, но первое с чего нужно начать – это узнать версию нашего сиквела. И все дело в том, что при анонсе SQL Server 2016 SP1 в далеком 2018-ом году, Майкрософт продемонстрировала чудеса щедрости и частично уравняла по функционалу все редакции в рамках своей новой инициативы – consistent programmability surface area (CPSA).
Если раньше приходилось писать код с прицелом под конкретную редакцию, то при обновлении на 2016 SP1 (и более поздние версии) многие архитектурные возможности Enterprise стали доступны для использования, в том числе и для Express Edition. Среди новых возможностей Express Edition можно выделить следующее: поддержка секционирования таблиц и индексов, создание Column-store и In-Memory таблиц, а также возможность сжатия данных. Это тот редкий случай, когда обновление от мелкомягких стоит того, чтобы его установить.
Достаточно ли этого чтобы использовать Express Edition для продакшен нагрузки?
Чтобы ответить на этот вопрос попробуем рассмотреть несколько сценариев.
Протестируем однопоточную нагрузку разных типов таблиц для вставки/обновления/удаления 200.000 строк:
По итогу выполнения мы получим следующие значения:
Один из наихудших результатов у нас показывает таблица на основе кластерного индекса (T1_CL). Если посмотреть статистику ожиданий в рамках выполнения первой таблицы:
то мы заметим, что наибольшая задержка наблюдается в рамках WRITELOG:
Откроем энциклопедию ожиданий за авторством Paul Randal и найдем там WRITELOG попутно сверяясь с MSDN:
This is the log management system waiting for a log flush to disk. It commonly indicates that the I/O subsystem can’t keep up with the log flush volume, but on very high-volume systems it could also be caused by internal log flush limits, that may mean you have to split your workload over multiple databases or even make your transactions a little longer to reduce log flushes. To be sure it’s the I/O subsystem, use the DMV sys.dm_io_virtual_file_stats to examine the I/O latency for the log file and see if it correlates to the average WRITELOG time. If WRITELOG is longer, you’ve got internal contention and need to shard. If not, investigate why you’re creating so much transaction log.
Наш случай весьма очевидный и в качестве решения проблемы с ожиданиями WRITELOG можно было бы вставлять данные не построчно, а группами строк за раз. Но у нас же сугубо академический интерес касательно оптимизации нагрузки, приведенной выше, поэтому стоило бы разобраться, как происходит модификация данных в SQL Server?
Предположим, мы выполняем модификацию строки. SQL Server вызывает компонент Storage Engine, тот, в свою очередь, обращяется к Buffer Manager (который работает с буферами в памяти и диском) и говорит, что я хочу изменить данные. После этого Buffer Manager обращается к Buffer Pool и модифицирует нужные страницы в памяти (если этих страниц нет, то он их подгрузит с диска, а мы попутно получим ожидания PAGEIOLATCH_*). В момент, когда страница в памяти изменилась, SQL Server еще не может сказать, что запрос выполнен. Иначе бы нарушался один из принципов ACID (Durability), когда в конце модификации гарантируется, что все данные будут записаны на диск.
После модификации страницы в памяти Storage Engine вызывает Log Manager, который записывает данные в файл лога. Но делает он это не сразу, а через Log Buffer, который имеет размер 60Кб (есть нюансы, но мы их тут пропустим) и используется для оптимизации производительности при работе с файлом лога. Сброс данных из буфера в файл лога происходит в ситуациях когда: буфер заполнился, мы вручную выполнили sp_flush_log или когда произошел коммит транзакции и все из Log Buffer записалось в файл лога. Когда данные были сохранены в файле лога, то идет подтверждение, что модификация данных произошла успешно и извещает об этом клиент.
Согласно этой логике можно заметить, что данные не попадают сразу в файл данных. Для оптимизации работы с дисковой подсистемой SQL Server использует асинхронный механизм для записи в файлы данных. Всего таких механизмов два: Lazy Writer (запускается на периодической основе, проверяет достаточно ли памяти для SQL Server, если наблюдается memory pressure, то страницы из памяти вытесняются и записываются в файл данных, а те которые были изменены он сбрасывает на диск и выкидывает из памяти) и Checkpoint (примерно раз в минуту сканирует грязные страницы, сбрасывает их на диск и оставляет в памяти).
Когда в системе происходит куча мелких транзакций (скажем если данные модифицируют построчно), то после каждого коммита данные уходят из Log Buffer в транзакционный лог. Помним, что в файл лога все изменения попадают синхронно и другим транзакциям приходится ждать своей очереди – это является сдерживающим фактором для построения высокопроизводительных систем.
Тогда какая альтернатива решения этой проблемы?
В SQL Server 2014 появилась возможность создавать In-Memory таблицы, которые, как декларировалось разработчиками, позволяют существенно ускорить OLTP нагрузку за счет нового движка Hekaton. Но если вы посмотрите на пример выше (T2_MEM), то однопоточная производительность In-Memory там даже хуже, чем у традиционных таблиц с кластерным индексом (T1_CL) – это происходит за счет XTP_PREEMPTIVE_TASK процессов, которые в фоне коммитят укрупненные изменения In-Memory таблиц в файл лога (и делают это не сильно хорошо, как показывает практика).
По факту весь смысл In-Memory в улучшенном механизме конкурентного доступа и снижении блокировок при модификации данных. В таких сценария их применение действительно приводит к потрясающим результатам, но для банального CRUD их применять не стоит.
Аналогичную ситуацию мы видим на дальнейших попытках ускорить работу In-Memory таблиц, накручивая поверх них Native Compile хранимые процедуры (T3_MEM_NC), которые отлично оптимизируют производительность в случае каких-то расчетов и итерационной обработки данных в них, но как обертка для CRUD операций проявляют себя посредственно и лишь снижают нагрузку на свой фактический вызов.
Вообще к In-Memory таблицам и Native Compile хранимкам у меня давняя нелюбовь – уж больно много было багов в SQL Server 2014/2016 связанных с ними. Часть вещей исправили, часть улучшили, но все равно использовать эту технологию нужно очень аккуратно. Например, после создания In-Memory файловой группы ее нельзя просто так взять и удалить без пересоздания целевой базы. И все бы ничего, но иногда эта файловая группа может разрастаться в несколько гигабайт даже если вы просто обновляете пару строк в In-Memory таблице… и если речь идет о продакшене, то я бы не стал использовать эту технологию в рамках основных баз.
Другое дело включить опцию Delayed Durability, которая позволяет не сбрасывать данные в файл лога сразу при коммите транзакции, а ждать пока накопится 60Кб изменений. Сделать это можно сделать форсированно на уровне всех транзакций выбранной базы данных:
или в рамках отдельных операций:
Преимущество от использования этой опции наглядно показано на примере T4_CL_DD (выигрыш в скорости в 2,5 раза по сравнению с T1_CL). Есть, конечно, и минусы от этой включения опции, когда при удачном стечении обстоятельств (в случае сбоя системы или отключения света) можно потерять примерно 60Кб данных.
Думаю, что тут не стоит навязывать своего мнения, ведь в каждой ситуации нужно взвесить все за и против, но от себя добавлю, что включение Delayed Durability меня спасало не один раз, когда требовалось срочно разгрузить дисковую подсистему при OLTP нагрузке.
И вот мы пришли к самому интересному – как максимально ускорить OLTP операции? Ответ кроется в правильном использовании In-Memory таблиц. До этого я их изрядно критиковал, но все проблемы с производительностью относятся лишь к таблицам, созданным как SCHEMA_AND_DATA (когда данные хранятся и в оперативной памяти, и на диске). Но если создать In-Memory таблицу с опцией SCHEMA_ONLY, то данные будут храниться только в ОЗУ… как минус – при перезагрузке сиквела данные в таких таблицах будут теряться. Плюс же – это возможность ускорить операции модификации данных в 4 раза по сравнению с обычными таблицами (T8_MEM_SO/T8_MEM_SO_NC).
Мой рабочий кейс – создается промежуточная база, в рамках которой есть In-Memory SCHEMA_ONLY таблица (все операции над ней оборачиваем в Native Compile процедуры), записи непрерывно в нее льются с максимальной скоростью, а отдельным потоком мы их переносим более большими порциями в основную базу для постоянного хранения. Кроме того, In-Memory таблицы с SCHEMA_ONLY отлично подходят для ETL загрузки в виде промежуточного буфера, поскольку не оказывают никакой нагрузки на дисковую подсистему.
Теперь перейдем к DW нагрузке, которой характерны аналитические запросы с выгребанием объёмных кусков информации.
Для этого создадим несколько таблиц с разными вариантами сжатия и поэкспериментируем с ними:
Первое, на что нужно обратить внимание, – это итоговый размер таблиц:
За счет возможности применения на Express Edition сжатия и Column-store индексов появилось куча вариантов, когда можно без существенной потери производительности хранить больше информации в рамках разрешенных 10Гб для файла данных:
Если заводить разговор о компрессии данных, то ROW сжатие усекает без потерь значение до минимально возможного фиксированного типа, PAGE – поверх ROW еще дополнительно сжимает данные в бинарном виде на уровне страницы. В таком виде страницы хранятся как на диске, так и в Buffer Pool-е и лишь в момент непосредственного доступа к данным происходит декомпрессия на лету.
Несомненный плюс от использования сжатия проявляется в снижении операций чтения с диска и меньшем объёме Buffer Pool задействованного под хранения данных – это особенно актуально если у нас медленный диск, мало оперативной памяти и относительно незагруженный процессор. Обратная сторона медали от применения сжатия – это лишняя нагрузка на процессор, но не такая критичная, чтобы вообще игнорировать «как прокаженного» данный функционал любезно предоставленный Майкрософт.
Очень интересно выглядит использования Column-store индексов, которые позволяют существенно сжимать данные и увеличивать производительность аналитических запросов. Давайте кратко рассмотрим, как они работают… поскольку это колоночная модель хранения информации, то данные в таблице разбиваются RowGroup размером примерно в миллион строк (итоговое количество может отличаться от того, как данные вставлялись в таблицу), далее в рамках RowGroup каждый из столбцов представляется в виде сегмента которые сжимается в LOB объект со своей метаинформацией (например, хранит в себе минимальное и максимальное значение в рамках сжатой последовательности).
В отличии от PAGE/ROW сжатия, Column-store индексы используют различные варианты компрессии в зависимости от типа данных целевого столбца – это может быть усечение значения (Value Scale), сжатие на основе словаря, битовые преобразования (Bit-Array Packing) и различные другие варианты (Run Length, Huffman Encoding, Binary Compression, LZ77). Как итог мы имеем возможность более оптимально сжимать каждый из столбцов.
Посмотреть, как сжаты те или иные RowGroup можно этим запросом:
Отметим небольшой нюанс, который может сильно повлиять на производительность использования Column-store индексов применительно к Express Edition. Поскольку сегменты и словари (на основе которых происходит декомпрессия) хранятся в разных структурах на диске, то крайне важно чтобы размер всех наших словарей умещался в памяти (для этого на Express Edition отводится не более 350 метров):
При этом сегменты могут подгружаться с диска по мере необходимости и практически не влияют на нагрузку процессора:
Обратите внимание чем меньше уникальных записей в рамках сегмента RowGroup-ы, то тем меньше будет размер словаря. Секционирование Column-store и вставка данных в нужную секцию вместе с хинтом TABLOCK позволит по итогу получать более маленькие локальные словари, а значит это снизит накладные расходы на использование колоночных индексов. Вообще-то самый простой способ оптимизации словарей заключается в самих данных – чем меньше уникальных данных в рамках столбца, тем лучше (это можно увидеть на примере DATETIME).
За счет колоночной модели вычитываться будут только те столбцы, которые мы запрашиваем, а дополнительные фильтры могут ограничивать вычитку RowGroup за счет упомянутой выше метаинформации. По итогу получается некий аналог псевдо-индекса, который есть одновременно на всех колонках, а это дает нам возможность очень быстро агрегировать и фильтровать… опять же со своими нюансами.
Рассмотрим несколько примеров, чтобы показать преимущества колоночных индексов:
Как говориться почувствуй разницу:
По при фильтрации могут вылазить не сильно хорошие нюансы:
И все дело в том, что для определенных типов данных (NUMERIC, DATETIMEOFFSET, [N]CHAR, [N]VARCHAR, VARBINARY, UNIQUEIDENTIFIER, XML) не поддерживается Row Group Elimination:
В части ситуаций есть откровенные недоработки оптимизатора, которые до боли напоминают старый баг в SQL Server 2008R2 (когда пред агрегация работает быстрее, чем агрегация, написанная более компактно):
И таких моментов, по правде, куча и маленькая тележка:
Рассмотреть их все не получится в рамках данной статьи, но многое о чем нужно знать прекрасно приводится в видео за авторством Дмитрия Пилюгина. Кроме того есть отличный блог посвященный Column-store индексам. Крайне рекомендую данные ресурсы для более глубокого погружения в тему колоночных индексов!
Если с функциональными возможностями все более-менее понятно и, надеюсь, я смог убедить на примерах выше, что зачастую они не является сдерживающим фактором для полноценной разработки под ExpressEdition. Но как быть с ресурсными ограничениями… я бы сказал каждый конкретный случай решается индивидуально.
Express Edition разрешено использовать всего 4 ядра на инстанс, но что нам мешает развернуть в рамках сервера (например, на котором 16 ядер) несколько инстансов, за каждым из них закрепить свои физические ядра и получить дешевый аналог масштабируемой системы особенно в случае микросерверной архитектуры – когда каждый сервис работает со своим экземпляром базы.
Не хватает Buffer Pool размером в один гигабайт? Возможно, стоит свести физические чтения к минимуму за счет оптимизации запросов и внедрения секционирования, колоночных индексов или банально сжать данные в таблицах. Если это не представляется возможным, то мигрировать на более быстрые дисковые массивы.
Но как быть с предельным размером файла данных, который не может превышать 10Гб и при попытке его увеличить, свыше указанной величины, мы ожидаемо получим ошибку:
Есть несколько вариантов обойти данную проблему.
Мы можем создать несколько баз данных, в которых будет размещаться своя порция исторических данных. Для каждой из таких таблиц мы зададим ограничение и далее объединим все эти таблицы в рамках одного представления. Так мы по итогу получим вертикальное шардирование в рамках одного инстанса.
При фильтрации в рамках поля, на котором задано ограничение, мы будем вычитывать только нужные нам данные:
что можно увидеть на плане выполнения или в статистике:
Кроме того, за счет ограничений нам разрешается прозрачно модифицировать данные в рамках представления:
Применяя подобный подход мы сможем частично решить проблему, но все равно каждая отдельная база будет ограничена заветными 10Гб.
Еще один вариант специально придуман для любителей архитектурных извращений – поскольку ограничение на размер файла данных не распространяется на системные базы данных (master, msdb, modelи tempdb), то всю разработку можно вести в них. Но чаще всего подобная практика использования системных баз данных в качестве пользовательских – это выстрел в себе ногу из рокетлаунчера. Потому даже не буду расписывать все подводные камни такого решения, но если все же сильно хочется – это точно гарантирует вам быструю прокачку матерного лексикона до уровня прораба с 30-ти летним опытом.
Теперь перейдем к рабочему решению проблемы.
Создаем базу данных нужного нам размера на Developer Edition и делаем детач:
Создаем базу с таким же именем на Express Edition и после останавливаем сервис:
Перемещаем файлы нашей базы c Developer Edition, на то место, где лежит такая же база на Express Edition, заменяя одни файлы другими. Запускаем экземпляр SQL Server Express Edition.
Проверяем размер наших баз данных:
Вуаля! Теперь размер файла данных превышает ограничение и при этом база полностью работоспособна:
Можно, как и прежде, делать шринк, резервные копии или менять настройки этой базы. Сложности возникнут только в случаях, если вам нужно будет восстановить базу из резервной копии или еще раз увеличить размер файла данных. В таких ситуациях, мы сможем восстановить резервную копию на Developer Edition, увеличить размер до требуемого и далее подменить файлы как было описано выше.
Как итог, SQL Server Express Edition очень часто незаслуженно обходят стороной, прикрываясь ресурсными ограничениям и еще котомкой других отговорок. Главный посыл статьи – это то, что спроектировать высокопроизводительную систему можно на любой редакции SQL Server.
Всем спасибо за внимание!
Подписывайтесь на инстаграм в рамках которого планируется делать анонсы будущих мероприятий в Харькове.
Кроме того, возникла идея по-местному под кофеек всех желающих подучить SQL Server и пообсуждать треш связанный с разработкой. Если такие мысли возникнут, то стучите на почту.
Нажмешь дизлайк и сказке конец – ты закроешь вкладку и продолжишь бесцельно бродить по рекомендациям Хабра и YouTube.
Захочешь продолжить и войдешь в страну чудес – я покажу тебе насколько глубока… невозможная… кроличья нора успешной разработки на SQL Server Express Edition.
Порой с некой душевной добротой я вспоминаю ранние годы своей карьеры… когда трава была зеленее после свежей покраски… когда руководство компании ложило первопричину на многие лицензионные условности… но время быстро меняется и приходится соблюдать правила рынка, если хочется быть частью крупного бизнеса.
Обратной стороной этой медали приходит горькое осознание главной истины капитализма – весь бизнес постепенно вынуждают мигрировать в облачные дата-центры либо платить за дорогие лицензии. Но что если есть иной путь – когда не нужно платить за лицензии, но при этом свободно пользоваться всеми важными плюшками коммерческих редакций SQL Server.
И речь сейчас идет даже не о Developer Edition, которую Майкрософт еще в 2014 году сделала полностью бесплатной, хотя раньше охотно отдавала в одни руки по 59.95$. Больше интересна оптимизация затрат для продакшен серверов, когда клиенты, в условиях кризиса, просят по максимуму сократить издержки их бизнеса на оборудование.
Безусловно, уже сейчас можно собирать чемоданы и мигрировать логику на бесплатные аналоги, вроде PostgreSQL или MariaDB. Но сразу возникает риторический вопрос – кто будет это переписывать и тестировать в условиях, когда всем все нужно «на вчера»? И даже если волевым решением попробовать быстро мигрировать ентерпрайз проект, то больше вероятность по итогу успешно сыграть в любимый шутер Курта Кобейна, чем отрелизиться. Потому мы просто подумаем, как из Express Edition выжать максимум в рамках текущих технических ограничений.
Предварительный диагноз для SQL Server Express Edition, вынесенный коллегией врачей: пациенту можно использовать не более 4-х логических ядер в рамках одного сокета, чуть больше 1Гб памяти выделяется под Buffer Pool, размер файла данных не может превышать 10Гб… спасибо, на добром слове, что пациент хоть под себя не ходит, а остальное как-то вылечим.
Как не парадоксально, но первое с чего нужно начать – это узнать версию нашего сиквела. И все дело в том, что при анонсе SQL Server 2016 SP1 в далеком 2018-ом году, Майкрософт продемонстрировала чудеса щедрости и частично уравняла по функционалу все редакции в рамках своей новой инициативы – consistent programmability surface area (CPSA).
Если раньше приходилось писать код с прицелом под конкретную редакцию, то при обновлении на 2016 SP1 (и более поздние версии) многие архитектурные возможности Enterprise стали доступны для использования, в том числе и для Express Edition. Среди новых возможностей Express Edition можно выделить следующее: поддержка секционирования таблиц и индексов, создание Column-store и In-Memory таблиц, а также возможность сжатия данных. Это тот редкий случай, когда обновление от мелкомягких стоит того, чтобы его установить.
Достаточно ли этого чтобы использовать Express Edition для продакшен нагрузки?
Чтобы ответить на этот вопрос попробуем рассмотреть несколько сценариев.
Протестируем однопоточную нагрузку разных типов таблиц для вставки/обновления/удаления 200.000 строк:
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
ON PRIMARY (NAME = N'express', FILENAME = N'X:\express.mdf', SIZE = 200 MB, FILEGROWTH = 100 MB)
LOG ON (NAME = N'express_log', FILENAME = N'X:\express_log.ldf', SIZE = 200 MB, FILEGROWTH = 100 MB)
ALTER DATABASE [express] SET AUTO_CLOSE OFF
ALTER DATABASE [express] SET RECOVERY SIMPLE
ALTER DATABASE [express] SET MULTI_USER
ALTER DATABASE [express] SET DELAYED_DURABILITY = ALLOWED
ALTER DATABASE [express] ADD FILEGROUP [MEM] CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE [express] ADD FILE (NAME = 'MEM', FILENAME = 'X:\MEM') TO FILEGROUP [MEM]
ALTER DATABASE [express] SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON
GO
USE [express]
GO
CREATE TABLE [T1_CL] (A INT PRIMARY KEY, B DATETIME INDEX IX1 NONCLUSTERED)
GO
CREATE TABLE [T2_MEM] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T3_MEM_NC] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
CREATE TABLE [T4_CL_DD] (A INT PRIMARY KEY, B DATETIME INDEX IX1 NONCLUSTERED)
GO
CREATE TABLE [T5_MEM_DD] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T6_MEM_NC_DD] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T7_MEM_SO] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GO
CREATE TABLE [T8_MEM_SO_NC] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GO
CREATE PROCEDURE [T3_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T3_MEM_NC] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T3_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T3_MEM_NC] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T3_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T3_MEM_NC] WHERE A = @i
END
GO
CREATE PROCEDURE [T6_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T6_MEM_NC_DD] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T6_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T6_MEM_NC_DD] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T6_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T6_MEM_NC_DD] WHERE A = @i
END
GO
CREATE PROCEDURE [T8_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T8_MEM_SO_NC] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T8_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T8_MEM_SO_NC] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T8_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T8_MEM_SO_NC] WHERE A = @i
END
GO
DECLARE @i INT
, @s DATETIME
, @runs INT = 200000
DROP TABLE IF EXISTS #stats
CREATE TABLE #stats (obj VARCHAR(100), op VARCHAR(100), time_ms BIGINT)
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T1_CL] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T1_CL] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T1_CL] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T2_MEM] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T2_MEM] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T2_MEM] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_I] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_U] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_D] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
INSERT INTO [T4_CL_DD] VALUES (@i, GETDATE())
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
UPDATE [T4_CL_DD] SET B = GETDATE() WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
DELETE [T4_CL_DD] WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
INSERT INTO [T5_MEM_DD] VALUES (@i, GETDATE())
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
UPDATE [T5_MEM_DD] SET B = GETDATE() WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
DELETE [T5_MEM_DD] WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_I] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_U] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_D] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T7_MEM_SO] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T7_MEM_SO] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T7_MEM_SO] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_I] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_U] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_D] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'DELETE', DATEDIFF(ms, @s, GETDATE())
GO
SELECT obj
, [I] = MAX(CASE WHEN op = 'INSERT' THEN time_ms END)
, [U] = MAX(CASE WHEN op = 'UPDATE' THEN time_ms END)
, [D] = MAX(CASE WHEN op = 'DELETE' THEN time_ms END)
FROM #stats
GROUP BY obj
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
По итогу выполнения мы получим следующие значения:
I U D
--------------- ------- ------- ------- ---------------------------------------------------------------
T1_CL 12173 14434 12576 B-Tree Index
T2_MEM 14774 14593 13777 In-Memory SCHEMA_AND_DATA
T3_MEM_NC 11563 10560 10097 In-Memory SCHEMA_AND_DATA + Native Compile
T4_CL_DD 5176 7294 5303 B-Tree Index + Delayed Durability
T5_MEM_DD 7460 7163 6214 In-Memory SCHEMA_AND_DATA + Delayed Durability
T6_MEM_NC_DD 8386 7494 6973 In-Memory SCHEMA_AND_DATA + Native Compile + Delayed Durability
T7_MEM_SO 5667 5383 4473 In-Memory SCHEMA_ONLY + Native Compile
T8_MEM_SO_NC 3250 2430 2287 In-Memory SCHEMA_ONLY + Native Compile
Один из наихудших результатов у нас показывает таблица на основе кластерного индекса (T1_CL). Если посмотреть статистику ожиданий в рамках выполнения первой таблицы:
SELECT TOP(20) wait_type
, wait_time = CAST(wait_time_ms / 1000. AS DECIMAL(18,4))
, wait_resource = CAST((wait_time_ms - signal_wait_time_ms) / 1000. AS DECIMAL(18,4))
, wait_signal = CAST(signal_wait_time_ms / 1000. AS DECIMAL(18,4))
, wait_time_percent = CAST(100. * wait_time_ms / NULLIF(SUM(wait_time_ms) OVER (), 0) AS DECIMAL(18,2))
, waiting_tasks_count
FROM sys.dm_os_wait_stats
WHERE waiting_tasks_count > 0
AND wait_time_ms > 0
AND wait_type NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT'
)
ORDER BY wait_time_ms DESC
то мы заметим, что наибольшая задержка наблюдается в рамках WRITELOG:
wait_type wait_time wait_resource wait_signal wait_time_percent waiting_tasks_count -------------------------------- ---------- -------------- ------------ ------------------ -------------------- WRITELOG 13.5480 10.7500 2.7980 95.66 600048 MEMORY_ALLOCATION_EXT 0.5030 0.5030 0.0000 3.55 608695 PREEMPTIVE_OS_WRITEFILEGATHER 0.0250 0.0250 0.0000 0.18 3 ASYNC_IO_COMPLETION 0.0200 0.0200 0.0000 0.14 1 IO_COMPLETION 0.0200 0.0200 0.0000 0.14 8
Откроем энциклопедию ожиданий за авторством Paul Randal и найдем там WRITELOG попутно сверяясь с MSDN:
This is the log management system waiting for a log flush to disk. It commonly indicates that the I/O subsystem can’t keep up with the log flush volume, but on very high-volume systems it could also be caused by internal log flush limits, that may mean you have to split your workload over multiple databases or even make your transactions a little longer to reduce log flushes. To be sure it’s the I/O subsystem, use the DMV sys.dm_io_virtual_file_stats to examine the I/O latency for the log file and see if it correlates to the average WRITELOG time. If WRITELOG is longer, you’ve got internal contention and need to shard. If not, investigate why you’re creating so much transaction log.
Наш случай весьма очевидный и в качестве решения проблемы с ожиданиями WRITELOG можно было бы вставлять данные не построчно, а группами строк за раз. Но у нас же сугубо академический интерес касательно оптимизации нагрузки, приведенной выше, поэтому стоило бы разобраться, как происходит модификация данных в SQL Server?
Предположим, мы выполняем модификацию строки. SQL Server вызывает компонент Storage Engine, тот, в свою очередь, обращяется к Buffer Manager (который работает с буферами в памяти и диском) и говорит, что я хочу изменить данные. После этого Buffer Manager обращается к Buffer Pool и модифицирует нужные страницы в памяти (если этих страниц нет, то он их подгрузит с диска, а мы попутно получим ожидания PAGEIOLATCH_*). В момент, когда страница в памяти изменилась, SQL Server еще не может сказать, что запрос выполнен. Иначе бы нарушался один из принципов ACID (Durability), когда в конце модификации гарантируется, что все данные будут записаны на диск.
После модификации страницы в памяти Storage Engine вызывает Log Manager, который записывает данные в файл лога. Но делает он это не сразу, а через Log Buffer, который имеет размер 60Кб (есть нюансы, но мы их тут пропустим) и используется для оптимизации производительности при работе с файлом лога. Сброс данных из буфера в файл лога происходит в ситуациях когда: буфер заполнился, мы вручную выполнили sp_flush_log или когда произошел коммит транзакции и все из Log Buffer записалось в файл лога. Когда данные были сохранены в файле лога, то идет подтверждение, что модификация данных произошла успешно и извещает об этом клиент.
Согласно этой логике можно заметить, что данные не попадают сразу в файл данных. Для оптимизации работы с дисковой подсистемой SQL Server использует асинхронный механизм для записи в файлы данных. Всего таких механизмов два: Lazy Writer (запускается на периодической основе, проверяет достаточно ли памяти для SQL Server, если наблюдается memory pressure, то страницы из памяти вытесняются и записываются в файл данных, а те которые были изменены он сбрасывает на диск и выкидывает из памяти) и Checkpoint (примерно раз в минуту сканирует грязные страницы, сбрасывает их на диск и оставляет в памяти).
Когда в системе происходит куча мелких транзакций (скажем если данные модифицируют построчно), то после каждого коммита данные уходят из Log Buffer в транзакционный лог. Помним, что в файл лога все изменения попадают синхронно и другим транзакциям приходится ждать своей очереди – это является сдерживающим фактором для построения высокопроизводительных систем.
Тогда какая альтернатива решения этой проблемы?
В SQL Server 2014 появилась возможность создавать In-Memory таблицы, которые, как декларировалось разработчиками, позволяют существенно ускорить OLTP нагрузку за счет нового движка Hekaton. Но если вы посмотрите на пример выше (T2_MEM), то однопоточная производительность In-Memory там даже хуже, чем у традиционных таблиц с кластерным индексом (T1_CL) – это происходит за счет XTP_PREEMPTIVE_TASK процессов, которые в фоне коммитят укрупненные изменения In-Memory таблиц в файл лога (и делают это не сильно хорошо, как показывает практика).
По факту весь смысл In-Memory в улучшенном механизме конкурентного доступа и снижении блокировок при модификации данных. В таких сценария их применение действительно приводит к потрясающим результатам, но для банального CRUD их применять не стоит.
Аналогичную ситуацию мы видим на дальнейших попытках ускорить работу In-Memory таблиц, накручивая поверх них Native Compile хранимые процедуры (T3_MEM_NC), которые отлично оптимизируют производительность в случае каких-то расчетов и итерационной обработки данных в них, но как обертка для CRUD операций проявляют себя посредственно и лишь снижают нагрузку на свой фактический вызов.
Вообще к In-Memory таблицам и Native Compile хранимкам у меня давняя нелюбовь – уж больно много было багов в SQL Server 2014/2016 связанных с ними. Часть вещей исправили, часть улучшили, но все равно использовать эту технологию нужно очень аккуратно. Например, после создания In-Memory файловой группы ее нельзя просто так взять и удалить без пересоздания целевой базы. И все бы ничего, но иногда эта файловая группа может разрастаться в несколько гигабайт даже если вы просто обновляете пару строк в In-Memory таблице… и если речь идет о продакшене, то я бы не стал использовать эту технологию в рамках основных баз.
Другое дело включить опцию Delayed Durability, которая позволяет не сбрасывать данные в файл лога сразу при коммите транзакции, а ждать пока накопится 60Кб изменений. Сделать это можно сделать форсированно на уровне всех транзакций выбранной базы данных:
ALTER DATABASE TT SET DELAYED_DURABILITY = FORCED
или в рамках отдельных операций:
ALTER DATABASE TT SET DELAYED_DURABILITY = ALLOWED GO BEGIN TRANSACTION t ... COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
Преимущество от использования этой опции наглядно показано на примере T4_CL_DD (выигрыш в скорости в 2,5 раза по сравнению с T1_CL). Есть, конечно, и минусы от этой включения опции, когда при удачном стечении обстоятельств (в случае сбоя системы или отключения света) можно потерять примерно 60Кб данных.
Думаю, что тут не стоит навязывать своего мнения, ведь в каждой ситуации нужно взвесить все за и против, но от себя добавлю, что включение Delayed Durability меня спасало не один раз, когда требовалось срочно разгрузить дисковую подсистему при OLTP нагрузке.
И вот мы пришли к самому интересному – как максимально ускорить OLTP операции? Ответ кроется в правильном использовании In-Memory таблиц. До этого я их изрядно критиковал, но все проблемы с производительностью относятся лишь к таблицам, созданным как SCHEMA_AND_DATA (когда данные хранятся и в оперативной памяти, и на диске). Но если создать In-Memory таблицу с опцией SCHEMA_ONLY, то данные будут храниться только в ОЗУ… как минус – при перезагрузке сиквела данные в таких таблицах будут теряться. Плюс же – это возможность ускорить операции модификации данных в 4 раза по сравнению с обычными таблицами (T8_MEM_SO/T8_MEM_SO_NC).
Мой рабочий кейс – создается промежуточная база, в рамках которой есть In-Memory SCHEMA_ONLY таблица (все операции над ней оборачиваем в Native Compile процедуры), записи непрерывно в нее льются с максимальной скоростью, а отдельным потоком мы их переносим более большими порциями в основную базу для постоянного хранения. Кроме того, In-Memory таблицы с SCHEMA_ONLY отлично подходят для ETL загрузки в виде промежуточного буфера, поскольку не оказывают никакой нагрузки на дисковую подсистему.
Теперь перейдем к DW нагрузке, которой характерны аналитические запросы с выгребанием объёмных кусков информации.
Для этого создадим несколько таблиц с разными вариантами сжатия и поэкспериментируем с ними:
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
ON PRIMARY (NAME = N'express', FILENAME = N'X:\express.mdf', SIZE = 200 MB, FILEGROWTH = 100 MB)
LOG ON (NAME = N'express_log', FILENAME = N'X:\express_log.ldf', SIZE = 200 MB, FILEGROWTH = 100 MB)
ALTER DATABASE [express] SET AUTO_CLOSE OFF
ALTER DATABASE [express] SET RECOVERY SIMPLE
ALTER DATABASE [express] SET DELAYED_DURABILITY = FORCED
GO
USE [express]
GO
DROP TABLE IF EXISTS [T1_HEAP]
CREATE TABLE [T1_HEAP] (
[INT] INT NOT NULL
, [VARCHAR] VARCHAR(100) NOT NULL
, [DATETIME] DATETIME NOT NULL
)
GO
;WITH E1(N) AS (SELECT * FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) t(N))
, E2(N) AS (SELECT '1' FROM E1 a, E1 b)
, E4(N) AS (SELECT '1' FROM E2 a, E2 b)
, E8(N) AS (SELECT '1' FROM E4 a, E4 b)
INSERT INTO [T1_HEAP] WITH(TABLOCK) ([INT], [VARCHAR], [DATETIME])
SELECT TOP(5000000)
ROW_NUMBER() OVER (ORDER BY 1/0)
, CAST(ROW_NUMBER() OVER (ORDER BY 1/0) AS VARCHAR(100))
, DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY 1/0) % 100, '20180101')
FROM E8
GO
DROP TABLE IF EXISTS [T2_CL]
SELECT * INTO [T2_CL] FROM [T1_HEAP] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T2_CL] ([INT]) WITH (DATA_COMPRESSION = NONE)
INSERT INTO [T2_CL] WITH(TABLOCK)
SELECT * FROM [T1_HEAP]
GO
DROP TABLE IF EXISTS [T3_CL_ROW]
SELECT * INTO [T3_CL_ROW] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T3_CL_ROW] ([INT]) WITH (DATA_COMPRESSION = ROW)
INSERT INTO [T3_CL_ROW] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T4_CL_PAGE]
SELECT * INTO [T4_CL_PAGE] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T4_CL_PAGE] ([INT]) WITH (DATA_COMPRESSION = PAGE)
INSERT INTO [T4_CL_PAGE] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T5_CCI]
SELECT * INTO [T5_CCI] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED COLUMNSTORE INDEX IX ON [T5_CCI] WITH (DATA_COMPRESSION = COLUMNSTORE)
INSERT INTO [T5_CCI] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T6_CCI_ARCHIVE]
SELECT * INTO [T6_CCI_ARCHIVE] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED COLUMNSTORE INDEX IX ON [T6_CCI_ARCHIVE] WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
INSERT INTO [T6_CCI_ARCHIVE] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
Первое, на что нужно обратить внимание, – это итоговый размер таблиц:
SELECT o.[name]
, i.[rows]
, i.[type_desc]
, total_mb = CAST(i.total_pages * 8. / 1024 AS DECIMAL(18,2))
FROM sys.objects o
JOIN (
SELECT i.[object_id]
, a.[type_desc]
, total_pages = SUM(a.total_pages)
, [rows] = SUM(CASE WHEN i.index_id IN (0,1) THEN p.[rows] END)
FROM sys.indexes i
JOIN sys.partitions p ON i.[object_id] = p.[object_id] AND i.index_id = p.index_id
JOIN sys.allocation_units a ON p.[partition_id] = a.container_id
WHERE a.total_pages > 0
GROUP BY i.[object_id]
, a.[type_desc]
) i ON o.[object_id] = i.[object_id]
WHERE o.[type] = 'U'
За счет возможности применения на Express Edition сжатия и Column-store индексов появилось куча вариантов, когда можно без существенной потери производительности хранить больше информации в рамках разрешенных 10Гб для файла данных:
rows type_desc total_mb
--------------- -------- ------------ ---------
T1_HEAP 5000000 IN_ROW_DATA 153.38
T2_CL 5000000 IN_ROW_DATA 163.45
T3_CL_ROW 5000000 IN_ROW_DATA 110.13
T4_CL_PAGE 5000000 IN_ROW_DATA 72.63
T5_CCI 5000000 LOB_DATA 81.20
T6_CCI_ARCHIVE 5000000 LOB_DATA 41.13
Если заводить разговор о компрессии данных, то ROW сжатие усекает без потерь значение до минимально возможного фиксированного типа, PAGE – поверх ROW еще дополнительно сжимает данные в бинарном виде на уровне страницы. В таком виде страницы хранятся как на диске, так и в Buffer Pool-е и лишь в момент непосредственного доступа к данным происходит декомпрессия на лету.
Несомненный плюс от использования сжатия проявляется в снижении операций чтения с диска и меньшем объёме Buffer Pool задействованного под хранения данных – это особенно актуально если у нас медленный диск, мало оперативной памяти и относительно незагруженный процессор. Обратная сторона медали от применения сжатия – это лишняя нагрузка на процессор, но не такая критичная, чтобы вообще игнорировать «как прокаженного» данный функционал любезно предоставленный Майкрософт.
Очень интересно выглядит использования Column-store индексов, которые позволяют существенно сжимать данные и увеличивать производительность аналитических запросов. Давайте кратко рассмотрим, как они работают… поскольку это колоночная модель хранения информации, то данные в таблице разбиваются RowGroup размером примерно в миллион строк (итоговое количество может отличаться от того, как данные вставлялись в таблицу), далее в рамках RowGroup каждый из столбцов представляется в виде сегмента которые сжимается в LOB объект со своей метаинформацией (например, хранит в себе минимальное и максимальное значение в рамках сжатой последовательности).
В отличии от PAGE/ROW сжатия, Column-store индексы используют различные варианты компрессии в зависимости от типа данных целевого столбца – это может быть усечение значения (Value Scale), сжатие на основе словаря, битовые преобразования (Bit-Array Packing) и различные другие варианты (Run Length, Huffman Encoding, Binary Compression, LZ77). Как итог мы имеем возможность более оптимально сжимать каждый из столбцов.
Посмотреть, как сжаты те или иные RowGroup можно этим запросом:
SELECT o.[name]
, row_group_id
, state_description
, total_rows
, size_mb = CAST(size_in_bytes / (1024. * 1024) AS DECIMAL(18,2))
, total_mb = CAST(SUM(size_in_bytes) OVER (PARTITION BY i.[object_id]) / 8192 * 8. / 1024 AS DECIMAL(18,2))
FROM sys.indexes i
JOIN sys.objects o ON i.[object_id] = o.[object_id]
CROSS APPLY sys.fn_column_store_row_groups(i.[object_id]) s
WHERE i.[type] IN (5, 6)
AND i.[object_id] = OBJECT_ID('T5_CCI')
ORDER BY i.[object_id]
, s.row_group_id
row_group_id state_description total_rows deleted_rows size_mb total_mb ------------- ------------------ ----------- ------------- -------- --------- 0 COMPRESSED 593581 0 3.78 31.80 1 COMPRESSED 595539 0 3.79 31.80 2 COMPRESSED 595539 0 3.79 31.80 3 COMPRESSED 599030 0 3.81 31.80 4 COMPRESSED 595539 0 3.79 31.80 5 COMPRESSED 686243 0 4.37 31.80 6 COMPRESSED 595539 0 3.79 31.80 7 COMPRESSED 738990 0 4.70 31.80
Отметим небольшой нюанс, который может сильно повлиять на производительность использования Column-store индексов применительно к Express Edition. Поскольку сегменты и словари (на основе которых происходит декомпрессия) хранятся в разных структурах на диске, то крайне важно чтобы размер всех наших словарей умещался в памяти (для этого на Express Edition отводится не более 350 метров):
SELECT [column] = COL_NAME(p.[object_id], s.column_id)
, s.dictionary_id
, s.entry_count
, size_mb = CAST(s.on_disk_size / (1024. * 1024) AS DECIMAL(18,2))
, total_mb = CAST(SUM(s.on_disk_size) OVER () / 8192 * 8. / 1024 AS DECIMAL(18,2))
FROM sys.column_store_dictionaries s
JOIN sys.partitions p ON p.hobt_id = s.hobt_id
WHERE p.[object_id] = OBJECT_ID('T5_CCI')
column dictionary_id entry_count size_mb total_mb ---------- ------------- ------------ -------- ---------- VARCHAR 1 593581 6.39 53.68 VARCHAR 2 738990 7.98 53.68 VARCHAR 3 686243 7.38 53.68 VARCHAR 4 595539 6.37 53.68 VARCHAR 5 595539 6.39 53.68 VARCHAR 6 595539 6.38 53.68 VARCHAR 7 595539 6.39 53.68 VARCHAR 8 599030 6.40 53.68 DATETIME 1 100 0.00 53.68 DATETIME 2 100 0.00 53.68 DATETIME 3 100 0.00 53.68 DATETIME 4 100 0.00 53.68 DATETIME 5 100 0.00 53.68 DATETIME 6 100 0.00 53.68 DATETIME 7 100 0.00 53.68 DATETIME 8 100 0.00 53.68
При этом сегменты могут подгружаться с диска по мере необходимости и практически не влияют на нагрузку процессора:
SELECT [column] = COL_NAME(p.[object_id], s.column_id)
, s.segment_id
, s.row_count
, CAST(s.on_disk_size / (1024. * 1024) AS DECIMAL(18,2))
FROM sys.column_store_segments s
JOIN sys.partitions p ON p.hobt_id = s.hobt_id
WHERE p.[object_id] = OBJECT_ID('T5_CCI')
column segment_id row_count size_mb total_mb ---------- ----------- ----------- -------- --------- INT 0 593581 2.26 31.80 INT 1 595539 2.27 31.80 INT 2 595539 2.27 31.80 INT 3 599030 2.29 31.80 INT 4 595539 2.27 31.80 INT 5 686243 2.62 31.80 INT 6 595539 2.27 31.80 INT 7 738990 2.82 31.80 VARCHAR 0 593581 1.51 31.80 VARCHAR 1 595539 1.52 31.80 VARCHAR 2 595539 1.52 31.80 VARCHAR 3 599030 1.52 31.80 VARCHAR 4 595539 1.52 31.80 VARCHAR 5 686243 1.75 31.80 VARCHAR 6 595539 1.52 31.80 VARCHAR 7 738990 1.88 31.80 DATETIME 0 593581 0.01 31.80 DATETIME 1 595539 0.01 31.80 DATETIME 2 595539 0.01 31.80 DATETIME 3 599030 0.01 31.80 DATETIME 4 595539 0.01 31.80 DATETIME 5 686243 0.01 31.80 DATETIME 6 595539 0.01 31.80 DATETIME 7 738990 0.01 31.80
Обратите внимание чем меньше уникальных записей в рамках сегмента RowGroup-ы, то тем меньше будет размер словаря. Секционирование Column-store и вставка данных в нужную секцию вместе с хинтом TABLOCK позволит по итогу получать более маленькие локальные словари, а значит это снизит накладные расходы на использование колоночных индексов. Вообще-то самый простой способ оптимизации словарей заключается в самих данных – чем меньше уникальных данных в рамках столбца, тем лучше (это можно увидеть на примере DATETIME).
За счет колоночной модели вычитываться будут только те столбцы, которые мы запрашиваем, а дополнительные фильтры могут ограничивать вычитку RowGroup за счет упомянутой выше метаинформации. По итогу получается некий аналог псевдо-индекса, который есть одновременно на всех колонках, а это дает нам возможность очень быстро агрегировать и фильтровать… опять же со своими нюансами.
Рассмотрим несколько примеров, чтобы показать преимущества колоночных индексов:
DBCC DROPCLEANBUFFERS SET STATISTICS IO, TIME ON SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T1_HEAP] SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T2_CL] SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T3_CL_ROW] SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T4_CL_PAGE] SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T5_CCI] SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T6_CCI_ARCHIVE] SET STATISTICS IO, TIME OFF
Как говориться почувствуй разницу:
Table 'T1_HEAP'. Scan count 1, logical reads 19633, ... CPU time = 391 ms, elapsed time = 400 ms. Table 'T2_CL'. Scan count 1, logical reads 20911, ... CPU time = 312 ms, elapsed time = 391 ms. Table 'T3_CL_ROW'. Scan count 1, logical reads 14093, ... CPU time = 485 ms, elapsed time = 580 ms. Table 'T4_CL_PAGE'. Scan count 1, logical reads 9286, ... CPU time = 828 ms, elapsed time = 1000 ms. Table 'T5_CCI'. Scan count 1, ..., lob logical reads 5122, ... CPU time = 8 ms, elapsed time = 14 ms. Table 'T6_CCI_ARCHIVE'. Scan count 1, ..., lob logical reads 2576, ... CPU time = 78 ms, elapsed time = 74 ms.
По при фильтрации могут вылазить не сильно хорошие нюансы:
DBCC DROPCLEANBUFFERS SET STATISTICS IO, TIME ON SELECT * FROM [T5_CCI] WHERE [INT] = 1 SELECT * FROM [T5_CCI] WHERE [DATETIME] = GETDATE() SELECT * FROM [T5_CCI] WHERE [VARCHAR] = '1' SET STATISTICS IO, TIME OFF
И все дело в том, что для определенных типов данных (NUMERIC, DATETIMEOFFSET, [N]CHAR, [N]VARCHAR, VARBINARY, UNIQUEIDENTIFIER, XML) не поддерживается Row Group Elimination:
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 2713, ... Table 'T5_CCI'. Segment reads 1, segment skipped 7. CPU time = 15 ms, elapsed time = 9 ms. Table 'T5_CCI'. Scan count 1, ..., lob logical reads 0, ... Table 'T5_CCI'. Segment reads 0, segment skipped 8. CPU time = 0 ms, elapsed time = 0 ms. Table 'T5_CCI'. Scan count 1, ..., lob logical reads 22724, ... Table 'T5_CCI'. Segment reads 8, segment skipped 0. CPU time = 547 ms, elapsed time = 669 ms.
В части ситуаций есть откровенные недоработки оптимизатора, которые до боли напоминают старый баг в SQL Server 2008R2 (когда пред агрегация работает быстрее, чем агрегация, написанная более компактно):
DBCC DROPCLEANBUFFERS
SET STATISTICS IO, TIME ON
SELECT EOMONTH([DATETIME]), Cnt = SUM(Cnt)
FROM (
SELECT [DATETIME], Cnt = COUNT(*)
FROM [T5_CCI]
GROUP BY [DATETIME]
) t
GROUP BY EOMONTH([DATETIME])
SELECT EOMONTH([DATETIME]), Cnt = COUNT(*)
FROM [T5_CCI]
GROUP BY EOMONTH([DATETIME])
SET STATISTICS IO, TIME OFF
И таких моментов, по правде, куча и маленькая тележка:
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 64, ... CPU time = 0 ms, elapsed time = 2 ms. Table 'T5_CCI'. Scan count 1, ..., lob logical reads 32, ... CPU time = 344 ms, elapsed time = 380 ms.
Рассмотреть их все не получится в рамках данной статьи, но многое о чем нужно знать прекрасно приводится в видео за авторством Дмитрия Пилюгина. Кроме того есть отличный блог посвященный Column-store индексам. Крайне рекомендую данные ресурсы для более глубокого погружения в тему колоночных индексов!
Если с функциональными возможностями все более-менее понятно и, надеюсь, я смог убедить на примерах выше, что зачастую они не является сдерживающим фактором для полноценной разработки под ExpressEdition. Но как быть с ресурсными ограничениями… я бы сказал каждый конкретный случай решается индивидуально.
Express Edition разрешено использовать всего 4 ядра на инстанс, но что нам мешает развернуть в рамках сервера (например, на котором 16 ядер) несколько инстансов, за каждым из них закрепить свои физические ядра и получить дешевый аналог масштабируемой системы особенно в случае микросерверной архитектуры – когда каждый сервис работает со своим экземпляром базы.
Не хватает Buffer Pool размером в один гигабайт? Возможно, стоит свести физические чтения к минимуму за счет оптимизации запросов и внедрения секционирования, колоночных индексов или банально сжать данные в таблицах. Если это не представляется возможным, то мигрировать на более быстрые дисковые массивы.
Но как быть с предельным размером файла данных, который не может превышать 10Гб и при попытке его увеличить, свыше указанной величины, мы ожидаемо получим ошибку:
CREATE DATABASE or ALTER DATABASE failed because the resulting cumulative database size would exceed your licensed limit of 10240 MB per database.
Есть несколько вариантов обойти данную проблему.
Мы можем создать несколько баз данных, в которых будет размещаться своя порция исторических данных. Для каждой из таких таблиц мы зададим ограничение и далее объединим все эти таблицы в рамках одного представления. Так мы по итогу получим вертикальное шардирование в рамках одного инстанса.
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('DB_2019') IS NOT NULL BEGIN
ALTER DATABASE [DB_2019] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2019]
END
GO
IF DB_ID('DB_2020') IS NOT NULL BEGIN
ALTER DATABASE [DB_2020] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2020]
END
GO
IF DB_ID('DB_2021') IS NOT NULL BEGIN
ALTER DATABASE [DB_2021] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2021]
END
GO
IF DB_ID('DB') IS NOT NULL BEGIN
ALTER DATABASE [DB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB]
END
GO
CREATE DATABASE [DB_2019]
ALTER DATABASE [DB_2019] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB_2020]
ALTER DATABASE [DB_2020] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB_2021]
ALTER DATABASE [DB_2021] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB]
ALTER DATABASE [DB] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
GO
USE [DB_2019]
GO
CREATE TABLE [T_2019] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2019] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20190101' AND [A] < '20200101')
GO
INSERT INTO [T_2019] VALUES ('20190101', 1), ('20190201', 2), ('20190301', 3)
GO
USE [DB_2020]
GO
CREATE TABLE [T_2020] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2020] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20200101' AND [A] < '20210101')
GO
INSERT INTO [T_2020] VALUES ('20200401', 4), ('20200501', 5), ('20200601', 6)
GO
USE [DB_2021]
GO
CREATE TABLE [T_2021] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2021] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20210101' AND [A] < '20220101')
GO
INSERT INTO [T_2021] VALUES ('20210701', 7), ('20210801', 8), ('20210901', 9)
GO
USE [DB]
GO
CREATE SYNONYM [dbo].[T_2019] FOR [DB_2019].[dbo].[T_2019]
CREATE SYNONYM [dbo].[T_2020] FOR [DB_2020].[dbo].[T_2020]
CREATE SYNONYM [dbo].[T_2021] FOR [DB_2021].[dbo].[T_2021]
GO
CREATE VIEW [T]
AS
SELECT * FROM [dbo].[T_2019]
UNION ALL
SELECT * FROM [dbo].[T_2020]
UNION ALL
SELECT * FROM [dbo].[T_2021]
GO
При фильтрации в рамках поля, на котором задано ограничение, мы будем вычитывать только нужные нам данные:
SELECT COUNT(*) FROM [T] WHERE [A] > '20200101'
что можно увидеть на плане выполнения или в статистике:
Table 'T_2021'. Scan count 1, logical reads 2, ... Table 'T_2020'. Scan count 1, logical reads 2, ...
Кроме того, за счет ограничений нам разрешается прозрачно модифицировать данные в рамках представления:
INSERT INTO [T] VALUES ('20210101', 999)
UPDATE [T] SET [B] = 1 WHERE [A] = '20210101'
DELETE FROM [T] WHERE [A] = '20210101'
Table 'T_2021'. Scan count 0, logical reads 2, ... Table 'T_2021'. Scan count 1, logical reads 6, ... Table 'T_2020'. Scan count 0, logical reads 0, ... Table 'T_2019'. Scan count 0, logical reads 0, ... Table 'T_2021'. Scan count 1, logical reads 2, ... Table 'T_2020'. Scan count 0, logical reads 0, ... Table 'T_2019'. Scan count 0, logical reads 0, ...
Применяя подобный подход мы сможем частично решить проблему, но все равно каждая отдельная база будет ограничена заветными 10Гб.
Еще один вариант специально придуман для любителей архитектурных извращений – поскольку ограничение на размер файла данных не распространяется на системные базы данных (master, msdb, modelи tempdb), то всю разработку можно вести в них. Но чаще всего подобная практика использования системных баз данных в качестве пользовательских – это выстрел в себе ногу из рокетлаунчера. Потому даже не буду расписывать все подводные камни такого решения, но если все же сильно хочется – это точно гарантирует вам быструю прокачку матерного лексикона до уровня прораба с 30-ти летним опытом.
Теперь перейдем к рабочему решению проблемы.
Создаем базу данных нужного нам размера на Developer Edition и делаем детач:
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
GO
ALTER DATABASE [express] MODIFY FILE (NAME = N'express', SIZE = 20 GB)
ALTER DATABASE [express] MODIFY FILE (NAME = N'express_log', SIZE = 100 MB)
ALTER DATABASE [express] SET DISABLE_BROKER
GO
EXEC [master].dbo.sp_detach_db @dbname = N'express'
GO
Создаем базу с таким же именем на Express Edition и после останавливаем сервис:
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
GO
ALTER DATABASE [express] MODIFY FILE (NAME = N'express', SIZE = 100 MB)
ALTER DATABASE [express] MODIFY FILE (NAME = N'express_log', SIZE = 100 MB)
ALTER DATABASE [express] SET DISABLE_BROKER
GO
Перемещаем файлы нашей базы c Developer Edition, на то место, где лежит такая же база на Express Edition, заменяя одни файлы другими. Запускаем экземпляр SQL Server Express Edition.
Проверяем размер наших баз данных:
SET NOCOUNT ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SET STATISTICS IO, TIME OFF
IF OBJECT_ID('tempdb.dbo.#database_files') IS NOT NULL
DROP TABLE #database_files
CREATE TABLE #database_files (
[db_id] INT DEFAULT DB_ID()
, [name] SYSNAME
, [type] INT
, [size_mb] BIGINT
, [used_size_mb] BIGINT
)
DECLARE @sql NVARCHAR(MAX) = STUFF((
SELECT '
USE ' + QUOTENAME([name]) + '
INSERT INTO #database_files ([name], [type], [size_mb], [used_size_mb])
SELECT [name]
, [type]
, CAST([size] AS BIGINT) * 8 / 1024
, CAST(FILEPROPERTY([name], ''SpaceUsed'') AS BIGINT) * 8 / 1024
FROM sys.database_files WITH(NOLOCK);'
FROM sys.databases WITH(NOLOCK)
WHERE [state] = 0
AND ISNULL(HAS_DBACCESS([name]), 0) = 1
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
EXEC sys.sp_executesql @sql
SELECT [db_id] = d.[database_id]
, [db_name] = d.[name]
, [state] = d.[state_desc]
, [total_mb] = s.[data_size] + s.[log_size]
, [data_mb] = s.[data_size]
, [data_used_mb] = s.[data_used_size]
, [data_free_mb] = s.[data_size] - s.[data_used_size]
, [log_mb] = s.[log_size]
, [log_used_mb] = s.[log_used_size]
, [log_free_mb] = s.[log_size] - s.[log_used_size]
FROM sys.databases d WITH(NOLOCK)
LEFT JOIN (
SELECT [db_id]
, [data_size] = SUM(CASE WHEN [type] = 0 THEN [size_mb] END)
, [data_used_size] = SUM(CASE WHEN [type] = 0 THEN [used_size_mb] END)
, [log_size] = SUM(CASE WHEN [type] = 1 THEN [size_mb] END)
, [log_used_size] = SUM(CASE WHEN [type] = 1 THEN [used_size_mb] END)
FROM #database_files
GROUP BY [db_id]
) s ON d.[database_id] = s.[db_id]
ORDER BY [total_mb] DESC
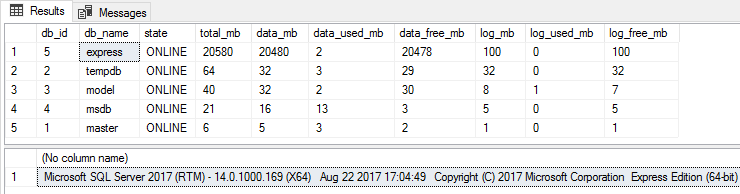
Вуаля! Теперь размер файла данных превышает ограничение и при этом база полностью работоспособна:
Можно, как и прежде, делать шринк, резервные копии или менять настройки этой базы. Сложности возникнут только в случаях, если вам нужно будет восстановить базу из резервной копии или еще раз увеличить размер файла данных. В таких ситуациях, мы сможем восстановить резервную копию на Developer Edition, увеличить размер до требуемого и далее подменить файлы как было описано выше.
Как итог, SQL Server Express Edition очень часто незаслуженно обходят стороной, прикрываясь ресурсными ограничениям и еще котомкой других отговорок. Главный посыл статьи – это то, что спроектировать высокопроизводительную систему можно на любой редакции SQL Server.
Всем спасибо за внимание!
Подписывайтесь на инстаграм в рамках которого планируется делать анонсы будущих мероприятий в Харькове.
Кроме того, возникла идея по-местному под кофеек всех желающих подучить SQL Server и пообсуждать треш связанный с разработкой. Если такие мысли возникнут, то стучите на почту.



