
Нам приходилось слышать абсолютно разные оценки скорости (ну или наоборот — оценки потребности в железе) систем распознавания речи, отличающиеся даже на порядок. Особенно радует, когда указаны системные требования из которых следует, что метрики сильно лучше, чем лучшие state-of-the-art системы из bleeding edge статей, а на практике иногда оказывается, что метрики рассчитаны в надежде, что "покупают для галочки и никто пользоваться не будет и так сойдет". Также не помогает то, что некоторые системы работают на GPU, а некоторые нет, равно как и то, что ядра процессоров могут отличаться в разы по производительности (например старые серверные процессора с тактовой частотой 2 — 2.5 GHz против современных решений от AMD с 4+ GHz на ядро имеющие до 64 ядер). Давайте в этом вместе разберемся, на самом деле, все не так уж и сложно!
Как правило люди начинают задумываться о скорости в 3 случаях:
- Когда ее не хватает или когда она является узким горлышком;
- Когда со скоростью нет проблем, но есть проблемы с ценой железа;
- Когда есть жесткое SLA по качеству сервиса от конечного заказчика;
- Когда есть жесткие требования по скорости "первого ответа" от конечного заказчика;
В этой статье мы постараемся ответить на несколько вопросов:
- Что вообще значит скорость?
- Какой скорости можно добиться в теории?
- Какой скорости можно добиться на практике и желательно без потери качества?
Определения
Но давайте для начала определимся с понятиями. Такой пример скорее является исключением в западном STT комьюнити, но лаборатория Facebook AI Research в последнее время активно наращивает свои позиции в распознавании речи и зачастую публикует интересные исследования, а в частности в качестве отправной точки по скорости интересна относительно недавняя статья, где они публикуют кроме всего прочего оценки скорости работы своих систем распознавания речи. Но как вы понимаете, обычно в таких статьях очень мало пишут про скорость и все всегда в духе "как все классно".
В частности, в статье приводятся 3 основные метрики, которыми обычно оценивается "скорость":
- Throughput (пропускная способность) — сколько потоков распознавания система может обрабатывать параллельно. Для простоты назовем это "потоками";
- Real Time Factor (RTF) (на знаю как кратко перевести) — насколько каждый поток распознавания распознается быстрее, чем реальное время. Давайте также для простоты определим Real Time Speed (RTS) как 1 / RTF, то есть количество секунд аудио, которое можно обработать за 1 секунду;
- Latency (задержка) — какую реальную задержку чувствует конечный пользователь прежде чем ему начинают приходить какие-то ответы системы;
Еще прежде чем оценивать скорость от FAIR, нужно понимать ряд вещей:
- Все тесты FAIR гоняют на процессоре Intel Skylake c 18 физическими ядрами (информации о тактовой частоте и наличии 2 потоков на ядро нет, но по числу ядер попробую предположить это какой-то мощный топовый процессор);
- Это результаты end-to-end алгоритма реализованного на C++ с "встроенным" декодингом;
- Скорее всего вероятно используются кастомные низкоуровневые реализации из wav2letter++;
- Важно понимать, что такие статьи это в первую очередь пиар и результаты тут пере-оптимизированы на маленькие чистые академические датасеты;
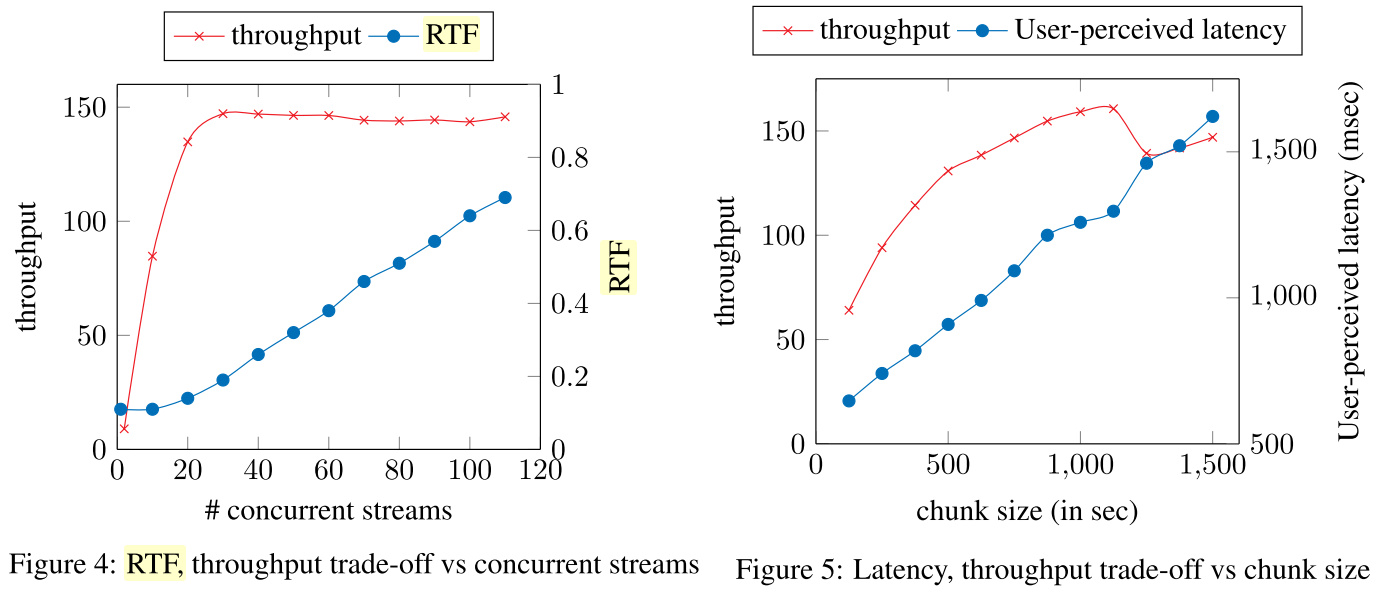
Интересные моменты:
- Общая "скорость" (RTS * число потоков) быстро выходит на плато. Также видно, что для получения гарантий по скорости работы системы нужно снижать размер чанка;
- FAIR потратили существенное время на оптимизацию своей нейросети, т.к. этой статьей они продолжают по сути целое направление своих исследований, где они пиарят так называемые TDS-слои;
- В этой статье их ноу-хау по сути является несколько технических оптимизаций по скорости и квантизация;
- С определенной натяжкой, можно сказать, что они сделали что-то близкое к state-of-the-art для быстрых и практичных сетей (конечно как обычно близко без гарантий, что вы сможете это повторить и что это пошло в реальный продакшен);
- В статье FAIR пишут, что их "оптимальные" характеристики это 40 потоков, 0.26 RTF и задержка в районе одной секунды (вообще на самом деле можно выбрать любые точки на графиках выше). Понятное дело, всегда можно перенастроить такую систему допустим на больше потоков ценой задержки, ну или допустим на меньшую задержку ценой общей пропускной способности;
- Быстро на коленке Пересчитаем 40 * 1 / 0.26 и разделим на 18 физических ядер процессора. Получаем, что за 1 секунду на 1 ядре серверного процессора они могут распознать где-то в районе 8-9 секунд аудио;
Выпишем теперь самое важное для сравнения:
- Чанки: равные чанки длиной в районе 750 мс (оптимальное значение);
- Пропускная способность: Оптимальные метрики 8-9 секунд аудио на ядро процессора, 40 потоков на 18 физических ядер процессора;
- Задержка: от 500 мс до 1000 мс, для заявленного оптимального чанка в 750 мс — скорее ближе к секунде;
- Низкоуровневая реализация на C++ со встроенным пост-процессингом;
Скорость Других Решений
Возникает закономерный вопрос — а какую скорость показывают другие системы на рынке? Мы давно не исследовали этот вопрос, т.к. в последних исследованиях качества мы использовали только облачные системы без гарантий по скорости и без указанных характеристик по железу. Тем не менее с некоторой натяжкой на коленке мы собирали вот такое сравнение. Оно не особо претендует на научность, скорее собрали что-то с миру по нитке. Провести качественное исследование даже своей системы и подобрать оптимальные внутренние параметры — это очень трудоемкая работа, а с другими системами это сделать запретительно дорого, да и неблагодарная это работа.
Теоретические Лимиты
Наша лучшая система сейчас не является полностью end-to-end системой, как система от FAIR, потому что мы сначала поставили задачу достижения высоких показателей на реальных данных, а уже потом миниатюризации. Поэтому сначала мы озаботились оптимизацией акустической модели, потом всего сервиса в целом, и уже потом мы будем заниматься интеграцией всего end-2-end (желательно чтобы еще работало на мобильниках).
Наша методология тестирования скорости несколько отличается от FAIR, т.к. мы не считаем оправданной трату финансовых и кадровых ресурсов, чтобы писать свои кастомные фреймворки на C++ для проведения академических изысканий. В первую очередь методология отличается тем, что мы вынуждены подавать данные батчами в нашу систему.
Это и проклятие и благословение одновременно. Очевидно, что батчами все процессится быстрее, но это очень сильно усложняет архитектуру и требования к прямоте рук при проектировании сервиса. Я даже слышал мнения, что с батчами "непонятно как" или "невозможно" сделать нормальный продакшен (на самом деле просто нужны прямые руки). Тем не менее после всех изысканий у нас получилось получить вот такие цифры:
| Размер батча | FP32 | FP32 + Fused | FP32 + INT8 | FP32 Fused + INT8 | Full INT8 + Fused | New Best |
|---|---|---|---|---|---|---|
| 1 | 7.7 | 8.8 | 8.8 | 9.1 | 11.0 | 22.6 |
| 5 | 11.8 | 13.6 | 13.6 | 15.6 | 17.5 | 29.8 |
| 10 | 12.8 | 14.6 | 14.6 | 16.7 | 18.0 | 29.3 |
| 25 | 12.9 | 14.9 | 14.9 | 17.9 | 18.7 | 29.8 |
Тут не надо ходить к бабке, чтобы понять, что миниатюризация и квантизация модели очень сильно докидывает. Докидывает настолько, что задержка перестает быть критичной даже для CPU модели. Этого к сожалению нельзя сказать про пропускную способность. В сравнении с FAIR или другими системами может показаться, что последние цифры нереалистичны, но тут надо понять ряд вещей:
- Это только одна часть пайплайна без пост-процессинга;
- Это не включает потери в реальной жизни на транспорт, сериализацию, коммуникацию, итд итп;
- Мы не знаем являются ли цифры FAIR сугубо теоретическими, или туда уже включены потери на оборачивание алгоритмов в продакшен сервис;

Посмотрим теперь, какие цифры можно будет получить для продакшен-дистрибутивов на реальном железе.
Практические Сайзинги
Мы потратили довольно много времени на оптимизацию гипер-параметров для продакшена и пришли к следующим цифрам.
Пара слов о методологии:
- Метрики рассчитаны для файлов длиной 1 — 7 секунд, которые "кормятся" в сервис в 4 — 8 — 16 потоков;
- Распределение длин файлов соответствует распределению длин файлов в реальных диалогах людей по телефону;
- Метрики рассчитаны для многопоточного веб-сервиса, что немного абстрагируется от сценария реального использования. Ну то есть если мы можем держать условно 8 потоков с условной гарантией в latency в 500 мс, то это значит, что правильно настроив конечную бизнес-логику, можно обрабатывать сильно больше, чем 8 одновременных звонков;
- Реальные люди не говорят одновременно, пока человек заканчивает вторую фразу мы уже успеваем обработать первую итд итп. Поэтому на реальном проекте можно опять же держать еще более высокую нагрузку. Но это уже сильно зависит от реального бизнес-кейса;
Сайзинги для GPU
| Сайзинг | Минимум | Рекомендуется |
|---|---|---|
| Диск | SSD, 256+ GB | NVME, 256+ GB |
| RAM | 32 GB | 32 GB |
| Ядер процессора | 8+ | 12+ |
| Тактовая частота ядра | 3 GHz+ | 3.5 GHz+ |
| 2 потока на ядро процессора | Да | Да |
| AVX2 инструкции процессора | Не обязательно | Не обязательно |
| Количество GPU | 1 | 1 |
| Метрики | 8 "потоков" | 16 "потоков" |
| Среднее время ответа, мс | 280 | 320 |
| 95-я перцентиль, мс | 430 | 476 |
| 99-я перцентиль, мс | 520 | 592 |
| Файлов за 1000 мс | 25.0 | 43.4 |
| Файлов за 500 мс | 12.5 | 21.7 |
| Секунд аудио в секунду (1 / RTF) | 85.6 | 145.0 |
| Секунд аудио в секунду на ядро | 10.7 | 12.1 |
Есть 3 типа подходящих GPU:
- Любые игровые GPU Nvidia выше чем 1070 8+GB RAM с турбиной;
- Любые однослотовые GPU Nvidia серии Quadro 8+GB RAM (TDP 100 — 150W) с турбиной или пассивные;
- Nvidia Tesla T4, пассивная, TDP 75W;
Мы часто сталкиваемся с тем, что заказчики не понимают и иррационально боятся использовать GPU в продакшене мотивируя это все разного рода отговорками (типичное "отдел закупок не одобрит"). Приведем топ мнений, которые мы слышали:
- "Карты слишком мощные (300 ватт) и горячие". Это не так. У игровых и карт для исследований TDP реально такой. Но TDP решений для продакшена в пике от 75 до 150 ватт, а на практике с нашими сетями будет где-то 50-75% от пиковых значений;
- "Карты очень греют сервер и серверную". Это конечно зависит от их количества, но с нашими сайзингами даже на крупные проекты хватит 2 карт (+ резерв);
- "Карты нарушают идеально продуманную циркуляцию воздуха в серверной". В идеальном мире вообще для серверных "предназначены" только пассивные карты Tesla согласно SLA от Nvidia. Но понятно почему монополист в SLA указывает это, т.к. карты Tesla в 2-3 раза дороже. Но если вам так надо "гарантий" — просто купите пассивные карты и оптимизируйте воздушные потоки сколько угодно;
- "Карты занимают только 2+ слота и не влазят в серверные шасси". Это не так. Карты Quadro и T4 занимают 1 слот;
- "Карты слишком дорогие". Топовые карты Tesla A100 действительно стоят US$12,500 в России. Но карты Quadro и T4 (я уже молчу про игровые) в рамках крупных проектов стоят уже вообще копейки;
- "Карты недолговечные и ломаются". Как и любой "силикон" если карта не бракованная — она будет служить 3-4 года, плюс никто не отменял гарантию. Если не хочется иметь точку отказа в виде охлаждения — всегда есть пассивные карты. Тут отмечу, что карты Nvidia с пробегом купленные с Авито прекрасно служат несколько лет в режиме 24/7 и сказки про "майнеров" это просто сказки, майнеры очень бережно относятся к технике. Знакомый майнер давно купил 100 карт Nvidia и AMD и за 3 года из строя не вышла ни одна зеленая карта;
Одна из целей данной статьи — развеять эти заблуждения. Забегая вперед — деплой на GPU примерно в 2-3 раза дешевле.
Сайзинги для CPU
| Сайзинг | Минимум | Рекомендуется |
|---|---|---|
| Диск | SSD, 256+ GB | SSD, 256+ GB |
| RAM | 32 GB | 32 GB |
| Ядер процессора | 8+ | 12+ |
| Тактовая частота ядра | 3.5 GHz+ | 3.5 GHz+ |
| 2 потока на ядро процессора | Да | Да |
| AVX2 инструкции процессора | Обязательно | Обязательно |
| Метрики | 4 "потока" | 8 "потоков" |
| Среднее время ответа, мс | 320 | 470 |
| 95-я перцентиль, мс | 580 | 760 |
| 99-я перцентиль, мс | 720 | 890 |
| Файлов за 1000 мс | 11.1 | 15.9 |
| Файлов за 500 мс | 5.6 | 8.0 |
| Секунд аудио в секунду (1 / RTF) | 37.0 | 53.0 |
| Секунд аудио в секунду на ядро | 4.6 | 4.4 |
Комментарии по Cайзингам
- В реальности со всем фаршем даже у сервиса с GPU получается только 10 — 15 RTS на одно ядро процессора (хотя теоретический RTS самой модели на GPU находится где-то в районе 500 — 1,000). В теории число воркеров CPU на 1 GPU можно наращивать больше (тем самым наращивая нагрузку на карту и пропускную способность), чем мы пробовали, но мы упираемся в удорожание процессоров. В какой-то момент горизонтальное резервирование становится важнее;
- CPU-версия сервиса показывает только в районе 5 честных RTS, что немало, но она скорее оптимизирована как баланс между гарантиями по latency и throughput;
- Метрики настоящие и честные и подбор параметров стоил много боли и страданий. Если честно — я вообще не видел, чтобы кто-то вообще показывал перцентили реальных систем;
- Многие крупные проекты просят 50 одновременных разговоров, поэтому иметь возможность покрыть такой проект используя всего 2 GPU (+ резервирование) это довольно круто;
- Использование GPU сервиса где-то в 2-3 раза дешевле, чем если считать все только на CPU;
Выводы
Если статья от FAIR показывание реальные продакшен показатели, то у нас получилось используя только открытые и свободные библиотеки достичь 50% их показателей. Но скорее всего конечно цифры там — теоретические. Это конечно не 20-30 RTS как у акустической модели, но как правило после упаковки в дистрибутив где-то теряется 40-50% показателей. В таком случае мы показали ряд вещей:
- Продакшен на GPU быстрее, удобнее и дешевле;
- Мы как минимум приблизились к цифрам от FAIR;
- Мы наглядно показали, что деплой на GPU с батчами не только возможен, но и прекрасно работает;
- Если грамотно прикрутить бизнес-логику к такому распознаванию, то можно держать достаточную нагрузку даже для высоконагруженных реальных проектов;
А что дальше? У нас большие планы на релиз некоторых комплиментарных распознаванию голоса технологий под довольно свободной лицензией MIT.




