

Пролог
Добрый день, уважаемые читатели. Совсем недавно мне пришлось осваивать новую для себя область CI/CD, настраивая с нуля доставку скриптов миграции базы данных в одном из проектов. При этом было тяжело преодолеть самый первый этап "глаза боятся", когда задача вроде бы ясна, а с чего начать, не знаешь. Однако вопрос оказался на поверку значительно проще, чем казалось изначально, давая при этом неоспоримые преимущества ценой нескольких часов работы и не требуя никаких дополнительных средств, кроме обозначенных в заголовке.
Полученным опытом я решил поделиться в данной статье, чтобы помочь тем, кто хочет автоматизировать свои рабочие процессы, но не знает, с чего начать.
Оглавление
Введение
Основы
Liquibase
Настройка сервера деплоя
Настройка GitLab Runner
Настройка CI/CD
Заключение
Введение
Об авторе
Меня зовут Копытов Дмитрий, я являюсь главным разработчиком и архитектором проектов. Специализируюсь на C#/.NET, Vue.js и Postgres.
К теме CI/CD пришел после получения "в наследство" проекта с уже существующим CI/CD, который пришлось перерабатывать.
О статье
В первую очередь статья предназначена для разработчиков, которые хотят внедрить в свои проекты CI/CD, но не знают, с чего начать, а также для тех, кому в наследство достались проекты с уже внедренным CI/CD, суть работы которого им не понятна.
Целью статьи является подробное описание технических аспектов настройки связки GitLab + Liquibase на конкретном примере, а также основы теории, чтобы у читателя отложилась не только сама инструкция, но и понимание процесса. Многие моменты и возможности GitLab CI/CD & Liquibase будут сознательно опущены во избежание перегрузки информацией.
Уже после написания большей части статьи, осознал насколько она оказалась большая, но разбить ее на несколько частей не вижу возможности без потери целостности. Приготовьтесь, будет многобукофф.
Перед самой публикацией во время выбора хабов обнаружил схожую статью по автоматизации деплоя Liquibase. Это досадная случайность без злого умысла, не более.
Кулинарный рецепт
Для приготовления блюда нужны следующие ингредиенты:
GitLab Community Edition – хранилище Git
GitLab Runner – рабочая лошадка CI/CD
Liquibase, на момент написания статьи версия 4.3.4
Драйвер Liquibase для целевой БД
Выделенный сервер с установленными Liquibase и GitLab Runner и доступом к целевой БД для наката скриптов и к GitLab для получения исходников. Необязательно.
3 чашки чая или кофе. Обязательно.
Основы
Используемые технологии
Все технологии, используемые в статье, являются открытыми, вы можете использовать их совершенно бесплатно без необходимости закупки Premium-фич.
Примеры из статьи (скрипты и конфиги) опубликованы на гитхабе: https://github.com/Doomer3D/Gliquibase.
GitLab CI/CD
CI/CD у всех на слуху, поэтому не буду вдаваться в детали, отмечу только, что в контексте статьи будет рассмотрен процесс автоматического (при мерже/коммите) или ручного (по команде) наката скриптов миграции базы данных на целевую среду, будь то дев или прод. В качестве конвейера будут использоваться GitLab pipelines, а непосредственным исполнителем будет GitLab Runner, поэтому если вы не используете GitLab в качестве хранилища, статья вам будет по большому счета бесполезна.
Все примеры будут рассмотрены в контексте используемого в нашей компании GitLab Community Edition 13.x.
Liquibase
Liquibase («ликви») – платформа c открытым кодом, которая позволяет управлять миграциями вашей базы. Если кратко, то Liquibase позволяет описывать скрипты наката и отката базы в виде файлов чейнжсетов (changeset). Сами скрипты при этом могут быть как обычными SQL-командами, так и БД-независимыми описаниями изменений, которые будут преобразованы в скрипт конкретно для вашей базы. Список поддерживаемых БД можно найти здесь: https://www.liquibase.org/get-started/databases.
Liquibase написан на Java, поэтому может быть запущен на любой машине с JVM.
В статье будет рассмотрен Oracle 19 в качестве целевой базы, потому что именно для него настраивал деплой на рабочем проекте. Но, как писал выше, тип базы не имеет принципиального значения.
Схема работы
В данном разделе я сначала хотел нарисовать схему, но быстро понял, что давно не рисовал диаграммы процессов, поэтому постараюсь объяснить на пальцах.
Когда разработчик делает коммит или мерж реквест, запускается конвейер CI/CD, называемый пайплайном (pipeline), который включает в себя этапы (stage), состоящие из джобов (job).
В нашем примере будет один этап – деплой (deploy), т.е. применение скриптов наката. При этом будет столько джобов, сколько стендов мы имеем. Предположим, что у нас всего два стенда – дев и прод. Соответственно, будет два джоба – деплой на дев (deploy-dev) и деплой на прод (deploy-prod), которые будут отличаться целевой БД. Кроме того, деплой на прод мы хотим запускать только вручную, по команде, а не в момент мержа или коммита.
Джобы обрабатываются раннером (GitLab Runner) – специальной программой, которая скачивает себе исходники проекта и выполняет скрипты на сервере деплоя, при этом раннеру передаются различные параметры в виде переменных окружения. Это может быть пользовательская информация, хранимая в настройках проекта, такая как адрес и логин/пароль сервера БД, а также информация о самом процессе CI/CD, например, название ветки, автор, текст коммита и т.п.
Важно! Раннер сам обращается к GitLab по http, а не наоборот, поэтому машина с раннером должна иметь доступ к GitLab, в то время как разработчик и сервер GitLab могут ничего не знать о машине, где находится раннер.
Если оба стенда – дев и прод, доступны с одной машины, достаточно будет одного раннера, однако обычно прод находится в другой сети, тогда в ней должен быть отдельный раннер с доступом к БД прода.
В нашем случае раннер будет вызывать Liquibase через командную строку. В параметрах к Liquibase будет передана информация о целевой базе и используемом драйвере, а сами скрипты наката Liquibase сформирует из описаний миграций из файлов вашего проекта.
В случае успеха, если скрипты отработали без ошибок, пайплайн считается успешным, а мерж реквест вливается в ветку. Картина будет примерно такой:

В противном случае пайплайн будет в состоянии failed:

Мы сможем провалиться в джоб и посмотреть логи, чтобы найти ошибку или перезапустить пайплайн, если проблема была в сетевом доступе. В моей практике была ситуация, что поднятый VPN на машине деплоя в какой-то момент стал блокировать доступ к GitLab по доменному имени, при этом пайплайн оказывался в состоянии pending, т.е. ожидал, что раннер подхватит джоб, но этого не происходило. Правка hosts и перезапуск пайплайна разрешили проблему.
Итак, подытожим, как выглядит схема работы:
Разработчик делает мерж реквест или коммит в ветку.
Запускается пайплайн, который исполняет ассоциированный с этой веткой джоб.
Джоб инициирует раннер, находящийся на удаленной машине.
Раннер скачивает исходники и выполняет скрипт, вызывающий Liquibase.
Liquibase генерирует и исполняет скрипты наката/отката.
...
Profit!
А теперь обо всем по порядку.
Liquibase
Этот раздел посвящен Liquibase. Здесь не будет полного изложения документации, потому что эта тема для отдельной статьи или даже для цикла статей, но я постараюсь осветить основы Liquibase.
Ссылка на официальную документацию по Liquibase: https://docs.liquibase.com/concepts/basic/home.html
Предполагается, что если вы, уважаемый читатель, вышли на эту статью, то имеете хотя бы начальное знакомство с Liquibase, именуемом в народе «ликви», но если нет, я все же изложу вкратце, что это такое и с чем его едят.
Liquibase – это платформа управления и наката миграций БД. В основе лежит понятие чейнжсета (changeset) – атомарного изменения базы. Чейнжсетом, например, может быть создание таблицы в базе, добавление колонки/триггера, или наполнение таблицы данными. Чейнжсеты объединяются в чейнжлоги (changelog), которые выстраиваются в цепочку, которая применяется на целевой БД последовательно, таким образом обновляя базу до актуального состояния.
changelog
Начнем рассмотрение Liquibase с понятия чейнжлога. Чейнжлог – это отдельный файл, содержащий в себе чейнжсеты или ссылки на другие чейнжлоги. Порядок включения чейнжлогов/чейнжсетов определяет порядок их наката. Как и чейнжсеты, чейнжлоги могут быть описаны в одном из четырех форматов: SQL, XML, JSON и YAML. В статье будут рассмотрены форматы SQL и XML как наиболее популярные и удобочитаемые.
Один из чейнжлогов является корневым, т.е. именно от него идет раскручивание всей цепочки. Назовем его мастером и дадим имя master.xml. Этот чейнжлог несет в себе функцию аккумуляции ссылок на другие чейнжлоги. Изначально у нас в проекте был один такой аккумулятор, в который последовательно дописывались ссылки на другие файлы, которые складировались в той же папке. Это приводило к двум проблемам:
Папка со временем разрослась до гигантских размеров, и ориентироваться в ней стало невозможно.
Когда с файлом стали работать два разработчика, изменение файла неизбежно приводило к конфликтам, которые приходилось решать.
Во избежание этих проблем рекомендую придерживаться другого подхода, связанного с разбиением задач по релизам/версиям/датам или каким-либо критериям, чтобы отдельные папки с изменениями были небольшими по размеру. В качестве примера приведу структуру тестового проекта для этой статьи.

Файлы Liquibase хранятся в папке db/changelog, в корне лежит мастер-файл master.xml
В отдельных папках, соответствующих релизам 156 и 157, складируются чейнжлоги. В общем случае один таск = один чейнжлог. Также отдельно выделена папка common для служебных целей, там лежит скрипт пре-миграции, который выполняется при каждом накате скриптов. Аналогичным образом можно было бы добавить скрипт пост-миграции, если это нужно.
Разберем файл master.xml:
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:pro="http://www.liquibase.org/xml/ns/pro"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-4.2.xsd http://www.liquibase.org/xml/ns/pro http://www.liquibase.org/xml/ns/pro/liquibase-pro-4.2.xsd ">
<preConditions>
<dbms type="oracle" />
</preConditions>
<!-- предварительные скрипты -->
<include file="/common/pre_migration.xml" />
<!-- релизы -->
<includeAll path="/v156" relativeToChangelogFile="true" />
<includeAll path="/v157" relativeToChangelogFile="true" />
</databaseChangeLog>XML-файл выглядит несколько перегруженным неймспейсами, пусть это вас сильно не волнует. Это стандартная обертка для любого XML-файла Liquibase.
Раздел preConditions определяет различные параметры запуска, конкретно здесь мы указываем, что используем oracle, но также можно указать имя пользователя, от которого будет происходить запуск скриптов. Более плотно preConditions используются в чейнжсетах.
Далее идет включение скриптов в нужной последовательности. Для этого существуют команды include (включение отдельного файла) и includeAll (включение папки).
Использование includeAll позволяет избежать проблем с конфликтами при правке файла-аккумулятора внутри релиза, но тогда нужно выработать стратегию именования файлов, т.к. их включение будет происходить в алфавитном порядке. В примере выше я использую дату + номер таска, но этого будет недостаточно в реальном проекте, если изменения по таску с меньшим номером нужно применить после таска с большим номером, и при этом они будут в один день.
Как альтернативу includeAll вы можете внутри папки релиза создать свой мастер-файл (аккумулятор скриптов релиза), в который включать ссылки на отдельные скрипты, что в целом менее удобно.
changeset
Чейнжсеты описываются внутри файлов чейнжлогов в виде отдельных блоков. Рассмотрим на примере файла 2021-05-01 TASK-001 CREATE TEST TABLE.xml:
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:pro="http://www.liquibase.org/xml/ns/pro"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-4.2.xsd http://www.liquibase.org/xml/ns/pro http://www.liquibase.org/xml/ns/pro/liquibase-pro-4.2.xsd ">
<changeSet author="Doomer" id="20210501-01">
<preConditions onFail="MARK_RAN">
<not>
<tableExists tableName="TEST"/>
</not>
</preConditions>
<createTable tableName="TEST" remarks="Тестовый справочник">
<column name="ID" type="NUMBER(28,0)" remarks="Идентификатор">
<constraints nullable="false" primaryKey="true" primaryKeyName="TEST_PK" />
</column>
<column name="CODE" type="VARCHAR2(64)" remarks="Код">
<constraints nullable="false" />
</column>
<column name="NAME" type="VARCHAR2(256)" remarks="Наименование">
<constraints nullable="false" />
</column>
</createTable>
<rollback>
<dropTable tableName="TEST" />
</rollback>
</changeSet>
</databaseChangeLog>В файле описан чейнжсет, который создает таблицу TEST с тремя колонками. При этом описание происходит в виртуальных сущностях, которые транслируются в скрипты для конкретной БД.
Элемент preConditions указывает, что чейнжсет нужно применять только в случае, если таблица не существует в базе.
Элемент rollback указывает, как нужно откатывать скрипт, если такой механизм планируется использовать. Откаты в нашей стране, конечно, популярны, но выходят за рамки данной статьи.
Рассмотрим основные атрибуты чейнжсетов.
Атрибут | Описание |
id | Идентификатор, обязательный атрибут, использование см. ниже. |
author | Автор, обязательный атрибут, использование см. ниже. |
dbms | Фильтр баз данных, для которых применяется чейнжсет. |
contexts | Контексты, для которых применяется чейнжсет. Например, мы можем указать, что чейнжсет применяется только на проде или везде, кроме прода. Подробнее по ссылке. |
runAlways | Булево. Указывает, что чейнжсет применяется при каждом запуске. Полезно для скриптов установки контекста окружения, см. ниже. |
runOnChange | Булево. Указывает, что чейнжсет применяется при изменении содержимого. Полезно для скриптов создания recreatable-объектов, таких как процедуры, вьюхи, триггеры и т.п. |
Подробную документацию по чейнжсетам можно почитать по ссылке.
DATABASECHANGELOG
Чейнжсеты, которые были применены к базе, сохраняются в специальную таблицу DATABASECHANGELOG, в паре с которой идет таблица DATABASECHANGELOGLOCK, обеспечивающая параллельную работу нескольких экземпляров Liquibase.
В таблице нет физических ключей, но у самих чейнжсетов есть уникальный ключ – это комбинация идентификатора, автора и имени файла. Политика именования чейнжсетов у всех может быть своя, у нас исторически сложился формат <дата>-<номер><ФИ автора>, например 20210501-01KD. Отмечу, что это мой первый проект с использованием Liquibase, поэтому не буду давать советов, как лучше именовать чейнжсеты.
Также у каждого чейнжсета вычисляется MD5-сумма на основе его тела, поэтому нельзя просто так менять файл чейнжсета, если он уже был применен к базе. Это может иметь значение при разработке, особенно при освоении Liquibase. Поначалу вы будете часто ошибаться с тем, как правильно составить чейнжсет, в итоге в базе окажется сохраненный чейнжсет с MD-5 суммой и неверно выполненный скрипт. В этом случае нужно будет вручную откатить его изменения, а также удалить соответствующие записи из DATABASECHANGELOG.
runAlways
База данных предоставляет инструменты для настройки контекста окружения, что может быть полезно, например, в сценарии аудита таблиц, когда записи, измененные скриптами, выполненных через Liquibase, нужно как-то помечать. Мы это решаем через установку переменной сессии USER_ID.
Для этой цели в описании мастер-чейнжлога включается скрипт пре-миграции, который занимается настройкой окружения. Приведу его текст:
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:pro="http://www.liquibase.org/xml/ns/pro"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-4.2.xsd http://www.liquibase.org/xml/ns/pro http://www.liquibase.org/xml/ns/pro/liquibase-pro-4.2.xsd ">
<changeSet author="SYSTEM" id="PRE_MIGRATION" runAlways="true">
<sql splitStatements="true" stripComments="true">
-- устанавливаем в контекст сессии пользователя liquibase
CALL DBMS_SESSION.SET_CONTEXT('CLIENTCONTEXT','USER_ID', 13);
</sql>
</changeSet>
</databaseChangeLog>Здесь в качестве тела используется SQL-скрипт, который записывает в переменную сессии USER_ID значение 13 – наш внутренний идентификатор пользователя Liquibase. Этот скрипт будет влиять на все последующие скрипты, поэтому помечен флагом runAlways и включен перед скриптами релизов.
SQL-чейнжсет
Чейнжсеты можно оформлять и в формате SQL, что особенно полезно при написании сложных запросов. Рассмотрим файл 2021-05-01 TASK-002 TEST.sql, который выполняется сразу после создания таблицы TEST:
--liquibase formatted sql
--changeset Doomer:20210501-02
--preconditions onFail:MARK_RAN
--precondition-sql-check expectedResult:1 SELECT COUNT(*) FROM ALL_TABLES WHERE TABLE_NAME = 'TEST' AND OWNER = 'STROY';
--precondition-sql-check expectedResult:0 SELECT COUNT(*) FROM TEST WHERE ID = 1;
insert into TEST (ID, CODE, NAME)
values (1, 'TEST', 'Какое-то значение');
--rollback not required
--changeset Doomer:20210501-03
--preconditions onFail:MARK_RAN
--precondition-sql-check expectedResult:1 SELECT COUNT(*) FROM ALL_TABLES WHERE TABLE_NAME = 'TEST' AND OWNER = 'STROY';
--precondition-sql-check expectedResult:1 SELECT COUNT(*) FROM TEST WHERE ID = 1;
update TEST
set NAME = 'CONTEXT USER_ID=' || nvl(SYS_CONTEXT('CLIENTCONTEXT', 'USER_ID'), 'NULL')
where ID = 1;
--rollback not requiredЭто файл с двумя чейнжсетами в составе.
Первый добавляет новую запись в таблицу TEST, проверяя существование таблицы и отсутствие элемента с ID = 1. Если одно из условий не выполнится, чейнжсет не будет применен, но будет помечен в DATABASECHANGELOG как выполненный (MARK_RAN). Подробнее можно почитать в документации по preConditions.
Второй чейнжсет обновляет созданную запись значением из переменной сессии USER_ID.
После наката скриптов мы предсказуемо увидим следующую картину в таблице TEST:

К сожалению, формат статьи и ее и без того обширная тема не позволяет описать чейнжсеты Liquibase более подробно, но тут можно только сказать классическое RTFM.
Командная строка Liquibase
Liquibase является консольным приложением, поэтому нужно понимать, как его вызывать. Вообще, это тема больше относится к области GitLab Runner'а, но чтобы не смешивать обе темы, рассмотрим вызов Liquibase в этом разделе.
Документация по командам Liquibase: https://docs.liquibase.com/commands/community/home.html
Нас в первую очередь интересуют команды:
update – применение изменений
updateSQL – получение SQL-скриптов для анализа, полезно для обучения
Обе команды имеют схожий набор параметров, поэтому рассмотрим основные из них на нашем тестовом примере:
Параметр | Описание | Пример значения |
changeLogFile | Путь к мастер-файлу чейнжлога, обязательный параметр | master.xml |
url | Адрес БД, обязательный параметр | jdbc:oracle:thin:1.2.3.4:1521:orastb |
username | Логин пользователя БД, обязательный параметр | vasya |
password | Пароль пользователя БД, обязательный параметр | pupkin |
defaultSchemaName | Имя схемы по умолчанию | DATA |
contexts | Контекст БД для фильтров чейнжсетов по контексту | dev / prod |
driver | Тип драйвера БД | oracle.jdbc.OracleDriver |
classpath | Путь до драйвера | /usr/share/liquibase/4.3.4/drivers/ojdbc10.jar |
outputFile | Путь до файла, куда выводить результат для команды updateSQL. Если не указано, вывод будет в консоль. |
Для обучения можно создать батник, который будет запускать Liquibase c вашим скриптом до его добавления в гите. Разумеется, надо помнить о необходимости отката изменений (см. выше). Рядом помещаете папку с Liquibase и драйвером, об установке которых рассказывается в следующем разделе, а также файл скрипта.
Пример батника для Windows:
call "C:\Temp\liqui\liquibase-4.3.1\liquibase.bat" ^
--defaultSchemaName=STROY ^
--driver=oracle.jdbc.OracleDriver ^
--classpath="C:\Temp\liqui\ojdbc5.jar" ^
--url=jdbc:oracle:thin:@1.2.3.4:1521:dev ^
--username=xxx ^
--password=yyy ^
--changeLogFile=.\master.xml ^
--contexts="dev"
--logLevel=info ^
updateSQLНастройка сервера деплоя
Выделенный сервер для деплоя, вообще говоря, не обязателен. Это может быть самая простая машина, которая имеет доступ к целевой базе данных, чтобы подключиться и накатить скрипты, и к серверу GitLab, откуда будут взяты исходники проекта. В целях безопасности эту машину можно изолировать от прочих ресурсов.
В нашей компании используются виртуальные машины на основе Centos 7, поэтому все примеры команд буду приводить именно для него. Также я исхожу из предположения, что вы знакомы с основами работы в консоли Linux.
Установка Java
Liquibase рекомендует использовать Java 11+, давайте установим его. Я использую OpenJRE 11:
sudo yum install java-11-openjdk
java --versionУстановка Liquibase
Официальная документация: https://www.liquibase.org/get-started/quickstart
Liquibase не требует установки, потому что является программой на Java. Заходим на сайт и скачиваем архив с программой. Архив распаковываем в папку по вашему усмотрению, но для себя я решил использовать путь /usr/share/liquibase/<version>, например /usr/share/liquibase/4.3.4
Там же, в папке с установленным Liquibase, создаем папку drivers и копируем в нее нужный драйвер для вашей БД. В моем случае это был ojdbc10.jar
Проверяем, что Liquibase работает:
cd /usr/share/liquibase/4.3.4
liquibase --versionУстановка Git
Git является зависимостью GitLab Runner и ставится автоматически, но нужно отметить одну неприятную особенность, характерную для Centos 7 и, возможно, для других версий пингвинообразных. Если вы просто установите GitLab Runner на голую ось, он потянет за собой git в виде зависимости, который в стандартном репозитории имеет версию 1.8. Эта версия откровенно баганая, что в связке с GitLab приводит к тому, что в какой-то момент, причем не сразу, CI/CD перестает работать с выдачей совершенно непонятной ошибки.
Чтобы избежать неприятных сюрпризов, необходимо установить более свежую версию git до установки GitLab Runner:
# проверяем текущую версию гита
git --version
# удаляем гит, если он версии 1.8
sudo yum remove git*
# устанавливаем последнюю версию гита на момент написания статьи (2.30)
sudo yum -y install https://packages.endpoint.com/rhel/7/os/x86_64/endpoint-repo-1.7-1.x86_64.rpm
sudo yum install gitУстановка GitLab Runner
Официальная документация: https://docs.gitlab.com/runner/install/linux-manually.html
# добавляем репу
curl -L "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh" | sudo bash
# устанавливаем
export GITLAB_RUNNER_DISABLE_SKEL=true; sudo -E yum install gitlab-runnerНастройка GitLab Runner
В этом разделе будет рассказано о том, как создать и настроить свой экземпляр GitLab Runner, который будет вызывать Liquibase.
Ссылка на официальную документацию по GitLab Runner: https://docs.gitlab.com/runner/configuration/
Для начала, нужно узнать, куда был установлен раннер, и дать ему права на исполнение:
# определяем место установки
which gitlab-runner # /usr/bin/gitlab-runner
# выдаем права на исполнение
sudo chmod +x /usr/bin/gitlab-runnerДалее, нужно создать пользователя для сервиса раннера и установить демона. Вполне возможно, что эти шаги уже были выполнены при установке.
# создаем пользователя
sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
# запускаем демона
sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runnerУправлять сервисом раннера можно по аналогии с systemctl:
# статус сервиса
sudo gitlab-runner status
# запуск сервиса
sudo gitlab-runner start
# останов сервиса
sudo gitlab-runner stop
# получения списка зарегистрированных раннеров
sudo gitlab-runner listПосле завершения настройки сервиса GitLab Runner нужно создать экземпляр раннера для запуска Liquibase. Для этого воспользуемся командой register, но перед этим нам нужно получить токен для нашего проекта в GitLab.
Переходим в интерфейсе GitLab в раздел Settings ⇨ CI/CD ⇨ Runners. Здесь мы видим список доступных нам раннеров, которые либо привязаны к группе проектов, либо к конкретному проекту. У меня этот список выглядит примерно так (немного законспирировал имена):

Нас интересуют два пункта:
Адрес вашего GitLab. Раннер будет обращаться к нему для получения исходников и команд на запуск джобов.
Токен для регистрации раннера. По нему раннер будет связан с нашим проектом или группой, если происходит настройка раннера для группы в целом.
Также у каждого раннера вы можете видеть теги, выделенные синим цветом. Это своего рода метки, по которым определяется, будет ли использовать раннер для конкретного джоба, об этом подробнее будет рассказано ниже. Пока достаточно знать, что раннер будет запущен, если его теги содержат теги джоба.
Регистрация раннера
Для создания раннера нужно выполнить команду sudo gitlab-runner register
Вас попросят ввести следующие параметры:
Enter the GitLab instance URLВводим адрес вашего GitLab
Enter the registration tokenВводим токен
Enter a description for the runnerВводим имя раннера, например, my-awesome-runner
Enter tags for the runnerВводим теги раннера через запятую. Пример: liquibase,dev
Выбор можно позже изменить через интерфейс GitLab CI/CD
Enter an executorВыбираем механизм исполнения раннера. Подробнее по ссылке.
Вводим shell
shell – это простейший механизм исполнения команд оболочки целевой ОС. Мы будем использовать скрипты на bash.
После регистрации раннера можно проверить его наличие через команду sudo gitlab-runner list или через интерфейс GitLab CI/CD:

Настройка CI/CD
Информация о том, что делать в процессе CI/CD хранится в файлах проекта. Главным является файл .gitlab-ci.yml в корне. Остальные файлы, в нашем случае скрипты на bash, размещаются на усмотрение разработчика, например, в папке /ci.
Все тонкости конфигурации тянут на отдельную статью, да и опыта в данной области у меня маловато, но то, что использовано в тестовом проекте, будет разложено по полочкам.
Для начала отмечу, что есть встроенный линтер для файла .gitlab-ci.yml, доступный по относительному пути ci/lint в проекте, например: https://gitlab.example.com/gitlab-org/my-project/-/ci/lint. Рекомендую воспользоваться им перед пушем конфига. Также предполагается, что вы знакомы с форматом YAML.
Полный листинг конфига в тестовом проекте:
variables:
LIQUIBASE_VERSION: "4.3.4"
stages:
- deploy
deploy-dev:
stage: deploy
tags:
- liquibase
- dev
script:
- 'bash ./ci/deploy-db.sh $DEV_DB $DEV_DB_USER $DEV_DB_PASS'
environment:
name: dev
only:
- dev
deploy-prod:
stage: deploy
tags:
- liquibase
- prod
script:
- 'bash ./ci/deploy-db.sh $DEV_DB $DEV_DB_USER $DEV_DB_PASS'
environment:
name: prod
when: manual
only:
- prodПеременные
Документация: https://docs.gitlab.com/ee/ci/variables/README.html
variables:
LIQUIBASE_VERSION: "4.3.4"В этом блоке описаны переменные окружения, которые в дальнейшем можно использовать в скриптах. Переменная LIQUIBASE_VERSION указывает на версию Liquibase, которая будет применяться для наката скриптов миграции. Если мы захотим сменить версию, просто установим новую версию Liquibase и поменяем значение этой переменной.
На самом деле, лучше описать эту переменную в настройках проекта, о чем мы поговорим далее, но это просто пример того, как можно использовать переменные в конфиге.
Переменные проекта можно настроить в разделе Settings ⇨ CI/CD ⇨ Variables.
Пример того, как выглядят переменные в интерфейсе:

Помимо переменных, описанных в непосредственно и конфиге и в настройках проекта, существует целый ряд предопределенных переменных, относящихся к процессу CI/CD, таких как имя коммита, ветки или имя пользователя, совершившего коммит. Они могут быть полезны для настройки обратной связи, например, для автоматических уведомлений по результатам деплоя.
Этапы (stages)
stages:
- deployВ этом блоке перечисляются этапы деплоя, о которых рассказано в разделе описания схемы работы.
Джобы (jobs)
Рассмотрим на примере джоба деплоя на дев:
deploy-dev:
stage: deploy
tags:
- liquibase
- dev
script:
- 'bash ./ci/deploy-db.sh $DEV_DB $DEV_DB_USER $DEV_DB_PASS'
environment:
name: dev
only:
- devСтрока stage: deploy указывает на этап, к которому относится данный джоб.
Теги перечислены массивом, т.е. это liquibase и dev. Наш ранее созданный раннер отреагирует на эти теги и запустит скрипты в разделе script. Важно отметить, что в джобе прода указан тег prod, поэтому раннер для него должен быть отдельный, исходя из соображений, что он, вероятно, находится в другой сети. А вообще, один и тот же раннер может обслуживать несколько проектов, если это требуется.
Блок environment указывает на окружение, которое можно настроить в отдельном разделе по пути Operations ⇨ Environments. Это своего рода дашборд ваших стендов (дев, предпрод, прод и т.п.), где можно увидеть их статус и выполнить, например, ручной деплой. Также можно настроить переменные, привязанные к окружению, но это премиум-фича, которую мне попробовать не удалось.
Пример страницы окружений:

Блок only указывает, для каких веток нужно применять данный джоб. Его братом является блок except, который указывает для каких веток джоб применять не нужно. Помимо веток можно настроить более сложные условия: https://docs.gitlab.com/ee/ci/jobs/job_control.html.
Для прода мы также указали when: manual. Это означает, что запуск деплоя для прода будет в ручном режиме при нажатии на кнопку в пайплайне, а не в момент коммита. Это позволит нам собрать чемодан до того, как что-то пойдет не так выполнить деплой в запланированное время.

Скрипт наката
В блоке script мы указываем список скриптов, которые будут выполнены раннером. Так как у нас shell-исполнитель на линуксе, будем использовать bash. Все переменные автоматически передаются в скрипт в виде переменных окружения, но т.к. реквизиты базы отличаются для разных стендов, передаем их непосредственно при вызове скрипта.
Разберем непосредственно скрипт вызова Liquibase:
#!/bin/bash
echo "Environment: $CI_ENVIRONMENT_NAME"
cd db/changelog
/usr/share/liquibase/$LIQUIBASE_VERSION/liquibase \
--classpath=/usr/share/liquibase/$LIQUIBASE_VERSION/drivers/ojdbc10.jar \
--driver=oracle.jdbc.OracleDriver \
--changeLogFile=master.xml \
--contexts="$CI_ENVIRONMENT_NAME" \
--defaultSchemaName=STROY \
--url=jdbc:oracle:thin:@$1 \
--username=$2 \
--password=$3 \
--logLevel=info \
updateПодробно параметры вызова Liquibase описаны в соответствующем разделе.
Переменные DEV_DB, DEV_DB_USER, DEV_DB_PASS приходят в скрипт в виде $1, $2 и $3 соответственно. Помимо них мы используем указанное в джобе имя окружения, которое приходит в предопределенной переменной $CI_ENVIRONMENT_NAME, что можно использовать, чтобы какие-то скрипты накатывались только на определенном стенде, а не на всех.
Если все настроено правильно, то после коммита конфига и скриптов в гит, заработает деплой.
Успешный лог пайплайна для Liquibase выглядит примерно так:
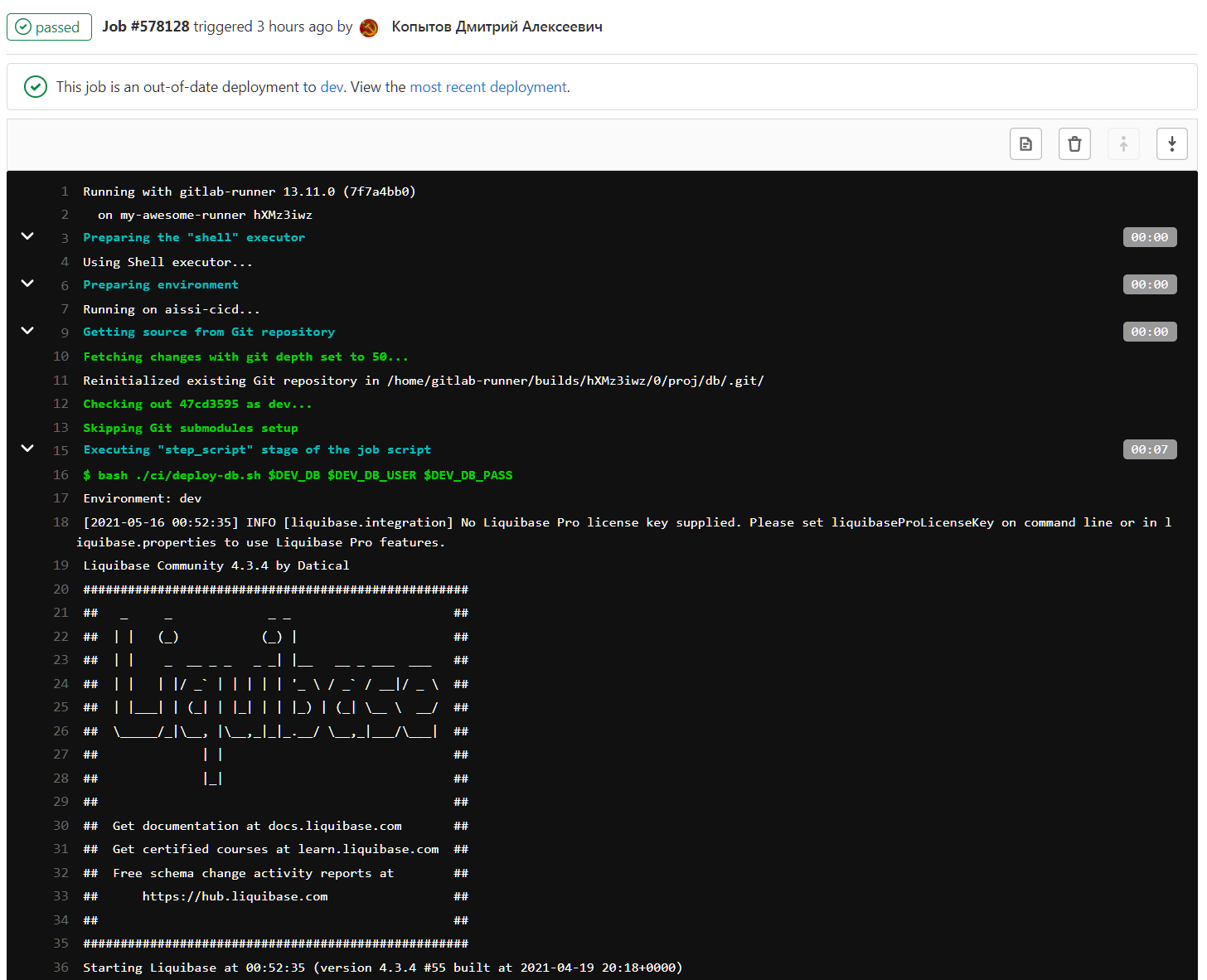
Отклонение мержей с ошибками
Если процесс деплоя пойдет с ошибками, можно не допустить соответствующий мерж. Особенно это полезно, если в CI/CD встроены тесты как отдельный этап. В нашем примере тестов нет, но Liquibase тоже может сломаться, если, например, указаны неверные пути до файлов.
Для запрета ошибочных мержей нужно установить галочку в разделе General ⇨ Merge requests.
Важно! Галочку нужно устанавливать после настройки CI/CD, иначе перестанут проходить любые мержи.

Заключение
Статья оказалась большой, но это не должно вас пугать. На самом деле мне удалось с нуля и без каких-либо предварительных знаний разобраться и настроить проект с деплоем примерно за 5 часов времени в пятницу вечером. Очень надеюсь, что данная статья поможет вам освоить деплой быстрее, а кого-то направит на путь CI/CD.
Если какие-то моменты остались за кадром, и есть желание узнать о них подробнее, пишите в комментариях. Буду иметь в виду, но обещать ничего не стану, т.к. эта статья, например, отняла у меня более 20 часов времени в течение трех недель, что в два-три раза больше среднего времени на написание статьи.
Как обычно, если понравилась статья, посмотрите другие:
Интересная статья, обязательная к прочтению: Умный парсер числа, записанного прописью
Автоматическое обновление скриптов после деплоя
Классовая сериализация на JavaScript с поддержкой циклических ссылок


