
Привет, меня зовут Петр и я работаю в Badoo в команде биллинга. В этой статье я хочу поделиться своим опытом работы над пет-проектом по созданию хранилища фотографий с возможностью поиска дубликатов. Я расскажу, с каким багажом я вошел в этот проект, в чем заключалась задача и как её решал. В конце поделюсь результатами и почему я считаю, что это один из лучших проектов, которым я занимался.
Однажды мои знакомые попросили сделать им хранилище изображений для их проекта по модерации внешних ресурсов. Условия: срок хранения до трех лет, фотографии при этом присылаются неравномерно, в среднем поток — 150.000 картинок в сутки.
Казалось бы, достаточно банальная задача. Если бы не еще одно условие: хорошо бы сопоставлять фотографии с уже имеющимися: искать дубликаты и помечать их.

Начну с того, что есть два класса дубликатов. Первый — это миниатюры, то есть одно и то же изображение, которое растянули или сжали. Второй класс назовем полудубликатами. Это изображения, которые получены из оригинала с более серьезными изменениями. Типичный пример: отрезали у изображения верх с водяным знаком и добавили свой:

Эти полудубликаты нас и интересовали: мы хотели сопоставлять именно этот класс. Но мне было неясно, как решить эту задачу, пока я не наткнулся на теорию о ключевых точках, которой очень загорелся, воспринял как личный вызов и активно ею занялся. Кратко расскажу, в чем заключается теория и как она позволила нам сравнивать полудубликаты.
Ключевые точки
Ключевая точка — это некоторая особенность изображения, где что-то происходит. Например, изменение контраста, который проявляется на углах и гранях. Есть очень много алгоритмов, которые позволяют выделить эти ключевые точки, и все они работают по-разному. На одном изображении они выдадут разное количество точек да и сами точки будут отличаться. Но, как правило, все они возвращают массив из структуры из трех параметров, x, y и q, где
x, y — координаты этой самой точки на картинке;
q — это некоторый параметр, который определяет качество этой точки, то есть насколько сильным было изменение.
Для сравнения алгоритмов я ввел для себя такое понятие как покрытие. Взял набор картинок из 10.000, разбил каждую на области 16х16 пикселей и посмотрел, в какой процент таких областей попадает хотя бы одна ключевая точка:
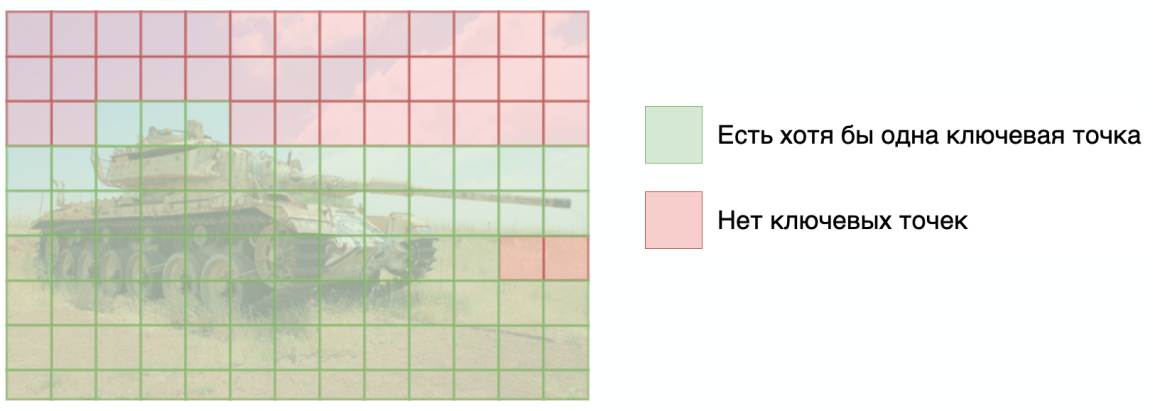
Это было нужно, чтобы выбрать алгоритм, который лучше всего описывает тестируемые мной изображения. Если в область не попадает ни одна ключевая точка, то сравнивание в этой области проводится не будет. И чем больше таких областей, тем менее точный поиск будет. В результате я получил большую таблицу, но основные алгоритмы выделились следующие:
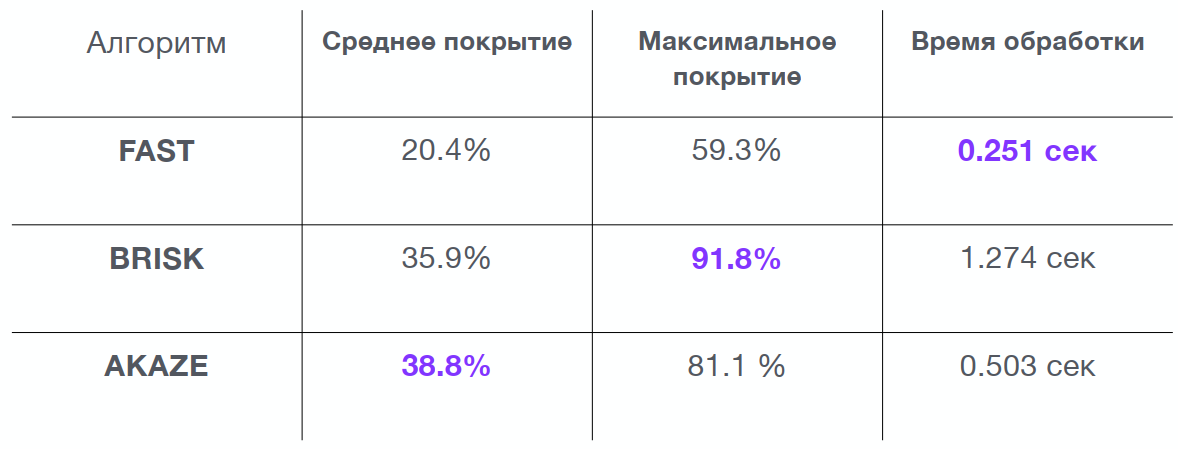
Исходя из таблицы, я выбрал алгоритм AKAZE: у него хоть и не самое высокое максимальное покрытие, но хорошее среднее значение и приемлемое время обработки. Стоит обратить внимание: выделение ключевых точек и анализ по этому алгоритму занимает полсекунды, что достаточно много при большом объеме изображений.
Анализ изменений
Итак, мы нашли локальную особенность на картинке. Теперь ее надо как-то описать, и в качестве примера я приведу принцип работы самого простого алгоритма — BRISK. На вход мы передаем алгоритму координаты x и y, и тот разбивает область диаметром в 30 пикселей вокруг этих координат на множество мелких частей. Дальше алгоритм бинарно сравнивает эти части между собой. Производится 512 вычислений, в результате мы получаем вектор длиной 512 бит, то есть для описания области диаметром 30 пикселей у нас уходит 64 байта. Этот вектор дальше будет называться дескриптором.
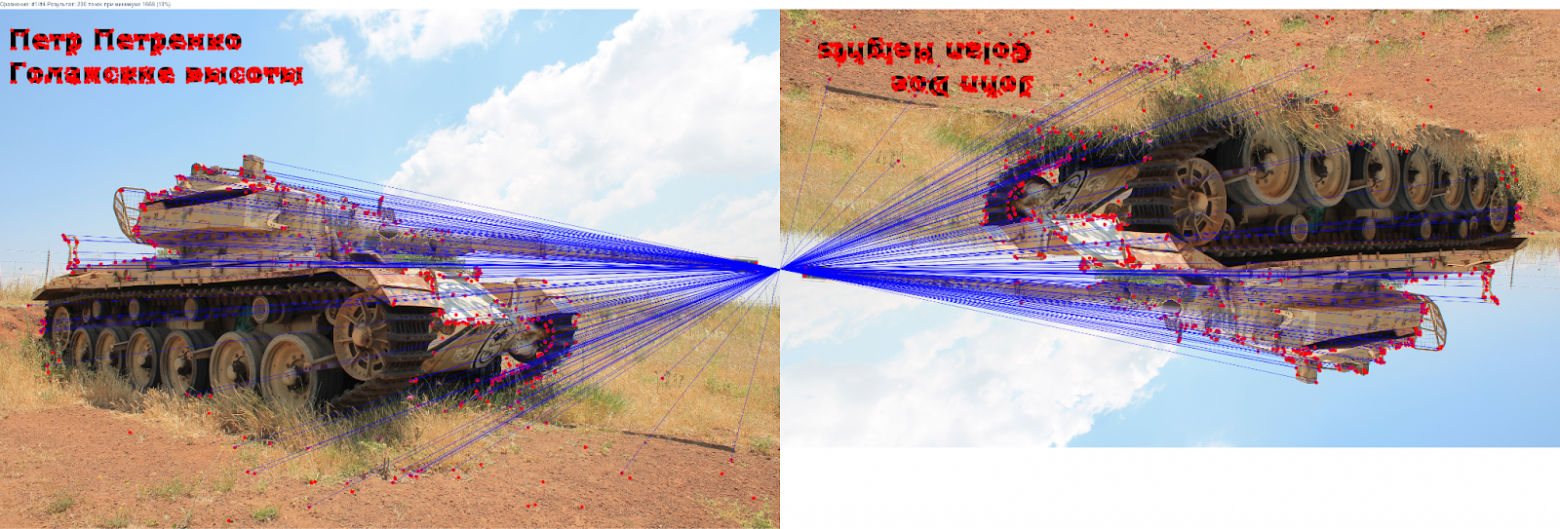
Теперь мы можем выделить ключевые точки по обоим нашим изображениям, посчитать дескрипторы и получить их массив для одного и второго изображения. И, сравнив эти строчки побитово, найти пары. Если это сделать аккуратно и визуализировать, то можно получить вот такую вот картинку:

Все алгоритмы достаточно сложны, чтобы нивелировать изменения, в частности поворот. Поэтому если просто перевернуть изображение, то ключевые точки также сопоставляются.
И вроде бы всё хорошо, но возникает другая проблема: такое прямое сравнение хорошо работает, только если изображение было сохранено без потери качества или масштабирования. Иначе появляются ошибки и дескрипторы не сопоставляются. Чтобы это исправить, я использовал одну интересную функцию.
Расстояние Хэмминга
Эта функция, которая говорит, сколько у нас есть позиций, где две строки одной длины отличаются. Рассмотрим пример:
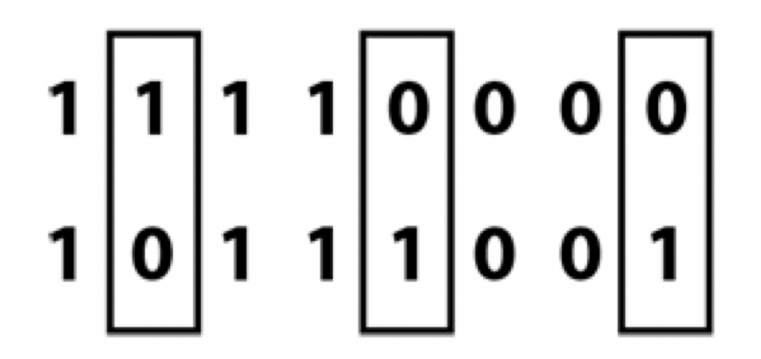
Видно, что две бинарные строки отличаются в трех позициях, то есть расстояние Хэмминга между этими двумя строками будет равно трем. Это расстояние для простоты я буду называть дальше также ошибкой.
Выбор дескриптора
Теперь, учитывая расстояние Хэмминга, мне было нужно выбрать подходящий алгоритм. К этому времени в базе проекта было собрано много изображений, и я скриптом создал для 10,000 картинок их различные модификации: обрезал сверху или снизу, именил размеры, добавленный текст. Полученные картинки сопоставил, чтобы сравнить заведомо похожие и заведомо не похожие изображения.
Потом я построил графики для каждого алгоритма, где видно, что чем большую ошибку (расстояние Хэмминга) мы допускаем, тем больше получаем положительных, но и ложноположительных сопоставлений:
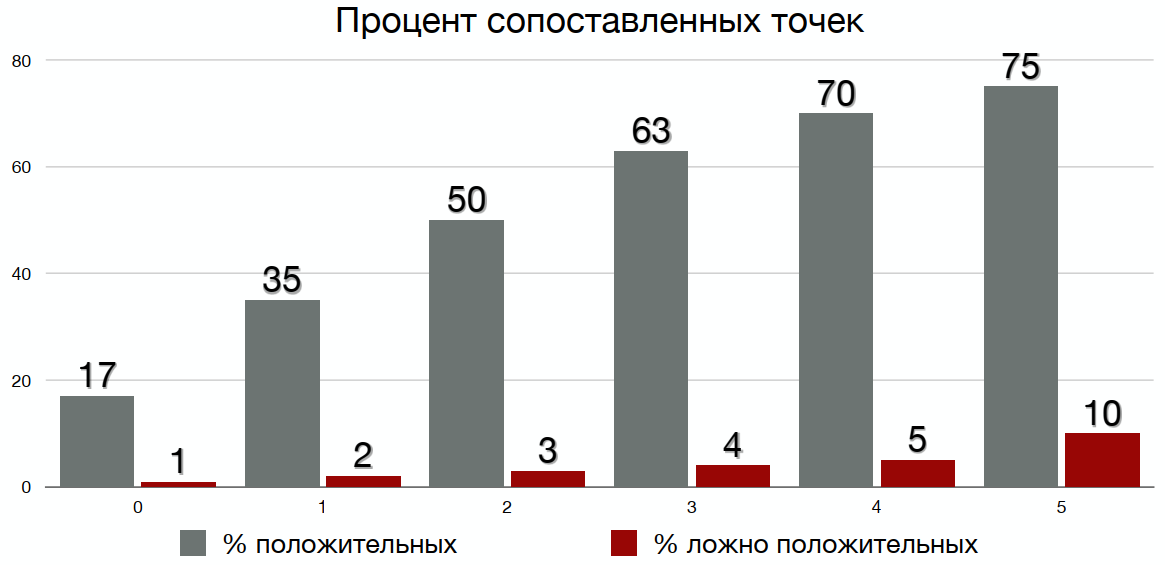
Разделив один график на другой, можно получить оптимальное расстояние Хэмминга, при котором максимально соотношение положительных к ложноположительным сопоставлениям. Например, для выбранного мной алгоритма получилось 3:
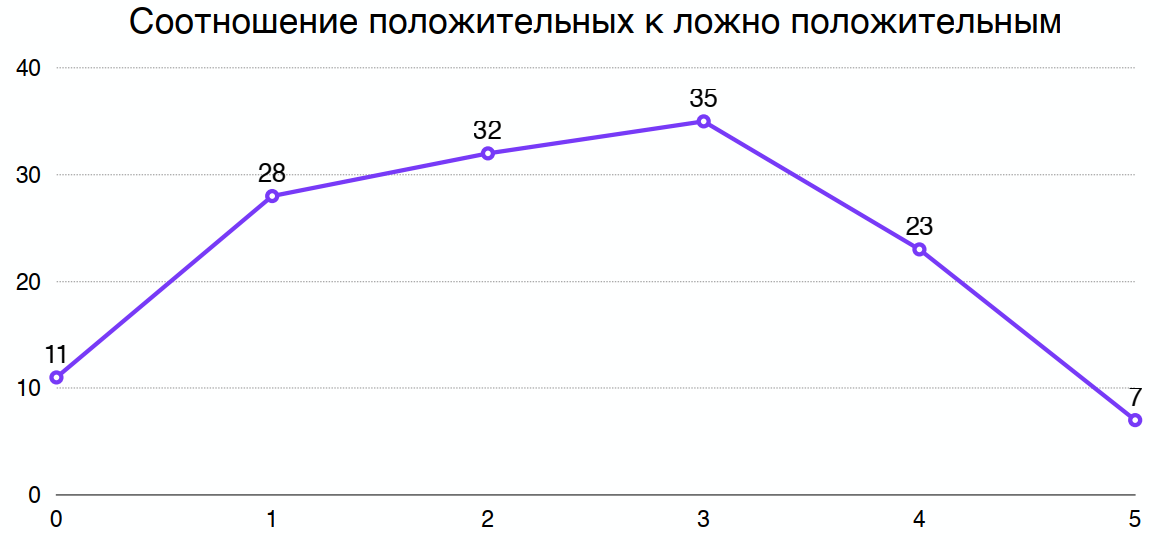
Выбирая алгоритм я также смотрел на процессорное время которое требуется на обработку изображения алгоритмом. А еще — на длину дескриптора, у разных алгоритмов его длина различна. Одно дело 8 байт, другое дело 64 на одну ключевую точку, которых будут миллиарды.
Итак, мы смогли сопоставить точки и даже нивелировали какую-то погрешность. Какие изображения теперь можно считать похожими?
Критерии
Во-первых, я пришел к выводу, что если у фото меньше 10 ключевых точек, то это, как правило, очень низкокачественные изображения. Их я просто отбрасывал, помечая как некачественные.
Во-вторых, картинки можно считать похожими, если пересечений больше 20% от возможного. Например, в одном изображении 100 ключевых точек, в другом — 200. Максимум может пересечься 100 точек, и, соответственно, достаточно 20 сопоставленных дескрипторов, чтобы эти два изображения признать похожими.
После того как мы научились сравнивать картинки, осталось только научиться искать одну в большой базе.
Как искать похожие изображения
Первой идеей был линейный поиск. Он очень простой: берем картинку и сравниваем с первой, а потом — со второй, третьей и так далее, пока они не закончатся. Номера тех что совпали — возвращаем как достигнутый результат. Но линейный поиск был вскоре отброшен. При линейном поиске с ростом базы в 2 раза время на обработку вырастает в те же 2 раза, что в итоге оказалось слишком много уже на базе в миллион.
Тест скорости:
Загружен 1 миллион изображений;
Получено примерно 350 миллионов ключевых точек;
База занимает 10 ГБ (то есть одна картинка в таком индексе занимает примерно 10 Кб).
Поиск одной ключевой точки — 47 секунд, а поиск всего изображения — 4,5 часа. Напомню, что в изначальной постановке задачи в день добавляется порядка 150 тысяч новых изображений — получится либо очень долго, либо нужно безумное количество серверов (чего не было).
Дальше я опробовал много других методов: например, HEngine, VP-деревья и разные специализированные движки. Все, кроме последних, я реализовывал на PHP. Но проблема оказалась не в производительности языка, а в алгоритмической сложности задачи, которую я пытался решить. И наконец одна интересная структура помогла мне найти решение.
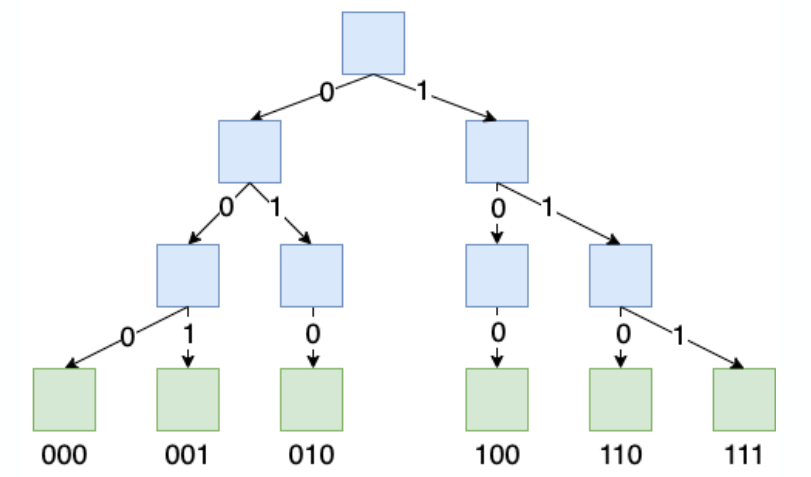
Префиксное дерево
Это дерево, в котором ключ закодирован не значением в самом узле, а путем до этого узла. В префиксном дереве есть два типа узлов. Голубым я отметил узлы, которые хранят информацию только о дочерних узлах. Зеленым — те, что хранят конечную информацию, это может быть какое-то значение, массив, указатель, всё что угодно.
Вот пример префиксного дерева, где закодированы 6 строк длиной в 3 бита:
Теперь разберемся, как можно в префиксном дереве искать с допустимой ошибкой. Например, нам нужно найти все строки которые отличаются от 010 на 1 бит. То есть мы допускаем только одно искажение в любом бите:
Сначала мы идем с корня, в котором пока накоплена ошибка 0, в узел и дальше по ветке 0. Она совпадает с нашим первым битом, поэтому накопленная ошибка не увеличивается.
Идем в следующий 0, а он уже отличается от нашего второго бита, поэтому накопленная ошибка становится 1.
Она не превышает максимально допустимую, поэтому мы продолжаем рассматривать решение и так, идя по ветке 0, доходим до самого низа. Если накопленная ошибка у нас остается равной 1, то мы признаем решение успешным.
Возвращаемся наверх и идем по ветви 1. Так как она отличается от нашего последнего бита, то ошибок становится две, то есть данное решение нам не подходит.
Дальше пробегаем вторую ветку и переходим на вторую половину дерева. И итоге нам подойдут три значения: два из них с искажением в 1 бит:
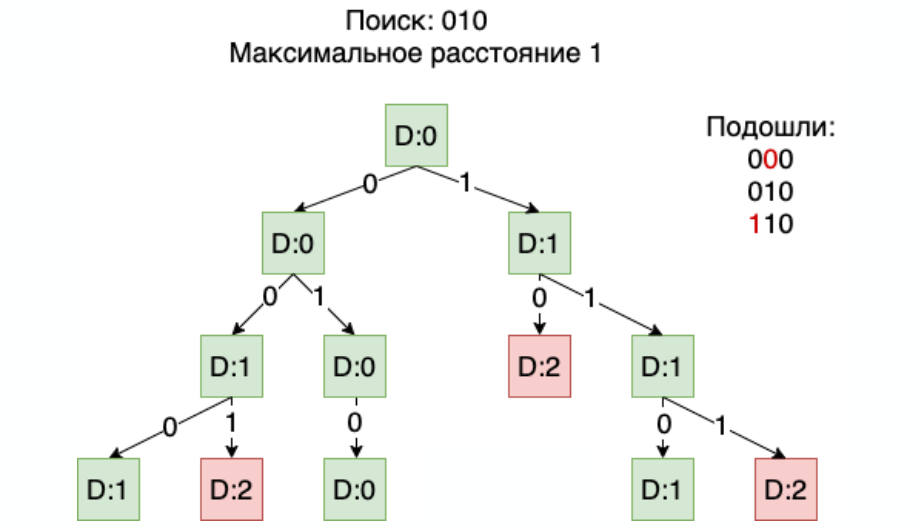
Смысл в том, что когда ошибка достигает максимального значения, глубже по дереву спускаться уже не нужно. Ошибка может только расти, и если она достигла какого-то максимального значения, то дальше будет только хуже. В результате поиск начинает работать очень быстро, даже если у дескриптора 512 уровней. А при росте количества элементов скорость с какого-то момента просто превращается в константу и никуда не двигается.
Таблица, которая у меня получилась при сравнении дерева с линейным поиском:
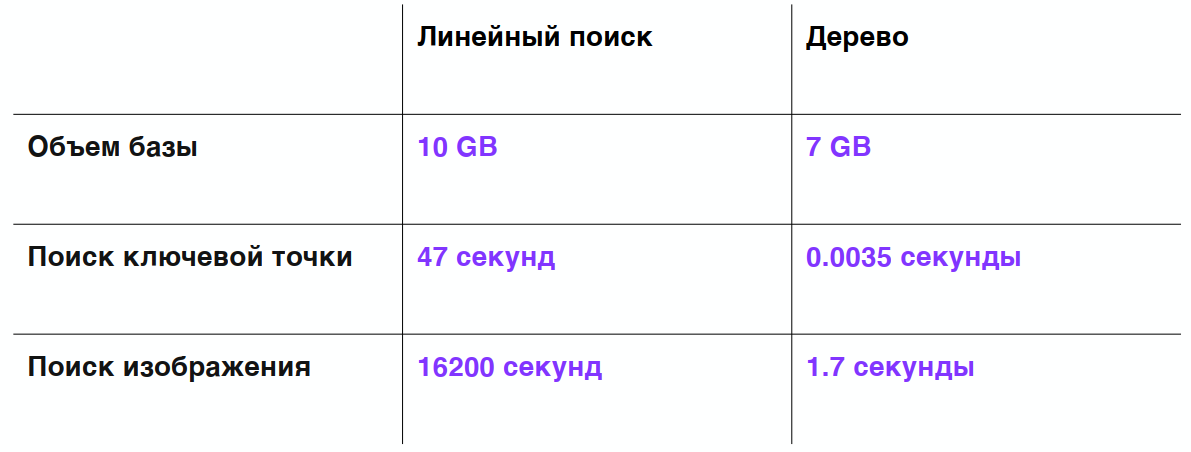
Видим, что на той же базе в 1 млн изображений размер базы внезапно уменьшился на 3 ГБ. Почему так произошло? Потому что префиксные деревья изначально делают дедупликацию данных, и поиск одной ключевой точки вместо 40 секунд стал занимать всего 3,5 мс. А поиск одного изображения стал быстрее в десять тысяч раз!
Конечно, чтобы обрабатывать 150 тысяч изображений в день, обработка должна проходить за полсекунды. Но никто не мешает искать в префиксном дереве во множестве потоков — и тем самым увеличивать скорость. Первая версия префиксное дерева была реализована на PHP, и она так быстро работала за счет удачно подобранного алгоритма.
На мой взгляд, префиксные деревья — это очень недооцененная структура данных в современном мире. Те же индексы: если у вас какое-то значение закодировано строкой и в данных мало энтропии — префиксные деревья будут занимать гораздо меньше памяти, чем двоичные деревья, которые используются в современных реляционных базах данных. Когда я использовал в Postgres префиксные деревья для индексов, мне удавалось уменьшить размер индекса в среднем в два раза.
Префиксное дерево может давать еще такой интересный эффект как рекомендации. Поскольку мы можем искать с какой-то допустимой ошибкой, а у вас, допустим, есть миллиард товаров или каких-то объектов, чье качество кодируется битами — то вы можете поискать и предложить объект, очень похожий на тот, что изначально искал пользователь.
Перейдём от теории к практике.
Реализация проекта
Хранение изображений
В первой итерации я просто складывал файлы на диск. Но когда картинок стало несколько миллионов, то выяснилось, что бэкапить такие данные, переносить и анализировать очень сложно. Поэтому в итоге была собрана такая схема:
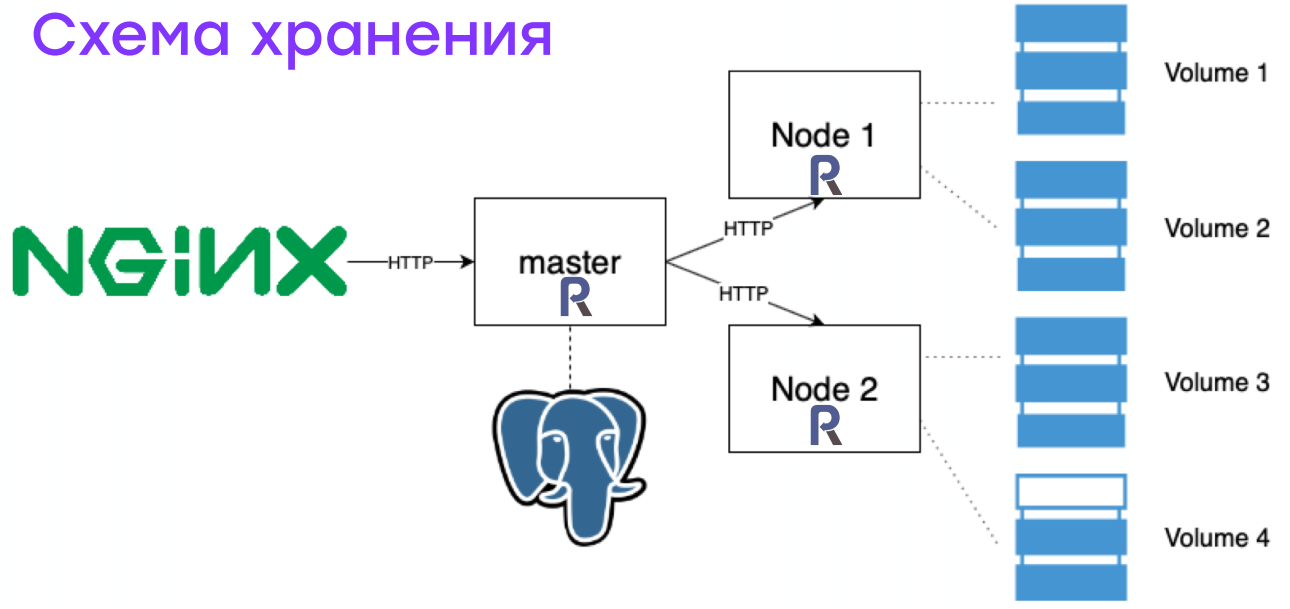
NGINX принимает запрос и пересылает его демону, написанному на ReactPHP. Демон с помощью данных, хранящихся в реляционных базах данных, понимает: что это за картинка, на каком сервере она хранится, в каком устройстве, с каким смещением и какого объема. Эта информация передается нужному серверу, который просто читает с блочного устройства нужное количество байт с нужным смещением.
Это дает очень большой прирост к производительности, особенно на задачах массовых данных, когда одновременно надо делать бэкап, пересчитывать все картинки для индекса или переносить их. Но даже одно чтение может проходить в десять раз быстрее.
Это решение пришло мне из системы резервного копирования Bacula. Как следствие, я понял, что ленточные носители очень удобно бэкапить, и при современных ценах на жесткие диски это вышло очень недорого (напомню, что проект был личным, много делалось на энтузиазме, поэтому позволить себе какие-то дорогие решения мы не могли).
Как выглядел кластер
При поиске одной картинки в префиксном дереве происходит примерно 10 тысяч операций чтения памяти для одной ключевой точки, то есть операций чтений из разных случайных блоков. Поэтому данные обязательно должны храниться в памяти, с диска читать такое количество данных невозможно. Но, конечно, рано или поздно заканчивается память. Где-то на 30 миллионах, заняв все 128 ГБ оперативной памяти, нам пришлось переходить к шардированию:
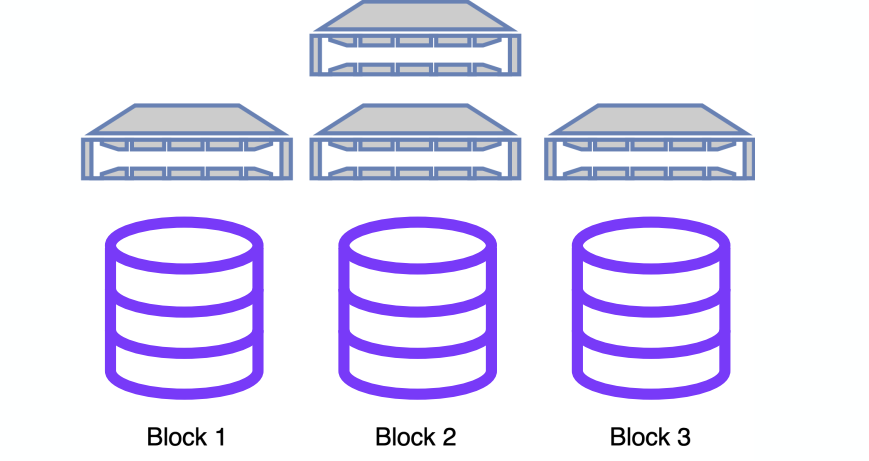
Для данного алгоритма это не проблема, но все ключевые точки одного изображения должны лежать в одном блоке. После чего данные разбиваются по разным блокам. Каждый блок может обслуживаться своим отдельным сервером или группой серверов. Всё это позволяет достигнуть отказоустойчивости и линейно повышать скорость поиска.
Как происходит поиск
Конвейер поиска выглядит достаточно просто. Есть некоторый PHP-демон, который успешно живет месяцами. Он принимает на вход картинку и отправляет ее на кластер, который выделяет ее ключевые точки. Так как картинки могут приходить очень большими пачками, то их нужно обрабатывать максимально быстро — поэтому этим занималось несколько узлов.
Дальше полученные ключевые точки отправлялись во все блоки, и один из обслуживающих блок серверов брал на себя задачу найти id всех похожих изображений и отправить их мастеру. Который компилировал эту информацию:

Вставка работала примерно также, но с единственным различием: запись происходила через демон ReactPHP и только в один блок, в зависимости от внутренней логики. У меня использовалась round-robin:

Результаты
Нам удалось достичь поиска 98 перцентиля (95% изображений) за 8 секунд. Но при большом количестве потоков это работало очень быстро. Кластер спокойно искал 200 фотографий в день, что позволяло с запасом решать наши задачи.
Всего у нас было 150 млн изображений на 18 ТБ, и в пики их обслуживало 9 узлов. Почему я говорю про пики? По мере того как мы узнавали что-то новое, нам удавалось оптимизировать расходы и оборудование. В конце у нас был узел, который имел на борту 768 ГБ оперативной памяти. Он держал почти весь индекс, который составлял 790 ГБ, но его стоимость была сопоставима с топовым игровым компьютером. Никаких заоблачных цен.
К сожалению, в прошлом году проект был закрыт, но я совершенно не жалею, что работал над ним. Потому что до этого я жил в некой парадигме, что PHP подходит только для сайтов. Как только вам нужно что-то серьезное или большое, то нужно использовать любой другой язык. Мой взгляд изменился, потому что почти всё в этом проекте было написано на PHP. Только один маленький кусочек был переписан на С — мультипоточность для дерева.
Я получил огромный опыт работы с распределенными вычислениями. Этот опыт до сих пор мне полезен. Я активно ищу и помогаю решить задачи в Badoo, связанные именно с этим, поскольку у нас очень большая инфраструктура. Пока я этим занимался, я много читал про базы данных, и многие мои решения были почерпнуты из документации Postgres и MySQL. У меня теперь есть уверенность в том, что почти любую задачу можно решить, если подойти к ней системно и выделить для этого достаточно времени.
К тому же, я очень интересно провел время, потому что люблю программировать. Мне интересно решать очень сложные задачи. Эта задача, наверное, была одной из самых сложных. Причем не только технических: непросто было не опускать руки каждый раз, когда я натыкался на новые проблемы и думал, что теперь точно конец, ничего больше нельзя сделать.
Что я хочу сказать напоследок? Хочу пожелать всем найти свой пет-проект, который так же как и меня в свое время, увлечет на пару лет и поможет круто прокачаться.
Конференция PHP Russia 2022 — отличное место, где можно рассказать о своём опыте сообществу. Она пройдет 12 и 13 сентября в Москве, в Radisson SAS Славянская. В центре внимания: развитие экосистемы (сам PHP, стандарты, фреймворки, библиотеки, OpenSource); опыт крупных компаний для построения на PHP сложных проектов и лучшие практики. И, конечно, темы повседневной разработки.
До 25 мая идет прием заявок на выступления. Оплачиваются расходы на дорогу и проживание спикеров. Все подробности на сайте.
")



