
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, Хабр! Меня зовут Роман Тезиков, я Data Scientist, специализируюсь на Computer Vision в Lamoda.
В R&D Lamoda мы постоянно имеем дело с различного рода рекомендациями. Когда покупатели не знают, какая вещь им нужна, они формируют ее абстрактный образ и пытаются найти что-то похожее с помощью привычных инструментов поиска. На сегодняшний день нейронные сети отлично справляются с задачей распознавания образов. Мы поставили перед собой цель — переосмыслить процесс выбора одежды с учетом Computer Vision. И сегодня я расскажу:
- какие проекты мы делаем с помощью компьютерного зрения;
- как учим сети распознавать одежду и даже оценивать стиль;
- с какими особенностями индустрии мы уже столкнулись;
- какие у нас планы на будущее.
В процессе мы научились решать задачу из знаменитого фильма «Бриллиантовая рука», где главный герой просит найти такое же платье, но с перламутровыми пуговицами.

Зачем компьютерное зрение нужно в индустрии моды
Для начала разберемся, что включает в себя Computer Vision в fashion-индустрии. Исследователи разделяют его на четыре группы.

Detection включает в себя, например, поиск объектов одежды на изображениях. Или Landmark Detection, где мы учим нашу сеть искать конкретные сочленения на одежде (рукава, плечи, колена и т.д). Item Retrieval — поиск одежды по текстовому или визуальному запросу.
Recommendation. Например, в корзине есть несколько разных видов одежды, которые можно проверить между собой на сочетаемость. В качестве рекомендации покупатель получает целый комплект одежды на примерку. Или другой случай: у пользователя есть история покупок, по которой мы способны вычленить общий стиль или группу стилей. Рекомендации в таком случае будут выдавать одежду в наиболее похожем по предпочтениям клиента стиле.
Synthesis — это любая генерация одежды на изображении. Например, виртуальная примерка товаров на изображении с вами. Может включать трансформацию позы, чтобы посмотреть со всех сторон, как на вас будет смотреться кофточка :) На Lamoda, например, уже есть возможность виртуальной примерки обуви через приложение.
Analysis — это все, что связано с трендами в одежде: поиск популярных товаров, нахождение зависимости в том, как они выглядят, анализ атрибутов.
Хочу платье-смокинг из Инстаграма: как используется CV в Lamoda
Компьютерное зрение появилось в Lamoda в начале декабря 2020. Наше преимущество — наличие своей фотостудии, а это целая фабрика по производству контента. Здесь готовят все съемки компании: от каталога до креативной рекламы. Студия работает без выходных, обрабатывая около 3 500 уникальных единиц (SKU) и 15 000 фото ежедневно.
При выборе одежды пользователи Lamoda часто пользуются фильтрами: выбирают нужную длину изделия, тип выреза, цвет или принт. Однако характеристик в фильтрах часто недостаточно для уточнения фасона или важных деталей. Например, с помощью таких фильтров сложно найти какое-нибудь «яркое мини-платье для диско 90-х» или «модные платья-смокинги из инстаграма».
Частично эту проблему решает визуальный поиск: в приложении Lamoda можно загрузить фото и найти похожие товары по картинке. Но референс все еще нужно найти самому.
В поиске решения задачи подбора товара под смутный образ мы хотели сделать новую функциональность, полностью основанную только на визуальных образах товаров. Никаких списков атрибутов, никаких слов на естественном языке, никаких готовых референсов.
В итоге мы придумали что-то вроде игры «Акинатор», где джин угадывает персонажа, задавая ему вопросы — только вместо вопросов у нас фотографии
товаров. И назвали мы наш инструмент «Лакинатор», где «ла» — отсылка к Lamoda :)
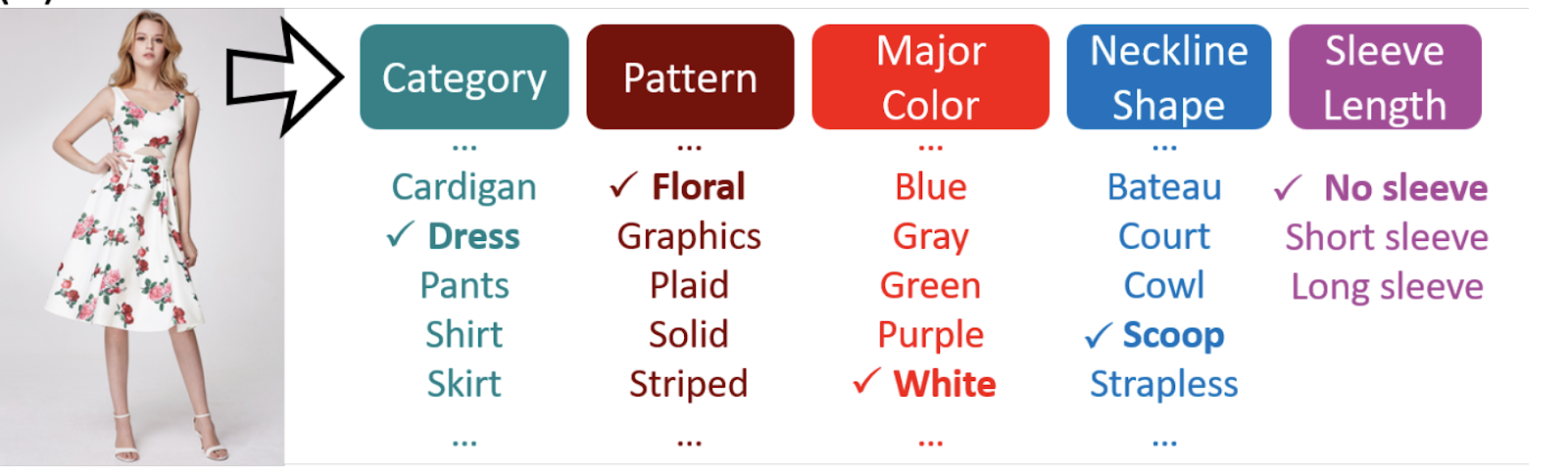
Распознавание и заполнение атрибутов: найди похожие!
Для нашей задачи на картинках всегда много лишнего: лицо модели, ее поза, задний фон, обувь и аксессуары. Мы же хотели научить сеть фокусироваться на содержательно важных факторах платья и обрабатывать эту информацию более детально. Для этого вместо классического автоэнкодинга поставили алгоритму задачу многоклассовой классификации.
Итого понятная нам задача: взять предобученную сеть, поменять ее выход на количество лейблов в нашем датасете и дообучить.
Мы взяли 15 атрибутов для платья. Количество классов для каждого атрибута варьировалось от 3 до 17. Сложности добавляло то, что на платье может быть только один вырез шеи и тип рукава, а другие классы, такие как ткань или цвет, могут присутствовать несколько раз на одном объекте.
Все атрибуты будем учить одновременно, делая предсказания из единого для них вектора. Такое обучение называется многоголовое или multi-head.
Для первого эксперимента взяли старый добрый ResNet — сеть для классификации изображений, созданную исследователями из Microsoft. Для обучения мы собрали датасет из 150 000 изображений с платьями. Оптимизировали нашу нейронку методом Adam.
Сейчас мы экспериментируем с новомодными visual-трансформерами. На картинке внизу показан блок TNT (Transformer-in-Transformer).
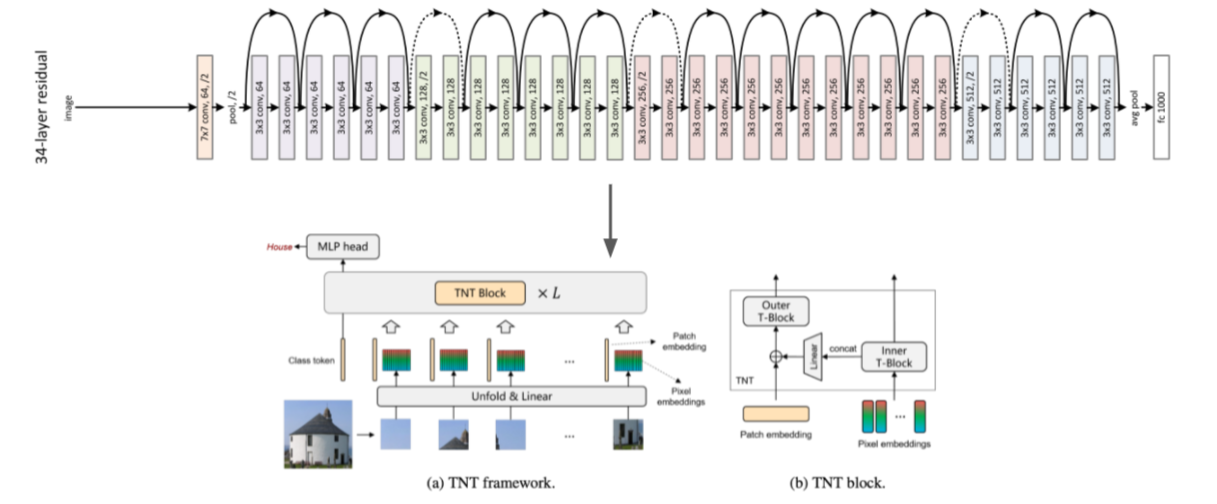
Transformer-in-Transformer — это классификатор изображений, который использует механизм внимания или attention. Подробнее про attention с визуализациями стоит посмотреть в блоге Jay Alammar “The Illustrated Transformer”.
Мы решили экспериментировать дальше. Вытащили из обученной сети результирующие векторы по всем нашим изображениям, затем искали ближайшие векторы к картинке-запросу.

Нейросеть смогла грамотно распределить платья по кластерам. Например, мы предложили ей зеленое платье со средней длиной рукава и круглой горловиной. В ответ получили примерно такие же.
Таким образом, мы решали задачу предсказания атрибутов одежды для «Лакинатора» и автоматически решили задачу визуального поиска. Благодаря этому, можем персонализировать рекомендации — смотреть, какую одежду выбирает человек, и предлагать ему визуально похожие вещи. Также можно искать одежду, которую нельзя выбрать фильтром. Как раз то самое: «Найди мне такую же кофточку, но с перламутровыми пуговицами».
Направление Computer Vision в Lamoda молодое и экспериментальное, но мы уже изначально озаботились об ML-OPS. Было важно сразу делать хорошо: с трекингом кода, гиперпараметров, логированием метрик, конфигурационными YAML-файлами и воспроизводимыми пайплайнами. Для обучения нейросетей используем PyTorch-Lightning и Albumentations. Для подбора гиперпараметров — Optuna. Все параметры моделей храним в конфигурационных файлах через Hydra, логируем в ClearML, а в продакшене запускаем пайплайны через Airflow.
Учимся измерять стиль и сочетать шлепки с костюмом
Другая задача, с которой нам предстояло работать — разобраться, как определить стиль одежды. При покупке вещи люди хотят видеть в рекомендациях одежду в нужном им стиле. Мы получали такие отзывы: «Ребята, я беру только смарт кэжуал, можно мне показывать его?» Или: «Я покупаю только черные балахоны, хочу видеть такие же».
Но выделить по атрибутам, например, романтический стиль не так-то просто. Мы стали разбираться, что такое стиль вообще и как его измерить.
Начали эксперименты с такой же сети-классификатора, но решили обучить ее на другие выходы. Для этого изменили вход — теперь это картинка с несколькими элементами одежды, по которой нужно предсказывать ее стиль: строгий, кэжуал, спортивный, романтический, минимализм.
Проблема оказалась в том, что у стиля нет единого определения. Разметка была очень шумная и во многом зависела от мнения стилиста. Значит, нужно собрать такой датасет из внешних источников.
Мы зафиксировали список стилей и определили поисковые запросы к ним. Всего вышло девять больших категорий:
- классический,
- кэжуал и смарт кэжуал,
- спортивный,
- гламур,
- гранж,
- романтический,
- минимализм,
- милитари,
- авангард.
Картинки искали в Pinterest, Google и Bing. Но после очистки датасета от него почти ничего не осталось. Конечно же, классификатор ничего не выучил, но как же тогда сделать лучше?
Можно исходить из скоринга, насколько элементы одежды сочетаются друг с другом.
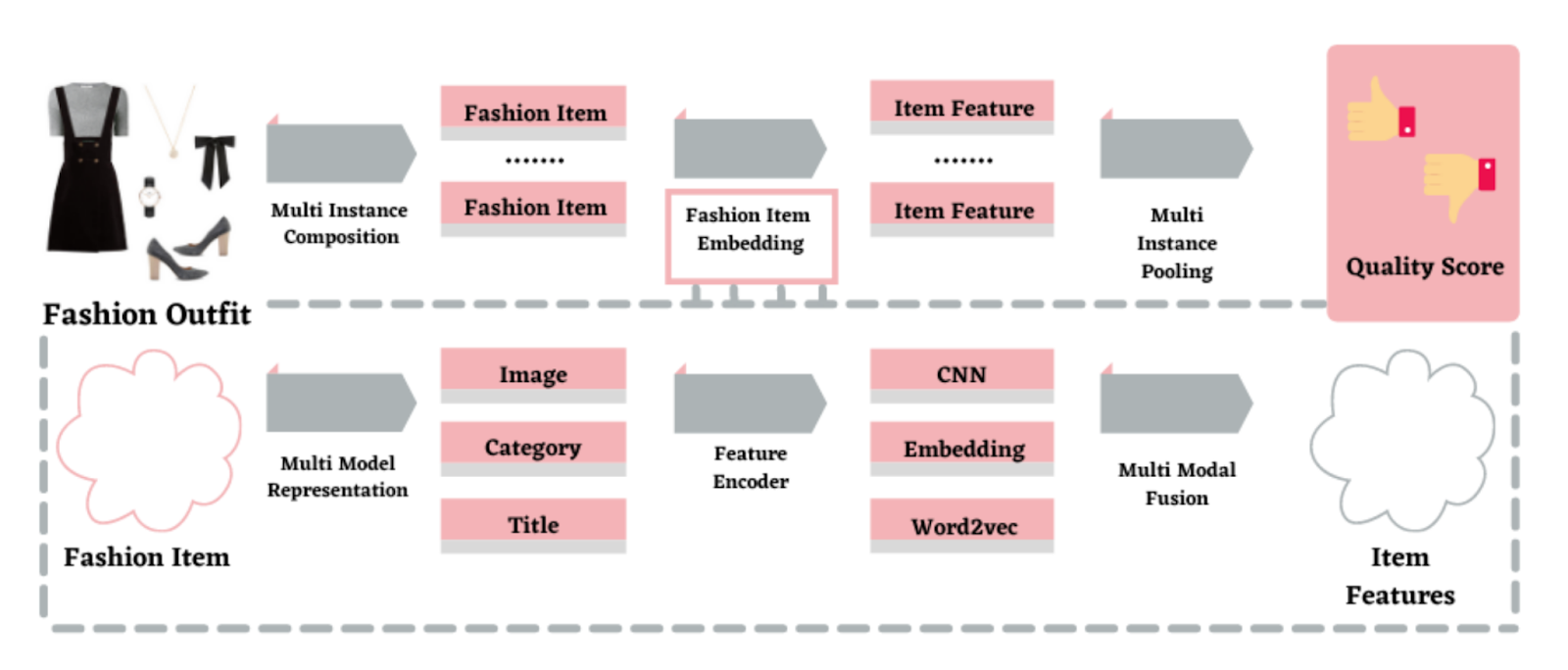
При этом подходе у датасета будет вход — несколько разных элементов одежды, а на выходе классификация «сочетается» или «не сочетается», числовой диапазон (рэнкинг) от 0 до 1. Входные картинки эмбеддятся другой сеткой — кодируются в некий вектор определенной размерности, из которой сеть потом делает предсказания. Давайте обучим такой пайплайн.
Здесь с датасетом было проще. Наши стилисты делают подборки на сайте — по умолчанию мы считаем, что такая одежда точно сочетается между собой. Для примеров несочетаемой одежды мы можем поискать просто рандомные картинки одежды в интернете или собрать наборы, которые заведомо не подходят друг другу, например, пиджак и шлепки.
Еще сильнее увеличить датасет нам поможет старый друг Pinterest. Люди часто выкладывают туда капсулы — комплекты одежды, которые хорошо сочетаются. Все они обычно собраны в одном стиле.

Как было выше сказано, на вход сети-оценщику мы подаем готовые эмбеддинги из другой сети. Нам не нужно было задаваться вопросом, откуда такую сеть взять, так как у нас есть уже обученная сеть для «Лакинатора»!
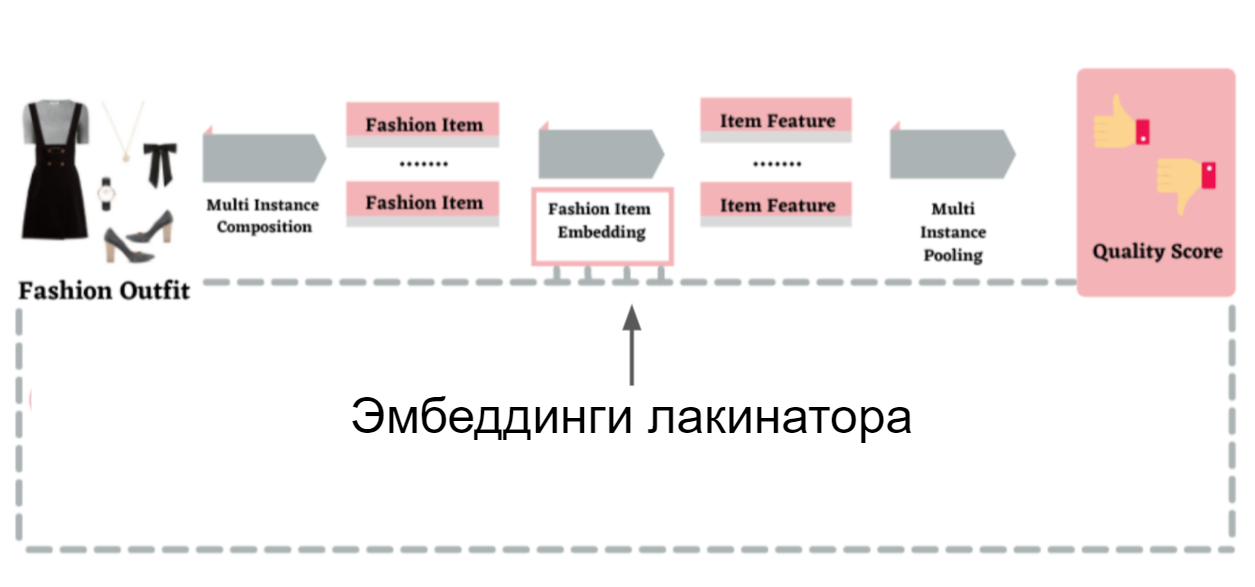
Решая задачу скоринга, мы получили ранжирование одежды по сочетаемости. Для этого взяли 100, 200 и 1000 товаров, прогнали все их сочетания между собой и отсортировали результаты по возрастанию оценки модели, то есть что больше или меньше понравилось нейросетке.
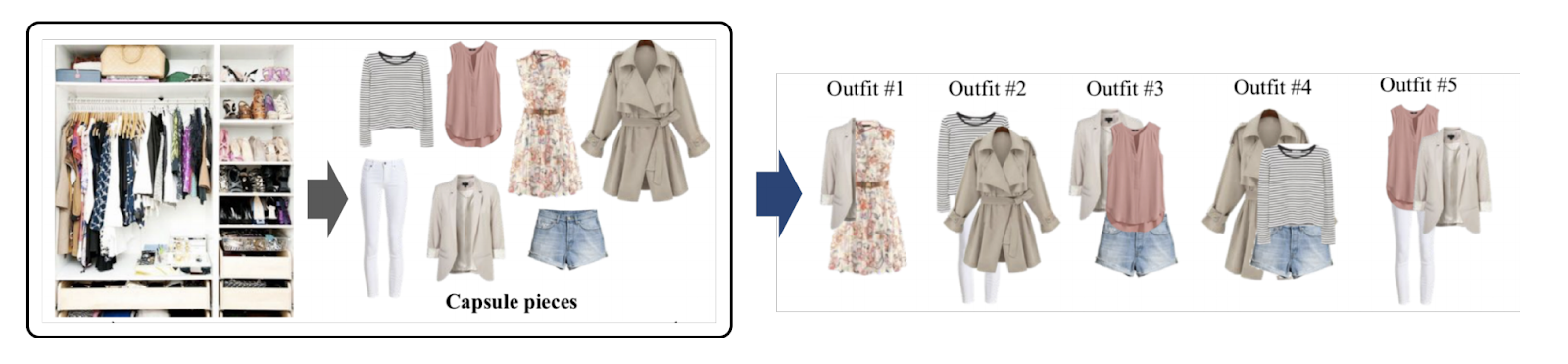
Такая модель поможет в поиске вещей, подходящих под выбранный товар. Например, мы знаем, что человек положил в корзину кроссовки. Дальше мы собираем товары из других категорий, которые могут подойти к этой обуви (футболки, брюки, шорты), так же сортируя получившиеся наборы по скору.

Все это похоже на кубики Lego. Мы обучили пару сетей, каждая из которых делает одну конкретную задачу — предсказывает атрибуты или сочетает скор. Потом собрали из этих сетей-блоков разные пайплайны.
Что мы хотим делать дальше в области компьютерного зрения
Дальше мы хотим пополнять нашу коллекцию подобных базовых блоков, например, сегментацией одежды.


Также планируем добавлять новые пайплайны из базовых кубиков. Например, можно сделать виртуального помощника, который на этапе примерки оценит посадку вещи по фотографии. Это как подружка, которая помогает на примерке и сидит прямо в телефоне.
На относительно отдаленное будущее обдумываем виртуальную примерку с помощью генеративных моделей. Оценить, как одежда сидит на модели — хорошо, но увидеть, как эта одежда будет сидеть на тебе до заказа еще лучше!

Как считаете, как скоро мы дойдем до умных онлайн-гардеробных? Делитесь в комментариях!
Интересные статьи
Интересные статьи




