В процессе перехода от монолитного приложения к микросервисной архитектуре мы сталкиваемся с новыми проблемами.
В монолитном приложении обычно достаточно просто определить, в какой части системы произошла ошибка. Скорее всего, проблема в коде самого монолита, либо в базе данных. Но когда мы начинаем искать проблему в микросервисной архитектуре, всё уже не так очевидно. Нужно найти весь путь, который прошел запрос от начала до конца, выделить его из сотен микросервисов. Причём многие из них еще и имеют собственные хранилища, в которых также могут возникать как логические ошибки, так и проблемы с производительностью и отказоустойчивостью.

Я долго искал инструмент, который помог бы справиться с такими проблемами (писал об этом на Хабре: 1, 2), но в итоге сделал собственное опенсорсное решение. В статье я рассказываю о преимуществах подхода service mesh и делюсь новым инструментом для его реализации.
Распределенный tracing является распространенным решением проблемы поиска ошибок в распределённых системах. Но что если в системе ещё не внедрён такой подход к сбору информации о сетевых взаимодействиях, или, что хуже, в части системы он уже исправно работает, а в части его нет, так как он не добавлен в старые сервисы? Для определения точной корневой причины проблемы необходимо иметь полную картину того, что происходит в системе. Особенно важно понимать, какие именно микросервисы участвуют в основных критичных для бизнеса путях.
Тут к нам на помощь может прийти service mesh подход, который займётся всей машинерией по сбору сетевой информации на уровне ниже, чем работают сами сервисы. Этот подход позволяет нам перехватывать весь трафик и анализировать его на лету. Причём приложения о нём даже не должны ничего знать.
Service mesh подход
Главной идеей service mesh подхода является добавление еще одного инфраструктурного слоя над сетью, который позволит нам делать любые вещи с межсервисным взаимодействием. Большинство реализаций работают следующим образом: к каждому микросервису добавляется дополнительный sidecar контейнер с прозрачным прокси, через который пропускается весь входящий и исходящий трафик сервиса. И это то самое место, где мы можем делать клиентскую балансировку, применять политики безопасности, вводить ограничения на количество запросов и собирать важную информацию по взаимодействию сервисов в production.
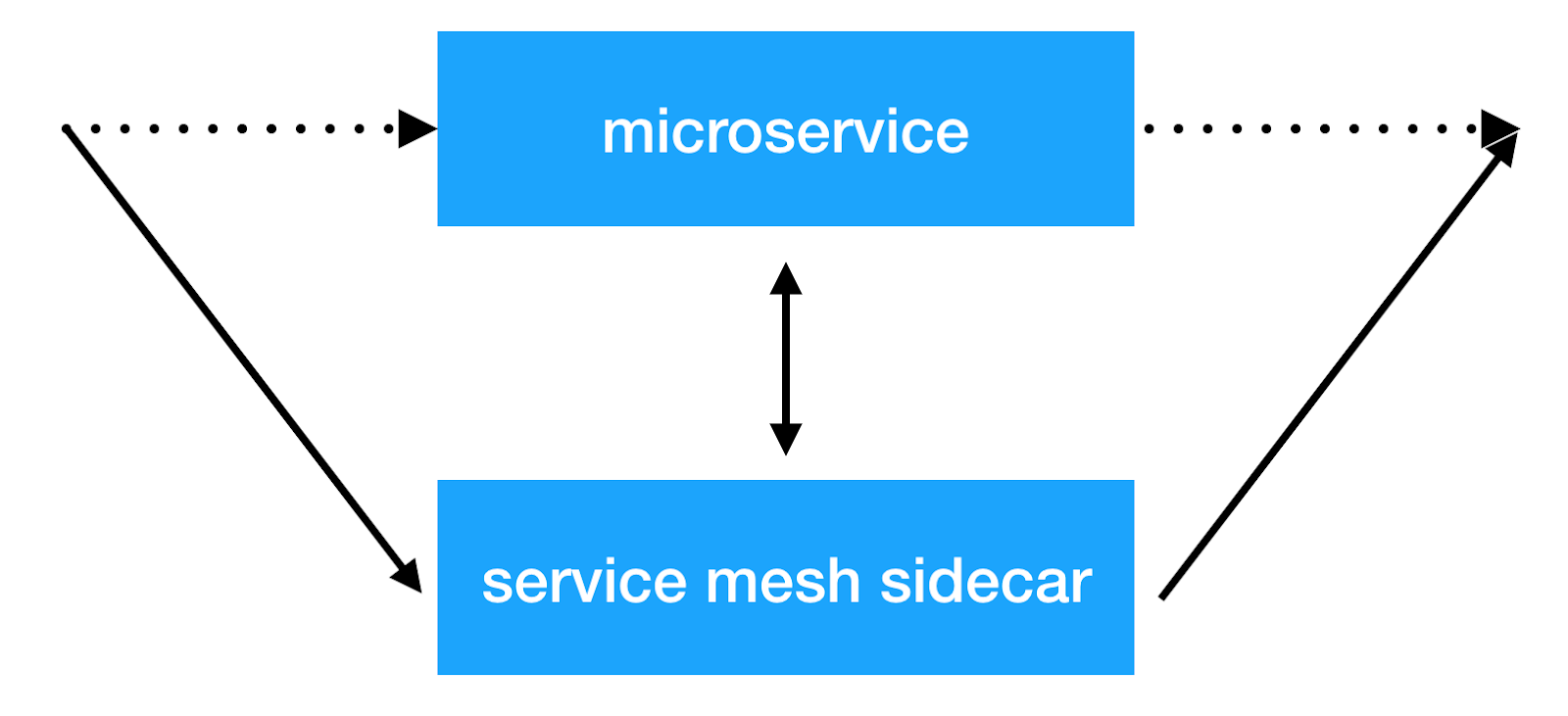
Решения
Уже есть несколько реализаций данного подхода: Istio и linkerd2. Они предоставляют множество возможностей из коробки. Но одновременно с этим приходит и большой overhead на ресурсы. Причём чем больше кластер, в котором работает такая система, тем больше потребуется ресурсов на поддержание новой инфраструктуры. В Авито мы эксплуатируем kubernetes кластеры, в которых находятся тысячи экземпляров сервисов (и их число продолжает быстро расти). В текущей реализации Istio потребляет ~300Mb оперативной памяти на каждый экземпляр сервиса. Из-за большого количества возможностей прозрачная балансировка также оказывает влияние на полное время ответа сервисов (вплоть до 10ms).
В итоге мы посмотрели на то, какие именно возможности нам нужны прямо сейчас, и решили, что основное, из-за чего мы начали внедрять подобные решения, была возможность собирать tracing информацию со всей системы прозрачно. Также нам хотелось иметь контроль над взаимодействием сервисов и делать различные манипуляции с заголовками, которые передаются между сервисами.
В итоге мы пришли к своему решению: Netramesh.
Netramesh
Netramesh — это легковесное service mesh решение с возможностью бесконечного масштабирования вне зависимости от количества сервисов в системе.
Главными целями нового решения являлись маленький overhead по ресурсам и высокая производительность. Из основных возможностей мы хотели сразу иметь возможность прозрачно отправлять tracing span’ы в нашу Jaeger систему.
Сегодня большинство облачных решений реализуется на Golang. И, конечно, на это есть свои причины. Писать на Golang сетевые приложения, работающие асинхронно с вводом-выводом и масштабирующиеся по необходимости на ядра, удобно и достаточно просто. И, что также очень важно, производительность получается достаточной для решения этой задачи. Поэтому мы тоже выбрали Golang.
Производительность
Мы сфокусировали наши усилия на достижении максимальной производительности. Для решения, которое деплоится рядом с каждым экземпляром сервиса, необходимо небольшое потребление оперативной памяти и процессорного времени. И, конечно, задержка на ответ должна быть также мала.
Давайте посмотрим, какие результаты получились.
RAM
Netramesh потребляет ~10Mb без трафика и 50Mb максимально с нагрузкой до 10000 RPS на один instance.
Istio envoy proxy всегда потребляет ~300Mb в наших кластерах с тысячами instance’ов. Это не позволяет масштабировать его на весь кластер.
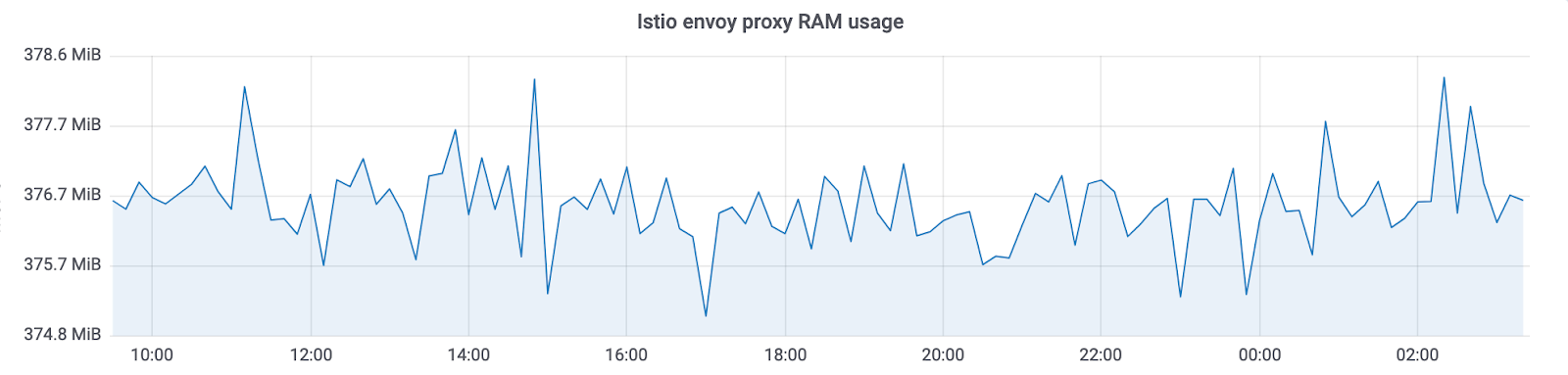

C Netramesh мы получили уменьшение потребления памяти в ~10 раз.
CPU
Использование CPU относительно равно под нагрузкой. Оно зависит от количества запросов в единицу времени к sidecar. Значения при 3000 запросах в секунду в пике:


Есть еще один важный момент: Netramesh — решение без control plane и без нагрузки не потребляет процессорное время. С Istio sidecar’ы всегда обновляют endpoint’ы сервисов. В итоге мы можем видеть такую картину без нагрузки:

Мы используем HTTP/1 для взаимодействия между сервисами. Увеличение времени ответа у Istio при проксировании через envoy было до 5-10ms, что достаточно много для сервисов, которые готовы отвечать за миллисекунду. С Netramesh это время уменьшилось до 0.5-2ms.
Масштабируемость
Небольшое количество ресурсов, затрачиваемое каждым прокси, дает возможность размещать его рядом с каждым сервисом. Netramesh намеренно был создан без control plane компонента для простого поддержания легковесности каждого sidecar’а. Часто в service mesh решениях control plane распространяет service discovery информацию в каждый sidecar. Вместе с ней приезжает и информация о timeout’ах, настройках балансировки. Все это позволяет делать много полезных вещей, но, к сожалению, раздувает sidecar’ы в размере.
Service discovery

Netramesh не добавляет каких-либо дополнительных механизмов для service discovery. Весь трафик проксируется прозрачно через netra sidecar.
Netramesh поддерживает HTTP/1 прикладной протокол. Для его определения используется конфигурируемый список портов. Обычно в системе есть несколько портов, по которым происходит взаимодействие по HTTP. Например, у нас для взаимодействия сервисов и внешних запросов используются 80, 8890, 8080. В таком случае их можно задать с помощью переменной окружения NETRA_HTTP_PORTS.
Если вы используете Kubernetes в качестве оркестратора и его механизм Service сущностей для внутрикластерного взаимодействия между сервисами, то механизм остается ровно таким же. Сначала микросервис получает service IP адрес с помощью kube-dns и открывает новое соединение к нему. Это соединение устанавливается сначала с локальным netra-sidecar и все TCP пакеты изначально прилетают именно в netra. Далее уже netra-sidecar устанавливает соединение с изначальной точкой назначения. NAT на pod IP на ноде остается ровно таким же как и без netra.
Распределенный tracing и прокидывание контекста
Netramesh предоставляет функциональность, необходимую для отправки tracing span’ов о HTTP взаимодействии. Netra-sidecar парсят HTTP протокол, измеряют задержки запросов, достают необходимую информацию из HTTP header’ов. В конечном счете мы получаем все trace’ы в единой Jaeger системе. Для тонкой конфигурации можно также использовать переменные окружения, которые предоставляет официальная библиотека jaeger go library.


Но есть проблема. Пока сервисы не будут генерировать и прокидывать специальный uber заголовок, мы не увидим соединенные tracing span’ы в системе. А это то, что нам необходимо для быстрого поиска причины проблем. Тут Netramesh снова имеет решение. Прокси читают HTTP заголовки и, если в них нет uber trace id, генерируют его. Netramesh также хранит информацию о входящих и исходящих запросах в sidecar и сопоставляет их путём обогащения необходимыми заголовками исходящих запросов. Все, что необходимо делать в сервисах — прокидывать всего один заголовок X-Request-Id, который можно сконфигурировать с помощью переменной окружения NETRA_HTTP_REQUEST_ID_HEADER_NAME. Для управления размером context’а в Netramesh, можно задавать следующие переменные окружения: NETRA_TRACING_CONTEXT_EXPIRATION_MILLISECONDS (время, в течение которого будет храниться контекст) и NETRA_TRACING_CONTEXT_CLEANUP_INTERVAL (периодичность подчистки контекста).
Также возможно комбинировать несколько путей в вашей системе путем маркирования их специальным сессионным маркером. Netra позволяет установить HTTP_HEADER_TAG_MAP для превращения HTTP заголовков в соответствующие tracing span теги. Это может быть особенно полезно для тестирования. После прохождения функционального теста, можно посмотреть какая часть системы была затронута, отфильтровав по соответствующему session ключу.
Определение источника запроса
Для определения того, откуда пришел запрос, можно воспользоваться функционалом автоматического добавления заголовка с источником. С помощью переменной окружения NETRA_HTTP_X_SOURCE_HEADER_NAME можно задать имя заголовка, которое будет автоматически устанавливаться. С помощью NETRA_HTTP_X_SOURCE_VALUE можно задать значение, в которое будет устанавливаться X-Source заголовок на все исходящие запросы.
Это позволяет унифицированно по всей сети сделать распространение этого полезного заголовка. Далее можно уже использовать его в сервисах и добавлять в логи, метрики.
Роутинг трафика и внутренности Netramesh
Netramesh состоит из двух главных компонентов. Первый, netra-init, устанавливает сетевые правила для перехвата трафика. Он использует iptables redirect правила для перехвата всего, либо части трафика на sidecar, который является вторым главным компонентом Netramesh. Можно настроить, какие именно порты нужно перехватывать на входящие и исходящие TCP сессии: INBOUND_INTERCEPT_PORTS, OUTBOUND_INTERCEPT_PORTS.
Также в инструменте есть интересная возможность — вероятностный роутинг. Если использовать Netramesh исключительно для сбора tracing span’ов, то в production окружении можно сэкономить ресурсы и включить вероятностный роутинг с помощью переменных NETRA_INBOUND_PROBABILITY и NETRA_OUTBOUND_PROBABILITY (от 0 до 1). Значение по умолчанию равно 1 (перехватывается весь трафик).
После успешного перехвата netra sidecar принимает новое соединение и использует SO_ORIGINAL_DST опцию сокета для получения изначальной точки назначения. Затем Netra открывает новое соединение к изначальному IP-адресу и устанавливает двустороннее TCP-общение между сторонами, слушая весь проходящий трафик. Если порт определен как HTTP, Netra пытается парсить его и трейсить. Если парсинг HTTP оказывается неуспешным, Netra делает фоллбэк на TCP и прозрачно проксирует байты.
Построение графа зависимостей
После получения большого количества tracing информации в Jaeger, хочется получить полный граф взаимодействий в системе. Но если ваша система достаточно нагружена и за день скапливаются миллиарды tracing span’ов, сделать их агрегацию становится не столь простой задачей. Есть официальный способ для этого: spark-dependencies. Тем не менее он займет часы для построения полного графа и заставит выкачать из Jaeger весь dataset за прошедшие сутки.
Если вы используете Elasticsearch для хранения tracing span’ов, можно воспользоваться простой утилитой на Golang, которая построит такой же граф за минуты, используя особенности и возможности Elasticsearch.
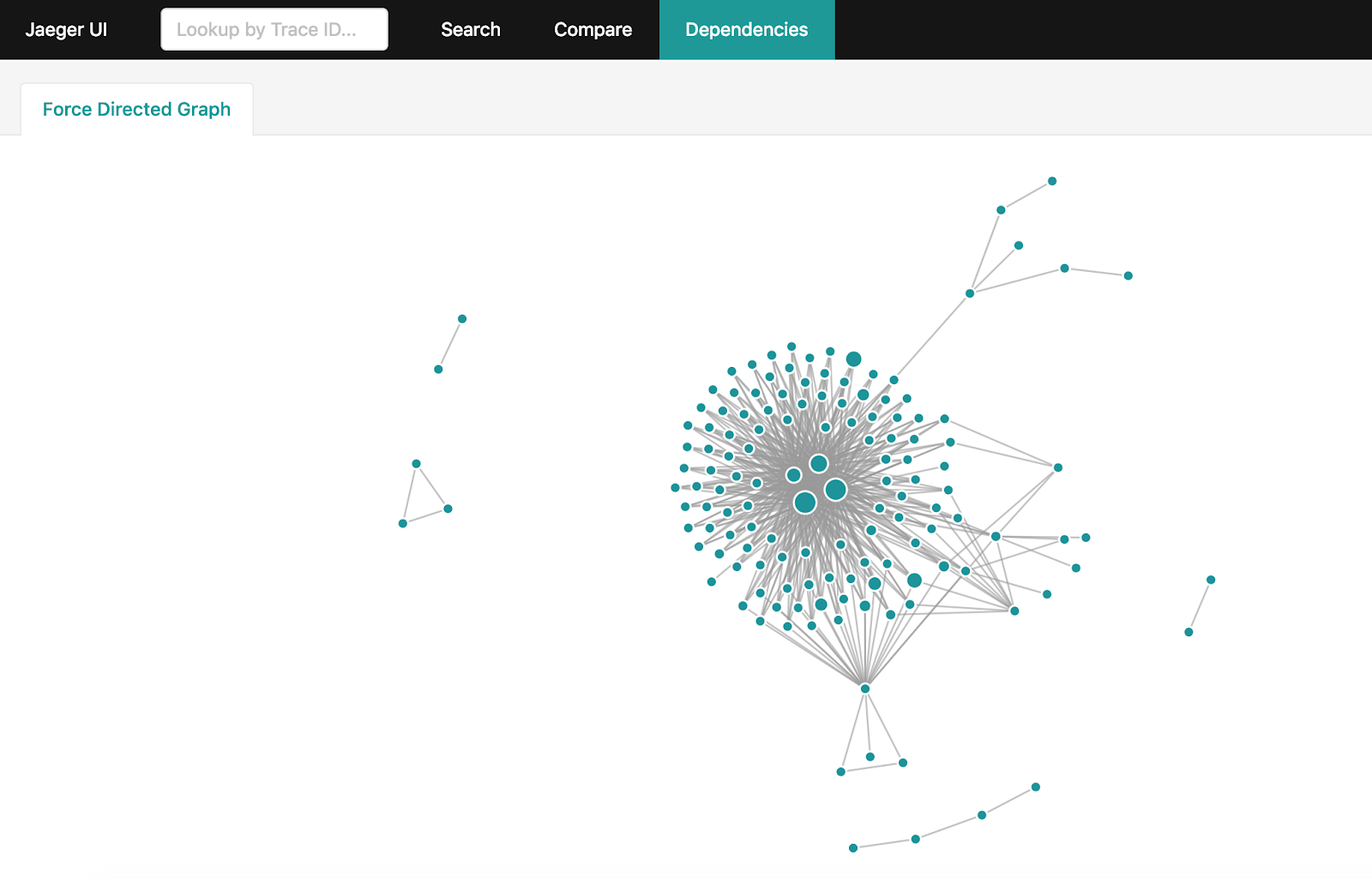
Как использовать Netramesh
Netra можно просто добавить к любому сервису, работающему под управлением любого оркестратора. Можно посмотреть пример тут.
На текущий момент у Netra нет возможности автоматического внедрения sidecar’а к сервисам, но есть планы на реализацию.
Будущее Netramesh
Главной целью Netramesh является достижение минимальных затрат на ресурсы и высокая производительность, предоставляя основные возможности для observability и контроля межсервисного взаимодействия.
В будущем Netramesh получит поддержку других протоколов прикладного уровня помимо HTTP. В ближайшем будущем появится возможность L7 роутинга.
Используйте Netramesh, если вы сталкиваетесь с подобными проблемами, и пишите нам вопросы и предложения.

 с CRM Битрикс24")

