
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
NeurIPS (Neural Information Processing Systems) – самая большая конференция в мире по машинному обучению и искусственному интеллекту и главное событие в мире deep learning.
Будем ли мы, DS-инженеры, в новом десятилетии осваивать еще и биологию, лингвистику, психологию? Расскажем в нашем обзоре.

В этом году конференция собрала более 13500 человек из 80 стран в Ванкувере (Канада). Сбербанк не первый год представляет Россию на конференции — команда DS рассказала о внедрении ML в банковские процессы, о ML-соревновании и о возможностях платформы Sberbank DS. Какими же были основные тренды 2019 года в ML-коммьюнити? Рассказывают участники конференции: Андрей Черток и Татьяна Шаврина.
В этом году на NeurIPS было принято более 1400 статей — алгоритмы, новые модели и новые применения к новым данным. Ссылка на все материалы
1. Интерпретируемость моделей и новая методология ML
Заглавная тема конференции — интерпретация и доказательства, почему мы получаем те или иные результаты. Можно долго рассуждать о философской важности интерпретации “черного ящика”, но больше было реальных методик и технических наработок в этой сфере.
Методология воспроизводимости моделей и извлечения знаний из них — новый инструментарий науки. Модели могут служить инструментом получения нового знания и его проверки, и воспроизводимым должен быть каждый этап препроцессинга, обучения и применения модели.
Существенная доля публикаций посвящена не построению моделей и инструментов, а проблемам обеспечения безопасности, прозрачности и проверяемости результатов. В частности, появился отдельный стрим об атаках на модель (adversarial attacks), причем рассматриваются варианты как атаки на обучение, так и атаки на применение.
Статьи:
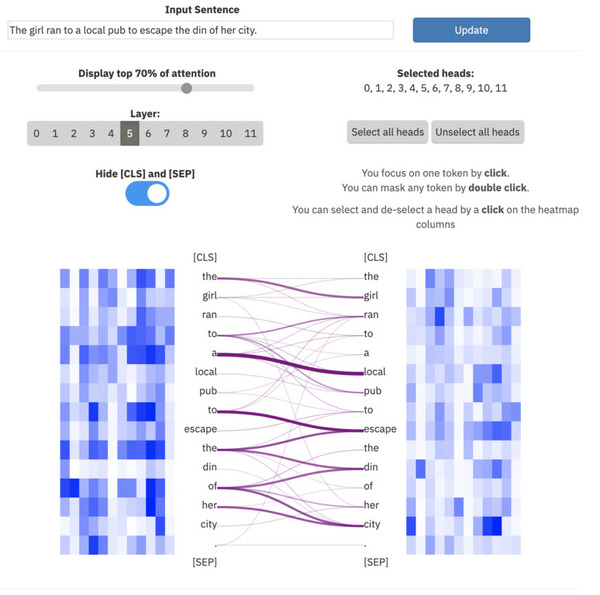
ExBert.net показывает интерпретацию моделей для задач обработки текста
2. Мультидисциплинарность
Чтобы обеспечить надежную проверку и разработать механизмы проверки и пополнения знаний, нужны специалисты смежных областей, одновременно обладающие компетенциями в ML и в предметной области (медицине, лингвистике, нейробиологии, образовании и т.д.). Особо стоит отметить более значимое присутствие работ и выступлений по нейронаукам и когнитивным наукам – происходит сближение специалистов и заимствование идей.
Помимо этого сближения, намечается мультидисциплинарность в совместной обработке информации из различных источников: текст и фото, текст и игры, графовые бд + текст и фото.
Статьи:
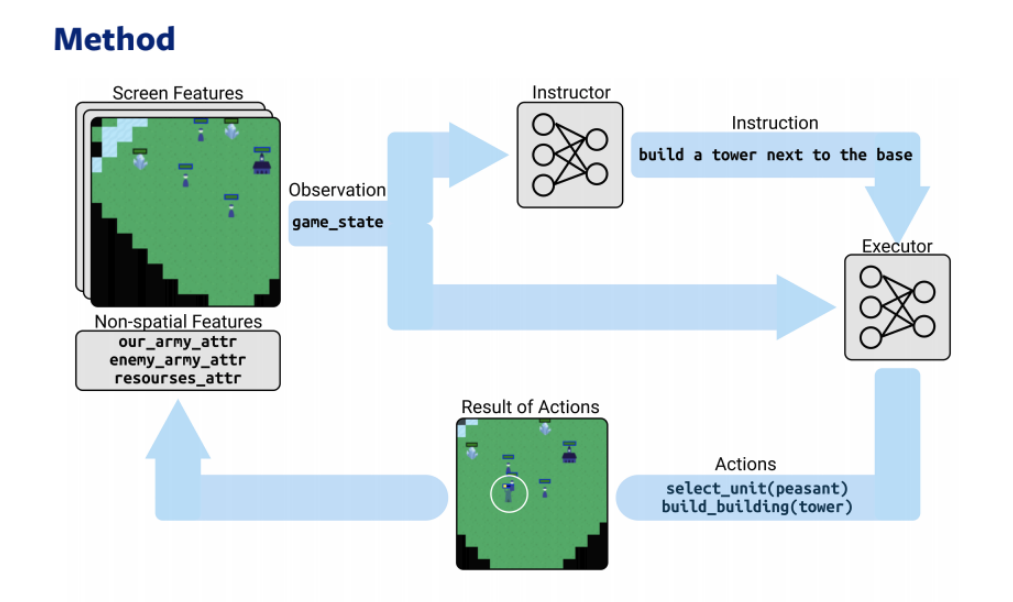
Две модели — стратег и исполнитель — на основе RL и NLP играют в онлайн-стратегию
3. Reasoning
Усиление искусственного интеллекта – движение в сторону самообучающихся систем, “осознанных”, рассуждающих и аргументирующих (reasoning). В частности, развивается causal inference и commonsense reasoning. Часть докладов посвящена мета-обучению (о том, как учиться учиться) и соединению DL-технологий с логикой 1 и 2 порядка — термин Artificial General Intelligence (AGI) становится обычным термином в выступлениях спикеров.
Статьи:
4.Reinforcement Learning
Большая часть работ продолжает развивать традиционные направления RL — DOTA2, Starcraft, соединение архитектур с компьютерным зрением, NLP, графовыми БД.
Отдельный день конференции был посвящен RL-воркшопу, на котором была представлена архитектура Optimistic Actor Critic Model, превосходящая все предыдущие, в частности Soft Actor Critic.
Статьи:

Игроки в StarCraft сражаются с моделью Alphastar (DeepMind)
5. GAN
Генеративные сети все еще в фокусе внимания: много работ используют vanilla GANы для математических доказательств, а также применяют их в новых, необычных вариантах (графовые генеративные модели, работа с рядами, применение к причинно-следственным связям в данных и т.д.).
Статьи:
Поскольку работ было принято более 1400 ниже мы расскажем о самых важных выступлениях.
Ссылка
Слайды и видео
Доклад посвящен общей методологии машинного обучения и перспективам, меняющим индустрию прямо сейчас – перед каким распутьем мы стоим? Как работает мозг и эволюция, и почему мы так мало используем то, что уже хорошо знаем о развитии естественных систем?
Индустриальное развитие ML во многом совпадает с вехами развития компании Google, из года в год публикующей свои исследования на NeurIPS:
Сегодня целая индустрия занимается вопросами безопасности данных, объединения и воспроизведения результатов обучения на локальных устройствах.
Federated learning – направление ML, в котором отдельные модели учатся независимо друг от друга, а затем объединяются в единую модель (без централизации исходных данных), с поправками на редкие события, аномалии, персонализацию и т.д. Все устройства с Android по сути – единый вычислительный суперкомпьютер для Google.
Генеративные модели на основании federated learning – будущее перспективное направление по мнению Google, которое находится “в ранних стадиях экспоненциального роста”. GANы, по мнению лектора, способны научиться воспроизводить массовое поведение популяций живых организмов, алгоритмы мышления.
На примере двух простых архитектур GAN показывается, что в них поиск пути оптимизации блуждает по кругу, а значит, как таковая оптимизация не происходит. При этом эти модели очень успешно моделируют эксперименты, которые биологи ставят над популяциями бактерий, заставляя их учиться новым стратегиям поведения в поисках пищи. Можно сделать вывод о том, что жизнь работает иначе, чем функция оптимизации.
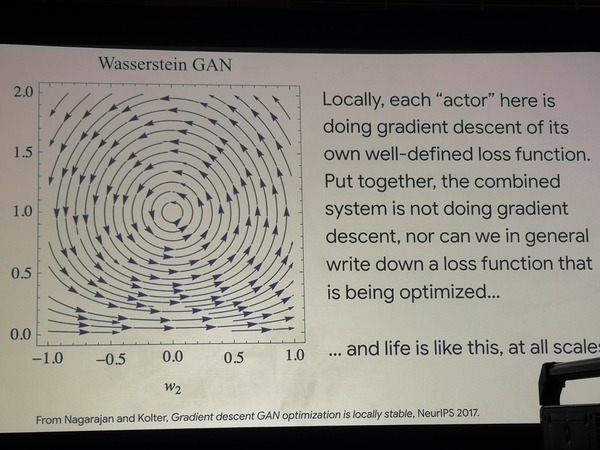
Блуждающая оптимизация GAN
Все то, что мы делаем в рамках машинного обучения сейчас – это узкие и крайне формализованные задачи, в то время как эти формализмы плохо обобщаются и не соответствуют нашему предметному знанию в таких областях, как нейрофизиология и биология.
Что действительно стоит позаимствовать из области нейрофизиологии в ближайшей перспективе – это новые архитектуры нейронов и немного пересмотреть механизмы обратного распространения ошибки.
Сам человеческий мозг учится не как нейросеть:
Обучение индивидуального мозга – низкоуровневая задача, возможно, нам стоит рассматривать “колонии” быстро сменяющихся индивидуумов, передающих друг другу знания, чтобы воспроизвести механизмы групповой эволюции.
Что мы можем перенять в алгоритмы ML уже сейчас:
С этой точки зрения практика SOTA решений — пагубная и должна быть пересмотрена в угоду развитию общих задач (benchmarks).
Видео и слайды
Доклад посвящен проблеме интерпретации моделей машинного обучения и методологии их непосредственной проверки и верификации. Любая обученная ML-модель может быть воспринята как источник знаний, которые из нее необходимо извлечь.
Во многих областях, особенно в медицине, применение модели невозможно без извлечения этих скрытых знаний и интерпретации результатов модели – иначе мы не будем уверены, что результаты будут стабильны, неслучайны, надежны, не убьют пациента. Целое направление методологии работы развивается внутри парадигмы deep learning и выходит за ее пределы – veridical data science. Что это такое?
Мы хотим достичь такого качества научных публикаций и воспроизводимости моделей, чтобы они были:
Эти три принципа образуют основу новой методологии. Как можно проверять модели ML на соответствие этим критериям? Самый простой способ – строить сразу интерпретируемые модели (регрессии, деревья решений). Однако, мы хотим получить и непосредственные плюсы deep learning.
Несколько существующих способов работать с проблемой:

Adversarial attack на свинью
Ошибки моделирования дорого стоят всем: яркий пример — работа Рейнхарта и Рогова "Growth in a time of debt" повлияла на экономическую политику многих европейских стран и вынудила их вести политику экономии, но внимательная перепроверка данных и их обработки годы спустя показала противоположный результат!
У любой ML-технологии есть свой жизненный цикл от внедрения до внедрения. Задача новой методологии – сделать проверку на трех основных принципах на каждом этапе жизни модели.
Итоги:
Лекция, посвященная моделированию поведения человека, его технологическим основам и перспективам применений.
Моделирование поведения человека можно разделить на:
Каждое из этих типов поддается моделированию при помощи ML, но с абсолютно разной входной информацией и признаками. У каждого типа также имеются свои этические проблемы, которые проходит каждый проект:
Индивидуальное поведение
В большей степени касается темы Computer Vision – распознавание эмоций человека, его реакций. Возможно только в контексте, во времени либо с относительной шкалой его собственной вариативности эмоций. На слайде – распознавание эмоций Моны Лизы при помощи контекста из эмоционального спектра средиземноморских женщин. Результат: улыбка радости, но с презрением и отвращением. Причина скорее всего в техническом способе определения “нейтральной” эмоции.
Поведение небольшой группы лиц
Пока хуже всего моделируется из-за недостаточности информации. В качестве примера показывались работы 2018 – 2019 гг. на десятках людей X десятках роликов (ср. датасеты изображений 100к++). Для наилучшего моделирования в рамках этой задачи необходима мультимодальная информация, желательно с датчиков на теле-альтиметр, термометр, запись с микрофона и т.д.
Массовое поведение
Самое развитое направление, так как заказчиком выступают ООН и многие государства. Камеры наружного наблюдения, данные телефонных вышек – биллинг, смс, звонки, данные о перемещении между границами государств – все это дает очень надежное представление о перемещении потоков людей, о социальных нестабильностях. Потенциальные применения технологии: оптимизация спасательных операций, оказание помощи и своевременная эвакуация населения при ЧС. Используемые модели в основном пока плохо интерпретируются – это различные LSTM и сверточные сети. Была краткая ремарка, что ООН лоббирует новый закон, который обяжет европейский бизнес делиться обезличенными данными, необходимыми для любых исследований.
Слайды
В лекции Иошуа Бенжио deep learning встречается с нейронаукой на уровне целеполагания.
Бенджио выделяет два основных типа задач по методологии нобелевского лауреата Дэниэла Канемана (книга «Думай медленно, решай быстро» )
тип 1 — Система 1, неосознанные действия, которые мы делаем «на автомате» (древний мозг): вождение машины по знакомым местам, хождение, распознавание лиц.
тип 2 — Система 2, осознанные действия (кора головного мозга), целеполагание, анализ, мышление, составные задачи.
ИИ пока что достигает достаточных высот лишь в задачах первого типа — тогда как наша задача привести его ко второму, научив выполнять мультидисциплинарные операции и оперировать логикой, высокоуровневыми когнитивными навыками.
Для достижения этой цели предлагается:
Вместо заключения оставляем запись invited talk: Бенжио — один из многих ученых, которые пытаются расширить область ML за пределы проблем оптимизации, SOTA и новых архитектур.
Открытым остается вопрос, насколько соединение проблем сознания, влияния языка на мышление, нейробиологии и алгоритмов — это то, что нас ожидает в будущем и позволит перейти к машинам, которые «думают» как люди.
Спасибо!
Будем ли мы, DS-инженеры, в новом десятилетии осваивать еще и биологию, лингвистику, психологию? Расскажем в нашем обзоре.
В этом году конференция собрала более 13500 человек из 80 стран в Ванкувере (Канада). Сбербанк не первый год представляет Россию на конференции — команда DS рассказала о внедрении ML в банковские процессы, о ML-соревновании и о возможностях платформы Sberbank DS. Какими же были основные тренды 2019 года в ML-коммьюнити? Рассказывают участники конференции: Андрей Черток и Татьяна Шаврина.
В этом году на NeurIPS было принято более 1400 статей — алгоритмы, новые модели и новые применения к новым данным. Ссылка на все материалы
Содержание:
- Тренды
- Интерпретируемость моделей
- Мультидисциплинарность
- Reasoning
- RL
- GAN
- Основные Invited Talks
- “Social Intelligence”, Blaise Aguera y Arcas (Google)
- “Veridical Data Science”, Bin Yu (Berkeley)
- “Human Behavior Modeling with Machine Learning: Opportunities and Challenges”, Nuria M Oliver, Albert Ali Salah
- “From System 1 to System 2 Deep Learning”, Yoshua Bengio
Тренды 2019 года
1. Интерпретируемость моделей и новая методология ML
Заглавная тема конференции — интерпретация и доказательства, почему мы получаем те или иные результаты. Можно долго рассуждать о философской важности интерпретации “черного ящика”, но больше было реальных методик и технических наработок в этой сфере.
Методология воспроизводимости моделей и извлечения знаний из них — новый инструментарий науки. Модели могут служить инструментом получения нового знания и его проверки, и воспроизводимым должен быть каждый этап препроцессинга, обучения и применения модели.
Существенная доля публикаций посвящена не построению моделей и инструментов, а проблемам обеспечения безопасности, прозрачности и проверяемости результатов. В частности, появился отдельный стрим об атаках на модель (adversarial attacks), причем рассматриваются варианты как атаки на обучение, так и атаки на применение.
Статьи:
- Veridical Data Science — программная статья о методологии верификации моделей. Включает обзор современных средств для интерпретации моделей, в частности — использование attention и получение feature importance за счет «дистилляции» нейросети линейными моделями.
- This Looks Like That: Deep Learning for Interpretable Image Recognition Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- A Benchmark for Interpretability Methods in Deep Neural Networks Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
- Towards Interpretable Reinforcement Learning Using Attention Augmented Agents Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, Danilo Jimenez Rezende
- A Debiased MDI Feature Importance Measure for Random Forests Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Knowledge Extraction with No Observable Data Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- A Step Toward Quantifying Independently Reproducible Machine Learning Research Edward Raff
ExBert.net показывает интерпретацию моделей для задач обработки текста
2. Мультидисциплинарность
Чтобы обеспечить надежную проверку и разработать механизмы проверки и пополнения знаний, нужны специалисты смежных областей, одновременно обладающие компетенциями в ML и в предметной области (медицине, лингвистике, нейробиологии, образовании и т.д.). Особо стоит отметить более значимое присутствие работ и выступлений по нейронаукам и когнитивным наукам – происходит сближение специалистов и заимствование идей.
Помимо этого сближения, намечается мультидисциплинарность в совместной обработке информации из различных источников: текст и фото, текст и игры, графовые бд + текст и фото.
Статьи:
- Нейробиология + ML — Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain)
- VisualQA — Learning by Abstraction: The Neural State Machine
- RL + NLP — Hierarchical Decision Making by Generating and Following Natural Language Instructions
Две модели — стратег и исполнитель — на основе RL и NLP играют в онлайн-стратегию
3. Reasoning
Усиление искусственного интеллекта – движение в сторону самообучающихся систем, “осознанных”, рассуждающих и аргументирующих (reasoning). В частности, развивается causal inference и commonsense reasoning. Часть докладов посвящена мета-обучению (о том, как учиться учиться) и соединению DL-технологий с логикой 1 и 2 порядка — термин Artificial General Intelligence (AGI) становится обычным термином в выступлениях спикеров.
Статьи:
- Heterogeneous Graph Learning for Visual Commonsense Reasoning Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Bridging Machine Learning and Logical Reasoning by Abductive Learning Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Implicitly learning to reason in first-order logic Vaishak Belle, Brendan Juba
- PHYRE: A New Benchmark for Physical Reasoning Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, Ross Girshick
- Quantum Embedding of Knowledge for Reasoning Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4.Reinforcement Learning
Большая часть работ продолжает развивать традиционные направления RL — DOTA2, Starcraft, соединение архитектур с компьютерным зрением, NLP, графовыми БД.
Отдельный день конференции был посвящен RL-воркшопу, на котором была представлена архитектура Optimistic Actor Critic Model, превосходящая все предыдущие, в частности Soft Actor Critic.
Статьи:
- Better Exploration with Optimistic Actor Critic; Kamil Ciosek, Quan Vuong, Robert Loftin, Katja Hofmann
- ChainerRL: A Deep Reinforcement Learning Library; Yasuhiro Fujita (Preferred Networks, Inc.)*; Toshiki Kataoka (Preferred Networks, Inc.); Prabhat Nagarajan (Preferred Networks); Takahiro Ishikawa (The University of Tokyo) [external pdf link].
- Dream to Control: Learning Behaviors by Latent Imagination; Danijar Hafner (Google)*; Timothy Lillicrap (DeepMind); Jimmy Ba (University of Toronto); Mohammad Norouzi (Google Brain)
- Материалы воркшопа
Игроки в StarCraft сражаются с моделью Alphastar (DeepMind)
5. GAN
Генеративные сети все еще в фокусе внимания: много работ используют vanilla GANы для математических доказательств, а также применяют их в новых, необычных вариантах (графовые генеративные модели, работа с рядами, применение к причинно-следственным связям в данных и т.д.).
Статьи:
- Mining GOLD Samples for Conditional GANs Sangwoo Mo, Chiheon Kim, Sungwoong Kim, Minsu Cho, Jinwoo Shin
- Progressive Augmentation of GANs Dan Zhang, Anna Khoreva
- Modeling Tabular data using Conditional GAN Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni
- papers.nips.cc/paper/9377-a-domain-agnostic-measure-for-monitoring-and-evaluating-gans
Поскольку работ было принято более 1400 ниже мы расскажем о самых важных выступлениях.
Invited Talks
“Social Intelligence”, Blaise Aguera y Arcas (Google)
Ссылка
Слайды и видео
Доклад посвящен общей методологии машинного обучения и перспективам, меняющим индустрию прямо сейчас – перед каким распутьем мы стоим? Как работает мозг и эволюция, и почему мы так мало используем то, что уже хорошо знаем о развитии естественных систем?
Индустриальное развитие ML во многом совпадает с вехами развития компании Google, из года в год публикующей свои исследования на NeurIPS:
- 1997 – запуск поисковых мощностей, первые сервера, небольшая вычислительная мощность
- 2010 – Джефф Дин запускает проект Google Brain, бум нейросетей в самом начале
- 2015 – индустриальное внедрение нейросетей, быстрое распознавание лиц прямо на локальном устройстве, низкоуровневые процессоры, заточенные под тензорные вычисления – TPU. Google запускает Coral ai – аналог raspberry pi, мини-компьютер для внедрения нейросетей в экспериментальные установки
- 2017 – Google начинает разработку децентрализованного обучения и объединения результатов обучения нейросетей с разных устройств в одну модель – на android
Сегодня целая индустрия занимается вопросами безопасности данных, объединения и воспроизведения результатов обучения на локальных устройствах.
Federated learning – направление ML, в котором отдельные модели учатся независимо друг от друга, а затем объединяются в единую модель (без централизации исходных данных), с поправками на редкие события, аномалии, персонализацию и т.д. Все устройства с Android по сути – единый вычислительный суперкомпьютер для Google.
Генеративные модели на основании federated learning – будущее перспективное направление по мнению Google, которое находится “в ранних стадиях экспоненциального роста”. GANы, по мнению лектора, способны научиться воспроизводить массовое поведение популяций живых организмов, алгоритмы мышления.
На примере двух простых архитектур GAN показывается, что в них поиск пути оптимизации блуждает по кругу, а значит, как таковая оптимизация не происходит. При этом эти модели очень успешно моделируют эксперименты, которые биологи ставят над популяциями бактерий, заставляя их учиться новым стратегиям поведения в поисках пищи. Можно сделать вывод о том, что жизнь работает иначе, чем функция оптимизации.
Блуждающая оптимизация GAN
Все то, что мы делаем в рамках машинного обучения сейчас – это узкие и крайне формализованные задачи, в то время как эти формализмы плохо обобщаются и не соответствуют нашему предметному знанию в таких областях, как нейрофизиология и биология.
Что действительно стоит позаимствовать из области нейрофизиологии в ближайшей перспективе – это новые архитектуры нейронов и немного пересмотреть механизмы обратного распространения ошибки.
Сам человеческий мозг учится не как нейросеть:
- У него не случайные первичные вводные, в том числе заложенные через органы чувств и в детстве
- У него есть заложенные направления инстинктивного развития (стремление выучить язык у младенца, прямохождение)
Обучение индивидуального мозга – низкоуровневая задача, возможно, нам стоит рассматривать “колонии” быстро сменяющихся индивидуумов, передающих друг другу знания, чтобы воспроизвести механизмы групповой эволюции.
Что мы можем перенять в алгоритмы ML уже сейчас:
- Применить cell lineage модели, обеспечивающие обучение популяции, но короткую жизнь индивидуума (“индивидуального мозга”)
- Few-shot learning на небольшом количестве примеров
- Более сложные структуры нейронов, немного другие функции активации
- Передача “генома” следующим поколениям – алгоритм обратного распространения ошибки
- Как только мы соединим нейрофизиологию и нейронные сети, мы научимся строить многофункциональный мозг из множества составляющих.
С этой точки зрения практика SOTA решений — пагубная и должна быть пересмотрена в угоду развитию общих задач (benchmarks).
“Veridical Data Science”, Bin Yu (Berkeley)
Видео и слайды
Доклад посвящен проблеме интерпретации моделей машинного обучения и методологии их непосредственной проверки и верификации. Любая обученная ML-модель может быть воспринята как источник знаний, которые из нее необходимо извлечь.
Во многих областях, особенно в медицине, применение модели невозможно без извлечения этих скрытых знаний и интерпретации результатов модели – иначе мы не будем уверены, что результаты будут стабильны, неслучайны, надежны, не убьют пациента. Целое направление методологии работы развивается внутри парадигмы deep learning и выходит за ее пределы – veridical data science. Что это такое?
Мы хотим достичь такого качества научных публикаций и воспроизводимости моделей, чтобы они были:
- предсказуемыми
- вычислимыми
- стабильными
Эти три принципа образуют основу новой методологии. Как можно проверять модели ML на соответствие этим критериям? Самый простой способ – строить сразу интерпретируемые модели (регрессии, деревья решений). Однако, мы хотим получить и непосредственные плюсы deep learning.
Несколько существующих способов работать с проблемой:
- интерпретировать модель;
- использовать методы, основанные на attention;
- использовать при обучении ансамбли алгоритмов, и добиваться того, чтобы линейные интерпретируемые модели учились предсказывать те же ответы, что и нейросеть, интерпретируя признаки из линейной модели;
- менять и аугментировать данные для обучения. Сюда входят и добавление шумов, помех, и data augmentation;
- любые методы, которые позволяют убедиться, что результаты модели не случайны и не зависят от мелких нежелательных помех (adversarial attacks);
- интерпретировать модель пост-фактум, после обучения;
- изучать весов признаков различными способами;
- изучать вероятности всех гипотез, распределение классов.
Adversarial attack на свинью
Ошибки моделирования дорого стоят всем: яркий пример — работа Рейнхарта и Рогова "Growth in a time of debt" повлияла на экономическую политику многих европейских стран и вынудила их вести политику экономии, но внимательная перепроверка данных и их обработки годы спустя показала противоположный результат!
У любой ML-технологии есть свой жизненный цикл от внедрения до внедрения. Задача новой методологии – сделать проверку на трех основных принципах на каждом этапе жизни модели.
Итоги:
- Развивается несколько проектов которые помогут ML-модели быть более надёжными. Это, например, deeptune (link to: github.com/ChrisCummins/paper-end2end-dl);
- Для дальнейшего развития методологии необходимо существенно поднять качество публикаций в сфере ML;
- Машинному обучению нужны лидеры с мультидисциплинарной подготовкой и экспертизой как в технических, так и гуманитарных областях.
“Human Behavior Modeling with Machine Learning: Opportunities and Challenges” Nuria M Oliver, Albert Ali Salah
Лекция, посвященная моделированию поведения человека, его технологическим основам и перспективам применений.
Моделирование поведения человека можно разделить на:
- индивидуальное поведение
- поведение небольшой группы лиц
- массовое поведение
Каждое из этих типов поддается моделированию при помощи ML, но с абсолютно разной входной информацией и признаками. У каждого типа также имеются свои этические проблемы, которые проходит каждый проект:
- индивидуальное поведение – похищение идентичности, deepfake;
- поведение групп людей – деанонимизация, получение информации о передвижениях, телефонных звонках и т.д.;
Индивидуальное поведение
В большей степени касается темы Computer Vision – распознавание эмоций человека, его реакций. Возможно только в контексте, во времени либо с относительной шкалой его собственной вариативности эмоций. На слайде – распознавание эмоций Моны Лизы при помощи контекста из эмоционального спектра средиземноморских женщин. Результат: улыбка радости, но с презрением и отвращением. Причина скорее всего в техническом способе определения “нейтральной” эмоции.
Поведение небольшой группы лиц
Пока хуже всего моделируется из-за недостаточности информации. В качестве примера показывались работы 2018 – 2019 гг. на десятках людей X десятках роликов (ср. датасеты изображений 100к++). Для наилучшего моделирования в рамках этой задачи необходима мультимодальная информация, желательно с датчиков на теле-альтиметр, термометр, запись с микрофона и т.д.
Массовое поведение
Самое развитое направление, так как заказчиком выступают ООН и многие государства. Камеры наружного наблюдения, данные телефонных вышек – биллинг, смс, звонки, данные о перемещении между границами государств – все это дает очень надежное представление о перемещении потоков людей, о социальных нестабильностях. Потенциальные применения технологии: оптимизация спасательных операций, оказание помощи и своевременная эвакуация населения при ЧС. Используемые модели в основном пока плохо интерпретируются – это различные LSTM и сверточные сети. Была краткая ремарка, что ООН лоббирует новый закон, который обяжет европейский бизнес делиться обезличенными данными, необходимыми для любых исследований.
“From System 1 to System 2 Deep Learning”, Yoshua Bengio
Слайды
В лекции Иошуа Бенжио deep learning встречается с нейронаукой на уровне целеполагания.
Бенджио выделяет два основных типа задач по методологии нобелевского лауреата Дэниэла Канемана (книга «Думай медленно, решай быстро» )
тип 1 — Система 1, неосознанные действия, которые мы делаем «на автомате» (древний мозг): вождение машины по знакомым местам, хождение, распознавание лиц.
тип 2 — Система 2, осознанные действия (кора головного мозга), целеполагание, анализ, мышление, составные задачи.
ИИ пока что достигает достаточных высот лишь в задачах первого типа — тогда как наша задача привести его ко второму, научив выполнять мультидисциплинарные операции и оперировать логикой, высокоуровневыми когнитивными навыками.
Для достижения этой цели предлагается:
- в задачах NLP использовать attention как ключевой механизм моделирования мышления
- использовать meta-learning и representation learning для лучшего моделирования признаков, влияющих на сознание, и их локализацию – и на их основе перейти к оперированию более высокоуровневыми концептами.
Вместо заключения оставляем запись invited talk: Бенжио — один из многих ученых, которые пытаются расширить область ML за пределы проблем оптимизации, SOTA и новых архитектур.
Открытым остается вопрос, насколько соединение проблем сознания, влияния языка на мышление, нейробиологии и алгоритмов — это то, что нас ожидает в будущем и позволит перейти к машинам, которые «думают» как люди.
Спасибо!




