

Чтобы состарить лицо на фотографии, сменить прическу или заставить его улыбаться, нужно изучить семантику, содержащуюся в отдельных слоях обученной GAN-модели. Недавние исследования генеративно-состязательных сетей показали, что разные слои содержат разную семантику синтезированных изображений: одни отвечают за цвет, а другие за текстуры и т.д.
Очень мало моделей позволяют управлять семантическими атрибутами конкретного слоя. Поэтому в этом месяце продолжают быть актуальными решения и подходы, которые позволяют управлять скрытым пространством для контролируемого создания высококачественных изображений. С них и начнем подборку:
StyleCLIP
Доступность: статья / репозиторий / колаб
Исследователи из Adobe активно пытаются понять, как использовать скрытые пространства StyleGAN, чтобы управлять сгенерированными изображениями.
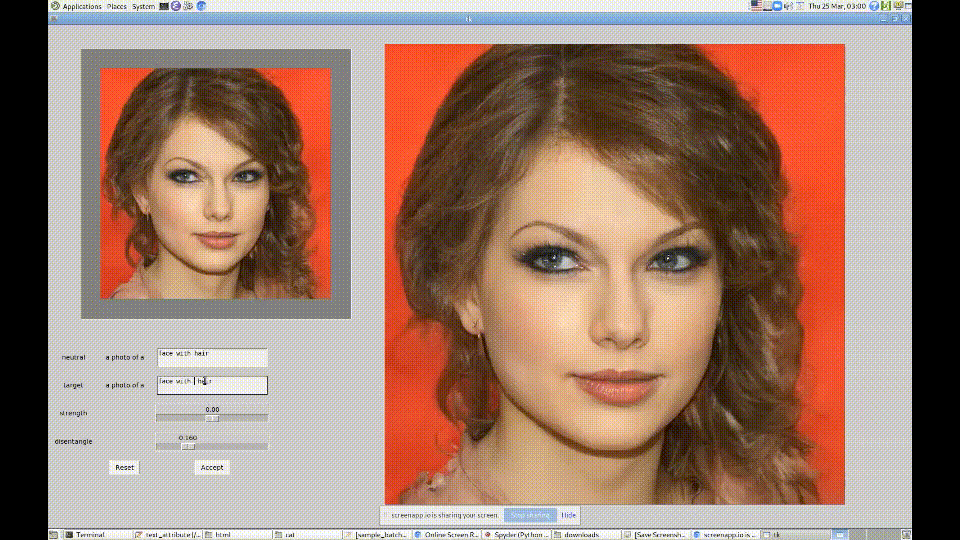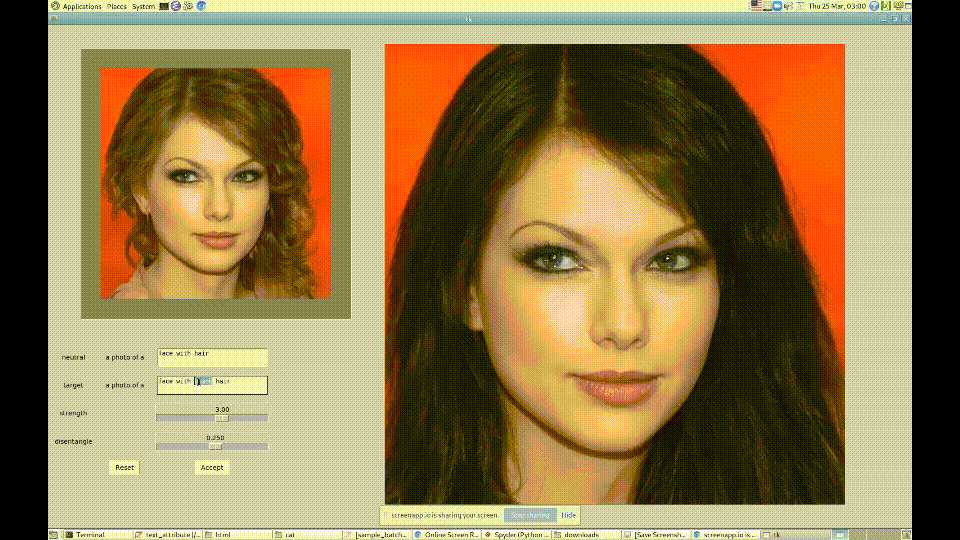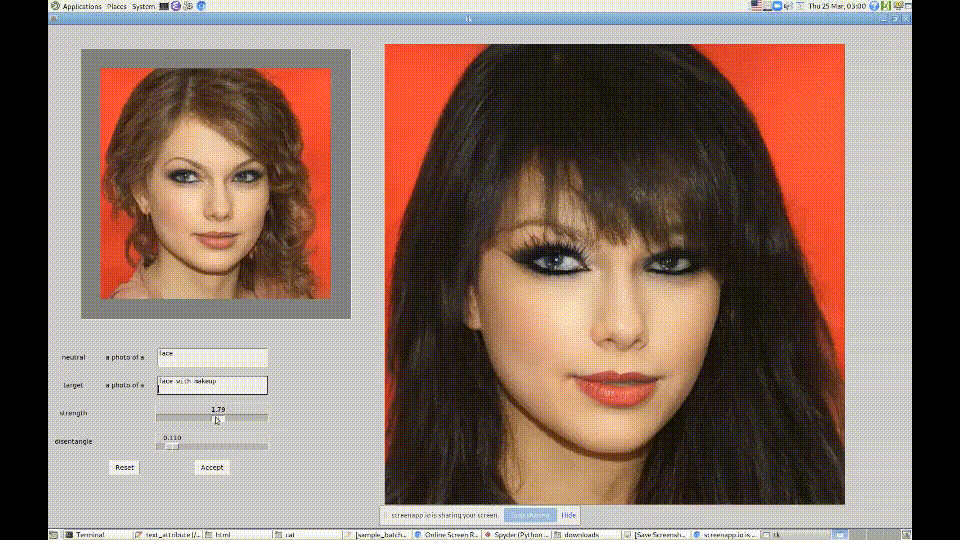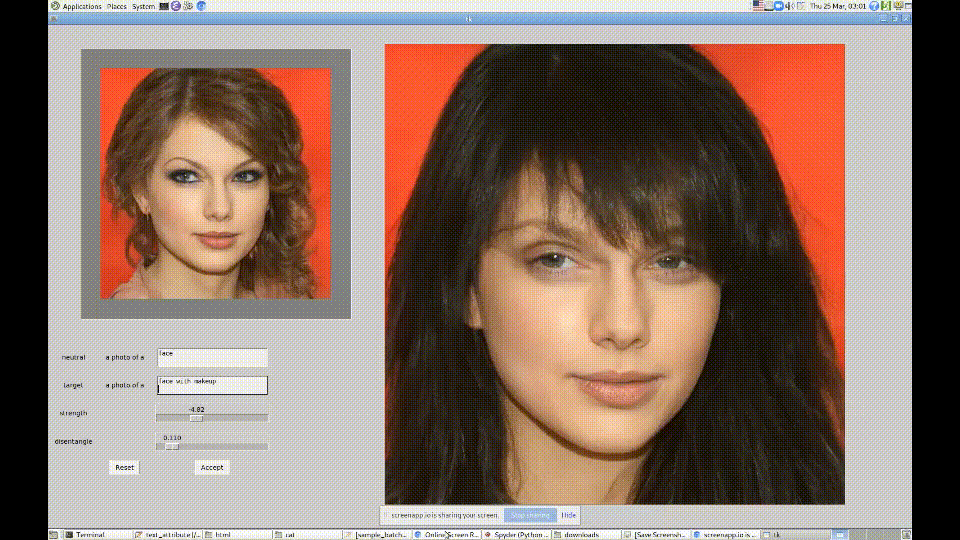
Вдохновившись возможностями CLIP, они создали модель и графический интерфейс для обработки изображений StyleGAN. Пользователь вводит текстовую подсказку, на основе которой генерируется измененное изображение на выходе. Чтобы сохранить узнаваемость личности на фото, используется модель ArcFace. Получился такой нейросетевой фотошоп, который позволяет достаточно качественно редактировать фото: менять возраст, стрижки, макияж и пр.
ReStyle
Доступность: статья / репозиторий / колаб
Еще один способ инвертировать изображение в скрытый код обученной GAN-модели для последующего манипулирования изображением. Вместо прямого предсказания скрытого кода заданного изображения за один проход через набор данных, кодировщик предсказывает остаток по отношению к текущей оценке инвертированного скрытого кода. То есть первоначальная оценка устанавливается как среднее значение скрытого кода по всему набору данных, и при инвертировании кодировщику передаются выходные данные предыдущего шага вместе с исходными входными данными. Итеративность увеличивает время получения выходных данных, но существенно улучшает их качество.

EigenGAN
Доступность: статья / репозиторий
Алгоритм самостоятельно находит скрытые пространства, чтобы потом ими можно было манипулировать. Иногда из-за сложности композиции разные атрибуты могут восприниматься моделью как один, например, поза и пол. Также модели не всегда удается находить отдельные атрибуты, например, очки, из-за того, что они реже встречаются в наборе данных.

LatentCLR
Доступность: статья / репозиторий
Фреймворк для обнаружения значимых векторов в скрытом пространстве GAN, который использует сравнительное обучение без учителя. Метод способен находить нелинейные вектора в предобученных моделях StyleGAN2 и BigGAN.
Geometry-Free View Synthesis
Доступность: статья / репозиторий / колаб
Представьте, что вы смотрите в открытый дверной проем и не видите часть комнаты. Тем не менее, вы можете по высоте потолка, расположению стен, освещению и т. д. представить себе, что скрыто от глаз.
Исследователи Гейдельбергского университета создали нейросетевую модель, которая действует по такому же принципу. Всего по одной фотографии интерьера квартиры она генерирует новые представления сцены, таким образом позволяя «погулять» по виртуальному пространству. Метод основан на трансформере, который берет на вход квантизованое представление фото в скрытом пространстве и синтезирует несколько вариантов вида сцены. Новизна подхода в том, что нужна всего одна фотография без предварительно созданных 3D-моделей и геометрического описания сцены, трансформер сам обучается пространственным отношениям между изображениями.

Articulated Animation
Доступность: страница проекта / статья / репозиторий
Исследователи Snap представили новую модель для анимации не только лица, а всего тела, которая не требует обучения под каждого отдельного человека — метод идентифицирует части тела, самостоятельно отслеживает их на видео и определяет их движение, учитывая основные оси. Чтобы отделить передний план от фона, с помощью дополнительного аффинного преобразования моделируется общее движение, не связанное с объектами. Чтобы движение выглядело более плавным и естественным, модель отделяет форму и расположение предметов в пространстве. Получаются дипфейки в полный рост.

VideoGPT
Доступность: страница проекта / статья / репозиторий / демо
Исследователи из Беркли представили новую архитектуру для генерации видео. В основе — вариационный автокодировщик VQ-VAE, который создает дискретное скрытое представление неразмеченного видео за счет использования трехмерных сверток и осевого self-attention. Затем используется простая GPT-подобная архитектура для авторегрессионного моделирования дискретных представлений с использованием временного кодирования.
Архитектура показала хорошие результаты на бенчмарках, поэтому авторы рассчитывают, что их подход станет эталоном для минималистичной реализации моделей генерации видеопотока на основе трансформеров.
MiVOS
Доступность: страница проекта / статья / репозиторий
Фреймворк для интерактивного отслеживания объектов на видео. Нейросеть преобразует пользовательский инпут в бинарные маски объектов. После эти маски распространяются на соседние кадры с помощью сверточной нейросети. Слой внимания сравнивает фрагменты текущего кадра со всеми фрагментами предыдущих кадров, чтобы дать пользователю возможность корректировать маски на любых кадрах.
На демонстрации видно, как это все происходит в графическом интерфейсе: пользователь отмечает на видео несколько точек, либо обводит фрагмент объекта, а система мгновенно сегментирует объект на других кадрах. Технология явно пойдет на пользу всем, кто работает с видео, поэтому ждем нечто подобное в Adobe Premier.

DINO
Доступность: публикация в блоге / статья / репозиторий
Ну а если руками ничего делать не хочется, то исследователи FAIR представили новый подход обнаружения и сегментации объектов на фото и видео без ручной разметки.
Авторы совместили сравнительное самостоятельное обучение и трансформеров. Благодаря первому модели обучаются на неразмеченных данных, а последнее позволяет им выборочно фокусироваться на определенных частях вводимых данных, чтобы эффективнее строить предположения.
Модель автоматически обучается интерпретируемому представлению, отделяет главный объект от фонового шума и учится сегментировать объекты без аннотаций. Обнаруживая части объекта и общие характеристики в изображениях, модель изучает пространство признаков. Обучаясь на датасете ImageNet, модель сгруппировала изображения в похожие категории — например, разделила животных на разные группы: птицы, рептилии, приматы и пр. Другим открытием стало то, что метод позволяет определять копии изображений, хотя такой задачи исследователи не ставили.
Также в рамках этой работы представили открытый алгоритм PAWS, который минимум в четыре раза сокращает количество циклов обучения, чем существенно экономит вычислительные ресурсы.

Завершим апрельскую подборку двумя кейсами применения ML в медицине:
Compositional Perturbation Autoencoder (CPA)
Доступность: публикация в блоге / статья / репозиторий
Сложные злокачественные опухоли часто требуют комбинации лекарств, чтобы воздействовать сразу на несколько типов клеток. Проблема в том, что найти среди бесконечного множества эффективную комбинацию лекарств и дозировок чрезвычайно сложно.
Исследовани FAIR и Мюнхенского центра им. Гельмгольца представили открытый фреймворк для построения моделей, которые предсказывают эффект комбинаций лекарств, дозировок, времени приема и т.д.
Transferable Visual Words
Доступность: статья / репозиторий
Чтобы сделать флюорографию или томографию, пациент принимает определенную позу. В итоге медицинские снимки отличаются консистентно ровной структурой. Это дает возможность автоматически разделить изображение на ряд фрагментов и находить среди них повторяющиеся анатомические признаки. Векторные представления этих фрагментов авторы называют «визуальными словами», семантика которых содержит информацию о здоровье человека. Их можно извлекать из неразмеченных данных и использовать для самообучающихся моделей.
В апреле стали доступны:
исходный код нейросети Swapping Autoencoder, о которой мы рассказывали в июле прошлого года;
исходный код и демо NLP-модели m2m100, которая поддерживает русский и неплохо справляется с переводом.
На этом все, спасибо за внимание и до встречи в следующем месяце!




