
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

В последнее время вышло несколько статей с критикой ImageNet, пожалуй самого известного набора изображений, использующегося для обучения нейронных сетей.
В первой статье Approximating CNNs with bag-of-local features models works surprisingly well on ImageNet авторы берут модель, похожую на bag-of-words, и в качестве "слов" используют фрагменты из изображения. Эти фрагменты могут быть вплоть до 9х9 пикселей. И при этом, на такой модели, где полностью отсутствует какая-либо информация о пространственном расположении этих фрагментов, авторы получают точность от 70 до 86% (для примера, точность обычной ResNet-50 составляет ~93%).
Во второй статье ImageNet-trained CNNs are biased towards texture авторы приходят к выводу, что виной всему сам набор данных ImageNet и то, как изображения воспринимают люди и нейронные сети, и предлагают использовать новый датасет – Stylized-ImageNet.
Более подробно о том, что на картинках видят люди, а что нейронные сети
ImageNet
Набор данных ImageNet начал создаваться в 2006 году усилиями профессора Fei-Fei Li и продолжает развиваться по сей день. На данный момент в нём содержится около 14 миллионов изображений, принадлежащих более 20 тысячам разных категорий.
С 2010 года подмножество этого набора данных, известное как ImageNet 1K с ~1 миллионом изображений и тысячей классов используется в соревновании ILSVRC (ImageNet Large Scale Visual Recognition Challenge). На этом соревновании в 2012 году "выстрелила" AlexNet, сверточная нейронная сеть, которая достигла top-1 точности в 60% и top-5 в 80%.
Именно на этом подмножестве датасета люди из академической среды меряются своими SOTA, когда предлагают новые архитектуры сетей.
Немного о процессе обучения на этом наборе данных. Речь пойдёт про протокол обучения на ImageNet именно в академической среде. То есть когда нам показывают в статье результаты какого-нибудь SE блока, ResNeXt или DenseNet сети, то процесс выглядит примерно так: сеть обучается в течении 90 эпох, скорость обучения снижается на 30 и 60 эпохе, каждый раз в 10 раз, в качестве оптимизатора выбирается обычный SGD с небольшим weight-decay, из аугментаций используется только RandomCrop и HorizontalFlip, картинка обычно ресайзится до 224х224 пикселей.
Вот пример скрипта из pytorch для обучения на ImageNet.
BagNet
Вернёмся к упомянутым ранее статьям. В первой из них авторы хотели получить модель, которую было бы легче интерпретировать чем обычные глубокие сети. Вдохновившись идеей bag-of-feature моделей, они создают свое семейство моделей – BagNets. Используя в качестве основы обычную ResNet-50 сеть.
Заменяя в ResNet-50 некоторые свертки 3х3 на 1х1, они добиваются того, что receptive field нейронов на последнем сверточном слое значительно уменьшается, вплоть до 9х9 пикселей. Тем самым они ограничивают информацию, доступную одному отдельному нейрону, до очень маленького фрагмента всего изображения – патча в несколько пикселей. Надо заметить, что для нетронутой ResNet-50 размер receptive field составоляет более 400 пикселей что полностью покрывает картинку, которая обычно ресайзится до 224х224 пикселей.
Этот патч – это самый максимальный фрагмент изображения, из которого модель могла бы извлечь пространственные данные. В конце модели все данные просто суммировались и модель никаким образом не могла знать где каждый патч находится по отношению к другим патчам.
Всего проверялось три варианта сетей с receptive field 9x9, 17х17 и 33х33. И, несмотря на полное отсутсвие пространственной информации, такие модели смогли достичь неплохой точности в классификации на ImageNet. Top-5 accuracy для патчей 9х9 составила 70%, для 17х17 – 80%, для 33х33 – 86%. Для сравнения, у ResNet-50 top-5 accuracy составляет приблизительно 93%.

Структура модели показана на рисунке выше. Каждый патч из qxqx3 пикселей, вырезанный из изображения, превращается сетью в вектор длиной 2048. Далее этот вектор подаётся на вход линейного классификатора, который выдаёт scores для каждого из 1000 классов. Собрав scores каждого патча в 2d массив можно получить heatmap для каждого класса и каждого пикселя исходного изображения. Финальный scores для изображения получался путем суммирования heatmap каждого класса.
Примеры heatmaps для некоторых классов:

Как видно, самый большой вклад в пользу того или иного класса вносят патчи, расположенные по краям объектов. Патчи с фона практически игнорируются. Пока всё идет нормально.
Посмотрим на наиболее информативные патчи:

Для примера авторы взяли четыре класса. Для каждого из них выбрали по 2х7 наиболее значимых патчей (то есть патчей, где score данного класса был наивысшим). Верхний ряд из 7 патчей взят из изображений только соответствующего класса, нижний – из всей выборки изображений.
Что на этих картинках можно увидеть примечательного. Например, для класса tench (линь, рыба) характерным признаком являются пальцы. Да, обыкновенные человеческие пальцы на зеленом фоне. А все потому, что почти на всех изображениях с этим классом присутствует рыбак, который, собственно, данную рыбу и держит в руках, хвастаясь трофеем.

Для портативных компьютеров характерным признаком являются клавиши с буквами. Клавиши печатной машинки тоже засчитываются в этот класс.
Для книжной обложки характерным признаком являются буквы на цветном фоне. Пусть это даже будет надпись на футболке или на пакете.
Казалось бы, данная проблема не должна нас беспокоить. Так как она присуща только узкому классу сетей с очень ограниченным receptive field. Но далее авторы посчитали корреляцию между logits (выходами сети перед финальным softmax), присваиваемыми каждому классу BagNet с разными receptive field, и logits из VGG-16, которая имеет достаточно большой receptive field. И нашли её довольно высокой.

Авторы задались вопросом, не содержит ли BagNet каких-либо намёков на то, как другие сети принимают решения.
Для одного из тестов они использовали такую технику как Image Scrambling. Которая состояла в том, чтобы с помощью генератора текстур на основе gram матриц, составить такую картинку, где сохранены текстуры, но отсутствует пространственная информация.

VGG-16, обученная на обычных полноценных картинках, справилась с такими scrambled картинками довольно неплохо. Её top-5 accuracy упала с 90% до 80%. То есть, даже сети, обладающие довольно большими receptive field, всё равно предпочли запомнить текстуры и проигнорировать пространственную информацию. Поэтому их accuracy и не упала сильно на scrambled images.
Авторы провели ещё ряд экспериментов, где сравнивали какие части из изображений являются наиболее значимыми для BagNet и остальных сетей (VGG-16, ResNet-50, ResNet-152 и DenseNet-169). Всё намекало на то, что остальные сети так же как и BagNet при принятии решений опираются на небольшие фрагменты изображений и допускают примерно одинаковые ошибки. Особенно это было заметно для не очень глубоких сетей типа VGG.
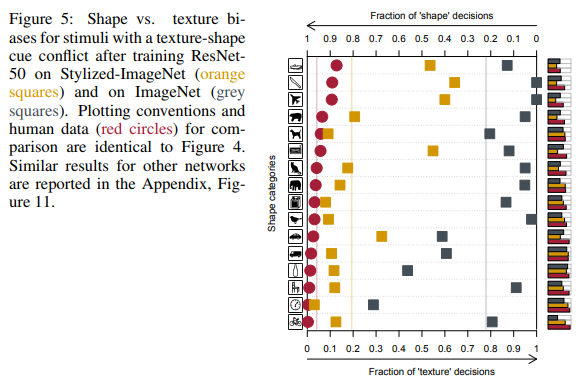
Эта склонность сетей принимать решения на основе текстур, в отличии от нас — людей, предпочитающих форму (см. рисунок ниже), подтолкнула авторов второй статьи на создание нового набора данных на основе ImageNet.
Stylized ImageNet
Первым делом авторы статьи с помощью style transfer создали набор изображений, где форма (пространственные данные) и текстуры на одном изображении противоречили друг другу. И сравнили результаты людей и глубоких свёрточных сетей разных архитектур на синтезированном наборе данных из 16 классов.

На крайнем справа рисунке люди видят кота, сети – слона.

Сравнение результатов людей и нейронных сетей.
Как видно, люди при отнесении объекта к тому или иному классу опирались на форму объектов, нейронные сети — на текстуры. На рисунке выше люди видели кота, сети — слона.
Да, тут можно придраться к тому, что сети тоже в чём-то правы и это, например, мог бы быть слон, сфотографированный с близкого расстояния, с татуировкой любимого котика. Но то, что сети при принятии решений ведут себя не так как люди, авторы посчитали проблемой и занялись поиском путей её решения.
Как было уже сказано выше, опираясь только на текстуры, сеть способна достичь неплохого результата в 86% top-5 accuracy. И речь идёт не о нескольких классах, где текстуры помогают правильно классифицировать изображения, а о большинстве классов.
Проблема именно в самом ImageNet, так как дальше будет показано, что сеть, способна выучить форму, но не делает этого, так как для получения хороших результатов на этом наборе данных достаточно и текстур, а нейроны, отвечающие за текстуры, находятся на неглубоких слоях, обучить которые гораздо легче.
Используя на этот раз несколько отличный механизм AdaIN fast style transfer авторы создали новый набор данных – Stylized ImageNet. Форма объектов бралась из ImageNet, а набор текстур из вот этого соревнования на Kaggle. Скрипт для генерации доступен по ссылке.

Далее для краткости ImageNet будем обозначать как IN, Stylized ImageNet как SIN.
Авторы взяли ResNet-50 и три BagNet с разными receptive field и обучили по отдельной модели для каждого из набора данных.
И вот что у них получилось:
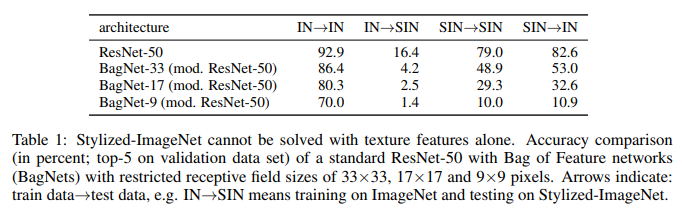
Что мы здесь видим. ResNet-50, натренированная на IN, полностью недееспособна на SIN. Что отчасти подтверждает то, что при тренировке на IN сеть оверфитится на текстуры и игнорирует форму объектов. В то же время ResNet-50 обученная на SIN прекрасно справляется и с SIN и с IN. То есть, если её лишить простого пути, сеть идет по трудному – учит форму объектов.
BagNet наконец-то начала вести себя ожидаемо, особенно на патчах малого размера, так как ей не за что зацепиться – текстурная информация попросту отсутствует в SIN.
На тех шестнадцати классах, что упоминались ранее, ResNet-50, обученная на SIN стала давать ответы больше похожие на те, что дают люди:
Кроме простого обучения ResNet-50 на SIN, авторы попробовали обучать сеть на смешанном наборе из SIN и IN, включая fine-tuning отдельно на чистом IN.

Как можно видеть, при использовании SIN+IN для обучения, результаты улучшились не только на основной задаче – классификации изображений на ImageNet, но и на задаче детектирования объектов на наборе данных PASCAL VOC 2007.
Кроме этого, сети, обученные на SIN стали более устойчивы к различному шуму в данных.
Заключение
Даже сейчас, в 2019 году, после семи лет прошедших с успеха AlexNet, когда нейронные сети широко используются в компьютерном зрении, когда ImageNet 1K де-факто стал стандартом для оценки работы моделей в академической среде, не совсем ясен механизм, как нейронные сети принимают решения. И как на это влияют наборы данных, на которых эти сети обучались.
Авторы первой статьи попытались пролить свет на то, как такие решения принимаются в сетях с архитектурой на основе bag-of-features с ограниченным receptive field, более простой для интерпретации. И, сравнив ответы BagNet и привычных глубоких нейронных сетей, пришли к выводу что процессы принятия решений в них довольно схожи.
Авторы второй статьи сравнили то, как картинки, на которых форма и текстуры противоречат друг другу, воспринимают люди и нейронные сети. И предложили для уменьшения различия в восприятии использовать новый набор данных – Stylized ImageNet. Получив в качестве бонуса прирост в точности классификации на ImageNet и детектиции на сторонних наборах данных.
Основной вывод можно сделать такой: сети, обучающиеся на картинках, имея возможность запоминать более высокоуровневые пространственные свойства объектов, предпочитают более лёгкий путь для достижения цели – оверфитнуться на текстуры. Если набор данных, на котором они тренируются, позволяет это.
Кроме академичсекого интереса проблема оверфиттинга на текстуры имеет значение и для всех нас, кто использует предобученные модели для transfer learning в своих задачах.
Важное для нас следствие из всего этого – не стоит доверять общедоступным предобученным на ImageNet весам моделей, так как для большинства из них использовались довольно простые аугментации, которые ни как не способствуют избавлению от оверфиттинга. И лучше, при наличии возможностей, иметь в заначке модели, обученные с более серьёзными аугментациями или же на связке Stylized ImageNet + ImageNet. Чтобы всегда была возможность сравнить, какая из них лучше подходит для нашей текущей задачи.
 с Keras")


")
