

Это пошаговая инструкция по классификации мультиспектральных снимков со спутника Landsat 5. Сегодня в ряде сфер глубокое обучение доминирует как инструмент для решения сложных проблем, в том числе геопространственных. Надеюсь, вы знакомы с датасетами спутниковых снимков, в частности, Landsat 5 TM. Если вы немного разбираетесь в работе алгоритмов машинного обучения, то это поможет вам быстро освоить это руководство. А для тех, кто не разбирается, будет достаточным знать, что, по сути, машинное обучение заключается в установлении взаимосвязей между несколькими характеристиками (набором признаков Х) объекта с другим его свойством (значением или меткой, — целевой переменной Y). Мы подаём на вход модели много объектов, для которых известны признаки и значение целевого показателя/класса объекта (размеченные данные) и обучаем ее так, чтобы она могла спрогнозировать значение целевой переменной Y для новых данных (неразмеченных).
В чём заключается основная проблема со спутниковыми снимками?
Два и более класса объектов (например, застройки, пустыри и котлованы) на спутниковых снимках могут иметь одинаковые спектральные характеристикизначения, поэтому в последние лет двадцать их классификация представляет собой трудную задачу.
Из-за этого, возможно использовать классические модели машинного обучения с учителем и без, но их качество будет далеко от идеала. Они всегда обладают одними и теми же недостатками. Рассмотрим пример:

Если в качестве классификатора использовать вертикальную линию и двигать её вдоль оси Х, то классифицировать изображения домов будет непросто. Данные распределены так, что разделить их на классы с помощью одной вертикальной линии невозможно (в таких случаях говорят, что «объекты разных классов не являются линейно разделимыми»). Но это не означает, что дома вообще нельзя классифицировать!
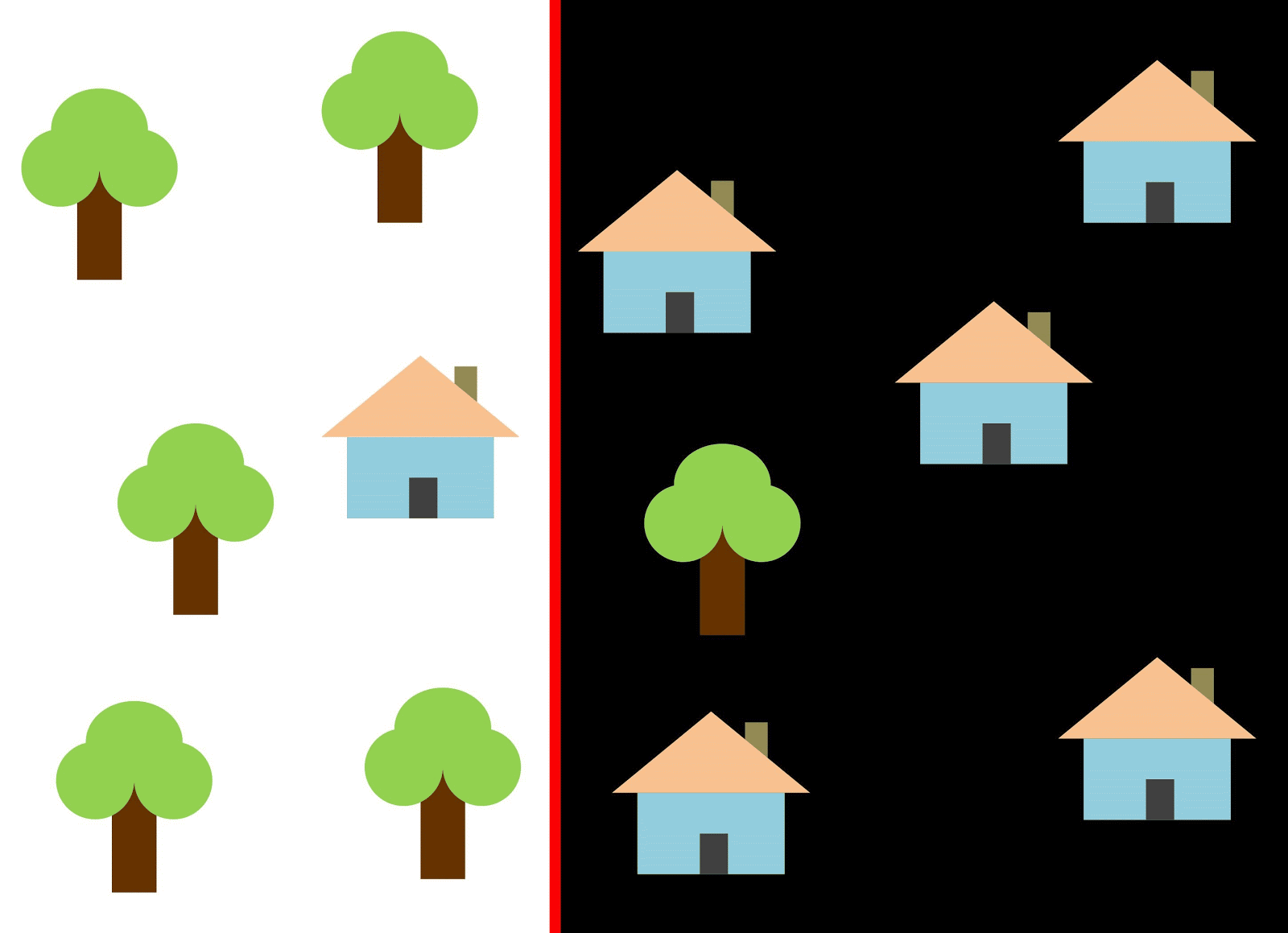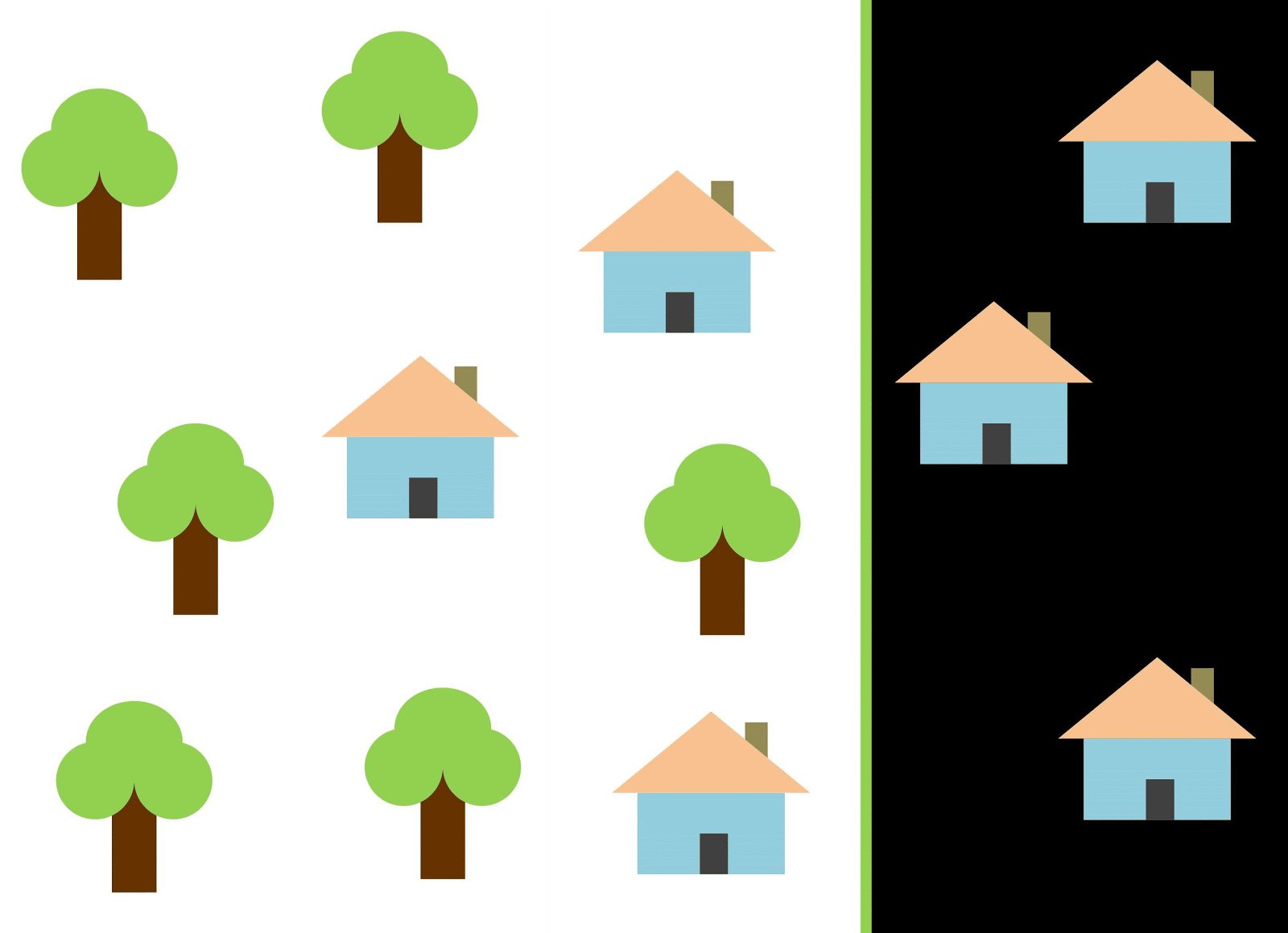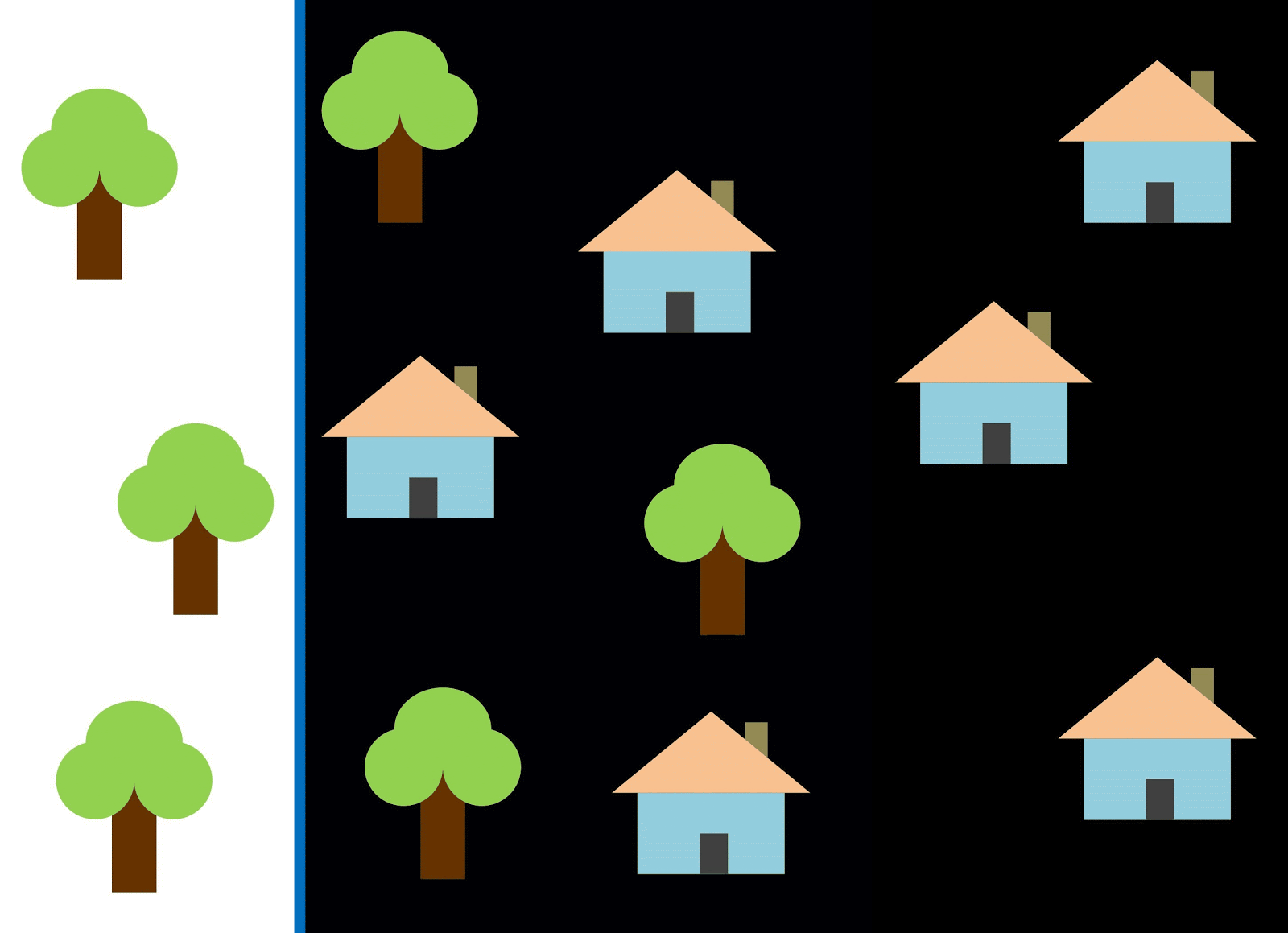
Давайте с помощью красной линии разделим два класса. В данном случае классификатор определил большинство домов, однако один дом не был отнесен к своему классу, а ещё три дерева были отнесены к «домам» ошибочно. Чтобы не пропустить ни один дом, можно использовать классификатор в виде синей линии. Тогда будут охвачены все дома, то есть мы говорим, что у метрики recall (полнота) высокое значение. Однако не все классифицированные значения оказались домами, то есть мы одновременно получили низкое значение метрики precision (точность). Если же мы воспользуемся зелёной линией, то все изображения, классифицированные как дома, действительно будут домами, то есть классификатор покажет высокую точность. В этом случае полнота будет меньше, поскольку три дома окажутся неучтёнными. В большинстве случаев нам приходится находить компромисс между точностью и полнотой.
Эта проблема домов и деревьев аналогична проблеме с застройкой, пустырями и котлованами. Приоритет метрик классификации спутниковых снимков может меняться в зависимости от задачи. Например, если вам нужно удостовериться, что все застроенные территории без исключений классифицированы как застройка, и вы готовы смириться с наличием пикселей других классов с аналогичными сигнатурами, которые тоже будут классифицированы как застройка, тогда вам потребуется модель с высокой полнотой. А если вам важнее классифицировать именно застройку, без добавления пикселей других классов, и вы готовы отказаться от классификации смешанных территорий, тогда выбирайте классификатор с высокой точностью. В случае с домами и деревьями обычная модель будет использовать красную линию, выдерживая баланс между точностью и полнотой.
Используемые данные
В качестве признаков мы будем использовать значения шести диапазонов (band 2 — band 7) изображения из Landsat 5 TM, и попытаемся спрогнозировать двоичный класс застройки. Для обучения и тестирования будут использованы многоспектральные данные (изображения и слой с бинарным классом застройки) с Landsat 5 за 2011 года для Бангалора. А для прогнозирования будут использованы многоспектральные данные Landsat 5, полученные в 2005-м в Хайдарабаде.
Поскольку мы используем для обучения размеченные данные, это называется обучение с учителем.

Многоспектральные обучающие данные и соответствующий двоичный слой с застройкой.
Для создания нейросети воспользуемся Python—библиотекой Google Tensorflow. Также нам потребуются эти библиотеки:
- pyrsgis — для чтения и записи GeoTIFF.
- scikit-learn — для предобработки данных и оценки точности.
- numpy — для базовых операций с массивами.
А теперь без дальнейших проволочек давайте писать код.
Положите все три файла в директорию, пропишите в скрипте путь и названия входных файлов, а затем прочитайте файлы GeoTIFF.
import os
from pyrsgis import raster
os.chdir("E:\\yourDirectoryName")
mxBangalore = 'l5_Bangalore2011_raw.tif'
builtupBangalore = 'l5_Bangalore2011_builtup.tif'
mxHyderabad = 'l5_Hyderabad2011_raw.tif'
# Read the rasters as array
ds1, featuresBangalore = raster.read(mxBangalore, bands='all')
ds2, labelBangalore = raster.read(builtupBangalore, bands=1)
ds3, featuresHyderabad = raster.read(mxHyderabad, bands='all')Модуль
raster из пакета pyrsgis считывает геолокационные данные GeoTIFF и значения цифровых номеров (DN) в виде отдельных NumPy-массивов. Если вас интересуют подробности, почитайте здесь.Теперь выведем на экран размер прочитанных данных.
print("Bangalore multispectral image shape: ", featuresBangalore.shape)
print("Bangalore binary built-up image shape: ", labelBangalore.shape)
print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)Результат:
Bangalore multispectral image shape: 6, 2054, 2044
Bangalore binary built-up image shape: 2054, 2044
Hyderabad multispectral image shape: 6, 1318, 1056Как видите, в изображениях Бангалора такое же количество строк и столбцов, как и в бинарном слое (соответствующем застройке). Количество слоёв в многоспектральных изображениях в Бангалоре и Хайдарабаде тоже совпадает. Модель будет учиться решать, какие пиксели относятся к застройке, а какие нет, на основе соответствующих значений по всем 6-ти спектрам. Поэтому многоспектральные изображения должны иметь одинаковое количество признаков (диапазонов), перечисленных в одном и том же порядке.
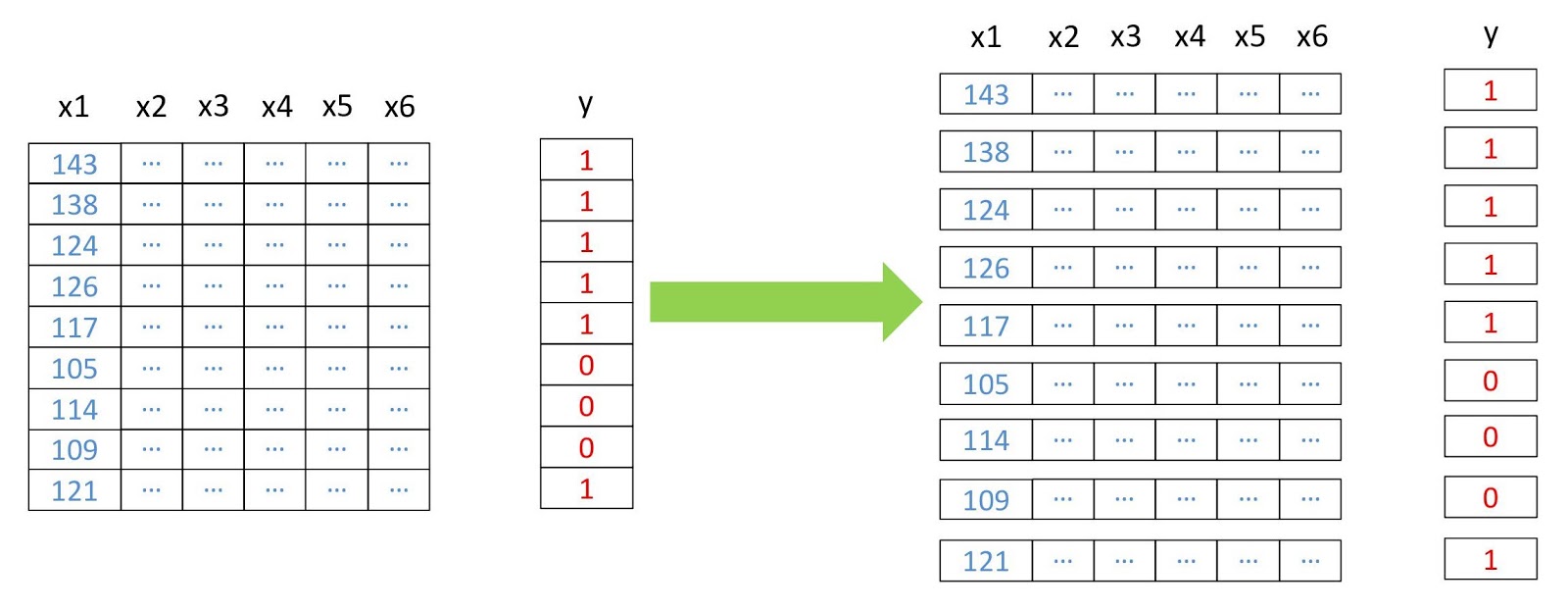
Теперь превратим массивы в двумерные, где каждая строка представляет отдельный пиксель, потому что это нужно для работы большинства алгоритмов машинного обучения. Сделаем мы это с помощью модуля
convert из пакета pyrsgis.
Схема реструктуризации данных.
from pyrsgis.convert import changeDimension
featuresBangalore = changeDimension(featuresBangalore)
labelBangalore = changeDimension (labelBangalore)
featuresHyderabad = changeDimension(featuresHyderabad)
nBands = featuresBangalore.shape[1]
labelBangalore = (labelBangalore == 1).astype(int)
print("Bangalore multispectral image shape: ", featuresBangalore.shape)
print("Bangalore binary built-up image shape: ", labelBangalore.shape)
print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)Результат:
Bangalore multispectral image shape: 4198376, 6
Bangalore binary built-up image shape: 4198376
Hyderabad multispectral image shape: 1391808, 6В седьмой строке мы извлекли все пиксели со значением 1. Это помогает избежать проблем с пикселями без информации (NoData), которые часто имеют крайне высокие или низкие значения.
Теперь разделим данные на обучающую и валидационную выборки. Это нужно для того, чтобы модель не видела тестовых данных и работала так же хорошо с новой информацией. Иначе модель переобучится и будет хорошо работать только на обучающих данных.
from sklearn.model_selection import train_test_split
xTrain, xTest, yTrain, yTest = train_test_split(featuresBangalore, labelBangalore, test_size=0.4, random_state=42)
print(xTrain.shape)
print(yTrain.shape)
print(xTest.shape)
print(yTest.shape)Результат:
(2519025, 6)
(2519025,)
(1679351, 6)
(1679351,)
test_size=0.4означает, что данные разделены на обучающие и валидационные в соотношении 60/40.
Многим алгоритмам машинного обучения, включая нейросети, нужны нормализованные данные. Это означает, что они должны быть распределены в рамках заданного диапазона (в данном случае от 0 до 1). Поэтому, чтобы выполнить это требование, мы нормализуем признаки. Сделать это можно с помощью извлечения минимального значения с последующим делением на разброс (разницу между максимальным и минимальным значениями). Поскольку датасет Landsat является восьмибитным, минимальное и максимальное значение будут равны 0 и 255 (2⁸ = 256 значений).
Обратите внимание, что для нормализации всегда лучше вычислять минимальные и максимальные значения на основе данных. Для упрощения задачи мы будем придерживаться восьмибитного диапазона по умолчанию.
Ещё один этап предварительной обработки заключается в преобразовании матриц признаков из двумерных в трёхмерные, чтобы модель воспринимала каждую строку как отдельный пиксель (отдельный объект обучения).
# Normalise the data
xTrain = xTrain / 255.0
xTest = xTest / 255.0
featuresHyderabad = featuresHyderabad / 255.0
# Reshape the data
xTrain = xTrain.reshape((xTrain.shape[0], 1, xTrain.shape[1]))
xTest = xTest.reshape((xTest.shape[0], 1, xTest.shape[1]))
featuresHyderabad = featuresHyderabad.reshape((featuresHyderabad.shape[0], 1, featuresHyderabad.shape[1]))
# Print the shape of reshaped data
print(xTrain.shape, xTest.shape, featuresHyderabad.shape)Результат:
(2519025, 1, 6) (1679351, 1, 6) (1391808, 1, 6)Всё готово, давайте соберём нашу модель с помощью keras. Для начала воспользуемся sequential-моделью, добавляя слои один за другим. У нас будет один входной слой с количеством узлов, равным числу диапазонов (
nBands) — в нашем случае их 6. Также будем использовать один скрытый слой с 14 узлами и функцией активации ReLu. Последний слой состоит из двух узлов для определения двоичного класса застройки с функцией активации softmax, которая подходит для вывода категоризированного результата. Подробнее о функциях активации написано здесь.from tensorflow import keras
# Define the parameters of the model
model = keras.Sequential([
keras.layers.Flatten(input_shape=(1, nBands)),
keras.layers.Dense(14, activation='relu'),
keras.layers.Dense(2, activation='softmax')])
# Define the accuracy metrics and parameters
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
# Run the model
model.fit(xTrain, yTrain, epochs=2)
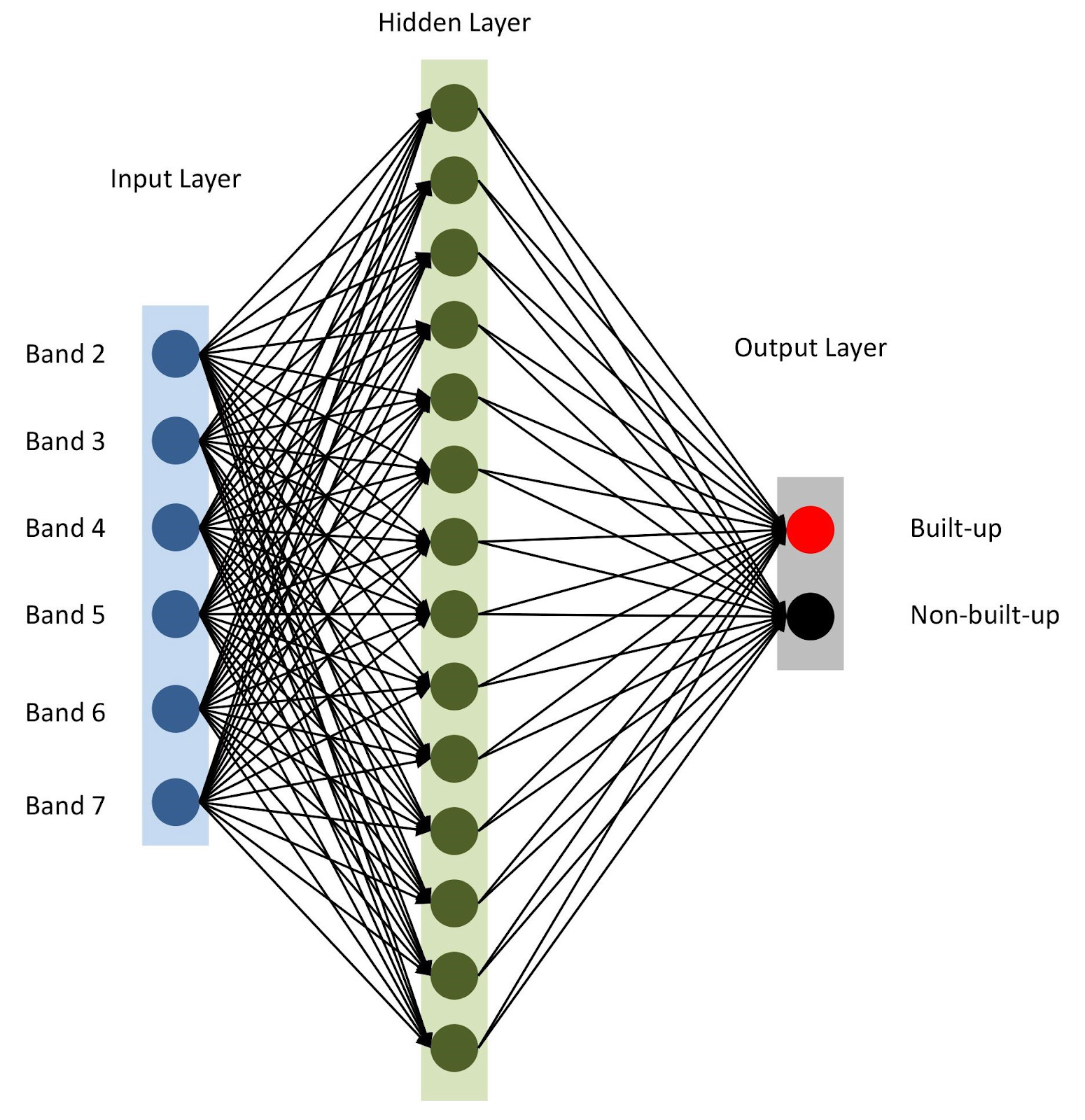
Архитектура нейросети
Как упоминалось в строке 10, мы задаем
adam в качестве оптимизатора модели (есть и несколько других). В данном случае будем использовать в качестве функции потерь перекрестную энтропию (en. categorical-sparse-crossentropy — подробнее о ней написано здесь). Для оценки качества работы модели будем использовать метрику accuracy.Наконец, запустим обучение нашей модели в течение двух эпох (или итераций) на
xTrain и yTrain. Это займёт какое-то время, в зависимости от размера данных и вычислительной мощности. Вот что вы увидите после компиляции:
Давайте спрогнозируем значения для валидационных данных, которые мы храним отдельно, и рассчитаем различные метрики точности.
from sklearn.metrics import confusion_matrix, precision_score, recall_score
# Predict for test data
yTestPredicted = model.predict(xTest)
yTestPredicted = yTestPredicted[:,1]
# Calculate and display the error metrics
yTestPredicted = (yTestPredicted>0.5).astype(int)
cMatrix = confusion_matrix(yTest, yTestPredicted)
pScore = precision_score(yTest, yTestPredicted)
rScore = recall_score(yTest, yTestPredicted)
print("Confusion matrix: for 14 nodes\n", cMatrix)
print("\nP-Score: %.3f, R-Score: %.3f" % (pScore, rScore))Функция
softmax генерирует отдельные столбцы для значений вероятности для каждого класса. Мы используем только значения для первого класса («есть застройка»), как видно по шестой строке приведенного выше кода. Оценивать работу моделей геопространственного анализа не так просто, в отличие от других классических задач машинного обучения. Будет нечестно полагаться на обобщенную суммарную ошибку. Ключом к успешной модели является пространственное расположение. Таким образом, матрица ошибок (confusion matrix), точность и полнота могут дать более корректное представление о качестве работы модели.
Так в консоли отображаются матрица ошибок, точность и полнота.
Как видно из confusion matrix, есть тысячи пикселей, которые относятся к застройке, но классифицированы иначе, и наоборот. Однако их доля от общего объёма данных не слишком велика. Точность и полнота на тестовых данных превысили порог в 0,8.
Вы можете потратить больше времени и выполнить несколько итераций для поиска оптимального количества скрытых слоев, количества узлов в каждом скрытом слое, а также количества эпох для достижения желаемой точности. По мере необходимости, в качестве признаков можно использовать индексы дистанционного зондирования вроде NDBI или NDWI. При достижении желаемой точности используйте модель для прогнозирования застройки на основе новых данных и экспортируйте результат в GeoTIFF. Для подобных задач можно использовать аналогичную модель с небольшими изменениями.
predicted = model.predict(feature2005)
predicted = predicted[:,1]
#Export raster
prediction = np.reshape(predicted, (ds.RasterYSize, ds.RasterXSize))
outFile = 'Hyderabad_2011_BuiltupNN_predicted.tif'
raster.export(prediction, ds3, filename=outFile, dtype='float')Обратите внимание, что мы экспортируем GeoTIFF со спрогнозированными значениями вероятности, а не с их бинаризированной по порогу версией. Позднее в ГИС-среде мы можем задать пороговое значение слоя типа float, как показано на рисунке ниже.

Слой застройки в Хайдарабаде, спрогнозированный моделью на основе многоспектральных данных.
Точность модели уже была измерена с помощью precision и recall. Вы можете провести и традиционные проверки (например, с помощью каппа-коэффициента) на новом спрогнозированном слое. Помимо вышеупомянутых сложностей с классификацией спутниковых снимков, к другим очевидным ограничениям относятся невозможность прогнозирования на основе снимков, сделанных в разное время года и в разных регионах, поскольку у них будут разные спектральные сигнатуры.
Описанная в этой статье модель имеет самую простую для нейросетей архитектуру. Лучших результатов можно добиться с более сложными моделями, в том числе свёрточными нейросетями. Главное преимущество такой классификации заключается в её масштабируемости (применимости) после обучения модели.
Использованные данные и весь код лежат тут.


