
Привет!
Часто ли вы видите токсичные комментарии в соцсетях? Наверное, это зависит от контента, за которым наблюдаешь. Предлагаю немного поэкспериментировать на эту тему и научить нейросеть определять хейтерские комментарии.
Итак, наша глобальная цель — определить является ли комментарий агрессивным, то есть имеем дело с бинарной классификацией. Мы напишем простую нейросеть, обучим ее на датасете комментариев из разных соцсетей, а потом сделаем простой анализ с визуализацией.
Для работы я буду использовать Google Colab. Этот сервис позволяет запускать Jupyter Notebook'и, имея доступ к GPU (NVidia Tesla K80) бесплатно, что ускорит обучение. Мне понадобится backend TensorFlow, дефолтная версия в Colab 1.15.0, поэтому просто обновим до 2.0.0.
Импортируем модуль и обновляем.
Посмотреть текущую версию можно так.
Подготовительные работы сделаны, импортируем все необходимые модули.
Я подгружаю данные прямо в сам Colab-ноутбук. Далее без проблем их уже извлекаю.
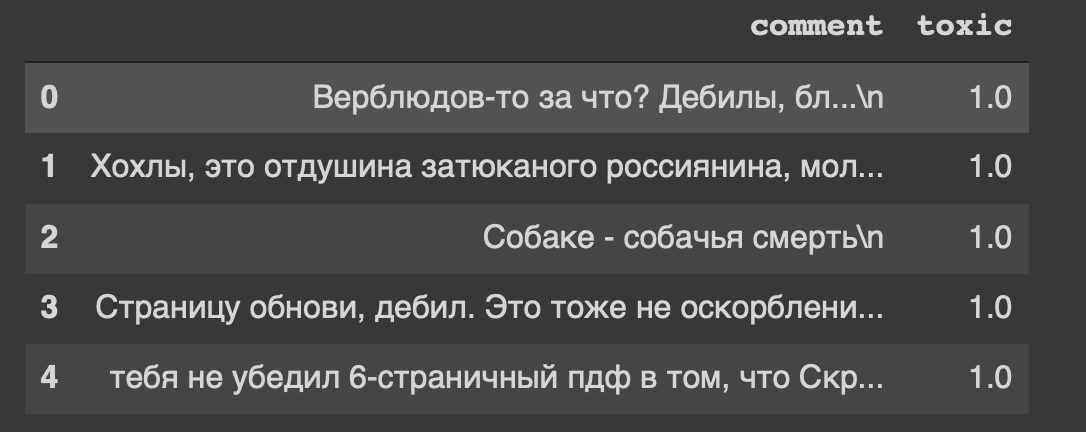
И это шапка нашего датасета… Мне тоже как-то не по себе от «страницу обнови, дебил».
Итак, наши данные находятся в таблице, мы ее разделим на две части: данные для обучения и для теста модели. Но это все текст, надо что-то делать.
Удалим символы новой строки из текста.
Комментарии имеют вещественный тип данных, нам необходимо перевести их в целочисленный. Далее сохраняем в отдельную переменную.
Теперь немного обработаем текст с помощью класса Tokenizer. Напишем его экземпляр.
Быстро про параметры
А теперь обработаем текст с помощью класса.
Получили 14к строк-образцов и 30к столбцов-признаков.

Я строю модель из двух слоёв: Dense и Dropout.
Нормализуем матрицу и разобьем данные на две части, как и договаривались (обучение и тест).
Процесс обучения покажу на последних итерациях.

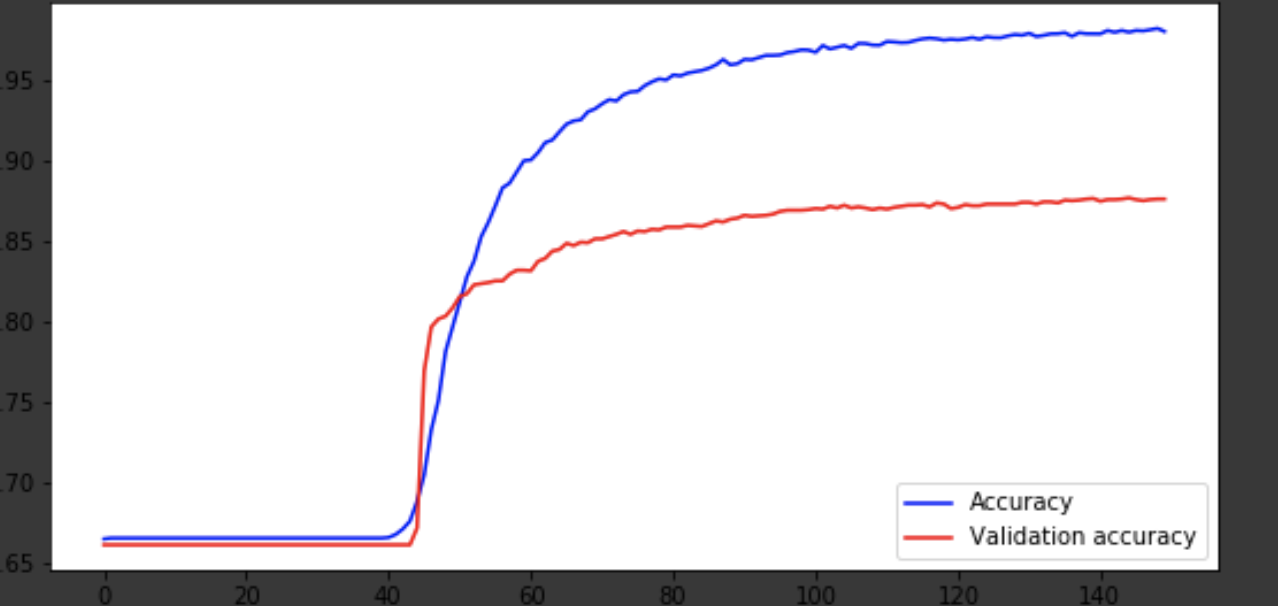
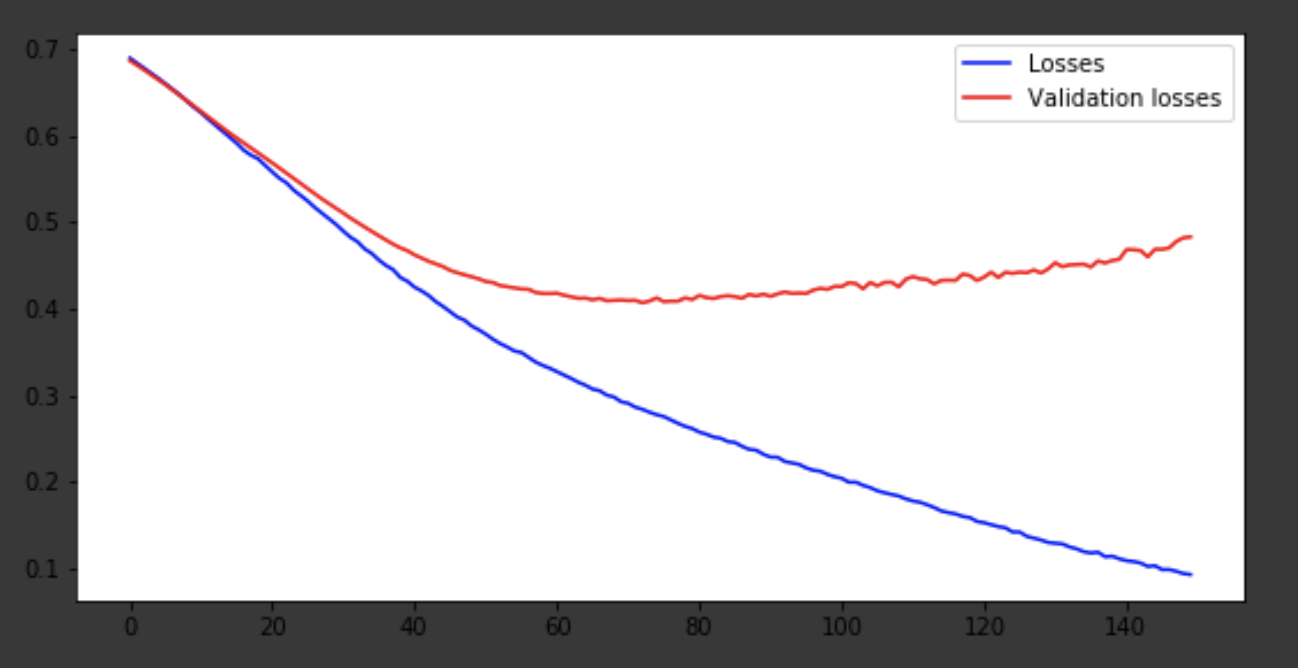
Модель вышла примерно на 75-ой эпохе, а дальше ведет себя плохо. Точность в 0,85 не огорчает. Можно поразвлекаться с количеством слоев, гиперпараметрами и попробовать улучшить результат. Это всегда интересно и является частью работы. О своих мыслях пишите в коменты, посмотрим, сколько хейта наберет эта статья.
Часто ли вы видите токсичные комментарии в соцсетях? Наверное, это зависит от контента, за которым наблюдаешь. Предлагаю немного поэкспериментировать на эту тему и научить нейросеть определять хейтерские комментарии.
Итак, наша глобальная цель — определить является ли комментарий агрессивным, то есть имеем дело с бинарной классификацией. Мы напишем простую нейросеть, обучим ее на датасете комментариев из разных соцсетей, а потом сделаем простой анализ с визуализацией.
Для работы я буду использовать Google Colab. Этот сервис позволяет запускать Jupyter Notebook'и, имея доступ к GPU (NVidia Tesla K80) бесплатно, что ускорит обучение. Мне понадобится backend TensorFlow, дефолтная версия в Colab 1.15.0, поэтому просто обновим до 2.0.0.
Импортируем модуль и обновляем.
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
!tf_upgrade_v2 -hПосмотреть текущую версию можно так.
print(tf.__version__)Подготовительные работы сделаны, импортируем все необходимые модули.
import os
import numpy as np
# For DataFrame object
import pandas as pd
# Neural Network
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
# Text Vectorizing
from keras.preprocessing.text import Tokenizer
# Train-test-split
from sklearn.model_selection import train_test_split
# History visualization
%matplotlib inline
import matplotlib.pyplot as plt
# Normalize
from sklearn.preprocessing import normalize
Описание используемых библиотек
- os — для работы с файловой системой
- numpy — для работы с массивами
- pandas — библиотека для анализа табличных данных
- keras — для построения модели
- keras.preprocessing.Text — для обработки текста, чтобы подать его в числовом виде для обучения нейронной сети
- sklearn.train_test_split — для отделения тестовых данных от тренировочных
- matplotlib — для визуализации процесса обучения
- sklearn.normalize — для нормализации тестовых и обучающих данных
Разбор данных с Kaggle
Я подгружаю данные прямо в сам Colab-ноутбук. Далее без проблем их уже извлекаю.
path = 'labeled.csv'
df = pd.read_csv(path)
df.head()И это шапка нашего датасета… Мне тоже как-то не по себе от «страницу обнови, дебил».
Итак, наши данные находятся в таблице, мы ее разделим на две части: данные для обучения и для теста модели. Но это все текст, надо что-то делать.
Обработка данных
Удалим символы новой строки из текста.
def delete_new_line_symbols(text):
text = text.replace('\n', ' ')
return textdf['comment'] = df['comment'].apply(delete_new_line_symbols)
df.head()Комментарии имеют вещественный тип данных, нам необходимо перевести их в целочисленный. Далее сохраняем в отдельную переменную.
target = np.array(df['toxic'].astype('uint8'))
target[:5]Теперь немного обработаем текст с помощью класса Tokenizer. Напишем его экземпляр.
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True,
split=' ',
char_level=False)Быстро про параметры
- num_words — кол-во фиксируемых слов (самых часто встречающихся)
- filters — последовательность символов, которые будут удаляться
- lower — булевый параметр, отвечающий за то, будет ли переведён текст в нижний регистр
- split — основной символ разбиения предложения
- char_level — указывает на то, будет ли считаться отдельный символ словом
А теперь обработаем текст с помощью класса.
tokenizer.fit_on_texts(df['comment'])
matrix = tokenizer.texts_to_matrix(df['comment'], mode='count')
matrix.shapeПолучили 14к строк-образцов и 30к столбцов-признаков.
Я строю модель из двух слоёв: Dense и Dropout.
def get_model():
model = Sequential()
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(16, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=RMSprop(lr=0.0001),
loss='binary_crossentropy',
metrics=['accuracy'])
return modelНормализуем матрицу и разобьем данные на две части, как и договаривались (обучение и тест).
X = normalize(matrix)
y = target
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2)
X_train.shape, y_train.shapeОбучение модели
model = get_model()
history = model.fit(X_train,
y_train,
epochs=150,
batch_size=500,
validation_data=(X_test, y_test))
historyПроцесс обучения покажу на последних итерациях.
Визуализация процесса обучения
history = history.history
fig = plt.figure(figsize=(20, 10))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(223)
x = range(150)
ax1.plot(x, history['acc'], 'b-', label='Accuracy')
ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy')
ax1.legend(loc='lower right')
ax2.plot(x, history['loss'], 'b-', label='Losses')
ax2.plot(x, history['val_loss'], 'r-', label='Validation losses')
ax2.legend(loc='upper right')Заключение
Модель вышла примерно на 75-ой эпохе, а дальше ведет себя плохо. Точность в 0,85 не огорчает. Можно поразвлекаться с количеством слоев, гиперпараметрами и попробовать улучшить результат. Это всегда интересно и является частью работы. О своих мыслях пишите в коменты, посмотрим, сколько хейта наберет эта статья.




