
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, меня зовут Максим Плавченок, я работаю в компании Bercut, занимаюсь интеграционным тестированием. В сентябре мы с командой прошли важную веху: получили ноль ошибок по результатам интеграционного тестирования для релиза новой версии биллинга для мобильного оператора. Мы шли к этому два года; хочу сегодня рассказать, за счёт чего нам удалось добиться цели.
Ноль ошибок по итогам интеграционных тестов – тут речь о тестировании новой функциональности на бизнес-приёмке на стороне оператора. Пара слов о том, как устроено это тестирование.
Мы выпускаем новые версии нашего биллингового софта по графику, 6 раз в год. Даты отгрузок релизов известны заранее. На момент написания этой статьи у нас уже есть запланированные даты релизов на весь следующий год.
Такая специфика связана с гонкой сотовых операторов за time-to-market. Главный принцип: абонент должен регулярно получать новые фичи биллинга. Платежи через смартфон, сохранение номера при смене оператора, возможность продавать неиспользованный трафик – обновления могут быть разными.
«Мы можем не знать, что именно мы зарелизим через год, но мы точно знаем дату, когда выйдет апдейт». За счёт этого удаётся выдерживать желаемый ритм обновлений.
У нас на стороне разработки биллинга в релизе участвует порядка 70 человек. Это 5-6 команд, каждая со своей специализацией: аналитика, разработка (несколько команд), функциональное тестирование, интеграционное тестирование.
Да, в биллинговых проектах у нас водопад. Но нынешняя история – не о том, как мы радикально изменили парадигму разработки с водопада на Agile или обратно. Каждый подход к разработке имеет свои преимущества и хорош в подходящих условиях; хочется это обсуждение оставить за рамками нынешней статьи. Сегодня хочу рассказать об эволюционном развитии: как мы двигались к нулю ошибок на приёмке релиза в рамках существующего подхода к разработке.
Зона дискомфорта
На момент начала описываемой истории, два года назад, мы имели следующую картину:
- команды в конце цепочки разработки бывали перегружены; «пора отдавать следующей команде, а предыдущая только-только начала свою часть работы»;
- заказчик мог находить после наших циклов тестирования в районе 70 ошибок.
Ошибки, которые можно было найти по результатам интеграционных тестов, могли быть минорными («часть сообщения отображается в виде прочерков») или даже критическими («не происходит переход на другой тариф»).
Мы решили изменить этот расклад: поставили цель – ноль ошибок на бизнес-приёмке на новой функциональности.
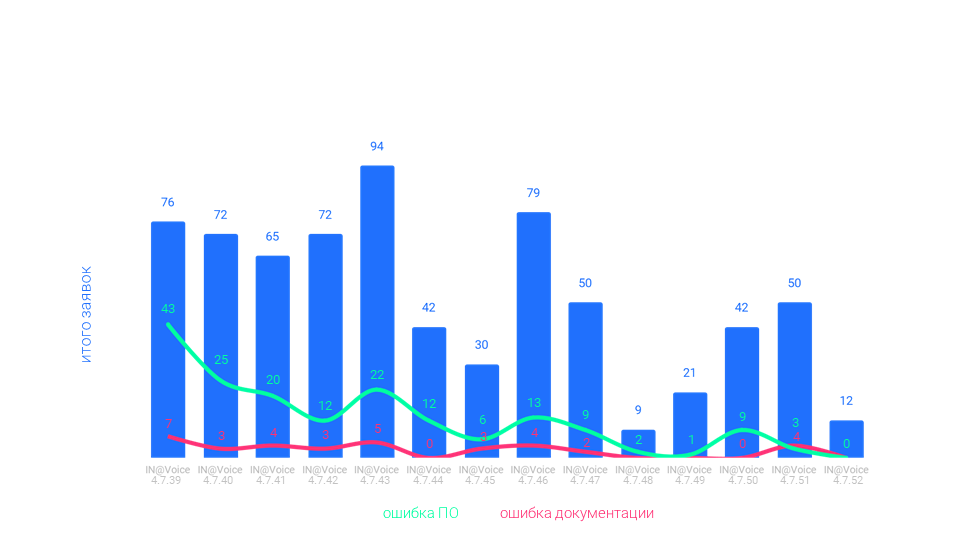
Через год мы смогли снизить число ошибок до 10-15, к середине 2020 – до 2-3. И вот в сентябре нам удалось достичь целевого нулевого показателя.
У нас получилось за счёт улучшений по нескольким направлениям: инструменты, экспертиза, документация, работа с заказчиком, команда. Улучшения различались по значимости: знать специфику и процессы заказчика – важно, перейти к новой шкале оценки сложности задач – опционально, а работать с мотивацией команды – критически важно. Но обо всём по порядку.
Точки роста
Главный инструмент интеграционного тестирования – тестовый стенд. Там происходит эмуляция деятельности абонента.
Общие стенды
На тестовые стенды накатываются дампы с продакшена – чтобы можно было тестировать в условиях, максимально приближенных к боевым.
Загвоздка в том, что дампы на наших стендах и стендах заказчика могли отличаться. Оператор делает дамп, передаёт нам, мы тестируем новую функциональность, отлавливаем и чиним баги. Отдаём готовую функциональность заказчику, коллеги на той стороне начинают тестировать. Наши и их дампы могли отличаться по актуальности: мы тестировали на июльском, оператор – на августовском, например.
Различия не критические, но всё-таки были. Это приводило к тому, что при тестировании на стороне заказчика могли появиться ошибки, которых не было у нас.
Что мы сделали: договорились, что схемы данных, на которых происходит тестирование, будут одинаковые, и в целом у нас будет общий стенд.
Отставание дампов осталось, но мы настроили инфраструктуру, на которой это отставание минимально. За счёт этого нам удалось уменьшить число ошибок, вызванных различиями тестовой и боевой сред.
Проверка настроек перед тестированием
Когда мы отдаём новую версию софта оператору, для тестирования на стороне заказчика нужно сделать настройку. Настроить новую функциональность, возможно, дополнительно настроить старую.
Чтобы рассказать о необходимых настройках, мы писали документацию. Только вот мануалы могли доносить информацию с искажениями. Документацию писали люди, читали люди, а в коммуникации людей случается недопонимание.
Такова специфика нашего софта: к настройкам предъявляются высокие требования по гибкости и срокам готовности. Настройки – сложные, и без дополнительной коммуникации средствами одной только документации не всегда удавалось передать всю необходимую информацию.
В итоге настройки могли выполняться не всегда верно, что приводило к обнаружению ошибок во время тестирования на стороне оператора. При разборе мы выясняли, что это были ошибки не софта, а именно настроек. Такие ошибки тратят драгоценное время.
Что мы сделали: ввели процедуру проверки нами настроек на стороне заказчика перед началом тестирования на стендах оператора.
Процедура такая: заказчик выбирает кейсы, которые мы показываем на настроенном стенде. Запускаем тесты. Если ошибки есть, мы их оперативно исправляем; если нет – тест считается пройденным.
Такой подход позволил нам при интеграционном тестировании уменьшить число ошибок, связанных с неправильными настройками.
Дополнительные коммуникации вокруг документации
Проверка настроек перед тестированием вдобавок к описанию этих настроек в мануалах – это один пример дополнительных коммуникаций вокруг документации. Были и другие.
Например, мы сделали так, что на нашей стороне в каждый момент времени всегда был специалист, к которому заказчик мог обратиться с вопросами по документации и системе в целом. Что-то вроде выделенной линии технической поддержки с нашими специалистами высокой квалификации.
Наши технические писатели организовали воркшопы для обучения сотрудников заказчика по использованию новой функциональности.
Процесс передачи документации стал менее дискретным, более непрерывным: новая информация, уточнения, рекомендации – теперь могли досылаться частями после “отгрузки” основных мануалов; по мере появления или по потребности.
Всё это позволило лучше информировать заказчика о новой функциональности и через это уменьшить число ошибок на интеграционных тестах.
Экспертиза по работе со сторонними системами
Для разработки биллинга нам нужно уметь вести учёт трафика. Для этого существуют отдельные PCRF-системы. Учёт звонков происходит в одной базе, СМС там же, а трафика – в другой базе; и есть специальное ПО, которое это всё синхронизирует.
При этом PCRF-системы – это сторонний проприетарный софт. То есть чёрный ящик: мы отдаём туда данные, получаем что-то в ответ, но не можем контролировать, что происходит внутри. И тем более не можем ничего там менять.
Такой расклад ограничивал наши возможности по локализации и починке багов, связанных с трафиком.
Что мы сделали: завели отдельную внутреннюю базу знаний по PCRF. Каждый инцидент, каждый вариант настройки, каждый инсайт – всё записывалось и шарилось в команде.
В итоге мы стали неплохими пользователями PCRF-системы, можем её настроить и понимаем, что она должна делать. Это позволяет экономить время на простых инцидентах. Со сложными случаями, конечно, всё равно обращаемся за помощью к разработчикам системы.
Больше стендов
Ещё одна особенность в тестировании биллинга мобильных операторов – пользовательские сценарии могут быть растянуты во времени. Полный сценарий, который мы хотим проверить, может занимать несколько дней или даже недель.
На этапе тестирования ждать несколько дней или недель затруднительно. В действительности для проверки таких сценариев чаще всего просто отматывается время в базе.
Чтобы перемотать время, нужно закрыть все сессии, кроме своей. Получаем ситуацию, когда на два тестовых стенда может претендовать, условно, 20 тестировщиков, и каждый хочет перемотать время. Это очередь. А очередь – это вероятность того, что к оговоренной дате отгрузки софта можем не успеть проверить всё как следует.
Что мы сделали: завели отдельный стенд для каждого тестировщика.
Это позволило нам убрать ошибки, которые случались из-за «поздно дошла моя очередь к стенду, не успел».
Виртуализация
Подготовка стенда – небыстрый процесс. Нужно подключиться к сети оператора, запросить доступы, и это ещё не всё. Полная процедура могла занимать до нескольких недель. Борьба за сокращение времени подготовки стенда была важным направлением в движении к цели в ноль ошибок.
Что мы сделали: задействовали виртуализацию.
Копирование виртуальных машин со всеми нужными настройками, предустановленным софтом и автоматизация этого процесса помогли сократить время подготовки стенда до «в пределах дня».
Планирование
Ошибки из интеграционных тестов – это ещё и результат просчётов в планировании релиза. Замахнулись на много, на момент фиксированной даты релиза успели не всё.
Что мы сделали: ввели промежуточные дедлайны для каждого этапа разработки. “Если известна конечная дата, то известна и каждая промежуточная" – такой принцип помог нам лучше контролировать скорость движения к цели релиза.
Саппорт и релиз параллельно
В начале нашего пути случалась ситуация, когда “долги” прошлого релиза конфликтовали с релизом следующим. После приёмки на стороне заказчика приезжали баги, все дружно отправлялись их чинить.
График выпуска релизов при этом не сдвигался. В итоге в то время, когда уже пора было заняться следующим релизом, мы могли всё ещё продолжать заниматься предыдущим.
Изменить ситуацию удалось за счёт выделения из команды двух групп: кто будет чинить ошибки с приёмки и кто будет заниматься новым релизом по графику.
Деление было условное: не обязательно половина туда, а половина сюда. Мы могли перебрасывать людей между группами по необходимости. Со стороны могло выглядеть, как будто ничего не поменялось: вот человек из команды, за спринт он и багами позанимался, и новыми фичами. Но по факту выделение отдельных групп было улучшением из разряда “теперь мы можем выдохнуть”. Сфокусированность каждой группы и распараллеливание работ между группами сильно нам помогли.
Хронологически это была одна из первых точек роста, которую мы сформулировали на постмортеме. И тут мой рассказ подходит к части про главный инструмент.
Главный инструмент
Улучшение, которое помогло нам больше всего – честные постмортемы.
Кто-то называет это ретроспективой, кто-то – анализом итогов; у нас в команде прижилось слово «постмортем». Все описываемые в этой статье улучшения были придуманы на постмортемах.
Принцип простой: случился релиз, нужно собраться и честно обсудить, как всё прошло. Звучит просто, но в реализации есть подводные камни. После «неудачного» релиза у людей в команде бывает настроение «некогда языками чесать, нужно дело делать». Кто-то может приходить на постмортемы и отмалчиваться (и таким образом, не доносить часть потенциально полезной информации).
За два года движения к цели в ноль ошибок у нас сложился ряд принципов, как мы проводим постмортемы.
- Собрать полную картину
Приглашаем расширенный состав участников. Разработчиков, тестировщиков, аналитиков, менеджеров, руководителей – всех, у кого есть желание высказаться. Организационно, собрать всех-всех не всегда получается. Это ок, так тоже работает. Речь о том, чтобы не отказывать в участии коллегам с формулировкой “мы тут в своей команде итоги подводим, вы в своей подведите”. Работа со стендами, код, процессы, взаимодействие – стремимся не упустить из виду ни одного аспекта.
- Не хвататься за всё сразу
Ок, по итогам постмортема мы придумали 30 точек роста. Сколько брать в работу? Может, у нас получится решить все до следующего раза? Для нас лучше всего сработал формат «выбрать 2-3». При таком раскладе есть фокус, и усилия людей в команде не распыляются. Лучше сделать меньше, но полностью, чем много, но не довести до ума.
- Не мудрить с форматом
Существует масса подходов к проведению постмортемов. Фасилитационные практики, приёмы из дизайн-мышления и латерального мышления, техника Голдратта и других уважаемых экспертов. По нашему опыту для старта достаточно здравого смысла. Записали проблемы, сгруппировали, выбрали несколько кластеров, отодвинули в сторону остальное (см. предыдущий пункт), обсудили, зафиксировали план. Когда есть единая цель, найти общий язык не так сложно.
- Брать в работу
Пожалуй, главный принцип в этом списке. Каким бы перспективным и убедительным ни получился список улучшений по итогам постмортема, если он не идёт в работу, то всё зря. Договорились, значит, делаем. Да, есть другие срочные дела. Но ещё у нас есть цель, и мы хотим к ней приближаться.
Постмортем может быть довольно болезненным процессом. Разговаривать о неуспехе, ещё и в конструктивном ключе непросто. Но побороть дискомфорт – стоит того. Уверен, что без постмортема нам не удалось бы придумать и реализовать все те вещи, которые помогли достичь цели в ноль ошибок в релизе.
Самый главный инструмент
Постмортем позволяет находить средства для достижения цели, но если разобраться, то и его можно назвать следствием более высокоуровневого принципа.
Самый главный инструмент – вовлечение команды.
У вовлечения есть инструментальная сторона. Например:
- если работаем сверхурочно, то начальник рядом с командой, помогает руками;
- если подбадривать команду трекингом прогресса, то найти наглядные метрики (для числа ошибок – несложно).
И дальше в том же духе.
Есть у вовлечения и сложно формализуемая сторона – способность делиться с командой своей верой в успех. Мы ведь с командой не то, чтобы заглянули в брошюру с ценностями компании, увидели там «сильнее вместе» и решили, что, бинго, решение найдено. Мы видели примеры, как непростые цели можно достигать через объединение усилий. У нас в команде были люди, кто верил в успех и стремился передать это убеждение коллегам. Остальное – дело техники.
Люди – самое главное.
В движении к цели в ноль ошибок в релизе было ещё много всего. Работа над улучшением документации, повышение скорости и качества реакции на вопросы заказчика – разное. В этот раз я постарался поделиться только некоторыми примерами и рассказать о базовых принципах.
Нам с командой ещё многое предстоит сделать в борьбе за качество релизов и оптимизацию time-to-market. Сделать регулярно воспроизводимым результат с нулем ошибок на интеграционных тестах, автоматизировать регресс.
Как достичь этих целей – нам ещё только предстоит выяснить. Но что мы точно знаем уже сейчас: мы обязательно будем делать постмортемы и реализовывать точки роста по мотивам. И постараемся пользоваться возможностями, которые есть у вовлечённой команды.
Надеюсь, что-нибудь из этого может быть полезно и вам.




