
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Одно время, приходилось много работать с логами. Они могли быть большими и находиться на разных серверах. Требовалось не найти что-то конкретное, а понять почему система ведёт себя не так как надо. По некоторым причинам, лог-агрегатора не было.
Хотелось иметь просмотрщик логов, позволяющий, в любой момент, открыть любой файл, без скачивания на локальную машину, как команда less в linux консоли. Но при этом, должна быть удобная подсветка текста, как в IDE, и фильтрация записей по различным параметрам. Фильтрация и поиск должны работать по событиям в логе, а не по строкам, как grep, это важно когда есть многострочные записи, например ошибки со стектрейсами. Так же должна быть возможность просматривать записи сразу из нескольких файлов на одной странице, смёржив их по таймстемпу, даже если файлы находятся на разных нодах.
И я придумал как сделать такую утилиту!
Log Viewer - это небольшое web-приложение, которое работает на нодах, где лежат логи, и показывает эти логи через Web интерфейс. Это именно просмотрщик, а не агрегатор, нет никакой индексации или считывания всего лога в память, читается только та часть лога, которую пользователь смотрит в текущий момент. Такой подход позволяет почти не занимать ресурсов.
Предвижу вопросы о производительности типа «Разве можно быстро фильтровать записи без индексации? В плохих случаях придётся остcканировать весь лог чтобы найти хоть одну запись подходящую под фильтр». Во первых, сканирование лога работает довольно быстро, 1Гб читается около 3,5сек, это терпимо. Во вторых, обычно известен временной интервал, в котором ищем проблему, если задан фильтр по дате, то будет сканироваться только та часть файла, в которой находятся записи относящиеся к тому времени. Найти границу временного интервала в файле можно очень быстро бинарным поиском.
Отображение лога
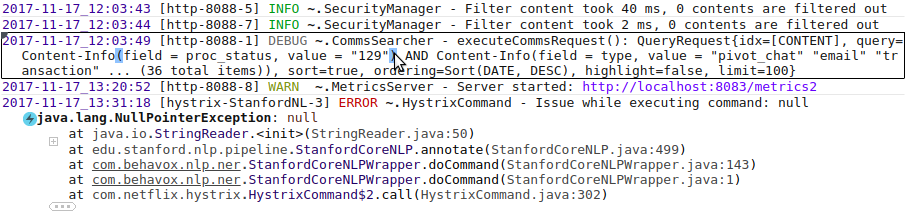
Чтобы легче различать границы одной записи, запись под курсором подсвечивается прямоугольником; поле severity подсвечивается различными цветами в зависимости от значения, парные скобки подсвечиваются когда наводишь курсор на одну из них.
Обратите внимание на стектрейс эксепшена, показаны только самые интересные строки, остальные сфолжены под «+» и «…» , интересными строками считаются классы из пакетов принадлежащий главному приложению, соседнии с ними, и первая строка. Пакеты главного приложения задаются в конфигурации. В таком виде стектрейс занимает намного меньше места на экране и его удобней смотреть. Возможно такая идея понравится разработчикам Java IDE.
Имя логгера тоже сокращено: «~.SecurityManager». Показывается только имя класса, а пакет сворачивается в «~».
Фолдинг влияет только на отображение, поиск работает по оригинальному тексту. Если совпадение найдётся в сокращённой части текста, то эта часть текста автоматически появится. Также, если пользователь выделит текст и нажмёт Ctrl+C, в буфер скопируется исходный текст, без всяких сокращений.
Архитектура позволяет легко навешивать на текст подсветку или всплывающие подсказки, благодаря этому, сделаны разные приятные мелочи типа показа даты в человеческом формате, если она напечатана в виде числа:

Фильтрация
Набор фильтров зависит от формата лога. Некоторые фильтры доступны всегда, например фильтр по подстроке, а некоторые появляются если в логе присутствует поле определённого типа. Это позволяет создавать специализированные фильтры для некоторых типов полей. Например, если в логе есть поле severity, то в верхней панельке появится такой UI компонент:
Severity filter
Очень удобно добавлять фильтры из контекстного меню. Можно выделить текст, кликнуть правой кнопкой мыши и выбрать «Не показывать записи с таким текстом». На панельку с фильтрами автоматически добавится фильтр по тексту, скрывающий записи с таким текстом. Помогает когда лог завален однообразными записями, не интересными в данный момент.
Добавление фильтров из контекстного меню
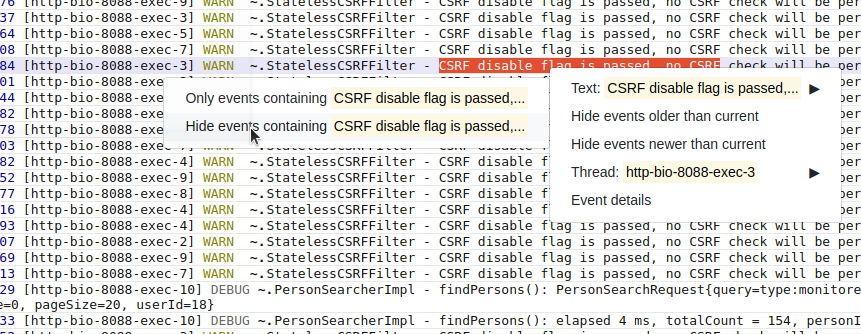
Можно кликнуть на запись и выбрать «Скрыть последующие записи» или «Скрыть предыдущие записи», чтобы работать только с определённой частью лога. Скрытие происходит добавлением фильтра по дате.
Для сложных случаев можно задать фильтр с условием написанным на JavaScript. Такой фильтр представляет из себя функцию принимающую одну записи и возвращающую true или false.
Пример фильтра на JavaScript
function isVisibleEvent(text, fields) {
var match = text.match(/Task completed, elapsed time: (\d+)ms$/)
if (!match)
return false // Don't show events not matched the pattern
var time = parseInt(match[1])
return time > 500 // Show only events where elapsed time is more than a threshold
}При изменении фильтров, просмотрщик старается максимально сохранить позицию в логе. Если есть выделенная запись, то изменение фильтров не изменит её положения на экране, а записи вокруг пропадут или появятся. Пользователь может задать фильтр, чтобы были видны только ошибки, найти подозрительную ошибку, затем убрать фильтр и смотреть что происходило вокруг этой ошибки.
Состояние панели фильтров отображается в параметрах URL, чтобы можно было добавить в закладки браузера текущую конфигурацию.
Мелкие, но полезные фичи
Когда находишь что-то интересное — хочется поделиться этим с командой, для этого можно создать специальную ссылку на текущую позицию в логе, и любой кто её откроет увидит точно такую же страницу, которая была при создании ссылки, включая состояние фильтров, текста в поле поиска, выделенной записи и т.д.
Если сервер расположен в другой таймзоне, над текстом с датой будет всплывающая подсказка с датой в таймзоне пользователя.
Конфигурация
Я старался сделать конфигурацию как можно проще, чтобы всё работало из коробки. Если попросить пользователя задать формат лога, то большинство просто закроют приложение и пойдут смотреть по старинке. Поэтому формат лога распознаётся автоматически. Конечно, это работает не всегда и часто не точно. Для таких случаев можно задать формат лога вручную в файле конфигурации. Можно использовать паттерны log4j, logback или просто регексп. Если ваш лог не распознался, но вам кажется что должен — создайте issue на GitHub, этим вы поможете проекту.
Самая нужная настройка — список видимых файлов. По умолчанию доступны все файлы с расширением «.log» и видна вся структура каталогов, но это не очень хорошо с точки зрения секьюрити. В конфигурационном файле можно ограничить видимость файлов с помощью списка паттернов типа такого:
logs = [
{
path: "/opt/my-app/logs/*.log"
},
{
path: ${HOME}"/work/**"
}
]Пользователю будут доступны только .log файлы в директории /opt/my-app/logs и любые файлы в директории ~/work и её поддиректориях.
Более подробная информация в документации на GitHub.
Работа с несколькими нодами
Мёрж файлов, расположенных на разных нодах — это киллер фича, ради которой и затевался проект. Как я уже говорил, файл никогда не скачивается полностью с одной ноды на другую и не индексируется. Поэтому, на каждой из нод должен быть запущен Log Viewer. Пользователь открывает web UI на одной из нод, указывает расположение логов, и Log Viewer коннектится к другим инстансам LogViewer чтобы подгружать содержимое лога через них. Записи из всех открытых файлов мёржатся по таймстемпу и показываются как буд-то это один файл.
Вкрадце опишу как это работает под капотом. Когда пользователь открывает страницу, надо показать конец лога, для этого на каждую ноду отправляется запрос «дай последние N записей», где N — количество строк помещающихся на экран. Полученные записи сортируются по таймстемпу, берутся последние N записей и показываются пользователю. Когда пользователь скролит страницу вверх, на все ноды посылается запрос «дай последние N записей с таймстемпом меньше T», где T — таймстемп самой верхней записи на экране. Полученные записи сортируются и добавляются на страницу. При скроле вниз происходит тоже самое, только в другую сторону. Поиск позиции в файле, где находятся записи старше/младше T, работает очень быстро, так как записи отсортированы по таймстемпу и можно использовать бинарный поиск. Там есть много нюансов, но общая схема такая. Мёрж работает только если система смогла определить фомат лога и в каждой записи задан полный тайстемп.
На данный момент, нет UI для выбора файлов на разных нодах, приходится прописывать файлы в параметрах URL в таком виде:
http://localhost:8111/log?path=/opt/my-app/logs/a.log@hostname1&path=/opt/my-app/logs/b.log@hostname1&path=/opt/my-app/logs/c.log@hostname2
здесь каждый параметр "path" задаёт один файл, после "@" указывается хост, на котором лежит файл и запущен инстанс просмотрщика логов. Можно указать несколько хостов через запятую. Если "@" отсутствует — файл находится на текущей ноде. Чтобы не иметь дела с огромными URL, есть возможность задать короткие ссылки в конфигурации, в разделе log-paths = { … }.
Встраивание просмотрщика в своё приложение
Log Viewer можно подключить к своему Java Web приложению как библиотеку, чтобы оно могло показывать пользователю свои логи. Иногда это удобней чем запуск отдельным приложением. Достаточно просто добавить зависимость на библиотеку библиотеку через Maven/Gradle и подключить один конфигурационный класс в spring context. Всё остальное сконфигурится автоматически, log viewer сам распознает какая система логгирования используется и возьмёт из её конфигурации расположение и формат логов. По умолчанию UI маппится на /logs, но всё можно кастомизировать. Пока автоматическая конфигурация работает только с Log4j и Logback.
Это тестировалось на маленьком количестве приложений, если у вас возникнут проблемы — смело пишите в discussions на GitHub.
Что планируется сделать в будущем
Было бы удобно, если бы была возможность оставлять комментарии к записям. Например, прикрепить номер тикита к сообщению об ошибке. Комментарий должен быть виден всем пользователям и, когда такая же ошибка вылетит в следующий раз, будет понятно что с ней делать.
Есть много идей по мелкому улучшению UI. Например, если в тексте встретился кусок JSON, то хочется чтобы просмотрщик умел показывать его в отформатированном виде, а не одной строкой. Хочется иметь возможность задать фильтр по severity для отдельного класса, а не сразу для всех.
Иногда нет возможности открыть порт на сервере для просмотра логов, есть только SSH доступ. Можно сделать поддержку работы через SSH. Web UI будет подниматься на локальной машине, коннектиться через SSH к серверу и запускать там специального агента. Агент будет принимать команды через input stream и возвращать нужные части лога через output stream.
Буду рад услышать фидбэк.


