
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Привет, Хабр!
Деплоймент приложений в мультикластерной среде Kubernetes — одна из самых актуальных тем. Подход позволяет расширить возможности для масштабирования сервисов, обеспечить локальность трафика за счёт географического расположения кластеров, добиться роста надёжности и отказоустойчивости развёртываемого решения, а также исключить риски взаимного влияния приложений в рамках одного кластера.
Вместе с тем управлять жизненным циклом подобных федеративных приложений довольно сложно. Под катом я предлагаю рассмотреть ключевые задачи в рамках создания федеративных сервисов и построить референсную архитектуру мультикластерного деплоймента, которую можно имплементировать в разных облачных инфраструктурах.
Строим архитектуру мультикластерного сервиса
Для иллюстрации мультикластерного подхода мы будем использовать простую систему, которая состоит из двух приложений. APP 1 обрабатывает внешний трафик от пользователей данной системы и в свою очередь вызывает APP 2 для обработки запросов, например, сохранения информации в базе данных.
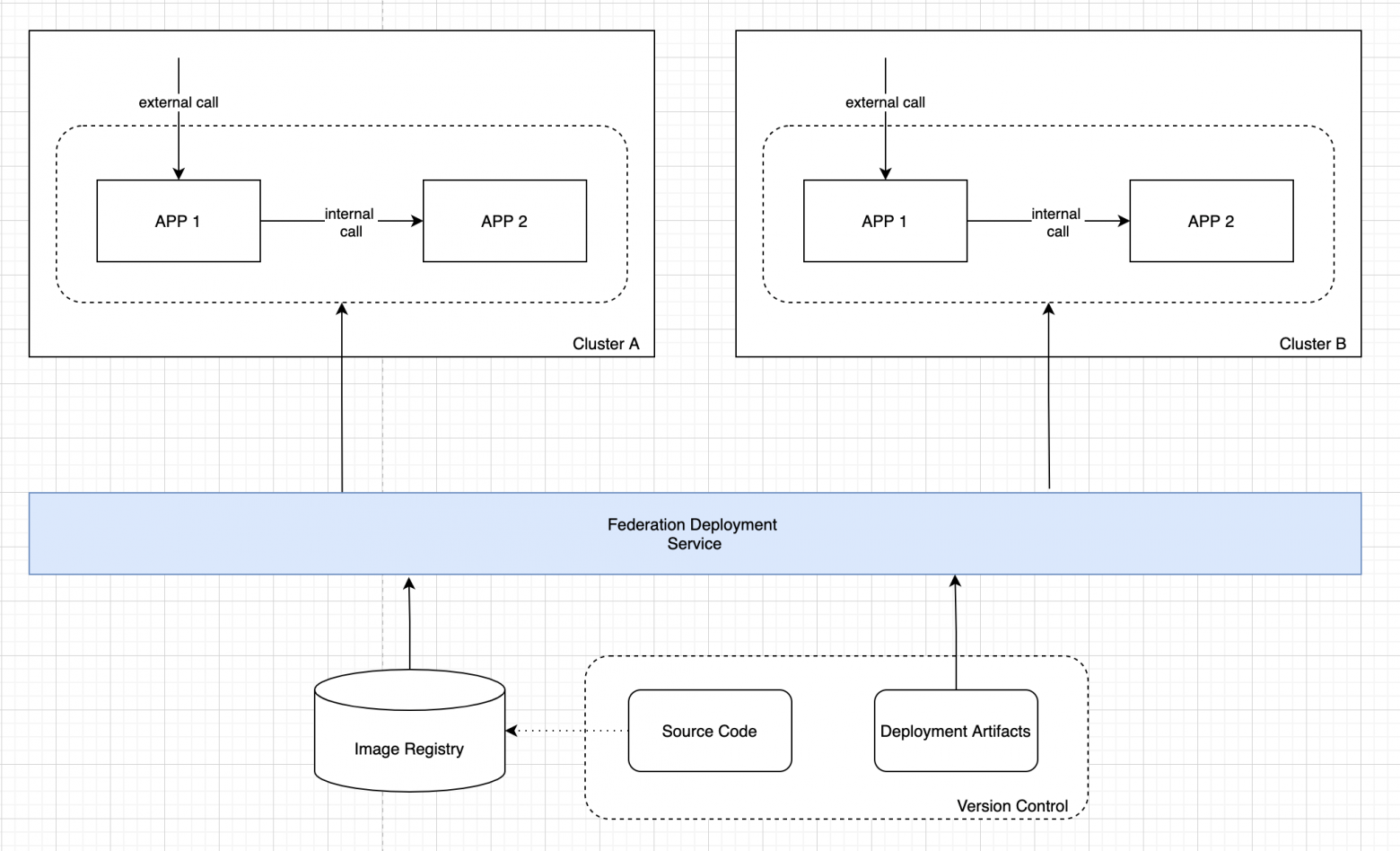
Исходный код наших приложений, как и артефакты для развёртывания (ресурсы Kubernetes, Helm-чарты или, например, шаблоны OpenShift), — всё размещается в системе версионного контроля. Дополнительно исходный код доступен в подготовленном для развёртывания виде — готовые docker-образы размещаются в корпоративном хранилище образов.
Теперь, когда у нас есть всё необходимое для развёртывания приложения, давайте подумаем, что нужно для того, чтобы сделать этот сервис мультикластерным.
Первая задача, которую надо решить, — деплоймент приложения. Когда у нас один кластер, это решается просто. Достаточно использовать kubectl apply либо более продвинутые подходы с шаблонами, например helm или шаблонизатор OpenShift.
Однако в условиях множества кластеров данный подход не масштабируется. Недостаточно просто запустить установку последовательно с разным окружением, так как при этом мы не можем автоматически обеспечить консистентность кластеров на уровне управления жизненным циклом приложения.
С учётом этой проблематики сформулируем требования для решения первой задачи. Нам необходим специализированный сервис для автоматизированного мультикластерного развёртывания, который:
использует стандартные артефакты (образ приложения и манифесты с возможностью шаблонизации) для развёртывания;
разворачивает приложение по заданному списку кластеров с обеспечением отката изменений по заданному набору критериев (например, при неуспешном деплойменте в один из кластеров);
обеспечивает непрерывную доставку изменений с автоматической поддержкой консистентности деплоймента в мультикластерной среде.
Теперь давайте отразим этот сервис в архитектуре и посмотрим на промежуточную схему.
Вторая задача — обеспечение балансировки и аварийного переключения для внешних запросов.
«Однокластерный» подход начинается с использования Ingress Controller на границе Kubernetes. Дополнительно необходим балансировщик нагрузки, который обеспечит распределение трафика между узлами кластера, где запущены экземпляры Ingress Controller. Такой балансировщик может предоставляться облачным провайдером для managed-кластеров, а может быть настроен вручную для on-premise-инсталляций.
В случае мультикластерной инсталляции данный подход масштабируется, однако при этом необходим дополнительный слой балансировки для распределения трафика уже между кластерами. В итоге мы получаем примерно такую картину:
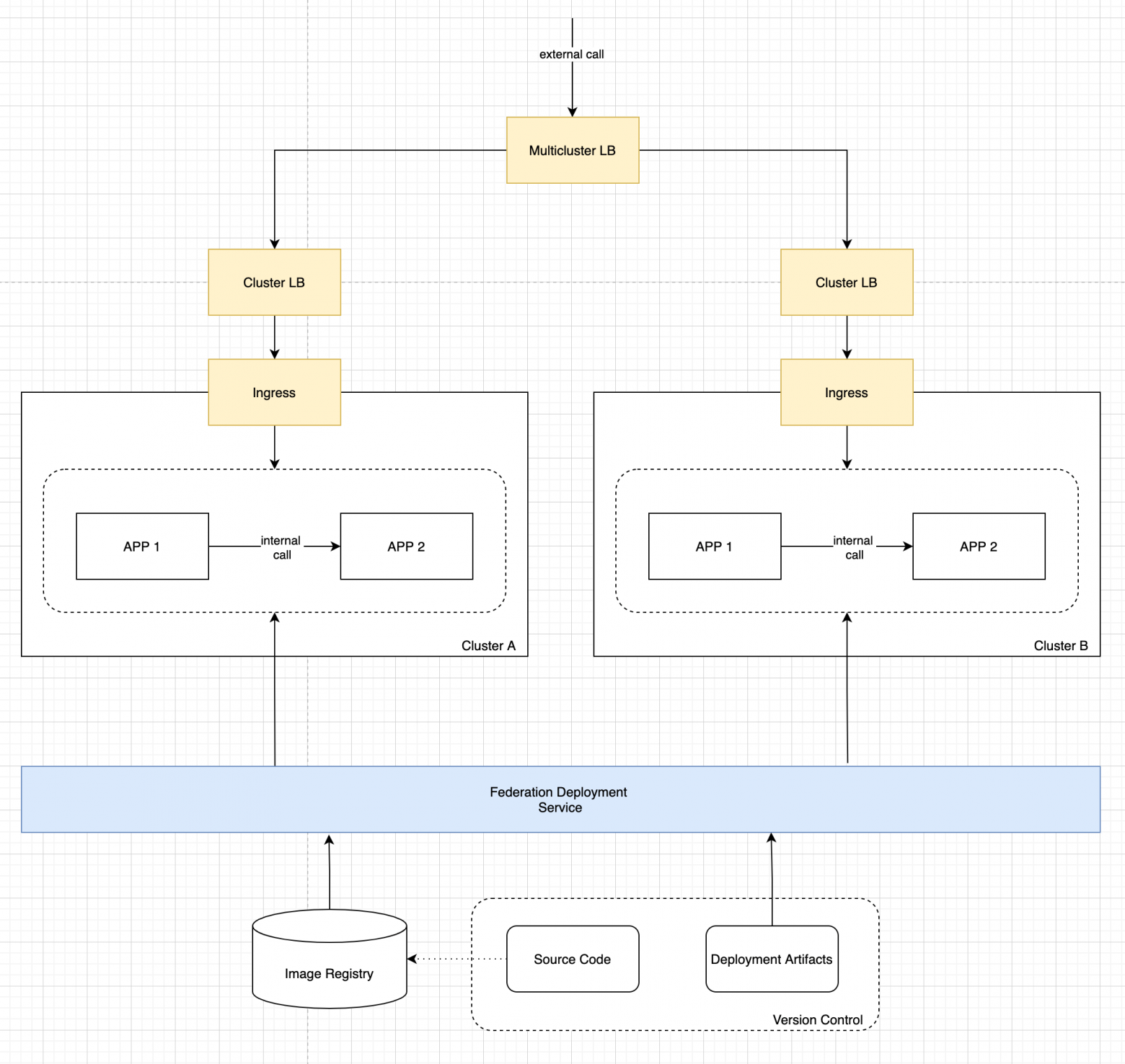
Данная схема решает поставленную задачу, однако является непрозрачной и сложной для конечного пользователя. Помимо стандартного набора действий для публикации приложения, необходимо помнить о том, что сервис является мультикластерным и необходима как минимум дополнительная настройка правил на уровне Multicluster LB.
Для устранения этого недостатка можно использовать специальный сервис, который инкапсулирует все подробности мультикластерной топологии приложения. Данный сервис:
предоставляет пользователю единый ресурс для публикации приложений в мультикластерной топологии;
обеспечивает генерацию всех необходимых сетевых ресурсов в рамках всех кластеров для балансировки и аварийного переключения внешних запросов;
обеспечивает непрерывную доставку изменений с автоматической поддержкой консистентности в мультикластерной среде.
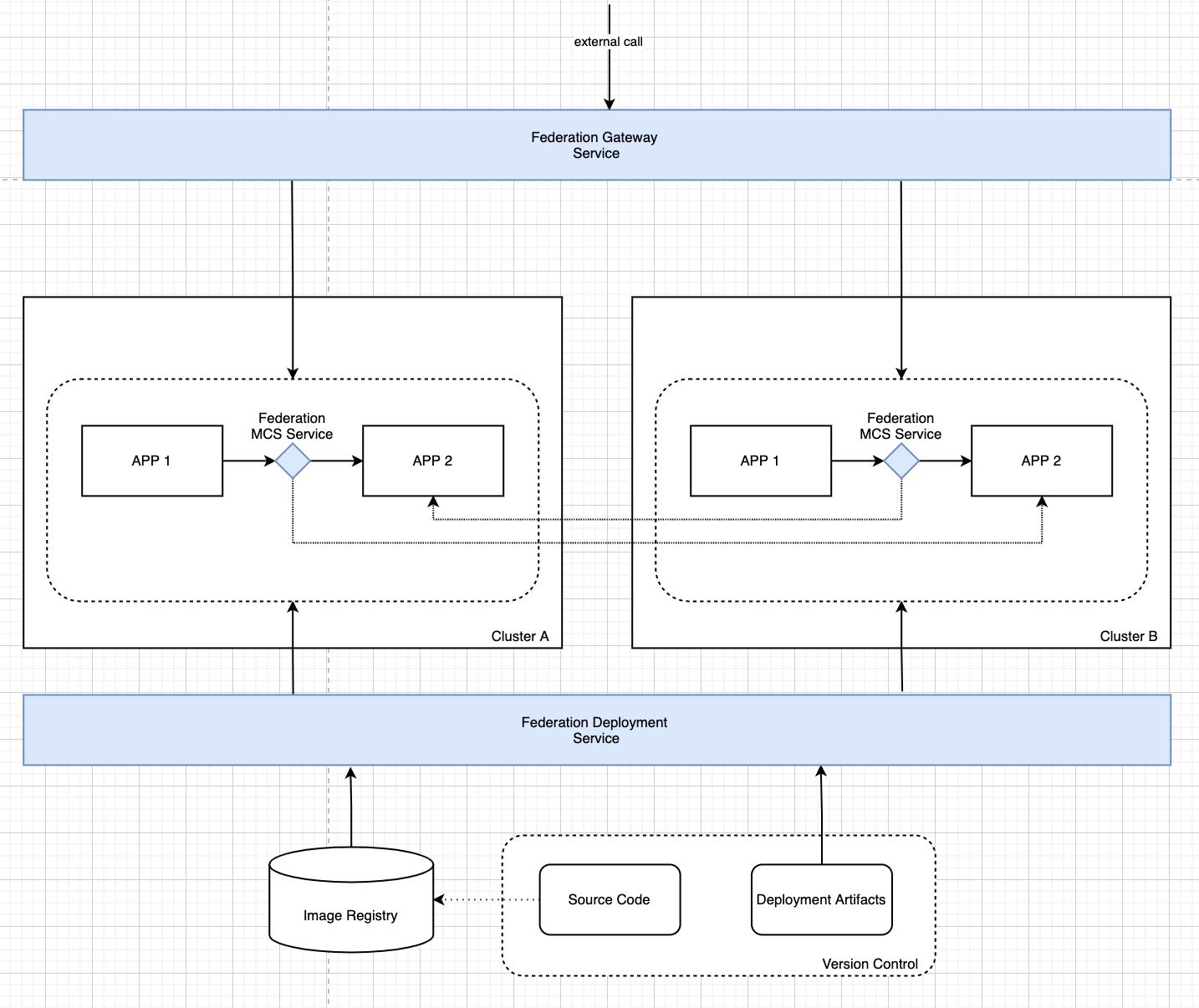
Таким образом, после решения второй задачи наша архитектура выглядит как на рисунке ниже
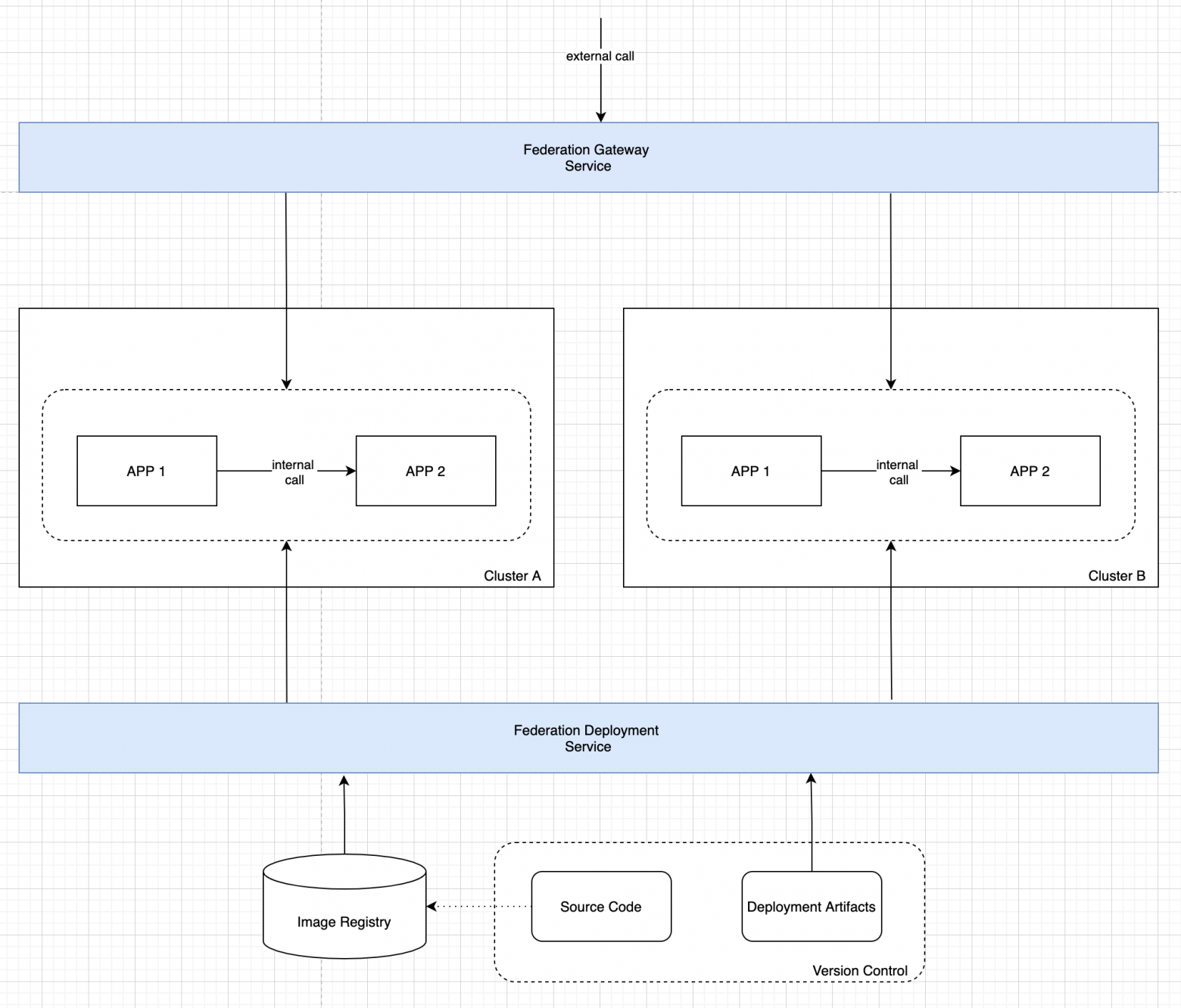
В рамках третьей задачи нам необходимо обеспечить балансировку и аварийное переключение для внутренних вызовов в нашей системе. Сложность в том, что мы не можем публиковать внутренние сервисы так же, как и внешние, но при этом должна быть возможность сетевых вызовов между кластерами. Кроме того, эта возможность должна быть прозрачна для приложений: мультикластерные сетевые вызовы осуществляются по тем же правилам, что и внутрикластерные.
Таким образом, нам необходим сервис, который:
обеспечивает возможность публикации сервисов из удалённых кластеров в текущем, при этом удалённые сервисы доступны для вызова тем же способом, что и локальные;
в ситуации, когда удалённый сервис имеет экземпляры и в текущем кластере, обеспечивается объединение удалённых и локальных экземпляров в рамках единого вызываемого адреса;
для удалённых сервисов, в том числе и с локальными экземплярами, обеспечивается балансировка и аварийное переключение по заданным правилам. Например, в случае недоступности локальных экземпляров удалённого сервиса трафик переключается на удалённые экземпляры в других кластерах.
С учётом решения третьей задачи общая архитектура выглядит так, как показано на рисунке ниже.
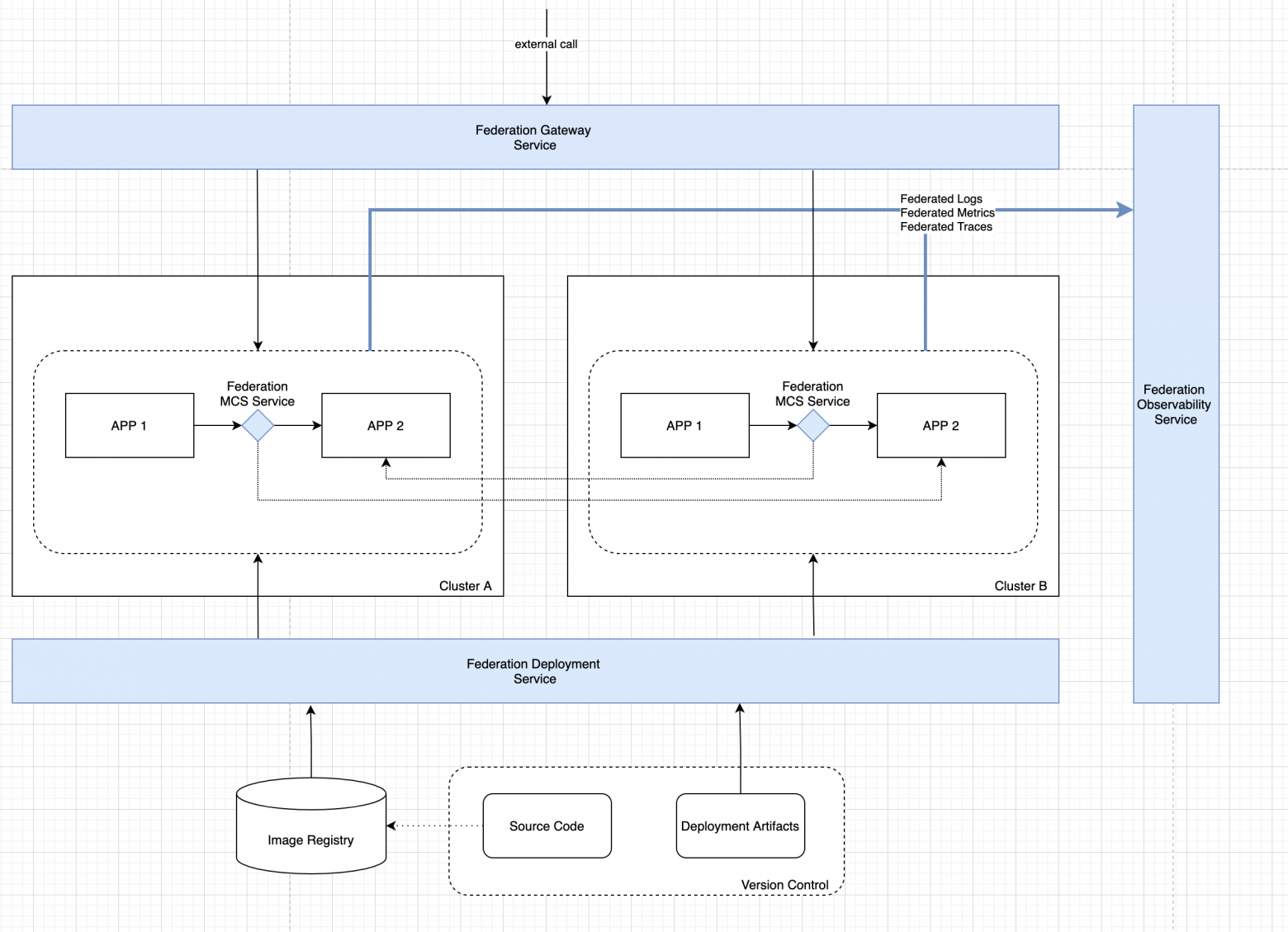
И наконец, в рамках четвёртой задачи важно не забыть об обозреваемости нашего приложения. Журналы, метрики и данные трассировки крайне важны при построении микросервисных систем, а в условиях мультикластерного деплоймента степень критичности данного функционала значительно увеличивается.
Для обеспечения достаточного уровня обозреваемости нам потребуется сервис, который:
агрегирует журналы приложений, данные трассировки и данные мониторинга (метрики) с учётом мультикластерной топологии развёртывания;
предоставляет унифицированный доступ к агрегированным данным.
В итоге мы получаем готовую архитектуру мультикластерного сервиса:
Реализуем архитектуру
Мы рассмотрели типовые задачи, которые необходимо решить для мультикластерной схемы развёртывания приложений в Kubernetes, и получили референсную архитектуру мультикластерного приложения.
Все сервисы в этой архитектуре я специально сделал абстрактными. Конкретную реализацию каждого из них вы можете найти у провайдера вашей облачной инфраструктуры или реализовать всё самостоятельно в частном облаке.
А ещё данная архитектура может быть легко имплементирована на базе продуктов Platform V Synapse. Это позволит не тратить ресурсы, не привязываться к сервису конкретного облака и сконцентрироваться исключительно на бизнес-логике.
Platform V Synapse — cloud-native децентрализованная интеграционная платформа для импортозамещения любых корпоративных сервисных шин. Входит в состав Platform V — облачной платформы для разработки бизнес-приложений, которая стала основой цифровизации Сбера.
Synapse построена на основе современного технологического стека и использует передовые open sourсe и cloud native технологии: Envoy, Kafka, Flink, Ceph, Kiali, Docker и другие.
В составе 6 ключевых модулей:
Synapse Service Mesh — надёжная интеграция и оркестрация микросервисов в облаке;
Synapse Nerve — безопасная передача файловой информации между системами и микросервисами в облаке, со встроенными средствами визуализации, мониторинга и анализа данных;
Synapse EDA — потоковая обработка событий;
Synapse AI — предиктивное управление трафиком, обогащаемое при помощи искусственного интеллекта и машинного обучения;
Synapse AppSharding — реализация горизонтального масштабирования для БД, не поддерживающих sharding «из коробки»;
Synapse API Management — публикация, управление доступом и аналитика использования API.
Сбер использует Platform V Synapse уже больше двух лет. За это время платформа позволила уменьшить среднее время задержки отклика систем с 50 мс до 8 мс, снять ограничения по масштабированию и снизить связанность систем. Synapse продемонстрировала отказоустойчивость 99,99%, выдержала нагрузки более 50 000 tps и сократила стоимость разработки на 54%.
В Сбере Synapse стала базой для миграции с legacy на микросервисный подход. Теперь продукт поставляется бизнесу и государству по модели PaaS и on-premise.


