
Не все дата-сайентисты умеют хорошо писать код. Их этому не учили. Также их не учили писать веб-сервисы, и они могут забывать, что код должен быть проверен. Дата-сайентисты — не разработчики, от них ждут высоких метрик и решения поставленных задач, а не умения писать модульные тесты и следить за кодом. По крайней мере, им это не прививают. Не говоря уже о том, что они не работают с Kubernetes и не пишут для него Helm charts.
Но нам с командой дата-сайентистов пришлось это все освоить и запустить. Меня зовут Дмитрий Аникин, в «Лаборатории Касперского» я занимаюсь оптимизацией внутренних бизнес-процессов со стороны Data Science. Хочу рассказать, какие проблемы у нас возникали на пути нашей модели — от простого артефакта до самостоятельного сервиса — и как мы их решили, освоив все несвойственные дата-сайентистам процессы. Как справедливо замечено в нашем самопредставлении, именно в таких моментах — весь драйв!

Всю эту историю расскажу на примере живого проекта MDR (Kaspersky Managed Detection and Response).
Пара слов о самой задаче. У нас есть компьютеры пользователей, в рамках сервиса MDR активность этих пользователей логируется, а данные отправляются по сети экспертам, чтобы они проанализировали логи на опасные инциденты. Проблема в том, что этот поток очень сильно забит алертами, ненужными для аналитиков, — это бесполезная трата их времени. Поэтому мы решили отфильтровать эти срабатывания правил. Как и в любом Data Science-проекте, у нас был заказчик, данные и желание. И с помощью экспериментов мы стали брать эти данные и проверять гипотезы:
Мы делаем это, как правило, в jupyter notebook. И это классная вещь, потому что документация внутри оформлена с помощью удобных markdowns, есть встроенные графики, удобно делиться инсайдами внутри команды и показывать какие-то метрики заказчикам. Правда, с jupyter есть и проблемы (особенно на удаленной работе), связанные с тем, что он немного недопилен в определенных местах. На JupyterCon 2018 был классный доклад «I don’t like notebooks» про плохие привычки, которые вырабатывает jupyter.
Тем не менее на этом этапе у нас есть артефакт, то есть результат нашего кода. Это обученная модель, которая способна решать задачу, и в нашем случае — это задача фильтрации потока. Но вместе с моделью мы обнаружили и проблемы. И первая из них была связана с воспроизводимостью.
Эта проблема важна и актуальна, потому что в первую очередь воспроизводимость нужна для экспериментов. Мне как дата-сайентисту не нравится, когда я на своем проекте получаю какие-то классные результаты, но эксперимент, который я потом пытаюсь воспроизвести, дает совсем другой результат. Хочется, чтобы результат на экспериментах был воспроизводим.
Также воспроизводимость полезна при дебаге. Если ваша модель ошиблась в проде, особенно если это какой-то критический пропуск, то вы или заказчик захотите понять, почему она приняла то или иное решение. С помощью воспроизводимости, применив какие-то методы интерпретации нашей модели, мы сможем понять это.
Еще воспроизводимость помогает переиспользовать результаты тестов в моделях по итогам их переобучения и экспериментов с ними — чтобы рассчитать качество заново и понять, удовлетворяет ли оно нашим ожиданиям.
Но на пути к воспроизводимости есть несколько подводных камней.
Те самые jupyter notebooks привносят путаницу состояний. Например, когда у вас падает соединение с тетрадкой, вы не можете узнать, на какой стадии находится ваше обучение и сколько вам осталось учить вашу модель.
Или это происходит, когда я беру тетрадку своего коллеги и хочу воспроизвести его результат, просто запуская его notebook шаг за шагом. Но в какой-то момент он падает, хотя этого быть не должно: он же уже готов, я просто воспроизвожу его модель.
Путаница состояний может случиться по разным причинам: коллега в творческом порыве выполнял ячейки в другом порядке или что-то установил из notebook, а потом стер эту ячейку. Эту проблему мы легко решили вынесением этапа обучения нашей модели и кода, который их обучает, в отдельные скрипты и модули.
Например, мой коллега, экспериментируя с новыми фичами, апгрейднул Keras, и все прошло нормально. Но когда я беру его скрипт или тетрадку и начинаю фитить модель, то не получаю похожую ошибку, потому что оказывается, что моя версия Tensorflow с данной версией Keras не очень дружит, а коллега ее не добавил:

Что в этой ситуации можно сделать? Разрешить и эту проблему было несложно — решение очевидное, но об этом нужно помнить, потому что про очевидное часто забывают:
Думаю, все знают, что проблема рандома тоже существует. Например, у нас были тесты на модуль train_model.py, и там один из тестов должен был подтвердить, что если два раза обучить catboost-модель на одинаковых данных, то roc auc по предиктам не поменяется. Тесты для keras-модели там не участвовали вообще, и когда мы начали их прогонять, то выяснилось, что просто так они этот тест не проходят.
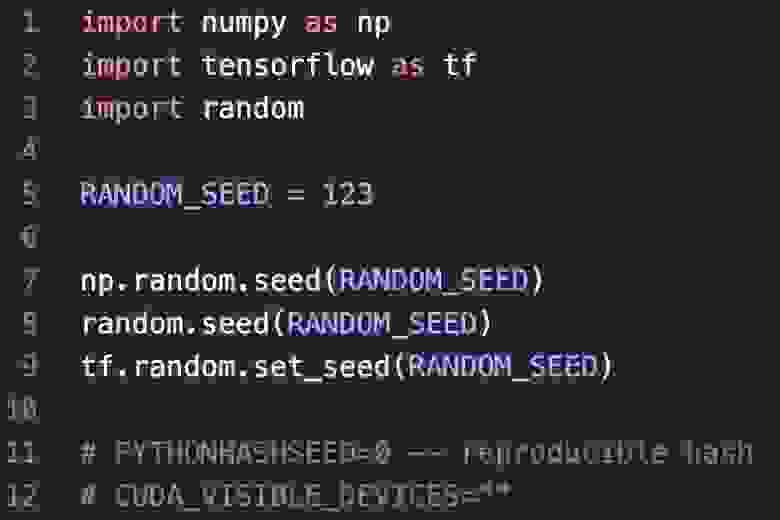
Это отдельная головная боль, но тоже решаемая: вам нужно зафиксировать seed, причем во множестве мест — в NumPy, просто в Python, в Tensorflow. То есть конфигурируем случайности проекта в отдельном месте.
Так мы прошли несколько камней преткновения на пути к воспроизводимости:

Но есть еще одна важная проблема, о которой я расскажу чуть-чуть подробней.
Версионировать желательно все. Модели версионируют многие, и это вроде бы очевидно — мы хотим уметь их сравнивать между собой. Это очень полезно, когда идет автоматическое переобучение и вы в рантайме подкладываете модель к вашему сервису, который ее использует. Для этого есть множество уже проверенных вариантов, например:
Данные, как и модели, тоже хорошо версионировать, к тому же есть DVC. Но все становится хуже с экспериментами и результатами — про это помнит меньше людей. Например, ваш тимлид хочет получить от вас решения для задачи по повышению качества. Вы проводите ряд экспериментов для проверки гипотез, и вам нужно эти гипотезы сравнивать, чтобы понять, какая лучше. Для этого можно поднять mlflow-сервер, но ваши коллеги могут не захотеть им пользоваться, потому что им нужно вспоминать, куда пушить, и вообще привнести новую практику может быть достаточно тяжело.
Но если предложить полуавтоматизированное решение — небольшой декоратор, который скрывает всю логику, — то коллегам останется только прописать все необходимое для лога эксперимента и отправить это на ML-сервер. И они начинают пользоваться вашим инструментом.

Mlflow, который я предложил в качестве решения
И очевидно, что нужно версионировать свои Python-утилиты, но об этом тоже помнят не все и не всегда. Это нам помогает быстро проверить версию выделения новых фичей в препроцессинге. А саму модель можно прикапывать не просто с помощью сериализованного файла модели, Python-объекта, а сделать это более хитро. Например, задать model_id или ренжу, когда мы обучали нашу модель. Либо инициализированные пороги, которые будут нужны модели для принятия ее решения. Либо тестовые данные, что были рядом при обучении, и которые мы прогнали через модель, получив качество и сохранив его. Также это может быть качество, которое мы получили, в сравнении с какими-то нижними порогами, и мы не хотим их проваливать. Эти данные переиспользуются в тестах, чтобы сравнить, совпадает ли качество и детерминирована ли наша модель.
Справившись с воспроизводимостью, мы теперь должны нашу модель для заказчика куда-то поставить.
Недолго поразмышляв, мы нашли очевидный ответ — веб-сервис, потому что его удобно масштабировать и им можно гибко управлять. Но проблема в том, что мы, дата-сайентисты, не учились писать веб-сервисы. Python-разработчиков в нашей команде (и даже в департаменте), которые могли бы выделить время для этого, не было. Поэтому компания расширила список вакансий Python-разработчиков. А параллельно мы сели писать код веб-сервиса сами.
Мы встроили нашу модель в небольшой микросервис, который вставили в тот поток, что идет с компьютеров бизнеса нашим аналитикам:

В итоге мы получили небольшой REST API, и хоть мы и дата-сайентисты, все же стали думать, что надо проверять, а жива ли наша модель. Очевидно, добавились ручки /ping и /predict для выполнения целевой задачи. Со временем мы поняли, что было бы здорово иметь еще и возможность получать сведения, какая модель сейчас работает внутри сервиса и на каких данных она была обучена (/info). А также хорошо бы получать с нее какие-то метрики и форсировано обновлять ее в бегущем веб-сервисе (/metrics, /update_model).
Еще немного освоив технологии, мы подняли nginx, Tornado и Docker, а для управления этим зоопарком — Docker-compose:

Казалось бы, все стало хорошо: модель работает, выдерживает rps и не требует много ресурсов. Но помимо этого у нас было еще кое-что — написанный нами код, а код нужно проверять.
Из всех тестов нам очевидно подходили модульные тесты. Но как нам про них помнить? Например, на нашем проекте были ситуации, когда я понимал, что коллега что-то не протестировал в веб-сервисе: код начинал падать и высыпать баги, когда я пытался с ним работать. А я хочу работать над своей задачей, а не над задачей коллеги.
Нам пришло на помощь небольшое правило: достаточно высокое ограничение на покрытие нашего кода тестами, и эмпирически мы выбрали 90%. Есть несколько классных расширений для pytest, которые позволяют оценивать, что нам нужно покрывать кодом и в каком количестве, — например, pycobertura.
Теперь, когда мы вносим новые изменения — будь то фичи, веб-сервисы или что-то еще, связанное с нашей моделью, — это позволяет нам не забыть про тесты. Потому что система всегда напомнит проверить то, что мы добавили. Так мы решили проблему параллельной работы над кодом и изменения версий библиотек. Выше я уже упоминал, что поймать баг на Pandas нам позволили именно модульные тесты.
Раз уж мы говорим о коде, то важно помнить и про Type Hints. Тоже вроде вещь очевидная, но не все ею пользуются и часто пренебрегают. На своих проектах, когда только пришел, я часто сталкивался с такой конструкцией:
Это очень страшно, потому что это может быть np.array, списком словариков или pd.DataFrame, и вообще бог весть чем:

Это проблема, потому что если из контекста следующих 5-6 строчек непонятно, что это такое, то придется ломать голову и разбираться. Поэтому использование Type Hints явно помогает понизить уровень вхождения и понимания вашего кода.
Также важно не забывать про Code Style. Я согласен, что у дата-сайентистов часто встречается плохой код, что они не следуют PEP. Своим коллегам я объясняю, почему стандарт оформления кода — это классно. С его помощью легче поддерживать наш проект, понижается порог вхождения в код для новых людей, да и банально просто приятно читать хороший код — ревью модуля или тетрадок не вызывает отвращения.
Но как можно уменьшить страдания при изучении кода и одновременно вспомнить в нужный момент про Code Style? Думаю, многие знают и пользуются black для форматирования кода и isort для сортировки импортов. Мы добавили к этому darker (+ опционально isort, mypy, etc.), чтобы применять black именно на тех изменениях, которые к нам поступили с последнего коммита, чтобы потом div на код ревью не выглядел монструозно.
Каждый раз, когда мы попытаемся со стейджа закоммитить наши изменения, с помощью pre-commit мы получим ошибку. Нас попросят заново прогнать все то же самое, и darker прожмет утилиту black на измененные строки. Это позволяет не ломать голову над Code Style и автоматизировать эту рутинную задачу.
Следующим вопросом стало: когда прогонять все эти тесты и утилиты?
CI позволил добиться раннего поиска дефектов в нашем коде за счет того, что мы стали часто соединять наши копии в одну общую и прогонять для них автоматизированные тесты. Pull request в нашем случае стал атомарной единицей запуска CI-пайплайна — когда мы пытаемся влить какие-то изменения, будет прогоняться CI-пайплайн. Развернули мы его на Azure.
В нашем проекте мы прошли несколько шагов. Во-первых, создали отдельный тестирующий контейнер, который содержит в себе все необходимые зависимости для запуска py-теста, а также его дополнительные расширения. Тестирующий контейнер запускает все наши дальнейшие тесты, и это позволяет нам не забывать про них.
После этого запустили Pylint для статического анализа кода и Mypy для проверки Type Hints. Напомню, что Code Style мы проверили перед тем, как коммитить. После этого наступила очередь тестов веб-сервиса, модулей и проверки покрытия кода. Если мы удовлетворены coverage, то получаем галочку на CI. Также мы должны были получить галочки при ревью, и — вуаля! — мы можем вливаться. Так мы обеспечили себе уверенность в том, что наш код будет работать.
Теперь пришло время отвлечься от кода (все-таки мы дата-сайентисты) и вернуться к нашей модели, чтобы посчитать ее качество онлайн.
Качество онлайн нужно для переобучения новой модели, чтобы понимать, что с моделью что-то не так и она нуждается в обновлении. Но не когда приходит письмо клиента или мы обнаружим ошибки в логах модели, а намного раньше. Также качество онлайн позволяет нам не делать отчеты в notebook для заказчика. Вместо этого у него есть инструмент, позволяющий ему самому отвечать на все возникающие у него вопросы о модели.
Для этого мы сделали небольшой веб-сервис Flask, чтобы получить мониторинг и алертинг. С его помощью мы можем, например, мониторить качество за разные периоды времени (день, месяц), а также в разрезе разных пользователей или текущей модели. Важно помнить, что мониторинг отвечает не на вопрос, что случилось. Он отвечает на вопрос, когда и где что-то произошло, позволяя локализовать поиск ошибки. Если мы захотим алертить о каком-то аномальном поведении, то настроим получение соответствующего письма и как-то на него отреагируем.
Также с помощью Flask мы можем мониторить количество. Например, у нас резко увеличился поток, пошла аномалия, и мы можем предупредить аналитиков об этом, а заказчик сам может посмотреть на дашборды. Или наоборот — у нас перестал идти поток, и, возможно, проблема на другой стороне.
Также Flask хорошо помогает отслеживать долю фильтрации. Это может быть любая прокси-метрика или показатель, чтобы на аналитиков не шло много ненужных им алертов. И наконец, просто можно видеть состояние сервиса. Это могут быть, например, 500-ки или различные технические показатели.
Настроить все эти метрики даже для дата-сайентиста оказалось не проблемой. Потому что есть проверенный стек Prometheus + Grafana, который позволяет очень просто добиться желаемого результата. С их помощью у нас строятся красивые дашборды, приходят письма на почту, если что-то пошло не так, и мы можем на это среагировать:

Как сделать так, чтобы все это собиралось? С нашего кода (то есть с нашего сервиса) Prometheus должен как-то забирать метрики, а Grafana должна брать их из Prometheus и рисовать. И на самом деле это достаточно просто.
Вот небольшой пример для дата-сайентистов. У Prometheus есть классный client, у которого есть разные абстракции: например, Counter или другие сущности. Если мы хотим считать http-коды, то прописываем названия нашей метрики, описываем ее и говорим, какие лейблы по этой метрике будем собирать. И, допустим, рядом с кодом мы могли бы собирать еще IP, то есть по какому IP сколько и каких http-кодов мы вернули:
Но важно помнить, что Prometheus не резиновый, и когда вы добавляете новый лейбл, то ваше множество расширяется пропорционально декартову произведению. И если значений становится больше 2000, то для Prometheus это уже не очень хорошо.
Так же просто мы можем данные лейблы инкрементировать, и Prometheus это у себя сохранит, а Grafana отрисует на дашборд, который мы показываем заказчику. То есть метрики собирать тоже достаточно просто, и у нас появился новый артефакт — образ сервиса качества:

Но одновременно появилась и проблема: у нас теперь есть несколько сервисов, которые в какой-то момент начинают общаться друг с другом. Оказывается, что взаимодействие и взаимосвязь компонентов тоже нужно проверять. Потому что нам надо знать еще на этапе тестирования, что взаимодействие отвалилось, а не на этапе выкатки в продакшен.
Что вообще можно проверять интеграционными тестами в ML-моделях? Например, это может быть работоспособность сервиса в Docker-образе, когда у нас есть собранный образ с моделью внутри. Мы можем проверить, а выполняет ли он вообще нашу задачу? Поднимем его, простучим какими-то данными и убедимся в том, что все работает.
Или можно проверить интеграцию нашего сервиса по расчету качества с базой данных. Например, он берет разметку из какого-то хранилища, но есть ли по этому индексу то, что мы хотим найти, или нет?
Или, как я уже говорил, можно проверить качество сервиса на отложенной выборке. Мы можем прикопать выборку заранее и посмотреть на наше качество в разрезе с базовыми порогами. Нежелательно, чтобы мы были хуже какого-то значения или по сравнению с последней версией сервиса — поэтому давайте спулим образ, прогоним через него эти же данные и посмотрим, есть ли резон обновлять нашу модель.
Наконец, мы можем проверить ожидаемые показатели сервиса. Например, прокси-показатели: поднимаем сервис и смотрим, выдерживает ли он нужную долю фильтрации потока.
Когда это все прогонять?
Это все прогонять нужно на этапе Continuous Delivery, где у нас также запускается тестирующий контейнер, который запускает pylint и сохранение логов. Это полезно для документации сборки. Можно запустить и pytest с сохранением логов. После чего скачиваем модель из хранилища, где мы ее держим. И проверяем, как она распаковывается, что мы вообще скачали и распаковали. Потому что если вы ее тянете, например, каким-нибудь curl, то вы можете получить ошибку с прокси, а дальше это все поедет в ваши скрипты. Это не очень хорошо.
Дальше мы собираем образ сервиса и прогоняем через него интеграционные тесты: тесты работы сервиса, тесты на общение с БД и тесты качества. После чего загружаем образы в хранилище. Если все хорошо, отправляем это в registry и деплоим на продакшен.
Так мы создали для нашей задачи модель и научились следить за кодом, чтобы эта задача могла быстро релизиться, а мы — находить ошибки на ранних этапах. Также у нас появились компоненты для понимания, что наш тамагочи в продакшене не умер. Было бы еще лучше, если мы настроили автоматическое переобучение модели, но тут к нам пришел бизнес и сообщил, что мы переезжаем в Kubernetes.
Для нас, дата-сайентистов, это был шок, потому что мы никогда не работали с Kubernetes, но теперь должны были написать для него Helm charts. И хотя специалисты DevOps нам дали пример, у них был слишком плотный график, чтобы нам помогать. Но мы и сами хотели разобраться в этом, чтобы не дергать их по каждому чиху, когда понадобится что-то поменять. Поэтому мы инвестировали в это время, и оказалось, что Kubernetes на самом деле достаточно дешев и прост, чтобы его попробовать и внедрить.
Так выглядит текущий пайплайн деплоя нашей модели:

Во-первых, у нас есть цепочка триггеров в Azure-пайплайне. В service запускается CD-сборка нашего основного сервиса (я его описывал выше). На этапе check quality по триггеру запускается сборка нашего небольшого веб-сервиса, который рассчитывает качество. Далее — retrain-model, и если там тоже все успешно и тесты проходят, то происходит сборка образа, который будет переобучать нашу модель в Kubernetes. Это отдельный Docker-образ, который будет запускаться джобой, ходить в хранилище, брать данные, обучать модель и, если все ОК по тестам, подкладывать ее в основной бегущий сервис. Тесты — это качество, работоспособность модели, сравнение с нашей текущей релизовой моделью.
На стадии tests триггерится сборка для образа тестов — тоже похожая джоба, но она проверяет, что наши компоненты в принципе встают на Kubernetes при раскатке, и все интеграционные тесты, доступ в базу и тому подобное работает. На common tag просто прогоняем небольшую сборку, которая всем нашим артефактам с предыдущих шагов навешивает один общий тэг. После этого мы все пушим в registry, и наша сборка (релиз-кандидат) готова.
Далее происходит разворачивание на стейджах Kubernetes, для этого мы и написали Helm charts — и мы раскручиваемся на dev. Если там все поднимается и тесты проходят успешно, то мы переезжаем на test, где начинаются регресс-тесты, и наш тамагочи (кандидат) начинает просто отстаиваться. И если все ОК, то в нужное время наш кандидат катится в prod.
Этот пайплайн выработался в нашей команде, а после использовался и переиспользовался в соседних командах тоже. Волна популярности ML Ops отражает факт, что многие задачи уже решены, появилось большое количество моделей и сервисов. И теперь нужно все модели, которые мы когда-то обучили, начинать поддерживать. И хотя дата-сайентистов не учат, как содержать код и следить за жизнеспособностью компонентов поставки, этому оказалось легко научиться.
Моя статья — как для начинающих Data Scientist'ов, так и для Data Scientist'ов с опытом. Даже опытные коллеги у нас с радостью переняли практики внутри компании, из чего я делаю вывод, что это знание полезное.
Следите за кодом, это не так сложно, как кажется. Хоть дата-сайентистов этому и не учат, но если мы введем пару практик и автоматизируем их, то достаточно быстро к этому привыкнем.
Не бойтесь новых практик и инструментов, они не такие страшные. Когда-то я не понимал, что такое веб-сервисы, но разобрался с этим, и наша модель стала работать. Мы изучили этот вопрос, потом изучили вопросы DevOps-технологии, того же самого Kubernetes. Сейчас нам это кажется достаточно простым и рутинным. И не нужно лишний раз дергать других людей.
Не ленитесь настроить инфраструктуру, это потом сэкономит вам много времени. Если это сделать один раз, то потом по нажатию одной кнопки можно очень быстро выкатывать новые релизы и этот же самый фреймворк переиспользовать на другие проекты. Например, у нас сократилась в разы поставка работающего MVP для новых задач просто за счет того, что мы берем уже наработанный фреймворк. Это все действует как отлаженный конвейер. Все то, что раньше было ручным трудом, сейчас автоматизировано, и бояться этого не стоит.
Приятное дополнение — все маленькие практики, которые я здесь описал, можно посмотреть в репозитории на тестовой игрушечной задаче. Там многие вещи, о которых сегодня рассказываю, я применил, и надеюсь, что как шаблон этот пример будет вам в дальнейшем полезен.
Видео моего выступления на Moscow Python Conf++ 2021:
Но нам с командой дата-сайентистов пришлось это все освоить и запустить. Меня зовут Дмитрий Аникин, в «Лаборатории Касперского» я занимаюсь оптимизацией внутренних бизнес-процессов со стороны Data Science. Хочу рассказать, какие проблемы у нас возникали на пути нашей модели — от простого артефакта до самостоятельного сервиса — и как мы их решили, освоив все несвойственные дата-сайентистам процессы. Как справедливо замечено в нашем самопредставлении, именно в таких моментах — весь драйв!
Всю эту историю расскажу на примере живого проекта MDR (Kaspersky Managed Detection and Response).
Пара слов о самой задаче. У нас есть компьютеры пользователей, в рамках сервиса MDR активность этих пользователей логируется, а данные отправляются по сети экспертам, чтобы они проанализировали логи на опасные инциденты. Проблема в том, что этот поток очень сильно забит алертами, ненужными для аналитиков, — это бесполезная трата их времени. Поэтому мы решили отфильтровать эти срабатывания правил. Как и в любом Data Science-проекте, у нас был заказчик, данные и желание. И с помощью экспериментов мы стали брать эти данные и проверять гипотезы:
Мы делаем это, как правило, в jupyter notebook. И это классная вещь, потому что документация внутри оформлена с помощью удобных markdowns, есть встроенные графики, удобно делиться инсайдами внутри команды и показывать какие-то метрики заказчикам. Правда, с jupyter есть и проблемы (особенно на удаленной работе), связанные с тем, что он немного недопилен в определенных местах. На JupyterCon 2018 был классный доклад «I don’t like notebooks» про плохие привычки, которые вырабатывает jupyter.
Тем не менее на этом этапе у нас есть артефакт, то есть результат нашего кода. Это обученная модель, которая способна решать задачу, и в нашем случае — это задача фильтрации потока. Но вместе с моделью мы обнаружили и проблемы. И первая из них была связана с воспроизводимостью.
Воспроизводимость
Эта проблема важна и актуальна, потому что в первую очередь воспроизводимость нужна для экспериментов. Мне как дата-сайентисту не нравится, когда я на своем проекте получаю какие-то классные результаты, но эксперимент, который я потом пытаюсь воспроизвести, дает совсем другой результат. Хочется, чтобы результат на экспериментах был воспроизводим.
Также воспроизводимость полезна при дебаге. Если ваша модель ошиблась в проде, особенно если это какой-то критический пропуск, то вы или заказчик захотите понять, почему она приняла то или иное решение. С помощью воспроизводимости, применив какие-то методы интерпретации нашей модели, мы сможем понять это.
Еще воспроизводимость помогает переиспользовать результаты тестов в моделях по итогам их переобучения и экспериментов с ними — чтобы рассчитать качество заново и понять, удовлетворяет ли оно нашим ожиданиям.
Но на пути к воспроизводимости есть несколько подводных камней.
Путаница состояний
Те самые jupyter notebooks привносят путаницу состояний. Например, когда у вас падает соединение с тетрадкой, вы не можете узнать, на какой стадии находится ваше обучение и сколько вам осталось учить вашу модель.
Или это происходит, когда я беру тетрадку своего коллеги и хочу воспроизвести его результат, просто запуская его notebook шаг за шагом. Но в какой-то момент он падает, хотя этого быть не должно: он же уже готов, я просто воспроизвожу его модель.
Путаница состояний может случиться по разным причинам: коллега в творческом порыве выполнял ячейки в другом порядке или что-то установил из notebook, а потом стер эту ячейку. Эту проблему мы легко решили вынесением этапа обучения нашей модели и кода, который их обучает, в отдельные скрипты и модули.
Сторонние зависимости
Например, мой коллега, экспериментируя с новыми фичами, апгрейднул Keras, и все прошло нормально. Но когда я беру его скрипт или тетрадку и начинаю фитить модель, то не получаю похожую ошибку, потому что оказывается, что моя версия Tensorflow с данной версией Keras не очень дружит, а коллега ее не добавил:
Что в этой ситуации можно сделать? Разрешить и эту проблему было несложно — решение очевидное, но об этом нужно помнить, потому что про очевидное часто забывают:
- Зафиксировать сразу в requirements-версию, тем более если наша модель должна выкатываться в продакшен.
- Прогнать модульные тесты. Например, мы столкнулись с проблемой, что Pandas в какой-то момент поменял контракт и в своей функции он возвращал не tuple, а скаляр. Мы это отловили с помощью unit-тестов на этапе тестирования, а не на продакшене.
Случайность
Думаю, все знают, что проблема рандома тоже существует. Например, у нас были тесты на модуль train_model.py, и там один из тестов должен был подтвердить, что если два раза обучить catboost-модель на одинаковых данных, то roc auc по предиктам не поменяется. Тесты для keras-модели там не участвовали вообще, и когда мы начали их прогонять, то выяснилось, что просто так они этот тест не проходят.
Это отдельная головная боль, но тоже решаемая: вам нужно зафиксировать seed, причем во множестве мест — в NumPy, просто в Python, в Tensorflow. То есть конфигурируем случайности проекта в отдельном месте.
Так мы прошли несколько камней преткновения на пути к воспроизводимости:
Но есть еще одна важная проблема, о которой я расскажу чуть-чуть подробней.
Версионирование
Версионировать желательно все. Модели версионируют многие, и это вроде бы очевидно — мы хотим уметь их сравнивать между собой. Это очень полезно, когда идет автоматическое переобучение и вы в рантайме подкладываете модель к вашему сервису, который ее использует. Для этого есть множество уже проверенных вариантов, например:
- Artefactory — можно просто на облачном хранилище или где-то еще расположить модели, протаргировав их ID.
- Data Vercinal Control умеет со второй версии и хранить модели, и версионировать их.
- Mlflow, который, помимо основной задачи треканья экспериментов, умеет также хранить модели.
Данные, как и модели, тоже хорошо версионировать, к тому же есть DVC. Но все становится хуже с экспериментами и результатами — про это помнит меньше людей. Например, ваш тимлид хочет получить от вас решения для задачи по повышению качества. Вы проводите ряд экспериментов для проверки гипотез, и вам нужно эти гипотезы сравнивать, чтобы понять, какая лучше. Для этого можно поднять mlflow-сервер, но ваши коллеги могут не захотеть им пользоваться, потому что им нужно вспоминать, куда пушить, и вообще привнести новую практику может быть достаточно тяжело.
Но если предложить полуавтоматизированное решение — небольшой декоратор, который скрывает всю логику, — то коллегам останется только прописать все необходимое для лога эксперимента и отправить это на ML-сервер. И они начинают пользоваться вашим инструментом.
Mlflow, который я предложил в качестве решения
И очевидно, что нужно версионировать свои Python-утилиты, но об этом тоже помнят не все и не всегда. Это нам помогает быстро проверить версию выделения новых фичей в препроцессинге. А саму модель можно прикапывать не просто с помощью сериализованного файла модели, Python-объекта, а сделать это более хитро. Например, задать model_id или ренжу, когда мы обучали нашу модель. Либо инициализированные пороги, которые будут нужны модели для принятия ее решения. Либо тестовые данные, что были рядом при обучении, и которые мы прогнали через модель, получив качество и сохранив его. Также это может быть качество, которое мы получили, в сравнении с какими-то нижними порогами, и мы не хотим их проваливать. Эти данные переиспользуются в тестах, чтобы сравнить, совпадает ли качество и детерминирована ли наша модель.
Справившись с воспроизводимостью, мы теперь должны нашу модель для заказчика куда-то поставить.
Как поставлять модель?
Недолго поразмышляв, мы нашли очевидный ответ — веб-сервис, потому что его удобно масштабировать и им можно гибко управлять. Но проблема в том, что мы, дата-сайентисты, не учились писать веб-сервисы. Python-разработчиков в нашей команде (и даже в департаменте), которые могли бы выделить время для этого, не было. Поэтому компания расширила список вакансий Python-разработчиков. А параллельно мы сели писать код веб-сервиса сами.
Веб-сервис
Мы встроили нашу модель в небольшой микросервис, который вставили в тот поток, что идет с компьютеров бизнеса нашим аналитикам:
В итоге мы получили небольшой REST API, и хоть мы и дата-сайентисты, все же стали думать, что надо проверять, а жива ли наша модель. Очевидно, добавились ручки /ping и /predict для выполнения целевой задачи. Со временем мы поняли, что было бы здорово иметь еще и возможность получать сведения, какая модель сейчас работает внутри сервиса и на каких данных она была обучена (/info). А также хорошо бы получать с нее какие-то метрики и форсировано обновлять ее в бегущем веб-сервисе (/metrics, /update_model).
Еще немного освоив технологии, мы подняли nginx, Tornado и Docker, а для управления этим зоопарком — Docker-compose:
Казалось бы, все стало хорошо: модель работает, выдерживает rps и не требует много ресурсов. Но помимо этого у нас было еще кое-что — написанный нами код, а код нужно проверять.
Модульные тесты
Из всех тестов нам очевидно подходили модульные тесты. Но как нам про них помнить? Например, на нашем проекте были ситуации, когда я понимал, что коллега что-то не протестировал в веб-сервисе: код начинал падать и высыпать баги, когда я пытался с ним работать. А я хочу работать над своей задачей, а не над задачей коллеги.
Нам пришло на помощь небольшое правило: достаточно высокое ограничение на покрытие нашего кода тестами, и эмпирически мы выбрали 90%. Есть несколько классных расширений для pytest, которые позволяют оценивать, что нам нужно покрывать кодом и в каком количестве, — например, pycobertura.
Теперь, когда мы вносим новые изменения — будь то фичи, веб-сервисы или что-то еще, связанное с нашей моделью, — это позволяет нам не забыть про тесты. Потому что система всегда напомнит проверить то, что мы добавили. Так мы решили проблему параллельной работы над кодом и изменения версий библиотек. Выше я уже упоминал, что поймать баг на Pandas нам позволили именно модульные тесты.
Type Hints
Раз уж мы говорим о коде, то важно помнить и про Type Hints. Тоже вроде вещь очевидная, но не все ею пользуются и часто пренебрегают. На своих проектах, когда только пришел, я часто сталкивался с такой конструкцией:
def transform(data):
passЭто очень страшно, потому что это может быть np.array, списком словариков или pd.DataFrame, и вообще бог весть чем:
Это проблема, потому что если из контекста следующих 5-6 строчек непонятно, что это такое, то придется ломать голову и разбираться. Поэтому использование Type Hints явно помогает понизить уровень вхождения и понимания вашего кода.
Code Style
Также важно не забывать про Code Style. Я согласен, что у дата-сайентистов часто встречается плохой код, что они не следуют PEP. Своим коллегам я объясняю, почему стандарт оформления кода — это классно. С его помощью легче поддерживать наш проект, понижается порог вхождения в код для новых людей, да и банально просто приятно читать хороший код — ревью модуля или тетрадок не вызывает отвращения.
Но как можно уменьшить страдания при изучении кода и одновременно вспомнить в нужный момент про Code Style? Думаю, многие знают и пользуются black для форматирования кода и isort для сортировки импортов. Мы добавили к этому darker (+ опционально isort, mypy, etc.), чтобы применять black именно на тех изменениях, которые к нам поступили с последнего коммита, чтобы потом div на код ревью не выглядел монструозно.
Каждый раз, когда мы попытаемся со стейджа закоммитить наши изменения, с помощью pre-commit мы получим ошибку. Нас попросят заново прогнать все то же самое, и darker прожмет утилиту black на измененные строки. Это позволяет не ломать голову над Code Style и автоматизировать эту рутинную задачу.
Следующим вопросом стало: когда прогонять все эти тесты и утилиты?
CI (Continuous Integration)
CI позволил добиться раннего поиска дефектов в нашем коде за счет того, что мы стали часто соединять наши копии в одну общую и прогонять для них автоматизированные тесты. Pull request в нашем случае стал атомарной единицей запуска CI-пайплайна — когда мы пытаемся влить какие-то изменения, будет прогоняться CI-пайплайн. Развернули мы его на Azure.
В нашем проекте мы прошли несколько шагов. Во-первых, создали отдельный тестирующий контейнер, который содержит в себе все необходимые зависимости для запуска py-теста, а также его дополнительные расширения. Тестирующий контейнер запускает все наши дальнейшие тесты, и это позволяет нам не забывать про них.
После этого запустили Pylint для статического анализа кода и Mypy для проверки Type Hints. Напомню, что Code Style мы проверили перед тем, как коммитить. После этого наступила очередь тестов веб-сервиса, модулей и проверки покрытия кода. Если мы удовлетворены coverage, то получаем галочку на CI. Также мы должны были получить галочки при ревью, и — вуаля! — мы можем вливаться. Так мы обеспечили себе уверенность в том, что наш код будет работать.
Теперь пришло время отвлечься от кода (все-таки мы дата-сайентисты) и вернуться к нашей модели, чтобы посчитать ее качество онлайн.
Мониторинг и алертинг
Качество онлайн нужно для переобучения новой модели, чтобы понимать, что с моделью что-то не так и она нуждается в обновлении. Но не когда приходит письмо клиента или мы обнаружим ошибки в логах модели, а намного раньше. Также качество онлайн позволяет нам не делать отчеты в notebook для заказчика. Вместо этого у него есть инструмент, позволяющий ему самому отвечать на все возникающие у него вопросы о модели.
Для этого мы сделали небольшой веб-сервис Flask, чтобы получить мониторинг и алертинг. С его помощью мы можем, например, мониторить качество за разные периоды времени (день, месяц), а также в разрезе разных пользователей или текущей модели. Важно помнить, что мониторинг отвечает не на вопрос, что случилось. Он отвечает на вопрос, когда и где что-то произошло, позволяя локализовать поиск ошибки. Если мы захотим алертить о каком-то аномальном поведении, то настроим получение соответствующего письма и как-то на него отреагируем.
Также с помощью Flask мы можем мониторить количество. Например, у нас резко увеличился поток, пошла аномалия, и мы можем предупредить аналитиков об этом, а заказчик сам может посмотреть на дашборды. Или наоборот — у нас перестал идти поток, и, возможно, проблема на другой стороне.
Также Flask хорошо помогает отслеживать долю фильтрации. Это может быть любая прокси-метрика или показатель, чтобы на аналитиков не шло много ненужных им алертов. И наконец, просто можно видеть состояние сервиса. Это могут быть, например, 500-ки или различные технические показатели.
Настроить все эти метрики даже для дата-сайентиста оказалось не проблемой. Потому что есть проверенный стек Prometheus + Grafana, который позволяет очень просто добиться желаемого результата. С их помощью у нас строятся красивые дашборды, приходят письма на почту, если что-то пошло не так, и мы можем на это среагировать:
Как сделать так, чтобы все это собиралось? С нашего кода (то есть с нашего сервиса) Prometheus должен как-то забирать метрики, а Grafana должна брать их из Prometheus и рисовать. И на самом деле это достаточно просто.
Вот небольшой пример для дата-сайентистов. У Prometheus есть классный client, у которого есть разные абстракции: например, Counter или другие сущности. Если мы хотим считать http-коды, то прописываем названия нашей метрики, описываем ее и говорим, какие лейблы по этой метрике будем собирать. И, допустим, рядом с кодом мы могли бы собирать еще IP, то есть по какому IP сколько и каких http-кодов мы вернули:
from prometheus_client import Counter
http_codes_count = Counter(
'http_codes_count',
'Amount of each http code',
['code'],
)
http_codes_count.labels(str(code)).inc()Но важно помнить, что Prometheus не резиновый, и когда вы добавляете новый лейбл, то ваше множество расширяется пропорционально декартову произведению. И если значений становится больше 2000, то для Prometheus это уже не очень хорошо.
Так же просто мы можем данные лейблы инкрементировать, и Prometheus это у себя сохранит, а Grafana отрисует на дашборд, который мы показываем заказчику. То есть метрики собирать тоже достаточно просто, и у нас появился новый артефакт — образ сервиса качества:
Но одновременно появилась и проблема: у нас теперь есть несколько сервисов, которые в какой-то момент начинают общаться друг с другом. Оказывается, что взаимодействие и взаимосвязь компонентов тоже нужно проверять. Потому что нам надо знать еще на этапе тестирования, что взаимодействие отвалилось, а не на этапе выкатки в продакшен.
Интеграционные тесты
Что вообще можно проверять интеграционными тестами в ML-моделях? Например, это может быть работоспособность сервиса в Docker-образе, когда у нас есть собранный образ с моделью внутри. Мы можем проверить, а выполняет ли он вообще нашу задачу? Поднимем его, простучим какими-то данными и убедимся в том, что все работает.
Или можно проверить интеграцию нашего сервиса по расчету качества с базой данных. Например, он берет разметку из какого-то хранилища, но есть ли по этому индексу то, что мы хотим найти, или нет?
Или, как я уже говорил, можно проверить качество сервиса на отложенной выборке. Мы можем прикопать выборку заранее и посмотреть на наше качество в разрезе с базовыми порогами. Нежелательно, чтобы мы были хуже какого-то значения или по сравнению с последней версией сервиса — поэтому давайте спулим образ, прогоним через него эти же данные и посмотрим, есть ли резон обновлять нашу модель.
Наконец, мы можем проверить ожидаемые показатели сервиса. Например, прокси-показатели: поднимаем сервис и смотрим, выдерживает ли он нужную долю фильтрации потока.
Когда это все прогонять?
CD (Continuous Delivery)
Это все прогонять нужно на этапе Continuous Delivery, где у нас также запускается тестирующий контейнер, который запускает pylint и сохранение логов. Это полезно для документации сборки. Можно запустить и pytest с сохранением логов. После чего скачиваем модель из хранилища, где мы ее держим. И проверяем, как она распаковывается, что мы вообще скачали и распаковали. Потому что если вы ее тянете, например, каким-нибудь curl, то вы можете получить ошибку с прокси, а дальше это все поедет в ваши скрипты. Это не очень хорошо.
Дальше мы собираем образ сервиса и прогоняем через него интеграционные тесты: тесты работы сервиса, тесты на общение с БД и тесты качества. После чего загружаем образы в хранилище. Если все хорошо, отправляем это в registry и деплоим на продакшен.
Так мы создали для нашей задачи модель и научились следить за кодом, чтобы эта задача могла быстро релизиться, а мы — находить ошибки на ранних этапах. Также у нас появились компоненты для понимания, что наш тамагочи в продакшене не умер. Было бы еще лучше, если мы настроили автоматическое переобучение модели, но тут к нам пришел бизнес и сообщил, что мы переезжаем в Kubernetes.
Pipeline
Для нас, дата-сайентистов, это был шок, потому что мы никогда не работали с Kubernetes, но теперь должны были написать для него Helm charts. И хотя специалисты DevOps нам дали пример, у них был слишком плотный график, чтобы нам помогать. Но мы и сами хотели разобраться в этом, чтобы не дергать их по каждому чиху, когда понадобится что-то поменять. Поэтому мы инвестировали в это время, и оказалось, что Kubernetes на самом деле достаточно дешев и прост, чтобы его попробовать и внедрить.
Так выглядит текущий пайплайн деплоя нашей модели:
Во-первых, у нас есть цепочка триггеров в Azure-пайплайне. В service запускается CD-сборка нашего основного сервиса (я его описывал выше). На этапе check quality по триггеру запускается сборка нашего небольшого веб-сервиса, который рассчитывает качество. Далее — retrain-model, и если там тоже все успешно и тесты проходят, то происходит сборка образа, который будет переобучать нашу модель в Kubernetes. Это отдельный Docker-образ, который будет запускаться джобой, ходить в хранилище, брать данные, обучать модель и, если все ОК по тестам, подкладывать ее в основной бегущий сервис. Тесты — это качество, работоспособность модели, сравнение с нашей текущей релизовой моделью.
На стадии tests триггерится сборка для образа тестов — тоже похожая джоба, но она проверяет, что наши компоненты в принципе встают на Kubernetes при раскатке, и все интеграционные тесты, доступ в базу и тому подобное работает. На common tag просто прогоняем небольшую сборку, которая всем нашим артефактам с предыдущих шагов навешивает один общий тэг. После этого мы все пушим в registry, и наша сборка (релиз-кандидат) готова.
Далее происходит разворачивание на стейджах Kubernetes, для этого мы и написали Helm charts — и мы раскручиваемся на dev. Если там все поднимается и тесты проходят успешно, то мы переезжаем на test, где начинаются регресс-тесты, и наш тамагочи (кандидат) начинает просто отстаиваться. И если все ОК, то в нужное время наш кандидат катится в prod.
Этот пайплайн выработался в нашей команде, а после использовался и переиспользовался в соседних командах тоже. Волна популярности ML Ops отражает факт, что многие задачи уже решены, появилось большое количество моделей и сервисов. И теперь нужно все модели, которые мы когда-то обучили, начинать поддерживать. И хотя дата-сайентистов не учат, как содержать код и следить за жизнеспособностью компонентов поставки, этому оказалось легко научиться.
Заключение
Моя статья — как для начинающих Data Scientist'ов, так и для Data Scientist'ов с опытом. Даже опытные коллеги у нас с радостью переняли практики внутри компании, из чего я делаю вывод, что это знание полезное.
Следите за кодом, это не так сложно, как кажется. Хоть дата-сайентистов этому и не учат, но если мы введем пару практик и автоматизируем их, то достаточно быстро к этому привыкнем.
Не бойтесь новых практик и инструментов, они не такие страшные. Когда-то я не понимал, что такое веб-сервисы, но разобрался с этим, и наша модель стала работать. Мы изучили этот вопрос, потом изучили вопросы DevOps-технологии, того же самого Kubernetes. Сейчас нам это кажется достаточно простым и рутинным. И не нужно лишний раз дергать других людей.
Не ленитесь настроить инфраструктуру, это потом сэкономит вам много времени. Если это сделать один раз, то потом по нажатию одной кнопки можно очень быстро выкатывать новые релизы и этот же самый фреймворк переиспользовать на другие проекты. Например, у нас сократилась в разы поставка работающего MVP для новых задач просто за счет того, что мы берем уже наработанный фреймворк. Это все действует как отлаженный конвейер. Все то, что раньше было ручным трудом, сейчас автоматизировано, и бояться этого не стоит.
Приятное дополнение — все маленькие практики, которые я здесь описал, можно посмотреть в репозитории на тестовой игрушечной задаче. Там многие вещи, о которых сегодня рассказываю, я применил, и надеюсь, что как шаблон этот пример будет вам в дальнейшем полезен.
Видео моего выступления на Moscow Python Conf++ 2021:




