
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Не знаю, о чем разговаривают разработчики между собой на конференциях, но у QA-инженеров только и разговоров, что о процессах. Как устроено тестирование, сколько автотестов, кто и когда их пишет, где их запускают, как обеспечивается качество на всех этапах разработки? Моя сегодняшняя статья как раз об этом – о том, как мы строим качество тестирования в hh. Будет немножко теории и множко практики. Поехали!

Кто такие: тестировщик и QA
В первую очередь стоит постулировать следующее: качество в hh – это не зона ответственности одного лишь тестировщика. Качеством у нас занимаются все: тестировщики, разработчики, дизайнеры и продакты. Мы стараемся заниматься этим на каждом из этапов разработки продукта. Начать хочется с древнего холивара по поводу тестирования. Сейчас можно выделить два термина: тестирование и обеспечение качества, которые часто используются для обозначения одного и того же.
Тестирование – это проверка соответствия между реальным и ожиданием поведением программ. Обеспечение качества (Quality Assurance), оно же аббревиатура QA, которую часто используют – это превентивный процесс, направленный на то, чтобы гарантировать, что все необходимые техники, процедуры, стандарты и методологии соблюдаются в процессе разработки продукта и предоставляют результат без дефекта.
Если уж совсем не душнить, то проще будет сказать так: тестирование – это один из этапов обеспечения качества. У нас в hh тестировщики – это quality assurance-инженеры, они влияют на весь процесс разработки, а не только ищут баги. Далее в статье я буду использовать термины “тестировщик” и “QA” как слова-синонимы, чтобы пускаться в излишнее занудство.
Итак, мы пришли к выводу, что QA – это не только про тестирование. Если мы говорим о QA-инженерах, то их задача – не просто протыкать все кнопки в новой фиче и перед релизом протыкать их еще раз, чтобы убедиться, что ничего не отвалилось. QA участвуют во всех этапах разработки продукта. Наша цель – выпустить оптимальный по качеству продукт за разумные сроки. Качество мы стараемся обеспечивать на каждом из этапов разработки. Мы следим за качеством кода, интерфейсов, дизайна и итоговым качеством всего получившегося продукта. QA может улучшать любой из этих процессов.
Этапы разработки фичи
Коротко напомню, как мы пишем код: что было три года назад и к чему мы пришли сейчас. Еще два-три года назад мы работали по так называемому trunk-based development. Нас это не устраивало, и со временем мы перешли на GitHub Flow. О том, как мы улучшали весь этот процесс и как был осуществлен переход, я уже рассказывал в предыдущей статье, поэтому сейчас я не буду на этом останавливаться. Перейдем к тому, как у нас вообще устроен весь процесс разработки фичи.
Весь процесс можно разделить условно на несколько этапов:
Идея;
Дизайн-демо;
Техническая проработка, декомпозиция и оценка задач;
Разработка;
Тестирование;
Финальный релиз – выкладка новой фичи в прод.
А теперь подробнее остановимся на каждом из этапов разработки продуктов.
Идея фичи
На этапе идеи продакты генерируют гипотезу, придумывают новую фичу или функционал, обсуждают эту идею с дизайнером, и вместе они разрабатывают первичный макет. На этом этапе идеи никогда не зафиксированы слишком жестко. Всегда есть возможность что-то изменить, дополнить макеты и тщательнее продумать пользовательские сценарии. Мы не бетонируем все требования на этом этапе, чтобы потом можно было обсудить их с командой, и кто-то предложит, может быть, что-то еще. Или поймем, что в таком виде фича не будет работать.

Дизайн демо
Когда этап идеи закончился, за ним приходит дизайн-демо. На этом этапе участвует непосредственно вся команда – два IOS-разработчика, два Android-разработчика и QA-инженер. Так устроена типичная dreamteam в мобильном направлении, и их у нас пять. Три в соискательском направлении, одно в работодательском и одна – платформенная. Кроме этого, команда в hh – это не просто пакет с программистами, а набор разных зон компетенции, каждая из которых важна. Каждый разработчик не просто круто пишет код, он может также отлично разбираться в дизайн-системе или писать сетевой слой.
На этапе дизайн-демо принимает участие вся команда и, бывает, другие заинтересованные лица. Это продакты из других направлений, еще тестировщики и так далее. Тестировщики обязательно участвуют на этапе показа макета. Потому что они чаще всего в рамках команды лучше других знают этот продукт. Они могут подсветить узкие места, непродуманные сценарии и взаимодействия новой фичи с уже существующими.
Процесс разработки фичи у нас всегда итеративный: если после первого обсуждения фичи что-то не так, дизайнер и продакт просто уходят на доработку. Они могу чуть-чуть переделать макет или немного перепродумать пользовательский сценарий. После этого мы снова собираемся, чтобы обсудить новый макет. Если всех всё устраивает, тогда макет пойдет непосредственно в разработку. Если нет – мы можем переделать и снова это обсудить.
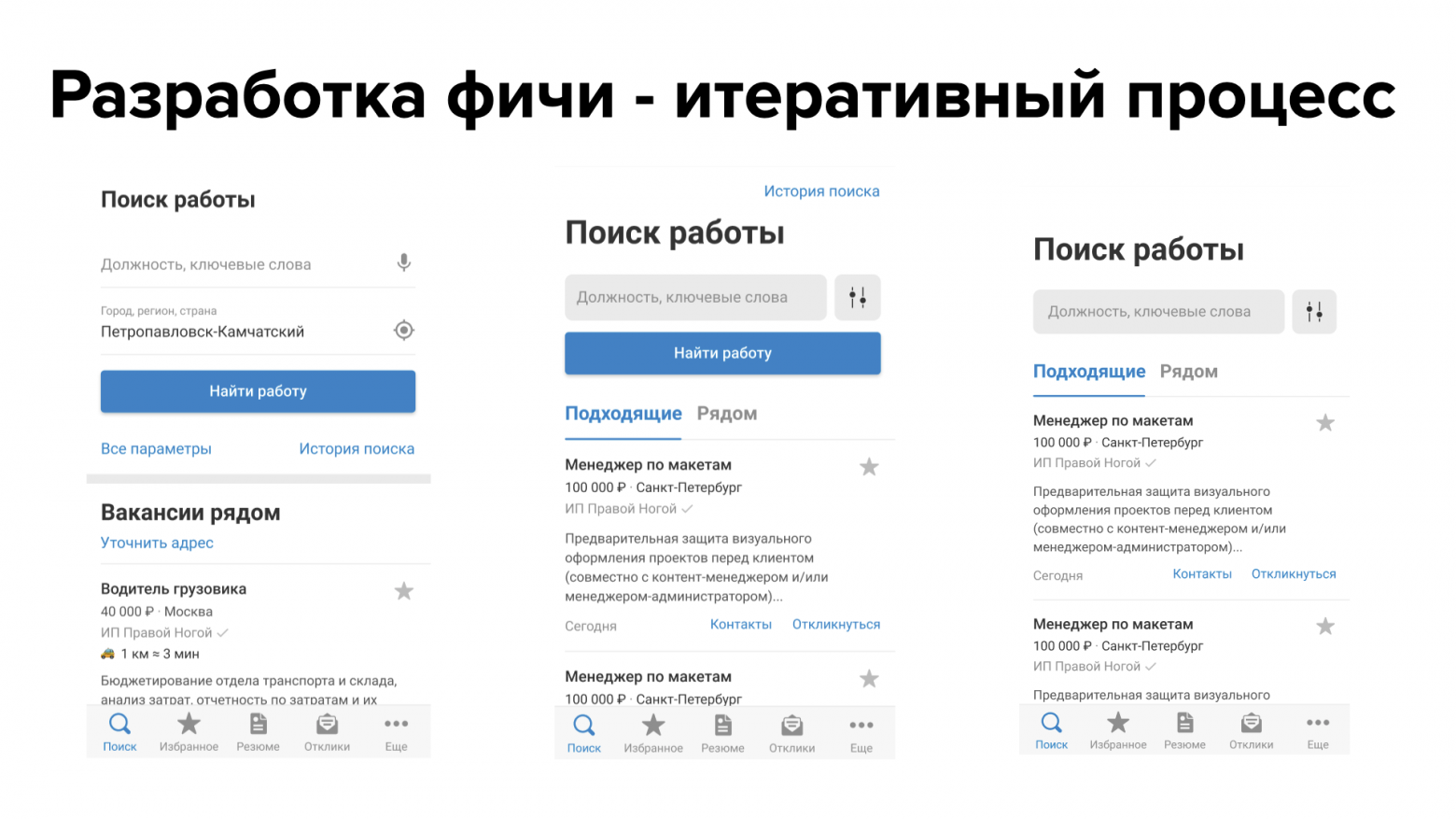
Подключение тестировщиков и вообще всей команды разработки на самых ранних этапах – это очень выгодно для процесса и бизнеса в целом. Тут работает простое правило: чем раньше будет обнаружен дефект или какая-либо проблема, тем дешевле будет ее исправить. Если дефект обнаружен на этапе макетов в Фигме или вообще в рамках идеи, то ничего не стоит это просто перерисовать или перепродумать. Но если же баг обнаружен непосредственно на релизе или даже после разработки, то его исправить куда дороже.
Конечно, в эпоху каскадной разработки исправить баг на проде было намного сложнее. Когда релизы были раз в год, а онлайн-обновлений не было, то если вы уже выпустили баг на прод, исправить его там без проблем было очень сложно. В эпоху итеративной разработки и гибких подходов, когда мы релизимся на сайте несколько раз в день, а релизы мобильных приложений раз в неделю, исправить баг с прода намного проще.
Но проблемы всё равно остаются. Если баг попал в прод и был в платном функционале, который из-за бага не работает, то нам нужно, как минимум, вернуть деньги заплатившим за него пользователям. А в худшем случае мы можем отхватить и неприятные репутационные риски.
Техническая проработка, декомпозиция и оценка
Следующий этап – это техническая проработка фичи, ее декомпозиция и оценка. На этом этапе принимают участие непосредственно разработчики и, при необходимости, техлиды направлений. Участие QA-инженеров на данном этапе обязательно. На этом этапе разработчики могут обсуждать реализацию конкретной фичи: какие могут быть проблемы, что придется изменить в уже работающем функционале, а может и вообще что-то придется отрефакторить.
Тестировщик внимательно слушает, что говорят разработчики, обсуждает и уже может спланировать свое тестирование вокруг потенциальных проблем. Например, если он слышит, что для разработки фичи придется исправить какой-то элемент дизайн-системы, то, скорее всего, также придется исправлять его и в других местах, где он вызывается.
На этом этапе тестировщик уже может примерно оценить, сколько времени ему понадобится на тестирование. Мы никогда жестко не фиксируем эту оценку от тестировщика, но она нужна нам для дальнейшего планирования загрузки команды.
Разработка
Следующий этап – непосредственно разработка. Во многих компаниях в этот момент тестировщики уходят писать какую-то тестовую документацию, тест-кейсы или что-то актуализировать. Мы же в этот момент интенсивно пишем автотесты. Но не для нового функционала, а для того, который уже существует, прошел определенные A/B-эксперименты и так далее. Всегда остается что-то, что не покрыто тестами и остро в них нуждается. Также у нас могут быть нестабильные тесты или тесты, которые нужно обновить. Ими тоже можно заняться.
Но мы не всегда ждем полного цикла окончания разработки конкретной фичи. Тестировщик может взять сборку уже где-то в середине процесса, если там готов частично работающий функционал, и посмотреть, как он реализован. Ведь даже на этом этапе уже могут встретиться проблемы, и чем раньше мы их заметим, тем лучше.
Тестирование
Как не сложно догадаться, на этом этапе происходит проверка разработанной фичи. Основной способ тестирования в hh – исследовательское тестирование. Это такой вид тестирования, который не требует написания тест-кейсов, но подразумевает, что каждый последующий тест выбирается на основании предыдущих.
Это не означает, что тестировщик в рандомном порядке тыкает кнопки и смотрит, что из этого получилось. Увы, нет. Такой способ требует большого опыта от тестировщика и очень хорошего знания продукта. Основные плюсы исследовательского тестирования, которые мы для себя выделяем:
Не требует поддержки и написания тест-кейсов;
Мы не подвержены так называемому парадоксу пестицида;
Повышенная скорость тестирования.
Что такое парадокс пестицида? Эту аналогию ввел Борис Бейзер в 1983 году. Он привел пример обработки полей от вредителей. То есть, если обрабатывать поля определенным пестицидом, то не всегда могут погибнуть все насекомые. Условно, погибнут 80% вредителей, а 20% останутся. И если повторно обработать тем же пестицидом эти 20% насекомых, то, скорее всего, они уже будут невосприимчивы к этому яду.

Так же и с тестированием. Повторное применение одних и тех же тест-кейсов, которые не проходят регулярное review или обновления, просто не будут эффективны для существующих багов. Ведь в рамках того сценария, который описан в тест-кейсе, вы, скорее всего, уже нашли все баги.
Но если сделать небольшой шаг в сторону, может оказаться, что там скрываются и другие баги. Поэтому так важно регулярно обновлять свою тестовую документацию. Но поскольку у нас в hh ее нет, и всё завязано на исследовательском тестировании, то парадокс пестицида в нашей работе встречается достаточно редко.
А благодаря тому, что мы не пишем и регулярно не обновляем тестовую документацию, у нас немного, но всё-таки повышается скорость тестирования.
Для заведения новых багов мы используем Jira. В тикет бага мы заносим все необходимое, для того чтобы баг легко воспроизводился и был максимально локализован. Это могут быть логи, скриншоты, видео, тестовое окружение и т.д. Конечно же там обязательно присутствуют предусловие, шаги воспроизведения, ожидаемый и фактический результат.
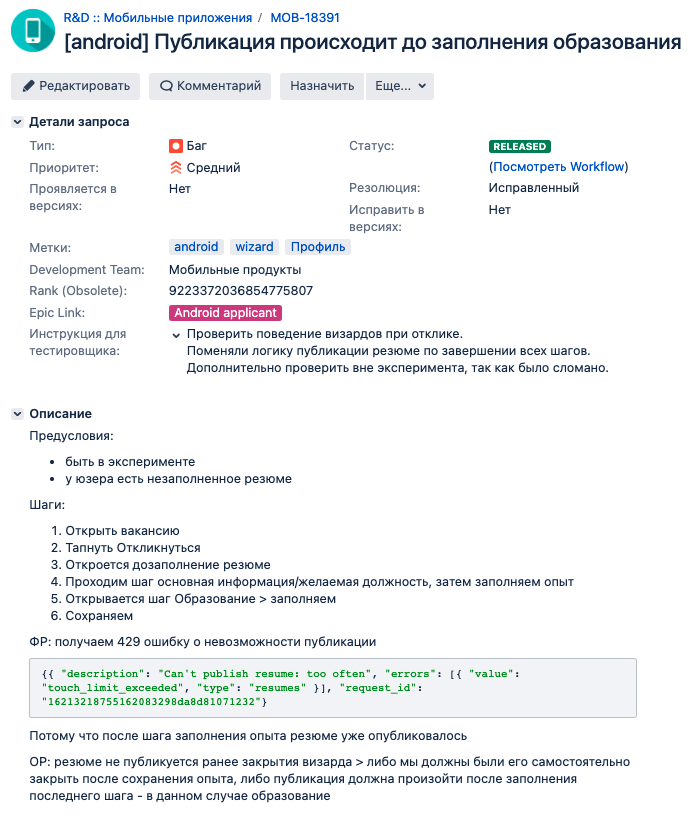
Еще у нас есть специальное поле – инструкция для тестировщика. Туда разработчик пишет какую-то полезную информацию, которая может пригодиться тестировщику при проверке задачи по исправленному багу. Там может быть написано, что в процессе разработки был задет еще какой-то функционал, и его тоже надо посмотреть. Либо там могут быть описаны какие-то специфические кейсы, которые тоже было бы неплохо посмотреть при тестировании. Это помогает не пропускать ничего важного.
Наши инструменты тестирования
Один из наших основных инструментов – это сниффер-трафик. Они могут быть разные. Это может быть Charles, Fiddler, Mitmproxy и так далее. Мы используем Charles, просто потому что нам с ним удобнее. Он не лучше и не хуже других инструментов.
В первую очередь мы используем его для просмотра сетевых запросов от приложения и ответов на них. А также для модификации тех самых запросов и ответов. Иногда вместо того, чтобы делать какой-то необычный запрос из приложения, проще подменить его руками. Кроме того, мы используем разные фичи типа Throttling или проксирования на тестовые стенды. В общем, всё, что может помочь нам в тестировании.
Следующий немаловажный инструмент – это Postman. Он немного похож на предыдущий инструмент, и мы используем его для отправки сетевых запросов к API и получению ответов. Не всегда интерфейс бывает реализован, а какой-то запрос хочется посмотреть уже сейчас – что на него вернет API. Именно для таких ситуаций мы и используем Postman. Кроме того, через Postman мы отправляем пуши на наши тестовые сборки, если необходимо проверить какой-нибудь особенно кастомный.

Еще мы используем тестовые стенды. Это полная копия прода, только с тестовыми данными. На тестовом стенде есть все сервисы, которые сейчас в проде, они всегда актуальны, если регулярно обновлять стенд. Тестировщик может включать или выключать разные сервисы, генерировать любые тестовые данные, а может вообще полностью сломать стенд. Но ничего страшного, в таком случае он просто создаст его заново.
Помимо этого, на стенде есть генерация тестовых данных через фикстуры. По сути, это обертка над API, которая позволяет создавать любые необходимые нам тестовые данные. Это намного проще, чем делать их через интерфейс.
Также стоит упомянуть и про дебаг-панель. Дебаг-панель – это часть приложения, которая доступна только в тестовых сборках. С ее помощью тестировщики могут включать те или иные фичи, генерировать тестовые данные, смотреть логи и еще много всяких полезных штук. Если вы работаете в крупной компании, и у вас еще нет дебаг-панели, то скорее всего, через какое-то время тестировщики всё-таки придут к вам с похожим запросом. Потому что дебаг панель действительно ускоряет тестирование. А если тестировщики не приходят к вам с подобными просьбами, вероятнее всего они и не знают, что так можно. Поэтому стоит донести до них ценность этого инструмента.


Еще полезные инструменты – это adb и Android studio или Xcode для разработки под iOS. Я думаю, эти инструменты не нуждаются в особом представлении, поэтому погнали дальше.
Факт, который многих настораживает – у нас в hh нет подробной документации по продукту. Всё описание фичи – это всего лишь макет и текст продакта об основной идее этой фичи: какой должна быть аналитика и всё в таком духе. Еще у нас нет подробных тест-планов, тест-кейсов и тестовых сценариев. Единственная тестовая документация, которая у нас есть – это чек-лист. В нем перечислены все функции, которые есть у нас в приложении, чтобы при регрессе тестировщик не забыл, что у нас вообще есть, и всё проверил.
Да, это иногда вызывает определенные трудности. У нас может смениться тестировщик, кто-то может что-то забыть. Иногда появляются вопросы – а почему это работает так, а не иначе? Но здесь есть и плюсы. Если такие вопросы возникают, значит в этом месте что-то не так, и это стоит обсудить. Ведь если всё работает хорошо, то вопросы такого рода вряд ли появятся.
Здесь наши полномочия всё
У QA в hh также же полномочия, как и во всех крупных компаниях с развитой инженерной культурой. QA могут заблокировать выпуск релиза, если понимают, что на проде есть какие-то критичные баги, массовые жалобы пользователей или краши. Также тестировщики определяют критичность того или иного бага. Для этого есть множество факторов: критичность функционала, репутационные риски или его массовость.
Кроме того, только QA имеет право мерджить в девелоп новую фичу. Конечно, такое право есть еще у тимлидов, но они стараются его не использовать просто так. Это сделано для того, чтобы мимо тестировщика ничего не прошло. Всё, что вмерджилось в develop, гарантировано протестировано и просмотрено тестировщиком.
Еще QA занимается процессом релиза мобильных приложений в сторы. Может сложиться впечатление, что тестировщики – это какие-то несговорчивые эгоцентристы, которые считают, что только они знают, как правильно. На самом деле, это не так. У нас в компании очень важен диалог. Критичность того или иного бага всегда можно с кем-то обсудить, будь то продакт или разработчик. Возможно, какой-то баг мы можем просто принять, а также принять связанные с ним риски и выпуститься. Но потом обязательно пофиксим.
Ключевое свойство QA у нас в компании – это умение соблюсти баланс между скоростью и качеством. Мы стараемся работать на тонкой грани, когда мы не гарантируем, что в проде у нас нет вообще никаких багов, и всё идеально и ничего не крашится. Но при этом мы стараемся поддерживать хорошую скорость доставки фичи до юзера с оптимальным качеством. Такому подходу мы учим всех новых тестировщиков, которые устраиваются к нам на работу, чтобы тестировщик не был необоснованным узким местом во всей разработки. Однако мы все равно стараемся соблюдать высокие стандарты качества у нас в приложении.
Релиз
Последний этап в разработке – это сам релиз. Как я уже говорил, релизами занимаются у нас тестировщики. Они сами создают релизные ветки, делают сборки и выкладывают их в store. С недавних пор мы всю эту рутину автоматизировали. Как у нас это получилось, я рассказал в одной из предыдущих статей.
Весь регресс у нас сведен к минимуму: у нас очень хорошее покрытие UI-тестами. И, соответственно, перед релизами тестировщики проверяют только тот функционал, который не покрыт тестами, либо который лучше лишний раз проверить. Перед тем, как новое приложение попадает в прод, мы выкладываем его в бета-канал Google Play. В бете обычно есть ограниченное число юзеров, которые предупреждены, что функционал может быть нестабильным и с некоторым количеством проблем.
На небольшом количестве пользователей мы можем убедиться, что с нашим приложением всё в порядке. Не всегда удается найти все краши и баги на этапе тестирования или разработки, и здесь можно обнаружить спрятавшийся краш. Если он есть и достаточно массовый, мы его фиксим и только потом уводим в прод.
Пофиксить такой краш – достаточно нетривиальная задача. И далеко не всегда его легко воспроизвести. Очень часто разработчики просто смотрят на stacktrace, понимают, в чем может быть проблема, фиксят это, а тестировщик уже никак не может проверить всё это руками. Поэтому мы просто заново выкладываемся в бета-канал и смотрим, что будет. Если в бете всё в порядке, то далее пойдет раскатка в прод. В прод мы тоже никогда не катимся сразу на 100%. Сначала мы выкладываем сборку на 20%, потом раскатываем на 50%, 70% и, наконец, доходим до 100%.
Мы никогда не выставляем сразу 100% в раскатке на всех пользователей. В Google Play есть такая особенность: если раскатить приложение на 100%, то сборку, которая сломалась, удалить оттуда уже нельзя. То есть, это APK останется там навсегда, пока ее не заменит свежая версия приложения с пофикшенным багом. Если же раскатить сборку только на 99%, то в случае массовой проблемы такую сборку уже можно удалить из Google Play. Оставшийся единственный процент обычно не страдает. У нас никогда не было жалоб, что юзеры не получили обновление.
Жизнь после релиза
После релиза мы обязательно мониторим, а что у нас вообще происходит в проде с приложением. В первую очередь мы смотрим на краши. У нас есть два важных показателя: crash-free по юзерам и по сессиям.
Для этого мы используем такие инструменты, как Firebase Crashlytics или Appmetrica. Мы стараемся придерживаться цифры 99,9% пользователей без крашей. Просто решили установить для себя такую величину и ей следовать. Она считается за определенный период для определенной версии.
Помимо крашей, мы обязательно мониторим отзывы о новой версии. И обязательно взаимодействуем с нашей техподдержкой. От пользователей могут приходить жалобы на какие-то баги, техпод их разбирает, и если баг повторяется, отдает в команду разработки. Мы его воспроизводим, разбираемся в проблеме и фиксим.
Также весь функционал у нас запускается под A/B-эксперименты. Благодаря этому мы всегда можем просто выключить что-то неработающее. Это, по сути, фиче-тогл. Если какой-то эксперимент, мы его выключаем, разработчики его чинят, и мы выпускаем всё это дело в следующей версии. И только тогда заново включаем эксперимент.
Заключение
Подведем небольшой итог. Качество мы выстраиваем на каждом из этапов разработки фичи, будь то дизайн-демо, проработка, тестирование или релиз. Чем раньше будет найдена проблема, тем легче и дешевле ее пофиксить.
Для того, чтобы нам было проще обеспечивать качество разработки, мы активно используем автотесты. Они у нас полностью нативные на iOS и Android. Для написания iOS-автотестов мы используем XCUITest, для Android – Kaspresso. Для генерации тестовых данных в Android пользуемся самописной DSL. Более подробно про нее можно почитать в нашей статье на Хабре.
Немного цифр про наши автотесты. В Android у нас примерно 400 UI-тестов. В iOS их 500. В основном все UI-тесты у нас пишут тестировщики, но и разработчикам писать их тоже не запрещено. Например, если в ходе разработки нового функционала или доработки старого были сломаны UI-тесты, то их фиксит сам разработчик.
У нас перевернутая пирамида тестирования. Основной упор мы делаем не на Unit-тест, а на UI. Да, UI-тесты более нестабильны, чем Unit, они проходят дольше, но в то же время мы им больше доверяем, так как они более подробно повторяют все пользовательские сценарии.
Помимо UI-тестов у нас есть Unit-тесты. В Android их примерно 1800, а в iOS почти 2000. Основной запуск тестов идет по ночам. Все тесты прогоняются на ветках разрабатываемых фичей, а также на develop. Утром разработчики могут посмотреть, в каком состоянии их разрабатываемый функционал. Основной упор мы делаем на develop. Если на нем за ночь упал какой-то тест, именно туда разработчик первым делом пойдет смотреть, что произошло. Возможно, там появился баг или причина в нестабильном тесте. В любом случае, это обязательно надо починить.
Мы всегда стремимся к тому, чтобы тесты на нашем develop были зелеными. Это очень важно для доверия к тестам. Если они постоянно случайно падают просто потому что нестабильны, то в какой-то момент у разработчиков просто пропадает доверие к таким тестам. Поэтому мы регулярно проводим разбор падений, фиксим наши нестабильные тесты, а также занимаемся развитием тестовой инфраструктуры.
На этом у меня всё. Пишите в комментариях, как устроено тестирование у вас и задавайте любые вопросы.
Всем мирного неба над головой.




