
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Всем привет! Недавно состоялся открытый вебинар «Обеспечение отказоустойчивости хранилищ». На нём рассмотрели, какие проблемы возникают при проектировании архитектур, почему выход из строя серверов — это не оправдание для падения сервера и как сокращать время простоя до минимума. Вебинар провёл Иван Ремень, руководитель направления серверной разработки в «Ситимобил» и преподаватель курса «Архитектор высоких нагрузок».
Зачем задумываться об отказоустойчивости хранилищ?
Задуматься об отказоустойчивости масштабируемых хранилищ и понять базовые проблемы кэширования следует ещё на стадии стартапа. Понятно, что когда вы пишете стартап, вы в самом начале делаете минимальную версию продукта. Но чем сильнее вы будете расти, тем быстрее вы упрётесь в производительность, что может привести к полной остановке бизнеса. А если вы получите деньги от инвесторов, то они, разумеется, тоже будут требовать постоянного роста и новых бизнес-фич. Чтобы найти правильный баланс, нужно выбирать между скоростью и качеством. При этом нельзя жертвовать ни тем, ни другим, а если жертвовать — то осознанно и в определённых пределах. Впрочем, универсальных рецептов здесь нет, как и идеальных решений.
Упираемся в базу на чтение
Это первый сценарий развития событий. Представьте, что у нас 1 сервер, нагрузка на процессор или жёсткий диск которого составляет 99 %. При этом:
- 90 % запросов — это чтение;
- 10 % запросов — это запись.
Лучший выход в данной ситуации — подумать о репликах. Почему? Это самое дешёвое и самое простое решение.
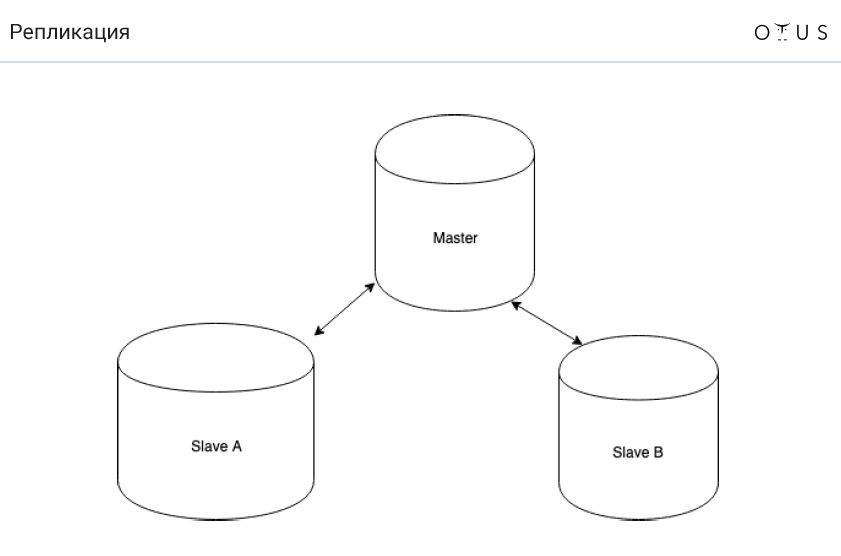
Репликация классифицируется:
1. По синхронности:
- синхронная;
- асинхронная;
- полусинхронная.
2. По переносимым данным:
- логическая (row-based, statement-based, mixed);
- физическая.
3. По числу нод на запись:
- master/slave;
- master/master.
4. По инициатору:
- pull;
- push.
А теперь задача про ведро воды. Представьте, что у нас MySQL и асинхронная master-slave репликация. В ДЦ идёт уборка, в результате которой уборщица спотыкается и выливает ведро воды на сервер с master-базой. Автоматика успешно переключает один самый свежий слейв в master-режим. И всё продолжает работать. Где подвох?
Ответ прост — у нас теряются транзакции, которые мы не успели зареплицировать. Следовательно, нарушается свойство D из ACID.
Теперь поговорим о том, как работает асинхронная репликация (MySQL):
- запись транзакции в движок хранилища (InnoDB);
- запись транзакции в бинарный лог;
- завершение транзакции в движке хранилища;
- возвращение подтверждения клиенту;
- передача части лога в реплику;
- выполнение транзакции на реплике (п. 1-3).
А теперь вопрос, что нужно поменять в вышеперечисленных пунктах, чтобы у нас никогда в конечном итоге не терялись репликации?
А поменять местами нужно всего два пункта: 4-й и 5-й («передача части лога в реплику» и «возвращение подтверждения клиенту»). Таким образом, если у нас вылетит мастер ноды, у нас всегда где-то останется лог транзакций (пункт 2). А если запись транзакции в бинарный лог прошла, значит выполнение транзакции тоже когда-нибудь произойдёт.
В результате мы получаем полусинхронную репликацию (MySQL), которая работает следующим образом:
- запись транзакции в движок хранилища (InnoDB);
- запись транзакции в бинарный лог;
- завершение транзакции в движке хранилища;
- передача части лога в реплику;
- возвращение подтверждения клиенту;
- выполнение транзакции на реплике (п. 1-3).
Sync vs semi-sync и async vs semi-sync
Почему-то в России большинство людей не слышали про полусинхронную репликацию. К слову, она хорошо реализована в PostgreSQL и не очень в MySQL. Подробнее об этом читайте здесь, но тезисно можно сформулировать следующее:
- полусинхронная репликация всё также отстает (но не так сильно), как и асинхронная;
- мы не теряем транзакции;
- достаточно довезти данные только до одного слейва.
Кстати, полусинхронная репликация применяется в Facebook.
Упираемся в базу на запись
Поговорим о диаметрально противоположной проблеме, когда имеем:
- 90 % запросов — запись;
- 10 % запросов — чтение;
- 1 сервер;
- нагрузку — 99 % (процессор или жёсткий диск).
Здесь приходит на помощь всем известный шардинг. Но сейчас давайте поговорим о другом:

Очень часто в таких случаях начинают применять master-master. Однако он не помогает в данной ситуации. Почему? Всё просто: записи на сервер не становится меньше. Ведь репликация подразумевает, что данные есть на всех нодах. Со statement-based репликацией, по сути, SQL будет выполняться на ВСЕХ нодах. C row-based чуть полегче, но всё равно дорого. А ещё master-master имеет проблемы с конфликтами.
На самом деле master-master имеет смысл использовать в следующих ситуациях:
- отказоустойчивость по записи (идея в том, что вы всегда пишете только в один master). Реализовать можно с помощью Virtual IP address;
- геораспределённые системы.
Однако следует помнить, что репликация master-master — это всегда сложно. И нередко master-master приносит больше проблем, чем решает.
Шардинг
Мы уже упоминали шардинг. Если кратко, то шардинг — это верный способ масштабировать запись. Идея в том, что мы распределяем данные по независимым (но не всегда) серверам. Каждый шард может реплицироваться независимо.
Первое правило шардинга — данные, которые используются вместе, должны лежать в одном шарде. Здесь работает формула
sharding_key -> shard_id. Соответственно, sharding_key у данных, которые используются вместе, должны совпадать. Первая сложность заключается в том, что если вы неправильно подберёте sharding_key, вам потом будет очень сложно всё перешардировать. Во-вторых, если у вас есть какой-то sharding_key, некоторые запросы будут выполняться очень тяжело. Например, вы не сможете найти среднее значение. Чтобы это продемонстрировать, давайте представим, что у нас есть два шарда по три значения в каждом: (1; 2; 3) (0; 0; 500). Среднее значение будет равно (1+2+3+500)/6 = 84,33333.
А теперь представьте, что у нас два независимых сервера. И пересчитаем среднее значение отдельно по каждому шарду. На первом из них получим 2, на втором — 166,66667. И даже если мы потом эти значения усредним, мы всё равно получим число, которое будет отличаться от правильного: (2+166,66667)/2 = 86,33334.
То есть среднее средних не равно среднему от всего:
avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))Простая математика, но её важно помнить.
Задача на шардинг
Допустим, у нас есть система диалогов в социальной сети. В диалоге может быть только 2 человека. Все сообщения лежат в одной таблице, в которой есть:
- ID сообщения;
- ID отправителя;
- ID получателя;
- текст сообщения;
- дата отправки сообщения;
- какие-нибудь флаги.
Какой ключ шардирования стоит выбрать, исходя из того, что у нас есть первое правило шардирования, описанное выше?
Вариантов решения этой классической задачи несколько:
- crc32(id_src//id_dst);
- crc32(1//2) != crc32(2//1);
- crc32(from+to)%n;
- crc32(min(from, to). max(from, to))%n.
Кеши
И пару слов про кеши. Можно сказать, что кеши — это антипаттерн, хотя с данным утверждением можно спорить (многие любят применять кешы). Но по большему счёту кеши нужны только для повышения скорости отдачи ответа. И их нельзя ставить, чтобы держать нагрузку.
Вывод прост — мы должны спокойно жить без кешей. Единственное, для чего они могут быть нужны — это точно для того же, зачем они нужны в процессоре: чтобы увеличивать скорость ответа. Если у вас в результате того, что пропадает кеш, база данных не выдерживает нагрузку — это плохо. Это крайне неудачный архитектурный паттерн, поэтому такого быть не должно. И какие-бы не были ресурсы, когда-нибудь ваш кеш обязательно свалится, что бы вы не делали.
Проблемы кешей тезисно:
- старт с холодным кешем;
- проблема инвалидации кеша;
- консистентность кеша.
Если вы всё же пользуетесь кешами, вам поможет консистентное хэширование. Это способ создания распределённых хеш-таблиц, при котором вывод из строя одного или более серверов-хранилищ не приводит к необходимости полного переразмещения всех хранимых ключей и значений. Впрочем, подробнее об этом можете почитать здесь.

Что ж, спасибо за внимание! Чтобы ничего не пропустить из прошедшей лекции, лучше смотрите вебинар полностью.




