После показа впечатляющего демо год назад и недавнего показа в превью UE5, Nanite сейчас весьма популярная тема. Мне просто захотелось окунуться в эту тему и немного развлечься, пытаясь разобраться и объяснить как на мой взгляд всё это работает и какие технические решения стоят за этим, используя кадр захваченный в RenderDoc. Стоит отдать должное Epic за открытость их технологий, что делает проще их изучение и структурирование; в редакторе есть маркеры и отладочная информация которые оказываются очень полезными.
Это кадр, который мы собираемся рассмотреть из демо-проекта Долина Древних. Он показывает взаимодействие между Nanite и не-Nanite геометрией и оно сделано действительно круто.

Nanite::CullRasterize
Первый этап в этом процессе — это Nanite::CullRasterize, и выглядит он следующим образом. Этот вызов отвечает за отсеивание экземпляров объектов и треугольников и их растеризацию. Ниже показано, как это выглядит в захваченном кадре.

Отсеивание экземпляров объектов
Одна из первых вещей, которые здесь происходят, это отсеивание экземпляров объектов. Похоже, что это фильтрация по пирамиде видимости и окклюзии на GPU. Тут используются как данные экземпляра, так и данные примитива и я предполагаю, что вначале происходит отсеивание целых объектов и если экземпляр остаётся, то начинается фильтрация на более детальном уровне. В буфере Nanite.Views хранится информация о камере для фильтрации по пирамиде видимости и иерархический буфер глубины (HZB), используемые для фильтрации окклюзии. Для построения иерархического буфера глубины берутся данные с предыдущего кадра и репроецируются на текущий. Я не уверен в том, как обрабатываются динамические объекты. Возможно, используется достаточно большой MIP-уровень (с низким разрешением), который достаточно консервативен.
Видимые и скрытые объекты записываются в буферы. Последние, как мне кажется, нужны, чтобы выполнять запросы окклюзии: информируем CPU что некоторый объект не видим и перестаём его обрабатывать пока он не станет видимым. Видимые объекты также записываются в список кандидатов на отрисовку.
Персистентное отсеивание
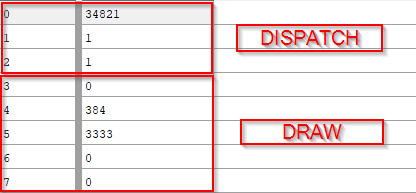
Судя по всему, персистентное отбрасывание связано со стримингом. Это фиксированный набор потоков вычислительного шейдера, которые, предположительно не связаны со сложностью сцены и вместо сцены, вероятно, проверяют окклюзию для некоторой пространственной структуры. Это довольно сложный шейдер, но глядя на его входные и выходные данные можно понять, что он пишет сколько кластеров треугольников каждого типа (для традиционной растеризации и растеризации с помощью вычислительных шейдеров) видны в буфер MainRasterizeArgsSWHW (SW-растеризация в вычислительном шейдере, HW — обычная растеризация).
Кластеризация и уровни детализации
Самое время поговорить об уровнях детализации, потому что именно здесь выбираются уровни для отрисовки. Несмотря на то, что некоторые люди предполагали использование геометрических изображений как способ уровней детализации, переходящих друг в друга, я не вижу здесь ничего подобного. Треугольники сгруппированы в патчи, которые именуются здесь кластерами. Некоторая часть отсеивания геометрии происходит на уровне кластеров. Техника кластеризации уже была ранее описана в статьях от Ubisoft и Frostbite. Для конкретного уровня детализации кластеры появляются и исчезают по мере уменьшения детализации для экземпляра объекта. Тут использованы какие-то сложные магические заклинания для того чтобы кластеры соединялись друг с другом без швов.
Растеризация
В захваченном кадре есть два вида растеризации: на вычислительных шейдерах и традиционная с вызовами отрисовки. Буферы, полученные на предыдущем шаге, содержат аргументы для выполнения непрямой отрисовки.

Первый вызов отрисовки использует традиционную аппаратную растеризацию. Критерий для предпочтения аппаратной или программной растеризации не очень понятен, но можно предположить, что он связан с размером треугольников относительно пикселей. Ранее Epic отмечали, что растеризация в вычислительных шейдерах может превосходить аппаратную растеризацию в некоторых сценариях, в то время как в остальных предпочтительнее аппаратный подход. Эти сценарии связаны с тем как аппаратная растеризация захлёбывается на большом количестве очень мелких треугольников поскольку не может эффективно распланировать их обработку. Страдает как загрузка видеокарты, так и производительность. Я могу найти несколько экземпляров из больших треугольников, но это сложно выбрать предпочтительный вид растеризации просто смотря на них.

Информация выше показывает нам размер кластеров (384 вершины, т.е. 128 треугольников). Он подозрительно хорошо делится на 32 и 64 которые обычно выбираются для эффективного заполнения варпа на GPU. Итак, 3333 кластера рисуются аппаратно в то время как программная растеризация позаботится об остальной геометрии Nanite. Каждая группа состоит из 128 тредов, поэтому я предполагаю, что каждый тред обрабатывает 1 треугольник (каждый кластер это 128 треугольников). Колоссальные 5 миллионов треугольников! Эти цифры говорят, что более 90% геометрии растеризуется программно, что подтверждает сказанное Брайеном Карисом здесь. Для теней выполняется тот же процесс, только рисуется всё в буфер глубины.
Описанный выше процесс повторяется для некоторой части геометрии в Post Pass. По-видимому, причиной для этого служит то, что Nanite создает более актуальный иерархический буфер глубины (в BuildPreviousOccluderHZB) с информацией о глубине для текущего фрейма, полученной на данном этапе, комбинирует её с информацией из ZPrepass (проход, который выполняется до начала Nanite) и использует все эти данные для более корректного отсеивания. Мне интересно, как происходит отсеивание для геометрии, которая была на краях буфера глубины с предыдущего кадра или была не видна на предыдущем кадре, чтобы не было артефактов с резким появлением объектов. В любом случае результатом стадии растеризации является одна текстура, о которой мы поговорим далее.
Буфер видимости
Одна из главных особенностей Nanite это буфер видимости. Это текстура формата R32G32_UINT, которая содержит информацию о треугольнике и глубине для каждого пикселя. На этом этапе ещё нет информации о материалах и данные из первого канала содержат информацию необходимую для получения свойств материала в дальнейшем. Буфер видимости — это не новая идея. Она уже была описана ранее (например, здесь и здесь), но насколько я знаю, не было коммерческих игр с ней. Если отложенное освещение отделяет освещение от геометрии, то эта идея разделяет геометрию и материалы: каждый пиксель/материал треугольника вычисляется только один раз и доступ к текстурам, буферам и ресурсам не осуществляется, если в дальнейшем эти данные не понадобятся. Буфер видимости организован следующим образом:
R [31:7] | R [6:0] | G |
ClusterID (25 bits) | Triangle ID (7 bits) | 32-bit Depth |



Тут возникает верхняя граница в примерно 4 миллиарда (232) треугольников, что было вполне достаточно ранее, но теперь я в этом уже не уверен. Вещь, которую я нахожу интересной, как эта информация ограничена. Другие подходы к буферу видимости предлагают хранить барицентрические координаты. Всё остальное будет получено позже при пересечении треугольника с лучом из камеры, чтении данных из исходного буфера и вычислении вертексных атрибутов на лету. Это детально описано здесь. И последнее замечание, можно заметить щель там где должен стоять персонаж, что позволяет оценить эффективность системы отсеивания.
Nanite::EmitDepthTargets
В конце этой фазы мы получим три типа информации: глубину, векторы движения и «глубина материала». Первые два — стандартные значения, которые будут позднее использованы, например для TAA, отражений и т.д. Также тут есть интересная текстура, которая называется Nanite Mask, которая просто показывает, где была отрисована геометрия Nanite. И выглядит она вот так:



Глубина материала
Однако, наиболее интересные данные в выходной текстуре на этом этапе — это глубина материала. В сущности это ID материала преобразованный в значение глубины и сохраненный в буфер глубины. Таким образом, на каждый материал приходится свой оттенок серого. Это будет использовано в дальнейшем как оптимизация, которая использует ранний тест глубины.

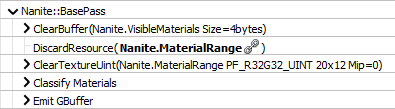
Nanite::BasePass
К счастью, сейчас мы имеем хорошее понимание геометрического конвейера. До сих пор мы вообще ничего не говорили о материалах. Это весьма интересно поскольку между генерацией буфера видимости и текущим моментом, много времени тратится на другие вещи: сетка освещения, атмосфера и т.д. и ещё рисуется G-buffer как это обычно бывает. Это действительно разделение геометрии и материалов, то на что и нацелен буфер видимости. Важные шаги происходят внутри Classify Materials и Emit G-buffer.
Classify materials
В проходе классификации материалов запускается вычислительный шейдер, который анализирует полноэкранный буфер видимости. Это очень важно для следующего прохода. Результат этого прохода — это текстура размером 20x12 (=240) пикселей в формате R32G32_UINT, которая называется Material Range. В ней закодирован промежуток материалов представленных в регионе размером 64x64. Это выглядит вот так:

Emit G-buffer
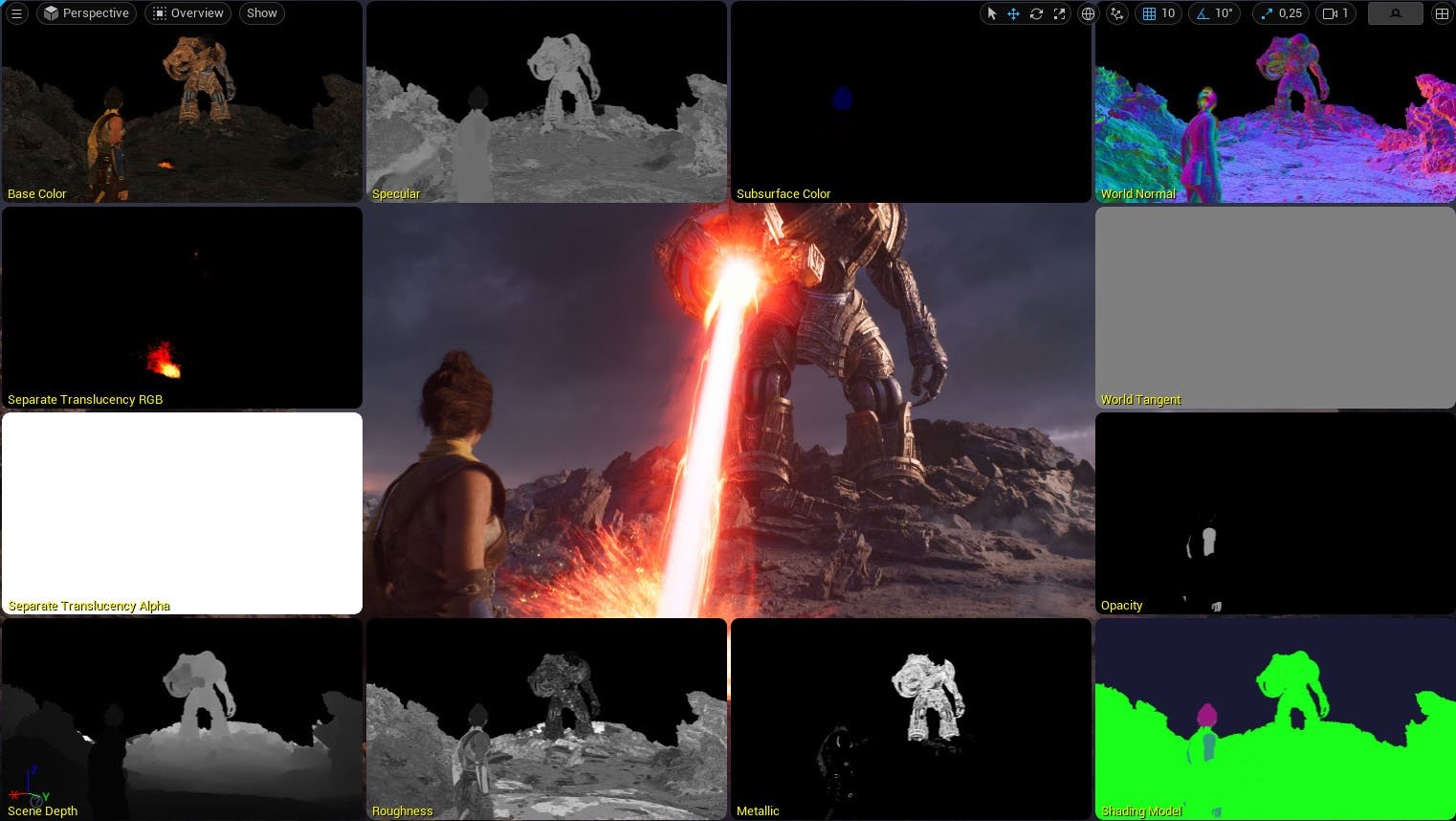
Мы наконец достигли точки, где встречаются видимость и материалы. Здесь информация треугольников из буфера видимости превращается в свойства поверхности. Unreal позволяет пользователям задавать произвольные материалы поверхностям. Так как же эффективно работать с этой сложностью? Вот как выглядит Emit G-buffer.
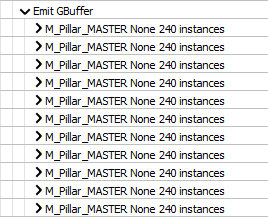
Мы видим что-то похожее на вызовы отрисовки на каждый ID материала и каждый вызов отрисовки делит экран на 240 квадратов, которые отрисовываются на экране. Полноэкранный проход отрисовки на каждый материал? Они обезумели? Не совсем. Мы отмечали ранее, что текстура с промежутками материалов состоит из 240 текселей, поэтому каждый квад такого полноэкранного прохода соответствует одному текселю. Вершины квада семплируют эту текстуру и проверяет релевантен ли квад для текущего прохода. Если нет, то координата x для вершины выставляется в NaN и весь квад отбраковывается. Это известная операция.
Насколько я могу судить, система использует 14 бит для ID материала. Максимум 16384 материалов. Через константный буфер в вершинный шейдер передаётся ID материала и можно проверить попадает ли он в промежуток материалов.
Вдобавок, вспомним, что мы сделали текстуру с глубиной материалов, где каждый ID материала выставляется в качестве глубины. Квады в качестве глубины хранят номер материала, и выполняется тест глубины установленный на равенство. Таким образом железо может очень быстро отбросить все нерелевантные пиксели. В качестве дополнительного шага движок имеет ранее размеченный трафаретный буфер, в котором отмечены пиксели, содержащие геометрию Nanite. Это позволяет использовать ранний тест трафарета в качестве оптимизации. Чтобы понять, что всё это значит, посмотрите на буфер альбедо.







Вы могли заметить, что некоторые квады полностью красные. Я предполагал, что они будут полностью отброшены в вершинном шейдере. Однако, я думаю, что текстура с промежутком материалов не зря называется именно так и это именно промежуток материалов, которые есть в тайле. Если материал внутри этого промежутка, но ни один пиксель ему не соответствует, он будет принят как кандидат несмотря на то, что будет полностью отброшен далее в тесте глубины. В любом случае, это главная идея. Один и тот же процесс, показанный на изображениях повторяется для всех материалов. Финальный G-buffer выглядит как тайлы ниже.
Заключительные замечания

На этом Nanite заканчивается и последующий конвейер отрисовки переходит к обычному отложенному освещению. Проделанная работа действительно замечательна. Я уверен, что есть ещё множество деталей, о которых я не знаю и неточности в том, как это работает. Поэтому я с нетерпением жду, что Брайен Кэрис расскажет на SIGGRAPH в этом году.

")


