
Хотелось бы поделиться с вами практическим опытом тестирования и использования системы хранения данных HPE Nimble, в нашем случае впечатлениями будем делиться относительно модели All-Flash – HPE Nimble AF40. Насколько эта статья будет актуальна и интересна – решать только вам, но мы в свое время столкнулись с проблемой поиска реальных историй (не путайте с историями успеха), в которых по большей степени автор делился бы своими мыслями, опытом и впечатлениями, т.е. чистыми эмоциями от сердца, а не сухими фактами или вездесущим маркетингом. Поэтому решили потратить немного своего времени и попробовать написать что-то подобное, поэтому не судите строго, т.к. это первая проба пера. Итак, поехали.
Чтобы немного ввести вас в курс дела для начала дадим скупую информацию о нашем подопытном. Данную модель HPE позиционирует среди своего же семейства All-Flash массивов Nimble, как оптимальный выбор по соотношению цена/производительность. С точки зрения производительности система достаточно сильно отличается от младшей модели AF20 (превышает почти в 5 раз!), но при этом не столь сильно уступает более старшим моделям – AF60 и AF80. Самой старшей модели наш экземпляр уступает по паспорту в среднем в 3 раза, по некоторым показателям и то меньше, а модели Nimble AF60 – не более, чем в 2 раза. Массивы всей линейки HPE Nimble имеют весь необходимый функционал, согласно своему статусу – массивам среднего ценового сегмента. Тут тебе и компрессия с дедупликацией, причем последняя с переменным блоком, и аппаратные снимки с согласованием на уровне приложения, и синхронная репликация, с возможностью реализации концепции Metro Storage Cluster, и поддержка технологии VVOL, QoS, возможность собирать Storage Pool из нескольких массивов – некое подобие федерации, и еще парочка козырей в рукаве в виде искусственного интеллекта и продвинутой аналитики.
Ну а теперь о цифрах
По паспорту система позволяет получить до 130К IOPS на блоках 4К в смешанной нагрузке 50/50 на случайных операциях ввода-вывода, 150K IOPS на все тех же блоках 4К при 100% случайном чтении и 150К IOPS при 100% случайной записи – все это без учета дедупликации. С ее же учетом итоговые показатели будут зависеть от ее общего коэффициента. К примеру, при общем коэффициенте дедупликации 10:1 немного просядут операции случайной записи – до 130К на блоках 4К. При этом количество IOPS на операциях чтения возрастет до 170К, а в смешенном режиме 50/50 заявлено 96К IOPS. По нынешним меркам – более чем скромно для All-Flash массива. Тем более, что массив является представителем Mid-Range сегмента, и от них ожидаешь действительно приличных цифр, так как сегмент представляет из себя подобие гоночного трека, где каждая доля секунды на счету и производители выставляют лучшее, лишь бы поразить искушенную публику и завоевать их сердца (а заодно и кошельки). Поражать тут с точки зрения цифр нечем, тем более что сейчас даже массивы Entry-Level (начального уровня) могут похвастаться и показателями 300+К IOPS, чему, к слову, могли бы и позавидовать приличное количество Hi-End систем хранения данных 8-10 летней давности. Да, прогресс не стоит на месте – все так и есть. Другой вопрос, что критерии выбора у всех разные и не всем нужен самый быстрый автомобиль. Я так точно больше являюсь адептом комфорта. Да, динамика, несомненно, вещь важная и необходимая (в определенной степени) для формирования того самого комфорта: когда машина едет и позволяет без напряга, когда надо прибавить, совершить динамичный маневр и вообще приятно, когда под капотом мощный движок, который, возможно, никогда не будет использоваться в полную силу, но кого это волнует... Сразу вспоминаются спорт-кары, которые весело и задорно урчат в городе от светофора до светофора, знатно взбалтывая тушки своих удалых владельцев – очень динамичный разгон и не менее динамичное торможение. На вкус и цвет фломастеры разные: кому-то нравится, кому-то нет. Я так всеми руками за практичность, т.е. можно есть суп вилкой, но зачем, когда есть ложка. Или зачем есть борщ черпаком из 10 литровой кастрюли, если есть тарелка и все та же ложка. Ну в общем, я думаю, вы меня поняли.
Вернемся к нашему подопытному. С цифрами определились, в голове зафиксировали. Тем самым, для нас не было по этому поводу никакого откровения. У вас теперь, надеюсь, тоже. Когда определились с ожидаемой производительностью массива, остался только один вопрос: насколько эти цифры будут честными, т.к. производители часто иногда завышают эти показатели и регулярно порой бывает невозможно тяжело добиться тех же показателей при тестировании аппарата (ставьте лайк, если тоже становились жертвой маркетинга и обладателем годового запаса лапши).
К слову, в нашей практике компания HPE не была замечена в каких-либо махинациях с цифрами, в неполноте или недостоверности ТТХ по продуктам. Чего не скажешь о документации по работе с оборудованием, уж простите – наболело. Поэтому мы, конечно же, отнеслись к заявленным цифрам с доверием… и сразу же решили их проверить (доверяй, но проверяй – к этой простой жизненной мудрости мы пришли, проводя теплые летние деньки за очередной мисочкой лапши).
Плавно переходя к тестированию, естественно, нельзя не упомянуть состав нашего тестового стенда: здесь, как говорится, best practice не заглядывал. Если серьезно, то оборудование уже весьма подуставшее, процессоры на подключенных хостах не каноничные (те самые красные), гипервизоры – End of General Support. Что действительно радует, так это наличие SAN-сети на коммутаторах SN6000 (8-гигабитный Qloqic SANbox 5800 — привет из 2010-го года). В общем, не 4 Гбит, — и уже хорошо. Но те самые 16 Гбит FC на HPE Nimble AF40 раскрыть, к сожалению, не удастся. Да и конфигурация самого массива, тоже, скажем так, не best practice, т.к. официально рекомендуется использовать минимум 4 порта ввод-вывода на каждом контроллере, а в нашем случае мы имеем только 2 порта 16 Гбит FC в режиме 8 Гбит.

Из трех серверов DL385 Gen7 собран кластер виртуализации на VMware ESXi 6.0.0. Управление через VMware vCenter в формате appliance на Linux. На каждом хосте по два процессора AMD Opteron 6180 SE и 192 ГБ оперативной памяти DDR3 PC3-10600 ECC RDIMM (1300 МГц). Для подключения к SAN-сети используется две однопортовые FC HBA 8 Гбит (HPE 81Q) на каждом из хостов. Сам же HPE Nimble AF40 укомплектован 24 твердотельными накопителями объемом 480 ГБ, двумя контроллерами и по одной двухпортовой 16 Гбит FC HBA в каждом из них.
Относительно выбора программного обеспечения для нагрузочного тестирования изначально выбрали классику жанра — vdbench, но потом все-таки остановились на HCIbench в виду большей простоты и наглядности, а также ориентированности на виртуальную среду VMware.
Пока это все было хождение вокруг да около и относительно самой системы хранения HPE Nimble AF40 не было сказано ничего, кроме заявленных ТТХ. Поэтому пора, так сказать, исправлять ситуацию, тем более что после затянувшегося аперитива, мы как раз подошли к этому весьма вкусному моменту. Делиться своими впечатлениями и результатами будем последовательно: начиная с настройки самой системы и далее переходя к тестам и кое-чему весьма интересному. Но обо всем по порядку.
Впечатление №1: распаковка, монтаж и первичная настройка
С вашего позволения тут я не стану сильно задерживаться, хотя есть любители посмаковать сей момент в полном объеме. Что тут сказать, упаковка внушает доверие, все очень добротно: плотная картонная коробка, притянутая болтами к деревянному паллету, внутри массив защищен плотным полиэтиленовым пакетом и черной разновидностью пенопласта (упругий и не крошится). Все на своих местах – коробочки и пакетики с аксессуарами. В общем на упаковке точно не сэкономили. Сам массив представляет собой полку на 4U, очень увесист и габаритен, глубина полки этого «мастодонта» — целых 89 см, а вес — более 50 кг. Хотя, чему удивляться — сама коробка огромна по меркам среднестатистического массива и как бы намекает на сидящего в ней «монстра». Шутки шутками, а вес имеет значение, особенно при монтаже. Так и здесь — металла много, пластика минимум, очень монолитно и добротно. Можно при желании хоть раз 10 монтировать и демонтировать — ничего не погнется, не сломается, не треснет и не отлетит. На самом деле, это давно стало проблемой для современного оборудования, которое изобилует пластиком; детальки так и норовят треснуть или сломаться даже после монтажа.
Первоначальная настройка массива до безобразия проста и интуитивно понятна. А дополнительную веру в собственные силы поможет обрести Welcome Center для Nimble. Производитель предлагает в помощь онлайн-портал с пошаговыми текстовыми и видео-инструкциями, что будет не только полезно и удобно, но и наглядно. Одним только Nimble там дело не ограничилось, доступны материалы и по другой системе хранения — HPE Primera.

Для начала нужно выбрать интересующую модель, после чего выводится список дальнейших рекомендаций, в том числе — прединсталляционный чек-лист, указывающий на основные подготовительные моменты, на которые стоит обратить пристальное внимание, чтобы в конечном итоге к полуночи карета не превратилась в тыкву.
Ну и, конечно же, захватывающие видео сопровождения, а в качестве бонуса еще и ссылка на Installation Guide:
Суммарно подготовка массива к работе занимает 15-30 минут. За качество исполнения, упаковку, внешний вид и простоту первоначальной настройки — «5» из «5». Вес и габариты, конечно, дают о себе знать, но можно и потерпеть.
Впечатление №2: подключение HPE Nimble AF40 к кластеру VMware
И здесь наc ждал первый приятный сюрприз и важное преимущество HPE Nimble — простая и понятная интеграция с VMware с использованием технологией VVOL. Это особенно эффектно в связи с тем, что мы до этого не использовали технологию VVOL, но идеологически пытались ее воссоздать вручную использованием выделенных VMware VMFS Datastores под каждый виртуальный диск каждой виртуальной машины. Такой ручной подход был призван упростить использование аппаратных снимков, обезопасить от возможных проблем с очередями на уровне LUN (когда есть один жирный VMware VMFS Datastore и все виртуальные машины живут на нем, как в большой коммунальной квартире с общей кухней, на которой периодически могут устраивать поножовщину).
При наличии в системе хранения данных механизмов QoS это еще и позволяло настраивать для каждого отдельного взятого диска виртуальной машины свои ограничения по производительности или наоборот гарантировать заданный минимум. Аппаратные снимки делались только на тех виртуальных томах системы хранения, которые принадлежали данной виртуальной машине, а не целиком всему общему VMware VMFS Datastore. Та же ситуация и с их восстановлением. Плюс, исключалась проблема с нехваткой места на общем VMware VMFS Datastore и остановкой всех виртуальных машин из-за ошибки записи, если вдруг администратор проглядел. То есть, по большей части, все — в угоду управляемости, контролю и исключению взаимовлияния.
Но, несмотря на такое весомое количество плюсов, минусов было также предостаточно, особенно в части трудозатрат. Речь идет про ручное создание всех необходимых виртуальных томов на уровне массива, презентация их кластеру, создание каждого из дисков виртуальной машины на своем выделенном VMware VMFS Datastore, и так далее. Стоит отметить, что такой вариант явно подошел бы не всем, так как существуют ограничения по их количеству — для ESXi 6.0.0 это значение равно 256. Но в нашем случае в лимит мы укладывались, а с неудобствами и трудозатратами мирились в угоду управляемости.
Технология VVOL вообще позволила уйти еще дальше. Помимо указанных плюсов и отсутствия явных минусов, она позволила перенести и полностью автоматизировать операции по созданию виртуальных томов на системе хранения данных для виртуальных машин на VMware vCenter. То есть, настроив интеграцию единожды, теперь вообще нет какой-либо необходимости заходить в интерфейс управления HPE Nimble AF40 или создавать новые презентации для новых томов. Даже не обязательно готовить тома заранее на системе хранения в случае использования специфических настроек (толстый или тонкий тип диска, включена ли компрессия и дедупликация, размер блока дедупликации). Теперь это все делается с помощью vCenter и VM Storage Policies.
Для этого удовольствия всего лишь необходимо выполнить пять основных шагов (не считая стандартных требований по подключению системы хранения к серверам через SAN фабрики, например, зонирование).
Шаг 1. Выполнить интеграцию с vCenter
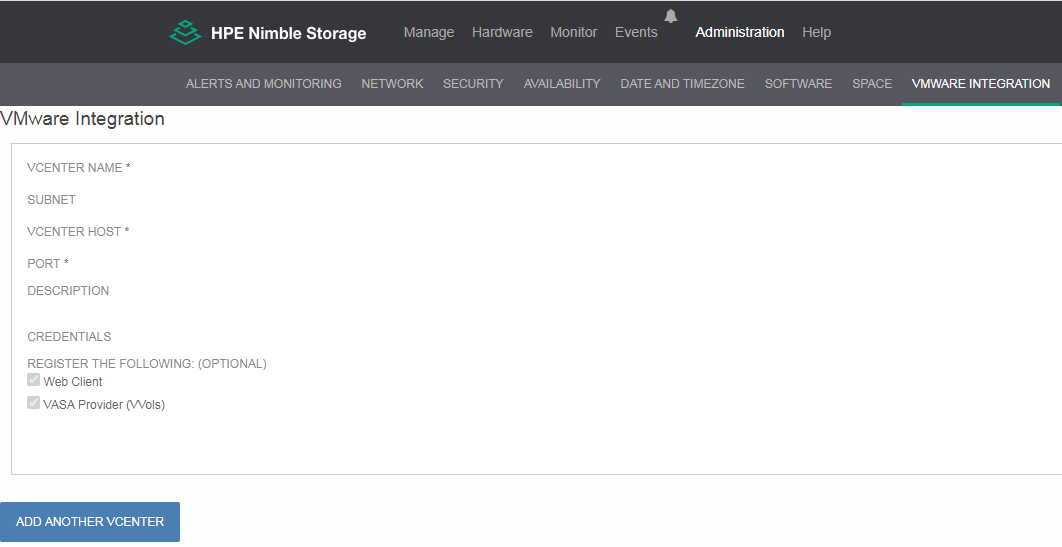
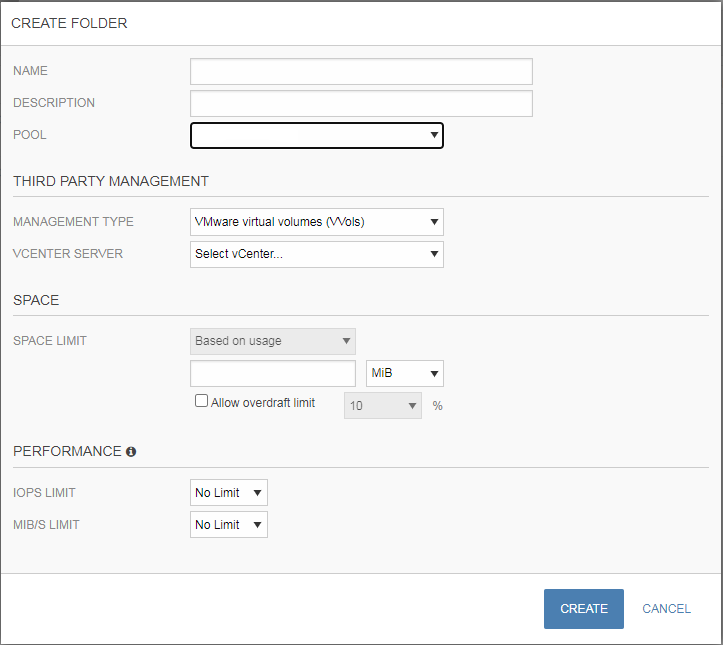
Шаг 2. Создать на HPE Nimble структурный каталог – Folder с указанием типа управления VVOLs:
Шаг 3. Ознакомиться с Performance Policies на HPE Nimble для создания VM Storage Policies (можно так же создавать свои Performance Policies на HPE Nimble с указанием преднастроек — это, по сути, профиль создания виртуального тома):
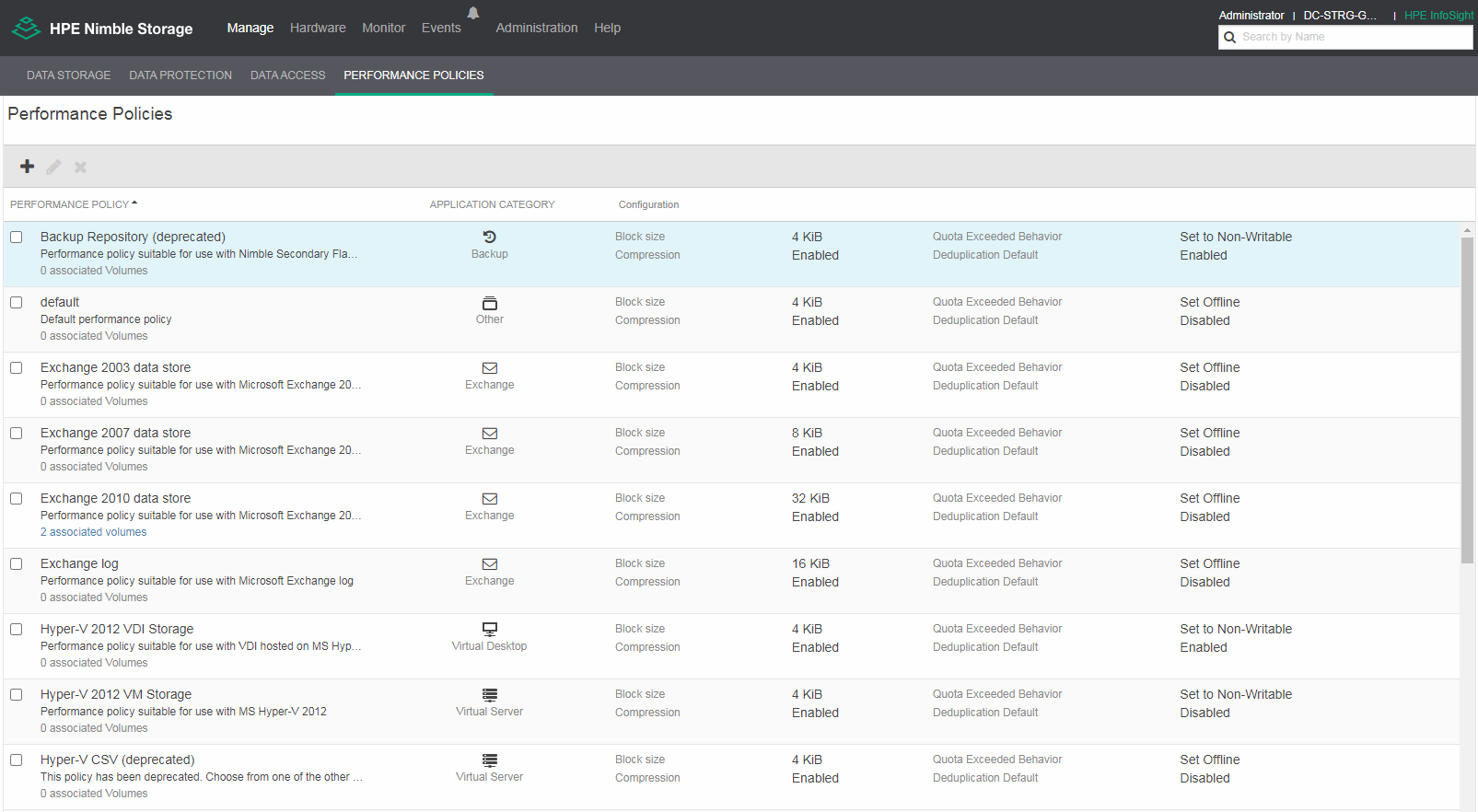
Шаг 4. Создать необходимый набор VM Storage Policies в vCenter на основе Performance Policies:
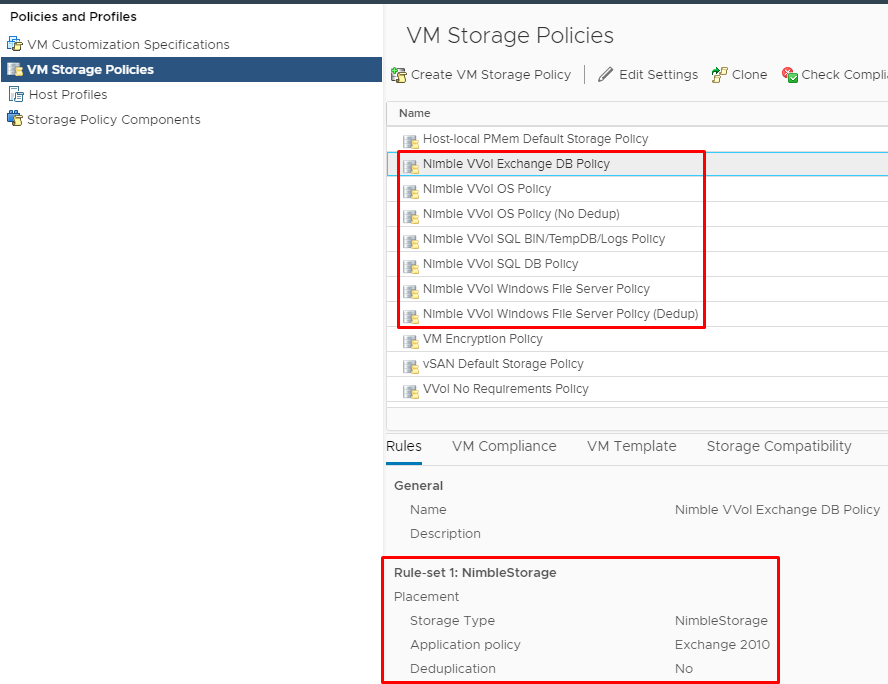
Шаг 5. Подключить Folder к кластеру в vCenter:
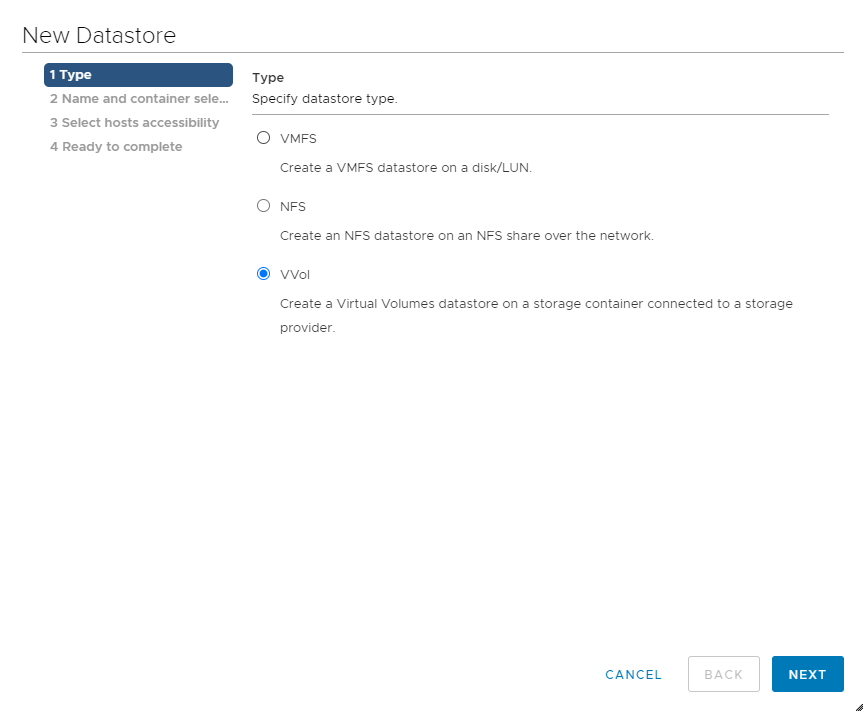
Для искушенных также есть возможность посмотреть разного рода информацию по VVOL через плагин HPE Nimble в vCenter, а также настроить график создания консистентных снапшотов на уровне VM Storage Policies:
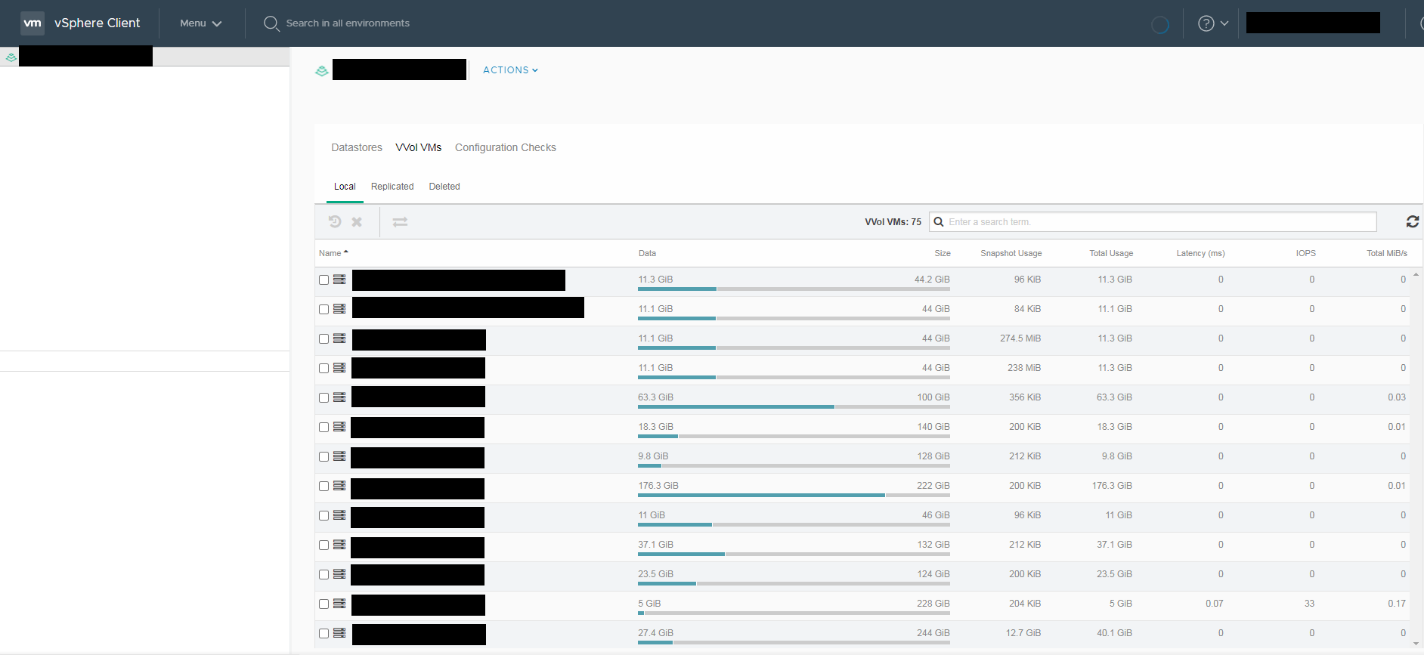

Впечатление №3: нагрузочное тестирование синтетическими тестами
А теперь самое время проверить заявленные ТТХ массива. Самый простой паттерн нагрузки — 100-процентное случайное чтение блоками 4К (без использования дедупликации). Используем встроенный в HCIbench нагрузочный инструмент со следующими настройками:
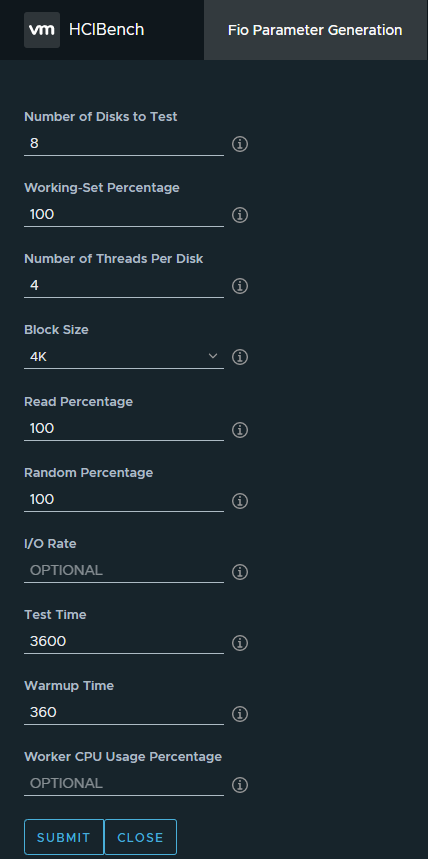
Общее количество виртуальных машин — 12, каждая — с 8 дисками объемом 10 ГБ, разогрев — 6 минут, время теста — 1 час, суммарное количество потоков — 384. Важный момент — перед тестом на диски записываются абсолютно случайные данные таким образом, что полностью отсутствуют блоки с 0, поэтому компрессия на данных дисках показывает коэффициент 1:1. Это важно, т.к. при наличии нулевых блоков операции чтения могут значительно ускоряться при включенной компрессии.
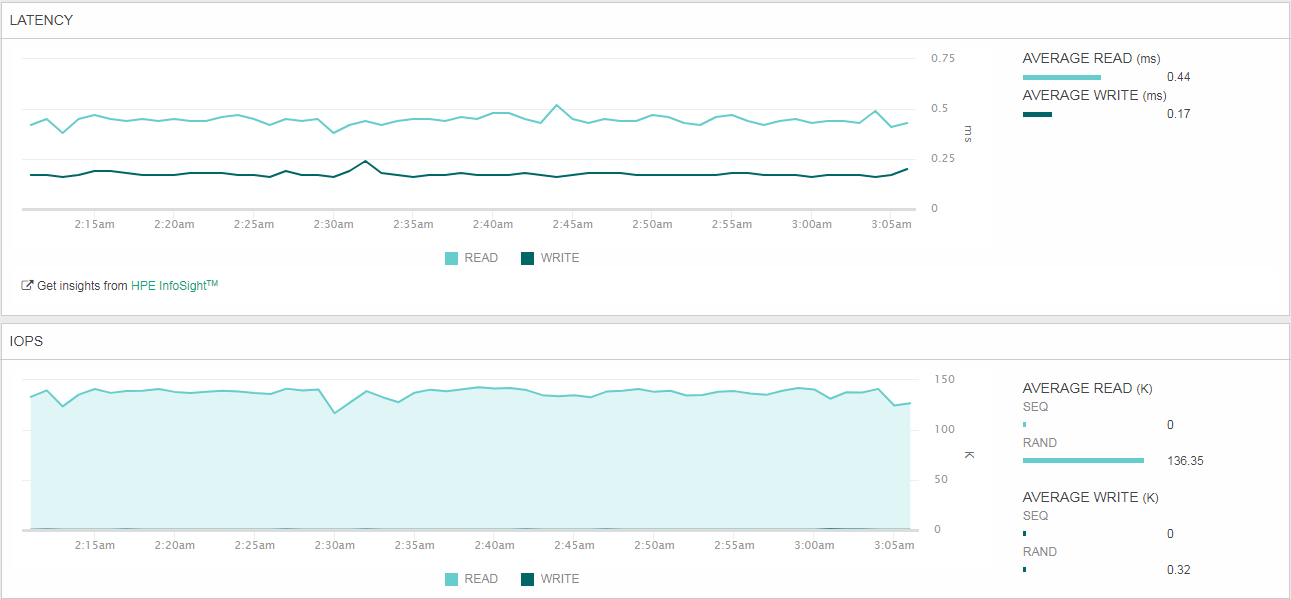
По результатам получаем следующее. Аналитика со стороны интерфейса управления HPE Nimble AF40:
Результаты со стороны HCIbench (для самых внимательных: время отчета указано с учетом временной зоны GMT -07:00, что составляет разницу в 10 часов по сравнению с GMT +03:00):
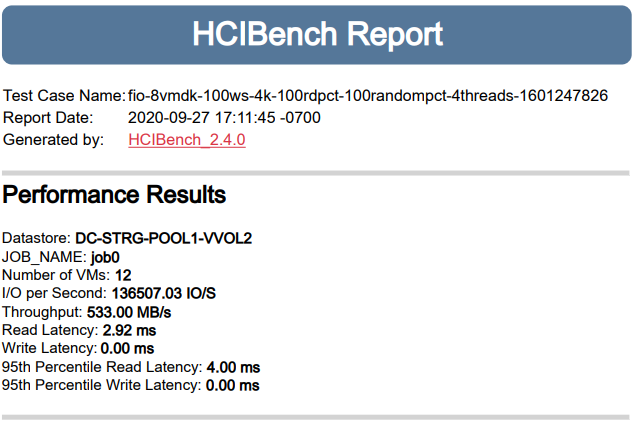
Задержки на чтение высоковаты — хотелось бы уложиться в 2 мс, — поэтому пробуем второй заход: настройки те же, но снижаем количество виртуальных машин до 6, тем самым снижая количество потоков до 192:
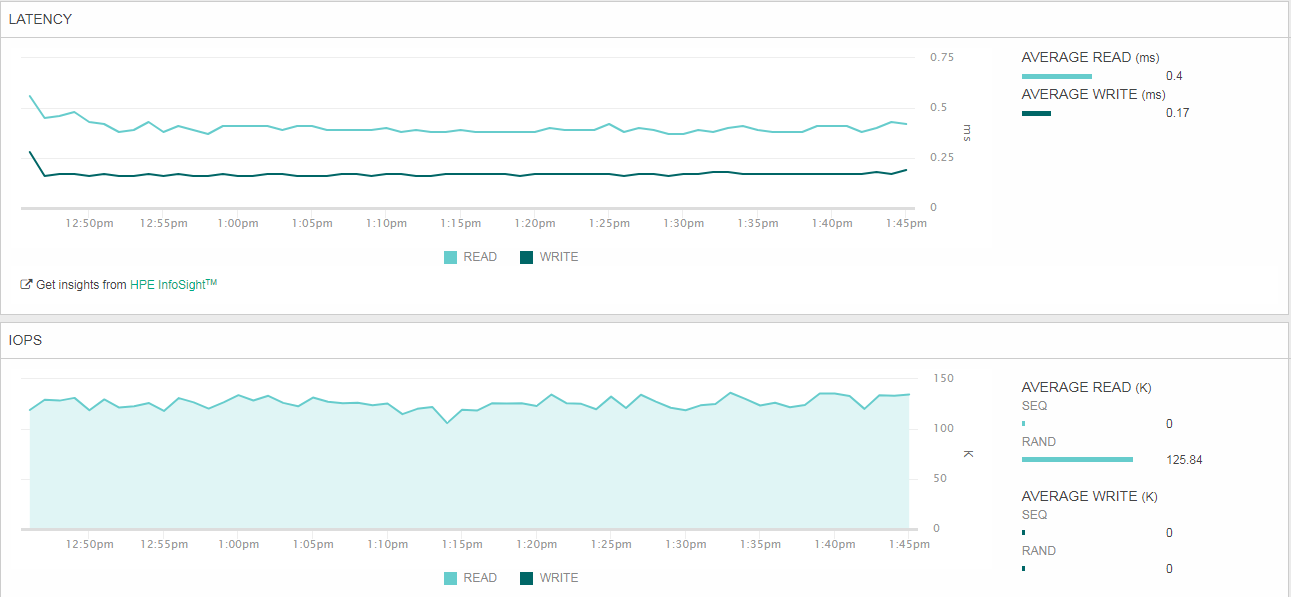
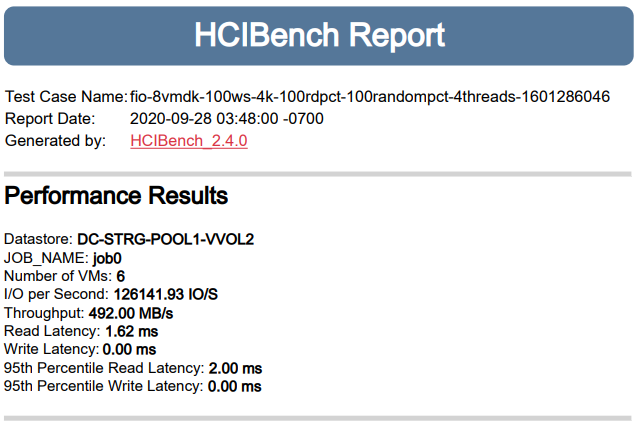
Уже значительно лучше.
Конечно, было интересно, как отработает QoS, поэтому выставили ограничение для тестируемых VVOL в 20К IOPS и еще раз запустили первый тест на 384 потока, но в целях экономии времени — продолжительностью всего 10 минут.
Используя SSH-подключение к хостам ESXi и встроенную утилиту esxtop, видим, что с каждого хоста генерируется нагрузка в 125-128 потоков и при этом получаем очень высокие показатели задержки от FC HBA сервера до системы хранения. И тут ничего удивительного: система хранения отрабатывает политику QoS, понижая максимальное количество операций ввода-вывода в секунду до 20 000, что приводит к скапливанию очередей и задержкам в вводе-выводе.

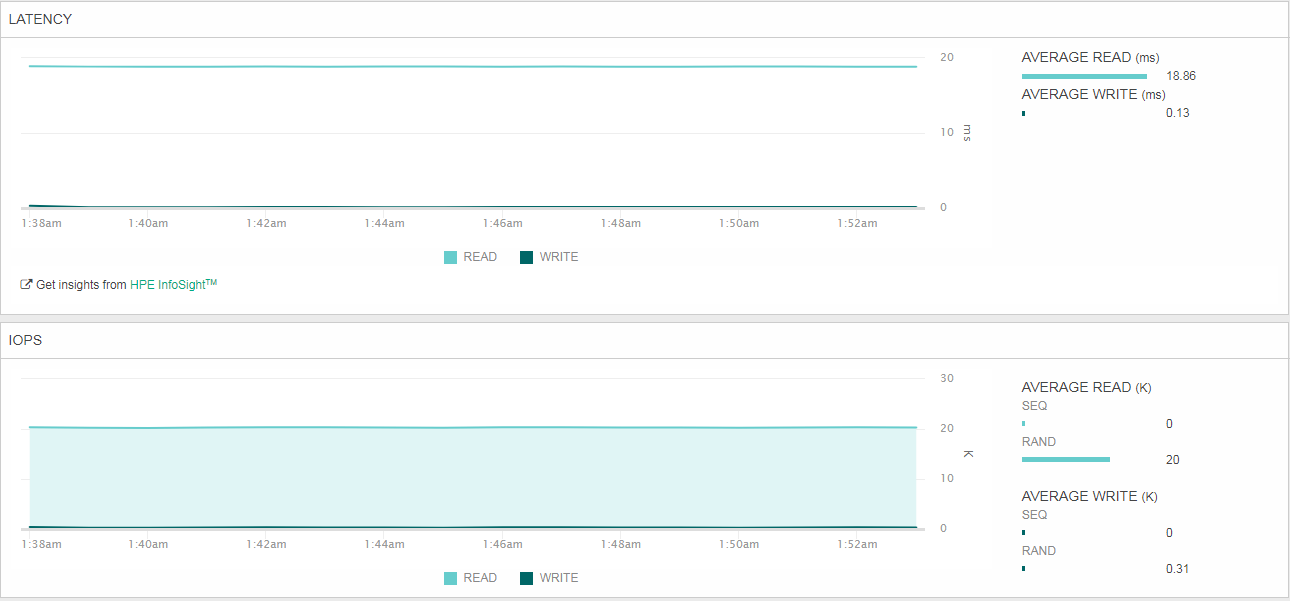
Собственно, тут иначе никак. Функционал крайне полезный и поможет защитить продуктивную среду или критически важные сервисы от паразитной нагрузки со стороны тестовых лабораторий или других менее важных сервисов, которые не чувствительны к задержкам.
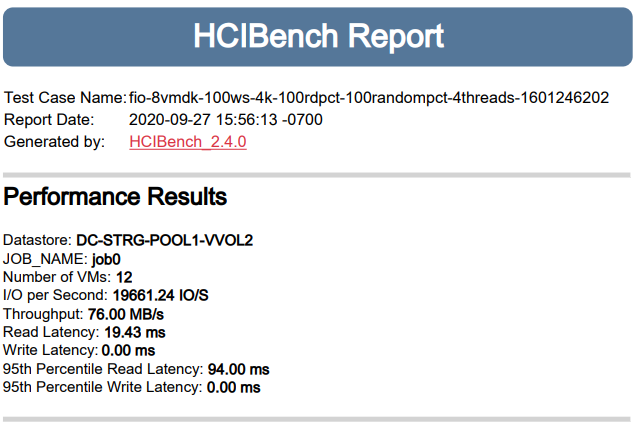
А как дела обстоят с записью? Прогоняем тест 100% случайная запись, размер блока – 4К, остальные параметры – те же. Опять же для начала – 384 потока.
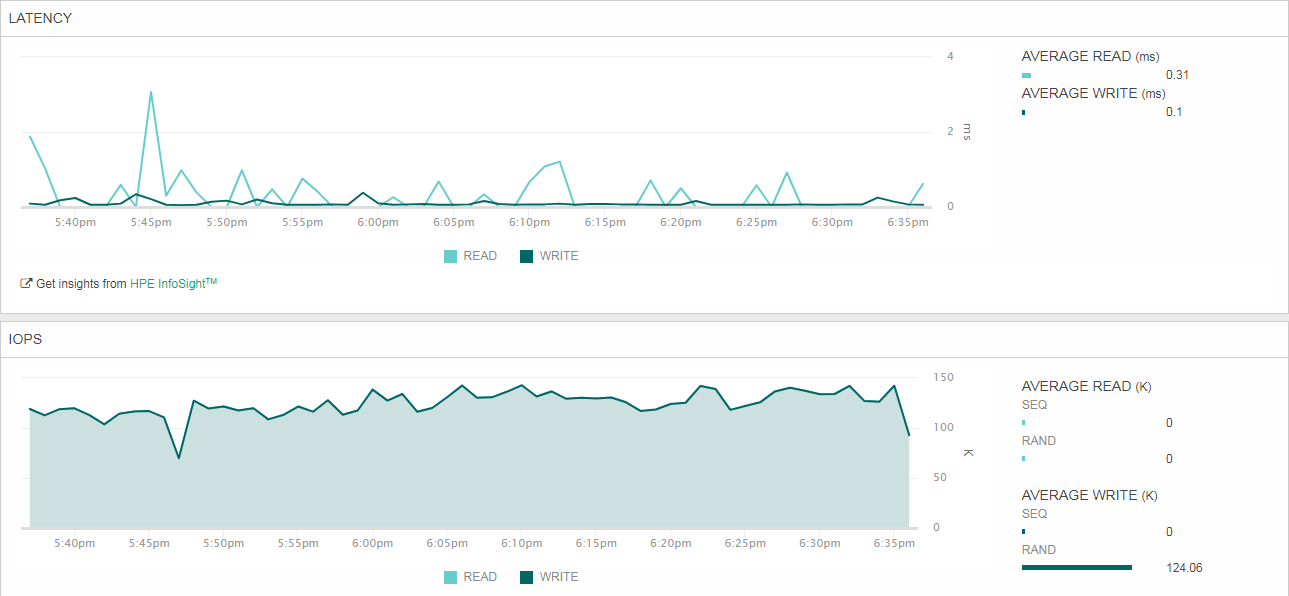
По традиции прогоняем тест второй раз, но уже с 6 виртуальными машинами, а, следовательно, в 192 потока.
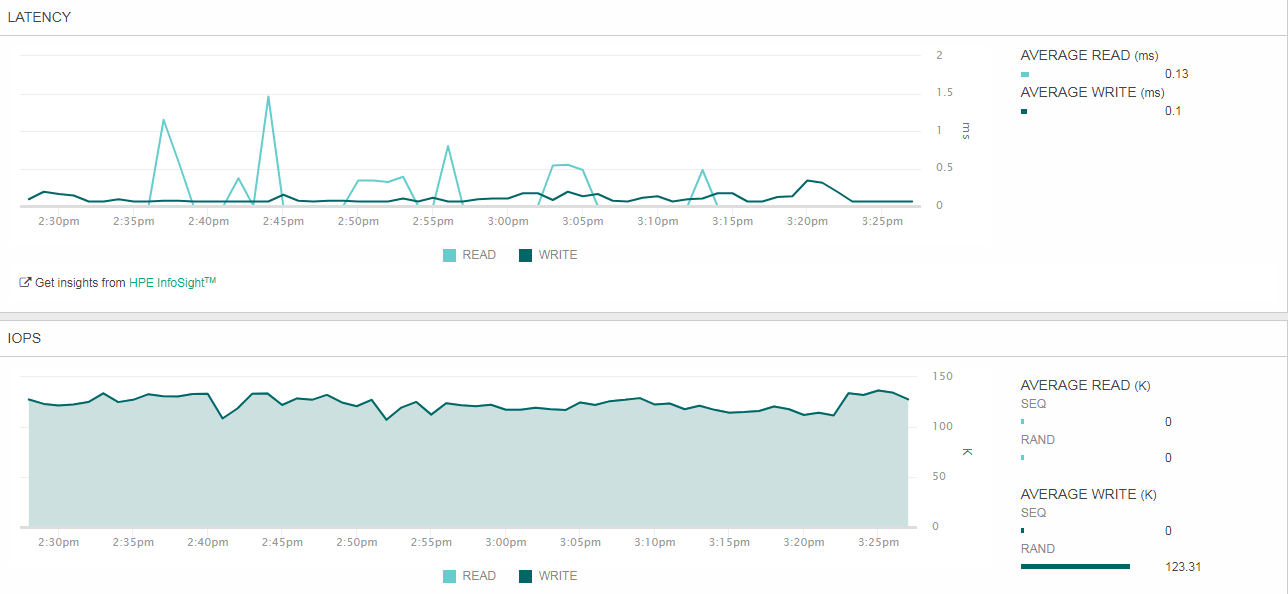
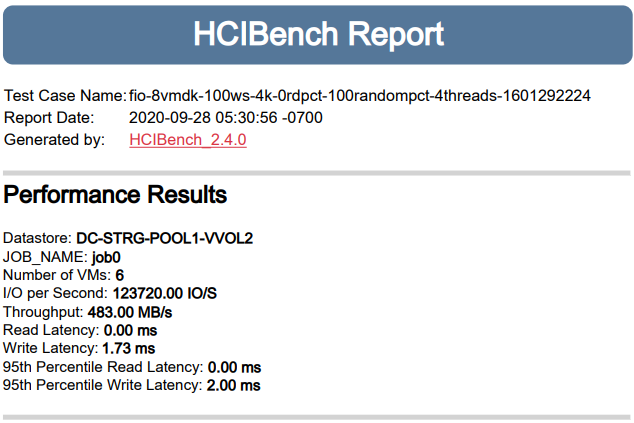
Тут тоже удалось уложиться в 2 мс. Результат весьма близок к аналогичным замерам по 100% случайному чтению. Это говорит о том, что соотношение показателей IOPS, заявленных вендором, являются релевантными. Напомню, по 150К IOPS для 100% случайного чтения блоками 4К и для 100% случайной записи блоками 4К. Хотя обычно на практике запись всегда проседает относительно чтения, вероятно, это чудесная магия запатентованной архитектуры HPE Nimble CASL с многоуровневым кэшированием как записи, так и чтения.
Есть еще, конечно, сложносоставной тест через vdbench для виртуальной среды, который максимально приближен к реальным нагрузкам, но на его повторный прогон, к сожалению, не хватило времени, а прошлых результатов не сохранилось (может быть в следующий раз, если тема зайдет).
Вывод: достаточно неплохие результаты с учетом устаревшего оборудования, отсутствием 16 гигабитного FC, что, по нашему мнению, как раз-таки и помешало выйти на заявленные цифры.
Когда с синтетикой покончено, самое время переходить к расширенной аналитике и искусственному интеллекту SkyNet HPE Infosight, который призван убить всех человеков упростить процессы мониторинга, управления и поддержки системы хранения на всем промежутке ее жизненного цикла.
Впечатление №4: ИИ HPE Infosight – в шахматы с ним не сыграешь, но вот проблемы найти и решить поможет
ИИ HPE Infosight здесь выступает в качестве бесплатного десерта, который тебе приносят в дорогом ресторане после сочного стейка. Вроде не заказывал, но принесли за счет заведения. Вроде бы и не хотелось, но раз принесли – то грех не попробовать. А попробовать стоило, я вам скажу.
Попадая на главную страницу HPE Infosight (уже после предварительной регистрации, авторизации и привязки массива), видим несколько разных меню, в которых есть что посмотреть.
В том числе разнообразные дашборды. Например, Operational, который позволяет оценить общее состояние массива, или Recommendations, которые дают возможность подробно ознакомиться с рекомендациями на рисунке выше в правой части скриншота. Рекомендации, кстати, формируются на основании аналитики, которая производится искусственным интеллектом c использованием машинного обучения и телеметрии всей инсталляционной базы HPE Nimble по всему миру (в лабораториях HPE Nimble это Cross Stack Recommendations).
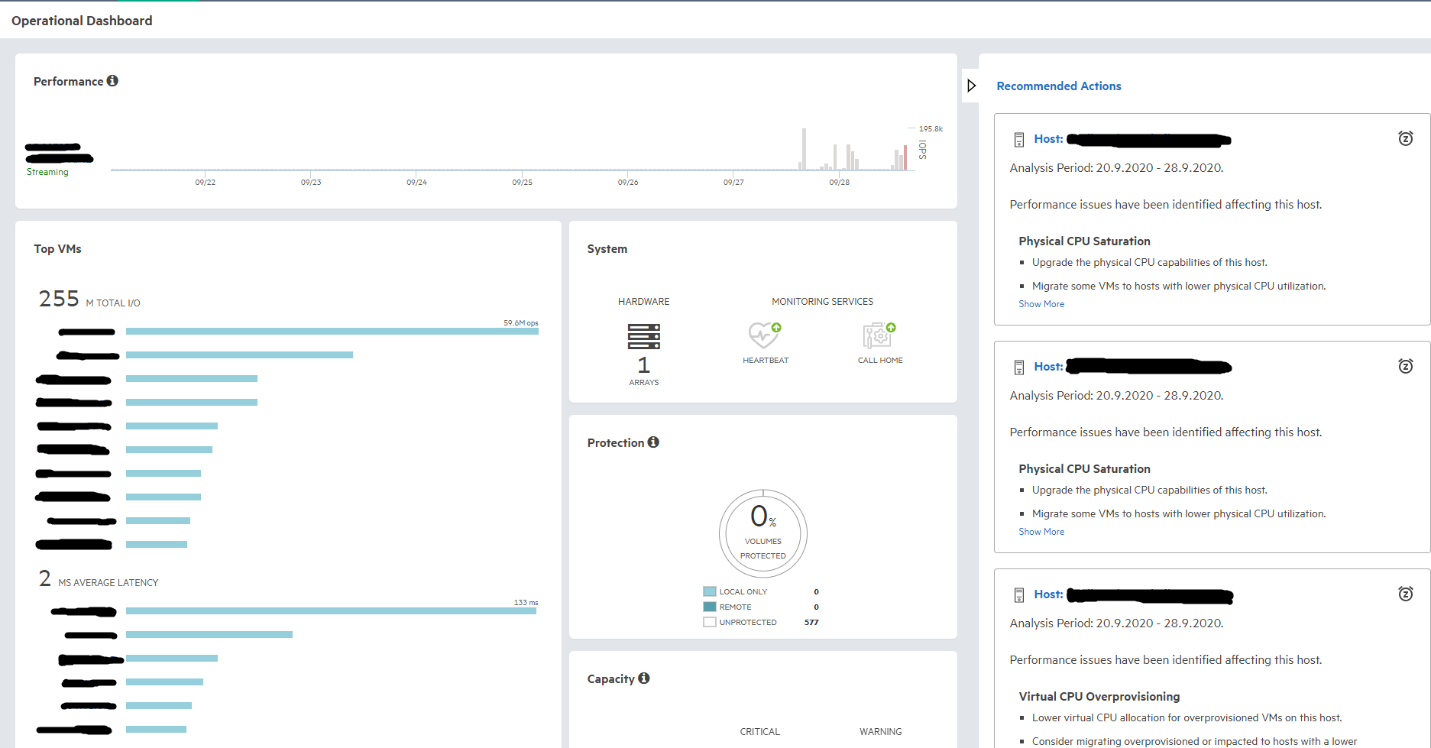
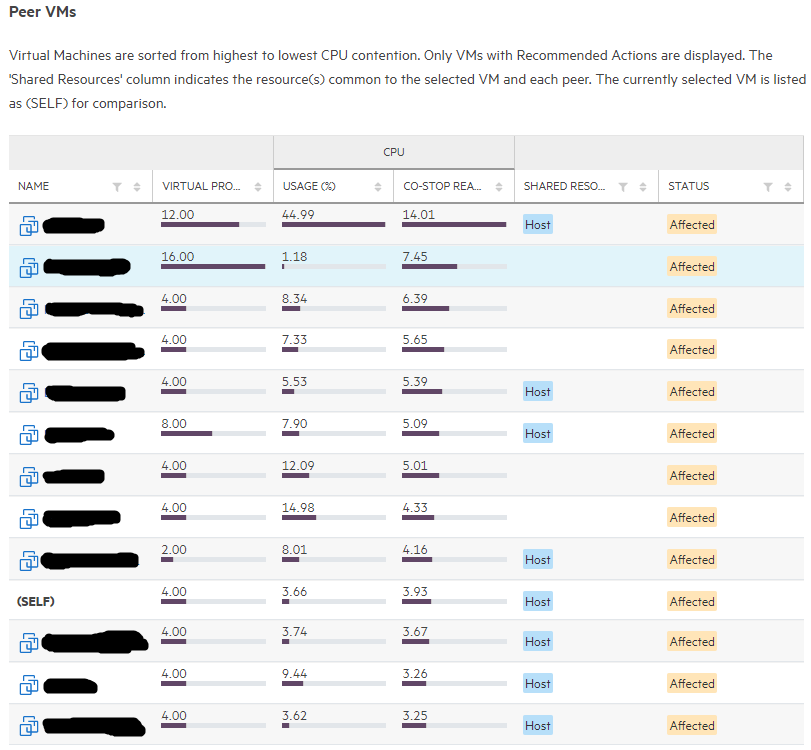
Ниже приведен пример рекомендаций по одной из проблем — Physical CPU Saturation с указанием масштаба бедствия. Также доступны рекомендации и по оставшимся двум проблемам — Elevated Latency, Virtual CPU Overprovisioning, и иногда щедрость тоже губит:
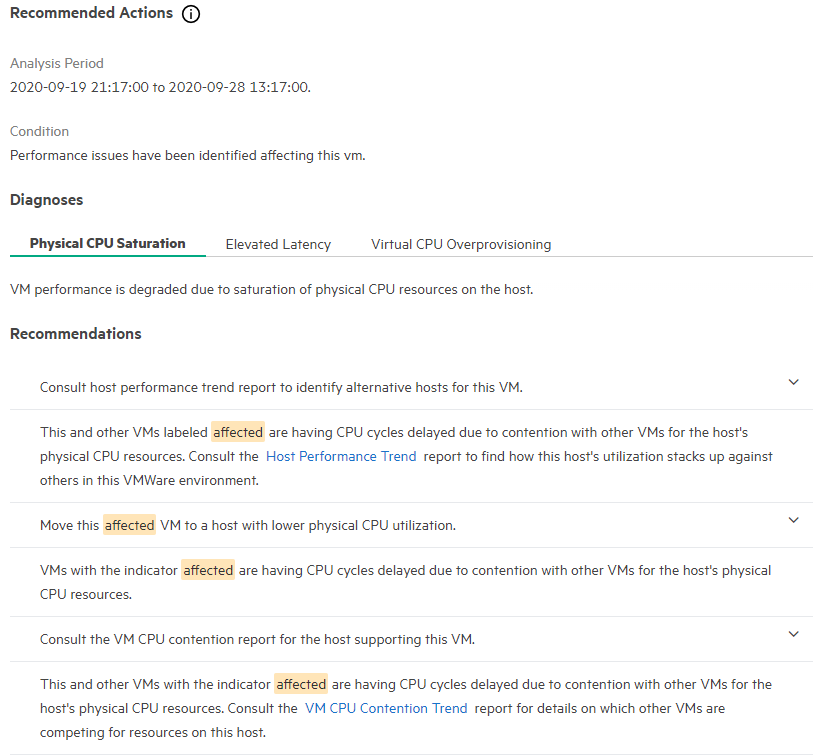

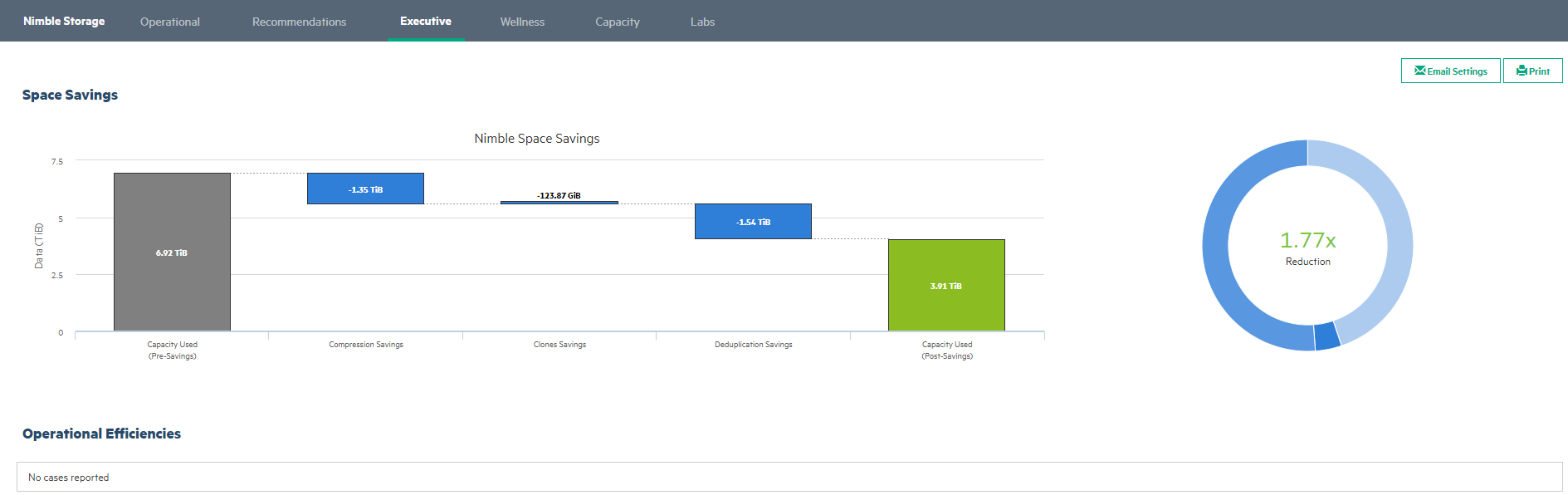
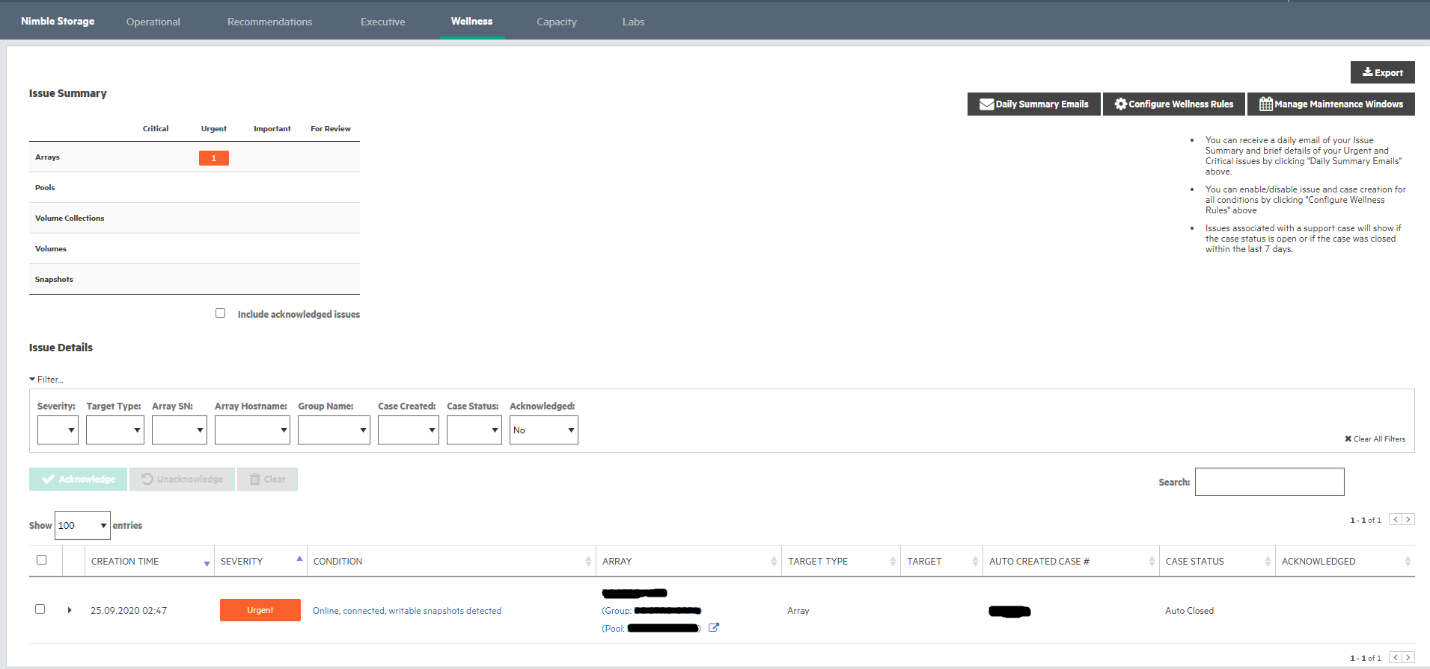
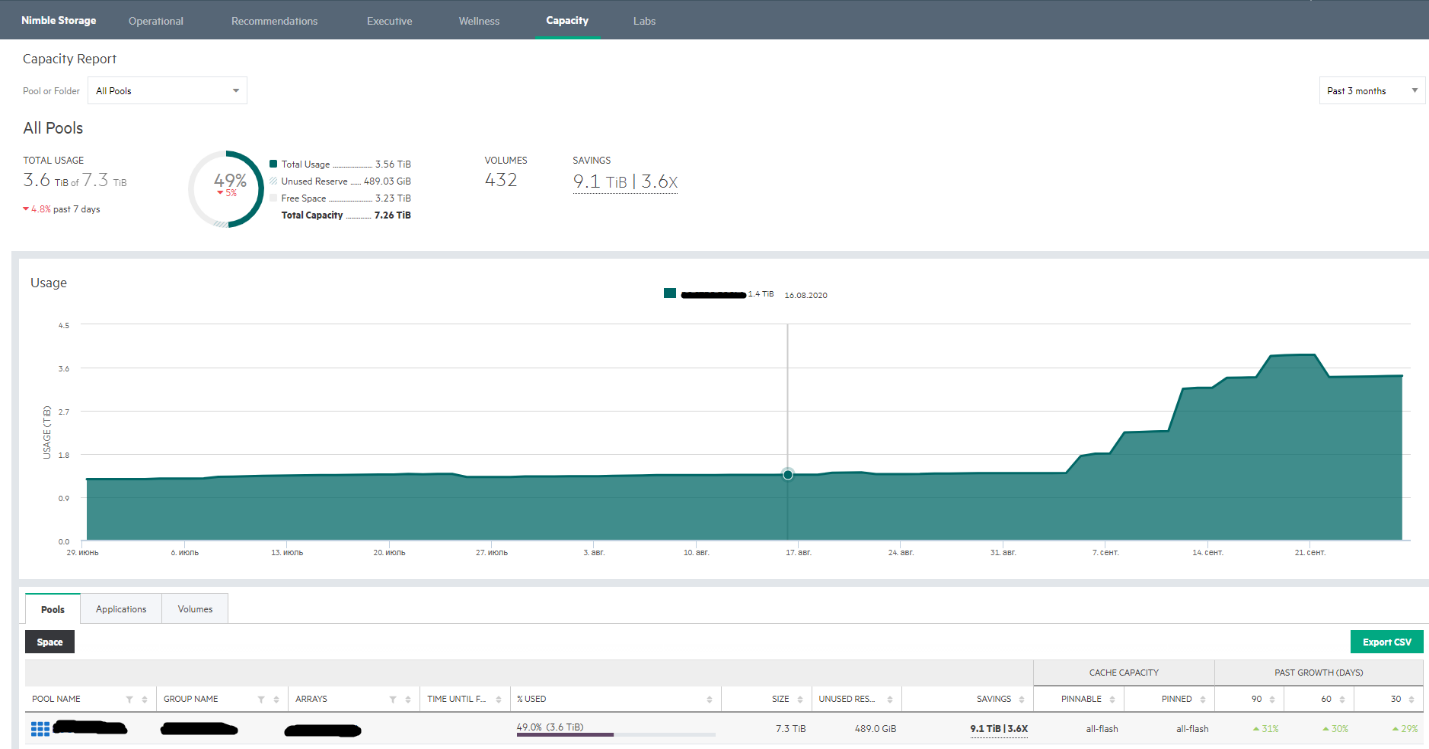
Также здесь присутствуют и отчеты для руководителей (Executive), которые показывают, есть ли открытые кейсы, по которым ведется работа, экономические показатели массива (сколько удалось сэкономить места благодаря технологиям компрессии и дедупликации), а также рекомендации в случае необходимости апгрейда массива. Wellness позволяет получить список по проблемам, если таковые имеются, а Capacity показывает разного рода тренды по динамике заполнения массива.
И, наконец, одно из самых полезных и интересных — это лаборатории HPE Infosight, где можно примерить на себя халат лаборанта и провести пару экспериментов или исследований.
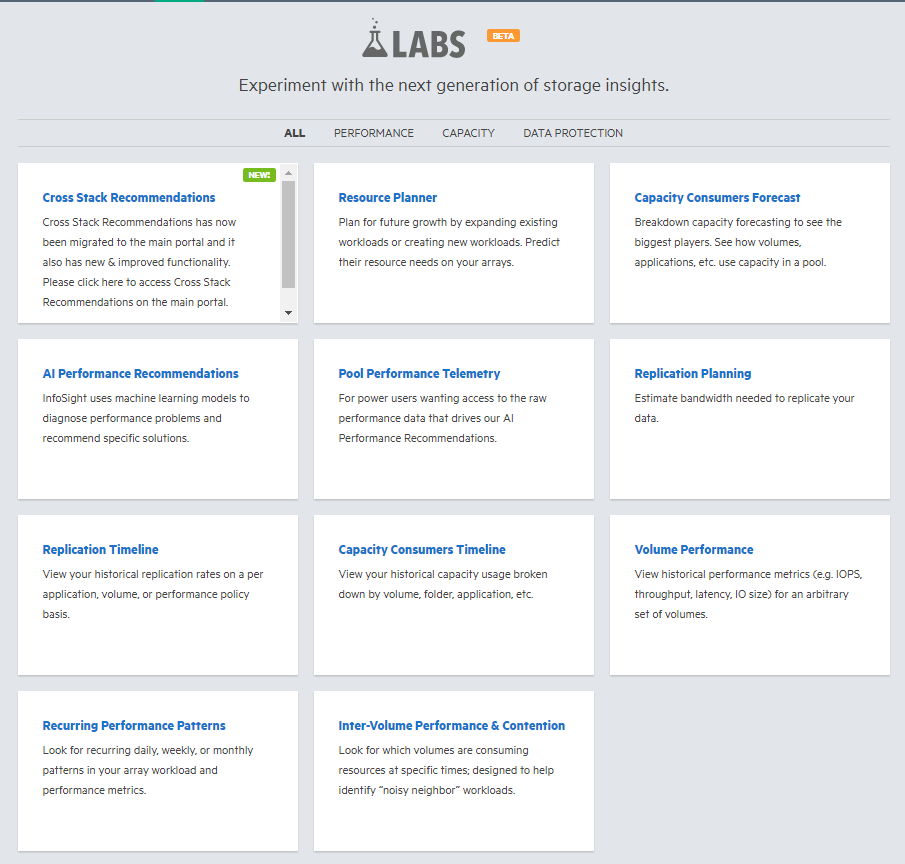
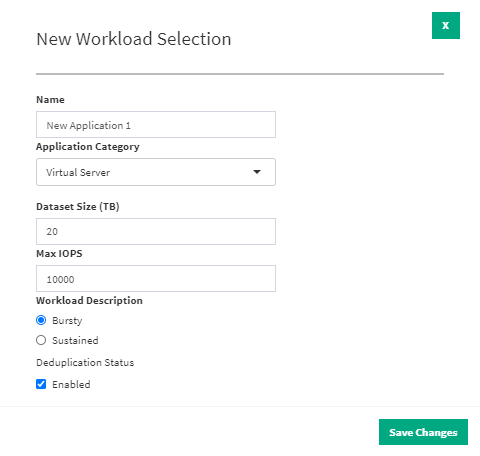
Тут и вышеупомянутая Cross Stack Recommendations, и Resource Planner, который позволит сэмулировать добавление на массив какой-либо нагрузки и изучить, как она повлияет в целом на производительность массива. При этом есть тонкая настройка выбранной нагрузки.
Раньше, кстати, для этого всего требовались отдельные продукты, например, HP Virtualization Performance Viewer, которые, естественно, стоили денег, и их необходимо было разворачивать и поддерживать.
Если вам кажется, что есть проблемы в производительности системы хранения данных, можно запустить AI Performance Recommendations и получить анализ за выбранный период. Соответственно, если будут проблемы — будут и рекомендации, как их устранить.

Одним словом, здесь есть где разгуляться, а самое главное — получить с минимальными усилиями отчеты и конкретную информацию (не надо ничего собирать, строить графики, вести Excel-таблицы и прочее), которую можно предоставить руководству, объяснив, что это ИИ на основе машинного обучения произвел анализ и интерпретацию входных данных.
Опытный заводчик виртуальных машин может подумать: «вот еще бы тут была корреляция метрик производительности по виртуальной инфраструктуре с метриками системы хранения, а то как-то неудобно что-то искать в VMware vCenter, что-то — в интерфейсе управления HPE Nimble в разделе Monitoring, а затем прикидывать одно к другому излюбленным эмпирическим методом». И, да, это тут тоже есть. В разделах Infrastructure -> Virtualization в зависимости от того, что вы используете (на текущий момент поддержка только для VMware и Hyper-V) можно получить информацию о своих дата-центрах, кластерах, хостах, дата-сторах и виртуальных машинах (их загрузка, производительность, метрики).
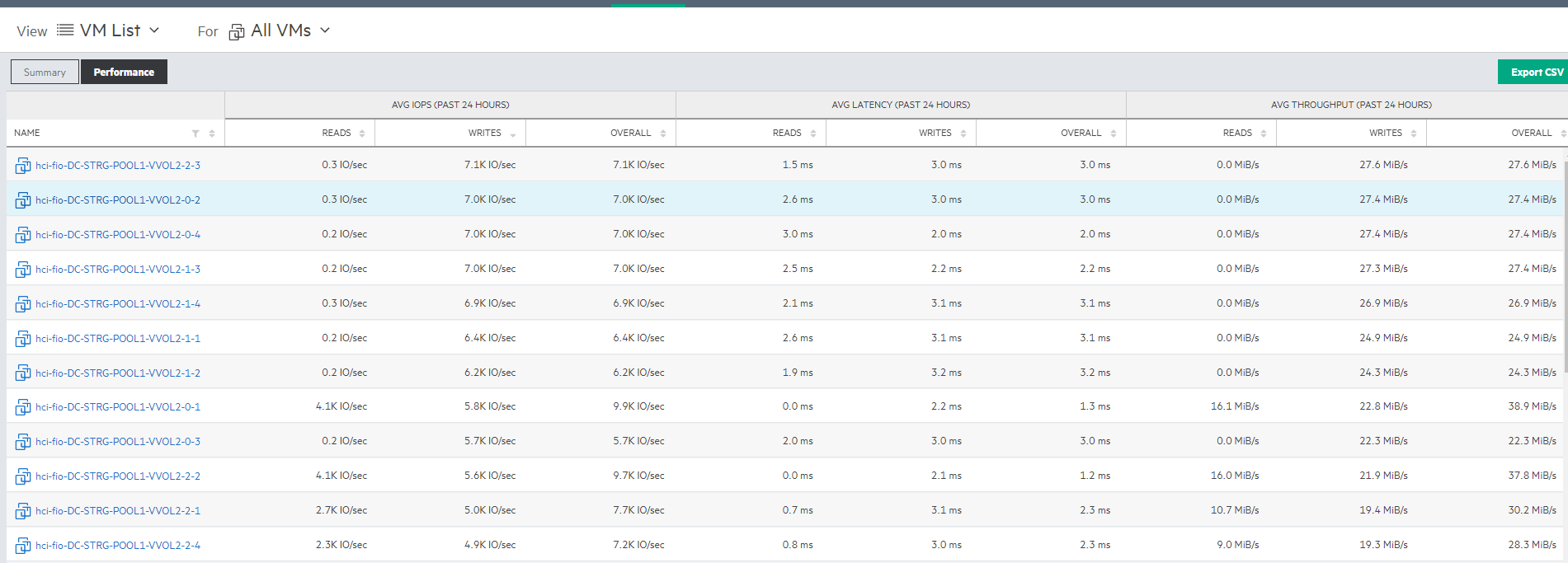
В разрезе виртуальных машин можно увидеть статистику по потребляемым ресурсам как со стороны вычислительной инфраструктуры, так и со стороны системы хранения данных, что также окажется крайне полезным.
Ну и напоследок это все решили заполировать самыми полезными ресурсами по HPE Nimble. Тут и документация, и прошивки, и дополнительное программное обеспечение, разного рода матрицы совместимости (куда же без них) и ссылка на портал поддержки, где можно вести работу по кейсам.
Резюме: с ИИ HPE Infosight все понятно, вещь полезная, удобная и нужная – это бесспорно. В 86% случаев система будет предотвращать или предлагать рабочее решение ваших проблем автоматически. Но вот в остальных случаях что? А если возникла жизненная необходимость пообщаться с “живым” человеком, а в ответ только бездушный голос машины или робота, который готов всячески тебе помочь, но в своей извращенной манере. Сразу вспоминается ситуация с дозвоном в банк или оператору связи, когда нужно еще очень сильно постараться, чтобы попасть на “живого” человека. Но тут, к счастью, обошлось. Есть выделенный телефон поддержки HPE Nimble, по которому отвечают люди и даже больше – инженеры (чувствуете разницу?) но сейчас будет вообще хорошо – инженеры поддержки 3 уровня, в том числе и русскоязычные.
Впечатление №5: поддержка, которая помогает
Как ни странно, в наше время — это большая редкость! При обращении в поддержку по какому-либо оборудованию, чаще всего приходится сталкиваться с поддержкой, которая меняет запчасти, иногда даже и не одну, иногда бывает даже замена “вкруг”. Понятно, что это все в угоду простоты замены, модульность систем к этому предрасполагает, но проблематика часто возникает не на уровне железа и замена запчастей не помогает ее решить. А время уходит, томное ожидание новых запчастей сменяется грустью о бесполезно потраченном на очередной заход сбора логов и общение с поддержкой времени. В очередной раз поменялся инженер по кейсу, которому необходимо объяснять все с самого начала или, ознакомившись с историей кейса, он все равно продолжает задавать все те же вопросы. А в это время и в твоей голове вьется, как назойливая муха, все тот же извечный вопрос – доколе?
В общем согласитесь, всегда приятно, когда кто-то ломает шаблоны. А еще приятнее, когда из этого действительно выходит толк. Так вот опишу нашу небольшую историю общения с L3 поддержкой HPE Nimble. Все началось с проблемы с одним из контроллеров во время тестирования их переключения (HA Failover). После переключения нагрузки, контроллер ушел за сигаретами в перезагрузку и после этого не вернулся. Странная, конечно, ситуация, но даже сброс по питанию не помог. Естественно, открылся кейс с помощью ИИ HPE Infosight и был автоматически передан инженерам L3 технической поддержки HPE Nimble, так как тут сбой контроллера на лицо и человекам виднее что там куда требовалась расширенная диагностика. Далее следовали в большинстве своем стандартные процедуры общения с поддержкой, исключая, разве что, прохождение кругов ада для того, чтобы попасть наконец к толковому инженеру (нашим кейсом, к слову, от начала и до конца занимался один и тот же инженер – Павел Тимургалеев). Мы уже были морально готовы к замене контроллера, согласитесь, достаточно ожидаемый исход. Но все получилось немного интереснее.
Проблема оказалась в том, что контроллер был подключен по консольному кабелю к серверу, на котором был установлен СКУД (сервер использовался нами для доступа к консоли массива). Серверов стоечных у нас было всего два, поэтому раскидали один контроллер к одному, второй к другому, остальные же серверы были в форм-факторе блейд-сервер. СКУД каким-то образом держал на себе консольный порт контроллера HPE Nimble и не давал ему загрузиться. С заменой по итогу обошлось, проблема была решена. Каким образом поддержка дошла до причины проблемы тоже остается загадкой. Но сам факт, что проблему удалось решить в кратчайшие сроки и максимально эффективно, т.е. без 2-3 итерацией замены контроллера, после которых стало бы понятно, что дело не в контроллере, действительно внушает уважение. Павлу и команде поддержки HPE Nimble однозначно хотелось бы выразить благодарность за проявленный профессионализм (надеюсь, им икнулось).
Странно, наверное, такое слышать, но, к сожалению, больше не приходилось общаться с технической поддержкой HPE Nimble, т.к. за год эксплуатации массива не возникло абсолютно никаких поломок или проблем. Приятно, когда общение с поддержкой превращается в маленький праздник.
На этой позитивной ноте я бы хотел уже откланяться, но вы же непременно скажете: а где же минусы, минусы-то где? Не бывает такого, чтобы без минусов. Да, соглашусь, без минусов, конечно же не обошлось. Один из основных минусов – это избыточная мощность. Честно говоря, под наши нагрузки хватило бы и гибридной модели в соотношении 20% SSD/80% MDL 7,2K, например, тех же HPE Nimble HF20 или HPE Nimble HF40, но был бюджет, а поэтому почему бы и нет. Но теперь приходится придумывать самим себе работу и вводить новые сервисы, т.к. видя, как система простаивает, сердце кровью обливается и хочется непременно ее нагрузить. Поэтому каждый раз, когда залезаешь в ИИ HPE Infosight, то получаешь мощного пинка от системы, она заставляет постоянно что-то оптимизировать, что-то настраивать, заставляет работать, одним словом, смотреть только вперед и не оглядываться назад, ведь за спиной – надежный соратник. А может быть VDI? А почему бы и нет, черт возьми! Поэтому сейчас начали разворачивать и тестировать VMware Horizon с использованием концепции Just-in-Time (linked clones уже не торт). А тем временем аппетиты растут и уже где-то там на горизонте маячат новые сервера с NVIDIA Tesla T4 или серии RTX6000. Было бы неплохо.
UPD: в рамках статьи упустил много чего интересного, а именно, первичную проблематику тестирования All-Flash массивов на гипервизорах VMware ESXi, с которой бились достаточно длительное время и грешили на HPE Nimble (мы и не говорили, что мы святые). Из коробки нагрузочное тестирование адекватно работать не будут: тут и проблемы с очередями на FC HBA (базовые значения драйвера) – DQLEN и No of outstanding IOs with competing worlds, а также ограничения со стороны виртуальных контроллеров виртуальных машин. Этого материала вполне хватит на отдельную статью.
")
 для освещения в квартире или рабочем месте, практическое применение + обзор ламп на 70, 150Вт")

