
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, Хабр! На связи снова Юрий Кацер, эксперт по ML и анализу данных в промышленности, а также руководитель направления предиктивной аналитики в компании «Цифрум» Госкорпорации “Росатом”. До сих пор рамках рабочих обязанностей решаю задачи поиска аномалий, прогнозирования, определения остаточного ресурса и другие задачи машинного обучения в промышленности. В рамках рабочих задач мне приходится часто сталкиваться с проблемой правильной оценки качества решения задачи, и, в частности, выбора правильной data science метрики в задачах обнаружения аномалий.
Поскольку речь пойдет о метриках обнаружения аномалий, давайте сначала определимся, что такое аномалия и обнаружение аномалий. В широком смысле аномалия означает отклонение от ожидаемого поведения. Обнаружение аномалий, в свою очередь, представляет собой задачу (или методику) выявления необычных паттернов, не соответствующих ожидаемому поведению. Обнаружение аномалий необходимо в различных областях знаний и прикладных решениях, например, чтобы отслеживать проникновения в компьютерные сети, детектировать аварийные ситуации на электростанциях, выявлять мошенничества при операциях с кредитными картами в банках, определять климатические изменения, создавать системы контроля состояния здоровья и для многого другого.
Важно заметить, что этой статье мы будем говорить об обнаружении аномалий в данных типа временные ряды. Давайте разберемся, что это такое!
Временной ряд — это последовательность точек или векторов, проиндексированных в хронологическом порядке и представляющих характеристику процесса.

Оценить алгоритмы обнаружения аномалий совсем не просто, поскольку существует множество математических задач и различных метрик, подходящих для конкретных проблем и условий. Часто исследователи и data scientist’ы берут общепринятую метрику, такую как F1, только потому, что ее настоятельно рекомендуют для задач классификации в общем случае. Чтобы помочь избежать неправильного выбора метрик, я решил сделать обзор метрик, используемых для оценки качества решения задач обнаружения аномалий.
Дисклеймер: Информация в статье изложена упрощенно, а сама статья не претендует на всеобъемлющий анализ рассматриваемого вопроса.
Пример и объяснение разницы между функциями потерь, критериями, метриками
Для лучшего понимания мы на примере объясним, о какой конкретно части алгоритма обнаружения аномалий идет речь в статье. В качестве примера алгоритма возьмем следующий:

Шаг 1. Прогнозирование (модель процесса): возьмем обученную (на данных нормального режима) модель машинного обучения для прогнозирования некоего существующего сигнала на одну точку вперед в каждый момент времени. Когда модель не совпадает с реальным сигналом, можно говорить, что процесс отклоняется от нормального состояния.
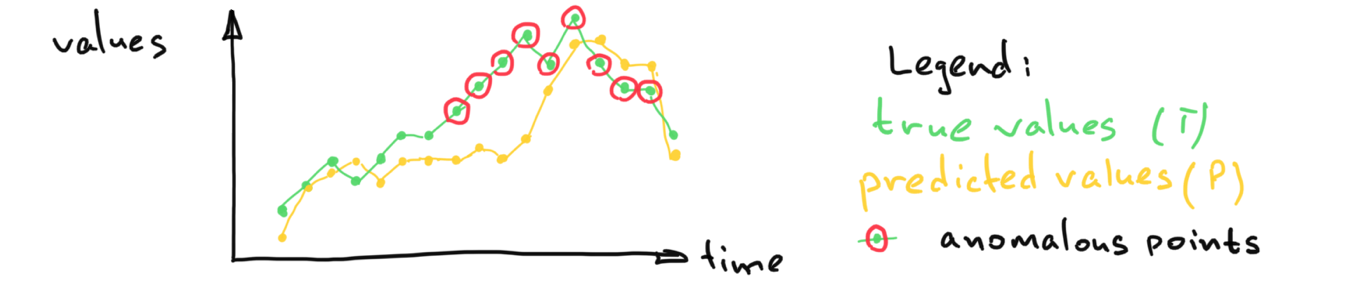
Шаг 2. Критерий обнаружения аномалий: наш алгоритм обнаружения аномалий основан на критерии сравнения функции ошибки (абсолютной ошибки) с заранее рассчитанным (на этапе обучения) порогом. Абсолютная ошибка растет, когда данные отклоняются от нормальных значений, использованных на этапе обучения модели. Превышение порога указывает на обнаружение аномалии.

Шаг 3. Оценка алгоритмов обнаружения аномалий: именно этому шагу и необходимым для него метрикам посвящена эта статья.

Таким образом:
в статье не рассматриваются функции потерь (cost functions, loss functions), оптимизируемые на этапе обучения алгоритмов машинного обучения в Шаге 1. Однако в качестве функции потерь (loss function) могут быть выбраны функции (критерий, метрика) из Шагов 2 или 3, чтобы максимально повысить качество работы модели;
в статье не рассматриваются критерии обнаружения аномалий из Шага 2, хотя они похожи на метрики машинного обучения;
статья посвящена Шагу 3 — оценке алгоритма обнаружения аномалий.
Матрица несоответствий
Прежде чем перейти к метрикам, нужно понять суть матрицы несоответствий (confusion matrix). Вот как она выглядит:

Как читать таблицу:
tp (истинно положительный): спрогнозировано аномальное значение, и это верно;
tn (истинно отрицательный): спрогнозировано нормальное значение, и это верно;
fp (ложноположительный): спрогнозировано аномальное значение, и это неверно;
fn (ложноотрицательный): спрогнозировано нормальное значение, и это неверно.
Задачи обнаружения аномалий
Для удобства дальнейшей систематизации метрик давайте определим задачи, которые чаще всего выделяют в проблеме обнаружения аномалий, но сначала скажем о различных типах аномалий. По количеству точек аномалии обычно делят на точечные (point) и коллективные (collective). Существуют также контекстуальные (contextual) аномалии, но коллективный и контекстуальный типы иногда объединяют в так называемый range-based тип. Но для простоты мы будем использовать термин коллективная аномалия для range-based, то есть для коллективных и контекстуальных вместе, а определение возьмем отсюда:
Коллективная аномалия — это аномалия, возникающая в виде последовательности временных точек, когда между началом и концом аномалии не существует неаномальных (нормальных) данных.

Подробнее о задаче обнаружения аномалий можно прочитать в другой моей статье.
Задача обнаружения аномалий часто трансформируется в задачу бинарной классификации (также часто называемую задачей обнаружения выбросов) и задачу обнаружения точки изменения состояния. Связь между задачами и типами аномалий показана на схеме.

Что это означает? При решении задачи детекции точечных аномалий мы будем использовать и оценивать алгоритмы бинарной классификации. Для коллективных аномалий мы можем использовать и оценивать как алгоритмы бинарной классификации, так и алгоритмы обнаружения точки изменения состояния (в зависимости от прочих условий или постановки бизнес-задачи). Другими словами, алгоритмы обнаружения точки изменения состояния применимы только для коллективных аномалий, потому что необходимо найти конкретную точку изменения состояния, где начинается коллективная аномалия. Однако можно интерпретировать коллективную аномалию как набор точечных аномалий, поэтому алгоритмы бинарной классификации применимы для обоих типов аномалий.

Классы метрик
Определив существующие задачи обнаружения аномалий, мы можем связать эти задачи с классами метрик, которые используются для оценки алгоритмов. О классах и метриках, относящихся к каждому классу, поговорим сразу после того, как посмотрим на рисунок ниже, где показана связь между задачами и классами метрик.

Итак, какие бывают классы метрик:
Метрики бинарной классификации: отнесение результата классификации объекта к одному из двух классов (нормальный, аномальный) с истинной (верной) меткой объекта.
Для задач обнаружения точки изменения состояния метрики бинарной классификации применяются на основе окна: проверяем, находится ли прогнозируемая точка изменения состояния в окне обнаружения, или сравниваем наложение прогнозируемого и истинного окон (положение, размер и т.д.).
Для задачи бинарной классификации метрики бинарной классификации применяются, учитывая каждую точку: проверяем правильность предсказанной метки для каждой точки.
Обнаружение на основе окна (вне бинарной классификации): сопоставление прогнозируемой точки изменения с окном вокруг фактической точки изменения способом, отличным от бинарной классификации.
Время (или номер точки) обнаружения: оценка разницы во времени (или номере точки / индексе) между прогнозируемой и фактической точками изменения состояния.
Классификация метрик обнаружения аномалий
В этом разделе покажем классификацию метрик и дадим краткую информацию о каждой из них.

Метрики обнаружения на основе окна (вне бинарной классификации)
NAB scoring algorithm (Скоринговый алгоритм NAB): основными особенностями этого алгоритма являются вознаграждение за раннее обнаружение и штрафование за ложноположительные и ложноотрицательные результаты. Это делается с помощью специальной функции оценки, которая применяется к окнам аномалий. Каждое окно представляет собой диапазон точек данных, сосредоточенных вокруг эталонной аномалии. Более подробная информация представлена в этой статье.
Rand Index (Индекс Рэнда): интуитивно индекс равен количеству совпадений между двумя сегментациями (прогнозируемой и эталонной). Более подробная информация представлена в этой статье.
Метрики оценки ошибки времени (или номера точки) обнаружения
ADD (average detection delay; средняя задержка обнаружения) = MAE (mean absolute error; средняя абсолютная ошибка) = AnnotationError (ошибка разметки): разница между прогнозируемой точкой изменения и истинной точкой изменения (можно измерять во времени, по количеству точек и т. д.). Абсолютное значение разницы между прогнозируемым и фактическим временем точки изменения суммируется и нормализуется на количество точек изменения. Более подробная информация представлена в этой статье.
MSD (mean signed difference; средняя ошибка со знаком): данная метрика в дополнение к средней абсолютной ошибке (MAE) учитывает направление ошибки (прогнозирует, что аномалия случится до либо после фактического времени точки изменения). Более подробная информация представлена в этой статье.
MSE (mean squared error; средняя квадратическая ошибка), RMSE (root mean squared error; среднеквадратическая ошибка), NRMSE (normalized root mean squared error; нормализованная среднеквадратическая ошибка): данные метрики служат альтернативами средней абсолютной ошибке (MAE). В этом случае ошибки возводятся в квадрат, и итоговая мера получается очень большой, если в классифицированных данных существуют несколько значительных выбросов. Более подробная информация представлена в этой статье.
ADD при заданной средней длине серии до ложного срабатывания (или при заданном уровне вероятности ложного срабатывания): служит критерием эффективности для количественной оценки склонности алгоритма обнаружения к ложным срабатываниям. Более подробная информация представлена в этой статье.
Hausdorff (Метрика Хаусдорфа): равняется наибольшему временному расстоянию между точкой изменения и ее прогнозом. Более подробная информация представлена в этой статье.
Существует еще много подобных метрик, которые подходят для особых областей применения и процедур обнаружения точки изменения состояния (например, средняя задержка обнаружения в наихудшем случае, интегральная средняя задержка обнаружения, максимальная условная средняя задержка обнаружения, среднее время между ложными срабатываниями и другие). О них можно прочитать в монографии Sequential Analysis: Hypothesis Testing and Changepoint Detection. Эта книга посвящена таким метрикам, которые в том числе служат критериями для алгоритмов обнаружения точек изменения состояния. Кроме того, в ней также содержатся рекомендации по выбору критериев или метрик для определения точки изменения в различных случаях, например, для контроля качества:
…Наилучшее решение — максимально быстро обнаруживать нарушения нормальной работы при минимальном количестве ложных срабатываний. … Таким образом, оптимальное решение основывается на компромиссе между скоростью обнаружения или задержкой обнаружения и частотой ложных срабатываний за счет сравнения потерь, на которые указывают истинные и ложные обнаружения.
Метрики бинарной классификации
FDR (fault detection rate; доля обнаруженных аномалий) = TPR (true positive rate; доля истинно положительных результатов) = Recall (Полнота) = Sensitivity (Чувствительность): отношение количества истинно положительных точек данных (точек изменения) к общему количеству истинно аномальных точек (или точек изменения) (TP+FN). Более подробная информация представлена в этой статье и в этой статье.
MAR (missed alarm rate; доля пропущенных срабатываний) = 1 — FDR: отношение количества ложноотрицательных точек данных (точек изменения) к общему количеству истинно аномальных точек (или точек изменения) (TP+FN).
Specificity (Специфичность): отношение количества истинно отрицательных точек данных (точек изменения) к общему количеству нормальных точек (TN+FP). Более подробная информация представлена в этой статье.
FAR (false alarm rate; доля ложных срабатываний) = FPR (false positive rate; доля ложноположительных результатов) = 1 — Специфичность: отношение количества ложноположительных точек данных (точек изменения) к общему количеству нормальных точек (TN+FP). Служит мерой того, как часто возникает ложное срабатывание.
G-mean (среднее геометрическое): комбинация Чувствительности и Специфичности. Более подробная информация представлена в этой статье.
Precision (Точность): отношение количества истинно положительных точек данных (точек изменения) к общему количеству точек, классифицированных как аномальные или точки изменения (TP+FP). Более подробная информация представлена в этой статье.
F-measure (F-мера): комбинация взвешенной Точности и Полноты (F1-мера представляет собой гармоническое среднее значение точности и полноты). Более подробная информация представлена в этой статье.
Accuracy (Точность): отношение количества правильно классифицированных точек данных (или точек изменения) к общему количеству точек данных (точек изменения). Более подробная информация представлена в этой статье.
ROC-AUC ROC-AUC (Receiver Operating Characteristic, area under the curve), PRC-AUC (Precision-Recall curve, area under the curve): полезные инструменты для прогнозирования вероятности бинарного результата. Более подробная информация представлена в этой статье и в этой статье.
MCC (Matthews correlation coefficient; Коэффициент корреляции Мэтьюса): мера, используемая для определения качества бинарной классификации, которая учитывает все истинно положительные, истинно отрицательные, ложноположительные и ложноотрицательные результаты. Более подробная информация представлена в этой статье.
Различие метрик бинарной классификации для задач обнаружения аномалий
Для задач обнаружения точки изменения состояния:
tp: количество правильно обнаруженных точек изменения (# of tp).
fp: количество точек, неправильно определенных как точки изменения (# of fp).
tn: количество нормальных точек, правильно определенных как нормальные (# of tn).
fn: количество пропущенных точек изменения (# of fn).
Для задач обнаружения выбросов:
tp: количество точек данных, правильно определенных как аномальные (# of tp).
fp: количество нормальных точек данных, неправильно определенных как аномальные (# of fp).
tn: количество нормальных точек данных, правильно определенных как нормальные (# of tn).
fn: количество точек данных, неправильно определенных как нормальные (# of fn).
Основное различие между определением результатов tp, fp, tn, fn для обнаружения выбросов и обнаружения точек изменения состояния состоит в том, что в первом случае каждой точке присваивают аномальный или нормальный индекс, а во втором случае каждую точку изменения состояния (или каждую истинную и ложную аномалию) определяют как обнаруженную либо как пропущенную.
Больше о метриках бинарной классификации для обнаружения аномалий во временных рядах можно прочитать в этой статье.
Заключение
Целью статьи было показать, как много метрик существует и практически все из них достаточно популярны используются в работе дата сайентистов при решении задач поиска аномалий. Также для всех метрик даны краткие описания и ссылки на статьи с их подробным описанием, примерами, реализациями и дополнениями.
Практические реализации некоторых метрик вы можете найти в различных библиотеках, как в классических типа sklearn, так и в специализированных, например, в TSAD (метрики для поиска точек изменения) или в PyOD (метрики для точечных аномалий).
Библиография
Ahmed, Mohiuddin, et al. “An investigation of performance analysis of anomaly detection techniques for big data in scada systems.” EAI Endorsed Trans. Ind. Networks Intell. Syst. 2.3 (2015): e5.
Aminikhanghahi, Samaneh, and Diane J. Cook. “A survey of methods for time series change point detection.” Knowledge and information systems 51.2 (2017): 339–367.
Truong, Charles, Laurent Oudre, and Nicolas Vayatis. “Selective review of offline change point detection methods.” Signal Processing 167 (2020): 107299.
Artemov, Alexey, and Evgeny Burnaev. “Ensembles of detectors for online detection of transient changes.” Eighth International Conference on Machine Vision (ICMV 2015). Vol. 9875. International Society for Optics and Photonics, 2015.
Tatbul, Nesime, et al. “Precision and recall for time series.” arXiv preprint arXiv:1803.03639 (2018).



")