
Давайте познакомимся с одной из атак на нейросети, которая приводит к ошибкам классификации при минимальных внешних воздействиях. Представьте на минуту, что нейросеть это вы. И в данный момент, попивая чашечку ароматного кофе, вы классифицируете изображения котиков с точностью более 90 процентов даже не подозревая, что “атака одного пикселя” превратила всех ваших “котеек” в грузовики.
А теперь поставим на паузу, отодвинем кофе в сторону, импортируем все необходимые нам библиотеки и разберем как работают подобные атаки
one pixel attack.
Цель данной атаки заставить алгоритм (нейросеть) выдать некорректный ответ. Ниже увидим это с несколькими различными моделями сверточных нейронных сетей. Используя один из методов многомерной математической оптимизации — дифференциальную эволюцию, найдем особенный пиксель, способный изменить изображение так, чтобы нейросеть стала неправильно классифицировать это изображение (несмотря на то, что ранее алгоритм “узнавал” это же изображение корректно и с высокой точностью).
Импортируем библиотеки:
Для нашего эксперимента загрузим датасет CIFAR-10, содержащий изображения реального мира, разбитых на 10 классов.
Посмотрим на любое изображение по его индексу. Например, вот на эту лошадь.

Нам придется искать тот самый могучий пиксель, способный изменить ответ нейросети, а значит, пора написать функцию для изменения одного или нескольких пикселей изображения.
Проверим?! Изменим один пиксель нашей лошади с координатами (16, 16) на желтый.

Для демонстрации атаки необходимо загрузить предобученные модели нейронных сетей на нашем датасете CIFAR-10. Мы будем использовать две модели lenet и resnet, но вы можете использовать для своих экспериментов и другие, раскомментировав соответствующие строки кода.
После загрузки моделей необходимо оценить тестовые изображения каждой модели, чтобы убедиться что мы атакуем только изображения, которые правильно классифицированы. Код ниже отображает точность и количество параметров каждой модели.
Все подобные атаки можно разделить на два класса: WhiteBox и BlackBox. Разница между ними в том, что в первом случае нам все достоверно известно об алгоритме, модели с которой имеем дело. В случае с BlackBox все что нам нужно это входные данные (изображение) и выходные данные (вероятности отнесения к одному из классов). Атака одного пикселя (one pixel attack) относится к BlackBox.
В этой статье рассмотрим два варианта атаки одного пикселя: untargeted и targeted. В первом случае нам будет абсолютно все равно к какому классу отнесет нейронная сеть нашего котика, главное, чтобы не к классу котиков. Targeted атака применима когда мы хотим, чтобы наш котик непременно стал грузовиком и только грузовиком.
Но как же найти те самые пиксели, изменение которых приведет к изменению класса изображения? Как найти пиксель, поменяв который one pixel attack станет возможна и успешна? Давайте попробуем сформулировать эту проблему как задачу оптимизации, но только очень простыми словами: при untargeted attack мы должны минимизировать доверие к нужному классу, а при targeted — максимизировать доверие к целевому классу.
При проведении подобного рода атак трудно оптимизировать функцию с помощью градиента. Необходимо использовать алгоритм оптимизации, который не полагается на гладкость функции.
Напомним, что для нашего эксперимента мы используем датасет CIFAR-10, содержащий изображения реального мира, размером 32 х 32 пикселя, разбитых на 10 классов. А это означает, что у нас есть целочисленные дискретные значения от 0 до 31 и интенсивности цвета от 0 до 255, и функция ожидается не гладкая, а скорее зазубренная, как показано ниже:
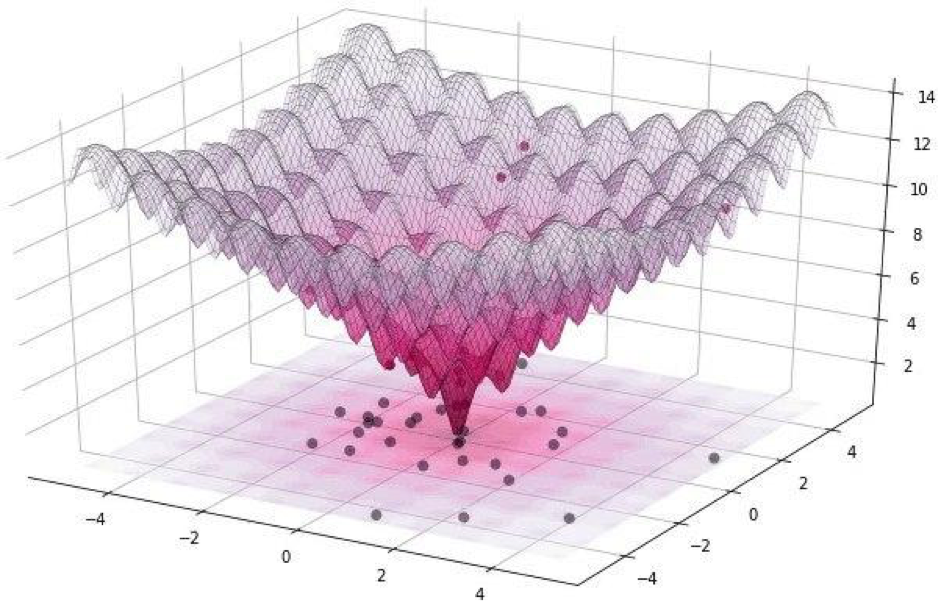
Именно поэтому мы используем алгоритм дифференциальной эволюции.
Но вернемся к коду и напишем функцию, которая возвращает вероятность достоверности модели. Если целевой класс является правильным, то эту функцию мы хотим минимизировать, чтобы модель была уверена в другом классе (что не верно).

Следующая функция понадобится нам, чтобы подтверждать критерий успеха атаки, она будет возвращать True, когда изменения было достаточно, чтобы обмануть модель.
Посмотрим на работу функции критерия успеха. В целях демонстрации предполагаем нецелевую атаку.

Пора собрать все пазлы в одну картинку. Будем использовать небольшую модификацию реализации дифференциальной эволюции в Scipy.
Пришло время поделиться результатами исследования (проведенной атаки) и посмотреть как изменение лишь одного пикселя превратит лягушку в собаку, кота в лягушку, а автомобиль в самолет. А ведь чем больше точек изображения позволено изменять, тем выше вероятность успешной атаки на любое изображение.



Продемонстрируем успешную атаку на изображение лягушки с помощью модели resnet. Мы должны увидеть уверенность в истинном снижении класса после нескольких итераций.

Это были примеры untargeted attack, а теперь проведем targeted attack и выберем к какому классу мы бы хотели, чтобы модель отнесла (классифицировала) изображение. Задача намного сложнее предыдущей, ведь мы заставим нейросеть классифицировать изображение корабля как автомобиля, а лошадь как кота.


Ниже мы попытаемся заставить lenet классифицировать изображение корабля как автомобиля.

Разобравшись с единичным случаями проведения атак, соберем статистику, используя архитектуру сверточных нейронных сетей ResNet, пройдясь по каждой модели, изменяя 1, 3 или 5 пикселей каждого изображения. В этой статье покажем итоговые выводы не утруждая читателя ознакомлением с каждой итерацией, поскольку это занимает немало времени и вычислительных ресурсов.
Для проверки возможности дискредитации сети был разработан алгоритм и измерено его влияние на качество прогноза решения по распознаванию образов.
Посмотрим окончательные результаты.
В приведенной таблице видно, что используя нейронную сеть ResNet с точностью 0.9231, меняя несколько пикселей изображения, мы получили очень неплохой процент успешно атакованных изображений (attack_success_rate).
В своих экспериментах вы вольны использовать и другие архитектуры искусственных нейронных сетей, благо их в настоящее время великое множество.

Нейросети окутали современный мир незримыми нитями. Уже давно придуманы сервисы, где используя ИИ (искусственный интеллект), пользователи получают обработанные фото, стилистически похожие на работы кисти великих художников, а сегодня алгоритмы уже умеют сами рисовать картины, создавать музыкальные шедевры, писать книги и даже сценарии к фильмам.
Такие сферы, как компьютерное зрение, распознавание лиц, беспилотные автомобили, диагностика заболеваний — принимают важные решения и не имеют права на ошибку, а вмешательство в работу алгоритмов приведет к катастрофическим последствиям.
One pixel attack – один из способов спуфинг атак. Для проверки возможности дискредитации сети был разработан алгоритм и измерено его влияние на качество прогноза решения по распознаванию образов. Результат показал, что применяющиеся сверточные архитектуры нейросетей уязвимы перед специально обученным алгоритмом One pixel attack, который подменяет один пиксель, с целью дискредитации алгоритма распознавания.
Статью подготовили Александр Андроник и Адрей Черный-Ткач в рамках стажировки в компании Data4.
А теперь поставим на паузу, отодвинем кофе в сторону, импортируем все необходимые нам библиотеки и разберем как работают подобные атаки
one pixel attack.
Цель данной атаки заставить алгоритм (нейросеть) выдать некорректный ответ. Ниже увидим это с несколькими различными моделями сверточных нейронных сетей. Используя один из методов многомерной математической оптимизации — дифференциальную эволюцию, найдем особенный пиксель, способный изменить изображение так, чтобы нейросеть стала неправильно классифицировать это изображение (несмотря на то, что ранее алгоритм “узнавал” это же изображение корректно и с высокой точностью).
Импортируем библиотеки:
# Python Libraries
%matplotlib inline
import pickle
import numpy as np
import pandas as pd
import matplotlib
from keras.datasets import cifar10
from keras import backend as K
# Custom Networks
from networks.lenet import LeNet
from networks.pure_cnn import PureCnn
from networks.network_in_network import NetworkInNetwork
from networks.resnet import ResNet
from networks.densenet import DenseNet
from networks.wide_resnet import WideResNet
from networks.capsnet import CapsNet
# Helper functions
from differential_evolution import differential_evolution
import helper
matplotlib.style.use('ggplot')
Для нашего эксперимента загрузим датасет CIFAR-10, содержащий изображения реального мира, разбитых на 10 классов.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Посмотрим на любое изображение по его индексу. Например, вот на эту лошадь.
image_id = 99 # Image index in the test set
helper.plot_image(x_test[image_id])
Нам придется искать тот самый могучий пиксель, способный изменить ответ нейросети, а значит, пора написать функцию для изменения одного или нескольких пикселей изображения.
def perturb_image(xs, img):
# If this function is passed just one perturbation vector,
# pack it in a list to keep the computation the same
if xs.ndim < 2:
xs = np.array([xs])
# Copy the image n == len(xs) times so that we can
# create n new perturbed images
tile = [len(xs)] + [1]*(xs.ndim+1)
imgs = np.tile(img, tile)
# Make sure to floor the members of xs as int types
xs = xs.astype(int)
for x,img in zip(xs, imgs):
# Split x into an array of 5-tuples (perturbation pixels)
# i.e., [[x,y,r,g,b], ...]
pixels = np.split(x, len(x) // 5)
for pixel in pixels:
# At each pixel's x,y position, assign its rgb value
x_pos, y_pos, *rgb = pixel
img[x_pos, y_pos] = rgb
return imgs
Проверим?! Изменим один пиксель нашей лошади с координатами (16, 16) на желтый.
image_id = 99 # Image index in the test set
pixel = np.array([16, 16, 255, 255, 0]) # pixel = x,y,r,g,b
image_perturbed = perturb_image(pixel, x_test[image_id])[0]
helper.plot_image(image_perturbed)
Для демонстрации атаки необходимо загрузить предобученные модели нейронных сетей на нашем датасете CIFAR-10. Мы будем использовать две модели lenet и resnet, но вы можете использовать для своих экспериментов и другие, раскомментировав соответствующие строки кода.
lenet = LeNet()
resnet = ResNet()
models = [lenet, resnet]
После загрузки моделей необходимо оценить тестовые изображения каждой модели, чтобы убедиться что мы атакуем только изображения, которые правильно классифицированы. Код ниже отображает точность и количество параметров каждой модели.
network_stats, correct_imgs = helper.evaluate_models(models, x_test, y_test)
correct_imgs = pd.DataFrame(correct_imgs, columns=['name', 'img', 'label', 'confidence', 'pred'])
network_stats = pd.DataFrame(network_stats, columns=['name', 'accuracy', 'param_count'])
network_stats
Evaluating lenet
Evaluating resnet
Out[11]:
name accuracy param_count
0 lenet 0.748 62006
1 resnet 0.9231 470218
Все подобные атаки можно разделить на два класса: WhiteBox и BlackBox. Разница между ними в том, что в первом случае нам все достоверно известно об алгоритме, модели с которой имеем дело. В случае с BlackBox все что нам нужно это входные данные (изображение) и выходные данные (вероятности отнесения к одному из классов). Атака одного пикселя (one pixel attack) относится к BlackBox.
В этой статье рассмотрим два варианта атаки одного пикселя: untargeted и targeted. В первом случае нам будет абсолютно все равно к какому классу отнесет нейронная сеть нашего котика, главное, чтобы не к классу котиков. Targeted атака применима когда мы хотим, чтобы наш котик непременно стал грузовиком и только грузовиком.
Но как же найти те самые пиксели, изменение которых приведет к изменению класса изображения? Как найти пиксель, поменяв который one pixel attack станет возможна и успешна? Давайте попробуем сформулировать эту проблему как задачу оптимизации, но только очень простыми словами: при untargeted attack мы должны минимизировать доверие к нужному классу, а при targeted — максимизировать доверие к целевому классу.
При проведении подобного рода атак трудно оптимизировать функцию с помощью градиента. Необходимо использовать алгоритм оптимизации, который не полагается на гладкость функции.
Напомним, что для нашего эксперимента мы используем датасет CIFAR-10, содержащий изображения реального мира, размером 32 х 32 пикселя, разбитых на 10 классов. А это означает, что у нас есть целочисленные дискретные значения от 0 до 31 и интенсивности цвета от 0 до 255, и функция ожидается не гладкая, а скорее зазубренная, как показано ниже:
Именно поэтому мы используем алгоритм дифференциальной эволюции.
Но вернемся к коду и напишем функцию, которая возвращает вероятность достоверности модели. Если целевой класс является правильным, то эту функцию мы хотим минимизировать, чтобы модель была уверена в другом классе (что не верно).
def predict_classes(xs, img, target_class, model, minimize=True):
# Perturb the image with the given pixel(s) x and get the prediction of the model
imgs_perturbed = perturb_image(xs, img)
predictions = model.predict(imgs_perturbed)[:,target_class]
# This function should always be minimized, so return its complement if needed
return predictions if minimize else 1 - predictions
image_id = 384
pixel = np.array([16, 13, 25, 48, 156])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
confidence = predict_classes(pixel, x_test[image_id], true_class, model)[0]
print('Confidence in true class', class_names[true_class], 'is', confidence)
print('Prior confidence was', prior_confidence)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence in true class bird is 0.00018887444
Prior confidence was 0.70661753
Следующая функция понадобится нам, чтобы подтверждать критерий успеха атаки, она будет возвращать True, когда изменения было достаточно, чтобы обмануть модель.
def attack_success(x, img, target_class, model, targeted_attack=False, verbose=False):
# Perturb the image with the given pixel(s) and get the prediction of the model
attack_image = perturb_image(x, img)
confidence = model.predict(attack_image)[0]
predicted_class = np.argmax(confidence)
# If the prediction is what we want (misclassification or
# targeted classification), return True
if verbose:
print('Confidence:', confidence[target_class])
if ((targeted_attack and predicted_class == target_class) or
(not targeted_attack and predicted_class != target_class)):
return True
# NOTE: return None otherwise (not False), due to how Scipy handles its callback function
Посмотрим на работу функции критерия успеха. В целях демонстрации предполагаем нецелевую атаку.
image_id = 541
pixel = np.array([17, 18, 185, 36, 215])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
success = attack_success(pixel, x_test[image_id], true_class, model, verbose=True)
print('Prior confidence', prior_confidence)
print('Attack success:', success == True)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence: 0.07460087
Prior confidence 0.50054216
Attack success: True
Пора собрать все пазлы в одну картинку. Будем использовать небольшую модификацию реализации дифференциальной эволюции в Scipy.
def attack(img_id, model, target=None, pixel_count=1,
maxiter=75, popsize=400, verbose=False):
# Change the target class based on whether this is a targeted attack or not
targeted_attack = target is not None
target_class = target if targeted_attack else y_test[img_id, 0]
# Define bounds for a flat vector of x,y,r,g,b values
# For more pixels, repeat this layout
bounds = [(0,32), (0,32), (0,256), (0,256), (0,256)] * pixel_count
# Population multiplier, in terms of the size of the perturbation vector x
popmul = max(1, popsize // len(bounds))
# Format the predict/callback functions for the differential evolution algorithm
def predict_fn(xs):
return predict_classes(xs, x_test[img_id], target_class,
model, target is None)
def callback_fn(x, convergence):
return attack_success(x, x_test[img_id], target_class,
model, targeted_attack, verbose)
# Call Scipy's Implementation of Differential Evolution
attack_result = differential_evolution(
predict_fn, bounds, maxiter=maxiter, popsize=popmul,
recombination=1, atol=-1, callback=callback_fn, polish=False)
# Calculate some useful statistics to return from this function
attack_image = perturb_image(attack_result.x, x_test[img_id])[0]
prior_probs = model.predict_one(x_test[img_id])
predicted_probs = model.predict_one(attack_image)
predicted_class = np.argmax(predicted_probs)
actual_class = y_test[img_id, 0]
success = predicted_class != actual_class
cdiff = prior_probs[actual_class] - predicted_probs[actual_class]
# Show the best attempt at a solution (successful or not)
helper.plot_image(attack_image, actual_class, class_names, predicted_class)
return [model.name, pixel_count, img_id, actual_class, predicted_class, success, cdiff, prior_probs, predicted_probs, attack_result.x]
Пришло время поделиться результатами исследования (проведенной атаки) и посмотреть как изменение лишь одного пикселя превратит лягушку в собаку, кота в лягушку, а автомобиль в самолет. А ведь чем больше точек изображения позволено изменять, тем выше вероятность успешной атаки на любое изображение.
Продемонстрируем успешную атаку на изображение лягушки с помощью модели resnet. Мы должны увидеть уверенность в истинном снижении класса после нескольких итераций.
image_id = 102
pixels = 1 # Number of pixels to attack
model = resnet
_ = attack(image_id, model, pixel_count=pixels, verbose=True)
Confidence: 0.9938618
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.4211318
Это были примеры untargeted attack, а теперь проведем targeted attack и выберем к какому классу мы бы хотели, чтобы модель отнесла (классифицировала) изображение. Задача намного сложнее предыдущей, ведь мы заставим нейросеть классифицировать изображение корабля как автомобиля, а лошадь как кота.
Ниже мы попытаемся заставить lenet классифицировать изображение корабля как автомобиля.
image_id = 108
target_class = 1 # Integer in range 0-9
pixels = 3
model = lenet
print('Attacking with target', class_names[target_class])
_ = attack(image_id, model, target_class, pixel_count=pixels, verbose=True)
Attacking with target automobile
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.22246778
Confidence: 0.23916133
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.5711696
Разобравшись с единичным случаями проведения атак, соберем статистику, используя архитектуру сверточных нейронных сетей ResNet, пройдясь по каждой модели, изменяя 1, 3 или 5 пикселей каждого изображения. В этой статье покажем итоговые выводы не утруждая читателя ознакомлением с каждой итерацией, поскольку это занимает немало времени и вычислительных ресурсов.
def attack_all(models, samples=500, pixels=(1,3,5), targeted=False,
maxiter=75, popsize=400, verbose=False):
results = []
for model in models:
model_results = []
valid_imgs = correct_imgs[correct_imgs.name == model.name].img
img_samples = np.random.choice(valid_imgs, samples, replace=False)
for pixel_count in pixels:
for i, img_id in enumerate(img_samples):
print('\n', model.name, '- image', img_id, '-', i+1, '/', len(img_samples))
targets = [None] if not targeted else range(10)
for target in targets:
if targeted:
print('Attacking with target', class_names[target])
if target == y_test[img, 0]:
continue
result = attack(img_id, model, target, pixel_count,
maxiter=maxiter, popsize=popsize,
verbose=verbose)
model_results.append(result)
results += model_results
helper.checkpoint(results, targeted)
return results
untargeted = attack_all(models, samples=100, targeted=False)
targeted = attack_all(models, samples=10, targeted=False)
Для проверки возможности дискредитации сети был разработан алгоритм и измерено его влияние на качество прогноза решения по распознаванию образов.
Посмотрим окончательные результаты.
untargeted, targeted = helper.load_results()
columns = ['model', 'pixels', 'image', 'true', 'predicted', 'success', 'cdiff', 'prior_probs', 'predicted_probs', 'perturbation']
untargeted_results = pd.DataFrame(untargeted, columns=columns)
targeted_results = pd.DataFrame(targeted, columns=columns)
В приведенной таблице видно, что используя нейронную сеть ResNet с точностью 0.9231, меняя несколько пикселей изображения, мы получили очень неплохой процент успешно атакованных изображений (attack_success_rate).
helper.attack_stats(targeted_results, models, network_stats)
Out[26]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.144444
1 resnet 0.9231 3 0.211111
2 resnet 0.9231 5 0.222222
helper.attack_stats(untargeted_results, models, network_stats)
Out[27]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.34
1 resnet 0.9231 3 0.79
2 resnet 0.9231 5 0.79
В своих экспериментах вы вольны использовать и другие архитектуры искусственных нейронных сетей, благо их в настоящее время великое множество.
Нейросети окутали современный мир незримыми нитями. Уже давно придуманы сервисы, где используя ИИ (искусственный интеллект), пользователи получают обработанные фото, стилистически похожие на работы кисти великих художников, а сегодня алгоритмы уже умеют сами рисовать картины, создавать музыкальные шедевры, писать книги и даже сценарии к фильмам.
Такие сферы, как компьютерное зрение, распознавание лиц, беспилотные автомобили, диагностика заболеваний — принимают важные решения и не имеют права на ошибку, а вмешательство в работу алгоритмов приведет к катастрофическим последствиям.
One pixel attack – один из способов спуфинг атак. Для проверки возможности дискредитации сети был разработан алгоритм и измерено его влияние на качество прогноза решения по распознаванию образов. Результат показал, что применяющиеся сверточные архитектуры нейросетей уязвимы перед специально обученным алгоритмом One pixel attack, который подменяет один пиксель, с целью дискредитации алгоритма распознавания.
Статью подготовили Александр Андроник и Адрей Черный-Ткач в рамках стажировки в компании Data4.

 файла в 1С-Битрикс")

