
Мы в Наносемантике занимаемся виртуальными ассистентами (чат-ботами и голосовыми помощниками) для компаний с большими колл-центрами. Раньше мы использовали распознавание и синтез речи других компаний, а 1.5 года назад решили, что хотим быть самодостаточным вендором.

Если интересно, зачем нам это, что у нас получилось, а также для чего нам выкладывать ASR & TTS в Open Source – добро пожаловать под кат.
Делать ASR – интересно и сложно, но можно взять готовые Open Source ASR, в частности, наш SOVA ASR и датасеты для него. Ссылки см. в конце статьи.
ASR (распознавание речи) мы используем для голосовых помощников. В основном, это проекты по роботам-консультантам и голосовым помощникам для крупных банков – для снижения нагрузки на колл-центры.
В наших проектах нам иногда приходится использовать решения Яндекса, ЦРТ и других вендоров: если у заказчика уже ASR внедрён, например, в IVR, и закуплен какой-то объём лицензий. В этом случае разработчик голосового робота (мы) сталкивается с довольно сложным процессом настройки бота, поскольку на чужой ASR тяжело повлиять.
NLU (движок анализа текстов) чат-бота всегда получает от ASR текст, который содержит ошибки распознавания, какой бы ASR ни был. Например, какие-то слова могут быть для ASR не знакомы. Не все движки/сервисы ASR позволяют проводить настройку, обучение языковой модели и прочее. Поэтому в NLU приходится закладываться на то, что могут прилететь «приколы» от ASR. Кроме того, качество поставленных в крупные компании годы назад ASR (с бессрочной лицензией) – ужасное.
Поэтому нам хотелось иметь в своём распоряжении собственный ASR. И TTS, аналогично.
Для приготовления ASR нужны два ингридиента – алгоритмы и обучающие данные.
ASR – это целый комплекс алгоритмов обработки сигналов и текстов. Традиционно системы распознавания речи состояли из нескольких компонентов:
Обучающие данные (датасет) – это коллекция пар «аудиозапись + текст». Обычно используются аудио длиной не более 10 секунд. Требуемый объём – несколько тысяч часов аудио минимум для нормального по качеству распознавания.
Эти данные (примеры) «показываются» алгоритму, обучающему акустическую и языковую модели. Механика процесса – классическое машинное обучение.
Мы начали делать свой ASR зимой 2019 года. В начале нашей работы мы рассматривали готовые Open Source наборы инструментов и библиотек, которые можно было бы попробовать пощупать и сравнить между собой. Среди них были как древние системы, которые не использовали нейронные сети – решения, основанные на скрытых марковских моделях (HMM), так и проекты, использующие нейронные сети.
Сейчас уже можно найти end-to-end сети, которые преобразуют входной сигнал в слова, это attention-based сети, рекуррентные нейронные сети, LSTM, полностью сверточные нейронные сети – сразу очень сложно понять, что даст наилучший результат как с точки зрения качества распознавания речи, так и с точки зрения производительности системы и ресурсов, которые будет необходимо заложить на подготовку такой системы.
Среди прочего можно упомянуть наиболее на наш взгляд интересные разработки:
Мы пробовали обучать сети с нуля на одинаковых данных, в том числе для одинаковых архитектур пробовали подавать им на вход различные акустические признаки (окна спектрограмм, мел-кепстральные коэффициенты и т. д.), сравнивали результаты, сравнивали с уже предобученными моделями, хоть на русском языке выбор готовых решений и очень ограничен. Для быстрого старта и возможности проводить сравнения нужны открытые данные, и здесь как раз пригождались аудиокниги, хоть для целевых систем обученные на них модели и не были пригодны. В любом случае, для наилучшего качества нужно собирать датасеты, которые бы максимально отражали суть целевых данных (например, нарезанные голосовые сообщения из Telegram или телефонные звонки), и обучать свои модели, оптимизируя их под конкретику своей задачи (автоматизация колл-центра, управление умным домом, распознавание в навигаторе и др.). Каждая область применения имеет совершенно разные особенности, даёт разный характер данных – и это необходимо учитывать при разработке и подготовке датасетов.
Сразу необходимо заметить, что ни одно из бесплатных или платных решений, существующих на данный момент, не дает 100% точность распознавания. Чего уж там, даже человек иногда не может однозначно понять, что было сказано другим, особенно, если второй человек произносит слова из тематики, с которой первый не знаком. Самый простой пример – вы наверняка слышали, как во время звонка кого-нибудь просят продиктовать фамилию по слогам, а то и по буквам, потому что фамилии достаточно разнообразны, и ни у кого в голове попросту не может находиться полный список всех фамилий и их написаний.
Здесь также можно привести пример про профессиональные термины: когда мы уже начали размечать данные из колл-центров отдела продаж SEO-услуг, мы даже составили для разметчиков небольшой словарь терминов поисковой оптимизации, так как люди просто не знали некоторых слов и поначалу неправильно отекстовывали или просто браковали непонятные им записи. Слова “аудит”, “пагинация”, “сео”, “сниппет”, “фавикон” и так далее – заимствованы из других языков и незнакомы большинству людей.
Добавлю, что даже если вы сможете прочитать по буквам новое незнакомое слово, оно все равно будет вызывать первое время заминку при прочтении, потому что вы его не ожидаете увидеть. Точно так же, если в лексиконе и языковой модели нет каких-то слов или словосочетаний, то система ASR попросту не сможет правильно распознать сказанное, и выдаст что-то близкое по звучанию. Если же кто-то скажет очень тихо и неразборчиво даже знакомое вам слово – вы, скорее всего, переспросите.
Для оценки качества распознавания существуют определенные метрики. Одна из наиболее популярных – WER (Word Error Rate) – мера оценки ошибки на уровне слов. Эта метрика – отношение суммы количества вставок лишних слов, удалений и замен слов к количеству слов в референсе (то есть к ручной отекстовке). По некоторым оценкам, на большом наборе произвольных аудиозаписей с речью даже человек допускает ошибки вплоть до WER = 0.05. Также можно рассматривать метрику CER (или LER, Character Error Rate/Letter Error Rate), которая рассчитывается аналогично, но на уровне букв, и по сути своей является расстоянием по Левенштейну.
Посчитаем метрики качества: на уровне слов имеем «пили» вместо «жили» – замена, исчезло слово «два» – удаление, в конце появилось слово «да» – вставка. На уровне букв: «пили» вместо «жили» – замена буквы «ж» на «п», удаление букв «д», «в», «а» и одного пробельного символа из-за исчезнувшего слова «два», вставка букв «д» и «а» и пробельного символа из-за добавления слова «да» в конце. В оригинале 5 слов и 30 букв (вместе с пробелами), у нас всего 1 замена, 1 удаление и 1 вставка на уровне букв и 1 замена, 4 удаления и 3 вставки на уровне букв. Считаем WER = (1 + 1 + 1) / 5 = 0.6, считаем CER = (1 + 4 + 3) / 30 = 0.27. Пример искусственный и приведен для демонстрации подсчета метрик. Для понимания – чем ближе к нулю показатели WER и CER, тем лучше работает система.
Сейчас даже у всех игроков на рынке систем распознавания речи (Яндекс, Google, ЦРТ, Azure, Tinkoff, Наносемантика) метрика WER держится на одних наших тестовых датасетах не ниже 0.1-0.15, на других данных – не ниже 0.15-0.25, а есть коммерческие системы, которые доходят аж до 0.35-0.5. Это означает, что мы, грубо говоря, в лучшем случае получаем ошибку в каждом седьмом-десятом слове, в системах похуже – в каждом четвертом, а то и втором.
Типы ошибок тоже бывают разные, где-то просто перепуталось окончание, а где-то оказалось совершенно другое слово, полностью меняющее смысл. Так, для дальнейшей подачи распознанного предложения в движок чат-бота гораздо хуже, если пришло сообщение “мама рыла раму”, нежели “мама мыла рама”, поскольку в одном случае просто допущена грамматическая ошибка, а во втором – мы получаем совершенно иное действие. Замеры качества мы проводим на довольно суровых датасетах из телефонии и голосовых сообщениях из Telegram, и они предельно не лабораторные, ниже будет приведена таблица сравнения систем распознавания речи разных вендоров.
Поговорим подробнее про данные, на которых мы алгоритмы ASR учили и тестировали.
Пожалуй, самая важная часть создания технологии распознавания речи — это подготовка данных. Если вы спросите разработчиков, сколько данных нужно для обучения – никто вам не ответит. Данных никогда не бывает слишком много. Нужны тысячи часов, чтобы получить хорошее распознавание. При этом, источники данных нужны именно такие, какие требуются для вашего продукта. Конечно, решения вроде уже упомянутого выше Wav2Vec позволяют значительно уменьшить потребность в аннотированных данных для обучения итоговой системы, но, как показала практика, с ростом количества этих данных качество всё равно растёт, и 10 минут размеченных аудио может и хватит для получения хороших результатов на довольно искусственном корпусе на английском языке, но этого совершенно недостаточно для промышленной системы. Стоит упомянуть, что, когда собираются датасеты – не все данные, которые вы получаете, например, от колл-центров, получится использовать для дообучения модели. Это могут быть какие-то мусорные данные, шумы, когда даже человеку невозможно распознать, что было сказано. Моделям на вход лучше подавать только те данные, в которых вы абсолютно уверены.
Итак, первый датасет, с которым мы начали работать – открытый 46-часовой датасет M-AILABS. Неплохой вариант для начала, содержащий очень чистые отрывки из аудиокниг, на нём мы проводили первые сравнения различных архитектур и фреймворков. Однако, в реальных условиях обученные на нём модели работали из рук вон плохо. Добавление аугментаций лишь немного спасало ситуацию. Также, конечно, стоит упомянуть проект Mozilla Common Voice, данные в котором уже менее лабораторные, и они периодически пополняются. Относительно недавно был опубликован датасет Open STT для русского языка, но перед использованием важно обратить внимание на происхождение данных в этом датасете + ограничения лицензии.
Отмечу, что если у вас есть конкретные алгоритмы на все компоненты ASR и датасет, то совершенно не гарантировано хорошее распознавание на новых целевых данных, сильно отличающихся от тех, на которых вы обучали нейронную сеть. Если вы собрали большое количество аудиокниг, и построили модели на них, то не факт, что ваш ASR будет успешно справляться с телефонными разговорами. Там, помимо сильно искаженного и сжатого сигнала аудио, сплошная живая человеческая речь, содержащая слова-паразиты, мычание, запинания и прочие моменты, которые совершенно не присущи речи профессиональных дикторов.
На подготовку своих собственных датасетов в достаточном для более-менее адекватного распознавания речи (не аудиокниг!) у нас ушло порядка 6 месяцев, и мы продолжаем подготовку данных, именно поэтому в начале для экспериментов мы рекомендуем брать уже готовые датасеты (тем более что сейчас в открытом доступе их стало значительно больше), и на них сравнивать различные решения.
В итоге на открытых датасетах мы сравнили качество, скорость обучения, простоту интерфейсов различных технологий, и остановились на wav2letter в качестве архитектуры для акустической модели системы, которую мы планировали дальше развивать. В дальнейшем мы переписали её архитектуру и код обучения на наш собственный нейросетевой фреймворк – PuzzleLib, стали подключать разные языковые модели, декодеры и прочее. Это заняло у нас несколько месяцев. Пример кода обучения базовой модели на нашем фреймворке можно найти в документации.
Для последующего обучения перед нами стояла задача собрать максимальный объем аудио, однако изначально у нас не было возможности скооперироваться с крупным колл-центром, как это делают другие крупные вендоры, поэтому следующим этапом стал сбор аудиокниг из открытых источников, лицензия которых позволяла использование. Так, мы нарезали и отекстовали аудио фрагментов на 1600+ часов. С книгами дополнительно было проще в плане текстов, они уже были подготовлены, и достаточно было лишь сравнивать после нарезки, что нарезанные кусочки не обрезаны, не содержат лишних призвуков и вообще соответствуют тексту. Сейчас инструменты для такого forced alignment можно без труда найти в интернете на свой вкус.
Чтобы повысить качество распознавания в телефонном тракте, а также повысить качество распознавания при работе с микрофонами конечных пользовательских устройств (смартфонов, ноутбуков и тд), мы в ходе обучения случайным образом добавляли различные аугментации, такие как вставка шумов окружения, добавление эффекта реверберации в аудио (имитация отражений звука от поверхностей), эквализация (в телефонных записях задраны средние частоты), замедление, ускорение, изменение высоты тона и многие другие.
Качество распознавания выросло, но из-за того, что сама речь в аудиокнигах записывалась в “лабораторных” условиях, модель, которую мы обучили на них, плохо себя показывала на живых разговорах. То есть дикторы в аудиокнигах зачитывали произвольные тексты, но обычные люди в жизни так не говорят. Также ошибочным шагом будет сбор данных, которые “начитывают” по листу, пусть даже непрофессиональные дикторы, пусть даже это записи из телефонного канала. Стало понятно, что нужно учиться самим добывать, нарезать и размечать данные (та же телефония и т. д.). Мы начали с внутренней телефонии компании, начали переговоры с потенциальными партнёрами, заинтересованными в автоматизации колл-центров. Абсолютно непригодна для сбора качественнго датасета Яндекс.Толока: добиться качественной работы с разметчиками Толоки не получится, нужна плотная работа с разметчиками.
Поэтому мы также начали разработку своего инструмента для разметки аудиозаписей – Маркера. Так у нас появился свой отдел разметки и качественный сервис, генерирующий нам датасеты.
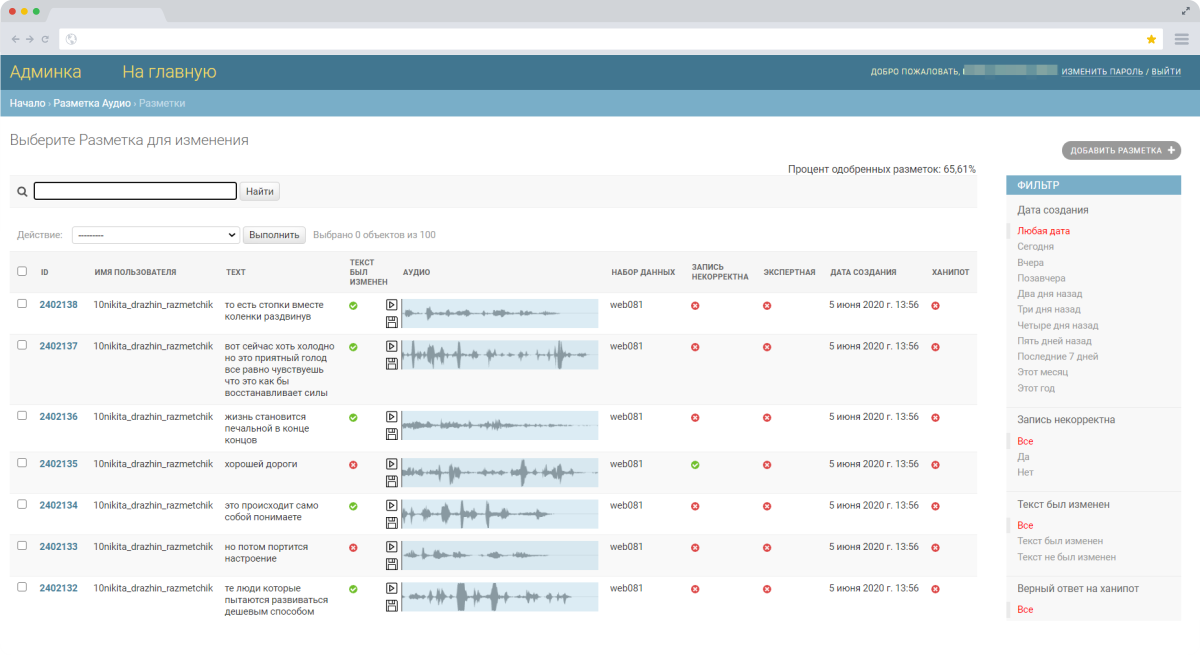
Разметчики, которые отекстовывают аудио, могут допускать ошибки. Это все нужно валидировать, контролировать, организовывать коллективные проверки одного и того же аудио, и т. д. В Маркере есть механика распределения заданий по людям так, чтобы каждая запись попадала к несколькими специалистам, а потом – к эксперту в случае разрозненных мнений. Мы это называем “экспертной оценкой”. Еще в работе с разметчиками мы применяем логику honeypots. Её смысл заключается в том, что мы даем человеку 100 заданий на разметку, при этом, на самом деле, из этих ста заданий мы и так знаем правильный ответ на 10 заданий. И если человек путается даже в этих десяти заданиях, то мы принимаем решение что, вероятно, либо человек ленится, либо просто он неопытный, и стоит с ним еще провести тренинг. Разметчиков у нас сейчас порядка 100 человек, мы с ними постоянно ведем работу, учим их, разбираем ошибки, ввели рейтинговую систему, систему экспертов – это в итоге позволяет получать очень хорошее качество (менее 3% WER).
Параллельно со сбором данных к августу 2019 года у нас сформировалось понимание того, что делать с этими данными, автоматизировались процессы передачи данных в обучение, тестирования.
Поняв, что у нас большие проблемы с реальными данными, с аудиокниг мы переключились на альтернативные способы сбора данных. Так мы разработали свою систему для сбора аудио. Человек зачитывает то, что написано на экране, это сохраняется и попадает к нам. Таким образом у нас накопилась база в 1700+ часов. Большим плюсом такого подхода было то, что люди зачитывали текст с абсолютно разных устройств и микрофонов соответственно. Как уже было упомянуто, большой минус здесь – люди читают текст, а не общаются вживую. Однако, суммарно всех собранных на тот момент данных хватило, чтобы подготовить неплохой демонстрационный стенд, с которым уже, во-первых, не стыдно было ходить к потенциальным партнёрам из колл-центров, во вторых, предлагать бесплатно пользоваться распознаванием в обмен на данные, которые через этот стенд проходят и далее используются для обучения моделей.
Что касается разработки, как мы уже упомянули, мы перенесли всю архитектуру wav2letter на свой фреймворк PuzzleLib. Изначально весь пайплайн не отличался высоким качеством распознавания фраз, поскольку мы использовали Greedy Decoder. Далее, разобравшись с подключением языковых моделей, мы реализовали Beam Search. В итоге мы пришли к выводу, что самое лучшее качество можно достигнуть с помощью CTC (Connectionist Temporal Classification) Decoder. На нем и остановились, часть кода для него позаимствована из оригинального репозитория wav2letter++, написана на C++ и подключается при помощи Python-обвязки.
Существенно ускорило подготовку моделей появление компьютеров с несколькими GPU. Мы распараллелили код для обучения на нескольких видеокартах и смогли запускать обучение и быстро что-то сравнивать, проводить эксперименты. Например, мы сравнивали модели, работающие с разными признаками: спектрограммами, MF фичами, MFCC фичами. В итоге мы остановились на спектрограммах, потому что при одинаковых условиях мы могли получить модель с лучшим качеством за фиксированное количество эпох.
Мы поддержали обучение с данными в формате float16, что уменьшило расход памяти и увеличило скорость обучения. Если в двух словах, можно обучать на стандартных тензорах, в которых типы данных float32, а можно обучать на float16 — это числа с половинной точностью. Если всё правильно настроить, то, в целом, без сильной потери точности, можно уменьшить расход памяти в два раза. И, соответственно, можно увеличить размер батча и занять больше места на видеокарте. Все это приводит к ускорению обучения.
В октябре 2019 года мы собрали первую версию собственного демонстрационного стенда с REST API, который мы уже могли показывать партнёрам и подключать для бесплатного пользования. Помимо прочего, наше API подключили к телеграм-боту @voicybot, наряду с распознаванием от Google и Wit.ai, за что отдельное спасибо Никите Колмогорову. Бот позволяет распознавать голосовые сообщения и продолжает работать с нашим публичным API.
Получив ядро, которое может переводить аудио в текст, мы начали добавлять в него различные косметические и функциональные улучшения. Во-первых, мы реализовали потоковое распознавание, изначально на web-сокетах, а затем занялись поддержкой протоколов gRPC и MRCP, поскольку на них был спрос у партнёров. В потоковом распознавании нужно учитывать, что использовать декодер с языковой моделью нужно по оконченным фразам, поэтому возникает потребность в определении тишины для выделения реплик, после которых наступают паузы. Для определения кусков с тишиной и голосом при потоковом распознавании мы используем Voice Activity Detector. Тут мы решили взять готовое решение WebRTC VAD. Наши внутренние тесты альтернативных решений подтвердили, что даже на наименее чувствительном уровне WebRTC VAD показывает лучшие результаты с определением кусков аудио, содержащих голос, как по точности, так и по полноте.
Есть несколько подходов по работе с потоковым распознаванием, можно либо после нарезки VAD прогонять собранные окна спектрограмм через акустическую модель, извлеченные из кусков аудио с речью, либо прогонять их постоянно небольшими батчами и выдавать результаты промежуточного распознавания (с жадным декодером), а по наступлению паузы прогонять всю фразу через CTC декодер и языковую модель. На выходе из акустической модели мы получаем набор наиболее вероятных с фонемной точки зрения кандидатов текста того, что было сказано, и дальше декодер при помощи заранее подготовленной языковой модели определяет, какие варианты наиболее вероятны из того, что было предсказано.
Языковая модель у нас в данный момент строится при помощи KenLM. Для её подготовки нужно собрать большой корпус разговорных неразмеченных текстов (гигабайты текстов): по предложению на строку в одном большом текстовом файле. Учимся мы на десятках гигабайтов текстов. В такой корпус мы подмешивали те данные, которые у нас были размечены из реальных аудио. В итоге получили достаточно неплохие результаты, однако здесь надо понимать, что данные надо также валидировать и очищать от различного мусора. Хороший буст качества для конкретного заказчика можно получить просто расширив языковую модель под его тематику.
Дальше к получаемым от ASR текстам мы применяем различные варианты улучшения внешнего вида. Например, мы обучили BERT восстанавливать пунктуацию. Он расставляет запятые, точки, вопросительные знаки просто по текстовому представлению. Также мы добавили перевод чисел, представленных словами, в цифры по словарю. В планах добавить аббревиатуры, зарубежные названия, имена, названия городов и компаний.
Вот к таким результатам нам удалось прийти на сегодняшний день:
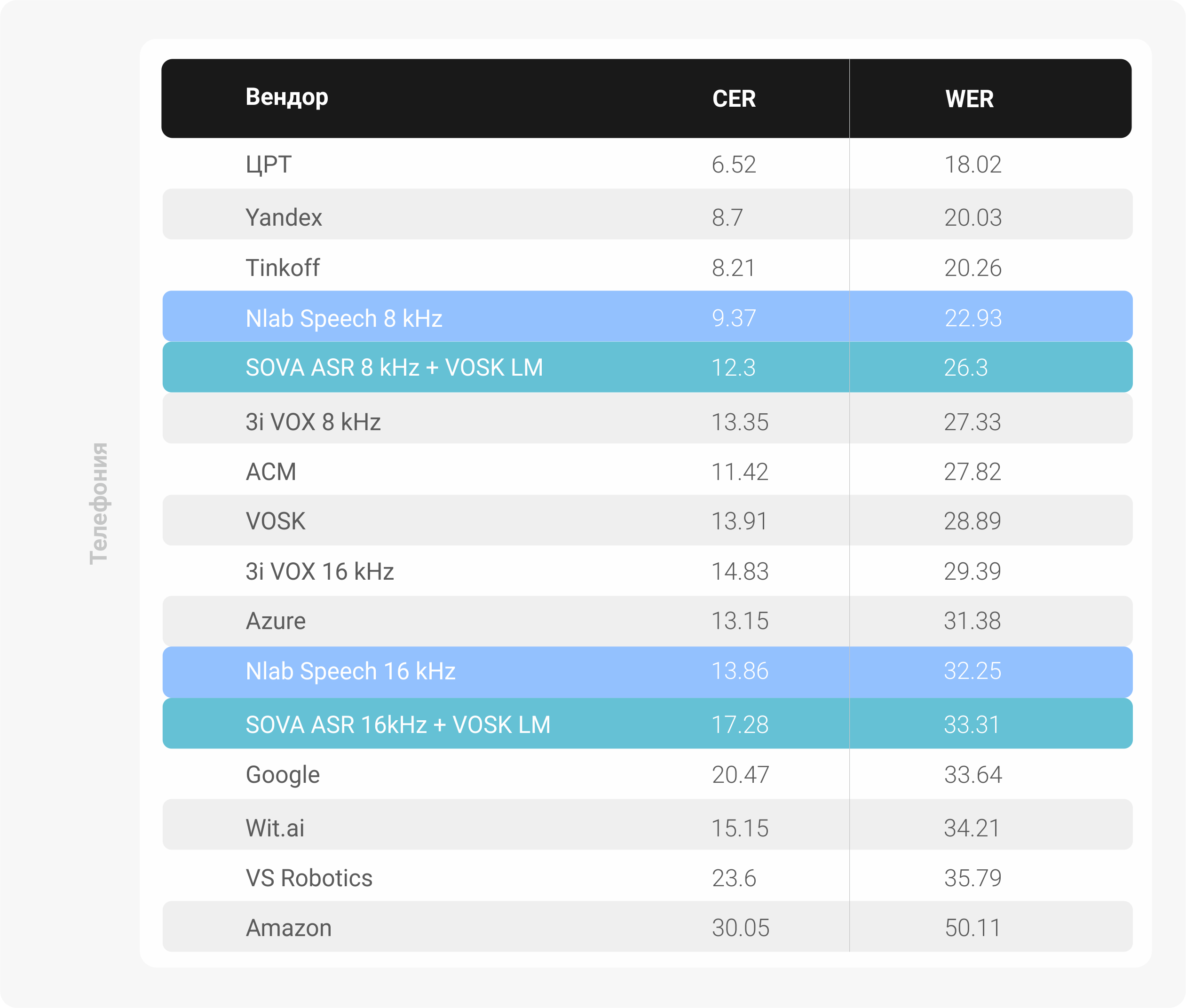
Пример аудио тестового датасета из колл-центра компании-партнёра:
Из тестового датасета голосовых сообщений, записанных с микрофонов различных пользовательских устройств:
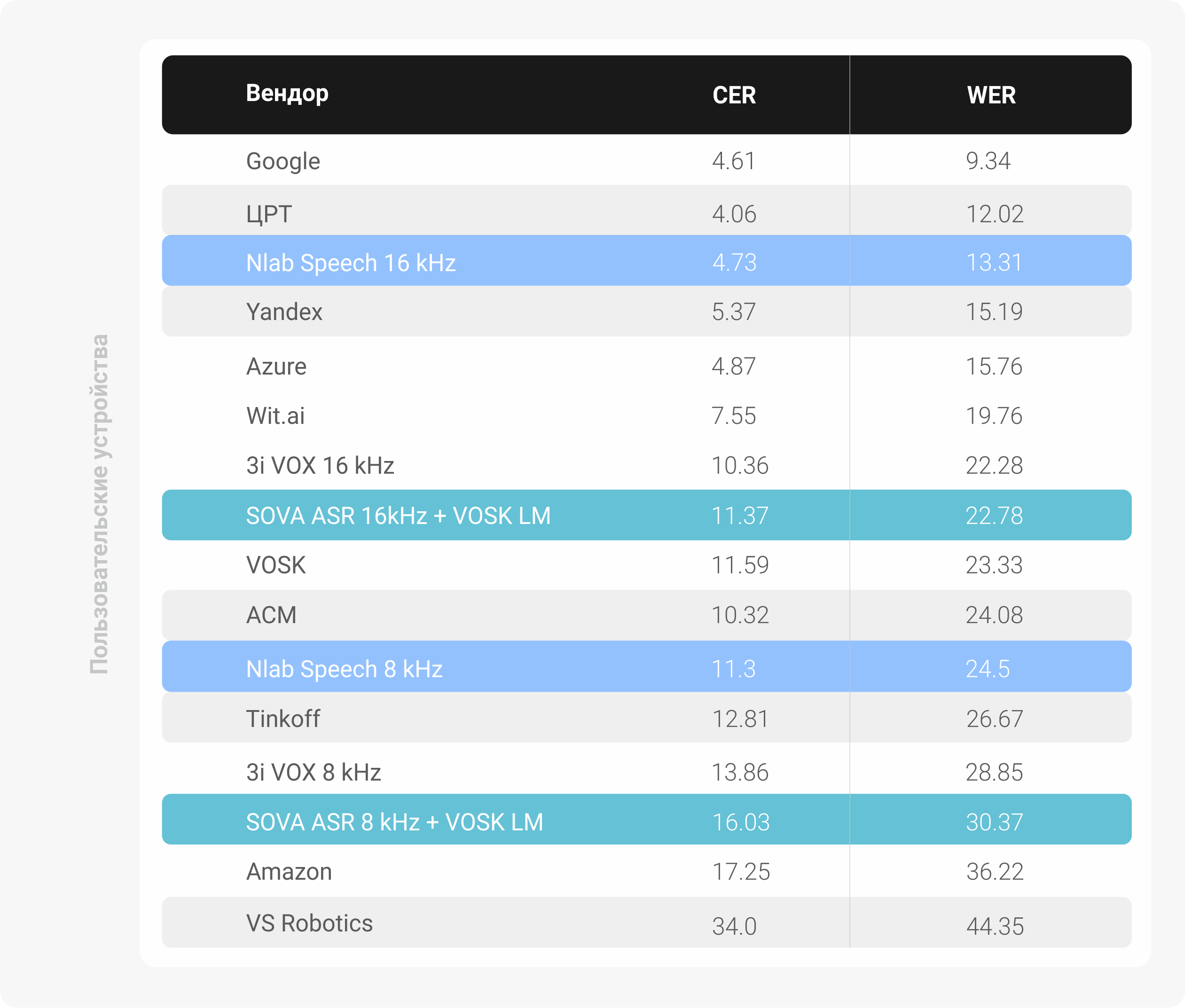
Здесь сразу нужно вставить несколько ремарок: в наших тестовых датасетах представлены данные, на которых мы гарантированно не обучали ни одну из наших моделей, оба датасета состоят из 500 моноканальных записей каждый в 8 кГц и 16 кГц для телефонии и микрофонов пользовательских устройств, все аудио длиной от 1.8 секунд до 6 секунд. Длина аудио в тестовых датасетах такая, потому что мы резали аудио записи по тишине, которая наступает между репликами в разговоре, либо в монологе.
Наши модели отмечены в бенчмарке цветом. NLab Speech – наше проприетарное решение и SOVA ASR – наше Open Source решение. Одно из ключевых решений, принятых нами – разделение на две независимые модели, одна из которых работает с телефонными данными и обучается на записях из колл-центров, а вторая – модель для работы с микрофонами пользовательских устройств, таких как смартфоны, ноутбуки и т. д. Это позволило получить качественный скачок в обоих направлениях.
Мы недавно выложили в открытый доступ наш движок распознавания речи, который построен на архитектуре wav2letter, в бенчмарках он обозначен как SOVA ASR, в нём также есть две раздельные акустические модели для 8 кГц и работы с телефонными звонками и 16 кГц для работы с микрофонами пользовательских устройств, которые можно использовать в зависимости от ваших потребностей. Для корректности сравнения с VOSK (тоже открытое распознавание речи от Николая Шмырёва) мы использовали языковую модель из релиза VOSK API для русского языка версии 0.10 (лишь превратив .arpa файл языковой модели в бинарник и собрав по этому файлу его лексикон). Вы также можете сами построить собственную языковую модель, которая будет совместима с SOVA ASR, просто воспользовавшись тулкитом KenLM и заготовив большой корпус текстов.
Говоря о производительности решений, не очень корректно сравнивать между собой различные API, так как решения расположены на разных хостах, и узким местом может оказаться передача файлов, но с VOSK мы провели сравнение, так как решение было у нас развёрнуто локально на виртуальной машине с процессором Intel® Xeon® Platinum 8259CL CPU @ 2.50GHz. В качестве показателя скорости мы взяли отношение среднего времени распознавания (при уже инициализированных моделях) к общей длине распознаваемых файлов, и получили следующие результаты:
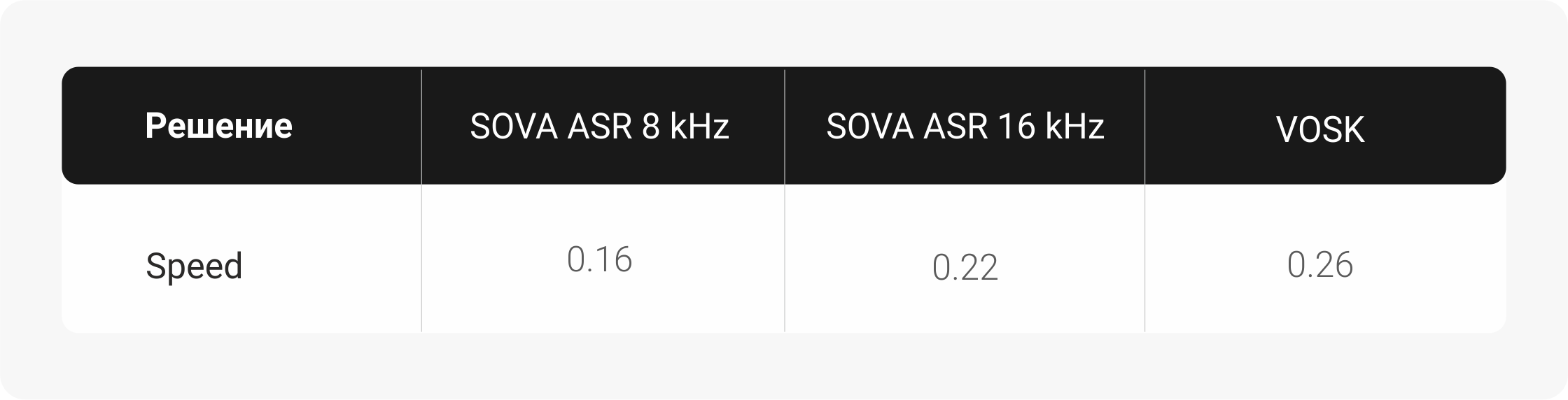
По расходу оперативной памяти SOVA ASR потребляет в пределах 2 GB RAM (как и VOSK, при использовании той же языковой модели), и может работать как на CPU, так и на GPU. GPU позволяет экономить ресурсы процессора и обеспечивать большее количество одновременных потоков при расходе ресурсов процессора с экономией до 10 раз.
Итак, что же необходимо учесть при создании собственного распознавания речи?
Сначала нужно подготовить инструменты для сбора и обработки данных, получить датасеты из нарезанных аудио с отекстовками. Данные нужны конкретного вида (если это колл-центр, то нужны записи звонков). Максимально автоматизировать сбор данных.
Выбрать акустические признаки и свою архитектуру нейронных сетей для их перевода в текстовые представления. Обучить акустическую модель. Максимально оптимизировать обучение акустической модели, так как это самая трудоёмкая по времени часть. Повышать качество акустической модели можно также при помощи добавления всевозможных аугментаций.
Собрать текстовый корпус по интересующей нас тематике и построить на нём языковую модель, реализовать учёт данных о частотности в декодере, обрабатывающем выходы акустической модели. Итоговое качество сильно будет зависеть от языковой модели, так как чтобы правильно распознавать слова, нужно знать об их существовании, их написании и контекстной встречаемости (в противном случае система будет пытаться предложить что-то созвучное, про что она знает, вместо правильного варианта). Надо разделять предложения по тишине и производить декодинг отдельных частей (иначе языковая модель может внести артефакты, попытавшись объединить подряд идущие предложения в связное одно).
Улучшать внешний вид и кастомизировать текстовые результаты под конкретные запросы, будь то восстановление пунктуации, либо перевод зарубежных названий в латиницу по словарю.
В ближайшем будущем мы планируем продолжать эксперименты с языковыми моделями. Многообещающим выглядит новый проект Smart Language Model. Также мы планируем расширять обучающий корпус, добавляя преимущественно живую разговорную речь.
Кроме того, мы улучшаем потоковое распознавание и занимаемся оптимизацией и балансировкой нагрузки.
Периодически приходят запросы по диаризации (разделению моно на 2 канала) аудио, существующие Open Source решения нас не устраивают по качеству, и тут тоже есть пространство для экспериментов.
Также хочется отметить, что не стоит останавливаться на одной технологии, если у вас получилось что-то с ней сходу достичь, но дальше у вас происходит застой. Так, мы отошли от акустической модели wav2letter, которая обучается на аннотированных данных, и перешли к обучению на неразмеченных данных (подход wav2vec), что дало хороший прирост качества.
Упомянутая в статье SOVA ASR – часть более крупного Open Source проекта SOVA.ai: мы делаем открытую платформу для создания голосовых помощников. Нас поддержал государственный фонд РВК. Государство в принципе поддерживает Open Source проекты, в том числе, в рамках Федерального проекта «Искусственный интеллект».
Данные и софт распостраняются под свободной лицензией Apache 2.0 (можно использовать для коммерческих целей).
Наши наработки доступны тут: наш GitHub
Распознавание речи: SOVA ASR
Датасет для распознавания речи: SOVA Dataset
Синтез речи: SOVA TTS
В течение месяца мы выложим больше данных, а в ноябре будут интересные релизы наших новых утилит.
Если то, что мы делаем, вам интересно – пишите, можем посотрудничать. Как на коммерческих проектах, так и в Open Source.
Спасибо за внимание!
Если интересно, зачем нам это, что у нас получилось, а также для чего нам выкладывать ASR & TTS в Open Source – добро пожаловать под кат.
TL;DR
Делать ASR – интересно и сложно, но можно взять готовые Open Source ASR, в частности, наш SOVA ASR и датасеты для него. Ссылки см. в конце статьи.
Зачем нам нужен свой ASR
ASR (распознавание речи) мы используем для голосовых помощников. В основном, это проекты по роботам-консультантам и голосовым помощникам для крупных банков – для снижения нагрузки на колл-центры.
В наших проектах нам иногда приходится использовать решения Яндекса, ЦРТ и других вендоров: если у заказчика уже ASR внедрён, например, в IVR, и закуплен какой-то объём лицензий. В этом случае разработчик голосового робота (мы) сталкивается с довольно сложным процессом настройки бота, поскольку на чужой ASR тяжело повлиять.
NLU (движок анализа текстов) чат-бота всегда получает от ASR текст, который содержит ошибки распознавания, какой бы ASR ни был. Например, какие-то слова могут быть для ASR не знакомы. Не все движки/сервисы ASR позволяют проводить настройку, обучение языковой модели и прочее. Поэтому в NLU приходится закладываться на то, что могут прилететь «приколы» от ASR. Кроме того, качество поставленных в крупные компании годы назад ASR (с бессрочной лицензией) – ужасное.
Поэтому нам хотелось иметь в своём распоряжении собственный ASR. И TTS, аналогично.
Из чего состоит система распознавания речи?
Для приготовления ASR нужны два ингридиента – алгоритмы и обучающие данные.
ASR – это целый комплекс алгоритмов обработки сигналов и текстов. Традиционно системы распознавания речи состояли из нескольких компонентов:
- акустическая модель, которая переводит сегменты звука (например, 20-ти миллисекундные кадры спектрограмм) в фонемы,
- модель произношения, соединяющая фонемы вместе для формирования слов,
- языковая модель, выражающая вероятности построенных фраз на основе частотных характеристик совместной встречаемости слов в том или ином корпусе речи.
Обучающие данные (датасет) – это коллекция пар «аудиозапись + текст». Обычно используются аудио длиной не более 10 секунд. Требуемый объём – несколько тысяч часов аудио минимум для нормального по качеству распознавания.
Эти данные (примеры) «показываются» алгоритму, обучающему акустическую и языковую модели. Механика процесса – классическое машинное обучение.
С чего мы начинали
Мы начали делать свой ASR зимой 2019 года. В начале нашей работы мы рассматривали готовые Open Source наборы инструментов и библиотек, которые можно было бы попробовать пощупать и сравнить между собой. Среди них были как древние системы, которые не использовали нейронные сети – решения, основанные на скрытых марковских моделях (HMM), так и проекты, использующие нейронные сети.
Сейчас уже можно найти end-to-end сети, которые преобразуют входной сигнал в слова, это attention-based сети, рекуррентные нейронные сети, LSTM, полностью сверточные нейронные сети – сразу очень сложно понять, что даст наилучший результат как с точки зрения качества распознавания речи, так и с точки зрения производительности системы и ресурсов, которые будет необходимо заложить на подготовку такой системы.
Среди прочего можно упомянуть наиболее на наш взгляд интересные разработки:
- Kaldi
- Wav2Letter++ от Facebook
- Jasper
- Wav2Vec
- ESPNet
- DeepSpeech 2 от Mozilla
- Listen-Attend-Spell
Мы пробовали обучать сети с нуля на одинаковых данных, в том числе для одинаковых архитектур пробовали подавать им на вход различные акустические признаки (окна спектрограмм, мел-кепстральные коэффициенты и т. д.), сравнивали результаты, сравнивали с уже предобученными моделями, хоть на русском языке выбор готовых решений и очень ограничен. Для быстрого старта и возможности проводить сравнения нужны открытые данные, и здесь как раз пригождались аудиокниги, хоть для целевых систем обученные на них модели и не были пригодны. В любом случае, для наилучшего качества нужно собирать датасеты, которые бы максимально отражали суть целевых данных (например, нарезанные голосовые сообщения из Telegram или телефонные звонки), и обучать свои модели, оптимизируя их под конкретику своей задачи (автоматизация колл-центра, управление умным домом, распознавание в навигаторе и др.). Каждая область применения имеет совершенно разные особенности, даёт разный характер данных – и это необходимо учитывать при разработке и подготовке датасетов.
Метрики качества
Сразу необходимо заметить, что ни одно из бесплатных или платных решений, существующих на данный момент, не дает 100% точность распознавания. Чего уж там, даже человек иногда не может однозначно понять, что было сказано другим, особенно, если второй человек произносит слова из тематики, с которой первый не знаком. Самый простой пример – вы наверняка слышали, как во время звонка кого-нибудь просят продиктовать фамилию по слогам, а то и по буквам, потому что фамилии достаточно разнообразны, и ни у кого в голове попросту не может находиться полный список всех фамилий и их написаний.
Здесь также можно привести пример про профессиональные термины: когда мы уже начали размечать данные из колл-центров отдела продаж SEO-услуг, мы даже составили для разметчиков небольшой словарь терминов поисковой оптимизации, так как люди просто не знали некоторых слов и поначалу неправильно отекстовывали или просто браковали непонятные им записи. Слова “аудит”, “пагинация”, “сео”, “сниппет”, “фавикон” и так далее – заимствованы из других языков и незнакомы большинству людей.
Добавлю, что даже если вы сможете прочитать по буквам новое незнакомое слово, оно все равно будет вызывать первое время заминку при прочтении, потому что вы его не ожидаете увидеть. Точно так же, если в лексиконе и языковой модели нет каких-то слов или словосочетаний, то система ASR попросту не сможет правильно распознать сказанное, и выдаст что-то близкое по звучанию. Если же кто-то скажет очень тихо и неразборчиво даже знакомое вам слово – вы, скорее всего, переспросите.
Для оценки качества распознавания существуют определенные метрики. Одна из наиболее популярных – WER (Word Error Rate) – мера оценки ошибки на уровне слов. Эта метрика – отношение суммы количества вставок лишних слов, удалений и замен слов к количеству слов в референсе (то есть к ручной отекстовке). По некоторым оценкам, на большом наборе произвольных аудиозаписей с речью даже человек допускает ошибки вплоть до WER = 0.05. Также можно рассматривать метрику CER (или LER, Character Error Rate/Letter Error Rate), которая рассчитывается аналогично, но на уровне букв, и по сути своей является расстоянием по Левенштейну.
Пример:
Оригинальная фраза: «жили у бабуси два весёлых гуся»
Предсказание: «пили у бабуси весёлых гуся да»
Посчитаем метрики качества: на уровне слов имеем «пили» вместо «жили» – замена, исчезло слово «два» – удаление, в конце появилось слово «да» – вставка. На уровне букв: «пили» вместо «жили» – замена буквы «ж» на «п», удаление букв «д», «в», «а» и одного пробельного символа из-за исчезнувшего слова «два», вставка букв «д» и «а» и пробельного символа из-за добавления слова «да» в конце. В оригинале 5 слов и 30 букв (вместе с пробелами), у нас всего 1 замена, 1 удаление и 1 вставка на уровне букв и 1 замена, 4 удаления и 3 вставки на уровне букв. Считаем WER = (1 + 1 + 1) / 5 = 0.6, считаем CER = (1 + 4 + 3) / 30 = 0.27. Пример искусственный и приведен для демонстрации подсчета метрик. Для понимания – чем ближе к нулю показатели WER и CER, тем лучше работает система.
Сейчас даже у всех игроков на рынке систем распознавания речи (Яндекс, Google, ЦРТ, Azure, Tinkoff, Наносемантика) метрика WER держится на одних наших тестовых датасетах не ниже 0.1-0.15, на других данных – не ниже 0.15-0.25, а есть коммерческие системы, которые доходят аж до 0.35-0.5. Это означает, что мы, грубо говоря, в лучшем случае получаем ошибку в каждом седьмом-десятом слове, в системах похуже – в каждом четвертом, а то и втором.
Типы ошибок тоже бывают разные, где-то просто перепуталось окончание, а где-то оказалось совершенно другое слово, полностью меняющее смысл. Так, для дальнейшей подачи распознанного предложения в движок чат-бота гораздо хуже, если пришло сообщение “мама рыла раму”, нежели “мама мыла рама”, поскольку в одном случае просто допущена грамматическая ошибка, а во втором – мы получаем совершенно иное действие. Замеры качества мы проводим на довольно суровых датасетах из телефонии и голосовых сообщениях из Telegram, и они предельно не лабораторные, ниже будет приведена таблица сравнения систем распознавания речи разных вендоров.
Поговорим подробнее про данные, на которых мы алгоритмы ASR учили и тестировали.
Сбор и разметка данных
Пожалуй, самая важная часть создания технологии распознавания речи — это подготовка данных. Если вы спросите разработчиков, сколько данных нужно для обучения – никто вам не ответит. Данных никогда не бывает слишком много. Нужны тысячи часов, чтобы получить хорошее распознавание. При этом, источники данных нужны именно такие, какие требуются для вашего продукта. Конечно, решения вроде уже упомянутого выше Wav2Vec позволяют значительно уменьшить потребность в аннотированных данных для обучения итоговой системы, но, как показала практика, с ростом количества этих данных качество всё равно растёт, и 10 минут размеченных аудио может и хватит для получения хороших результатов на довольно искусственном корпусе на английском языке, но этого совершенно недостаточно для промышленной системы. Стоит упомянуть, что, когда собираются датасеты – не все данные, которые вы получаете, например, от колл-центров, получится использовать для дообучения модели. Это могут быть какие-то мусорные данные, шумы, когда даже человеку невозможно распознать, что было сказано. Моделям на вход лучше подавать только те данные, в которых вы абсолютно уверены.
Итак, первый датасет, с которым мы начали работать – открытый 46-часовой датасет M-AILABS. Неплохой вариант для начала, содержащий очень чистые отрывки из аудиокниг, на нём мы проводили первые сравнения различных архитектур и фреймворков. Однако, в реальных условиях обученные на нём модели работали из рук вон плохо. Добавление аугментаций лишь немного спасало ситуацию. Также, конечно, стоит упомянуть проект Mozilla Common Voice, данные в котором уже менее лабораторные, и они периодически пополняются. Относительно недавно был опубликован датасет Open STT для русского языка, но перед использованием важно обратить внимание на происхождение данных в этом датасете + ограничения лицензии.
Отмечу, что если у вас есть конкретные алгоритмы на все компоненты ASR и датасет, то совершенно не гарантировано хорошее распознавание на новых целевых данных, сильно отличающихся от тех, на которых вы обучали нейронную сеть. Если вы собрали большое количество аудиокниг, и построили модели на них, то не факт, что ваш ASR будет успешно справляться с телефонными разговорами. Там, помимо сильно искаженного и сжатого сигнала аудио, сплошная живая человеческая речь, содержащая слова-паразиты, мычание, запинания и прочие моменты, которые совершенно не присущи речи профессиональных дикторов.
На подготовку своих собственных датасетов в достаточном для более-менее адекватного распознавания речи (не аудиокниг!) у нас ушло порядка 6 месяцев, и мы продолжаем подготовку данных, именно поэтому в начале для экспериментов мы рекомендуем брать уже готовые датасеты (тем более что сейчас в открытом доступе их стало значительно больше), и на них сравнивать различные решения.
В итоге на открытых датасетах мы сравнили качество, скорость обучения, простоту интерфейсов различных технологий, и остановились на wav2letter в качестве архитектуры для акустической модели системы, которую мы планировали дальше развивать. В дальнейшем мы переписали её архитектуру и код обучения на наш собственный нейросетевой фреймворк – PuzzleLib, стали подключать разные языковые модели, декодеры и прочее. Это заняло у нас несколько месяцев. Пример кода обучения базовой модели на нашем фреймворке можно найти в документации.
Новость. Недавно мы выложили свою нейросетевую библиотеку в Open Source. Всем, кому интересно пощупать, вот Github, а вот документация.
Для последующего обучения перед нами стояла задача собрать максимальный объем аудио, однако изначально у нас не было возможности скооперироваться с крупным колл-центром, как это делают другие крупные вендоры, поэтому следующим этапом стал сбор аудиокниг из открытых источников, лицензия которых позволяла использование. Так, мы нарезали и отекстовали аудио фрагментов на 1600+ часов. С книгами дополнительно было проще в плане текстов, они уже были подготовлены, и достаточно было лишь сравнивать после нарезки, что нарезанные кусочки не обрезаны, не содержат лишних призвуков и вообще соответствуют тексту. Сейчас инструменты для такого forced alignment можно без труда найти в интернете на свой вкус.
Чтобы повысить качество распознавания в телефонном тракте, а также повысить качество распознавания при работе с микрофонами конечных пользовательских устройств (смартфонов, ноутбуков и тд), мы в ходе обучения случайным образом добавляли различные аугментации, такие как вставка шумов окружения, добавление эффекта реверберации в аудио (имитация отражений звука от поверхностей), эквализация (в телефонных записях задраны средние частоты), замедление, ускорение, изменение высоты тона и многие другие.
Качество распознавания выросло, но из-за того, что сама речь в аудиокнигах записывалась в “лабораторных” условиях, модель, которую мы обучили на них, плохо себя показывала на живых разговорах. То есть дикторы в аудиокнигах зачитывали произвольные тексты, но обычные люди в жизни так не говорят. Также ошибочным шагом будет сбор данных, которые “начитывают” по листу, пусть даже непрофессиональные дикторы, пусть даже это записи из телефонного канала. Стало понятно, что нужно учиться самим добывать, нарезать и размечать данные (та же телефония и т. д.). Мы начали с внутренней телефонии компании, начали переговоры с потенциальными партнёрами, заинтересованными в автоматизации колл-центров. Абсолютно непригодна для сбора качественнго датасета Яндекс.Толока: добиться качественной работы с разметчиками Толоки не получится, нужна плотная работа с разметчиками.
Поэтому мы также начали разработку своего инструмента для разметки аудиозаписей – Маркера. Так у нас появился свой отдел разметки и качественный сервис, генерирующий нам датасеты.
Разметчики, которые отекстовывают аудио, могут допускать ошибки. Это все нужно валидировать, контролировать, организовывать коллективные проверки одного и того же аудио, и т. д. В Маркере есть механика распределения заданий по людям так, чтобы каждая запись попадала к несколькими специалистам, а потом – к эксперту в случае разрозненных мнений. Мы это называем “экспертной оценкой”. Еще в работе с разметчиками мы применяем логику honeypots. Её смысл заключается в том, что мы даем человеку 100 заданий на разметку, при этом, на самом деле, из этих ста заданий мы и так знаем правильный ответ на 10 заданий. И если человек путается даже в этих десяти заданиях, то мы принимаем решение что, вероятно, либо человек ленится, либо просто он неопытный, и стоит с ним еще провести тренинг. Разметчиков у нас сейчас порядка 100 человек, мы с ними постоянно ведем работу, учим их, разбираем ошибки, ввели рейтинговую систему, систему экспертов – это в итоге позволяет получать очень хорошее качество (менее 3% WER).
Параллельно со сбором данных к августу 2019 года у нас сформировалось понимание того, что делать с этими данными, автоматизировались процессы передачи данных в обучение, тестирования.
Сложности, которые мы преодолели
Поняв, что у нас большие проблемы с реальными данными, с аудиокниг мы переключились на альтернативные способы сбора данных. Так мы разработали свою систему для сбора аудио. Человек зачитывает то, что написано на экране, это сохраняется и попадает к нам. Таким образом у нас накопилась база в 1700+ часов. Большим плюсом такого подхода было то, что люди зачитывали текст с абсолютно разных устройств и микрофонов соответственно. Как уже было упомянуто, большой минус здесь – люди читают текст, а не общаются вживую. Однако, суммарно всех собранных на тот момент данных хватило, чтобы подготовить неплохой демонстрационный стенд, с которым уже, во-первых, не стыдно было ходить к потенциальным партнёрам из колл-центров, во вторых, предлагать бесплатно пользоваться распознаванием в обмен на данные, которые через этот стенд проходят и далее используются для обучения моделей.
Что касается разработки, как мы уже упомянули, мы перенесли всю архитектуру wav2letter на свой фреймворк PuzzleLib. Изначально весь пайплайн не отличался высоким качеством распознавания фраз, поскольку мы использовали Greedy Decoder. Далее, разобравшись с подключением языковых моделей, мы реализовали Beam Search. В итоге мы пришли к выводу, что самое лучшее качество можно достигнуть с помощью CTC (Connectionist Temporal Classification) Decoder. На нем и остановились, часть кода для него позаимствована из оригинального репозитория wav2letter++, написана на C++ и подключается при помощи Python-обвязки.
Существенно ускорило подготовку моделей появление компьютеров с несколькими GPU. Мы распараллелили код для обучения на нескольких видеокартах и смогли запускать обучение и быстро что-то сравнивать, проводить эксперименты. Например, мы сравнивали модели, работающие с разными признаками: спектрограммами, MF фичами, MFCC фичами. В итоге мы остановились на спектрограммах, потому что при одинаковых условиях мы могли получить модель с лучшим качеством за фиксированное количество эпох.
Мы поддержали обучение с данными в формате float16, что уменьшило расход памяти и увеличило скорость обучения. Если в двух словах, можно обучать на стандартных тензорах, в которых типы данных float32, а можно обучать на float16 — это числа с половинной точностью. Если всё правильно настроить, то, в целом, без сильной потери точности, можно уменьшить расход памяти в два раза. И, соответственно, можно увеличить размер батча и занять больше места на видеокарте. Все это приводит к ускорению обучения.
В октябре 2019 года мы собрали первую версию собственного демонстрационного стенда с REST API, который мы уже могли показывать партнёрам и подключать для бесплатного пользования. Помимо прочего, наше API подключили к телеграм-боту @voicybot, наряду с распознаванием от Google и Wit.ai, за что отдельное спасибо Никите Колмогорову. Бот позволяет распознавать голосовые сообщения и продолжает работать с нашим публичным API.
Как устроена NLab Speech
Получив ядро, которое может переводить аудио в текст, мы начали добавлять в него различные косметические и функциональные улучшения. Во-первых, мы реализовали потоковое распознавание, изначально на web-сокетах, а затем занялись поддержкой протоколов gRPC и MRCP, поскольку на них был спрос у партнёров. В потоковом распознавании нужно учитывать, что использовать декодер с языковой моделью нужно по оконченным фразам, поэтому возникает потребность в определении тишины для выделения реплик, после которых наступают паузы. Для определения кусков с тишиной и голосом при потоковом распознавании мы используем Voice Activity Detector. Тут мы решили взять готовое решение WebRTC VAD. Наши внутренние тесты альтернативных решений подтвердили, что даже на наименее чувствительном уровне WebRTC VAD показывает лучшие результаты с определением кусков аудио, содержащих голос, как по точности, так и по полноте.
Есть несколько подходов по работе с потоковым распознаванием, можно либо после нарезки VAD прогонять собранные окна спектрограмм через акустическую модель, извлеченные из кусков аудио с речью, либо прогонять их постоянно небольшими батчами и выдавать результаты промежуточного распознавания (с жадным декодером), а по наступлению паузы прогонять всю фразу через CTC декодер и языковую модель. На выходе из акустической модели мы получаем набор наиболее вероятных с фонемной точки зрения кандидатов текста того, что было сказано, и дальше декодер при помощи заранее подготовленной языковой модели определяет, какие варианты наиболее вероятны из того, что было предсказано.
Языковая модель у нас в данный момент строится при помощи KenLM. Для её подготовки нужно собрать большой корпус разговорных неразмеченных текстов (гигабайты текстов): по предложению на строку в одном большом текстовом файле. Учимся мы на десятках гигабайтов текстов. В такой корпус мы подмешивали те данные, которые у нас были размечены из реальных аудио. В итоге получили достаточно неплохие результаты, однако здесь надо понимать, что данные надо также валидировать и очищать от различного мусора. Хороший буст качества для конкретного заказчика можно получить просто расширив языковую модель под его тематику.
Дальше к получаемым от ASR текстам мы применяем различные варианты улучшения внешнего вида. Например, мы обучили BERT восстанавливать пунктуацию. Он расставляет запятые, точки, вопросительные знаки просто по текстовому представлению. Также мы добавили перевод чисел, представленных словами, в цифры по словарю. В планах добавить аббревиатуры, зарубежные названия, имена, названия городов и компаний.
Бенчмарк
Вот к таким результатам нам удалось прийти на сегодняшний день:
Пример аудио тестового датасета из колл-центра компании-партнёра:
Из тестового датасета голосовых сообщений, записанных с микрофонов различных пользовательских устройств:
Здесь сразу нужно вставить несколько ремарок: в наших тестовых датасетах представлены данные, на которых мы гарантированно не обучали ни одну из наших моделей, оба датасета состоят из 500 моноканальных записей каждый в 8 кГц и 16 кГц для телефонии и микрофонов пользовательских устройств, все аудио длиной от 1.8 секунд до 6 секунд. Длина аудио в тестовых датасетах такая, потому что мы резали аудио записи по тишине, которая наступает между репликами в разговоре, либо в монологе.
Наши модели отмечены в бенчмарке цветом. NLab Speech – наше проприетарное решение и SOVA ASR – наше Open Source решение. Одно из ключевых решений, принятых нами – разделение на две независимые модели, одна из которых работает с телефонными данными и обучается на записях из колл-центров, а вторая – модель для работы с микрофонами пользовательских устройств, таких как смартфоны, ноутбуки и т. д. Это позволило получить качественный скачок в обоих направлениях.
Мы недавно выложили в открытый доступ наш движок распознавания речи, который построен на архитектуре wav2letter, в бенчмарках он обозначен как SOVA ASR, в нём также есть две раздельные акустические модели для 8 кГц и работы с телефонными звонками и 16 кГц для работы с микрофонами пользовательских устройств, которые можно использовать в зависимости от ваших потребностей. Для корректности сравнения с VOSK (тоже открытое распознавание речи от Николая Шмырёва) мы использовали языковую модель из релиза VOSK API для русского языка версии 0.10 (лишь превратив .arpa файл языковой модели в бинарник и собрав по этому файлу его лексикон). Вы также можете сами построить собственную языковую модель, которая будет совместима с SOVA ASR, просто воспользовавшись тулкитом KenLM и заготовив большой корпус текстов.
Говоря о производительности решений, не очень корректно сравнивать между собой различные API, так как решения расположены на разных хостах, и узким местом может оказаться передача файлов, но с VOSK мы провели сравнение, так как решение было у нас развёрнуто локально на виртуальной машине с процессором Intel® Xeon® Platinum 8259CL CPU @ 2.50GHz. В качестве показателя скорости мы взяли отношение среднего времени распознавания (при уже инициализированных моделях) к общей длине распознаваемых файлов, и получили следующие результаты:
По расходу оперативной памяти SOVA ASR потребляет в пределах 2 GB RAM (как и VOSK, при использовании той же языковой модели), и может работать как на CPU, так и на GPU. GPU позволяет экономить ресурсы процессора и обеспечивать большее количество одновременных потоков при расходе ресурсов процессора с экономией до 10 раз.
Выводы
Итак, что же необходимо учесть при создании собственного распознавания речи?
Сначала нужно подготовить инструменты для сбора и обработки данных, получить датасеты из нарезанных аудио с отекстовками. Данные нужны конкретного вида (если это колл-центр, то нужны записи звонков). Максимально автоматизировать сбор данных.
Выбрать акустические признаки и свою архитектуру нейронных сетей для их перевода в текстовые представления. Обучить акустическую модель. Максимально оптимизировать обучение акустической модели, так как это самая трудоёмкая по времени часть. Повышать качество акустической модели можно также при помощи добавления всевозможных аугментаций.
Собрать текстовый корпус по интересующей нас тематике и построить на нём языковую модель, реализовать учёт данных о частотности в декодере, обрабатывающем выходы акустической модели. Итоговое качество сильно будет зависеть от языковой модели, так как чтобы правильно распознавать слова, нужно знать об их существовании, их написании и контекстной встречаемости (в противном случае система будет пытаться предложить что-то созвучное, про что она знает, вместо правильного варианта). Надо разделять предложения по тишине и производить декодинг отдельных частей (иначе языковая модель может внести артефакты, попытавшись объединить подряд идущие предложения в связное одно).
Улучшать внешний вид и кастомизировать текстовые результаты под конкретные запросы, будь то восстановление пунктуации, либо перевод зарубежных названий в латиницу по словарю.
Планы на будущее
В ближайшем будущем мы планируем продолжать эксперименты с языковыми моделями. Многообещающим выглядит новый проект Smart Language Model. Также мы планируем расширять обучающий корпус, добавляя преимущественно живую разговорную речь.
Кроме того, мы улучшаем потоковое распознавание и занимаемся оптимизацией и балансировкой нагрузки.
Периодически приходят запросы по диаризации (разделению моно на 2 канала) аудио, существующие Open Source решения нас не устраивают по качеству, и тут тоже есть пространство для экспериментов.
Также хочется отметить, что не стоит останавливаться на одной технологии, если у вас получилось что-то с ней сходу достичь, но дальше у вас происходит застой. Так, мы отошли от акустической модели wav2letter, которая обучается на аннотированных данных, и перешли к обучению на неразмеченных данных (подход wav2vec), что дало хороший прирост качества.
SOVA.ai
Упомянутая в статье SOVA ASR – часть более крупного Open Source проекта SOVA.ai: мы делаем открытую платформу для создания голосовых помощников. Нас поддержал государственный фонд РВК. Государство в принципе поддерживает Open Source проекты, в том числе, в рамках Федерального проекта «Искусственный интеллект».
Данные и софт распостраняются под свободной лицензией Apache 2.0 (можно использовать для коммерческих целей).
Наши наработки доступны тут: наш GitHub
Распознавание речи: SOVA ASR
Датасет для распознавания речи: SOVA Dataset
Синтез речи: SOVA TTS
В течение месяца мы выложим больше данных, а в ноябре будут интересные релизы наших новых утилит.
Если то, что мы делаем, вам интересно – пишите, можем посотрудничать. Как на коммерческих проектах, так и в Open Source.
Спасибо за внимание!


