
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Всех приветствую! Я планирую создать цикл статей, демонстрирующий распространенные ошибки, влияющие на производительность приложения со стороны бэкенда, а также методы их поиска и устранения. Для этого, я написал приложение, в котором специально допустил различные ошибки, чтобы по порядку найти и исправить их.
В текущей статье, рассмотрим темы - n+1, пагинация и индексы. Приятного чтения!
Описание приложения
Рассматриваемый проект - это веб-журнал посещений различных мест людьми с возможностью выгрузки и загрузки журнала в формате XML. Пользователь может загрузить журнал посещений в формате XML через форму на странице /upload, и на основе информации из файла будет заполнена база данных. Вся информация о посещениях будет отображаться на главной странице /index. Экспорт из системы осуществляется через команду, которая преобразует информацию из системы в формат XML и выгружает ее в файл (data.xml).
Схема данных:
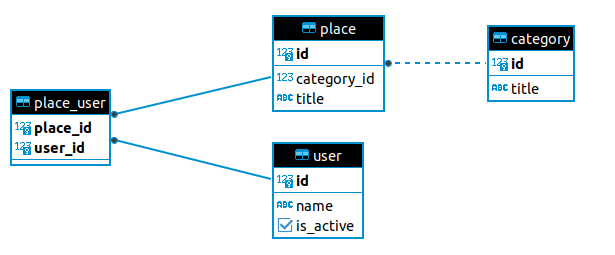
Самостоятельно ознакомится с проектом можно в репозитории. Проект написан на Symfony 6.2, postgreSQL 15.
Дисклеймер
Проект написан с учебной целью и не претендует на хорошую практику, так как некоторые важные элементы отсутствуют или упрощены, в надежде, что читатель заинтересуется темой и воспользуется профессиональной литературой.
n+1
Проблема n+1 (также известная как проблема дополнительных запросов) возникает в контексте использования объектно-реляционных отображений (ORM), когда при загрузке связанных данных из базы данных дополнительно загружаются связанные сущности. Иными словами, когда делаем n запросов, а могли бы запросить те же данные одним запросом (или по крайней меньшим количеством).
Так как пример написан на Symfony, то для поиска проблемы, воспользуемся Symfony Profiler.
Начнем с изучения главной страницы (/index):

Можно заметить, что на ней нет медиа, стилей и js, страница загружается долго, а также 1268 запросов, что косвенно указывает на проблему n+1.
Перейдем в QueryMetrics, посмотрим на запросы, выполняемые при вызове /index:
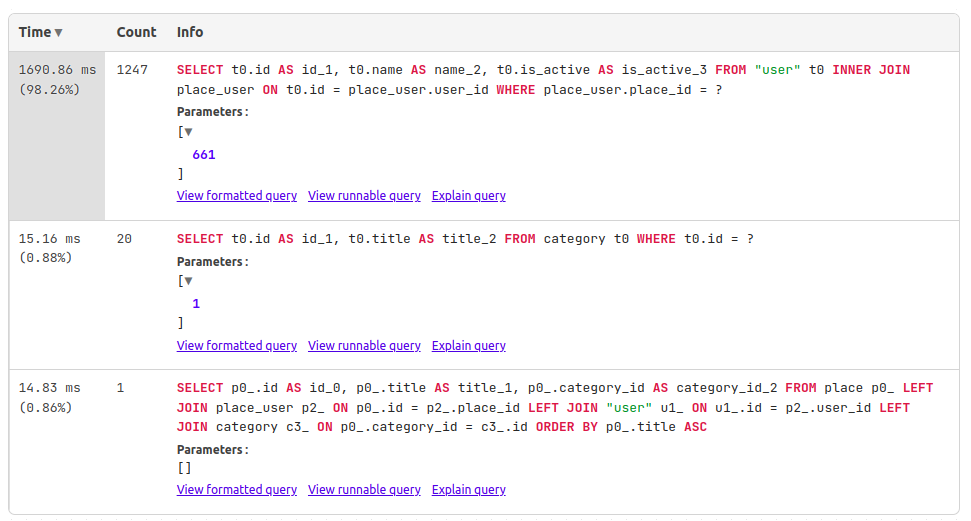
99% запросов не уникальные, что подтверждает наличие проблемы n+1. Далее, последовательно проанализируем код.
Это метод контроллера (IndexController), обрабатывающий запрос к странице /index:
#[Route('/', name: 'app_index_index', methods: ['GET'])]
public function index(IndexService $service): Response
{
return $this->render('index/index.html.twig', [
'data' => array_map($service->getTransformerForIndex(), $service->getIndexList()),
]);
}Ничего не обычного, всё интересное находится в сервисе (IndexService), в котором находятся методы для получения данных (getIndexList()) и трансформации данных (getTransformerForIndex()) в нужный формат.
Посмотрим на метод getTransformerForIndex() в IndexService:
public function getTransformerForIndex(): Closure {
$transformer = function (Place $place) {
return [
'title' => $place->getTitle(),
'category' => $place->getCategory()->getTitle(),
'users' => $place->getUsers()->reduce(fn($item,User $user) =>
$item .= $user->getName() . '| '
)
];
};
return $transformer;
}В этом методе как раз и происходит дополнительная загрузка связанных сущностей, а именно, получение категории $place->getCategory() (не можем же мы без категории, получить её название) и преобразование имен людей посетивших это место в строку (соответственно, с загрузкой всех посетителей $place->getUsers()).
Почему тогда, метод ($service->getIndexList()), который делает запрос на получение данных, не запрашивает сразу связанные сущности? Обратимся к методу getIndexList():
public function getIndexList(): array {
return $this->em
->getRepository(Place::class)
->createQueryBuilder('p')
->select('u','c','p')
->leftJoin('p.users', 'u')
->leftJoin('p.category', 'c')
->orderBy('p.title', 'ASC')
->getQuery()
->getResult();
}Действительно, этот код будет работать, но связанные сущности он не загружает, а загружает только Place. Для того, чтобы получить все связанные сущности, нужно их тоже выбрать! Добавим выборку связанных сущностей (user, category) в метод getIndexList():
public function getIndexList(): array {
return $this->em
->getRepository(Place::class)
->createQueryBuilder('p')
->select('u','c','p')
->leftJoin('p.users', 'u')
->leftJoin('p.category', 'c')
->orderBy('p.title', 'ASC')
->getQuery()
->getResult();
}Посмотрим результат, перейдем на страницу /index:
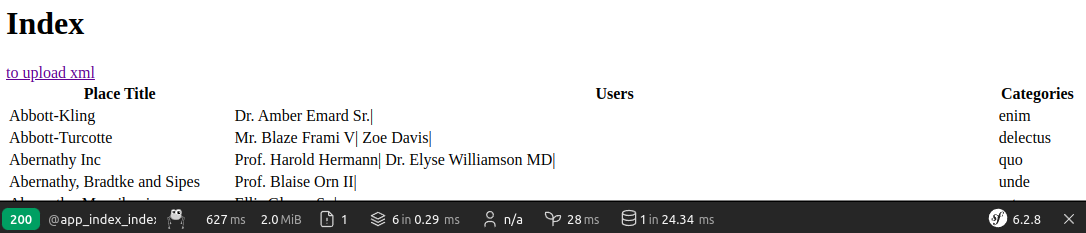
Одной строчкой кода, производительность выросла в 74 раза! Удалось сократить 1268 запросов до 1 и повысить скорость выполнения запросов с 1793 мс до 24 мс.
В разобранном примере, оптимизирован запрос составленный через QueryBuilder, но в большинстве случаев, ORM уже имеет механизмы для загрузки связанных сущностей, советую изучить эти механизмы по запросу в поисковике - lazy/eager/etc fetch {orm_name}.
Пагинация
Пагинация - это метод разбиения данных на части для удобства навигации и оптимизации ресурсов. Предлагаю к рассмотрению, два часто встречающихся вида пагинации - смещением и курсорная.
Пагинация смещением - это подход, при котором данные разбиваются на страницы с определенным количеством элементов на странице. При переключении на следующую страницу происходит смещение (offset) на определенное количество элементов (limit).
Курсорная пагинация - это подход, при котором каждый элемент списка имеет уникальный идентификатор (курсор), по которому можно определить его местоположение в списке. При переключении на следующую страницу используется курсор последнего элемента на текущей странице для получения следующих элементов. Важно, чтобы курсор был уникальным полем в таблице и элементы выводились в последовательности (были отстортированы по полю-курсору). Курсорная пагинация производительнее чем смещением, так как используется только limit и уникальное поле.
Когда использовать смещением, а когда курсорную? Если нужна пагинация на отсортированом списке по уникальному полю, и нет нужды в навигации по страницам (пример, лента новостей в соц.сетях), хорошее решение курсорная. В других случаях, сложность реализации и полученная выгода от курсорной падает, лучшим выбором будет смещением.
Приступим к практике. Сделаем оба вида пагинации, для этого, будем передавать значения ( {limit,offset} - для пагинации смещением, {limit,cursor_title} - для курсорной, так как поле place.title - уникальное и происходит сортировка по этому полю) GET запросом и модифицировать данные исходя из переданных значений.
Получим request в контроллере и передадим его в $service->getIndexList(), который делает запрос на получение данных:
#[Route('/', name: 'app_index_index', methods: ['GET'])]
public function index(IndexService $service, Request $request): Response
{
return $this->render('index/index.html.twig', [
'data' => array_map($service->getTransformerForIndex(), $service->getIndexList($request)),
]);
}Модифицируем запрос, исходя из полученных значений:
public function getIndexList(Request $request): array {
$q = $this->em
->getRepository(Place::class)
->createQueryBuilder('p')
->select('u','c','p')
->leftJoin('p.users', 'u')
->leftJoin('p.category', 'c')
->orderBy('p.title', 'ASC');
// Пагинация смещением
if((null !== $request->get('limit')) && (null !== $request->get('offset'))) {
$q->setFirstResult((int)$request->get('offset'));
$q->setMaxResults((int)$request->get('limit'));
};
//Курсорная пагинация
if((null !== $request->get('limit')) && (null !== $request->get('cursor_title'))) {
$q->where('p.title > :cursor');
$q->setParameter('cursor', $request->get('cursor_title'));
$q->setMaxResults((int)$request->get('limit'));
};
return $q->getQuery()->getResult();
}Сравним результаты, для этого сделаем запросы на получение одинаковых данных к пагинациям.
Пагинация смещением. Запрос: /index/?limit=200&offset=1000. Результат:
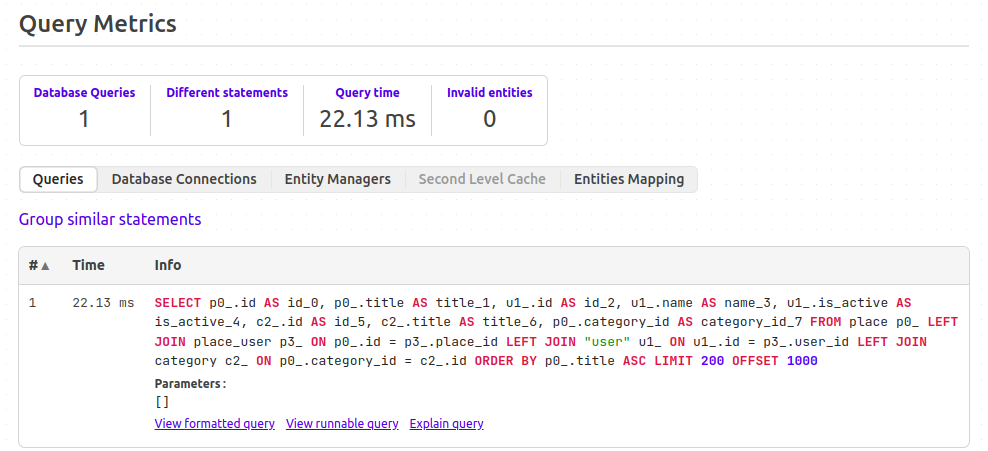
Пагинация курсорная. Запрос: /index/?cursor_title=Marks%2C%20Hilpert%20and%20Langosh&limit=200. Результат:
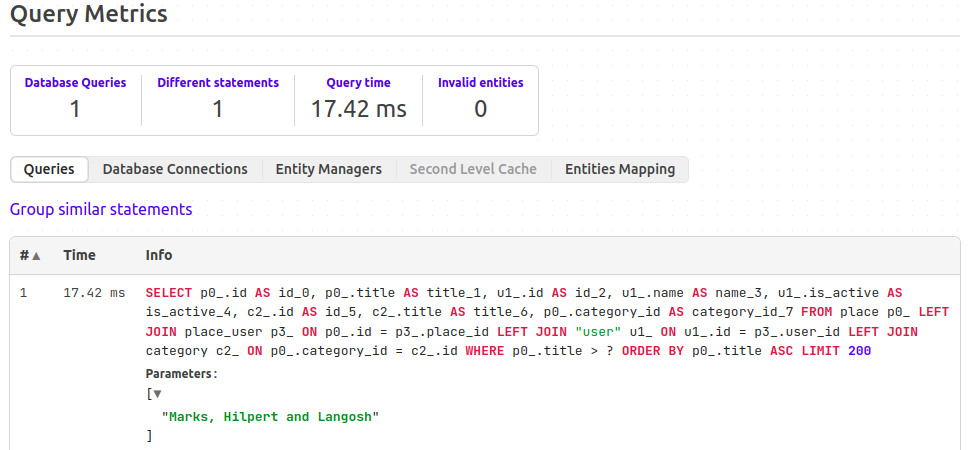
Курсорная пагинация показывает лучшие результаты, так как в запросе выбираются 200 элементов, в то время, как в пагинации смещением, выбираются 1200 элементов и 1000 отбрасываются.
Индексы
Индексы в базах данных – это механизмы, которые ускоряют поиск и выборку данных из таблиц. Индексы создаются на одном или нескольких полях таблицы и содержат отсортированные значения этих полей вместе с ссылками на соответствующие записи.
В большинстве случаев, индекс это btree (но и применяются другие структуры данных, например Hash)
Важно отметить, что создание слишком большого количества индексов может снизить производительность базы данных, так как при каждой операции изменения данных приходится обновлять все индексы. Поэтому необходимо балансировать между количеством индексов и их эффективностью.
Посмотрим какие индексы сейчас присутствуют в бд:
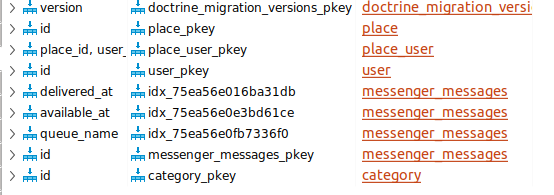
В релевантных таблицах (place,user,category) только первичные ключи.
Тогда, создадим дополнительные индексы для улучшения производительности. Но по каким полям создавать? Чтобы ответить, проанализируем запрос, на примере запроса, который формируется при курсорной пагинации (index/?cursor_title=Marks%2C Hilpert and Langosh&limit=200)
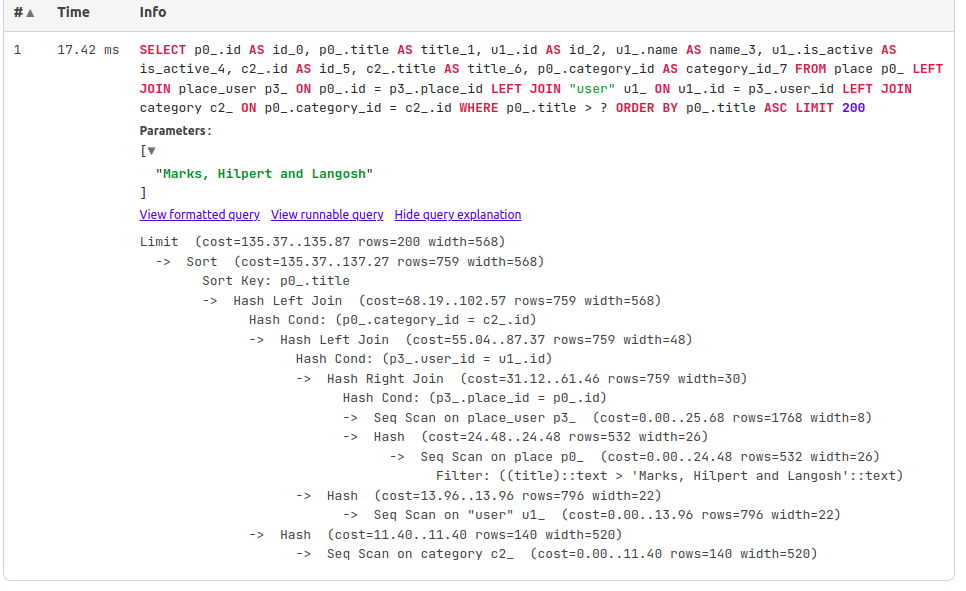
В поиске участвуют первичные, внешние ключи, название места. Создадим индексы по этим полям:
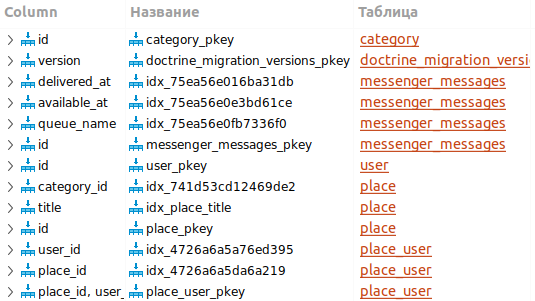
Проверим скорость выполнения с индексами:
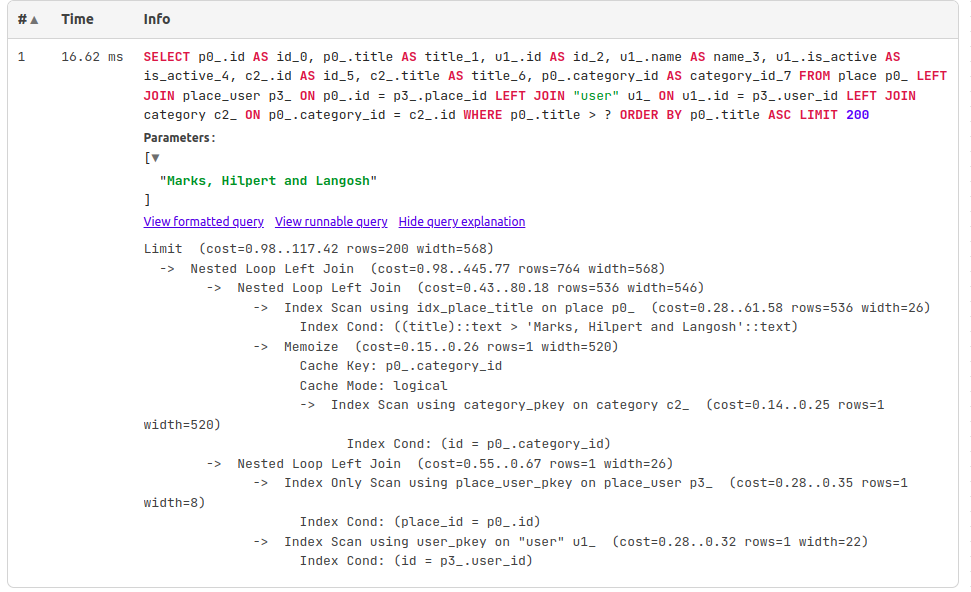
Запрос выполняется немного быстрее.
Обратите внимание на объяснение запросов до и после создания индексов. Почему Hash стал Nested loop и что это такое? А что будет, если обратиться к /index без пагинации (с индексами и без), Hash или Nested loop? (используется postgres15, в таблице Place > 1000, User > 700 записей), а если возьмем MySQL 5.4? Будет ли разница между select count(*) from place и select count(title) from place, займут эти запросы время больше чем О(1) или субд будет что то считать? На каких столбцах в 95% случаях следует создать индекс? Вопросы на подумать)
Вместо итогов
Рассмотренные методы в статье, позволили снизить нагрузку, увеличили скорость выполнения и добавили удобства навигации. В следующих статьях, познакомимся с методами оптимизации при записи данных, затронем такие темы: UnitOfWork, batching, утечки памяти (циклические ссылки и сборщик мусора PHP) и не рассмотренные темы оптимизации получения данных. Если статья понравилась, ставьте классы. Всем добра!




")